0 提纲
- 现象与原因
- 非平衡数据处理方法概览
- 数据预处理层面
- 特征层
- 算法层面
1 现象与原因
非平衡数据分类问题:在网络信息安全问题中,诸如恶意软件检测、SQL注入、不良信息检测等许多问题都可以归结为机器学习分类问题。这类机器学习应用问题中,普遍存在非平衡数据的现象。
产生的原因:
- 攻击者的理性特征使得攻击样本不会大规模出现;
- 警惕性高的攻击者,会经常变换攻击方式避免被防御方检测出来。
非平衡数据对各种分类器的影响:
NN
- Bayes
- 决策树
- Logistic回归
当用于非平衡数据分类时,为了最大化整个分类系统的分类精度,必然会使得分类模型偏向于多数类,从而造成少数类的分类准确性低。
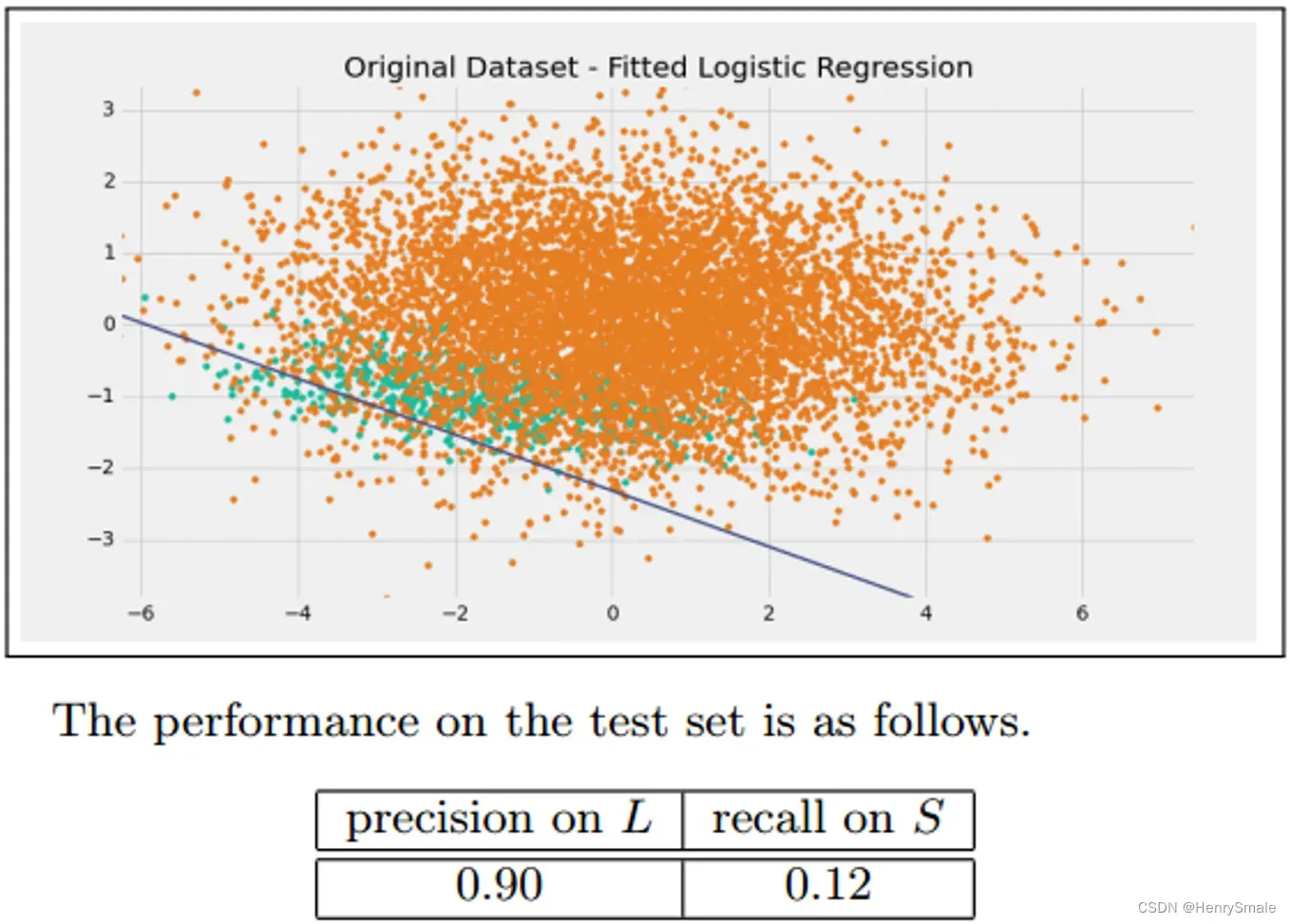
2 非平衡数据处理方法概览
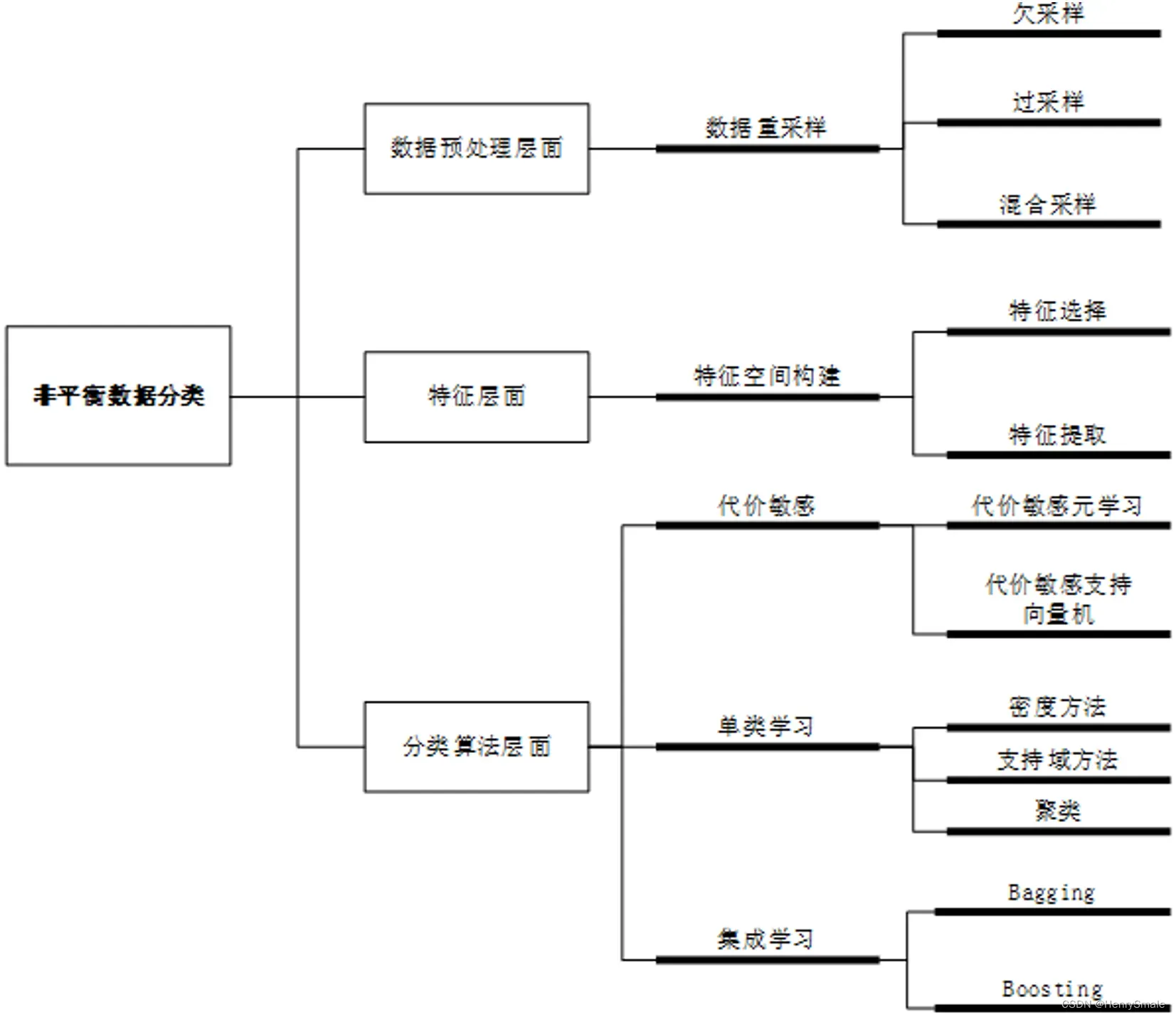
2.1 数据预处理层面
保证样本分布不变的情况下,改变训练集中每个类的样本数量,降低非平衡程度。
- 欠采样:减少多数类的样本数量;
- 过采样:提升少数类的样本数量;
- 混合采样:对多数类和少数类分别执行欠采样和过采样。
2.2 特征层面
