首先听一下作者的AI懒羊羊翻唱效果,如果觉得可以,再继续往下看
【AI懒羊羊】翻唱 冬眠 core 司南
序
最近一段时间,AI懒羊羊的翻唱歌曲的视频再各个平台有广泛的热度。很多人都喜欢这个可爱的形象和它那萌化人心的声音。那么,这个AI声音模型是如何训练出来的呢?接下来,我将为您详细解答。
简单拆解成四步: 1,声音提取 2, 模型训练 3, 歌曲推理 4,歌曲合成
一、声音提取
声音提取是整个环节最重要的,提取声音的方法有很多,包括手动提取和自动提取。手动提取需要使用音频编辑软件,通过手动选择需要提取的音频片段,然后导出为独立的音频文件。这种方法比较简单,但是比较费时费力,适合处理少量音频。自动提取可以使用基于信号处理的方法,例如短时傅里叶变换、小波变换等,将音频信号分解为不同的频段,然后提取特征或进行分类。
首先,为了训练AI懒羊羊的声音模型,我们需要收集大量的懒羊羊的声音样本。这些样本应该包括懒羊羊在不同情况下的语音,例如开心、生气、困惑等等。我们可以从动画、视频或者录音中获取这些声音样本。这一步必不可少也是最重要的一步。
