文章目录
- 一、程序存储空间
- 1.1 C语言程序存储空间
- 1.2 用户空间和内核空间
- 1.3 用户模式和内核模式
- 二、内核调用-系统调用-C语言库函数
- 2.1 系统调用和内核调用
- 2.2 C语言库函数
- 三、Linux如何执行一个程序
一、程序存储空间
本节说的空间主要是指内存空间,即程序如何分配和使用内存。
1.1 C语言程序存储空间
可执行程序,而不是源代码。
C语言程序的存储空间包括以下几个主要部分:
-
代码段(Text Segment): 也称正文段, 代码段是存储C程序的机器代码的区域。它包含了程序的指令集,这些指令由编译器生成,并且在程序执行时按照顺序执行。代码段通常是只读的,这意味着程序在运行时不能修改它。
-
数据段(Data Segment): 数据段用于存储全局变量、静态变量和常量数据。这些数据在程序运行期间存在,并且可以被程序的不同函数访问。数据段通常分为初始化数据段(.data)和未初始化数据段(.bss)。初始化数据段存储已初始化的全局变量和常量数据,而未初始化数据段存储未初始化的全局变量(被自动初始化为0或空指针)。
-
堆(Heap): 堆是动态分配的内存区域,用于存储程序在运行时动态分配的内存块。堆内存由程序员显式分配和释放,通常使用标准库函数(如
malloc()和free())来进行管理。堆内存的分配和释放可以在程序运行时动态发生,因此它的大小和生存期不容易预测。 -
栈(Stack): 栈用于存储函数的局部变量、函数参数和函数调用的返回地址。每当函数被调用时,一个新的栈帧(stack frame)会被创建,用于存储函数的上下文信息。当函数返回时,栈帧会被销毁。栈是一个后进先出(LIFO)的数据结构,通常由操作系统管理。
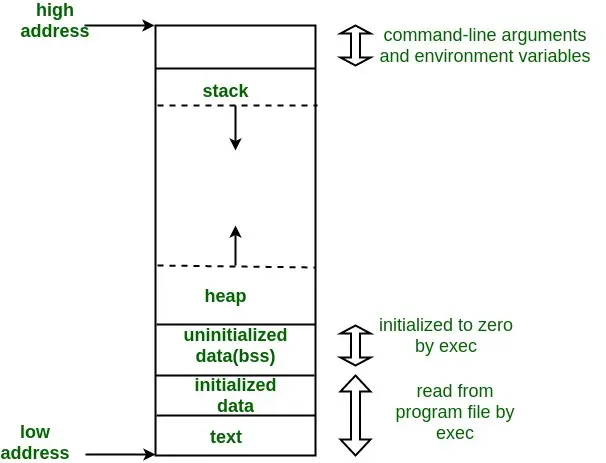
- 每个部分还有更加细致的划分,比如常量区和全局区。
- 前面列举的是程序运行的时候会被加载到内存中的部分。还有一些其他的段,在程序开发和调试期间很有用,比如:
- 符号表段(Symbol Table Section): 符号表是一个数据结构,它包含了程序中定义的符号(如变量名、函数名等)与其在可执行文件中的地址之间的映射关系。符号表通常位于可执行文件的一个独立段中,以便在调试和分析期间进行访问。它有助于调试器查找变量或函数的地址,以及生成堆栈跟踪信息。
- 调试信息段(Debug Information Section): 调试信息段包含了程序的调试信息,如源代码位置、变量名、数据结构的布局等。这些信息用于生成符号化的错误消息、断点设置和源代码级别的调试。调试信息通常位于可执行文件的一个单独段中,例如DWARF格式或COFF格式。
- 字符串表段(String Table Section): 字符串表段包含了可执行文件中使用的所有字符串,包括符号表中的符号名称、调试信息中的源代码文件路径等。这有助于减小可执行文件的大小并提高效率,因为它可以避免重复存储相同的字符串。
- 重定位表段(Relocation Table Section): 重定位表段包含了程序中需要在加载时进行动态链接的地址重定位信息。这些信息指示了在可执行文件中的哪些位置需要进行符号解析和地址重定位。重定位表在动态链接期间使用,以确保程序在不同的内存位置上正确运行。
