2022.11月
文章目录
- 一、引言
- 1.1 数据中的知识发现包括哪几个步骤?(Knowledge Discovery from Data, KDD)
- 1.2 数据挖掘应用
- 二、学习的可行性
- 2.1 Hoeffding 不等式(Hoeffding’s Inequality)
- 2.2 用 Hoeffding 不等式说明学习的可行性
- 三、数据和数据预处理
- 3.1 有哪四种不同的属性类型?分别可以进行什么操作?
- 3.2 非对称属性(Asymmetric Attributes)
- 3.3 数据对象之间相似度、相异度计算
- 3.4 数据预处理的主要任务
- 3.5 处理缺失值的方法
- 四、决策树学习
- 4.1 决策树学习的基本思想
- 4.2 分类错误率,熵,信息增益的概念,如何根据不同度量选择最佳划分
- 4.3 缺失值对决策树有何影响?
- 4.4 给定混淆矩阵,分类效果度量不同指标的含义及计算方法。
- 4.5 评估分类器性能的留一法和 k 折交叉验证
- 4.6 过拟合和欠拟合
- 五、神经网络
- 5.1 神经网络如何学习,有何特点?
- 5.2 梯度下降算法
- 5.3 多层神经网络使用什么算法进行训练?
- 六、贝叶斯学习
- 6.1 根据贝叶斯理论,如何计算一个假设 h 成立的后验概率?
- 6.2 极大后验概率假设和极大似然假设有何区别?
- 6.3 最小描述长度的基本思想
- 6.4 贝叶斯最优分类器的基本思想
- 6.5 朴素贝叶斯分类算法
- 6.6 贝叶斯信念网络的预测和诊断
- 6.7 偏差方差分析
- 七、基于实例的学习
- 7.1 K 近邻学习算法
- 7.2 K 近邻学习计算距离时为何要进行归一化
- 7.3 局部加权线性回归
- 7.4 基于案例的学习与 k 近邻学习的异同
- 7.5 懒惰学习和积极学习的区别
- 八、集成学习
- 8.1 集成学习的定义
- 8.2 集成学习的两个主要问题
- 8.3 Stacking 基本思想及其伪代码
- 8.4 Bagging 基本思想及其伪代码
- 8.5 Boosting 基本思想及其伪代码
- 8.6 为何集成学习有效
- 九、分类技术
- 9.1 基于规则的分类器有何优点,需要解决什么问题
- 9.2 序列覆盖算法
- 9.3 支持向量机基本原理
- 十、聚类分析
- 10.1 聚类的定义
- 10.2 聚类的类型
- 10.3 簇的类型
- 10.4 层次聚类的两种主要类型
- 10.5 计算簇间相似性的单链(MIN)和全链(MAX)方法
- 10.6 K 均值和 k 中心点算法
- 10.7 DBScan 算法
- 10.8 聚类评估
- 十一、关联分析
- 11.1. 概念:项集,频繁项集,支持度,置信度,极大频繁项集,闭频繁项集
- 11.2. Apriori 算法
- 11.3 FP 增长算法
- 11.4 关联模式评估
- 十二、 维度约减
- 12.1 过滤方法和包裹方法有何区别及优劣
- 12.2 五种不同的特征搜索方法,基本思想及其伪代码
- 12.3 维度约减结果评估
- 十三、 Refer
一、引言
1.1 数据中的知识发现包括哪几个步骤?(Knowledge Discovery from Data, KDD)
- 数据融合(Data Consolidation)—>数据筛选与预处理(Selection & Preprocessing)—>数据挖掘(Data Mining)—>解释和评估(Interpretation& Evaluation)
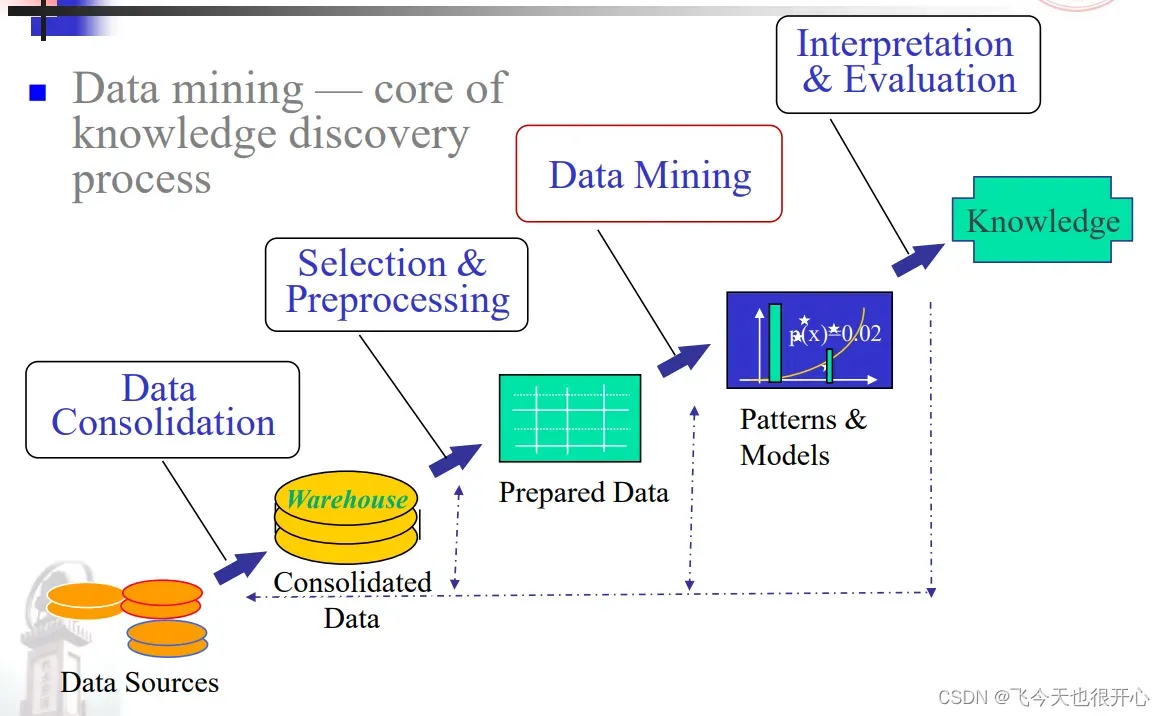
1.2 数据挖掘应用
- 目标检测、文本分类、语音识别、数据建模、自动驾驶、用户自定义学习、疾病故障自检
二、学习的可行性
2.1 Hoeffding 不等式(Hoeffding’s Inequality)
其中 分别是预测概率,实际概率,误差和样本数
2.2 用 Hoeffding 不等式说明学习的可行性

