目录
- 前言
- 总体设计
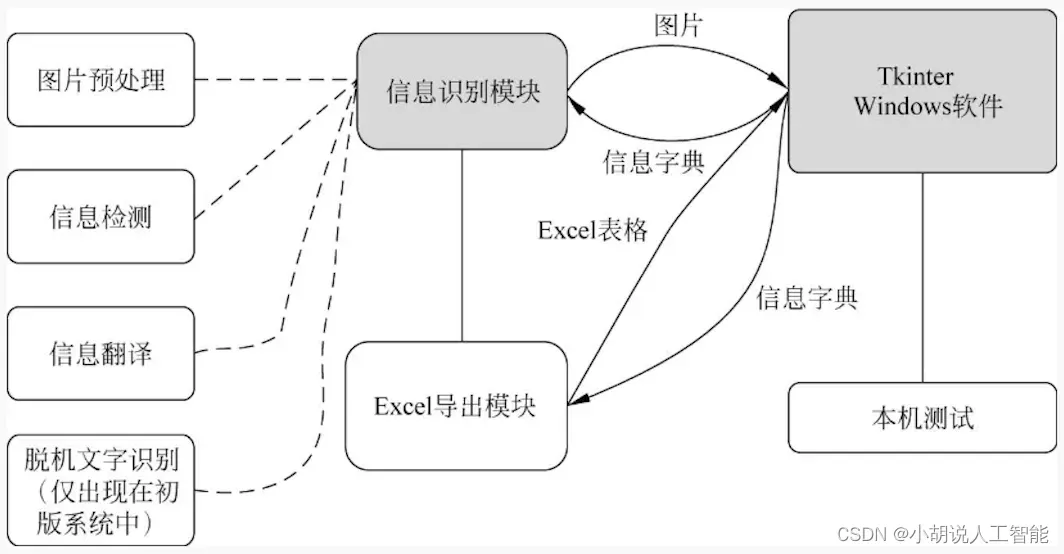
- 系统整体结构图
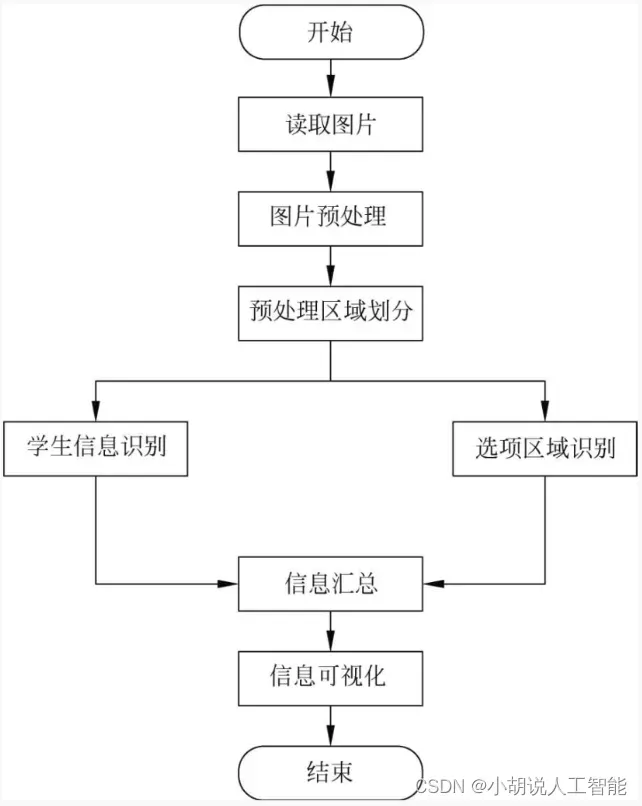
- 系统流程图
- 运行环境
- Python 环境
- PyCharm安装
- OpenCV环境
- 模块实现
- 1. 信息识别
- 2. Excel导出模块
- 3. 图形用户界面模块
- 4. 手写识别模块
- 系统测试
- 1. 系统识别准确率
- 2. 系统识别应用
- 工程源代码下载
- 其它资料下载
前言
本项目基于Python和OpenCV图像处理库,在Windows平台下开发了一个答题卡识别系统。系统运用精巧的计算机视觉算法,实现了批量识别答题卡并将信息导出至Excel表格的功能。这一解决方案使得答题卡的判卷过程变得轻便、高效且准确。
首先,我们以Python语言作为开发基础,结合OpenCV图像处理库,为系统提供了强大的图像处理和分析能力。这使得我们能够在图像中准确地定位答题卡,检测填涂区域,以及识别填涂的内容。
在Windows平台下进行开发,我们能够充分利用操作系统的功能,确保系统在用户环境中的稳定性和兼容性。
系统中的计算机视觉算法经过精心设计,可以可靠地识别答题卡上的填涂信息。从扫描的图像中,我们能够确定哪些选项被填涂,并将这些信息精准地提取出来。
一旦信息被提取,系统能够将这些数据导出至Excel表格,实现了高效的数据整理和统计功能。这使得判卷过程变得高度自动化,减少了繁琐的手动工作,同时也降低了错误的风险。
总结而言,本项目的开发利用了Python语言和OpenCV图像处理库的强大功能,实现了一个全面的答题卡识别系统。通过高效的图像处理和数据导出功能,系统不仅减轻了判卷的负担,还大幅度提高了识别的准确性和效率。这对于教育机构和考试机构来说,都具有极大的实用价值。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
系统流程图
系统流程如图所示。
运行环境
本部分包括Python环境、OpenCV环境、图像处理工具包、requests、 base64和xlwt模块 。
Python 环境
需要Python 3.6及以上配置。在Windows环境下下载Anaconda完成Python所需配置,下载地址为https://www.anaconda.com/。
PyCharm安装
在网站https://www.jetbrains.com/pycharm/中下载对应机器的安装包。采用免费社区版下载exe格式文件即可。
OpenCV环境
在PyCharm中安装OpenCV 3.4.15,选择Settings下Project中的Interpreter,单击右上角加号,搜索需要添加的库,选中Specifyversion和3.4.15,单击OK按钮即可。
按如上方法安装imutils、requests和base64。 通过pip install xlwt安装xlwt模块,实现数据写入Excel表格的功能。
模块实现
本项目包括4个模块:信息识别、Excel导出、图形用户界面和手写识别,下面分别介绍各模块的功能及相关代码。
1. 信息识别
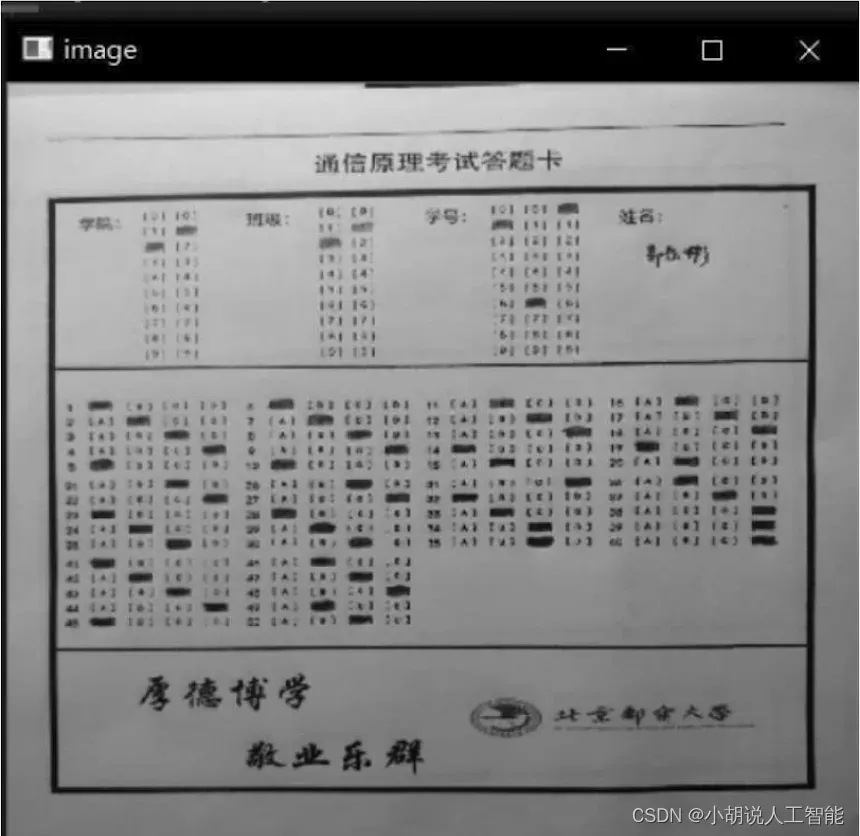
基于OpenCV算法,实现对图片中选项信息、学生身份信息的检测。在开始编写系统前,用Photoshop软件绘制用到的答题卡,如图所示。

答题卡中共计50道单选题,每选对1题得2分,漏选提示“漏选”,多选提示“多选”,最后返回成绩和统计错误选项的字典。
学院、班级、学号等信息采用“涂出来”的方式,相比初版系统中“写出来”的方式,识别准确率更高,代码更简单。
具体描述如下:
(1)利用get_position函数,通过上述信息识别算法,拿到身份信息被涂轮廓的重心坐标数组Info和选项信息被涂轮廓重心坐标数组Answer。
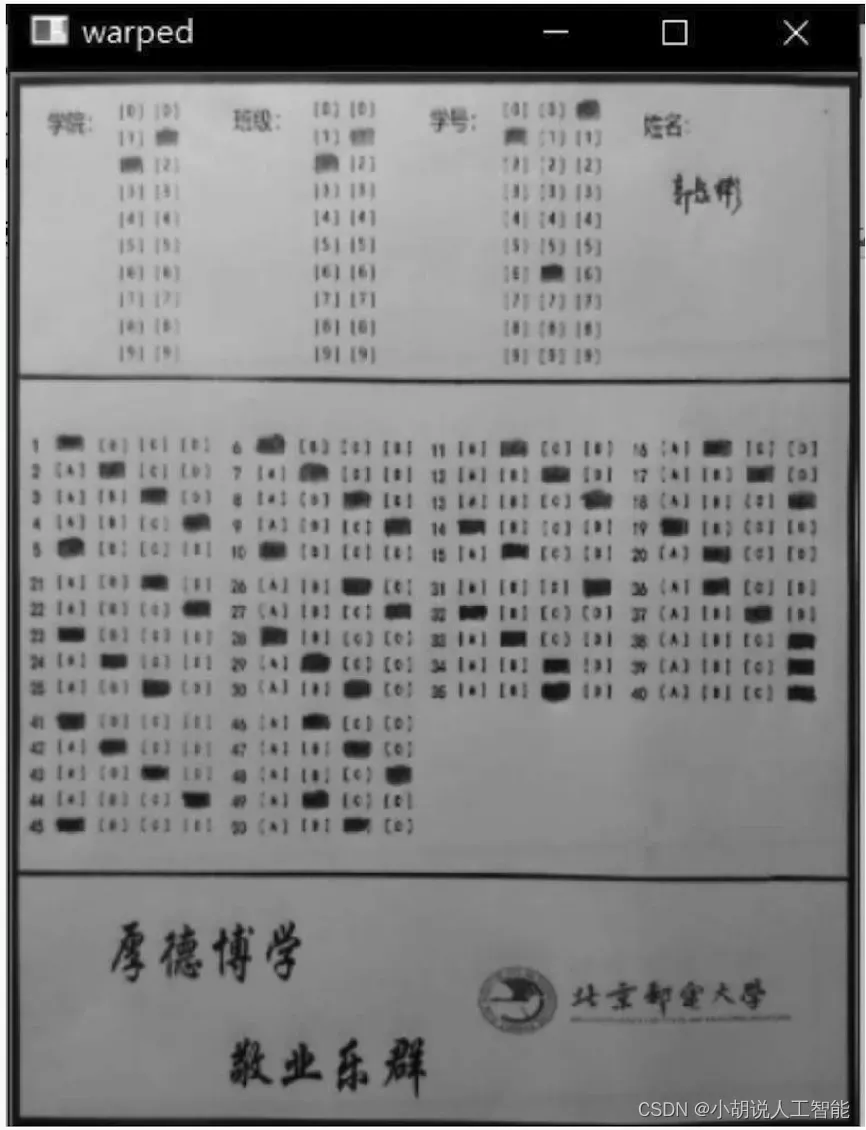
图片预处理:将图片做滤波去噪后,进行透视变换,并调整至2400X 2800的统一规格, 如图1~图9所示。
相关代码如下:
#导入相应数据包
import cv2
import matplotlib.pyplot as plt
import imutils
import numpy as np
def cv_show(name, img): #展示图片
cv2.namedWindow(name, 0)
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
def order_points(pts): #对4点进行排序
#共4个坐标点
rect = np.zeros((4, 2), dtype = "float32")
#按顺序找到对应坐标0、1、2、3分别是左上、右上、右下、左下
#计算左上和右下
s = pts.sum(axis = 1)
rect[0] = pts[np.argmin(s)]
rect[2] = pts[np.argmax(s)]
#计算右上和左下
diff = np.diff(pts, axis = 1)
rect[1] = pts[np.argmin(diff)]
rect[3] = pts[np.argmax(diff)]