查看各部分大小的命令:
root@CQUPTLEI:~/LinuxC/CLanguage# size time
text data bss dec hex filename
1603 600 8 2211 8a3 time
- text 表示代码段的大小。
- data 表示数据段的大小。
- bss 表示未初始化的数据段(BSS段)的大小。
- dec 表示十进制总大小。
- hex 表示十六进制总大小。
- filename 是程序的文件名。
另外对于运行的程序,可以使用pmap查看内存映射情况(即各个部分位于内存地址的哪个位置,大小如何)。
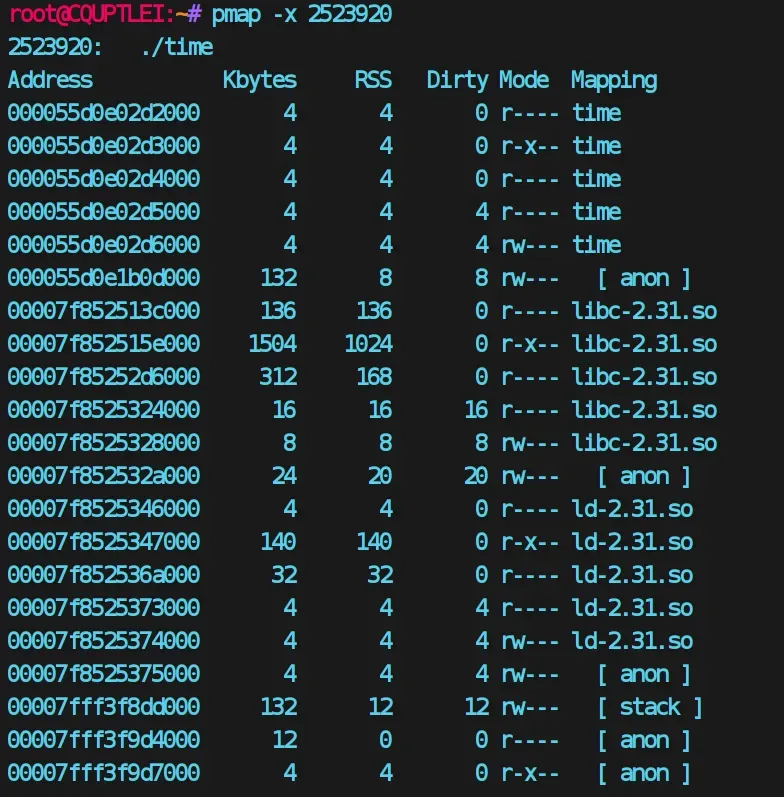
解释:
- 000055d0e02d2000 到 000055d0e02d6000 是程序的代码段和数据段,可执行和可读写。
- 000055d0e1b0d000 是程序的堆,可读写。
- 00007f852513c000 到 00007f852532a000 是共享的动态链接库(libc-2.31.so 和 ld-2.31.so)的内存映射,具有不同的权限和大小。
- 00007fff3f8dd000 到 00007fff3f9d7000 是进程的栈,可读写。
- ffffffffff600000 是内核的虚拟内存地址范围,通常不可执行。
通过地址高低、权限、占用内存大小来判断。也可以使用其他命令。
1.2 用户空间和内核空间
用户空间(User Space) 和 内核空间(Kernel Space) 是指操作系统中的两个不同的内存区域,用于存放不同类型的程序代码和数据,并具有不同的特权级别和访问权限。这两个空间在操作系统中的分隔是为了提高系统的安全性和稳定性。
以下是关于用户空间和内核空间的主要特点和区别:
用户空间(User Space):
-
应用程序执行区域: 用户空间是用于存放用户级别的应用程序代码和数据的区域。大多数应用程序的执行发生在用户空间。
-
特权级别低: 用户空间中的代码和数据运行在较低的特权级别下,通常是用户模式(
User Mode)或非特权模式。这意味着用户程序不能直接访问底层硬件资源或进行敏感的系统操作。 -
有限的权限: 用户空间中的程序对于系统资源(如硬件设备、内核数据结构等)的访问受到限制。程序必须通过系统调用来请求内核执行特权操作,例如文件操作、网络通信等。
-
错误隔离: 用户空间的程序通常不能直接影响整个系统的稳定性。如果一个用户空间的应用程序崩溃或出现错误,通常不会导致整个系统崩溃。
内核空间(Kernel Space):
-
操作系统核心区域: 内核空间是操作系统核心(内核)的执行区域,其中包含了操作系统的核心代码和数据结构。操作系统内核负责管理系统资源、进程调度、设备驱动程序等任务。
-
特权级别高: 内核空间中的代码和数据运行在较高的特权级别下,通常是内核模式(
Kernel Mode)或特权模式。这使得内核可以直接访问系统的底层硬件资源和进行特权操作。 -
无限的权限: 内核空间中的代码具有无限制的权限,可以执行任何操作系统功能,并且可以访问系统的所有资源。(当然了,并非所有硬件资源都可以无限访问,需要芯片厂商开放给你才行)
-
