数据预处理
短期数据
short_data = pd.read_csv('short-customer-data.csv') # 导入数据
print(short_data.shape) # 查看短期数据集的大小
short_data.head()
# 41176行14列)问题:探索短期数据各指标数据的缺失值和“user_id”列重复值,删除缺失值、重复值所在行数据
short_data = short_data.dropna(axis = 0) # 按行删除缺失值
short_data = short_data.drop_duplicates('user_id',keep='first') # 保留第一次出现的重复值,删除剩余重复值
short_data = short_data.reset_index(drop = True) # 重置索引
short_data.shape # 查看短期数据集的大小
#30445行14列长期数据
long_data_train = pd.read_csv('long-customer-train.csv') # 导入数据集
print(long_data_train.shape) # 查看数据集大小
long_data_train.head()
# (9300行11列)问题:长期数据中的客户年龄“Age”列存在数值为-1、0 和“-”的异常值,删除存在该情况的行数据
long_data_train['Age'].sort_values() # 降序查看数据情况根据输出结果可知,存在 ‘-‘ 这类异常值,所以对它进行清洗
long_data_train = long_data_train[
long_data_train['Age'] != '-'].reset_index(drop = True) # 筛选出无 “-”异常值的数据
print('清洗完含“-”的异常值后的数据大小:',long_data_train.shape)
#清洗完含“-”的异常值后的数据大小: (9222, 11)从原本的9300行降为9222,说明数据处理成功(也可以再按照排序查看数据情况)。根据处理后的数据继续处理后续两个异常值。利用降序查看数据情况的方法可知,经过上一次数据清洗后,再用下面的代码可知,没有 -1 这类异常值,但有 0 这类的异常值,所以只需要处理异常值为0的数据
long_data_train['Age'].apply(lambda x : 1 if x == 0 else 0).sum() # 查看异常值的数据类型
long_data_train['Age'].apply(lambda x : 1 if x == '0' else 0).sum() # 查看异常值的数据类型由上面的代码块可知,0 这类异常值的数据类型是字符型的,所以筛选清洗时用字符型进行索引
long_data_train = long_data_train[
long_data_train['Age'] != '0'].reset_index(drop = True) # 筛选掉含有 0 异常值的行
print('清洗完含“0”的异常值后的数据大小:',long_data_train.shape)
#清洗完含“0”的异常值后的数据大小: (9198, 11)从上一次清洗结果,行数由9222变为9198,说明清洗成功。
问题:“Age”列存在空格和“岁”等异常字符,删除这些异常字符但须保留年龄数值
print('含有异常字符的样本量为:',
long_data_train['Age'].apply(lambda x : 1 if ' ' in x or '岁' in x else 0).sum())
long_data_train['Age'] = long_data_train['Age'].apply(lambda x : x.replace(' ','').replace('岁','')).sort_values()
print('清洗异常字符后,存在异常字符后的样本量为:',
long_data_train['Age'].apply(lambda x : 1 if ' ' in x or '岁' in x else 0).sum())pandas中用apply结合lambda的匿名函数,能减少用for while等循环和定义函数的写法。上面的代码主要是将单元格里的异常字符替换为无,其他的数据保持不变,实现删除异常字符且保留数值的结果。
# 查看年龄的结果
long_data_train['Age'].sort_values() # 存在年龄为1的客户
#所以删除这部分信息
long_data_train = long_data_train[long_data_train['Age'] != '1']
long_data_train['Age'] = long_data_train['Age'].apply(lambda x : int(x))同时,对数据清洗时查看是否有问题,可以通过describe函数进行查看。
例如:当年龄特征未进行数据类型转换时,通过describe函数查看是不存在年龄特征的数据的,因为它是字符型数据,所以无法计算。这时候就可以通过转换数据类型使得字段可计算。同理,转换后的年龄字段,最小值为1,结合实际情况分析可知,银行客户的年龄不可能为1岁,所以可以判定为异常值。
数据分析
定义画图的全局变量
import warnings
from matplotlib.font_manager import FontProperties
# 导入中文为宋体,英文为新罗马的字体
config = {
"font.family":'serif',
"font.size": 18,
"mathtext.fontset":'stix',
"font.serif": ['SimSun'],
}
plt.rcParams.update(config)
warnings.filterwarnings("ignore") # 忽略版本之类的警告信息短期数据
问题:计算短期数据所有指标之间的相关性,绘制相关系数热力图,并在报告中对结果进行必要分析。
常见相关系数的使用条件:
皮尔逊相关系数:线性关系,正态分布,数据为连续型数据,三者缺一不可
斯皮尔曼相关系数:不满足皮尔逊相关系数的条件中任何一条即可使用
肯德尔相关系数:和斯皮尔曼差不多,只不过从协同角度进行考虑关系