return rect
def toushi_transform(image, pts): #输入原始图像和4角点坐标
#获取输入坐标点
rect = order_points(pts)
(tl, tr, br, bl) = rect
#计算输入的w和h值
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
#变换后对应坐标位置
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
#计算变换矩阵
print("原始四点坐标:\n",rect,"\n变换后四角点坐标:\n",dst)
M = cv2.getPerspectiveTransform(rect, dst)
print("变换矩阵:",M)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
#返回变换后结果
return warped
def get_postion(image_name):
#读入图片
image = cv2.imread(image_name)
#预处理
#转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#高斯滤波
blurred = cv2.GaussianBlur(gray, (3, 3), 0)
#自适应二值化方法
blurred=cv2.adaptiveThreshold(blurred,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,51,2)
cv_show('blurred',blurred)
edged = cv2.Canny(blurred, 10, 100)
#为透视变换做准备
cnts = cv2.findContours(edged, cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1]
docCnt = None
#确保至少有一个轮廓被找到
if len(cnts) > 0:
#将轮廓按大小降序排序
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)
#对排序后的轮廓循环处理
for c in cnts:
#获取近似的轮廓
peri = cv2.arcLength(c, True)
approx = cv2.approxPolyDP(c, 0.02 * peri, True)
#如果近似轮廓有4个顶点,认为找到了答题卡
if len(approx) == 4:
docCnt = approx
break
newimage=image.copy()
for i in docCnt:
#circle函数为在图像上作图,新建一个图像用来演示4角选取
cv2.circle(newimage, (i[0][0],i[0][1]), 50, (255, 0, 0), -1)
#透视变换
paper = toushi_transform(image, docCnt.reshape(4, 2))
warped = toushi_transform(gray, docCnt.reshape(4, 2))
#cv_show('warped',warped)
#对灰度图应用二值化算法
thresh=cv2.adaptiveThreshold(warped,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,53,2)
#重塑可能用到的图像
width1=2400
height1=2800
#转换成标准大小:2400*2800
thresh = cv2.resize(thresh, (width1, height1), cv2.INTER_LANCZOS4)
paper = cv2.resize(paper, (width1, height1), cv2.INTER_LANCZOS4)
warped = cv2.resize(warped, (width1, height1), cv2.INTER_LANCZOS4)
cv2.imwrite("warped.jpg", warped)
识别被涂选项轮廓的重心相关代码如下:
#透视变换、resize成2400*2800的图片
#均值滤波
ChQImg = cv2.blur(thresh, (23, 23))
#二进制二值化
ChQImg = cv2.threshold(ChQImg, 100, 225, cv2.THRESH_BINARY)[1]
#cv_show('ChQImg',ChQImg)
#在二值图像中查找轮廓
cnts = cv2.findContours(ChQImg, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if imutils.is_cv2() else cnts[1]
Answer=[]
Info=[]
for c in cnts:
#计算轮廓的边界框,利用边界框数据计算宽高比
(x, y, w, h) = cv2.boundingRect(c)