系统关键性: 内核空间中的代码对于整个系统的稳定性至关重要。内核必须设计得稳定且不容易受到用户空间程序的恶意或错误行为的干扰。
用户空间和内核空间的分隔是为了提高系统的安全性和稳定性。用户空间用于存放应用程序代码和数据,而内核空间包含操作系统内核的核心代码和数据。用户程序通过系统调用等接口来请求内核执行特权操作,以访问底层资源。这种分隔使得操作系统能够保护系统资源并隔离用户程序的错误,从而提高了系统的可靠性和安全性。
在传统的操作系统设计中,主要有两个关键的内存空间,即用户空间和内核空间,用于分离用户应用程序和操作系统内核的执行环境和权限。然而,一些特殊的操作系统或安全机制可能引入其他内存区域或权限级别。
以下是一些可能存在的其他内存区域或权限级别:
中断上下文(Interrupt Context): 中断上下文是操作系统内核在响应硬件中断时运行的上下文。这个上下文通常具有比用户空间更高的特权级别,因为内核需要能够处理硬件中断并采取适当的措施。中断上下文不同于用户空间和内核空间,因为它是由硬件事件触发的。
超级用户/特权级别(Supervisor/Privileged Mode): 一些操作系统或处理器体系结构可能支持多个特权级别,例如用户模式、内核模式和超级用户模式。超级用户模式通常具有更高的权限,可以执行特权操作,如修改页表或直接访问硬件寄存器。这种多级特权级别的设计可以增强操作系统的安全性和隔离性。
用户模式切换(User Mode Switch): 在多任务操作系统中,内核可能会在不同任务之间进行用户模式切换。这涉及到保存和恢复任务的上下文,以便在任务之间切换时能够保持执行状态。这种切换可能涉及到额外的内存区域来存储任务上下文。
内核模块(Kernel Module): 一些操作系统允许动态加载内核模块,这些模块是在内核空间中运行的,但它们的加载和卸载过程可能涉及到特殊的内存区域。
1.3 用户模式和内核模式
用户模式(User Mode)和内核模式(Kernel Mode)是操作系统和处理器体系结构中的两种不同特权级别或特权模式,它们用于控制程序对系统资源的访问和执行权限。
用户模式(User Mode):
-
较低特权级别: 用户模式是处理器的一种较低特权级别,通常用于执行普通用户应用程序。在用户模式中,应用程序的执行受到限制,不能直接访问底层硬件资源或执行特权操作。
-
受限制的系统资源访问: 应用程序在用户模式下运行时,其访问系统资源(如文件、设备、内存)受到操作系统的控制和限制。应用程序必须通过系统调用等接口来请求内核执行特权操作,以访问受保护的资源。
-
异常处理: 如果应用程序执行了非法或无效的操作,例如访问受保护的内存区域,处理器会生成异常,将控制权转移到内核模式下的操作系统内核,由内核处理异常。
内核模式(Kernel Mode):
-
较高特权级别: 内核模式是处理器的一种较高特权级别,通常用于执行操作系统内核的代码。在内核模式中,内核拥有最高的特权,可以直接访问和控制系统的底层硬件资源。
-
无限制的系统资源访问: 内核模式下的操作系统内核可以无限制地访问系统的各种资源,包括硬件设备、内存管理、中断处理等。内核模式允许执行特权指令,以完成各种系统管理任务。
-
异常处理和系统调用: 内核模式下的操作系统内核负责处理异常情况,如硬件故障、非法指令执行等。此外,内核模式下的操作系统内核还响应并执行系统调用,以满足用户程序的特权操作请求。