三、数据和数据预处理
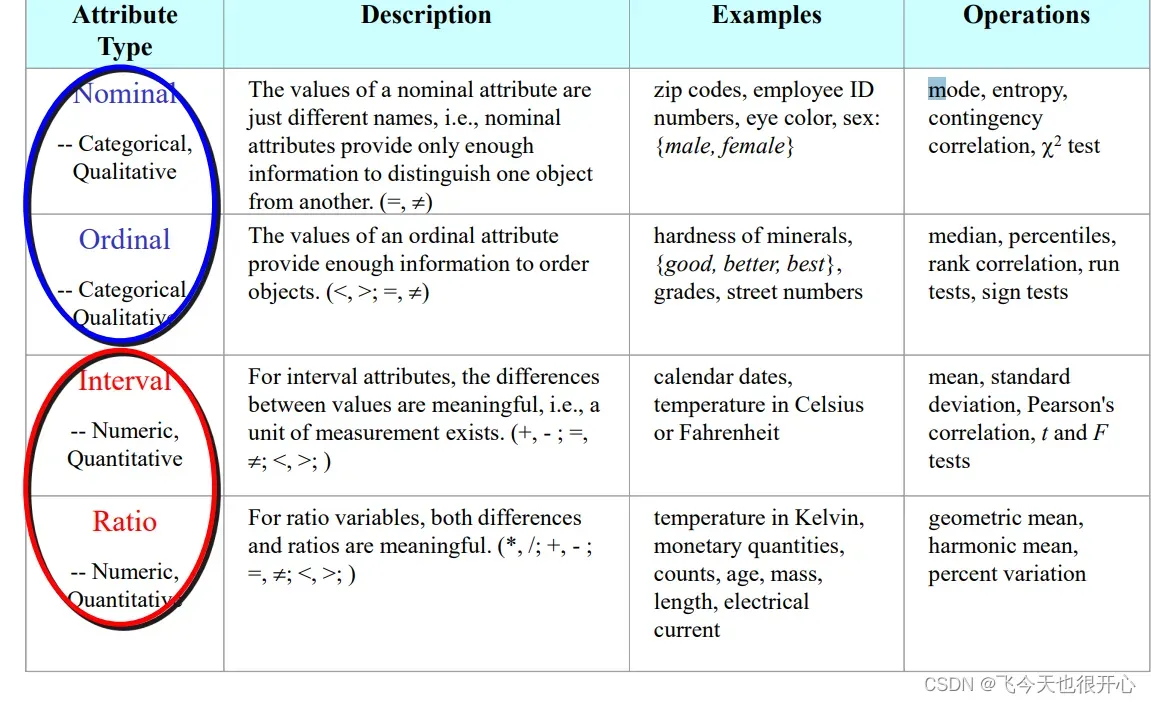
3.1 有哪四种不同的属性类型?分别可以进行什么操作?
- 标称属性(nominal),如ID号:模、熵、卡方;
- 序数属性(ordinal),如等级:中值、百分比、符号检测;
- 区间属性(interval),如日期:平均值、标准差;
- 比率属性(ratio),如length:几何平均数、调和平均数;
3.2 非对称属性(Asymmetric Attributes)
对于非对称属性,只有存在–非零属性值–才被认为是重要的。
- 解释:对属性的关注值不同,比如二元属性,当考虑普通人的患癌情况时,健康时属性为0,患癌时为1,这样大部分情况下该属性都为0,因此我们一般只关注属性为1的情况,所以这个就是非对称的二元属性。
3.3 数据对象之间相似度、相异度计算
3.3.1 相关性分析
-
卡方计算