if (x > 1200 and y > 1700): continue #排除右下角区域的误选
#if (w > 60 &h > 20)and y>900 and y<2000:
if (95 > w > 60) and y > 880 and y < 2050:
M = cv2.moments(c)
cX = int(M["m10"] / M["m00"])
cY = int(M["m01"] / M["m00"])
#绘制中心及其轮廓
cv2.drawContours(paper, c, -1, (0, 0, 255), 5, lineType=0)
cv2.circle(paper, (cX, cY), 7, (255, 255, 255), -1)
#保存题目坐标信息
Answer.append((cX, cY))
if ( 90> w > 55) and y<800 and x<1750 :
M = cv2.moments(c)
cX = int(M["m10"] / M["m00"])
cY = int(M["m01"] / M["m00"])
#绘制中心及其轮廓
cv2.drawContours(paper, c, -1, (0, 255, 0), 5, lineType=0)
cv2.circle(paper, (cX, cY), 7, (255, 255, 255), -1)
#保存题目坐标信息
Info.append((cX, cY))
cv_show('paper',paper)
cv2.imwrite("paper.jpg", paper)
imm = cv2.resize(paper, (180, 210), cv2.INTER_LANCZOS4)
cv2.imwrite("imm.jpg", imm)
print(Answer)
print(len(Answer))
print(Info)
return Info,Answer








[ (977, 1992),(165, 1992),(523, 1926),(861,1925 ),( 1097,1859 ),(403,1853 ),(978,1790),( 284, 1784 ),(861,1717),(166,1716),(2239, 1643),( 1544, 1638),(978, 1631),(406, 1629),(2237, 1572),(1542, 1569),(286, 1557 ),( 859,1561 ),( 2238,1503 ),(1422,1497),(167,1486 ),(739,1490),( 1306, 1428 ),(2118, 1432),(1095, 1424),(523,1417),( 1657,1362), (1997,1360), (976,1359), (405,1347),(1999,1273),(1424,1264),( 738,1264),(165,1256) ,(1303, 1200) ,(1877, 1199) ,(1094,1199),( 521, 1189), ( 2242,1130),(976 ,1129),(1660, 1128) ,(402,1118),(1542, 1062),(2123,1060) ,(853, 1058),( 282,1049),( 2000,990),(1423,991) ,(161, 976),(734, 982) ]
共计50个,与所涂的50个选项相匹配。
返回个人信息轮廓重心坐标Info: [ (1531, 528) ,(1218,238),(336, 239),(889, 235),(437, 167),(992, 165) ,(1428, 162) ,(1634, 96) ],共计8个点,包括2个确定学院、2个确定班级、3个确定学号、1个学号确认点。
(2)使用explain ()函数,对个人信息轮廓重心坐标进行解释。返回对应的学院、班级和学号。在预处理时,通过透视变换,从拍摄图片中取出答题卡,将图片调整至2400 X 2800的规格,如图10和图11所示。
各信息所在位置基本不变,用Photoshop查看像素位置坐标,反复调整边界参数,如下图所示。
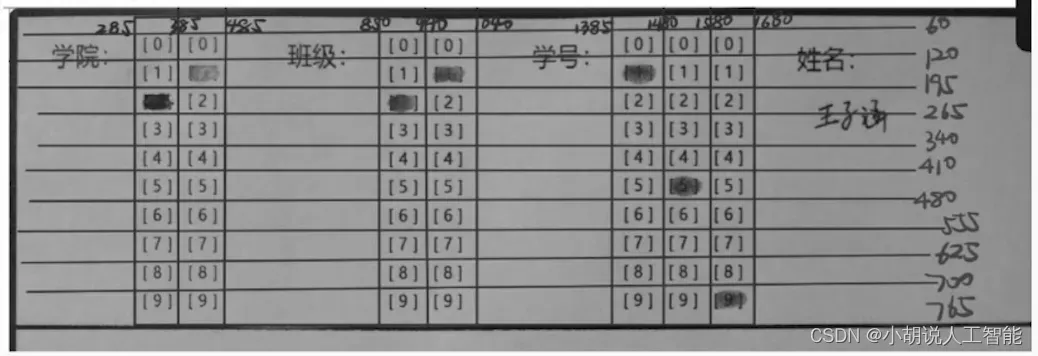
判断上述信息数组中轮廓重心的图像像素坐标。根据重心x坐标所在区间,判断信息类型(学号、班级或学院);根据重心y坐标所在区间,判断数字大小:
def judge(x,y):
xt0=[285,385,485, 850,940,1040, 1385,1480,1580,1680]
yt0=[60,120,195,265,340,410,480,555,625,700,756]
flagy=-1
flagx=-1
for j in range(10):
if yt0[j]<y and y<yt0[j+1]:
flagy=j
for i in range(7):
if i<=1:
if xt0[i]<x and x<xt0[i+1]:
flagx=i
elif i<=3:
if xt0[i+1]<x and x<xt0[i+2]:
flagx=i
else:
if xt0[i+2]<x and x<xt0[i+3]:
flagx=i
return flagx,flagy