接下来,我们需要使用深度学习框架,RVC模型技术是基于深度学习的语音处理技术,其核心原理是将输入的源声音与目标声音进行对齐和映射,从而实现将源声音转化为目标声音的效果。具体而言,RVC技术分为两个阶段:训练阶段和推理阶段。在训练阶段,RVC技术需要收集大量的源声音和目标声音数据作为训练样本,这些样本需要包含源声音和目标声音的对应关系。然后,将源声音和目标声音进行特征提取,通常使用的是基于Mel频谱的声音特征。接下来,利用深度神经网络模型,如WaveNet或Tacotron2,进行训练,训练的目标是使得模型能够准确地将源声音映射到目标声音。在推理阶段,RVC技术使用训练好的模型对新的源声音进行转换,将其转化为目标声音。整体原理是通过将源声音与目标声音进行对齐和映射,从而实现变声。调整模型的参数,以便更好地模拟懒羊羊的声音。
提取方式
此外我这里还有个 奇技淫巧 方式,
1,在视频平台搜索 懒羊羊声音合集,懒羊羊声音语录 这样的搜索方式。
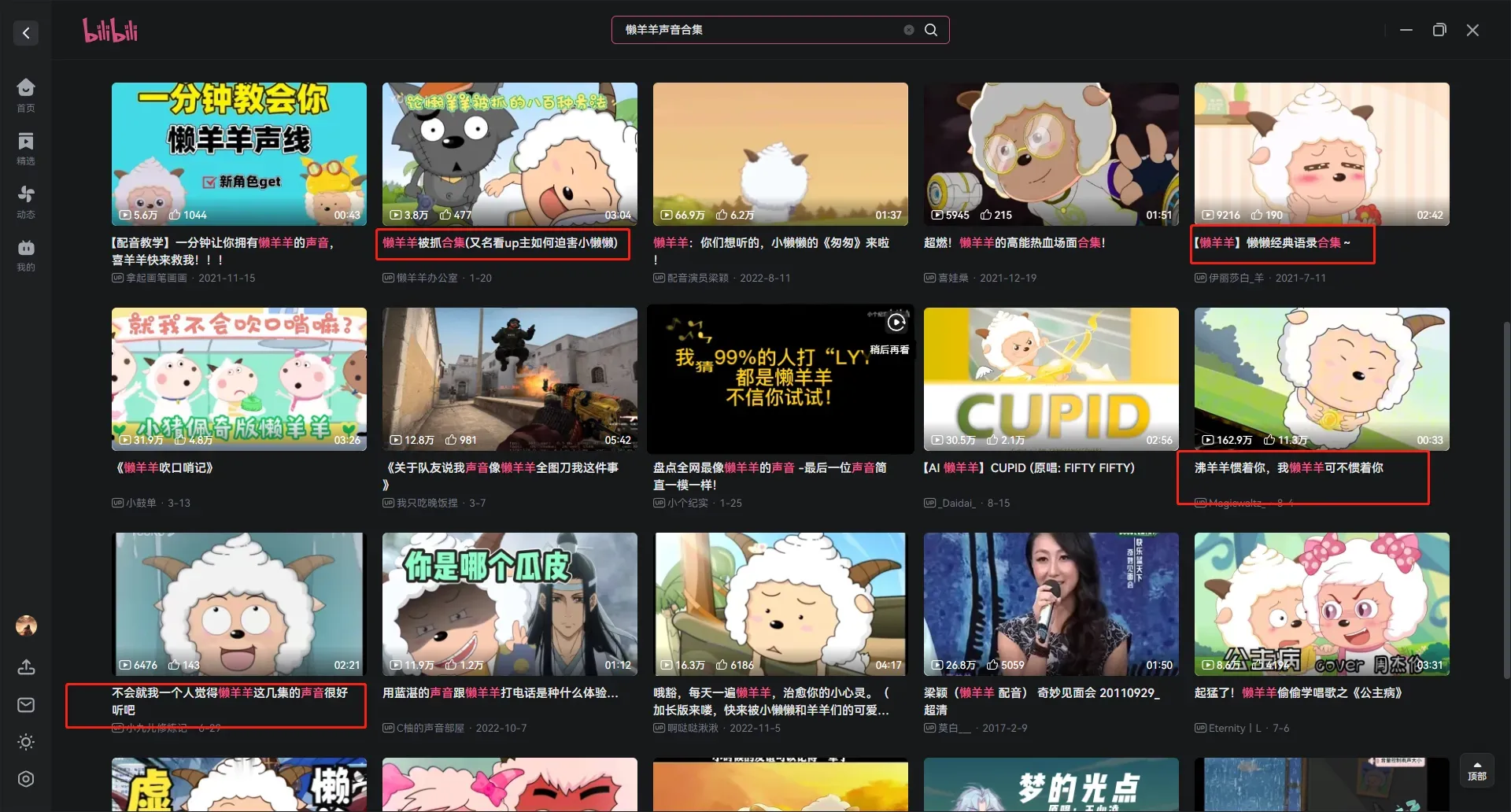