A为实际值,T为理论值The larger the Χ2 value, the more likely the variables are related
3.3.2 相似性计算
-
欧氏距离(缺点:单位敏感,无法识别变量的相关性)
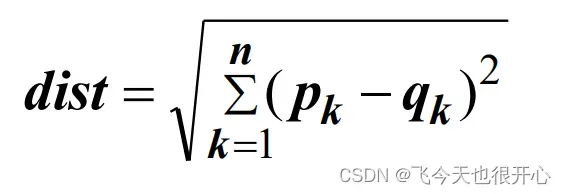
-
闵氏距离
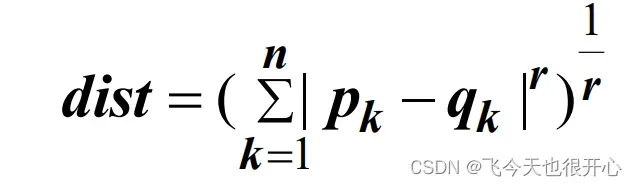
-
马氏距离
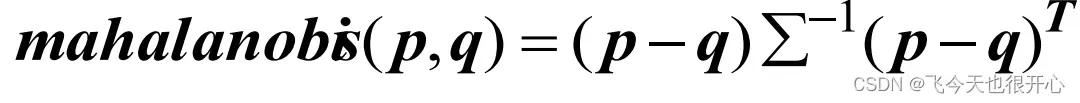
协方差矩阵
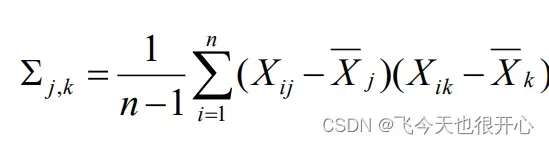
-
SMC & Jaccard 指数

3.4 数据预处理的主要任务
- 数据清理:填写缺失值、光滑噪声数据、识别/删除离群的点
- 数据集成:将多个数据源上的数据合并
- 数据变换:数据标准化和数据聚合
- 数据规约:将巨大的数据规模变小,但分析结果大体相同
- 数据离散化:增强鲁棒性
3.5 处理缺失值的方法
- 减少数据集并删除缺失值所在样本
- 找到缺失的值:输入缺失数据的合理预测值、使用一些常量自动替换缺失值、使用其他特征值替换缺失值
四、决策树学习