考虑到短期数据中存在多个离散型数据,所以采用斯皮尔曼相关系数进行处理。
# 斯皮尔曼相关系数计算
from scipy import stats
name = short_data.columns.tolist()[1:] # 获取短期数据除去用户id的特征名
dic = dict() # 将特征名按照字典的形式存储,便于dataframe重名
for i in range(len(name)):
dic.update({i:name[i]})
Spearmanr = pd.DataFrame(stats.spearmanr(short_data.iloc[:,1:])[0]) # 计算相关性结果,并转为dataframe形式
Spearmanr = Spearmanr.rename(columns = dic).T.rename(columns = dic) # 转置相关性结果,并重命名
# 将计算结果以热力图的形式呈现
from pyecharts import options as opts
from pyecharts.charts import HeatMap
value = [[i, j,round(Spearmanr.iloc[i,j],3)] for i in range(len(Spearmanr.columns)) for j in range(len(Spearmanr.columns))]
c = (
HeatMap(init_opts=opts.InitOpts(bg_color= '#fff'))
.add_xaxis(name)
.add_yaxis("",name, value,label_opts=opts.LabelOpts(is_show=True, position="inside"))
.set_global_opts(
title_opts=opts.TitleOpts(title=""),
visualmap_opts=opts.VisualMapOpts(
max_=1,
min_=-1,
is_show = True,
pos_right = "right"
),
)
#.render("heatmap_base.html")
)
c.render_notebook()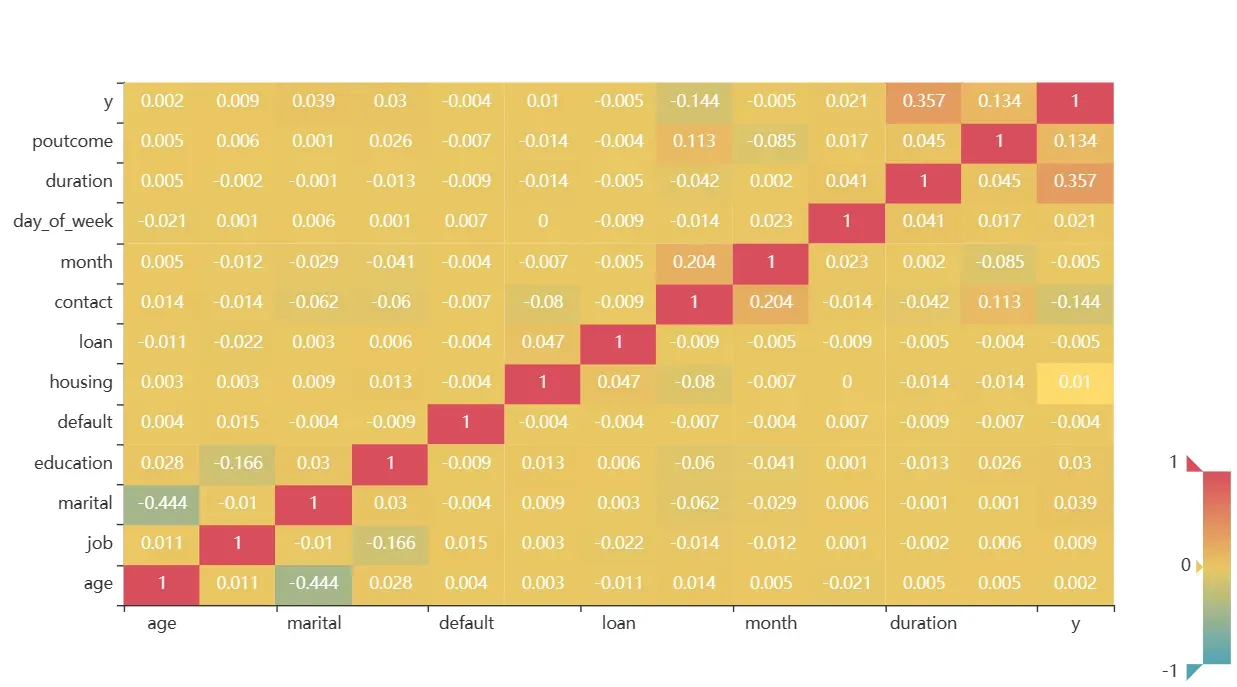
由热力图可知,
银行活动客户是否购买产品与最近一次拜访客户的通话时长、上一次银行活动呈现正相关关系,即随着通话时长的增加或上一次银行活动成功可能性的增加,银行客户更加愿意购买活动产品。银行活动客户是否购买产品与手机类型呈现负相关关系,即使用座机或传统手机的客户更加愿意购买产品。
客户年龄与婚姻状况呈现负相关关系,即年龄越高,婚姻状态越容易趋向于离婚或丧偶。
题目:在同一画布中,绘制反映两种产品购买结果下不同年龄客户量占比的分组柱状图,x 轴为年龄,y 轴为占比数值。
处理思路:
取出不同购买结果的数据集
利用value_counts函数按照某个特征进行分组聚合
根据分组聚合后的结果,用apply结合lambda匿名函数进行计算占比量——每个年龄的人数除以总人数
# 获取购买产品的客户年龄数据,按照年龄进行分组计数且按年龄升序排序
yes_age = pd.DataFrame(short_data[
short_data['y'] == 'yes']['age'].value_counts().sort_index())
yes_age_x = yes_age.index # 索引为客户的年龄
yes_age_y = yes_age['age'].apply(lambda x : x/yes_age['age'].sum()) # 计算每个年龄的人数占比量
# 同理,获取为购买产品客户的信息
no_age = pd.DataFrame(short_data[short_data['y'] == 'no']['age'].value_counts().sort_index())
no_age_x = no_age.index
no_age_y = no_age['age'].apply(lambda x : x/no_age['age'].sum())
# 将上述的信息进行可视化
plt.figure(figsize=(14,6),facecolor='#fff',dpi=300) # 定义画布
plt.bar(yes_age_x,yes_age_y,color = 'teal',alpha=0.5) # 购买产品的客户数据图
plt.bar(no_age_x,no_age_y,color = 'lightpink',alpha= 0.5) # 为购买产品的客户数据图
plt.xlabel('年龄',fontdict={'fontsize':12}) # 横坐标的标题和字体大小
# 纵坐标的标题和字体大小,以及标题的位置
plt.ylabel('各年龄的人数占比量',y = 1.04,rotation = 360,fontdict={'fontsize':12})
# 图例
plt.legend(['购买产品的客户','未购买产品的客户'])
plt.show()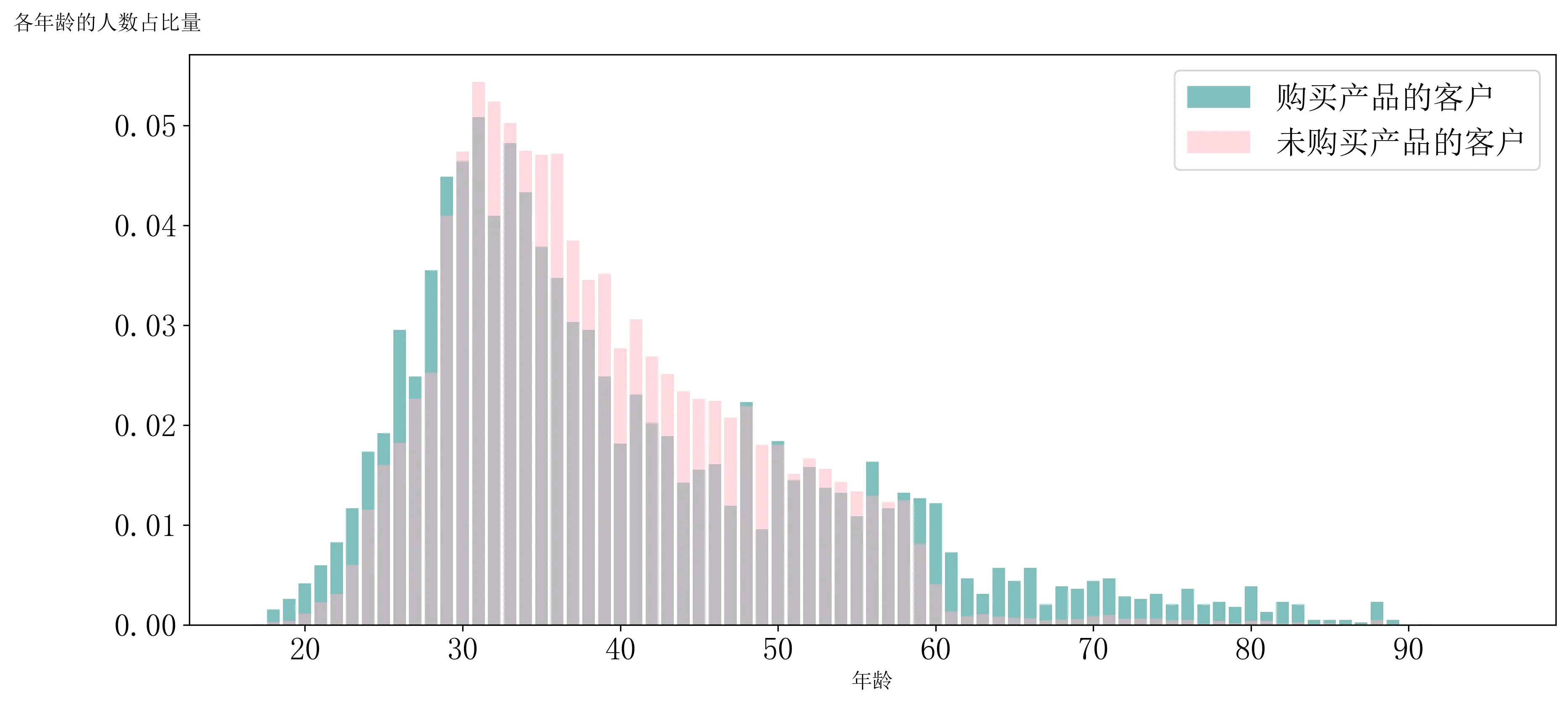
购买产品的客户和未购买产品的客户主要集中在18~60岁区间内,以30岁为界限,前面的人群主要为购买产品的,后面的人群主要为未购买产品的。在状老年群体中购买产品的占比量大于未购买产品的占比量。
题目:在同一画布中,绘制蓝领(blue-collar)与学生(student)的产品购买情况饼图,并设定饼图的标签,显示产品购买情况的占比。
按照上一个代码的逻辑:
筛选出蓝领和学生的信息
按照是否购买产品和职业信息进行分组聚合 (groupby函数和value_counts函数任选)
计算不同购买情况和不同职业下的人数占比量(这里用饼图展示,则可以少了这一步,否则用apply和lambda进行计算)
stu_blue = short_data[
(short_data['job'] == 'student') | (short_data['job'] == 'blue-collar')
].reset_index(drop = True) # 筛选出满足蓝领和学生的信息,并重置索引
stu_blue = pd.DataFrame(