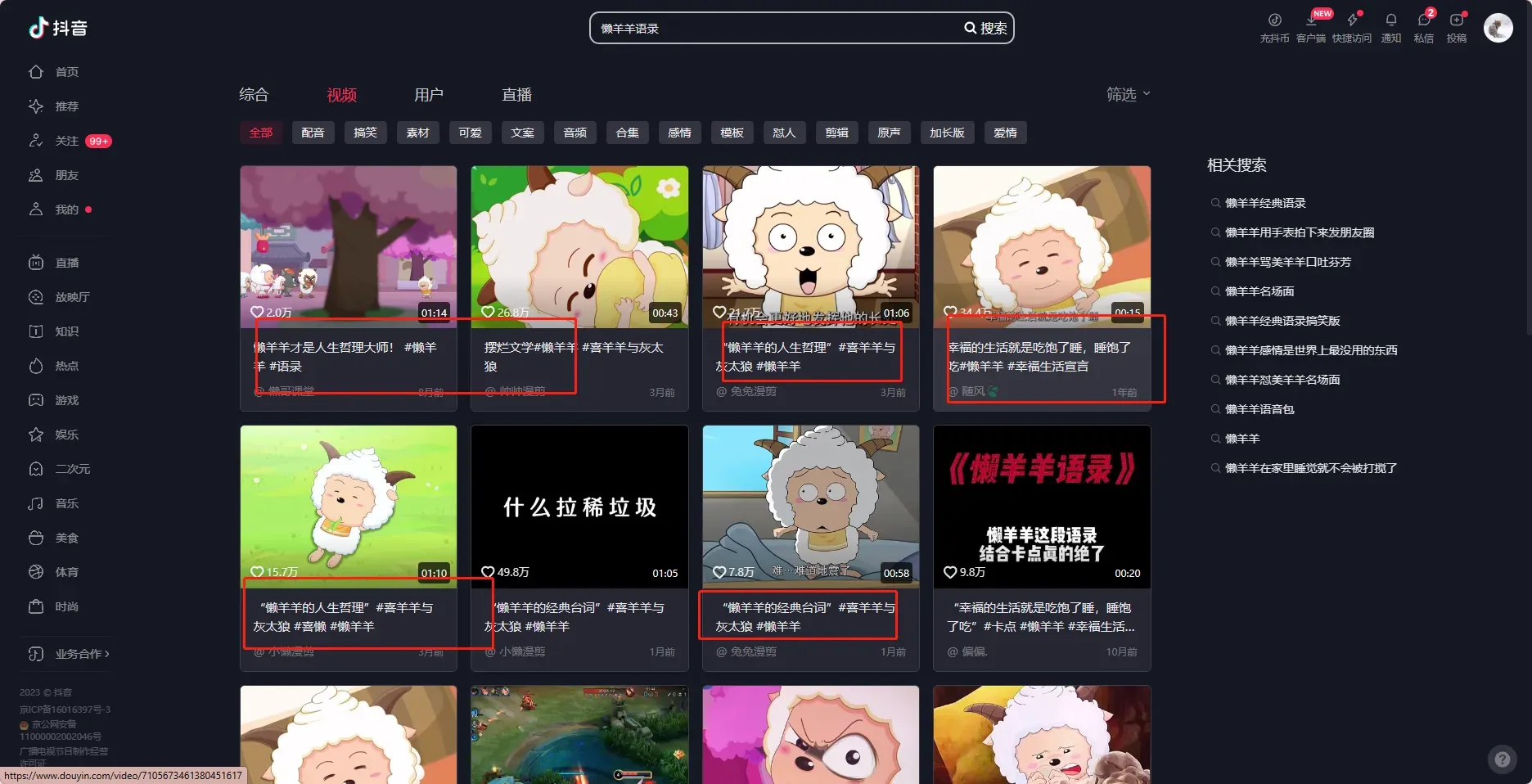
2,找懒羊羊的声优配音员,找到相符合的声音,进行提取
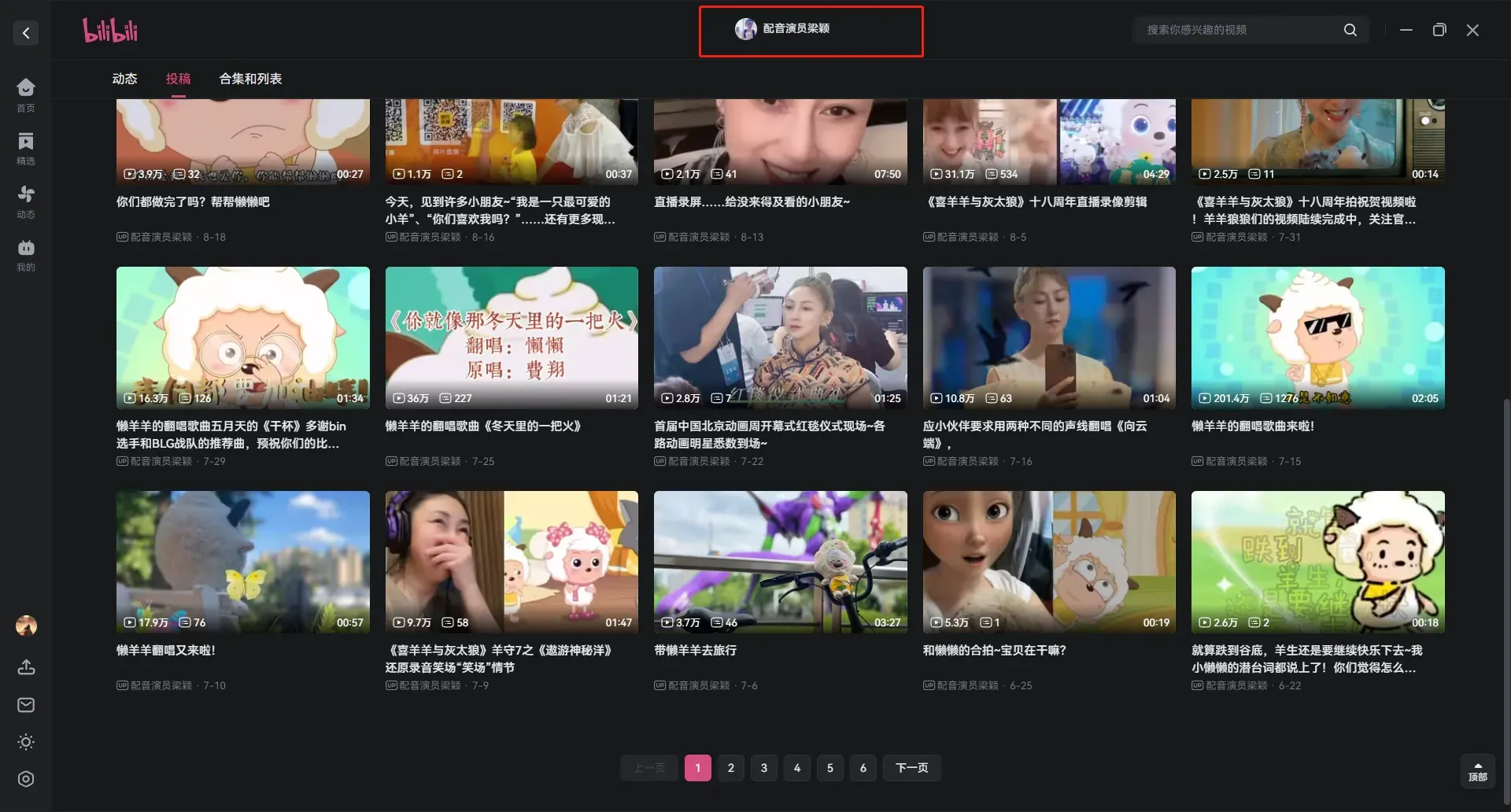
将提取之后的视频进行转换,转换成音频格式,如果是mp4则可以改后缀mp3。其他格式也需要转成声音格式。
转成声音格式之后推荐再用UVR5进一步声音提纯处理,整理成音频素材集之后,就可以进行下一步操作了。
常用工具下载
B站视频下载工具 百度网盘 请输入提取码
视频转码工具 百度网盘 请输入提取码
UVR5.5 百度网盘 请输入提取码
UVR 使用方式 UVR5.5音频分离工具使用教程 – 模型工坊-模型工坊 (mxgf.cc)
在线下载
抖音无水印工具_最新抖音在线无水印解析_抖音图文无水印下载_TikTok Downloader no watermark_ouo工具 (ouotool.com)
二、模型训练
RVC介绍
Retrieval-based-Voice-Conversion-WebUI 简称 RVC