4.1 决策树学习的基本思想
- 根节点:每种属性值都会被测试,选择最好的一个(容易分、分的快)去当作根节点的测试方法(就是希望每次选择的属性可以让划分后的分支数据更有区分性,使各个分支的数据分类纯度更高,最好是每个分支的样本数据尽可能属于同一类别。)
- 节点:测试属性;分支:属性的可能取值。
- 为每个属性的可能值创建根节点的后代,并且将训练示例分类到适当的后代节点。
- 然后使用与每个后代节点相关联的训练示例重复整个过程,以选择在树中该点测试的最佳属性。
4.2 分类错误率,熵,信息增益的概念,如何根据不同度量选择最佳划分
决策树学习的关键在如何选择最优划分属性。一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别, 即结点的 “纯度”(purity)越来越高。(贪心划分策略)
-
基尼系数
是节点t第j个类的占比
如果分成了k个孩子
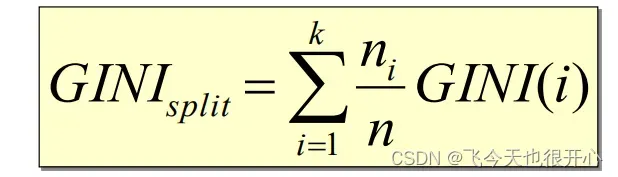
-
熵
-
信息增益
因为信息与熵大小相等意义相反,所以消除了多少熵就相当于增加了多少信息,这就是信息增益的由来。
母节点p,被划分为k个子类
取最大信息增益进行划分
-
信息增益率

-
分类误差
4.3 缺失值对决策树有何影响?
- 影响不纯度的计算
- 影响如何向子节点分配带有缺失值的实例
- 影响带有缺失值的测试实例如何分类
4.4 给定混淆矩阵,分类效果度量不同指标的含义及计算方法。
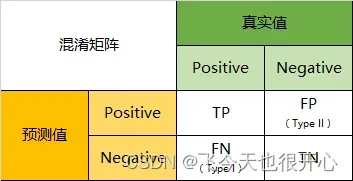
- 准确率:
- 召回率:
- F1-score:
- ROC:横坐标—>假阳率,纵坐标—>真阳率
4.5 评估分类器性能的留一法和 k 折交叉验证
-
留一法:每次只留下一个样本做测试集,其它样本做训练集,如果有k个样本,则需要训练k次,测试k次。
留一法计算最繁琐,但样本利用率最高。适合于小样本的情况。
-
K-折交叉验证:将全部训练集 S分成 k个不相交的子集,轮流拿出一个作为测试集,其它k-1个作为训练集,计算k次求得的分类率的平均值,作为该模型或者假设函数的真实分类率。
这个方法充分利用了所有样本。但计算比较繁琐,需要训练k次,测试k次。
4.6 过拟合和欠拟合
- 过拟合:决策树节点很多(分了好多类别,即模型过于复杂),也可能因为缺少训练样本数据
- 欠拟合:当模型太简单,训练样本和测试样本误差都很大
五、神经网络
5.1 神经网络如何学习,有何特点?
- 特点(Properties of Artificial Neural Networks )
- 许多简单的类似神经元的阈值切换单元
- 单元之间许多加权互联
- 高度并行、分布式处理
- 通过调整连接权值进行学习
- 如何学习(How a Neural Network learn?)
- 神经网络通过调整权值达到能够正确分类训练数据,进而分类未知的测试数据
- 神经网路需要很长时间进行训练
- 对噪音和不完整数据有很强的容忍性
5.2 梯度下降算法

