17年的老论文了,作为入门是可以的
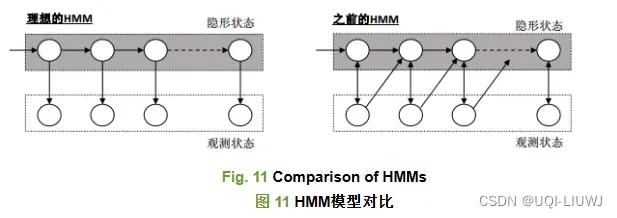
1 Intro
- GPS信号和实际的轨迹是有一段距离的
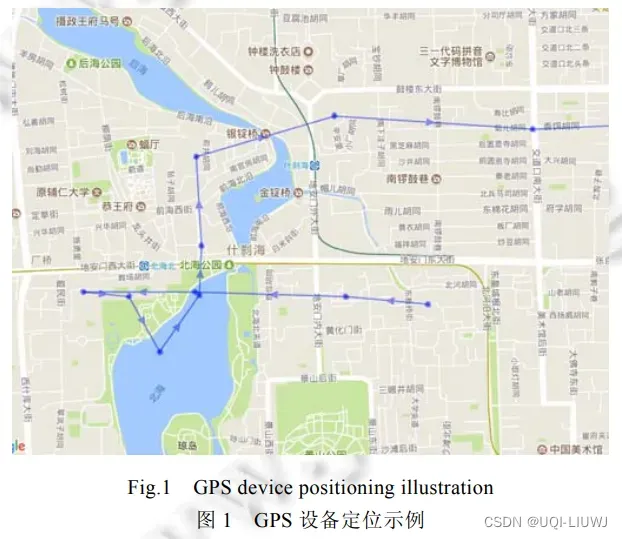
- 如果对GPS数据不做处理直接定位,那么位置会被定位到非道路的建筑、湖泊、公园中,这显然是不合理的
- ——>需要对GPS数据进行处理,使得其能较为准确地匹配到路网上
2 问题描述
2.1 GPS日志
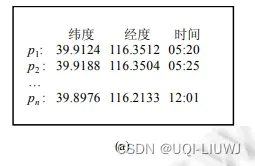
- 一系列GPS点的集合
- 每个GPS的点包括经度、维度、时间戳
2.2 GPS轨迹
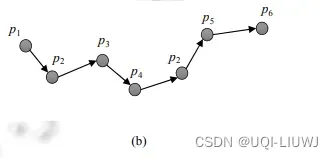
- 一条GPS轨迹T是一个GPS点的序列
- 一条轨迹任意两个相邻点之间的时间间隔不超过ΔT(一个阈值)
2.3 路段
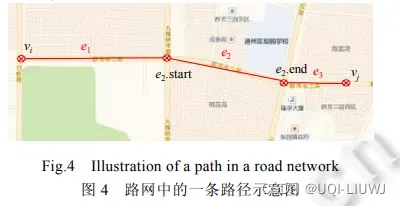
- 一个路段 e 是一条有向边,具有编号 e.id、行驶速度 e.v、长度 e.l、开始点 e.start、结束点 e.end 和中间点列表.
- 一条道路可以包含多个路段
2.4 路网
一个有向图 G(V,E)
2.5 路径
- 给定路网 G 中的两个顶点 vi,vj,一条路径 P 是始于 vi 止于 vj 的一组连接的路段
2.6 路网匹配
给定未加工的 GPS 轨迹 T 和路网 G(V,E),从 G 中寻找路径 P(实际路径匹配轨 迹 )
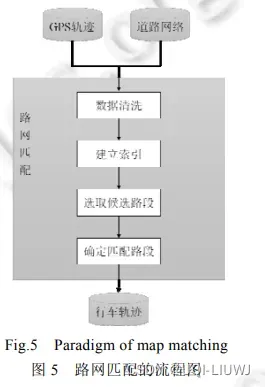
3 路网匹配算法分类
3.1 根据输入数据涉及的信息
3.1.1 几何匹配方法
- 仅利用时空道路网络的几何信息进行匹配(距离、角度、形状等)
- 不考虑路段间的连通性
3.1.1.1 总体的优缺点
- 优点
- 相对简单,易于实现
- 在定位系统没有较大误差的情况下匹配度较高
- 缺点
- 没有使用 GPS 采集点之间的联系、交通规则信息和道路的拓扑信息等——>准确率下降
- 一旦出现错误匹配 无法及时修正——>稳定性较差
- 虽然可以为密集的 GPS 轨迹提供良好的匹配,但如果是针对有噪声且稀疏的数据就不再适用.