一个基于VITS的简单易用的语音转换(变声器)框架
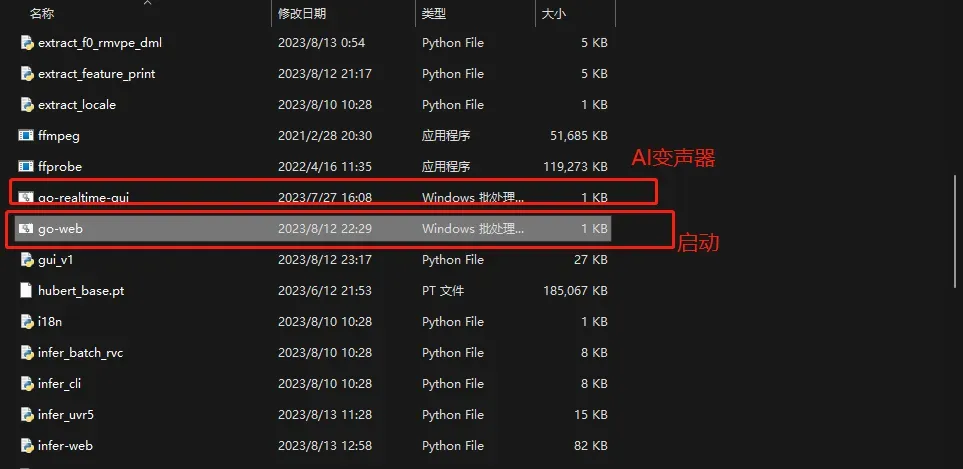
将整合包下载并解压,启动go-web.bat 等待运行
RVC0813 整合包下载(整合包 包含 运行环境 启动器)
版本说明
下载RVC0813AMD_Intel包可解锁A卡I卡
(1)双击go-realtime-gui-dml.bat使用实时变声,A卡大概能压到300ms左右,以下有压力
(2)双击go-web-dml.bat使用训练推理(CPU训练)
N卡用户下载RVC0813Nvidia
(1)双击go-realtime-gui.bat使用实时变声,N卡大概能压到100ms左右,以下有压力
(2)双击go-web.bat使用训练推理
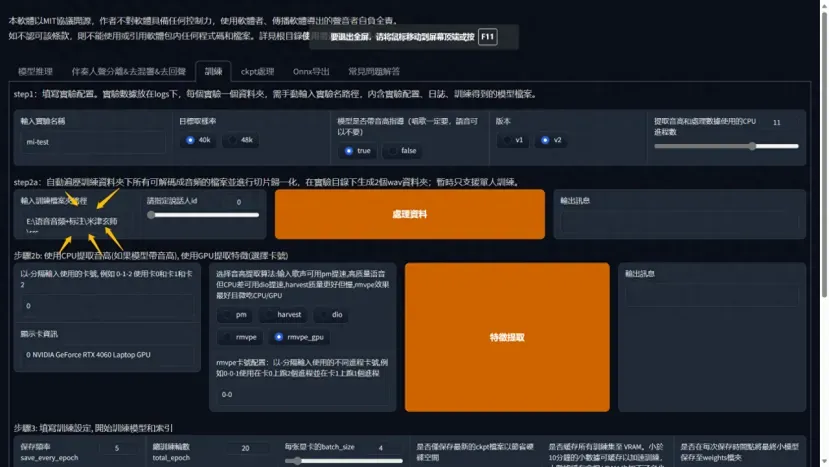
进入训练界面,默认的参数默认就行,不用动
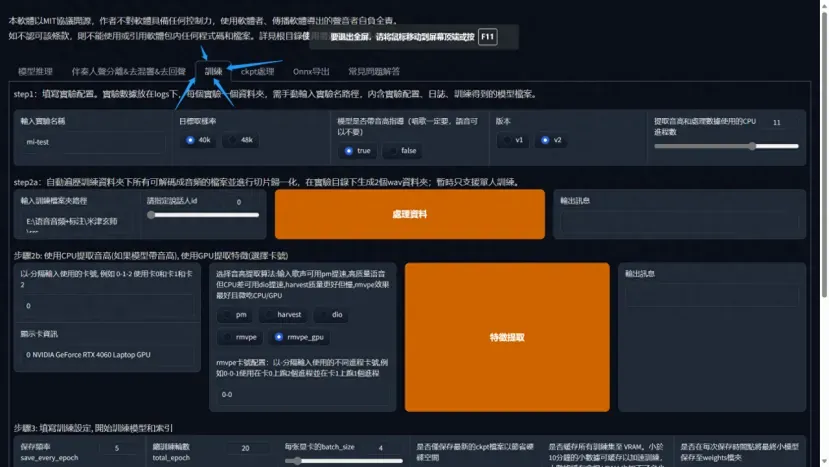
3,输入音频文件夹路径,处理数据