stu_blue.groupby(['y','job']
).count()['user_id']).reset_index(['job','y']) # 按照购买情况和职业进行分组聚合(计数),并重置索引
# 将两个特征信息组合起来,作为一个新列,方便给图表的标签进行标注
stu_blue['label'] = stu_blue['y'] + '_'+ stu_blue['job']
plt.figure(figsize=(4,3),facecolor='#fff',dpi=300)
patches,l_text,p_text=plt.pie(
stu_blue['user_id'], # 数据
labels = stu_blue['label'], # 每块饼的标签
colors = ['crimson','lightpink','teal','lightskyblue'], # 每块饼的颜色
autopct = "%.1f%%", # 每块饼里面的数值格式
explode = [0.05, 0.05, 0.05, 0.05]) # 每块饼之间的间隔大小
# 每个饼里面的数值大小
for t in p_text:
t.set_size(8)
# 每个饼的标签大小
for t in l_text:
t.set_size(6)
plt.show()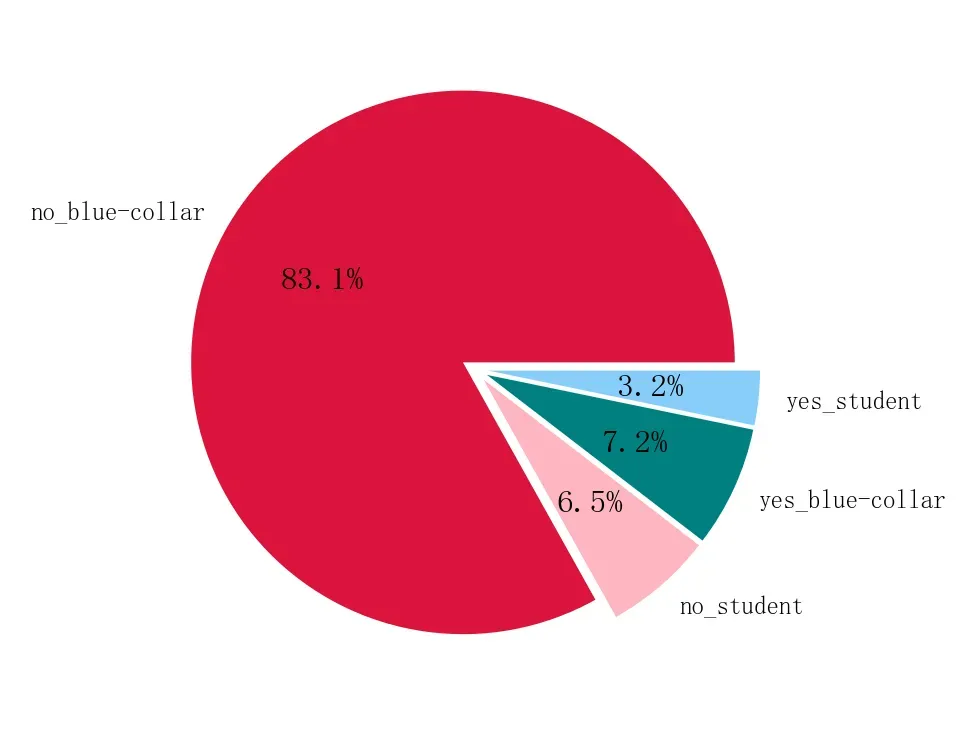
从图中可知,职业为蓝领且未购买产品的人数占83.1%,其次是职业为蓝领且购买产品的人数、职业为学生且未购买产品的人数、职业为学生且购买产品的人数,说明各个职业的未购买产品的人数占比可能均要大于购买产品的人数占比。
就此图而言,购买产品的主力人群为蓝领。从业务角度思考,分析蓝领为什么存在大量未购买产品的原因是提升产品销量的一个重要问题。
题目:以产品购买结果为 x 轴、拜访客户的通话时长为 y 轴,绘制拜访客户的通话时长箱线图。
duration_yes = short_data[short_data['y'] == 'yes']['duration'] # 获取购买产品的客户通话时长
duration_no = short_data[short_data['y'] == 'no']['duration'] # 获取未购买产品的客户通话时长
# 定义一个画布,两块区域 一行两列
fig = plt.figure(figsize=(20,8),facecolor='#fff') # 定义画布的整体效果
plt.subplot(1,2,1) # 有两块区域一行两列,在第一列画上这个图
plt.boxplot(duration_yes,showmeans = True) # showmeans显示平均值的位置
plt.xticks([])
plt.xlabel('购买产品的客户')
plt.ylabel('通话时长',y = 1.04,rotation = 360)
plt.subplot(1,2,2) # 有两块区域一行两列,在第二列画上这个图
plt.boxplot(duration_no,showmeans = True)
plt.xticks([])
plt.xlabel('未购买产品的客户')
plt.ylabel('通话时长',y = 1.04,rotation = 360)
duration_yes.describe() # 查看描述性统计信息
'''
25%:下四分位数
50%:中位数
75%:上四分位数
箱型图上、下限计算:
upper = 上四分位数 + 1.5×IQR
lower = 下四分位数 - 1.5×IQR
IQR = 上四分位数 - 下四分位数
'''
IQR = 706.250000 - 245.000000
print("上限:",706.250000 + 1.5*IQR)
print("下限:",245.000000 - 1.5*IQR)
#上限: 1398.125
#下限: -446.875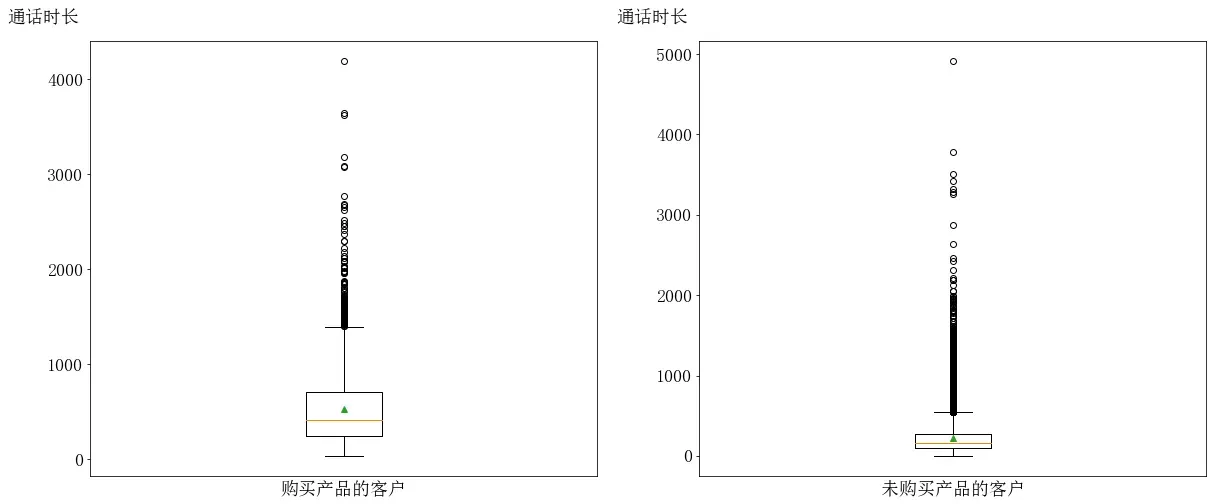
任何一类购买情况的客户通话时长的中位数靠近下方,且中位数小于平均数,说明数据的分布呈现左偏分布。
未购买产品客户的通话时长要比购买产品客户的通话时长更加集中,说明通话时长短是导致客户不购买产品的原因之一。
从箱体大小和位置分析,购买产品客户的箱体在于未购买产品客户的箱体之上,说明两种购买情况之间存在较大的差异。
长期数据
题目:在同一画布中,绘制反映两种流失情况下不同年龄客户量占比的折线图,x 轴为年龄,y 轴为占比数值。
exited_yes = pd.DataFrame(long_data_train[
long_data_train['Exited'] == 1
]['Age'].value_counts().sort_index()).reset_index() # 筛选出已流失客户的年龄信息
# 查看数据类型可知,年龄特征的数据类型为字符型,所以改为整数型
exited_yes_x = exited_yes['index'].apply(lambda x : int(x))
# 对各年龄的占比人数进行统计
exited_yes_y = exited_yes['Age'].apply(lambda x : x/exited_yes['Age'].sum())
# 下面的代码操作作用,同上
exited_no = pd.DataFrame(long_data_train[
long_data_train['Exited'] == 0]['Age'].value_counts().sort_index()).reset_index()
exited_no_x = exited_no['index'].apply(lambda x : int(x))
exited_no_y = exited_no['Age'].apply(lambda x : x/exited_no['Age'].sum())
# 绘制图形
plt.figure(figsize=(15,6),facecolor='#fff',dpi=300)
plt.plot(exited_yes_x,exited_yes_y,c = 'teal')
# 数据取索引为1开始,因为存在1岁的客户,这个是异常情况,所以不考虑
plt.plot(exited_no_x,exited_no_y,c = 'lightpink')