def explain(Info):
id={}
for item in Info:
if item[0]!=-1 or item[1]!=-1:
pos,num=judge(item[0],item[1])
id[pos]=num
sch_num=id[0]*10+id[1]
cls_num=id[2]*10+id[3]
stu_num=id[4]*100+id[5]*10+id[6]
print("学号:",sch_num,"班级:",cls_num,"学号:",stu_num)
return sch_num,cls_num,stu_num
以测试图片为例返回结果——学院: 21、班级: 21、学号: 160。
(3)使用calculate ()函数,对选项轮廓重心坐标进行解释。返回包含对应的题号和选项的字典,如果遇到多涂、漏涂情况,则返回“多涂”“漏涂”的提示。同样使用Photoshop查看像素位置坐标,反复调整边界参数,如下图所示。
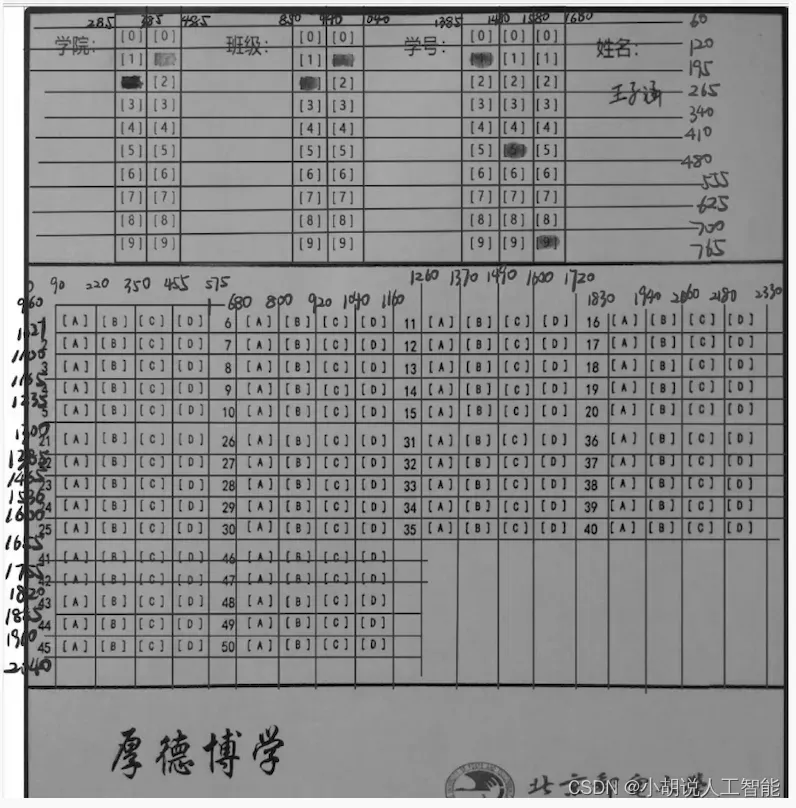
编写judgey0()函数判断题号和judgex0函数判断选项。根据选项每四个为一堆的特点,做除法和取余数,使用judge0()函数,将题号与所涂选项匹配。
相关代码如下:
def judgey0(y):
if (y / 5 < 1):
return y + 1
elif y / 5 < 2 and y/5>=1:
return y % 5 + 20 + 1
else:
return y % 5 + 40 + 1
def judgex0(x):
if(x%5==1):
return 'A'
elif(x%5==2):
return 'B'
elif(x%5==3):
return 'C'
elif(x%5==4):
return 'D'
def judge0(x,y): #返回题号和答案
if x/5<1 :
#print(judgey0(y))
return judgey0(y),judgex0(x)
elif x/5<2 and x/5>=1:
#print(judgey0(y)+5)
return judgey0(y)+5,judgex0(x)
elif x/5<3 and x/5>=2:
#print(judgey0(y)+10)
return judgey0(y)+10,judgex0(x)
else:
#print(judgey0(y)+15)
return judgey0(y)+15,judgex0(x)
def calculate(Answer):
xt1 = [0, 90, 220, 350, 455, 575, 680, 800, 920, 1040, 1160, 1260, 1370, 1490, 1600, 1720, 1830, 1940, 2060, 2180, 2330]#横向划分点
yt1 = [960, 1027, 1100, 1165, 1235, 1300, 1385, 1465, 1536, 1600, 1655, 1755, 1820, 1885, 1960, 2040]#纵向划分点
ans_dict = {}
for i in Answer:
for j in range(0, len(xt1) - 1):
if i[0] > xt1[j] and i[0] < xt1[j + 1]:
for k in range(0, len(yt1) - 1):
if i[1] > yt1[k] and i[1] < yt1[k + 1]:
a, b = judge0(j, k)
if (a in ans_dict.keys()):
ans_dict[a]='多选' #之前有被选过,判多选
else:
ans_dict[a] = b
break
print('ans:',ans_dict)
return ans_dict
根据重心坐标所在区间,得到对应的题号和选项。以测试图片为例,返回携带选项信息字典ans:{50: ‘C’ ,45: ‘A’,44: ‘D’,49: ‘B’ ,48: ‘D’,43: ‘C’ ,47: ‘C’, 42:‘B’,46: ‘B’, 41 : ‘A’, 40: ‘D’, 35: ‘C’ ,30:‘C’,25:‘C’,39: ‘D’,34: ‘C’,24:‘B’,29 :‘B’,38:‘D’,33: ‘B’ ,23: ‘A’,28: ‘A’,32: ‘A’,37: ‘C’ ,27:‘D’,22:‘D’,31 : ‘D’, 36: ‘B’,26: ‘C’,21: ‘C’,20: ‘B’, 15:‘B’,10: ‘A’,5:‘A’, 14: ‘A’, 19: ‘A’, 9 :‘D’,4:‘D’ ,18 :‘D’,8:‘C’,13 :‘D’,3:‘C’ ,12:‘C’,17:‘C’, 7:‘B’,2:‘B’,16 : ‘B’,11 : ‘B’,1:‘A’,6: ‘A’}。 其中ans[题号]=所涂答案。
(4)使用sumall()函数,对上述功能进行汇总,并对比正确答案和学生涂写答案,返回学院、班级、学号、分数、错题完成信息识别功能。
def sumall(image_name,true_ans=true_ans):
Info,Answer=get_postion(image_name) #拿到信息轮廓数组