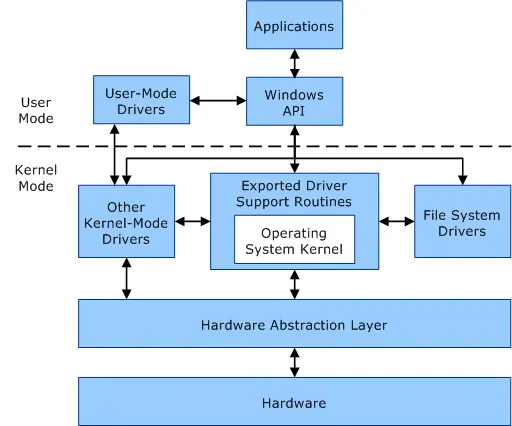
拿个微软的图看把:
二、内核调用-系统调用-C语言库函数
2.1 系统调用和内核调用
系统调用(System Call)和内核调用(Kernel Call)都是操作系统内核提供给用户空间程序的接口,用于访问操作系统核心功能的方法。它们允许应用程序执行需要特权级别或操作系统提供的服务,如文件操作、网络通信、进程管理等。
虽然它们有相似之处,但它们在一些方面有所不同。
系统调用(System Call):
-
用户空间和内核空间分离: 系统调用是用户空间和内核空间之间的接口。用户空间程序通过系统调用请求内核执行某些任务。
-
高层接口: 系统调用通常是高层次的接口,提供了相对较简单的、面向应用程序的方式来访问内核功能。例如,C库(libc)提供了许多系统调用的包装函数,以便程序员更容易地使用它们。
-
通常使用函数调用的方式: 系统调用通常通过函数调用的方式来触发,例如C语言中的
read()、write()、fork()等函数就是系统调用的例子。 -
具有安全性和权限控制: 系统调用是操作系统对用户空间的安全性和权限控制的重要门户。内核会验证用户是否有执行特定系统调用的权限,并确保用户程序不能直接访问内核的数据结构。
内核调用(Kernel Call):
-
更低级别的接口: 内核调用通常是更低级别的接口,允许用户程序直接调用内核的功能。这种调用可能涉及到内核内部数据结构和功能,因此需要更谨慎的使用。
-
通常使用汇编或特定编程语言: 内核调用通常不是以高级语言函数的形式提供,而是以底层的方式实现,可能需要使用汇编语言或特定的编程语言来进行调用。
-
较少的安全性和权限控制: 内核调用通常不提供像系统调用那样的安全性和权限控制层。用户程序可以更自由地调用内核的功能,但这也使得它们更容易破坏系统稳定性。
-
通常用于开发操作系统或内核模块: 内核调用通常被用于开发操作系统内核本身或内核模块。它们不是一般用户程序的主要接口。
总结:系统调用是用户空间程序与内核之间的标准接口,提供了高级别的、安全的方式来访问内核功能,而内核调用更低级别,通常用于开发操作系统或内核模块,直接调用内核功能,但需要更谨慎的处理。用户程序在编写时通常使用系统调用,而操作系统内核的开发者可能需要使用内核调用来开发操作系统本身的部分。
2.2 C语言库函数
系统调用、库函数和内核调用之间存在密切的关系,它们共同构成了操作系统和用户程序之间的接口和交互方式:
系统调用与库函数的关系:
- 系统调用是操作系统提供给用户程序的接口之一,它允许用户程序请求操作系统执行特权级别的任务,如文件操作、进程管理、网络通信等。
- 库函数是在用户空间中实现的高级别接口,它们通常封装了系统调用,提供更方便、更抽象的方式来使用操作系统功能。库函数通常包括对系统调用的封装,以及其他一些常用功能的实现。例如,C语言的标准库(libc)包含了许多库函数,它们实际上是建立在系统调用之上的。
- 用户程序通常首先调用库函数,而库函数可能在需要时调用系统调用来完成具体的操作。这种嵌套关系使得用户程序可以更轻松地访问和使用操作系统功能,而不必直接与系统调用交互。