plt.xticks([i for i in range(18,95,3)],rotation=330)
plt.xlabel('年龄')
plt.ylabel('各年龄的人数占比量',y = 1.04,rotation = 360)
plt.legend(['已流失的客户','未流失的客户'])
plt.tight_layout()
plt.show()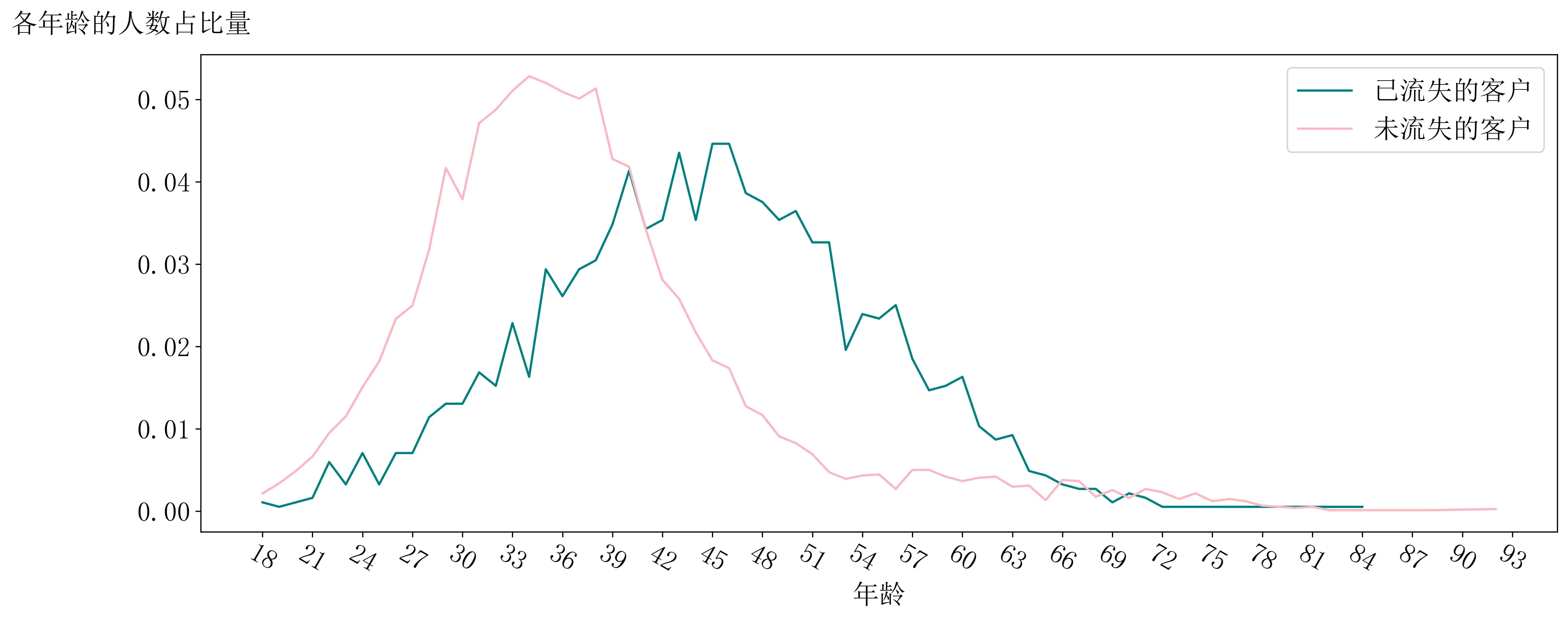
在长期数据的客户信息中,未流失的客户群体的年龄主要分布在18~51岁之间,已流失客户群体的年龄主要分布在18~69岁之间。
状老年人群的流失情况较为严重,青壮年人群的保留情况较为好,说明长期数据中产品的受众主要为青壮年人群。
题目:在同一画布中,绘制反映两种流失情况下客户信用资格与年龄分布的散点图,x 轴为年龄,y 轴为信用资格。
# 筛选出已流失信息
ca_yes = long_data_train[long_data_train['Exited'] == 1].sort_values('Age')
# 筛选出未流失信息
ca_no = long_data_train[long_data_train['Exited'] == 0].sort_values('Age')
# 绘制图形,利用子图
fig = plt.figure(figsize=(20,8),facecolor='#fff')
plt.subplot(1,2,1) #plt.subplot(3, 4, 1)
plt.scatter(ca_yes['Age'].apply(lambda x : int(x)),
ca_yes['CreditScore'],c = 'teal')
plt.xlabel('年龄',fontdict={"fontsize":16})
plt.ylabel('信用资格',y = 1.04,rotation = 360,fontdict={"fontsize":16})
plt.title('已流失的客户关系图',fontdict={"fontsize":16})
plt.subplot(1,2,2) #plt.subplot(3, 4, 1)
plt.scatter(ca_no['Age'].apply(lambda x : int(x)),ca_no['CreditScore'],c = 'crimson')
plt.xlabel('年龄',fontdict={"fontsize":16})
plt.ylabel('信用资格',y = 1.04,rotation = 360,fontdict={"fontsize":16})
plt.title('未流失的客户关系图',fontdict={"fontsize":16})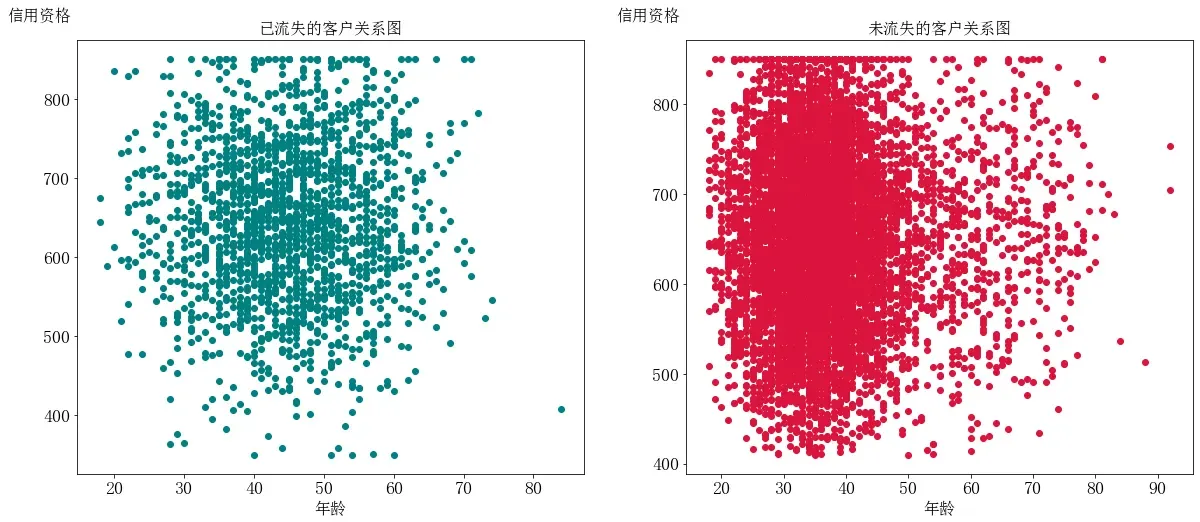
从上图可知,已流失客户的分布状况比较离散,未流失客户的分布状况整体较为离散,但在20~50岁之间存在较为集中的情况。
题目:构造包含各账号户龄在不同流失情况下的客户量占比透视表,并在同一画布中绘制反映两种流失情况的客户各账号户龄占比量的堆叠柱状图,x 轴为客户的户龄,y 轴为占比量。
from pyecharts import options as opts
from pyecharts.charts import Bar
tenure_y_n = pd.pivot_table(long_data_train,index = ['Exited','Tenure']
,aggfunc = 'count').reset_index(['Tenure','Exited'])
tenure_yes = tenure_y_n[tenure_y_n['Exited'] == 0]['CustomerId'].values.tolist()
tenure_no = tenure_y_n[tenure_y_n['Exited'] == 1]['CustomerId'].values.tolist()
print("1:",tenure_yes)
print("0:",tenure_no)
c = (
Bar(init_opts=opts.InitOpts(bg_color= '#fff'))
.add_xaxis([i for i in range(11)])
.add_yaxis("客户已流失",[i/(sum(tenure_yes)+sum(tenure_no)) for i in tenure_yes], stack="stack1")
.add_yaxis("客户未流失", [i/(sum(tenure_yes)+sum(tenure_no)) for i in tenure_no], stack="stack1")
.set_colors(["teal","lightpink"])
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title=""))
#.render("bar_stack0.html")
)
c.render_notebook()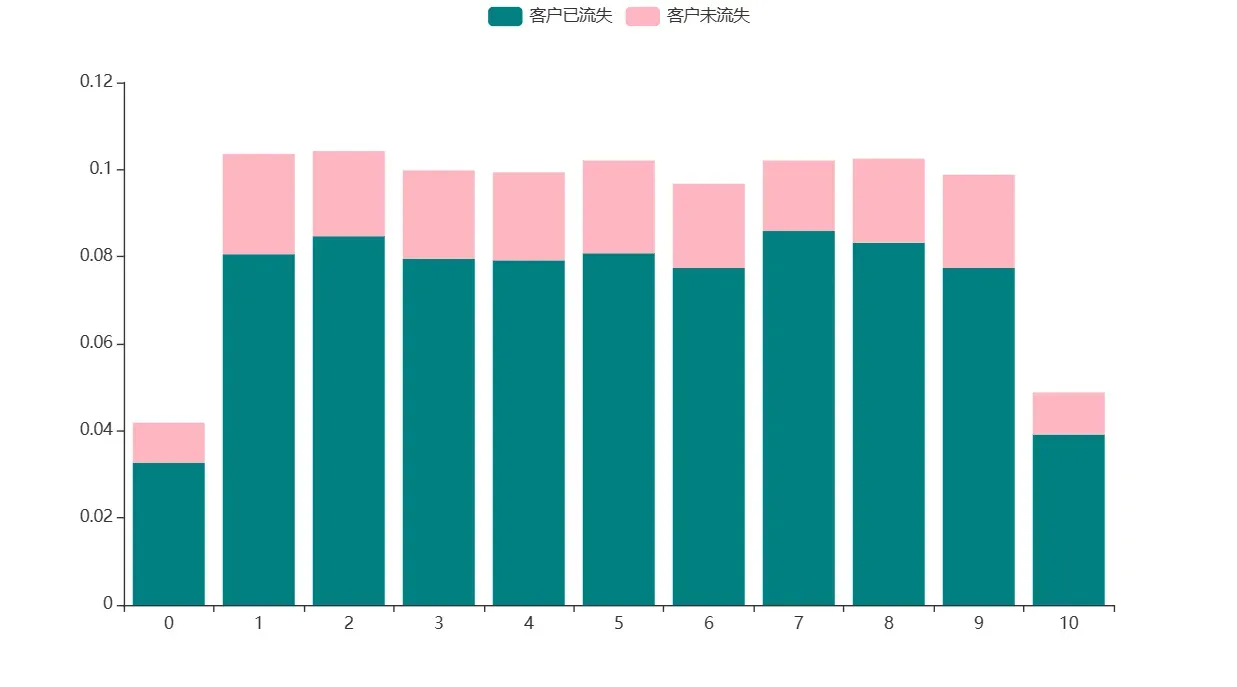
通过上图分析可知,相同账户户龄的不同流失情况之间的关系较为稳定,并没有出现较大差异的账户户龄,说明不同账户户龄之间的流失情况不存在差异。同时,账户户龄为0和11年的人数占比较少,账户户龄的人数占比主要分布在1~9年之间。
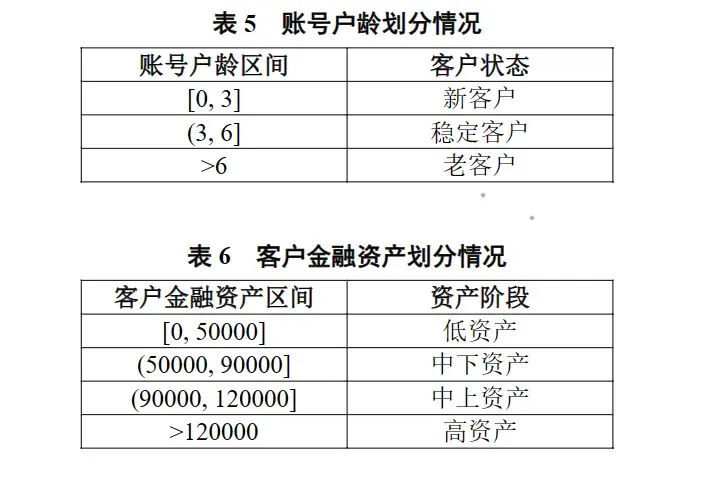
题目:新老客户各资产阶段的客户流失情况分析。按照下图对账号户龄和客户金融资产进行划分,并分别进行特征编码作为新的客户特征,统计新、老客户在各资产阶段中流失的客户量,在同一画布中绘制热力图,热力图颜色的最大和最小取值设为 1300 和 100。
# 客户类型判别
status = long_data_train['Tenure'].apply(
lambda x : '新客户'if x<=3 else '稳定客户'if x <= 6 else '老客户')
# 资产类型判别
assetStage = long_data_train['Balance'].apply(