5.3 多层神经网络使用什么算法进行训练?
反向传播算法(Backpropagation)
六、贝叶斯学习
6.1 根据贝叶斯理论,如何计算一个假设 h 成立的后验概率?
- 先验概率
- 训练集D,未观察到:先验概率
- 训练集D,观察到,h成立的概率
- 则后验概率
6.2 极大后验概率假设和极大似然假设有何区别?
-
极大后验概率假设(Maximum A Posteriori (MAP) hypothesis)
-
极大似然假设(Maximum Likelihood (ML) hypothesis)
如果假设空间H中所有假设h的先验概率相等,则MAP变为极大似然假设
6.3 最小描述长度的基本思想
模型复杂度与拟合度的一个折衷
Minimum Description Length Principle,由模型(假设)复杂度和错误率之后来描述:
为假设h的编码
为在假设的帮助下编码时对数据的描述(只传递h预测错误的数据)
- 与极大后验概率的关系:
6.4 贝叶斯最优分类器的基本思想
所有假设的后验概率加权到得新实例的分类
-
设V为所有可能分类结果的集合
-
当假设空间巨大的时候,贝叶斯最优分类器在计算上是不可行的
-
采用采样的方法进行解决上述问题(Gibbs Algorithm采样假设h)
6.5 朴素贝叶斯分类算法
朴素贝叶斯算法基于最大后验概率假设(MAP),并假设所有属性值独立于分类目标,简化贝叶斯最优分类器
一个实例 使用朴素贝叶斯分类,
为目标分类空间,有限
假设属性值 条件独立于分类目标
,因此
进而得到朴素贝叶斯分类器(Naive Bayes classifier)为:
6.6 贝叶斯信念网络的预测和诊断
朴素贝叶斯的假设十分理想,贝叶斯网络(信念)则将该假设弱化为无边连接则独立;
贝叶斯网络是一有向无环图(directed acyclic graph (DAG))
- 节点:贝叶斯意义下的变量—>它们可能是可观察量、潜在变量、未知参数或假设。
- 边:代表条件依赖,无边的节点即条件独立的
每个节点都与一个概率函数相关联,该概率函数将节点父变量的一组特定值作为输入,并给出节点表示的变量的概率。
-
主要应用概率公式:条件独立公式和全概率公式,全概率公式:
-
预测:前推导;诊断:由后验找原因

6.7 偏差方差分析
Error = Bias + Variance
-
偏差(Bias):实际值与预测值之间的误差
-
方差(Variance):对于一个给定点模型预测的变化性(由于训练集不一样等)
-
方差偏差-权衡:简单的模型方差小,偏差大(拟合度低);反之,则方差大,偏差小


七、基于实例的学习
当遇到新查询时,检索和处理与查询实例相关的实例;基于局部相似性的学习
7.1 K 近邻学习算法
-
目标函数为离散的
采用投票的方法,k个最近点函数值众数即为新实例的函数值
-
目标函数为连续的(实数)
-
k值的影响
大的k对噪声不敏感,适用于较大的训练集;
-
距离度量,引入加权距离
核函数
,如欧氏距离(要转变为倒数,距离越近权值越大)
7.2 K 近邻学习计算距离时为何要进行归一化
不同维度特征的量纲可能不同,为了保证每个特征的同等重要性,需要对每个特征维度进行归一化处理
7.3 局部加权线性回归
局部加权回归泛化k-NN方法,构造一个显式近似来覆盖 x 周围的局部区域
-
局部加权线性回归的一般形式为:
三类常用损失函数(只考虑最近k个点,考虑全局距离加权,综合前两者)

-
径向基函数(神经网络)—RBF
选择k个中心点
,使用核函数进行加权计算,调整权值来逼近目标函数(全局目标函数)

7.4 基于案例的学习与 k 近邻学习的异同
k近邻学习即为基于案例的学习算法
基于实例学习分两类,一个是实例在欧式空间内,有knn和局部加权。一个是复杂符号表示,有基于案例的推理
7.5 懒惰学习和积极学习的区别
- 懒惰学习(Layz):处理是后续进行的(直到查询到来,并存储所有训练样例)(局部表达逼近)(such as: K-NN,局部加权线性回归**)**
- 积极学习(Eager):在查询到来之前已经有了泛化能力/显示表达式(全局表达逼近)(such as: RBF, decision tree)
- 懒惰学习训练时间短,查询(测试)时间长代价大;积极学习则反之
八、集成学习
集成学习是一种组合许多弱学习器以尝试产生强学习器的技术
8.1 集成学习的定义
集成学习是一种组合许多弱学习器以尝试产生强学习器的技术
8.2 集成学习的两个主要问题
-
如何生成基础学习器(弱学习器)
Different learners, Bootstrap samples,…
-
如何组合弱学习器
- (加权)投票
- (加权)平均
- 弱学习器组合算法(Stacking,Boost)
8.3 Stacking 基本思想及其伪代码
两层,第一层为弱分类器(base leaner, 使用训练样本的有放回抽样(Bootstrap* *Sample) 训练第一层的分类器);第二层为Meta classifier,使用第一层的输出和样本的真实标签进行训练
-
基本思想为由第二层的元分类器(Meta Classifer)判断第一层的弱分类器是否正确学习到了训练数据特征
-
伪代码