3.1.1.2 分类
- 点到点匹配方法 (An introduction to map matching for personal navigation assistants)
- 方法介绍
- 首先计算 GPS 点与道路网络上每个节点的距离
- 然后将 GPS 点匹配到距离最近的节点上
- 优点
- 算法简单,容易实现,计算速度快
- 缺点
- 但受道路网络上节点密度及分布影响,容易造成错误匹配,实用性不强
- 方法介绍
- 点到线匹配方法 (Some map matching algorithrns for personal navigation assistants)
- 方法介绍
- 将道路网络中的所有路段都看作候选路段
- 首先计算 GPS 点到每个候选路段的投影距离
- 然后选择距 GPS 点最近的路段为匹配路段
- 相应的投影点就是匹配节点
- 优点
- 相比于点到点的匹配方案,准确度提高
- 缺点
- 没有考虑道路的拓扑结构和车辆的历史信息——>稳定性不好,在复杂路况下容易发生错误匹配
- 方法介绍
- 线到线匹配方法 (Road reduction filtering for GPS-GIS navigation)
- 方法介绍
- 首先获得车辆的历史轨迹曲线
- 然后与候选路段进行相似性比较
- 最终选择相似度最高的路段
- 优点
- 考虑车辆的历史信息,提高了匹配效率
- 缺点
- 但计算量大,受异常值影响较大
- 某个 GPS 点 的匹配错误可能会引起一系列的错误匹配
- 方法介绍
3.1.2 拓扑匹配方法
- 不仅要考虑 GPS 采集点与道路的距离,而且要考虑路网的拓扑连通性以及历史采集点——>匹配效率和准确性在一定程度上有所提高
- 缺点:仍然容易受到采集噪声和数据稀疏性的影响
3.1.2.1 分类
- 简单拓扑关系匹配方法(Matching planar maps)
- 方法介绍
- 运用车辆历史数据、轨迹之间关系和道路拓扑特征等 信息来限制采样点的候选匹配
- 优点
- 利用空间道路网——>提高匹配效率
- 缺点
- 容易受到采集噪声和数据稀疏性的影响
- 在复杂路况下容易发生错误匹配
- 方法介绍
- 加权拓扑匹配方法(A general map matching algorithm for transport telematics applications)
- 方法介绍
- 首先对轨迹方向、GPS 点到道路的距离以及相关性等进行加权计算,得到路段的权重
- 然后选择权重最大的路段为匹配路段
- 优点
- 相比于简单拓扑关系匹配方法,引入额外的参数和准则以提高匹配效率
- 缺点
- 仍然容易受到采集噪声和数据稀疏性的影响
- 仍然在复杂路况下容易发生错误匹配
- 方法介绍
3.1.3 概率匹配方法
- 给每个 GPS 样本点设定一个椭圆或矩形的置信区域
- 根据 GPS 的点和在置信区域内的位置之间的距离获得概率值
- 根据概率值的大小来决定最佳匹配路径
3.1.3.1 缺点
- 大多数基于概率信息算法都涉及公式推导,不容易理解,实现起来比较困难
- 算法计算开销较大,匹配准确性很低
3.1.3.2 分类
- 置信区间匹配方法 (Map matching integrity using multi-sensor fusion and multi-hypothesis road tracking.)
