在学习某一神经网络框架时,数据流总是能帮助大家更好地理解整个模型的运行逻辑/顺序,而其中Dataloader的作用在某些时候更是至关重要的。
笔者将自己的学习到的关于dataloader的创建,作用尽可能详细地记录下来以方便日后回顾,也欢迎各位匹配指正。
一句话概括
Dataloader本质是一个迭代器对象,也就是可以通过
for batch_idx,batch_dict in dataloader 来提取数据集,提取的数量由batch_size 参数决定,得到这一batch的数据后,就可以喂入网络开始训练或者推理了。
在迭代的过程中,dataloader会自动调用dataset中的__getitem__ 函数,以获取一帧数据(item)
dataloader的初始化
以openpcdet框架下的dataloader初始化为例:
#in pcdet/datasets/__init__.py
dataloader = DataLoader(
dataset,
batch_size=batch_size,
pin_memory=True,
num_workers=workers,
shuffle=(sampler is None) and training,
collate_fn=dataset.collate_batch, #将一个list的sample组成一个mini-batch的函数
drop_last=False, sampler=sampler, timeout=0
)
下面结合pytorch官方文档来详细解释每个参数的意义
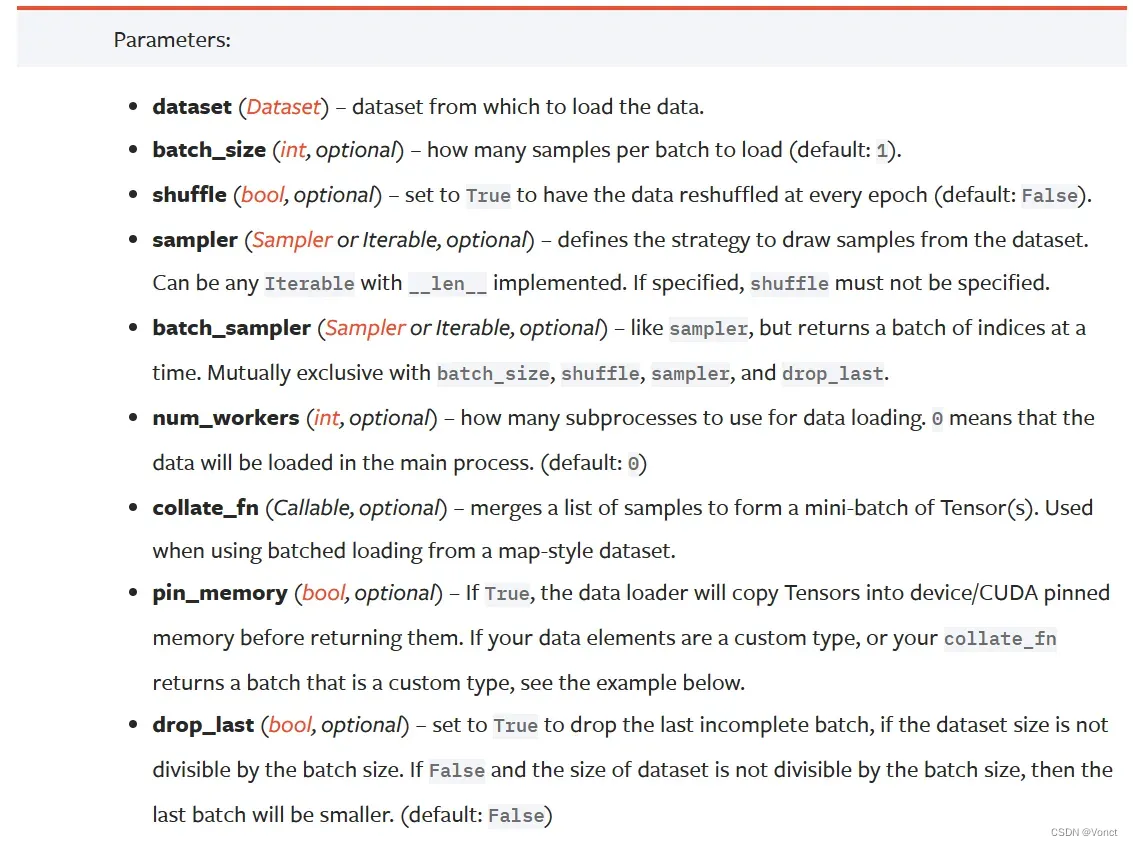 1. dataset (Dataset) – dataset from which to load the data.