虽然样本数量少,但可能在某些特征子空间中,能有效区分少数类样本和多数类样本。利用特征选择或特征提取来确定子空间的构成。
主要特征选择或特征提取有:
- 信息增益:基于信息熵来计算,它表示信息消除不确定性的程度,可以通过信息增益的大小为变量排序进行特征选择;
- 卡方统计:留取
- 互信息:考虑每个特征和类别之间的互信息
,根据互信息的大小对特征 排序,然后选择最前面的
- 主成分分析:PCA的思想是将
维特征映射到
),这
维特征;
- 深度神经网络:也是一种特征提取方法,当少数类样本比较多的时候,也可以考虑使用。
2.3 分类算法层面
虽然采样方法在一些数据集上取得了不错的效果,但欠采样容易剔除重要样本,过采样容易导致过学习,因此,采样方法调整非平衡数据的学习能力十分有限。
传统分类方法通常假设不同类别的样本分布均衡,并且错分代价相等,这种假设并不适合于非平衡数据的情况。因此,在分类模型与算法层面,改变假设前提,设计新的代价函数,提升对少数类样本的识别准确率。
改变代价函数就涉及到代价敏感学习,此外,单类学习和集成学习都可用来解决非平衡分类问题。
3 数据预处理层面
3.1 欠采样
欠抽样方法通过减少多数类样本来提高少数类的分类性能。
常见的欠采样方法有随机欠采样、启发式欠采样等。