-
与Stacking对应的是RegionBoost:其不对每个基础学习器(base learner)的训练数据使用单一的准确度度量,而是根据每个基础分类器预测与等待预测的示例的相似示例的好坏来
加权每个基础分类器的预测。有些分类器只对问题空间的某些区域表现良好,在对应该落入其中一个区域的新点进行分类时,使用该区域上的准确率作为基分类器的权重。
产生基(弱)分类器的方法:
- Homogenous Models(同质模型,即单个模型,不同训练集产生多个分类器—
Bagging,Boosting,DECORATE) - 不同的方法,相同的训练集。(很少使用)
- Homogenous Models(同质模型,即单个模型,不同训练集产生多个分类器—
8.4 Bagging 基本思想及其伪代码
使用可放回重复抽样(***Bootstrap* *Sample)***产生多个训练集训练多个分类器,采用多数投票的方式聚合得到最终结果;分类器最好是不稳定的

8.5 Boosting 基本思想及其伪代码
每轮对数据集的样本进行权重的重分配,错误的样本权重更高,正确的样本权重更低,产生新的弱分类器;最终由弱分类器投票得到结果

- AdaBoost是Boosting的一具体实现方法
DECORATE: 人工产生额外的训练数据,并打标签(与现在集成器预测相反)加入训练集产生新的分类器,如果集成准确率下降则拒绝该分类器。
随机森林(Random Forest):随机生成多个决策树进行投票获得最终解决;决策树生成有两个随机(使用有放回随机抽样的方法获得每个decision tree的训练样本,根据概率分布(如均匀概率分布)抽取部分特征构建节点)。
8.6 为何集成学习有效
- 集成学习有效的充分必要条件:基(弱)学习器是准确的(至少需要比随机猜测准确率高)和多样的(diversity,即在新的样本上预测误差不同)
- 统计上来讲(statistical):单个假设空间很大,但训练数据不足时,单个假设对于不可见数据准确率低,集成学习采用平均多个假设减低不可见数据的风险
- 计算上来讲(Computational):许多学习算法容易陷入局部最优解(如神经网络,决策树),集成学习从不同的初始点出发降低这一风险。
- 表示上来讲(representational):集成学习通过加权多个基学习器能够扩展代表函数的假设空间(更加的flexibility)
九、分类技术
9.1 基于规则的分类器有何优点,需要解决什么问题
- 优点:
- 可解释性高
- 容易生成
- 对一个新的实例分类迅速(速度快)
- 性能与决策树相当(性能优)
- 需要解决的问题
-
构建的规则不能够覆盖所有数据(不完备)
Soultion:定义默认规则,
defaut class -
构建的规则不能够互斥(一个样例可能被多个规则覆盖)
Solution:有序规则集合,无序规则通过准确率加权
-
9.2 序列覆盖算法
一种从训练数据集直接构建分类规则的算法
- 从一个空规则集合和一个给定的类别顺序开始,
- 针对每一个类别
- 使用Learn-One-Rule函数提取一个最好的规则r(贪婪思想,最好指覆盖尽量多的y类样本,尽量少的其他样本)
- 移除被规则r覆盖的数据,并将r加入R的底部
- 重复3,4直至达到终止条件,然后再循环2
9.3 支持向量机基本原理
支持向量机(SVM)是一类按监督学习方式对数据进行二元分类的广义线性分类器(常对小样本数据),其决策边界是对学习样本求解的最大边距超平面,可以将问题化为一个求解凸二次规划的问题。
具体来讲:
- 线性可分时,在原空间寻找两类样本的最优分类超平面
- 线性不可分时,加入松弛变量并通过非线性映射将低维度输入空间的样本映射至高纬度空间使其线性可分,进而在高维特征空间寻找最优分类超平面。
十、聚类分析
10.1 聚类的定义
从数据中挖掘簇,簇内各对象之间彼此相似/相关,而簇间对象不相似/不相关