- 方法介绍
- 首先在置信区域内选出多条路段加入到候选路段集中
- 然后对每条候选路段都计算出一个得分
- 最终选择得分最高的路段作为匹配路段
- 优点
- 即使某个 GPS 点匹配错误也不会对后续匹配产生太大影响
- 缺点
- 也降低了路网匹配程序的执行速度
- 方法介绍
- 新型概率匹配方法(Map-Matching in complex urban road networks.)
- 方法介绍
- 在道路交叉口处设置一个椭圆或矩形的置信区域
- 通过一些基于经验性研究准则来检测车辆在道路交叉口的转弯动作
- 优点
- 计算速度较快,稳定性较好,对识别车辆转弯很有效,即使车辆低速运行时也能正确匹配
- 方法介绍
3.1.4 其他
- 模糊逻辑方法 (A high accuracy fuzzy logic based map matching algorithm for road transport.)
- 贝叶斯推断(Development of a map matching method using the multiple hypothesis technique.)
- HMM等
- 卡尔曼滤波(Fusion of map and sensor data in a modern car navigation system.)
- 稳定性较高,特别是在交叉路口.
- 但是由于没有充分考虑车辆信息和路网信息,匹配最初阶段效果并不理想
3.2 根据考虑的采样点的范围
3.2.1 局部/增量方法
- 利用当前 GPS 轨迹点的局部特征来进行路网匹配.
- 算法使用贪心策略,从已经匹配好的解决方案中不断延伸,得到最终的全局解
3.2.1.1 特点
- 优点
- 计算速度快、实时性强——>经常用于有在线需求的应用
- 当采样速率较高时(比如 2s~5s), 能够获得良好的匹配效果
- 缺点
- 随着采样率的降低,局部/增量算法将呈现“弧跳”现象,造成精度的显著降低(57)
- 只考虑当前位置,相邻点的相关性被完全忽略,结果受到测量误差影响很大——>准确性普 遍较低.
3.2.1.2 分类
- Matching GPS observations to locations on a digital map
- 方法介绍
- 使用距离相似度和方向相似度组合来评价候选边
- 复杂度
- O(n)
- 特点
- 除了位置样本外,该方法假设预期行驶路线没有任何进一步知识,而且也不使用任何速度信息
- 方法介绍
- Addressing the need for map-matching speed: Localizing global curve-matching algorithms.
- 方法介绍
- “自适应裁剪”,将轨迹分段,采用 Dijkstra 算法在两个采样点之间构建最短路径
- 复杂度
- ܱO(mnlogm),m 是路网的边 数,n 是采样点个数
- 特点