- 随机欠采样通过随机地去掉一些多数类样本来减小多数类的规模,缺点是会丢失多数类的一些重要信息,不能够充分利用已有的信息。
- 启发式欠采样基本出发点是保留重要样本、有代表性的样本,而这些样本的选择是基于若干启发式规则。经典的欠采样方法是邻域清理(NCL,Neighborhood cleaning rule)和Tome links法,其中NCL包含ENN,典型的有以下若干种。
3.1.1 编辑最近邻规则Edited Nearest Neighbor (ENN)
对于多数类的一个样本,如果其大部分近邻样本都跟它自己本身的类别不一样,就将该样本删除。
也可以从少数类的角度来处理:对于少数类的一个样本,如果其大部分近邻样本都是少数类,则将其多数类的近邻删除。
3.1.2 浓缩最近邻规则Condensed Nearest Neighbor (CNN)
在训练集中随机选择一个样本 ,找到距离这个样本
最近的同类样本
和非同类样本
,然后计算
与
的距离和
与
的距离,如果符合:
那么认为这个样本是我们所需要的用于训练模型的样本。如果不符合上式,则将这样的样本剔除掉。
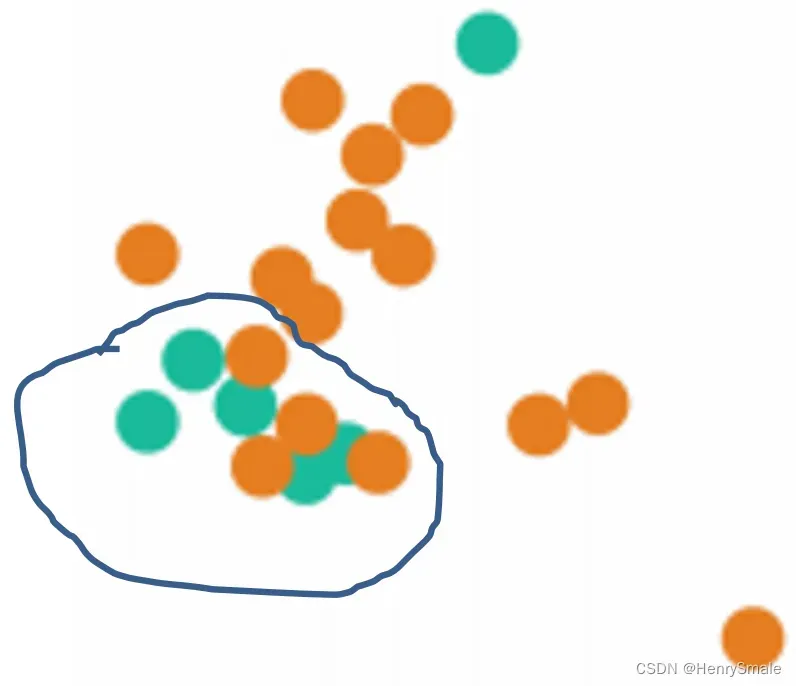
3.1.3 近似缺失方法Near Miss (NM)