sch_num, cls_num, stu_num=explain(Info) #解释个人信息
ans=calculate(Answer) #判断所涂选项
score=0
false_ans={}
for i in range(1,len(true_ans)+1):
if (i in ans.keys()):
if(ans[i]==true_ans[i]):
score+=2
else:
false_ans[i]=ans[i]
else:
false_ans[i]='漏选'
print(false_ans)
return sch_num,cls_num,stu_num,score,false_ans
2. Excel导出模块
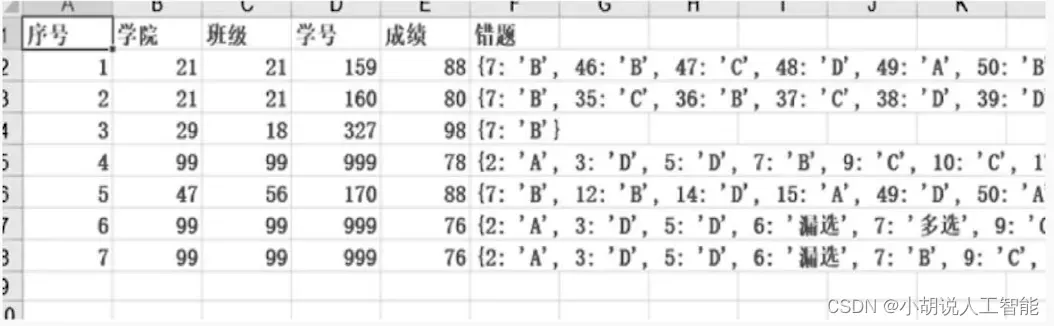
本系统用data字典记录每次识别的信息,其中data字典初始化如下: data={"序号": ["学 院","班级","学号","成绩","错题"]},使用xlwt将data字典中信息导出到当前路径下名为data.xls的Excel表格中。
相关代码如下:
import xlrd,xlwt,os
def set_stlye(name,height,bold=False):
#初始化样式
style = xlwt.XFStyle()
#创建字体
font = xlwt.Font()
font.bold = bold
font.colour_index = 4
font.height = height
font.name = name
style.font = font
return style
def write_excel(data):
if os.path.exists("data.xls"):
os.remove("data.xls")
book = xlwt.Workbook(encoding='utf-8') #创建Workbook,相当于创建Excel
#创建sheet,Sheet1为表的名字,cell_overwrite_ok为覆盖单元格
sheet1 = book.add_sheet(u'Sheet1', cell_overwrite_ok=True)
r = 0
for i, j in data.items(): #i表示data中的key,j表示data中的value
le = len(j) #values返回的列表长度
if r == 0:
sheet1.write(r, 0, i,set_stlye("Time New Roman",220,True))
#添加第 0 行 0 列数据单元格背景设为黄色
else:
sheet1.write(r, 0, i,set_stlye("Time New Roman",220,True) )
#添加第1列的数据
for c in range(1, le + 1): #values列表中索引
if r == 0:
sheet1.write(r, c, j[c - 1],set_stlye("Time New Roman",220,True))
#添加第 0 行2 列到第 5 列的数据单元格背景设为黄色
else:
sheet1.write(r, c, j[c - 1],set_stlye("Time New Roman",220,True))
r += 1 #行数
#sheet_merge()合并单元格
book.save('data.xls')
print("已导出至:data.xls")
如果data.xls存在,导出时将其覆盖。以测试为例,结果如图所示。
3. 图形用户界面模块
利用Python标准GUI库Tkinter实现本模块功能,如图14和图15所示。


读取图片时,用户可以输入图片地址,单击【选择文件】按钮,批量处理本地图片文件。选择图片所在的文件夹,系统将识别每个满足条件的图片。
在设置中,用户可以自定义确定答案。单击【识别】按钮,系统可识别所选中的图片文件,并将识别后的学院、班级、学号、成绩、错题等信息显示在右边。单击【导出】按钮,将本次系统识别的所有数据导出到data.xls表格中。
相关代码如下:
import tkinter as tk
from iidd import sumall
from ooctest import getinfo
from PIL import Image,ImageTk
import cv2
from excel import write_excel
data = {
"序号": ["学院", "班级", "学号", "成绩","错题"]
}
cnt=0
import os
def walk(path):
files=[]
if not os.path.exists(path):
return -1
for root, dirs, names in os.walk(path):
for filename in names:
file=os.path.join(root, filename)
print(file) #路径和文件名连接构成完整路径
files.append(file)
return files
#if __name__=='__main__':
#path='C:/Users/wanli/answer sheet/images'