- 增量算法快,质量低;全局算法慢, 质量好.——>这种思路可以达到二者的平衡,
- 方法介绍
- Segment-Based map matching
- 方法介绍
- 引入基于分段的匹配算法
- 给不同采样点分配置信度值.先匹配高置信度分段,然后使用之前匹配的边来匹配低置信度分段
- 复杂度
- O(mlogm+mlog|G|+m|C|S),
- S 是调用相似度函数所需要的时间
- m 是采样点个 数
- C 是候选结果数
- |G|表 示地图的大小
- O(mlogm+mlog|G|+m|C|S),
- 特点
- 采样率很高时,执行速度快且效果好
- 采样率低的话,两个采样点之间断了联系则很难匹配——>精度显著下降
- 方法介绍
3.2.2 全局算法
- 考虑整个采样轨迹
- 从路网中找到一条与其最接近的匹配路径
- 大多数全局路网匹配算法使 用“弗雷歇距离”或其变体来测量采样轨迹和匹配路径的相似度 算法笔记:Frechet距离度量_fréchet距离_UQI-LIUWJ的博客-CSDN博客
3.2.2.1 特点
- 优点
- 与局部/增量算法相比,全局算法更准确
- 对采样率降低表现出更大的健壮性
- 能够较好地处理长采样间隔情况下的路网匹配问题
- 缺点
- 计算成本较高
- 需要整个行驶轨迹的信息,所以通常适用于离线任务(例如在所有轨迹产生后,挖掘频繁 的轨迹模式)
3.2.2.2 分类
- On map-matching vehicle tracking data
- 方法介绍
- 提出两种全局算法:
- 一种使用弗雷歇距离来衡量 GPS 轨迹和候选路段序 、列的匹配度,旨在最小化弗雷歇距离;
- 另一种扩展上述算法,用弱弗雷歇距离(weak-Fréchet-distance)来减少异常值的影响
- 提出两种全局算法:
- 复杂度
- m 是路 网的边数
- n 是采样点 个数
- 特点
- 准确率提高
- 没有考虑轨迹中的时间/速度信息
- 方法介绍
- Map-Matching for low-sampling-rate GPS trajectories
- 方法介绍
- 将相邻时刻轨迹点的候选匹配路段构建成候选匹配图
- 从构建出的候选匹配图中求解并搜寻一条最佳匹配路径——>该路径即最终匹配结果
- 复杂度
- n 是轨迹点个数
- m 是路网路段数
- k 是每个轨迹点候选点个数
- 方法介绍
3.3 根据采样频率
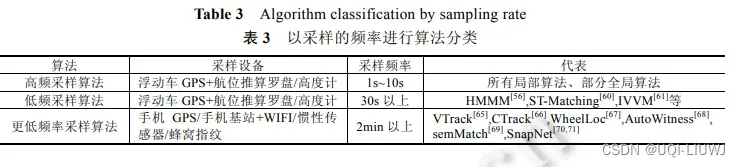
4 基于HMM的路网匹配
机器学习笔记&Python笔记:HMM(隐马尔科夫模型)_UQI-LIUWJ的博客-CSDN博客
4.1 HMM+路网匹配
4.1.1 概念对应
- 观测状态——从 GPS 设备中得到的位置信息(经度、纬度)
- 隐藏状态——拥有 GPS 设备的物体(车、人等)实际所在的位置