NearMiss 作为 随机欠采样 的改进,它主要为了缓解随机欠采样中的信息丢失问题,通过启发式的规则从多数类样本中选择具有代表性的样本进行训练,利用距离远近剔除多数类样本的一类方法,主要有以下三种:
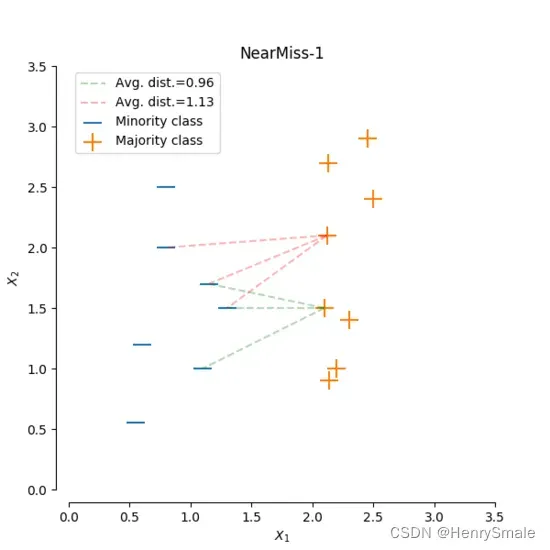
- NearMiss-1:对于每个多数类样本,计算与每个少数类样本的距离,选择最近的
如下图, “ + ”代表多数类,“ – ”代表少数类,我们取 ,计算多数类中的两个样本的距离。通过计算发现,绿线的距离比红线的距离小,也就是说绿线对应的样本到 最近的 3 个少数类样本 的距离比红线对应的样本小,因此我们选择绿线对应的多数类样本。
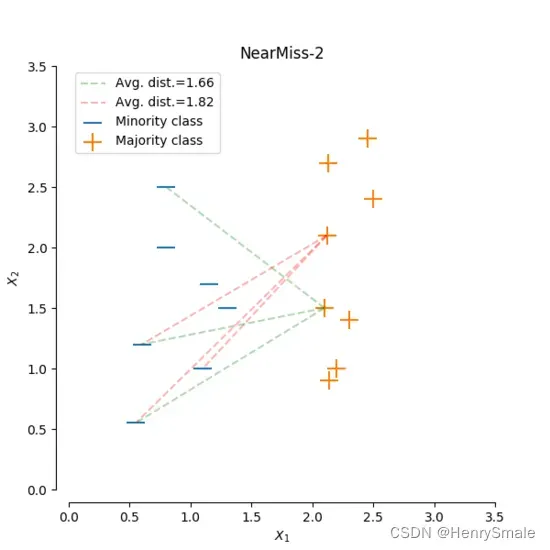
- NearMiss-2 :对于每个多数类样本,计算与每个少数类样本的距离,选择最远的
同样,我们取 ,计算多数类中的两个样本的距离。通过计算发现,绿线的距离比红线的距离小,即绿线对应的样本到 最远的 3 个少数类样本 的距离比红线对应的样本小,因此我们选择绿线对应的多数类样本。
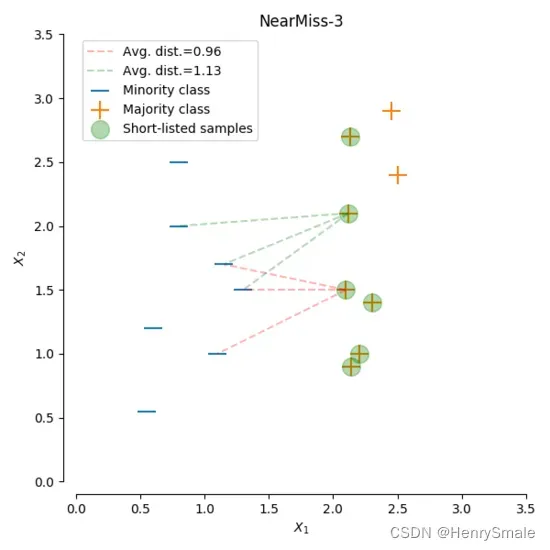