一般来说,用户程序调用系统调用接口时,会产生一个中断或异常,处理器特权级别从用户模式切换到内核模式;一个系统调用对应一个系统调用号,内核通过特定的号码来调用相应的服务例程。一些列操作完成后,内核会将调用结果返回给用户程序,特权模式也会切回到用户模式。
三、Linux如何执行一个程序
简要图示:
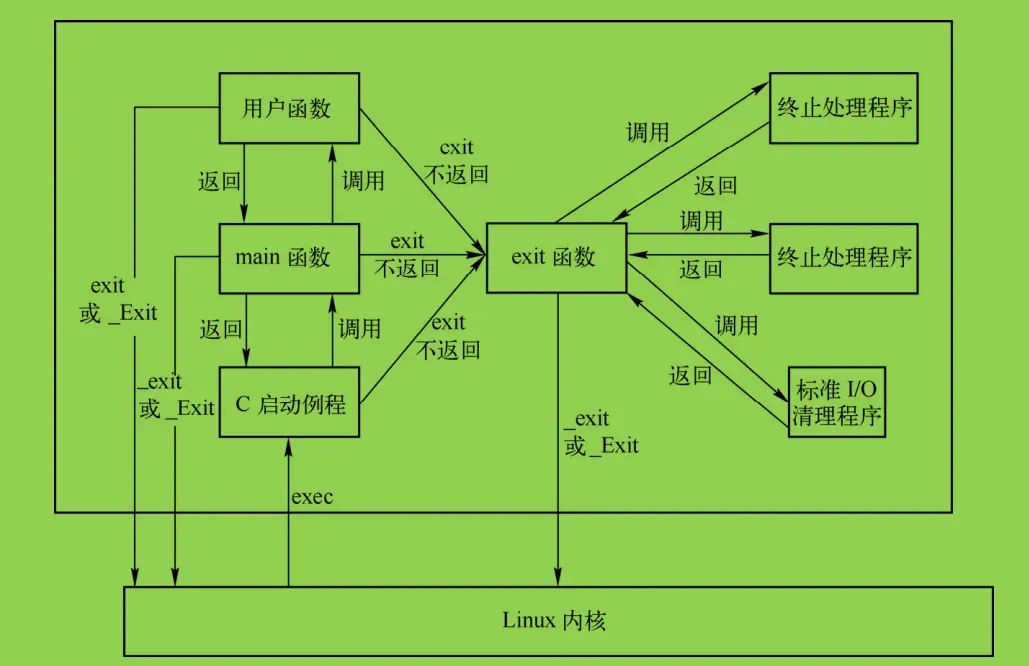
运行一个程序:
./ xxx
命令解析:首先,Shell会解析你输入的命令。在这里,
./xxx表示在当前目录下运行名为xxx的程序。程序查找:然后,Shell会在文件系统中查找你指定的程序。这里,它会在当前目录下查找名为
xxx的文件。权限检查:接着,Shell会检查你是否有执行该程序的权限。如果你没有执行权限,Shell将不会启动该程序。
创建进程:如果你有执行权限,Shell会通过调用
fork()函数创建一个新的进程来运行该程序。加载和执行:新创建的进程会加载程序的代码和数据到内存中,并开始执行。如果程序是动态链接的,那么在这个阶段,动态链接器(由程序头中的PT_INTERP指定)也会被加载到内存中,并负责处理如符号解析和重定位等任务。
执行main()函数:最后,新创建的进程开始执行程序的main函数。当main函数返回时,进程结束,资源被操作系统回收。
其中,创建一个新进程的过程主要涉及以下步骤:
-
调用fork()函数:
fork()函数会复制当前进程(称为父进程),创建一个新的进程(称为子进程)。子进程几乎是父进程(在这里指的是shell进程)的完全复制,包括程序计数器、CPU寄存器、打开文件描述符、信号控制设置等。 -
分配PID:每个进程在系统中都有一个唯一的进程标识符(PID)。新创建的子进程会被分配一个新的PID。
-
复制父进程的资源:子进程会继承父进程的资源,如打开文件、挂起信号等。这些资源是被复制的,而不是共享的。也就是说,父子进程并不共享这些资源。
-
返回PID:在父进程中,
fork()函数返回新创建子进程的PID。在子进程中,fork()函数返回0。这样,程序可以区分父进程和子进程。 -
执行子进程:如果调用
fork()后紧接着调用exec()函数,子进程就会替换成一个全新的程序,开始执行新程序的main函数。
在Linux中,一个进程有8种方式可以终止:
正常终止有5种方式:
- 从
main函数返回。 - 调用
exit函数。 - 调用
_exit或_Exit函数。 - 最后一个线程从其启动例程返回。
- 最后一个线程调用
pthread_exit。
异常终止有3种方式:
- 调用
abort函数。 - 接收到一个信号并终止。
- 最后一个线程对取消请求做出响应。
拓展说明:
exit()函数:
exit()函数是C语言的标准库函数,定义在<stdlib.h>头文件中。这个函数用于立即终止调用进程。任何属于该进程的打开的文件描述符都会被关闭,该进程的子进程由进程1继承。与return不同,exit是系统调用级别的,它表示了一个进程的结束。
在C语言程序中,exit()函数可以由任何需要终止程序的函数调用:
-
在
main函数中:当main函数执行完毕并准备返回时,会隐式地调用exit()函数。 -
在其他函数中:如果在主函数
main()或WinMain()之外的其他函数体内需要退出程序,也可以调用exit()函数。 -