- 观测状态概率(输出概率)——观测的 GPS 样本点离候选路段越近,这个样本点在这个路段上的概率就越大.
- 状态转移概率
- ——前后两个 GPS 样本点的距离越近,状态转移概率越大
- ——(或者)真实路段上的前后两个点之间距离与 GPS 观测的前后两个样本点之间距离越接近,状态转移概率越大.
4.1.2 主要思路
- 对于每一个 GPS 轨迹点:
- 首先确定一组候选路段,每个候选路段被表示为马尔可夫链中的隐藏状态(顶点),并具有观测状态概率(输出概率)
- 输出概率描述GPS 点与候选路段匹配的可能性.
- 如果GPS 点非常接近某个路段,就给这个路段指定一个较高的输出概率值
- 然后为马尔可夫链中连接每一对相邻顶点的边计算权重(即状态转移概率)
- 使用维特比算法(或其他解HMM的方法)得到最大似然路径
- 首先确定一组候选路段,每个候选路段被表示为马尔可夫链中的隐藏状态(顶点),并具有观测状态概率(输出概率)
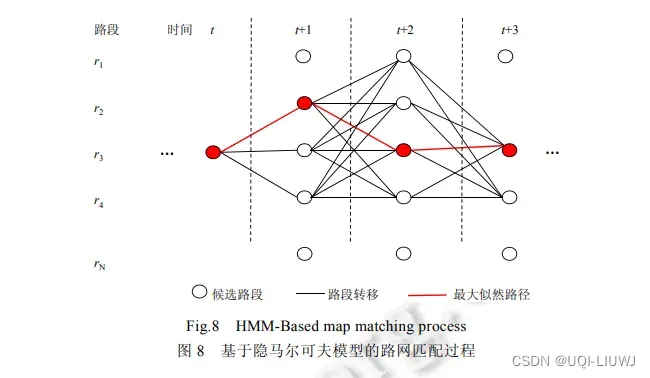
4.2 基于HMM的路网匹配算法举例
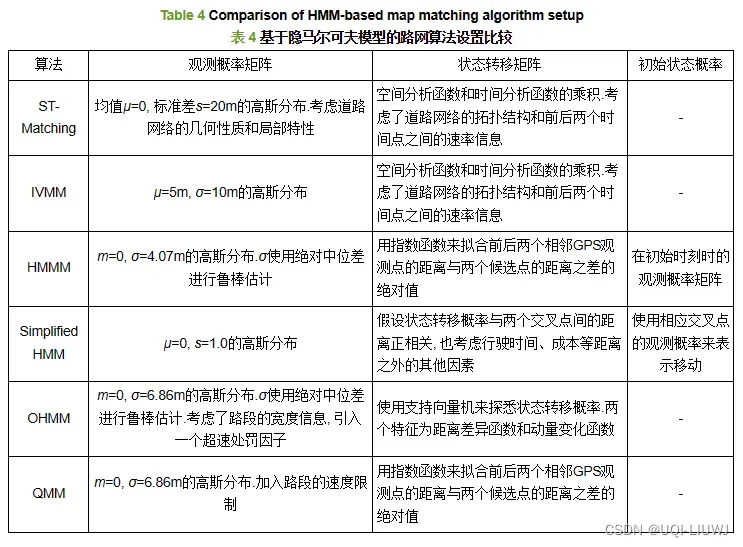
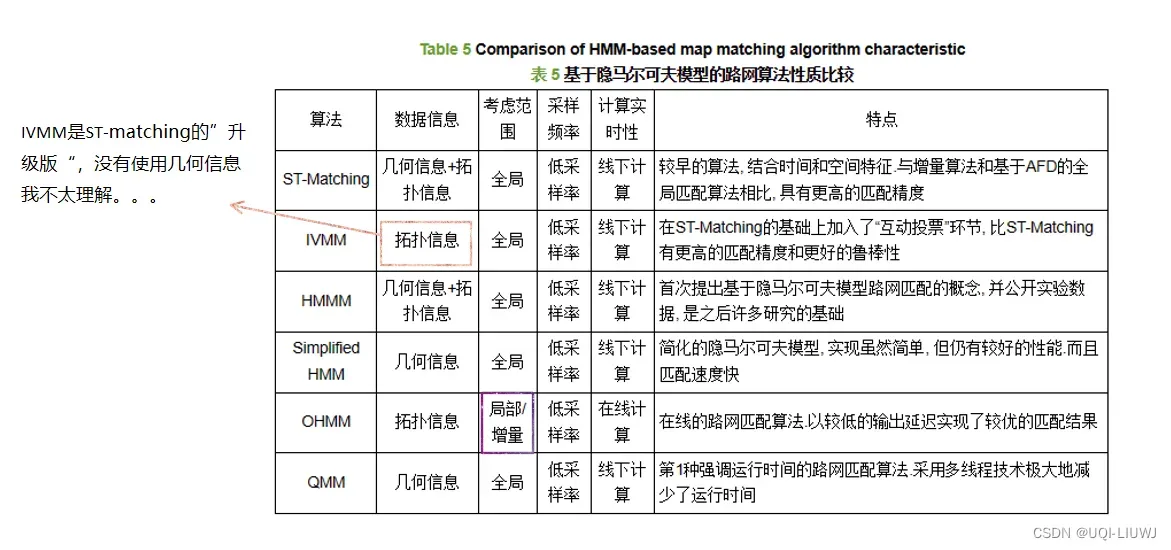
4.2.1 ST-matching
论文笔记:Map-Matching for low-sampling-rate GPS trajectories(ST-matching)_UQI-LIUWJ的博客-CSDN博客
4.2.2 IVMM (interactive-voting based map matching algorithm)
论文笔记:An Interactive-Voting Based Map Matching Algorithm_UQI-LIUWJ的博客-CSDN博客
- ST-Matching 在匹配路网时,会把 GPS 点对应到距离较近的路段上,并不考虑其相邻点的关系,所以会出现锯齿形的线路
- IVMM 的提出,就是为了“拉直”不匹配的路段,使其更适合地面真实路径
4.2.3 HMMM(hidden markov model map matching through noise and sparseness)
和St-matching很相似,只有少许的不同
论文笔记:Hidden Markov Map MatchingThrough Noise and Sparseness_UQI-LIUWJ的博客-CSDN博客
4.2.4 Simplified HMM
Development of map matching algorithm for low frequency probe data partC2012
- 4.2.1~4.2.3的方法并不是完全的HMM,因为在计算转移概率的时候,不仅候选点ci和cj的距离需要考虑,观测点oi和oj也需要考虑