- NearMiss-3:一个两段式的算法。 首先,对于每一个少数类样本, 保留距离最近的
个多数类样本;接着对于保留的多数类样本,计算与每个少数类样本的距离,选择最近的
如下图,其中我们取 ,首先计算得到保留的多数类样本( Short-listed samples ,绿圈),然后在这些样本中,计算与每个少数类样本的距离,选择最近的 3 个少数类样本并计算这 3 个少数类样本的平均距离,保留平均距离最大的多数类样本。
- NearMiss-1 与 NearMiss-2 方法仅一字之差,但是造成的结果却大不相同;
- NearMiss-1 使用的是最近的
- 而 NearMiss-2 使用的则是最远的
- 由于 NearMiss-1 使用的只是局部样本的信息,容易受到噪声的影响。
- NearMiss-3 因为在前期进行了多数类样本保留,对于噪声点具有一定的鲁棒性。
3.1.4 Tomek Links方法
如果有两个不同类别的样本,它们的最近邻都是对方,也就是A的最近邻是B,B的最近邻是A,那么A,B就是Tomek link。
数学语言:两个不同类别的样本点和
,它们之间的距离表示为
,如果不存在第三个样本点
使得
或者
成立,则称
为一个Tomek link。
3.2 过采样
3.2.1 SMOTE
该算法只是简单在两个近邻之间进行插值采样。
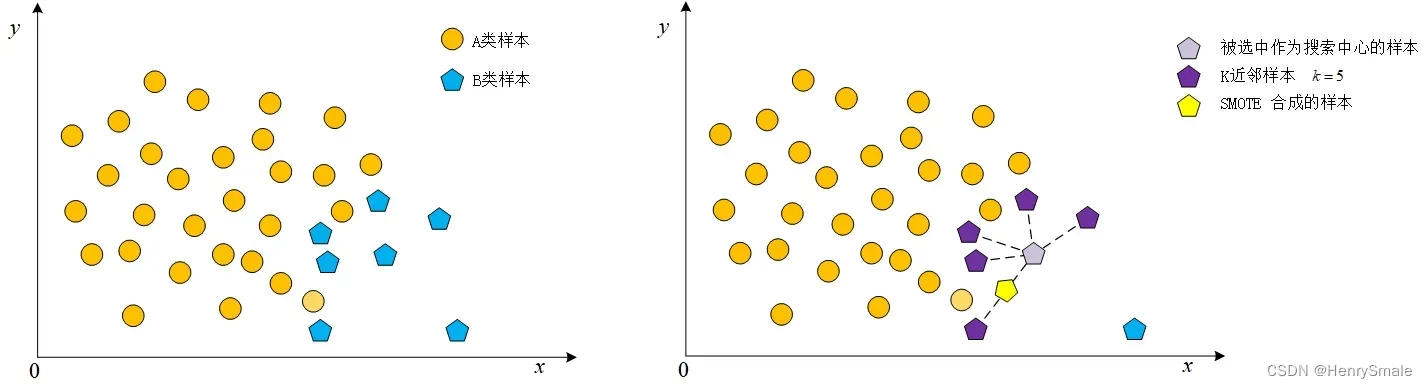
- 随机选择一个五边形样本点
为中心;
- 搜索离它距离最近的
- 随机选择一个被搜索到的样本点
,用样本点
- 通过两个样本点利用线性代数的知识就可以生成一个新的样本:
优点:简单
缺点:
- 如果选取的少数类样本周围都是少数类样本,则新合成的样本不会提供太多有用信息。就像SVM中远离边界的点对决策边界影响不大;
- 如果选取的少数类样本周围都是多数类样本,这类的样本可能是噪声,则新合成的样本会与周围的多数类样本产生大部分重叠,导致分类困难。
3.2.2 Borderline-SMOTE1
由于原始SMOTE算法的对所有少数类样本都是一视同仁的,我们希望新合成的少数类样本能处于两个类别的边界附近,因为在实际建模过程中那些处于边界位置的样本更容易被错分,因此利用边界位置的样本信息产生新样本可以给模型带来更大的体征,能提供足够的信息用以分类,即Borderline SMOTE算法做的事情。
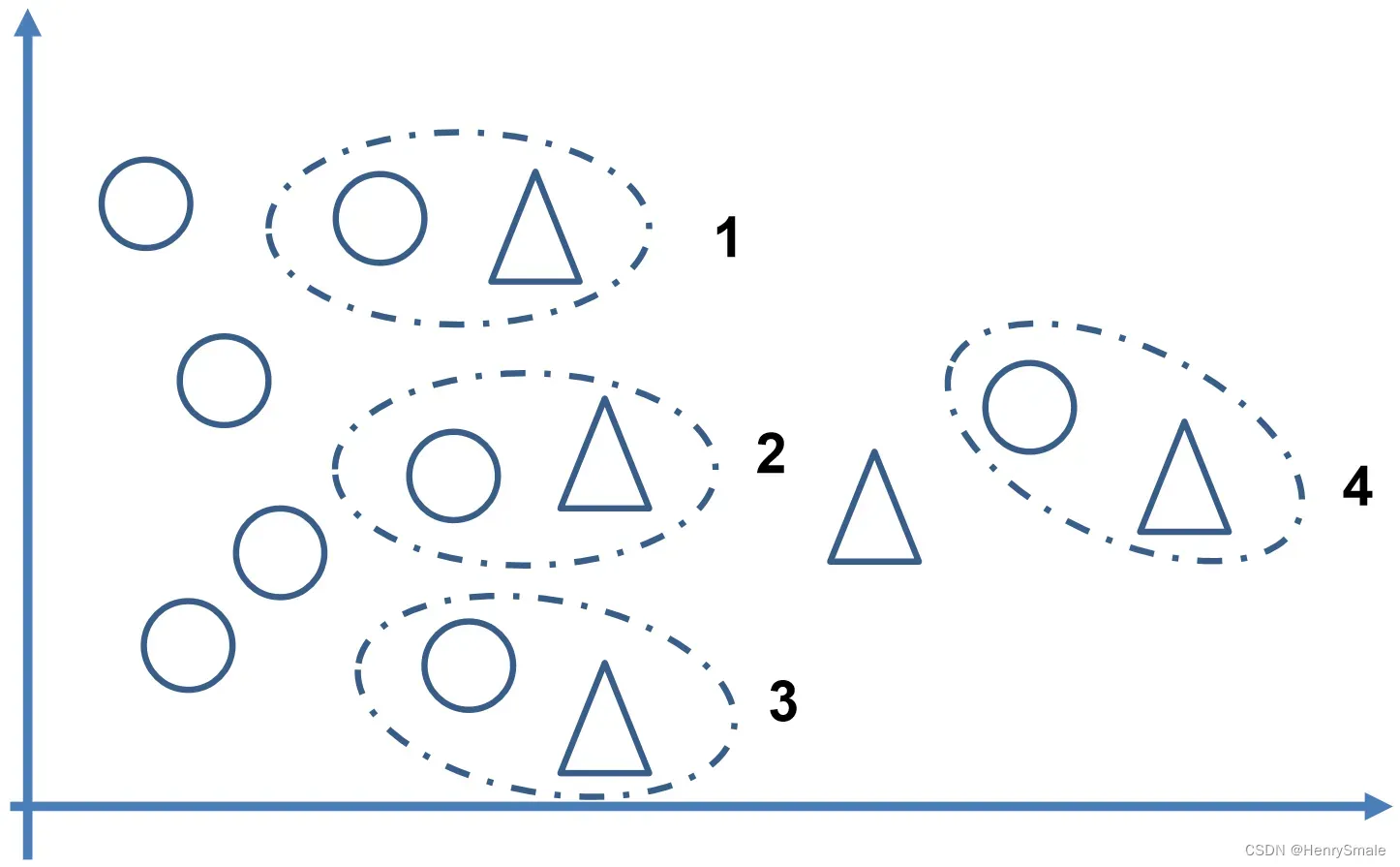
这个算法会先将所有的少数类样本分成三类,如图所示:
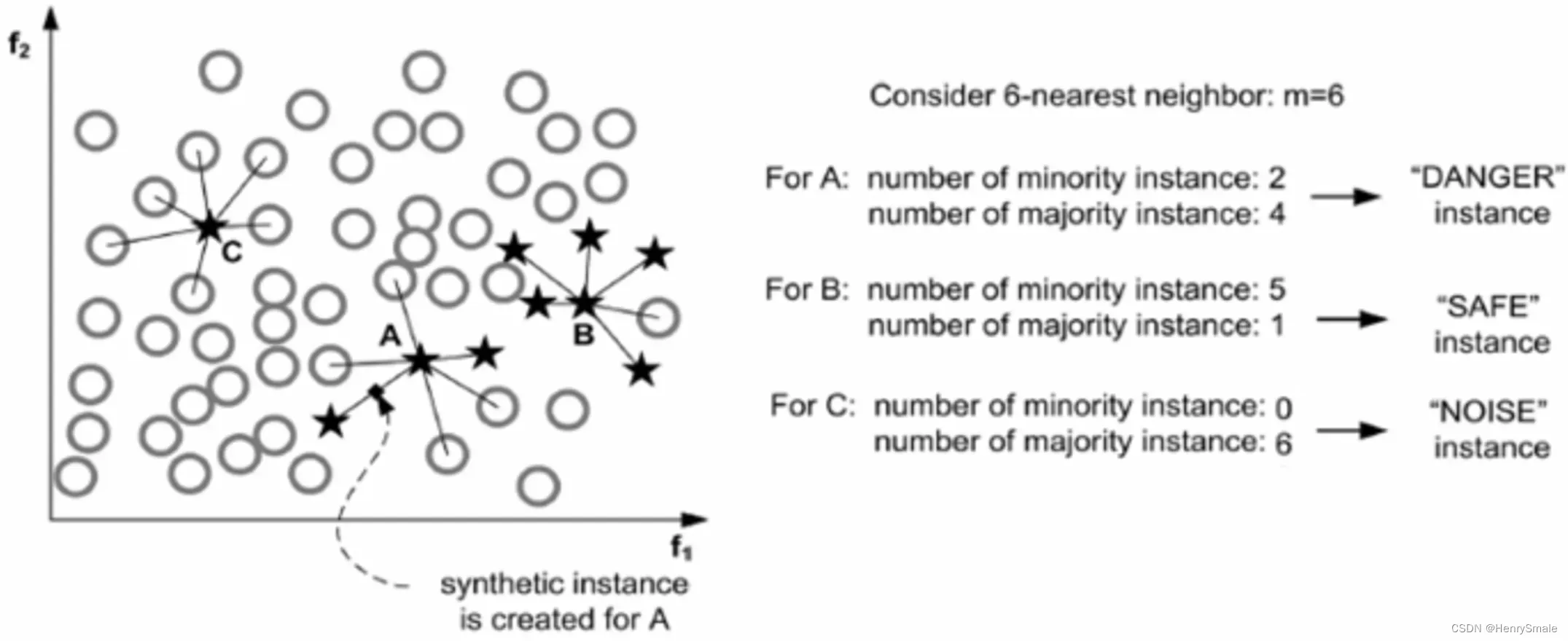
- “noise”:所有的
- “danger”:超过一半的
- “safe”:超过一半的
Borderline-SMOTE1算法只会从处于danger状态的样本中随机选择,然后用SMOTE算法产生新的样本。处于”danger”状态的样本代表靠近”边界”附近的少数类样本往往更容易被误分类。因而Border-line SMOTE只对那些靠近”边界”的少数类样本进行人工合成样本,而SMOTE则对所有少数类样本一视同仁。
3.2.3 Borderline-SMOTE2
少数类样本集用表示,多数类样本集用
表示,整个数据集用
表示。
在DANGER数据集中的点不仅从集中求最近邻并生成新的少数类点,同时也在
数据集中求最近邻,并生成新的少数类点。这会使得少数类的点更加接近其真实值。
对于danger中的每个样本:
- (1) 在
和
中分别得到
和
;
- (2) 在
比例的样本点和
作随机的线性插值产生新的少数类样本;
- (3) 在
比例的样本点和
3.3 混合采样
将过采样和欠采样技术结合起来同时进行,即组合重采样。基本思想是增加样本集中少数类样本的个数,同时减少多数类样本的个数,以此来降低不平衡度。