#walk(path)
def discern():
global imgs
print(entry_img_name.get())
global cnt
cnt+=1
da=[] sch_num,cls_num,stu_num,score,false_ans=sumall(entry_img_name.get(),true_ans=true_ans) da.append(sch_num);da.append(cls_num);da.append(stu_num);da.append(score);da.append(str(false_ans));
data[cnt]=da
imm = Image.open('imm.jpg') #将照片展示
imgs = ImageTk.PhotoImage(imm)
print(score)
l_info1.config(text='学院:'+ str(sch_num)+'班级: '+str(cls_num))
l_info2.config(text='学号: '+str(stu_num))
l_info3.config(text='错题:'+str(false_ans))
l_score.config(text='成绩:'+str(score))
imLabel.config(image=imgs)
def set_ans():
def confirm():
global ans_str,true_ans
ans_str = new_ans.get()
window_set_ans.destroy()
true_ans=eval(ans_str)
window_set_ans=tk.Toplevel(window)
window_set_ans.geometry('350x200')
window_set_ans.title('初始化试卷')
new_ans = tk.StringVar()
new_ans.set(str(true_ans))
tk.Label(window_set_ans, text='输入正确答案').place(x=10, y=10)
entry_new_ans = tk.Entry(window_set_ans, textvariable=new_ans,
justify='left')
entry_new_ans.place(x=100, y=10,width=230,height=150)
btn_confirm = tk.Button(window_set_ans, text='确定', command=confirm)
btn_confirm.place(x=150, y=130)
hbar=tk.Scrollbar(window_set_ans,orient='horizontal', command=entry_new_ans.xview)
entry_new_ans.configure(xscrollcommand=hbar.set)
hbar.pack(side='bottom',fill='x')
entry_new_ans.columnconfigure(0, weight=1)
true_ans={1:"A", 2:'B', 3:'C', 4:'D', 5:'A',
6:"A", 7:'A', 8:'C', 9:'D', 10:'A',
11:"B", 12:'C', 13:'D', 14:'A', 15:'B',
16:"B", 17:'C',18:'D', 19:'A', 20:'B',
21:"C", 22:'D', 23:'A', 24:'B', 25:'C',
26:"C", 27:'D', 28:'A', 29:'B', 30:'C',
31:"D", 32:'A', 33:'B', 34:'C', 35:'D',
36:"D", 37:'A', 38:'B', 39:'C', 40:'D',
41:"A", 42:'B', 43:'C', 44:'D', 45:'A',
46:"A", 47:'B', 48:'C', 49 :'C', 50:'C' }
def write():
print(data)
write_excel(data)
tell.config(text='已导入到data.xls')
window = tk.Tk()
window.title('答题卡识别系统')
window.geometry('550x400')
menubar=tk.Menu(window)
filemenu = tk.Menu(menubar,tearoff=0)
menubar.add_cascade(label='设置',menu=filemenu)
filemenu.add_cascade(label='初始化试卷',command=set_ans)
l_score=tk.Label(window,text='成绩:')
l_score.place(x=250,y=350)
l_info1=tk.Label(window,text='学院:班级:')
l_info1.place(x=250,y=250)
l_info2=tk.Label(window,text='姓名:学号:')
l_info2.place(x=250,y=300)