- ——>这篇论文将之前的HMM模型简化,在计算状态转移概率时不考虑观测点之间的信息
- 观测概率矩阵还是和ST-matching的一样
- 状态转移矩阵变成
- c是常数
- dij是两个candidate之间的距离
- Simplified HMM算法按照理想模型设定了状态转移概率公式,
- 错误率比HMMM算法略大, 说明变种HMM更接近现实路网匹配
- 但Simplified HMM算法的匹配效率提高了很多, 约为前者的2倍
- 该算法实现更为简单, 且在处理低频采样的GPS轨迹时仍有较好的性能
4.2.5 OHMM(online map-matching based on hidden Markov model)
- 观测概率矩阵:
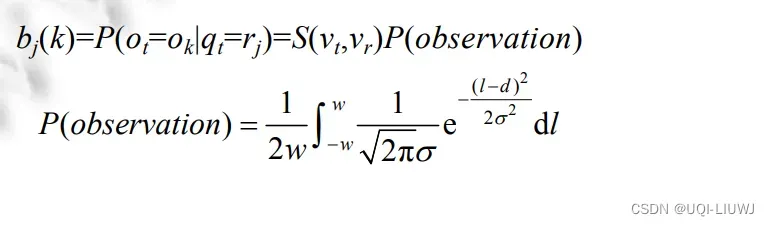
- 这里的P(observation)考虑了路段的宽度信息
- w表示路段宽度
- d是GPS样本点和路段之间的距离
- S(vt,vr)是超速处罚因子
- 它是基于这样的假设——驾驶员不太可能在很大程度上超过速度限制
- 目的是帮助区分从同一路口分叉出的可能具有不同速度限制的紧密间隔的平行道路
- vt是t时刻的记录速度, vr是路段r的速度限制
- 如果遵守了速度限制, 那么max(0, vt–vr)=0,此时S(vt, vr)=1,不起作用
- 这里的P(observation)考虑了路段的宽度信息
- 状态转移矩阵
- 和其他不同的是(之前的算法都是先验第选择一个模型),这里使用了SVM来辅助计算转移状态矩阵
- 优点是提供了一个数据驱动的框架, 用于集成多个转移评分函数
- 论文中设计了两个评分函数(可以更多,评分函数的个数就是SVM每个元素的维度)
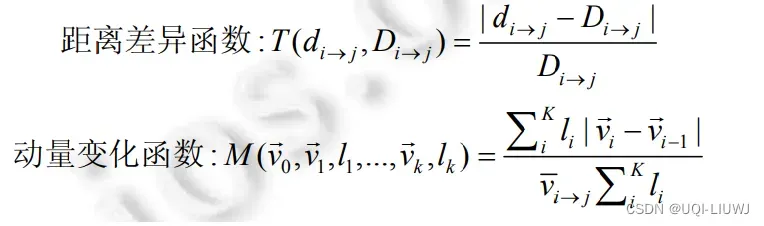
- 对距离差异函数,
是从i行驶到j时,最有可能的路径,
是
- d是两个时刻之间以平均速度行驶的距离
- 如果
- 动量变化函数测量车辆在
- v是在
- 动量变化函数可以描述为平滑因子来惩罚一些不可行的转换, 比如有很多急转弯
- v是在
- 对距离差异函数,
- 这两个函数计算出来的都只是一个特征, 然后使用被标记为正确或不正确转换的实例,训练SVM分类器
- 特征向量由上述两个评分函数给出的分数组成
- 使用这种分类方法, 转移概率就是输入的分数组合属于“正确转换”类的概率
- 和其他不同的是(之前的算法都是先验第选择一个模型),这里使用了SVM来辅助计算转移状态矩阵
4.2.6 QMM(quick map matching using multi-core CPUs)
Quick map matching using multi-core CPUs 2012 ACM-GIS
- 第1个强调运行时间的路网匹配算法
- 算法设计在多核CPU上运行, 因为路段的处理可以在建立索引时彼此分离, 并且每个样本轨迹点在匹配时相互独立.