lambda x : '低资产'if x <= 50000 else '中下资产'if x <= 90000 else '中上资产'if x <= 120000 else '高资产')
# 增加一个计数列,以dataframe的形式存在
sas_exited = long_data_train[['Exited']]
sas_exited['status'] = status
sas_exited['assetStage'] = assetStage
sas_exited['count'] = 1
# 按照客户类型和资产类型进行聚合操作
sas_et_res = sas_exited.groupby(
['Exited','status','assetStage']
).count().reset_index(['assetStage','status','Exited'])
# 按照要求筛选出新客户和老客户
sas_et_res = sas_et_res[(sas_et_res['status'] == '新客户') | (sas_et_res['status'] == '老客户')]
print([sas_et_res['count'].values.tolist(),
(sas_et_res['status'] + '_' +sas_et_res['assetStage']).values.tolist()])
# 这里面的数据在打印的数据中,手动输入(大数据需要找其他的方法进行程序性输入)
from pyecharts import options as opts
from pyecharts.charts import HeatMap
old_AssetStage = ['中上资产', '中下资产', '低资产', '高资产']
value = [
[0,0,546],
[1,0,241],
[2,0,970],
[3,0,794],
[0,1,534],
[1,1,232],
[2,1,1063],
[3,1,798],
]
c = (
HeatMap(init_opts=opts.InitOpts(bg_color= '#fff'))
.add_xaxis(old_AssetStage)
.add_yaxis("", ['新客户','老客户'],value,label_opts=opts.LabelOpts(is_show=True, position="inside"))
.set_global_opts(
title_opts=opts.TitleOpts(title=""),
visualmap_opts=opts.VisualMapOpts(max_=1300,min_=100,pos_right='left'),
)
#.render("heatmap_base3.html")
)
c.render_notebook()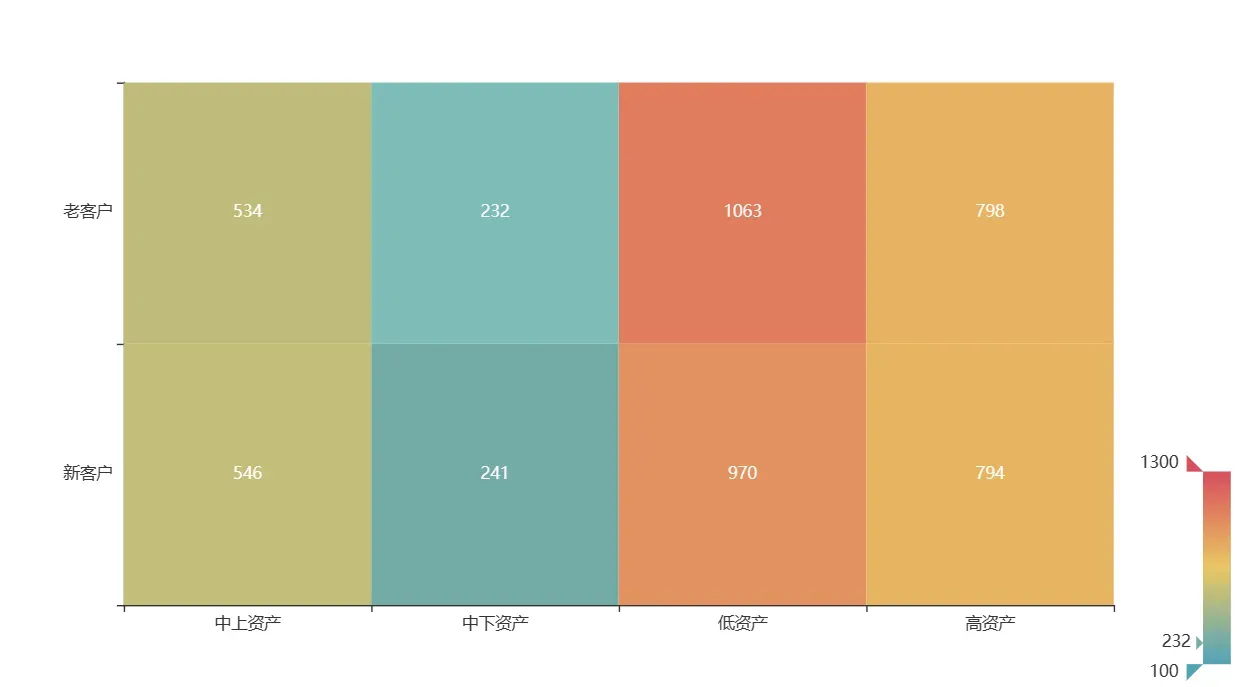
这是未流失的客户数据
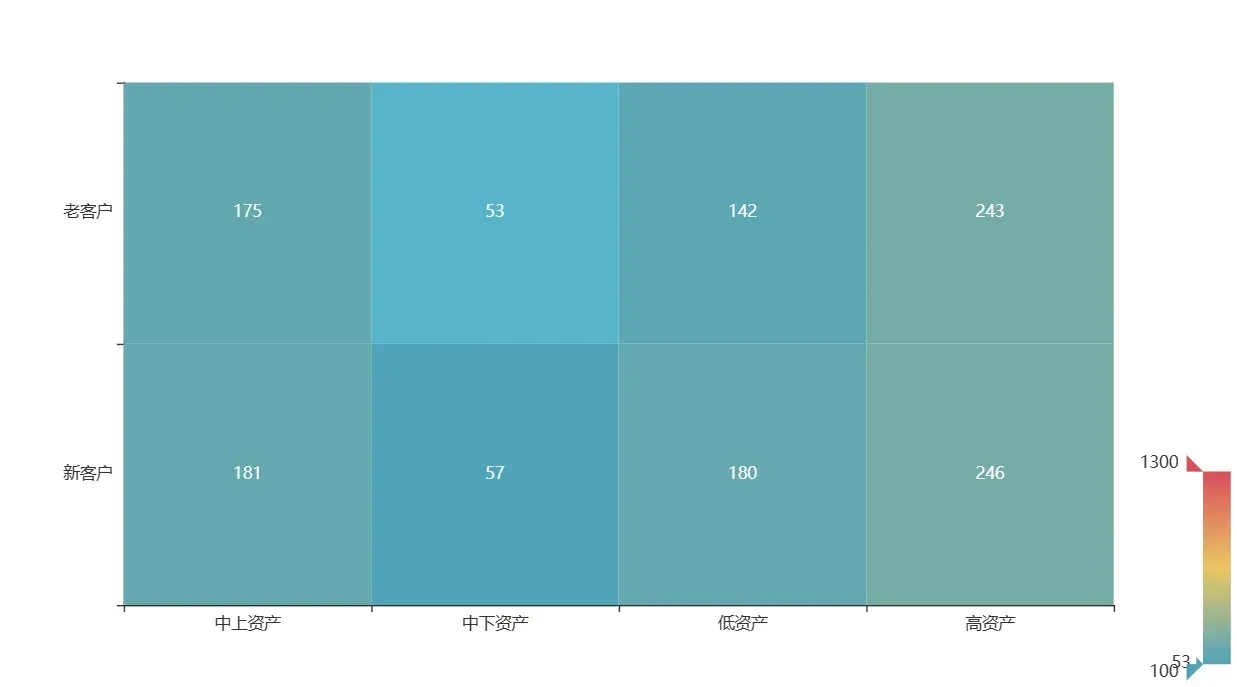
这是已流失的客户数据
题目虽然说是筛选出流失的客户量,但热力图的范围限制感觉是说明未流失的客户量。因为已流失的客户最大为246,最小为53,最小值都不在颜色棒的范围内,但是未流失的客户量均处于颜色棒的范围内。
根据未流失客户量的热力图分析可知,低资产的不同客户类型的客户量最大,其次是高资产、中上资产和中下资产,说明客户资产的分布是两头大中间的形状。同时,按照客户类型进行分析,相同资产类型的不同客户类型之间的客户量较为详尽,说明相同资产类型的不同客户类型之间的客户量不存在差异。
模型构建
题目:长期数据存在“Exited”特征分布不均衡、各项数值分布跨度大等现象。体现为:未流失客户量是已流失客户量的 3 倍以上;客户信用资格最大数值达到 25万,而客户活动状态则为 0 和 1 等。考虑上述现象,对银行客户长期忠诚度进行预测。
long_data_train['Exited'].value_counts() #查看因变量的数据情况题目中已经说了存在不平衡分布,但一般没说明数据分布状态,可以用groupby和value_counts看一下标签的分布状态。以此作为参考依据,分析采用的方法。
类别 | 样本量 |
0 | 7361 |
1 | 1837 |
从上表可知,数据之间存在不均衡的情况,所以模型构建时评价结果会倾向于大类样本的结果,导致模型的预测性较差。
不平衡数据的处理方法从大方向上分为两类——增加数据或改进算法。大多数情况下,很难增加具有真实意义的数据,因为数据的获取难度较大。所以增加数据是考虑对原始数据本身的特征和分布情况,通过一些方法进行填补补充,并不一定保证填补的数据具有真实意义的效果。改进算法,一般采用的是对小类样本的计算过程更加偏向,通过不平等的分配权重改变预测结果。
在PYTHON中处理不平衡数据的第三方库为imbalanced-learn,下面是第三方库的安装方法:
# 正常安装,可能速度较慢
pip install imbalanced-learn
# 清华源安装,可能出现一些不可预测的报错,一般情况下换源即可
pip install imbalanced-learn https://pypi.tuna.tsinghua.edu.cn/simple特征处理
首先,对进行构建模型的特征进行转换和筛选。
按照数据的实际意义可知
性别、信用卡持卡状态、活动状态三个特征为离散型变量;
用户id 只是一个标识列,无任何意义,故不参与模型构建;
其他的特征可认为连续型变量
对于定性变量采用特征编码的方法主要为独热编码处理,其原理是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。例如:
性别 | → | 性别_男 | 性别_女 |
男 | 1 | 0 | |
女 | 0 | 1 | |
男 | 1 | 0 |
# 将数据分为定性和定量两类数据,对定性数据进行特征编码
qual = long_data_train[['Gender','HasCrCard','IsActiveMember']]
quan = long_data_train[['CreditScore','CreditScore','Tenure','Balance','Balance','EstimatedSalary']]