l_info3=tk.Label(window,text='错题:')
l_info3.place(x=330,y=350)
var_img_name=tk.StringVar()
var_img_name.set("new2.jpg")
#var_name=tk.StringVar()
#var_id=tk.StringVar()
#var_class=tk.StringVar()
#var_school=tk.StringVar()
l_en=tk.Label(window,text='输出图片地址')
l_en.place(x=25,y=225)
entry_img_name=tk.Entry(window,textvariable=var_img_name)
entry_img_name.place(x=30,y=250)
btn_test=tk.Button(window,text='识别',command=discern)
btn_test.place(x=40,y=300)
btn_excel=tk.Button(window,text='导出',command=write)
btn_excel.place(x=40,y=350)
#显示图片
#im = Image.open('mario_star.jpg')
#mario= ImageTk.PhotoImage(im)
imLabel = tk.Label(window,text='结果:')
imLabel.place(x=270,y=20)
def choose_fiel():
selectFileName = tk.filedialog.askopenfilename(title='选择文件') #选择文件
var_img_name.set(selectFileName)
def getall():
selectFileName0 = tk.filedialog.askdirectory() #选择文件
#var_img_name.set(selectFileName0)
files=walk(selectFileName0)
for filename in files:
global cnt
cnt += 1
da = []
sch_num, cls_num, stu_num, score, false_ans = sumall(filename, true_ans=true_ans)
da.append(sch_num);
da.append(cls_num);
da.append(stu_num);
da.append(score);
da.append(str(false_ans));
data[cnt] = da
tell.config(text='批量处理完毕')
submit_button1 = tk.Button(window, text ="选择文件", command = choose_fiel)
submit_button1.place(x=30,y=180)
submit_button1 = tk.Button(window, text ="批量处理", command = getall)
submit_button1.place(x=100,y=180)
tell=tk.Label(window,text='欢迎进入机读卡识别系统')
tell.place(x=30,y=70)
window.config(menu=menubar)
window.mainloop()
print(data)
4. 手写识别模块
初版系统答题卡如图所示。
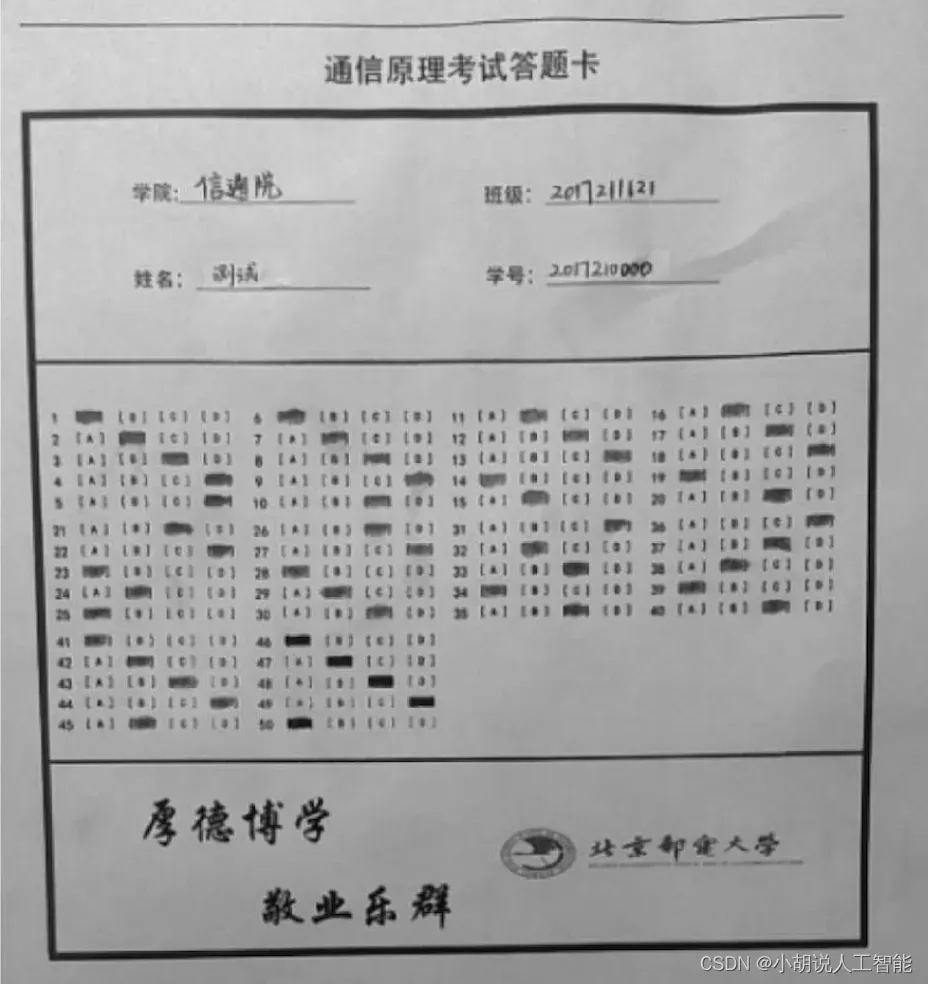
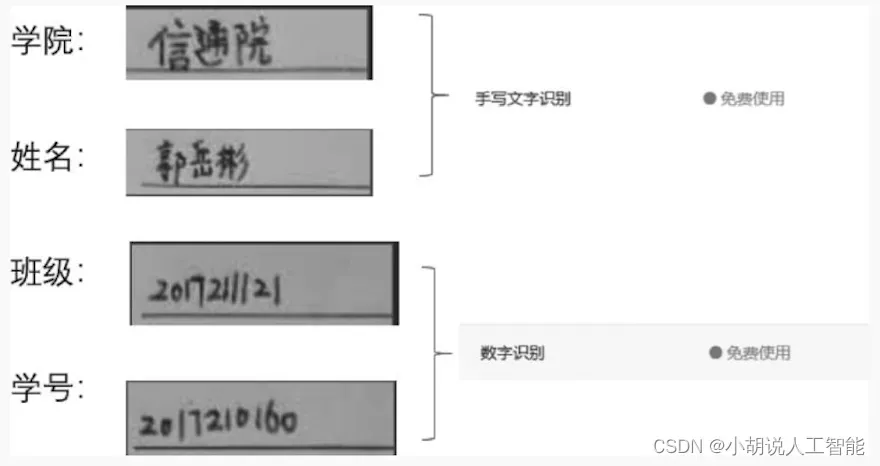
与最终版系统相似,对传入图片进行预处理、区域划分等操作。但这里让学生以“写出来”的方式填写个人信息,针对个人信息部分,调用百度API对学院、姓名进行手写文字识别,对班级、学号进行数字识别,如图所示。
在百度AI开放平台注册,并创建调用手写文字识别和数字识别的应用,如图所示。
使用API Key和Secret Key获得access_token, 对从答题卡中获取的学院、姓名做手写文字识别,对班级、学号做数字识别,将信息汇总到dict字典。
相关代码如下:
#encoding:utf-8
import requests
import base64
host= 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id= &client_secret= '
response = requests.get(host)
if response:
print(response.json())
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/handwriting"
#二进制方式打开图片文件
school = open('school.jpg', 'rb')
school_img = base64.b64encode(school.read())
name = open('name.jpg', 'rb')
name_img = base64.b64encode(name.read())