将要训练的的干声数据集放到本地任意英文路径文件夹内复,点击处理数据
处理数据
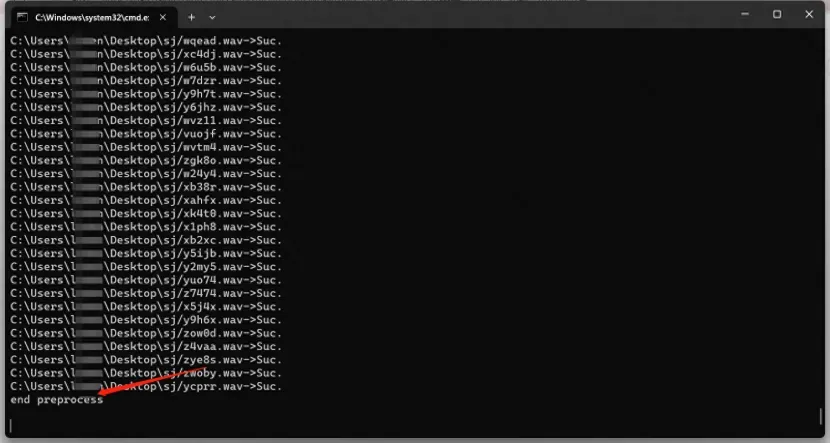
出现 end preprocess 表示处理完毕
特征提取
(特征提取是从声音信号中提取有用信息的过程,这些信息可以被用于训练模型进行分类或识别)
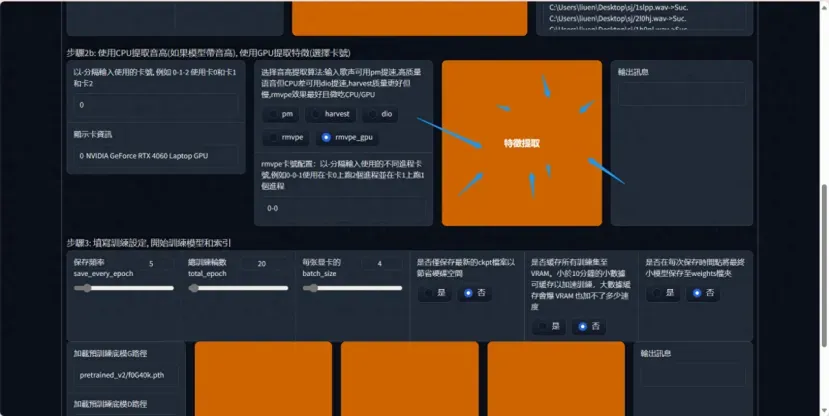
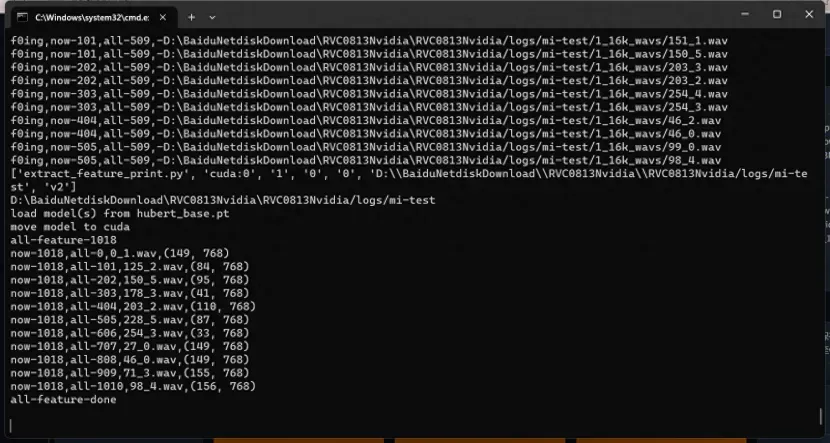
出现 all-feature-done 表示已经处理完毕,可以进行最后一步处理了
开始训练,设置训练的步数和保存频率
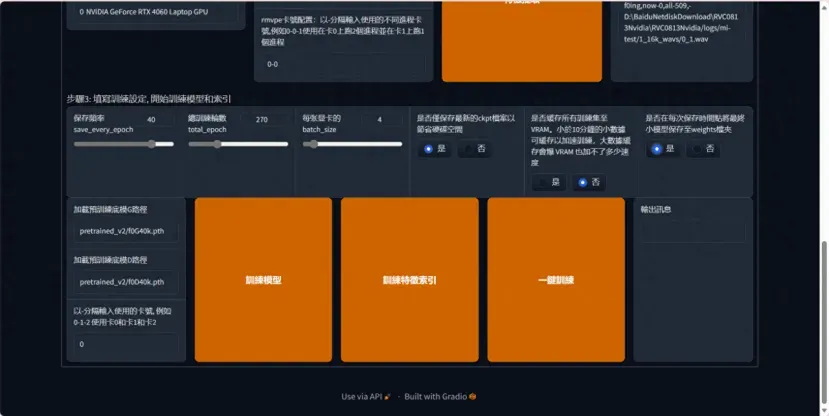
保存頻率 这个数值表示多少轮保存一次模型,如果你的电脑很牛很稳定 50轮也是可以的,不然就推荐 20-40轮保存一次模型
總訓練輪數一般 300轮,模型就可以出炉了
每张显卡的batch_size 如果你的显存是8则填8,显存多少,填多少数值。