# sklearn中的OneHotEncoder是处理独热编码
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(categories='auto').fit(qual) # 实例化独热编码方法的对象
result = enc.transform(qual).toarray() # 独热处理后的结果
print('编码后的数据变量名:',enc.get_feature_names()) # 获取数据编码后的特征名
print(result)数据增加
X,y就是构建模型使用的数据。对构建模型的数据集进行划分,进行相关模型构建。
# 按照dataframe的形式拼接起来
result = pd.DataFrame(result,columns = ['Gender_0','Gender_1','HasCrCard_0','HasCrCard_1',
'IsActiveMember_0','IsActiveMember_1'])
X = pd.concat([quan,result],axis = 1) # 按照列,将特征编码后的定性数据与定量数据合并为特征集
y = long_data_train[['Exited']] # 获取标签数据
Xtrain, Xtest, Ytrain, Ytest = train_test_split(
X,y,test_size=0.3,random_state = 42) # 百分之七十的训练集,百分之三十的测试集
# 用随机森林先做初步的模型预测
model = RandomForestClassifier(random_state=42).fit(Xtrain,Ytrain)
y_pred = model.predict(Xtest)
print(classification_report(Ytest,y_pred))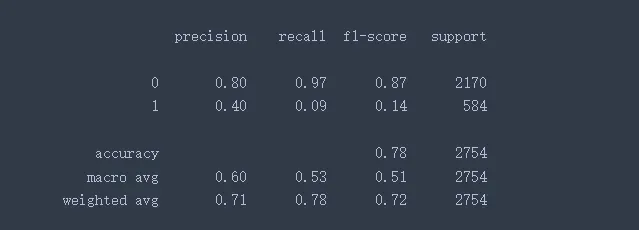
利用随机森林的默认参数进行训练,通过classification_report函数输出预测结果报告。从上图可知,第0类的预测f1值约为0.87,第1类的预测f1值约为0.14,准确率约为0.78,宏观avg值约为0.51,加权avg值约为0.72。
根据F1值可知,模型对于第1类的类别预测能力很弱,因为模型会倾向于考虑预测大类样本的数据,模型直接将第1类剔除,保底都能正确预测大多数的第0类的样本。但若考虑第0类样本的正确预测,可能导致部分第1类的预测失败,这个第0类预测失败的代价高于第1类预测成功的代价,所以可能就不考虑这种策略了。
本文选取SMOTEN、SMOTE、SVMSMOTE、ADASYN、BorderlineSMOTE五种过采样方法进行增加数据。
def increase_data(x,y,ways,delete_increase_data = True):
'''
x → 特征集,dataframe形式,因为下面有.values,否则会报错
y → 标签集,同理
ways → 实例好的填补数据方法
delete_increase_data → 是否对测试集中的填补数据进行删除,下文有对比分析
'''
# 数据采样实现,这个传入的x,y应该只能是series,dataframe是不可以的,列表不清楚
X_res, y_res = ways.fit_resample(x.values, y.values)
# 转换为dataframe 方便删除数据
X_res,y_res = pd.DataFrame(X_res),pd.DataFrame(y_res)
# 按照划分数据集,划分比例为7:3
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X_res,y_res,test_size=0.3,random_state = 42)
# 将测试集中填补的信息剔除
if delete_increase_data:
Xtest,Ytest = Xtest.reset_index(),Ytest.reset_index()
Xtest = Xtest[Xtest['index'] <= X.shape[0]].drop('index',axis = 1).values
Ytest = Ytest[Ytest['index'] <= X.shape[0]].drop('index',axis = 1).values
return Xtrain, Xtest, Ytrain, Ytest对采取的采样方法进行实例化,并用默认参数的随机森林进行训练,并可视化最终结果。
from imblearn.over_sampling import SMOTEN,SMOTE,SVMSMOTE,ADASYN,BorderlineSMOTE
smote = SMOTE(random_state = 42)
smoten = SMOTEN(random_state = 42)
svmsmo = SVMSMOTE(random_state = 42)
adasyn = ADASYN(random_state = 42)
bdsmo = BorderlineSMOTE(random_state = 42)
f1_0,f1_1 =[],[]
for i in [smote,smoten,svmsmo,adasyn,bdsmo]:
Xtrain, Xtest, Ytrain, Ytest = increase_data(X,y,i)
model = RandomForestClassifier(random_state = 42).fit(Xtrain,Ytrain)
y_pred = model.predict(Xtest)
# print('未流失客户的预测结果:',f1_score(Ytest,y_pred,average='binary',pos_label=0))
# print("已流失客户的预测结果:",f1_score(Ytest,y_pred,average='binary',pos_label=1))
# print(classification_report(Ytest,y_pred))
f1_1.append(f1_score(Ytest,y_pred,average='binary',pos_label=1))