1. dataset (Dataset) – dataset from which to load the data.
即自定义的数据集,非常重要,因为dataloader会调用dataset的一些重载函数(e.g. __getitem__ && __len__ )
2. batch_size (int, optional) – how many samples per batch to load(default: 1).
-
pin_memory(bool, optional) – If
True, the data loader will copy Tensors into device/CUDA pinned memory before returning them. If your data elementsare a custom type, or yourcollate_fnreturns a batch that is a custom type,see the example below.当设置为True时,将会在返回**
batch之前将batch**数据复制到固定的内存区域,这样在GPU训练过程中,数据从内存到GPU的复制可以使用异步的方式进行,从而提高数据读取的效率。通常情况下,当使用GPU训练模型时,数据读取会成为整个训练过程的瓶颈之一。使用**
pin_memory**可以将数据在CPU和GPU之间进行传输时的复制时间减少,从而提高数据加载的速度,加速训练过程。需要注意的是,使用**
pin_memory会占用更多的内存空间,因此在内存资源紧张的情况下,需要谨慎使用。同时,在某些情况下(例如数据集比较小的情况下),使用pin_memory**并不会带来明显的加速效果。 -
num_workers (int, optional) – how many subprocesses to use for dataloading.
0means that the data will be loaded in the main process.(default:0)这也是一个很有意思的参数,按照官方的说法,
num_workers用于设置数据加载过程中使用的子进程数。其默认值为**0**,即在主进程中进行数据加载,而不使用额外的子进程。
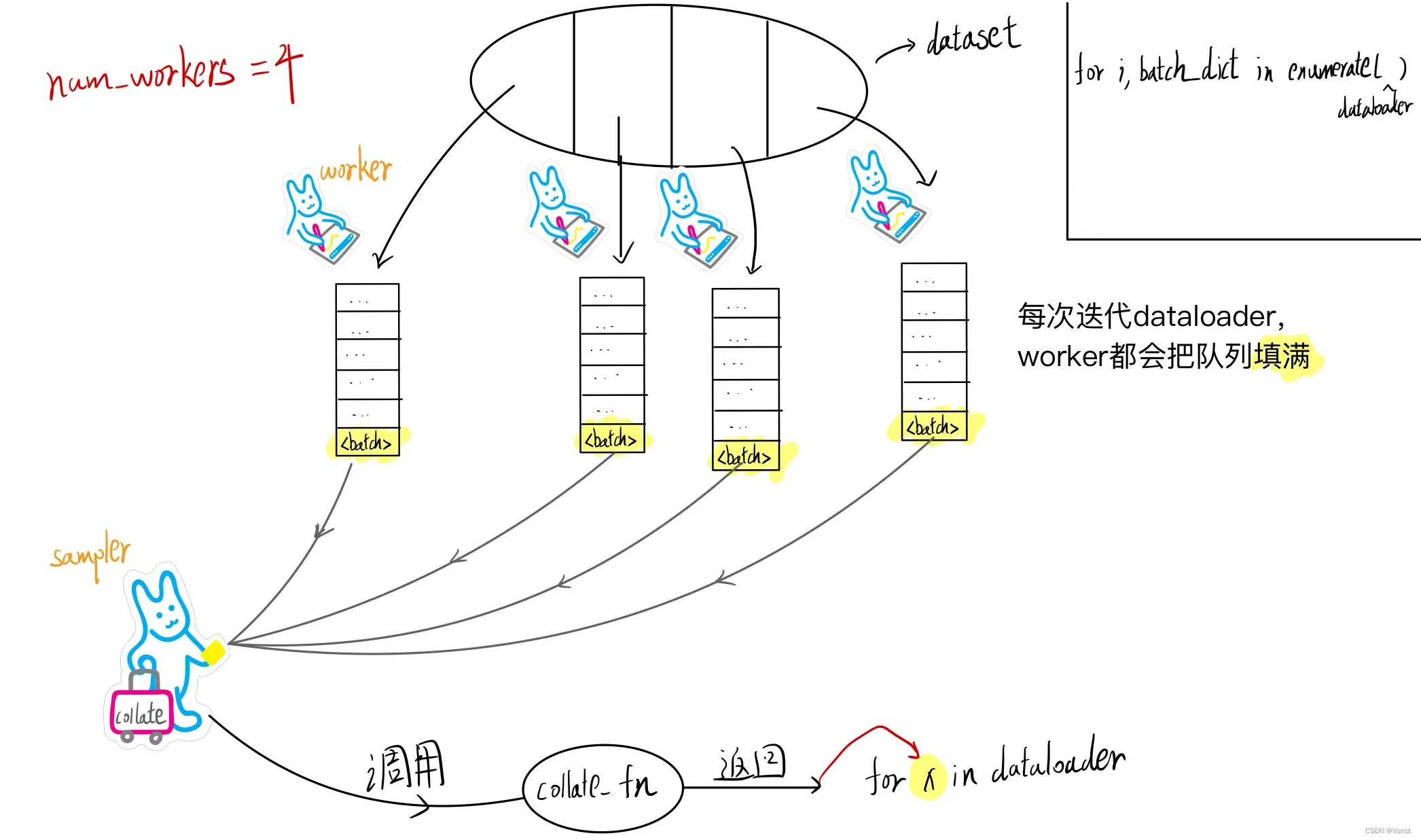
下面说一下个人的理解,在初始化dataloader对象时,会根据num_workers创建子线程用于加载数据(主线程数+子线程数=num_workers)。每个worker或者说线程都有自己负责的dataset范围(下面统称worker)
每当迭代dataloader对象时,工人们(workers)就开始干活了:将数据从数据源(如硬盘)加载到内存(数据加载),当一个worker读取(调用__getitem__)到足够的数据(看你在dataset中怎么定义一个item了)后,会将这些数据封装成一个 (即一帧),并将其放到该worker独有的内存队列中。
要注意的是,每次迭代时,worker会尽可能地读数据,直到自己的队列被填满。
当所有workers的队列都被填满时,一个名为sampler的线程将会被创建,它的作用就是收集各workers队列中队首的 ,把他们放到一个各线程共享内存的缓冲队列中,并调用collate_fn函数来将batch_size个 整合,最后返回给迭代的输出。
这时候大家肯定会有点疑惑,那当迭代到后期时,需要读取的样本都已经在队列中了,是不是意味着这时候工人们已经在休息了?根据chatgpt的回答:是的!下面以一张图来帮助大家理解
-
collate_fn (Callable, optional) – merges a list of samples to form a mini-batch of Tensor(s). Used when using batched loading from a map-style dataset.
整合多个样本到一个batch时需要调用的函数,当__getitem__返回的不是tensor而是字典之类时,需要进行collate_fn的重载,同时可以进行数据的进一步处理以满足pytorch的输入要求