- 算法应用多线程技术极大地减少了运行时间
- 在观测概率矩阵中,QMM考虑了侧路问题
- 基于车辆更可能在具有较高速度约束的主要道路上行驶而不是侧路行驶的假设, 在计算观测概率时加入路段的速度限制Vr
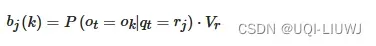
- 速度大的主路,输出概率搞
- 基于车辆更可能在具有较高速度约束的主要道路上行驶而不是侧路行驶的假设, 在计算观测概率时加入路段的速度限制Vr
4.2.7 总结
4.2.8 基于HMM的手机轨迹路网匹配算法
- 手机数据一般非常稀疏且噪声较大
- SnapNet系统
- 使用增量HMM算法为具有噪声和稀疏性特征的粗粒度蜂窝数据提供实时地图匹配
- 运用一系列的过滤器和一些启发式方法来减少噪声
- 利用插补解决数据稀疏问题
- Accurate and efficient map matching for challenging environments. Sigspatial 2014
- Accurate real-time map matching for challenging environments. IEEE Trans. on Intelligent Transportation Systems, 2017
- Real-Time large-scale map matching using mobile phone data 2017 TKDE
- 总结并比较了一些利用手机数据进行路网匹配的方法
- 提出了一种基于自适应HMM的模型,
- 使用大量移动数据来学习模型参数,
- 利用数据的稀疏性来提供实时快速维特比处理,
- 将各个手机轨迹映射到道路段
- 该模型首次单独使用手机大数据进行细粒度路网匹配.
- SnapNet系统
5 实验
5.1 数据集
5.1.1 合成数据
- ST-Matching使用
- 首先随机选择两个顶点的道路网络, 并计算它们之间最短的k条路径
- 然后随机从k条路径中选择一个轨迹作为Ground Truth, 记为G:e1, e2, e3, …, en
- 其背后的动机是:移动物体通常遵循从源到目的地的方向, 但不一定严格遵循最短路径
- 从G中每k‘段选择一个路段, 比如选择e1, e1+k‘, …, e1+mk‘
- 可以通过改变k‘的值来实现抽样率的调整
5.1.2 真实数据
- 北京数据
- ST-Matching算法和IVVM算法使用
- 以人们标记的真实路径数据作为ground truth
- ST-Matching算法和IVVM算法使用
- 西雅图GPS数据
- Microsoft Research – Emerging Technology, Computer, and Software Research
- 行驶距离为80km, 包含7 531个GPS采样点
- HMMM和Simplified HMM算法使用
- 新加坡数据
- OHMM算法使用
- 在新加坡的4条公交线路上收集的ground truth数据来评估算法的性能
- 选择了4条涵盖新加坡农村和城市地区的路线
- 农村路线的转弯次数较少, 主要由高速公路等直线路线组成
- 城市路线除了大量分岔路外, 还覆盖着高层建筑密集的城市街区
- 竞赛数据
- QMM算法采用
- 2012年ACM SIGSPATIAL Cup(http://depts.washington.edu/giscup/home)的训练数据