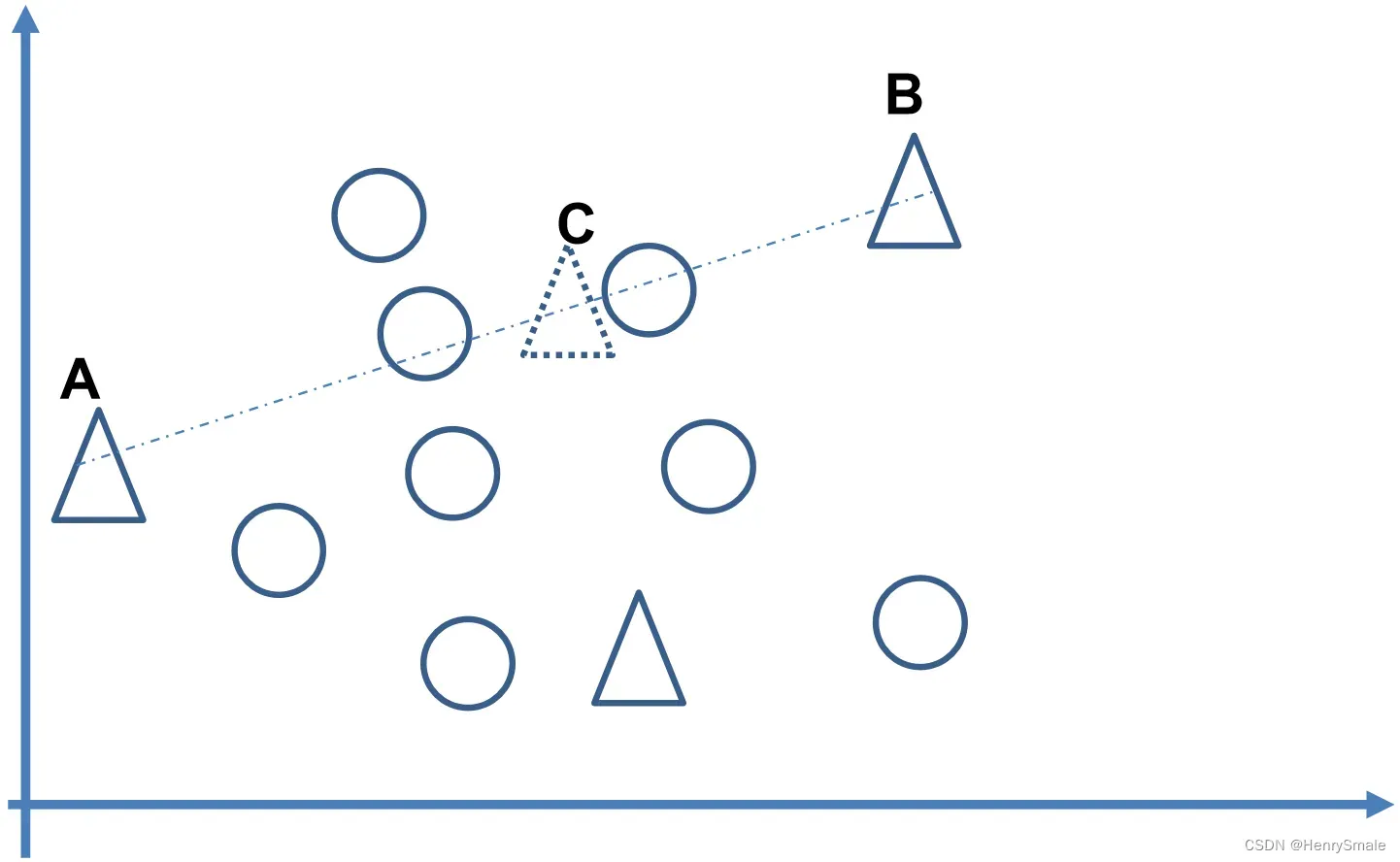
3.3.1 SMOTE + Tomek Link Removal
首先,利用SMOTE方法生成新的少数类样本,得到扩充后的数据集。然后剔除
中的Tomek links对。
为什么需要这两者的组合呢?
避免SMOTE导致原本属于多数类样本的空间被少数类“入侵”(invade),由Tomek links去除噪声点或者边界点。
3.3.2 SMOTE + ENN
和SMOTE+Tomek links方法的思路相似,包含两个步骤:
- 利用SMOTE方法生成新的少数类样本,得到扩充后的数据集
;
- 利用SMOTE方法生成新的少数类样本,得到扩充后的数据集
- 对
- 对
4 特征层
特征层解决不平衡数据分类的思路就是选择最合适的特征表示空间,再进行分类。
“最合适”是指提高少数类及整体的分类正确性。把数据样本投影到这个“最合适”的子空间中,多数类可能聚集在一起或重叠在一起,那么就有利于减小数据的非平衡性。
根据机器学习的特征理论,在特征空间的构造方面,存在两大类方法:
- 特征选择:监督方法(信息增益、互信息),无监督方法(特征数);
- 特征提取:主成分分析,深度神经网络。
文章出处登录后可见!