比如在openpcdet框架的poinpillar中,__getitem__返回的是一个包含标注信息、点云信息、图像信息等的data_dict字典,这时候就需要调用自定义的collate_fn来进行打包
在poinpillar中该函数为:
@staticmethod
def collate_batch(batch_list, _unused=False):
"""
由于训练集中不同的点云的gt框个数不同,需要重写collate_batch函数,
将不同item的boxes和labels等key放入list,返回batch_size的数据
"""
# defaultdict创建一个带有默认返回值的字典,当key不存在时,返回默认值,list默认返回一个空
data_dict = defaultdict(list)
# 把batch里面的每个sample按照key-value合并
for cur_sample in batch_list:
for key, val in cur_sample.items():
data_dict[key].append(val)
batch_size = len(batch_list)
ret = {}
# 将合并后的key内的value进行拼接,先获取最大值,构造空矩阵,不足的部分补0
# 因为pytorch要求输入数据维度一致
for key, val in data_dict.items():
try:
# voxels: optional (num_voxels, max_points_per_voxel, 3 + C)
# voxel_coords: optional (num_voxels, 3)
# voxel_num_points: optional (num_voxels)
if key in ['voxels', 'voxel_num_points']:
ret[key] = np.concatenate(val, axis=0)
elif key in ['points', 'voxel_coords']:
coors = []
for i, coor in enumerate(val):
#在每个坐标前面加上序号 e.g. shape (N, 4) -> (N, 5) [20, 30, 40, 0.4] -> [i, 20, 30, 40, 0.4]
# 在scatter起到作用,因为这时候(生成伪图像)就是分batch操作了,需要根据batch_idx 即 下面函数的
# constant_values 来区分voxel属于哪一帧
coor_pad = np.pad(coor, ((0, 0), (1, 0)), mode='constant', constant_values=i)
"""
((0,0),(1,0))
在二维数组array第一维(此处便是行)前面填充0行,最后面填充0行;
在二维数组array第二维(此处便是列)前面填充1列,最后面填充0列
mode='constant'表示指定填充的参数
constant_values=i 表示第一维填充i
"""
coors.append(coor_pad)
ret[key] = np.concatenate(coors, axis=0) # (B, N, 5) -> (B*N, 5)
elif key in ['gt_boxes']:
# 获取一个batch中所有帧中3D box最大的数量
max_gt = max([len(x) for x in val])
# 构造空的box3d矩阵(B, N, 7)
batch_gt_boxes3d = np.zeros((batch_size, max_gt, val[0].shape[-1]), dtype=np.float32)
for k in range(batch_size):
batch_gt_boxes3d[k, :val[k].__len__(), :] = val[k]
ret[key] = batch_gt_boxes3d
# gt_boxes2d同gt_boxes
elif key in ['gt_boxes2d']:
max_boxes = 0
max_boxes = max([len(x) for x in val])
batch_boxes2d = np.zeros((batch_size, max_boxes, val[0].shape[-1]), dtype=np.float32)
for k in range(batch_size):
if val[k].size > 0:
batch_boxes2d[k, :val[k].__len__(), :] = val[k]
ret[key] = batch_boxes2d
elif key in ["images", "depth_maps"]:
# Get largest image size (H, W)
max_h = 0
max_w = 0
for image in val:
max_h = max(max_h, image.shape[0])
max_w = max(max_w, image.shape[1])
# Change size of images
images = []
for image in val:
pad_h = common_utils.get_pad_params(desired_size=max_h, cur_size=image.shape[0])
pad_w = common_utils.get_pad_params(desired_size=max_w, cur_size=image.shape[1])
pad_width = (pad_h, pad_w)
# Pad with nan, to be replaced later in the pipeline.
pad_value = np.nan
if key == "images":
pad_width = (pad_h, pad_w, (0, 0))
elif key == "depth_maps":
pad_width = (pad_h, pad_w)
image_pad = np.pad(image,
pad_width=pad_width,
mode='constant',
constant_values=pad_value)
images.append(image_pad)
ret[key] = np.stack(images, axis=0)
else:
ret[key] = np.stack(val, axis=0)
except:
print('Error in collate_batch: key=%s' % key)
raise TypeError
ret['batch_size'] = batch_size
return ret
-
sampler (Sampler or Iterable, optional) – defines the strategy to draw samples from the dataset. Can be any
Iterablewith__len__implemented. If specified,shufflemust not be specified.sampler的主要作用是控制样本的采样顺序,并提供样本的索引。在默认情况下,dataloader使用的是SequentialSampler,它按照数据集的顺序依次提取样本,但在某些情况下,我们可能需要自定义采样顺序。比如说想从队尾提取数据。
比如,当我们处理非常大的数据集时,为了提高训练效率,可能需要对数据进行分布式采样,这时候就需要使用DistributedSampler。DistributedSampler会将数据集划分成多个子集,每个子集分配给不同的进程进行采样。在这种情况下,如果使用默认的SequentialSampler,可能会导致各个进程采样到相同的数据,从而降低训练效率。
此外,还有一些自定义的sampler,比如随机采样器(RandomSampler)和加权采样器(WeightedRandomSampler),它们可以按照不同的采样策略对数据集进行采样,从而满足不同的训练需求。
因此,根据不同的训练需求,我们可能需要自定义sampler来控制数据的采样顺序。 -
待续
文章出处登录后可见!