点击一键训练

终端显示Epoch: 1字符,表示第一轮,正在训练了
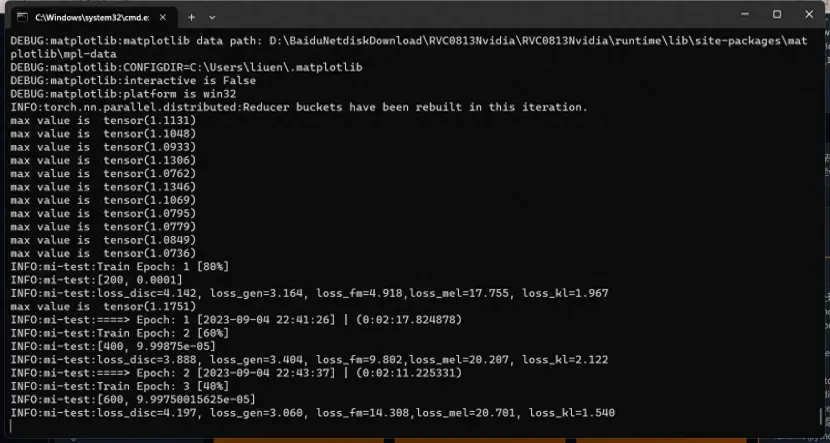
等待几个小时后,就训练结束了,就可以进行下一步,对声音模型进行推理试音了。
三、 歌曲分离/推理
1,歌曲分离
1,准备好歌曲文件,格式包括AAC,FLAC等主流声音格式,但不包括加密格式,比如网易云加密歌曲,酷狗,qq音乐。
2,将歌曲文件放到UVR 5,进行分离,分离的目的是 把伴奏和人声抽离出来
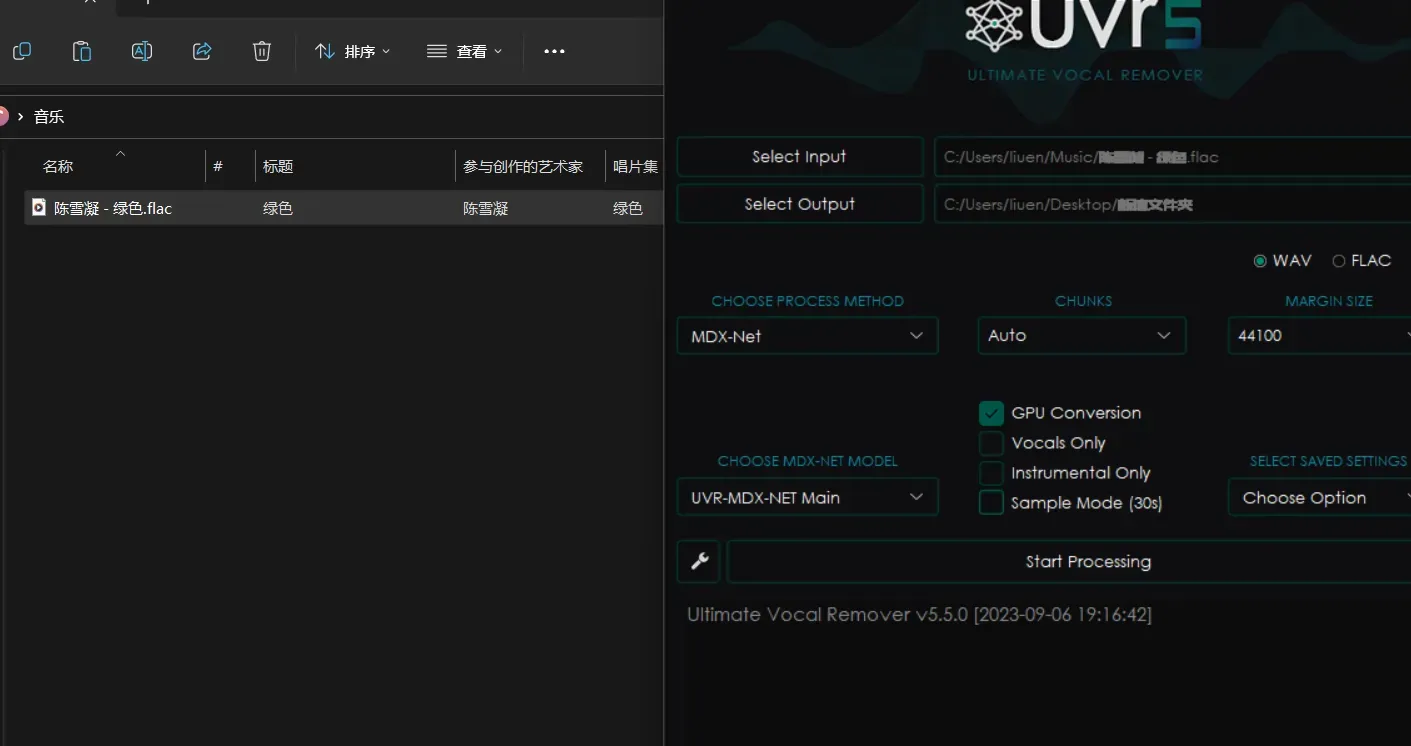
处理完成之后会得到两个音频文件
1_陈雪凝 – 绿色_(Instrumental) 伴奏
1_陈雪凝 – 绿色_(Vocals) 人声
等下推理时候会用到 这个 _(Vocals) 人声部分
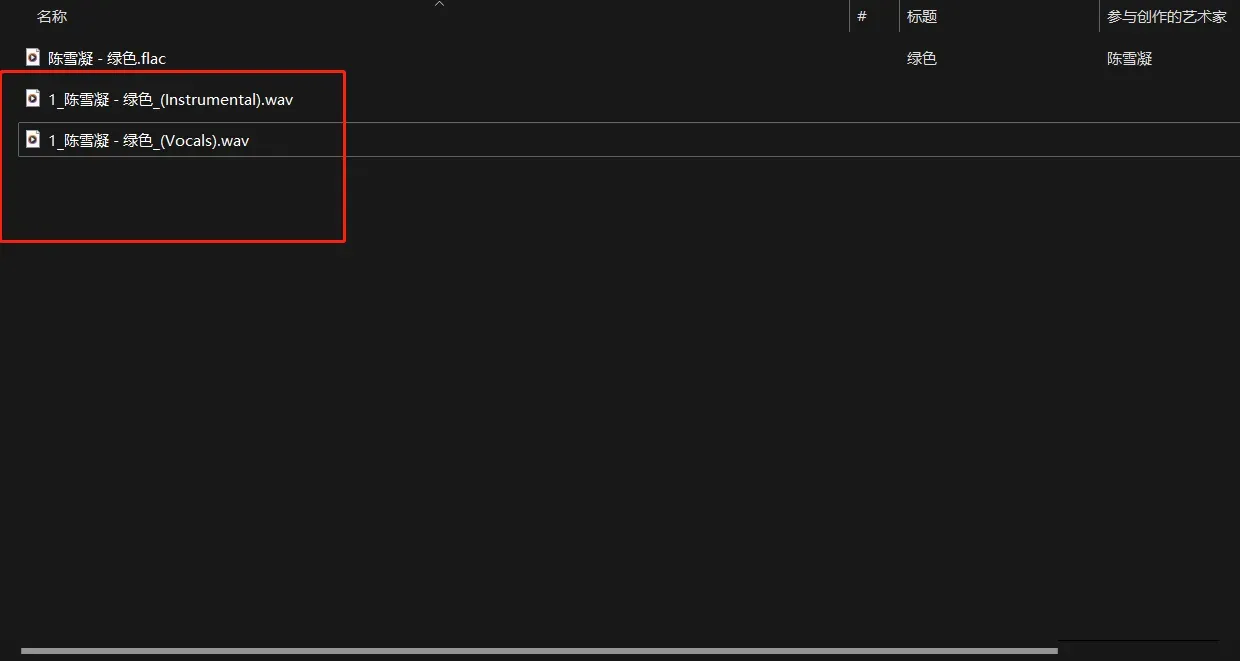
注:
- 模型要记得选择 MDX-NET UVR-MDX-NET Main
处理模型下载