- 华盛顿州路网信息的简化版本
5.2 评估标准
| 算法 | 评估标准 |
| ST-matching |  |
| IVMM |  |
| HMMM | 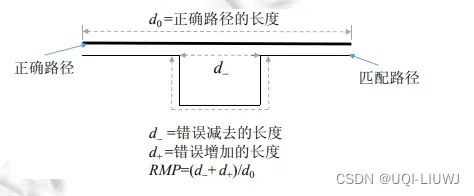 |
| QMM |  |
5.3 算法参数
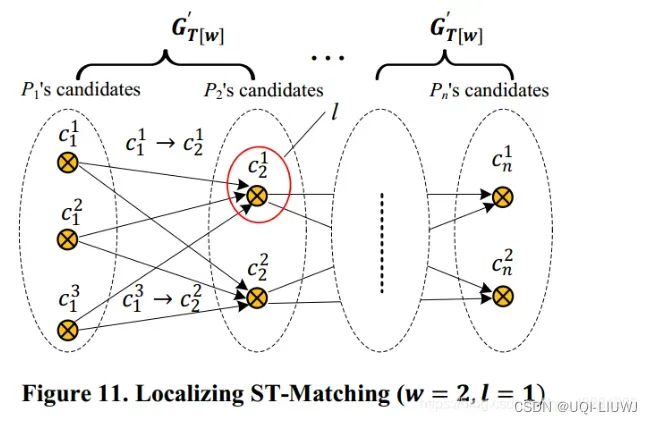
5.3.1 窗口
- 大多数现有的增量/在线算法、轨迹具有太多点的全局算法,往往使用滑动窗口策略
- 滑动窗口方法简单地 将轨迹划分为固定大小的输入序列,并且独立地处理它们.
- 固定滑动窗口(fixed sliding window,FSW)
- 将轨迹分割为窗口可以减少平均延迟并节省在线处理的存储空间,但不一定加快总体处理时 间,因为算法中花费最大的部分是最短路径计算
- 为了降低计算复杂度,算法试探性地保留具有top- l 个分数的 候选点,从而减少下一个采样点需要计算的最短路径数量
- 当 l=1 时,算法退化成增量算法
- 可变滑动窗口(variable sliding window,VSW)
- 滑动窗口的大小可以根据状态空间的 结构而变化
5.3.2 HMM中断
- 基于隐马尔可夫模型路网匹配算法在实际应用中可能会出现中断的情况——从一个时间点到下一个时间点 的所有转移概率为 0
- 出现中断的原因可能有:
- 路线本地化
- 在选择某个 GPS 点的候选路段时,为了避免不合理的计算量,一般会忽略距离 GPS 点超过 一定距离的路段,而不将它们添加到 HMM 里面
- 这可能会导致在特定时间中没有匹配候选.
- 当车辆在未标记在地图上的道路上行驶时,或者经历特别高的噪声时(比如当车辆进入隧道时),可能出现这种情况
- 低概率路线
- 当路线变得迂回时,对于该路线上的任何两个采样点之间的最短路径距离可能远大于它 们之间的欧式距离.
- 在这种情况下,对应于该路线的转移概率将变得非常小,这将触发 HMM 中断
- 路线本地化
- 由于上述的简化限制了将被考虑的匹配候选路线的数量,可能会找不到通过 HMM 的完整路径
- ——>这就导致了HMM中欧段
- HMM 中断发生的频率越高,匹配算法的效率就越低
- 解决方法:
- Hidden Markov map matching through noise and sparseness 2009 ACM-GIS
- 在时间t和t+1之间检测到中断时, 从模型中移除观测点ot和ot+1, 并检查中断是否已经愈合.
- 如果t-1和t+2的测量点在HMM中重新连接, 则中断愈合;
- 否则, 继续去除中断任一侧上的点, 直到中断愈合或中断超过180s.
- 如果中断超过180s, 就将数据拆分为前后两个单独的行程, 并分别对每个行程进行路网匹配
- 在时间t和t+1之间检测到中断时, 从模型中移除观测点ot和ot+1, 并检查中断是否已经愈合.
- On-Line viterbi algorithm and its relationship to random walks
- 适当地扩大参数β, 可以有效地减少中断情况
- 但是对匹配精度具有不可估量的影响
- Hidden Markov map matching through noise and sparseness 2009 ACM-GIS
文章出处登录后可见!
已经登录?立即刷新