params_s = {"image":school_img}
params_n = {"image":name_img}
#access_token =“按上面方法获得”
#print(access_token)
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
responseS = requests.post(request_url, data=params_s, headers=headers)
dict={}
if responseS:
print(responseS.json())
print (responseS.json()['words_result'][0]['words'])
dict['school']=responseS.json()['words_result'][0]['words']
responseN = requests.post(request_url, data=params_n, headers=headers)
if responseN:
print (responseN.json()['words_result'][0]['words'])
dict['name']=responseN.json()['words_result'][0]['words']
#数字识别
cls = open('cls.jpg', 'rb')
cls_img = base64.b64encode(cls.read())
id = open('id.jpg', 'rb')
id_img = base64.b64encode(id.read())
params_c = {"image":cls_img}
params_i = {"image":id_img}
ru='https://aip.baidubce.com/rest/2.0/ocr/v1/numbers'
ru = ru + "?access_token=" + access_token
responseC = requests.post(ru, data=params_c, headers=headers)
responseI = requests.post(ru, data=params_i, headers=headers)
if responseS:
print (responseC.json()['words_result'][0]['words'])
dict['class']=responseC.json()['words_result'][0]['words']
if responseN:
print (responseI.json()['words_result'][0]['words'])
dict['id']=responseI.json()['words_result'][0]['words']
初版系统运行结果如图所示。
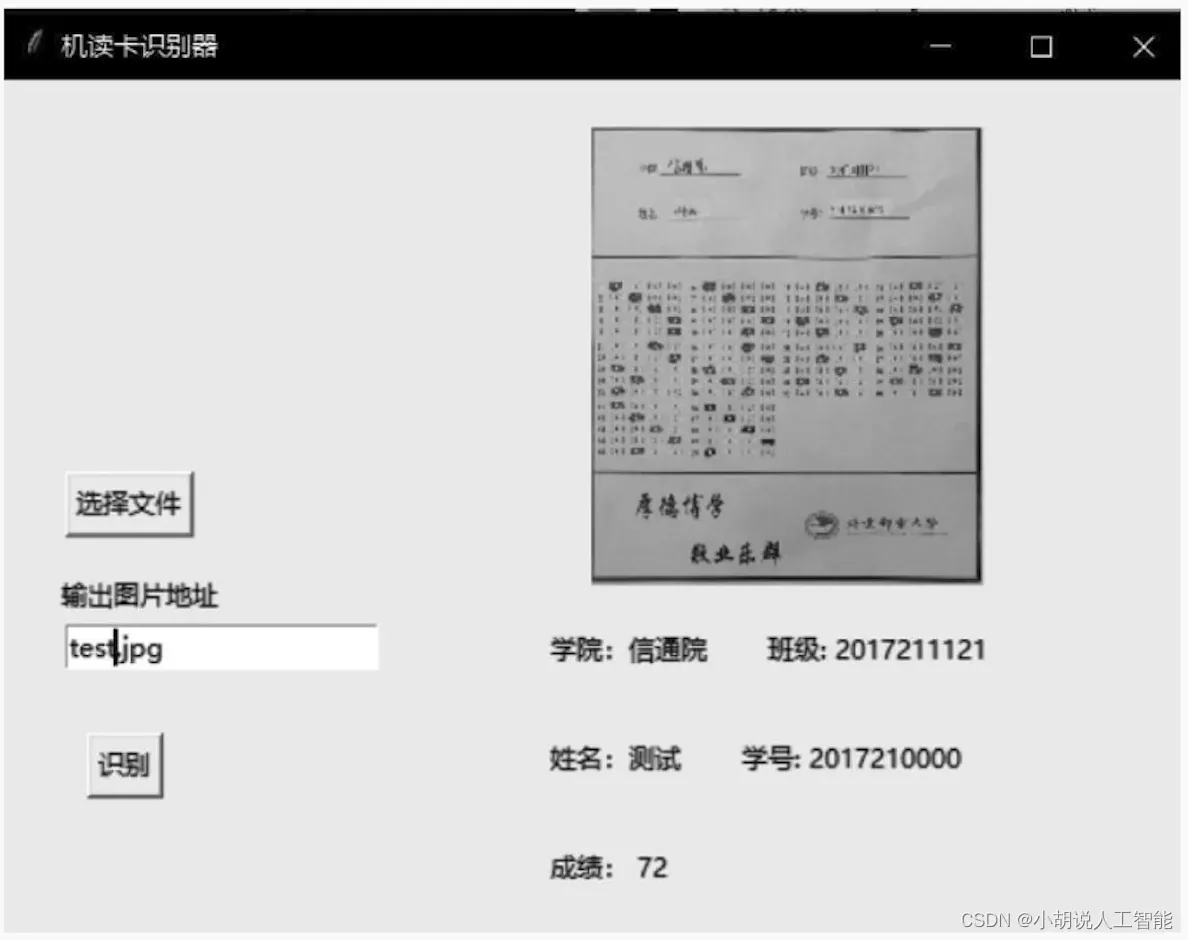
由于这种方法准确率低、需联网、速度慢、有使用次数限制等原因,已不在目前系统中使用。曾考虑搭建神经网络,但准确率仍然达不到要求,且代码烦琐,违背构建轻量系统的初衷,所以选择让学生把信息涂出来的方式,按上述OpenCV算法进行识别,准确率几乎达到100%。
系统测试
本部分包括系统识别准确率和系统识别应用。
1. 系统识别准确率
通过绘制数张答题卡进行测试,识别准确率达到100%。识别答题卡的原则是:如果照片不规范,则系统不识别;如果系统可识别,则需保证识别结果完全正确。每张答题卡测试效果如图16~图22所示。

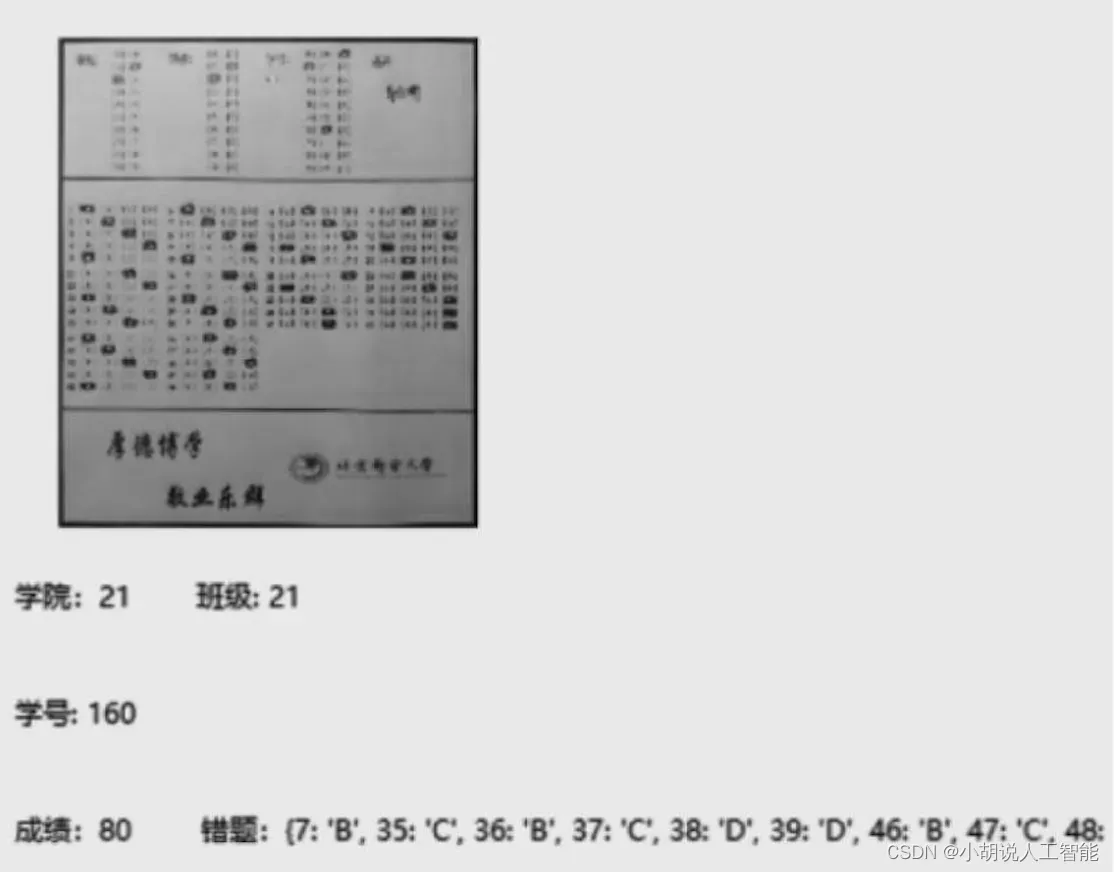




前4张测试图正常随机填涂,均准确无误。
针对不符合要求的图片,系统提示不合法。
针对多涂、漏涂情况,本系统能准确识别,并在错题字典中反馈信息。
虽然不能通过大量数据验证系统的稳定性,但至少说明程序是准确的,对于符合要求的图片,能够正确识别照片答题卡中学生信息和选项信息。
2. 系统识别应用
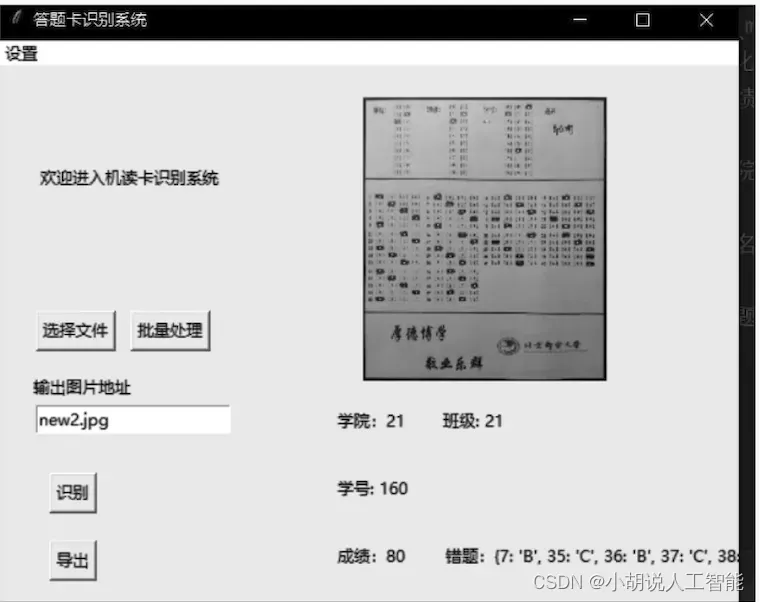
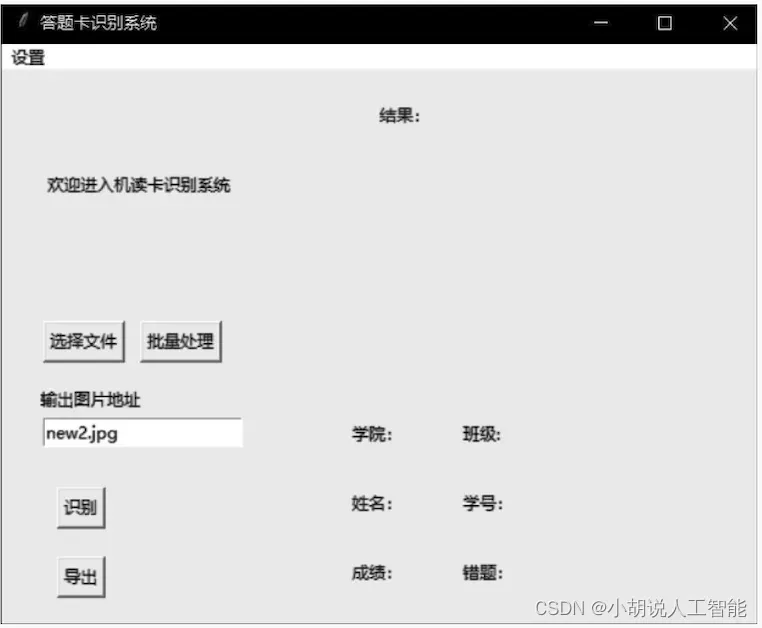
配置环境后,运行answer sheet中的turntogui.py文件,即可成功进入本系统,如图所示。
顶端为【设置】菜单,单击将弹出【初始化试卷】窗口,拖动滚动条,修改标准答案的字典。单击【确定】按钮完成修改,返回主界面,如图所示。
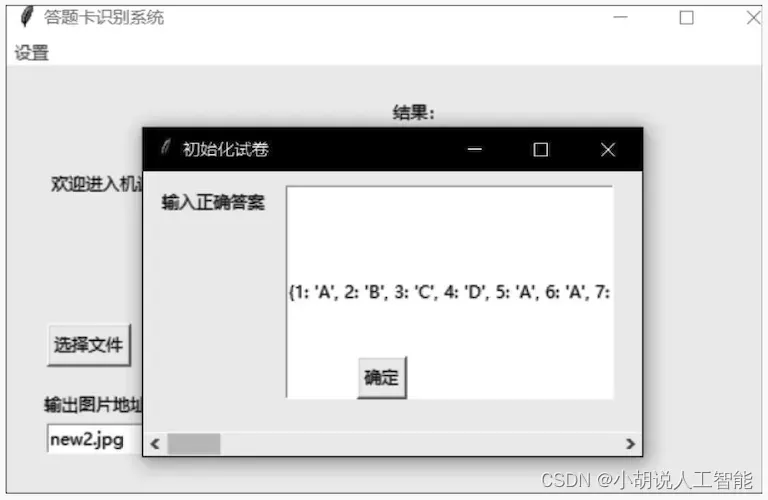
菜单栏下方为提示信息。
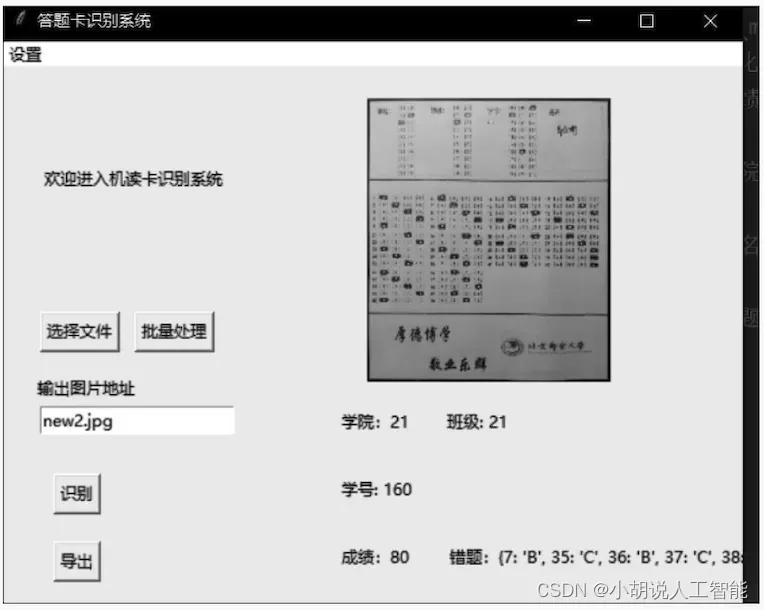
单击【选择文件】可以选择本地文件识别;单击【批量处理】按钮可以选择指定文件夹,识别文件夹内符合要求的图片。
手动输入图片地址,单击【识别】 按钮识别图片,单击【导出】按钮将信息导出为data.xls文件。
在启动识别后,窗口右侧将展示识别得到的信息,如图片、学院、学号、成绩和错题集等。
系统测试效果如图所示。
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。
文章出处登录后可见!