将下载好的模型,放到UVR根目录下面的models文件夹下
- 如果分离过程中出现报错,可能原因是显存或内存不足,尝试重启电脑
2,歌曲推理
- 打开整合包
RVC0813 整合包下载(整合包 包含 运行环境 启动器)
下载之后,解压
版本说明
下载RVC0813AMD_Intel包可解锁A卡I卡
(1)双击go-realtime-gui-dml.bat使用实时变声,A卡大概能压到300ms左右,以下有压力
(2)双击go-web-dml.bat使用训练推理(CPU训练)
N卡用户下载RVC0813Nvidia
(1)双击go-realtime-gui.bat使用实时变声,N卡大概能压到100ms左右,以下有压力
双击go-web.bat使用训练推理
选择合适自己的显卡下载
- 等待启动,出现地址,表示启动成功
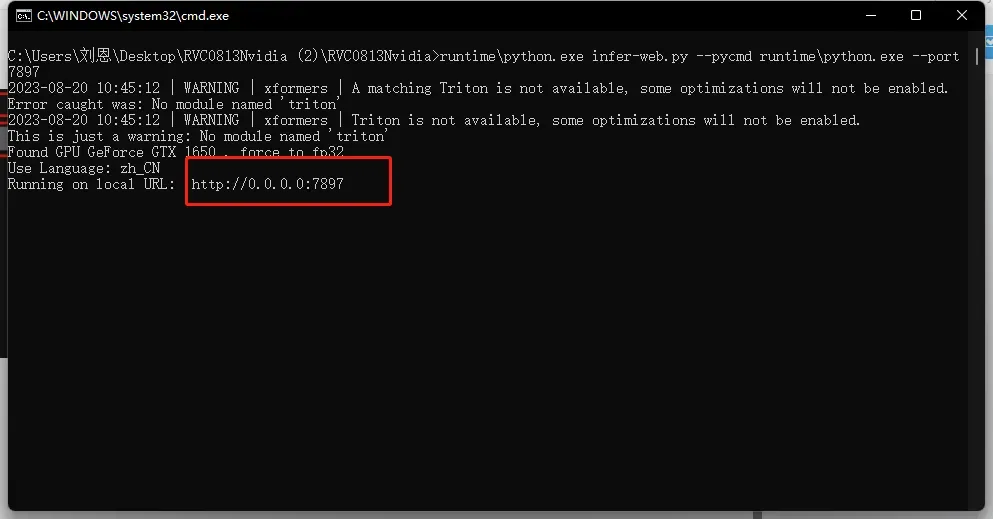
启动成功会自动跳转WEBUI
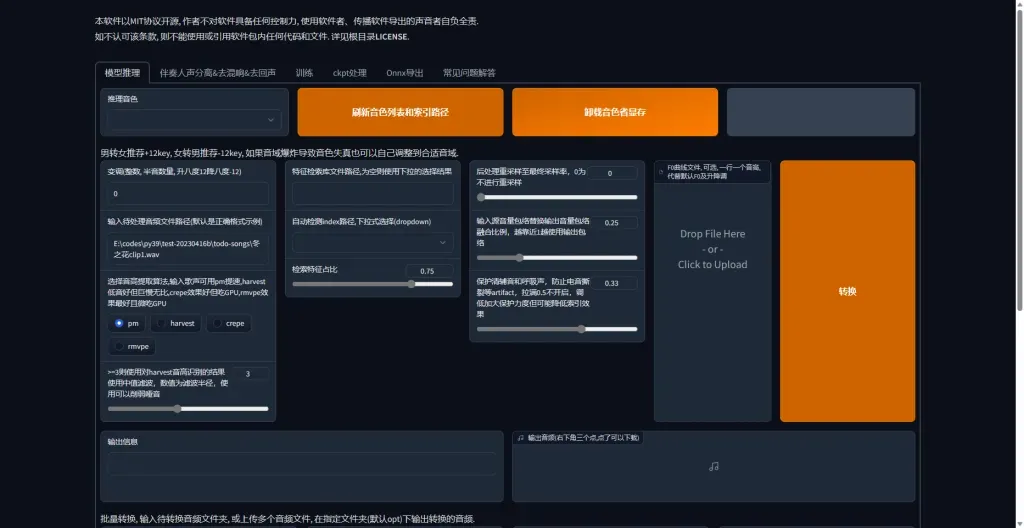