f1_0.append(f1_score(Ytest,y_pred,average='binary',pos_label=0))
其中f1_score的average有多个参数,一般默认的为二分类——“binary”,除此之外还有macro,micro,weighted,samples分别是宏观avg、微观avg、加权avg、平均avg。从名字上,weighted和samples应该一致,但后者仅对多分类起效果。详情看,f1_score的官网
pos_label参数是指定输出哪一类的结果,默认是输出第1类的结果。对于多分类或者不平衡数据需要关注某一类的输出结果时,可以指定使用。
c = (
Bar(init_opts=opts.InitOpts(bg_color= '#fff'))
.add_xaxis(['SMOTE','SMOTEN','SVMSMOTE','ADASYN','BorderlineSMOTE'])
.add_yaxis("0", [round(i,4) for i in f1_0])
.add_yaxis("1", [round(i,4) for i in f1_1])
.set_global_opts(title_opts=opts.TitleOpts(title="", subtitle=""))
.set_colors(['crimson','teal'])
)
c.render_notebook()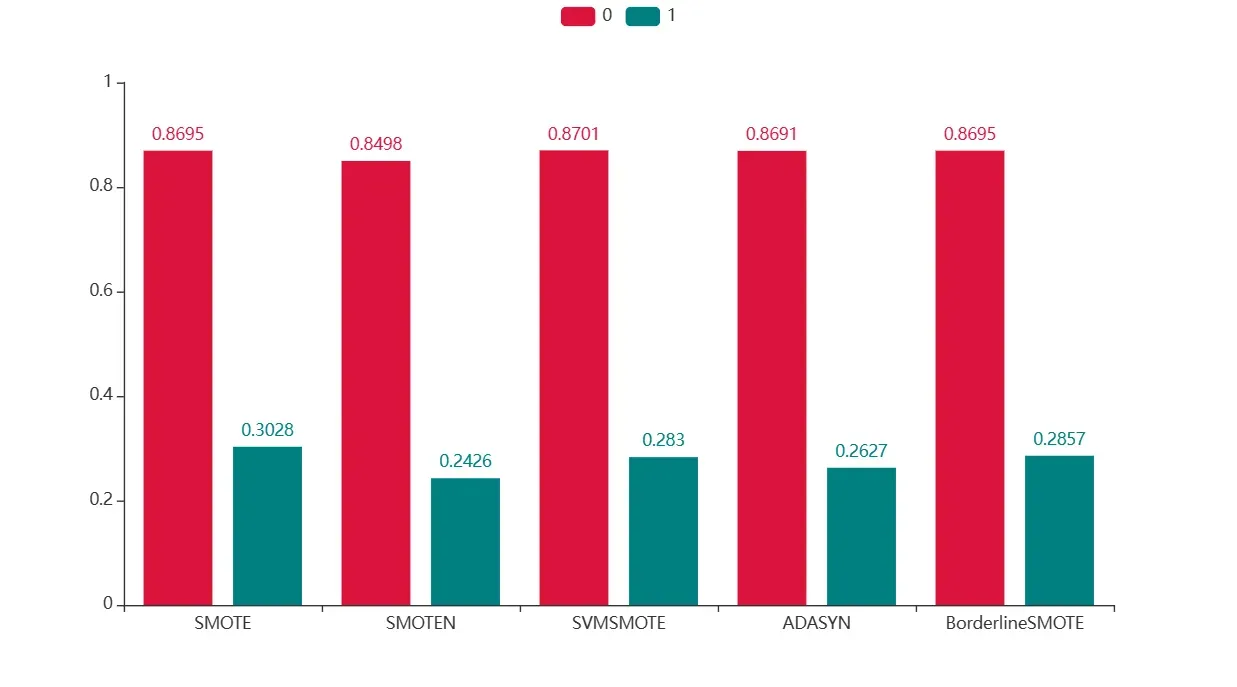
其中,对于大类样本的预测结果最好的是SVMSMOTE采样方法,小类样本预测结果最好的是SMOTE采样方法,且两种方法大类样本预测结果的差异并不是太大,所以考虑SMOTE方法进行采样,以此作为训练数据进行模型训练。
对于模型选择常用的树模型进行训练,这里仅列出三个模型分为随机森林,XGBOOST和极限提升树。
下面是经过简单调参后的模型代码
from sklearn.ensemble import ExtraTreesClassifier,RandomForestClassifier
from xgboost import XGBClassifier
rfc = RandomForestClassifier(n_estimators=100,
max_depth = 1,
min_samples_leaf = 1,
min_samples_split = 2,
random_state=42).fit(Xtrain,Ytrain)
xgb=XGBClassifier(n_estimators = 470,
max_depth = 40,
learning_rate = 0.56,
min_child_weight = 1,
random_state = 42).fit(Xtrain,Ytrain,eval_metric = 'auc')
etc=ExtraTreesClassifier(n_estimators = 460,
max_depth = 1,
min_samples_leaf = 1,
min_samples_split = 2,
random_state = 42).fit(Xtrain,Ytrain)
c = (
Bar(init_opts=opts.InitOpts(bg_color= '#fff'))
.add_xaxis(['RandomForestClassifier','XGBClassifier','ExtraTreesClassifier'])
.add_yaxis("0", [0.71,0.85,0.74])
.add_yaxis("1", [0.36,0.32,0.39])
.set_global_opts(title_opts=opts.TitleOpts(title="", subtitle=""))
.set_colors(['crimson','teal'])
)
c.render_notebook()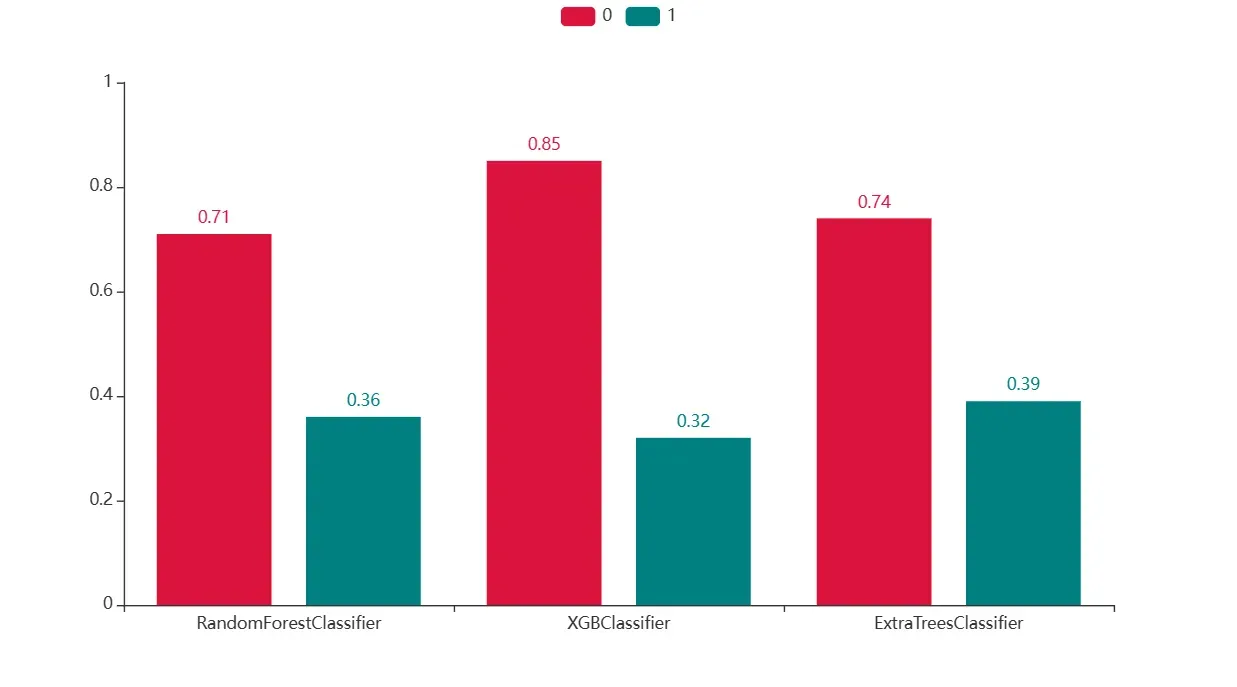
从上图可知,大类样本预测能力还是XGBOOST的好,小类样本预测能力是极限提升树的效果好。但结果的大小还是太低,提升并不是太大。
回到前面定义的增加数据函数中,其中包含了一个默认输入参数,这个参数是控制是否删除测试数据中的插补数据。如何保证你插补的数据满足这个数据的分布,或者说能否具有原始数据的真实意义,这是插补完数据需要考虑的。
将增加数据函数的默认参数改为False,即不删除增加的填补数据,得到如下结果:
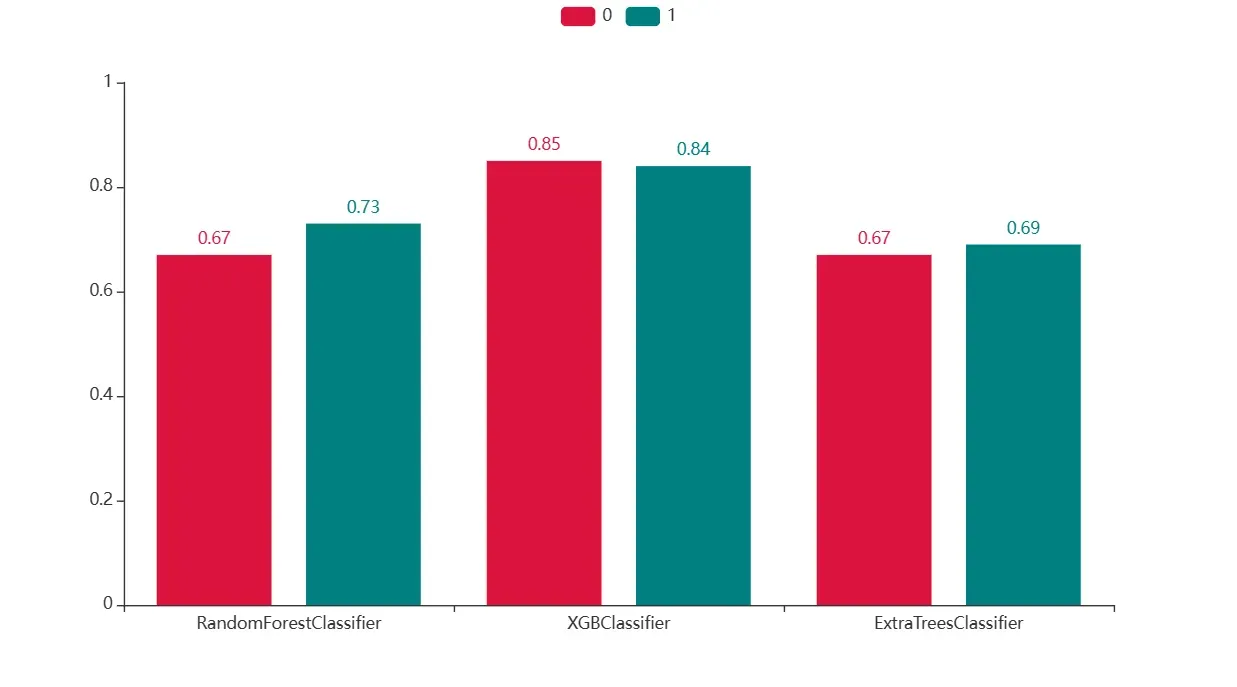
对于第1类的数据的预测结果大幅提升,同时XGBOOST在不减低第0类的预测能力,能够使得第1类的预测能力大幅提升,说明XGBOOST的预测能力比较好。其他两种模型,在预测第1类数据的过程中,减低了预测第0类的数据,模型效果较差。
从预测结果分析,加入了插补数据进行预测后,模型的预测能力呈现得更好,说明其中预测较多的数据为插补数据,但问题是插补数据并不一定是客观的数据,所以单纯看含有填补数据的测试结果可能是有误的。
算法改进
imbalance_learn库中提供了四种不平衡样本数据处理模型,分别为EasyEnsemble、RUSBoost、BalancedRandomForest、BalancedBagging。下面,通过四种模型的默认参数进行数据训练,不考虑填补数据。
from imblearn.ensemble import EasyEnsembleClassifier,RUSBoostClassifier
from imblearn.ensemble import BalancedRandomForestClassifier,BalancedBaggingClassifier
Xtrain, Xtest, Ytrain, Ytest = increase_data(X,y,smote,delete_increase_data=True)
eec = EasyEnsembleClassifier(random_state = 42).fit(Xtrain,Ytrain)
y_pred = eec.predict(Xtest)
print("eec的预测结果:",classification_report(Ytest,y_pred))