错误处理:当程序遇到无法处理的错误情况时,可能会调用
exit()来立即终止程序。
_exit 和 _Exit :
-
_exit()函数是在<unistd.h>头文件中定义的。它是POSIX.1标准的一部分,因此在POSIX兼容的系统(如Linux)上可用。 -
_Exit()函数是在<stdlib.h>头文件中定义的。它是ISO C99标准的一部分,因此在支持C99或更高版本的系统上可用。 -
这两个函数都用于立即终止程序,不执行任何清理操作或刷新缓冲区。
abort函数:
abort()函数是C语言的一个标准库函数,定义在<stdlib.h>头文件中。这个函数的功能是以非正常的方式终止当前执行的程序。它不接受任何参数,也没有返回值。
与exit()函数不同,abort()函数会使程序立即终止,不会进行常规的清理工作,比如清理堆栈、释放内存等。当程序遇到无法恢复的错误条件时,可以调用abort()函数来立即终止程序。
以下是一个使用abort()函数的示例代码:
#include <stdio.h>
#include <stdlib.h>
int main() {
int value = 0;
printf("Enter an integer greater than zero: ");
scanf("%d", &value);
if (value <= 0) {
fprintf(stderr, "Invalid input. Program will terminate.\n");
abort();
}
printf("You entered: %d\n", value);
return 0;
}
在上述示例中,如果用户输入小于或等于零的整数,程序将打印一条错误消息并调用abort()函数来终止程序²。希望这个答案对你有所帮助!
程序异常退出的问题: 不做清理和不刷新缓冲区
-
数据丢失:如果缓冲区中的数据没有被写入到文件或设备中,那么这些数据可能会丢失。例如,如果你的程序在崩溃时没有刷新缓冲区,那么缓冲区中的数据将无法输出。
-
资源泄露:如果程序在终止时没有进行适当的清理工作,可能会导致资源泄露。例如,如果你的程序打开了一个文件但没有关闭它,那么这个文件描述符就会一直被占用,直到系统重启。
-
性能下降:不刷新缓冲区可能会影响程序的性能。例如,如果缓冲区满了但没有被刷新,那么程序可能需要等待直到有足够的空间来存储新的数据。
-
数据混乱:不刷新缓冲区可能会导致数据混乱。比如,发一个数据,666,还没有被读,又发一个数据,999,这时如果再读,就是666999了。
常见的例子是:端口被占用。
进程1:
在Unix和类Unix系统(如Linux)中,进程1通常是init进程(systemd)。init进程是系统启动后的第一个进程,由内核自动启动。它在系统启动后执行许多重要的任务,包括:
-
初始化系统:init进程负责启动和配置系统的各个部分。
-
创建其他进程:init进程可以启动其他的系统进程。
-
收养孤儿进程:当一个父进程结束,而它的子进程还在运行,这些子进程就成为了“孤儿”进程。这些孤儿进程将被init进程“收养”,也就是说,它们的父进程将变为init。
-
系统关机或重启:当你想要关机或重启系统时,这个请求会被发送给init进程,由它来完成关机或重启的操作。
文章出处登录后可见!