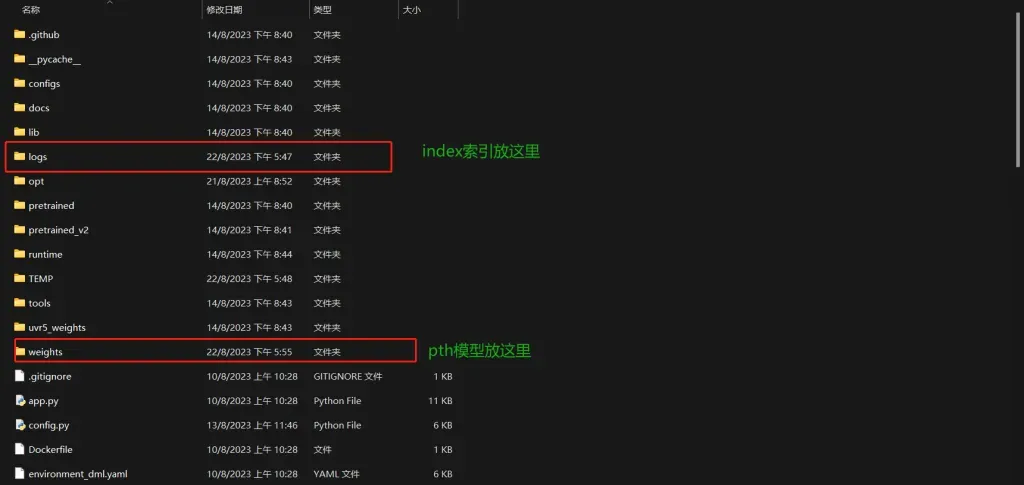
将模型放置到目录(训练好的,忽略这一步)
刷新音色,然后按顺序进行推理
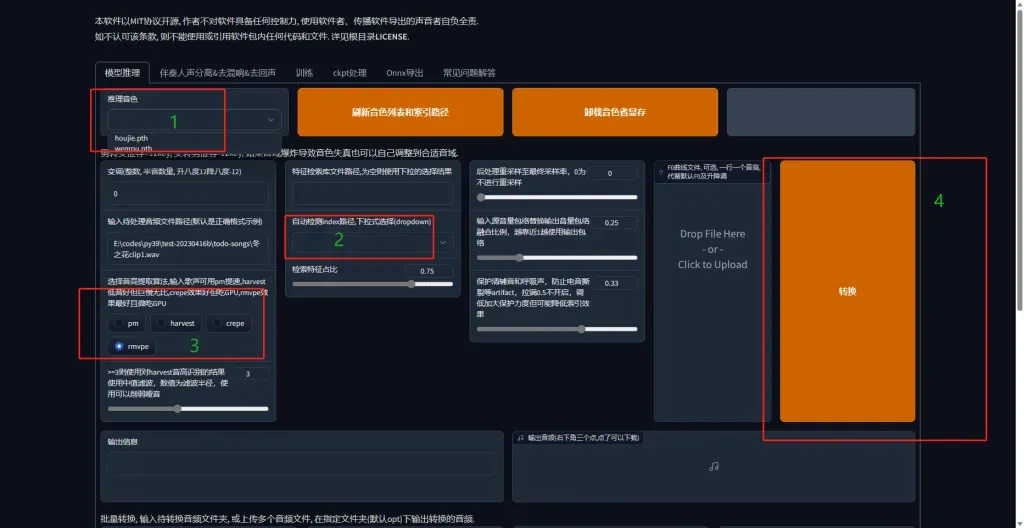
解疑
音频地址
WIN11 鼠标右击可以快速复制地址,复制的地址前后如果带有双引号记得删除”“
WIN10 需要将声音文件放到 任意文件夹内,按shift+鼠标右键 选择复制路径

四、歌曲合成
所需工具 AU 链接:百度网盘 请输入提取码
解压密码 @vposy
1,转换后的歌曲人声下载到桌面
2,使用AU将伴奏和转换后的人声合并
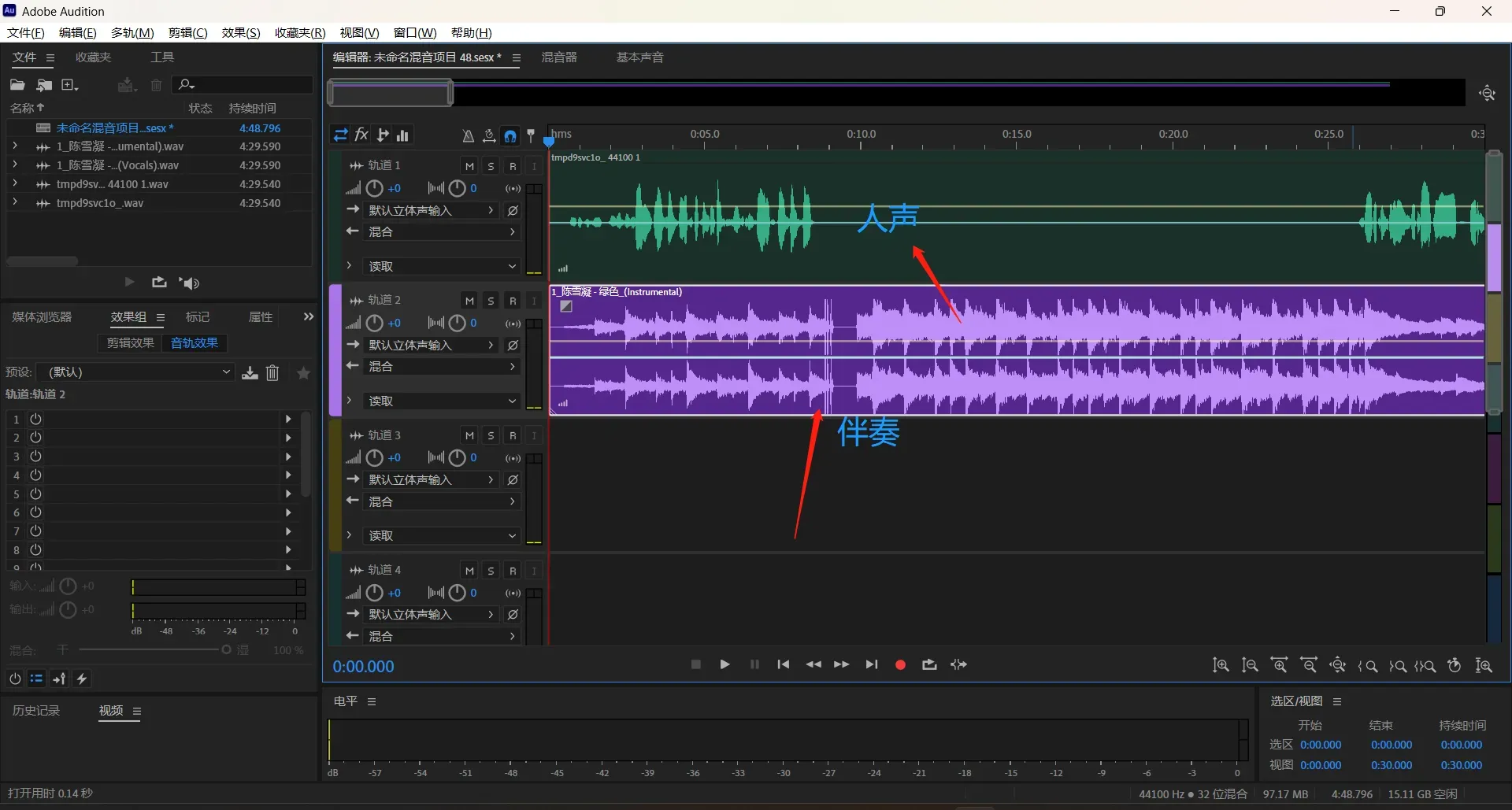
首先新建多轨会话,将转换的人声和伴奏拉进AU
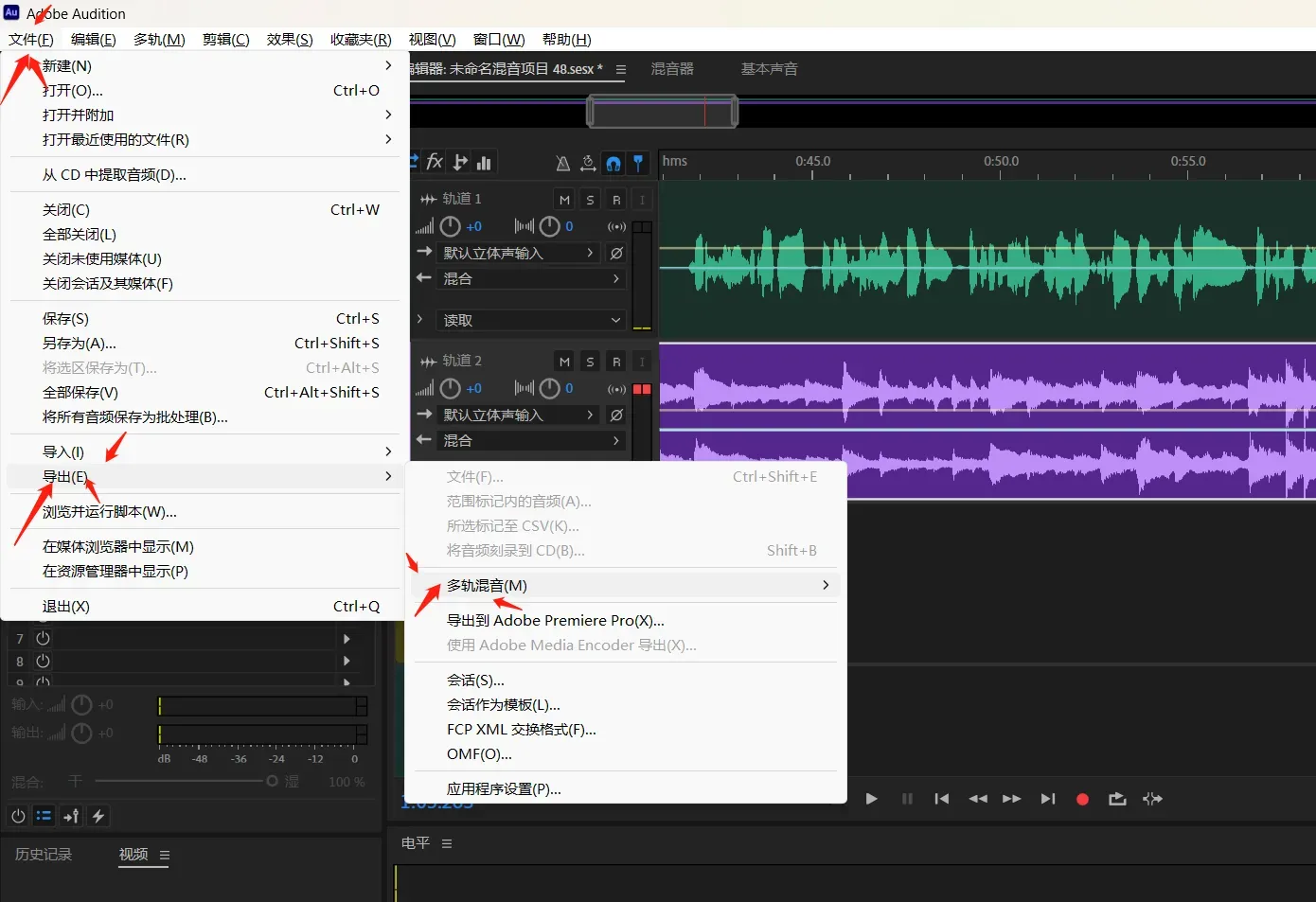
导出
教程结束,教程写的有点乱,多多包涵,有什么不懂的欢迎私。
五、模型下载
模型已上传至,模型工坊。mxgf.cc 搜索懒羊羊 就可下载
训练写文章不易,希望支持下
文章出处登录后可见!