print("_______________________________")
rbc = RUSBoostClassifier(random_state = 42).fit(Xtrain,Ytrain)
y_pred = rbc.predict(Xtest)
print("eec的预测结果:",classification_report(Ytest,y_pred))
print("_______________________________")
bbfc = BalancedRandomForestClassifier(random_state = 42).fit(Xtrain,Ytrain)
y_pred = bbfc.predict(Xtest)
print("eec的预测结果:",classification_report(Ytest,y_pred))
print("_______________________________")
bbc = BalancedBaggingClassifier(random_state = 42).fit(Xtrain,Ytrain)
y_pred = bbc.predict(Xtest)
print("eec的预测结果:",classification_report(Ytest,y_pred))
print("_______________________________")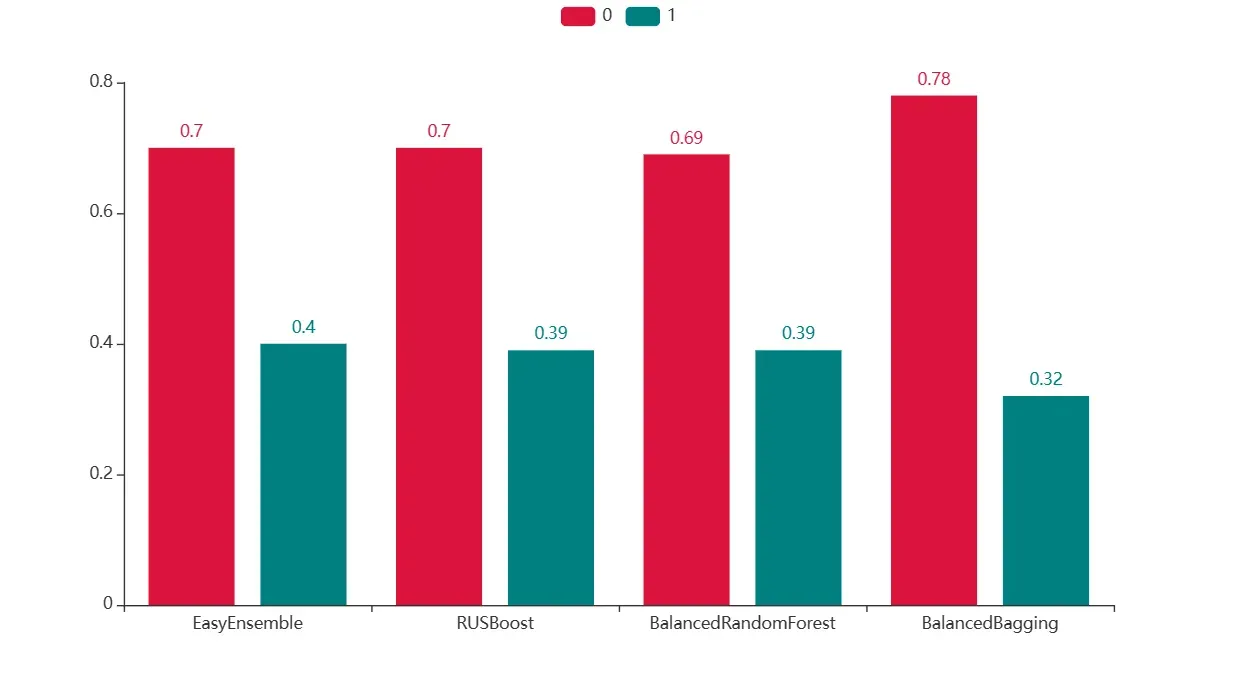
从上图可知,EasyEnsemble的第0类的预测能力一般,但第1类样本的预测能力比较好,其他模型也都对数据的预测有一定的改善作用。由于不平衡数据中存在基础模型的选择,所以默认参数最好的模型改变基础模型后不一定最好,反之,默认参数最差的模型改变基础模型后不一定最差。
针对每一个模型进行比较简单的调参后,得到如下参数结果并可视化参数结果对应的模型效果。(这里的数据都没有进行特征编码的数据,不知道为啥不特征编码的效果比特征编码的效果好)
model = EasyEnsembleClassifier(n_estimators=140,
base_estimator=GradientBoostingClassifier(),
sampling_strategy=0.6,n_jobs=6,random_state=0).fit(Xtrain,Ytrain)
y_pred = model.predict(Xtest)
print(classification_report(Ytest,y_pred))
print('——————————————————————————————')
model = EasyEnsembleClassifier(n_estimators=38,
base_estimator=RandomForestClassifier(),
sampling_strategy=0.59,n_jobs=6,random_state=0).fit(Xtrain,Ytrain)
y_pred = model.predict(Xtest)
print(classification_report(Ytest,y_pred))
print('——————————————————————————————')
model = GradientBoostingClassifier(n_estimators=170,
learning_rate=0.54,max_depth=170,random_state=0
).fit(Xtrain,Ytrain)
y_pred = model.predict(Xtest)
y_pred = model.predict(Xtest)
print(classification_report(Ytest,y_pred))
print('——————————————————————————————')
model = BalancedBaggingClassifier(n_estimators=90,bootstrap=True,
sampling_strategy=0.9,n_jobs=6,random_state=0
).fit(Xtrain,Ytrain)
y_pred = model.predict(Xtest)
y_pred = model.predict(Xtest)
print(classification_report(Ytest,y_pred))from pyecharts.charts import Bar
from pyecharts import options as opts
c = (
Bar(init_opts=opts.InitOpts(bg_color= '#fff'))
.add_xaxis(['EasyEnsemble—提升树','RUSBoost—随机森林','GradientBoosting','BalancedBagging'])
.add_yaxis("0", [0.89,0.89,0.86,0.88])
.add_yaxis("1", [0.62,0.60,0.47,0.59])
.set_global_opts(title_opts=opts.TitleOpts(title="", subtitle=""))
.set_colors(['crimson','teal'])
)
c.render_notebook()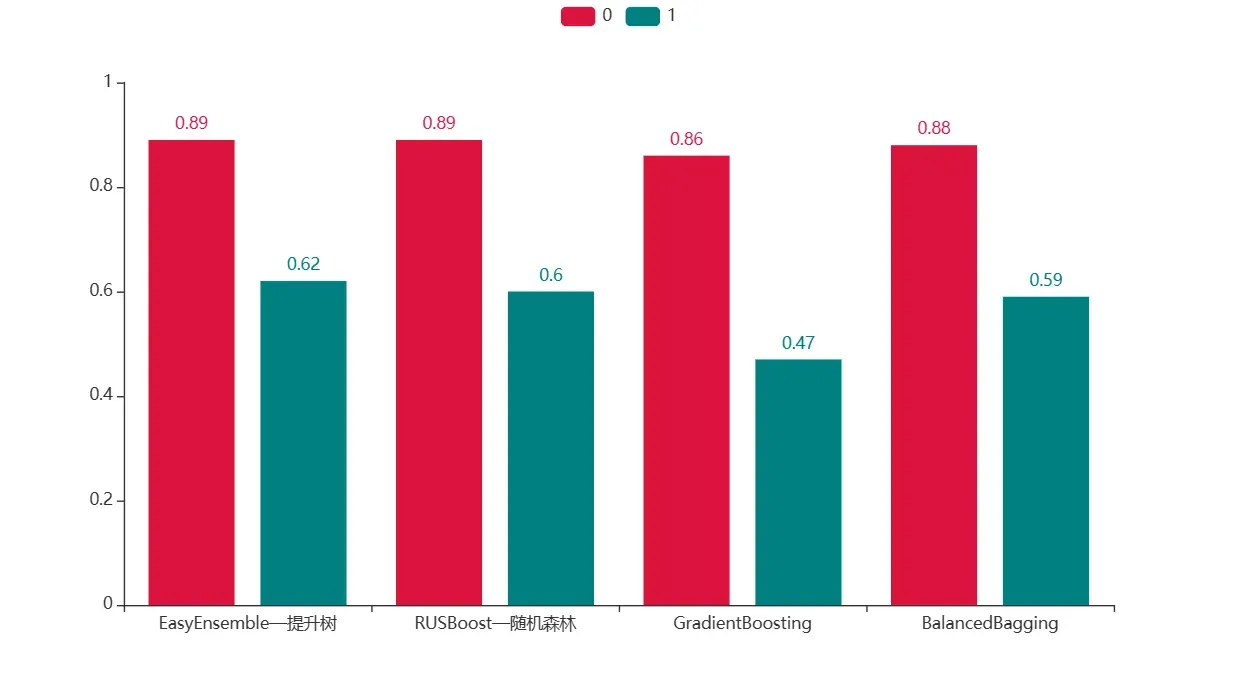
从简单调参后的结果可知,基于提升树的EasyEnsemble模型对第1类的预测能力是最好的,且不影响第0类模型的预测,其他模型也有类似的效果。这里调整的参数不包括基模型中的参数,所以可以选择训练较好的基模型加入其中,再次调整数据不平衡模型,可能得到更好的结果。相对于增加数据的方法,改进模型的方法虽然没有使得模型有很好的预测能力,但也具有较好的预测能力。同时,因为不引入其他数据的影响,对于结果的说明也更加的科学。
参考文献
SMOTE过采样及其改进算法研究综述_石洪波
Exploratory Undersampling for Class-Imbalance Learning—Xu-Ying Liu, Jianxin Wu, and Zhi-Hua Zhou, Senior Member, IEEE
文章出处登录后可见!