10.2 聚类的类型
- 分层(Hierarchical,嵌套)与分区(Partitional,非嵌套)
- 排他、重叠、模糊
- 完全(complete)与部分(Partial)
10.3 簇的类型
- 分离良好的(Well-Separated),簇中一个点到簇内任意点的距离<到其他簇任意点的距离。
- 基于中心的(Center-Based),簇中一个点到簇中心<到其他簇簇中心的距离。
- 基于邻接的(Contiguous-Based),簇中一个点到簇中(存在)一个或多个点的距离<到其他簇任意点的距离。用于簇不规则或交织在一起时,但对噪声敏感。
- 基于密度的(Density-Based),簇是点的密集区域,由低密度区域与其他高密度区域分开。用于簇不规则或交织在一起时,对噪声不敏感。
- 基于概念的(Conceptual Clusters),一个簇是一个点集,这些点集共享一些共同的属性或者代表一个特定的概念。之前的簇定义都可以被该定义所包含。
- 基于目标函数的(Objective Function),查找最小化或最大化目标函数的聚类方式。
10.4 层次聚类的两种主要类型
- 聚合(Agglomerative):从每个点都是一簇出发,每次聚合最邻近的簇,直至达到要求的k个簇或只剩下一个簇。
- 分离(Divsive):从每个点同属一个簇出发,每次分离出一个最不相关的簇,直至达到要求的k个簇或每个簇仅包含一个点。
关键在于,如何计算簇间相似度,方法包括(最小,最大,簇平均,质心距离,基于目标函数的)。
缺点:做了就不能重做(属于一个簇定下来就永远定下来了)
10.5 计算簇间相似性的单链(MIN)和全链(MAX)方法
- MIN: 两个簇的相似度定义为两个不同簇中两点之间距离的最小值(相似度的最大值)。优点是可以处理多种规格(size)的簇,缺点为对噪声和异常点敏感。
- MAX: 两个簇的相似度定义为两个不同簇中两点之间距离的最大值(相似度的最小值)。优点对噪声和异常点不敏感,缺点为容易将大簇划分为小簇。
10.6 K 均值和 k 中心点算法
- K均值(K-Means):每一个簇都被一个中心关联起来。
- 算法流程:初始选择k个点作为中心点,然后计算各点与中心点之间的距离,将点分配至距离最近的中心点所在簇内;更新中心点(通常取簇点均值),重复分配过程,直至中心点不再发生变化。
- 评价方法:误差平方和(Sum of Squared Error,SSE):
,其中,
为第i个簇,
为
- 初始中心点的选择方法:多次运行(根据SSE选择最好的结果);抽样然后使用层次方法决定初始中心点(小样本可行);选择>k个中心点然后再次(根据最广泛分离)选择;二等分 K 均值;后处理方法
- 空簇的处理方法:选择替代的中心点(如离所有中心最远的点作为中心取代空簇中心点);中心更新策略变为每次点分配都重新计算中心
- K中心点(K-medoids):中心点为并非簇内的平均点,而是簇内位于最中心的某点。
- Partitioning Around Medoids-PAM(K中心点的一种简单实现):从一组初始的中心点开始,如果随机选择一个簇非中心点,若它提高了所得聚类的质量,则用该点迭代地替换其中一个中心点。
- 弥补了K-mean的一部分缺点:对噪声,异常点不敏感。
10.7 DBScan 算法
DBScan,Density Based Spatial Clustering of Applications with Noise.
-
几个基础概念:
- EPs* : 邻居的最大半径;
- MinPts:在EPs内最少需要包含点的数量
- Density: 给定半径内包含点的数量
- 中心点(core point):在EPs内包含点数量≥MinPts
- 边缘点(border point)*:不是中心点但在中心点半径内的点
- 噪声点(noise point)*:中心点与边缘点之外的点。
- 直接密度可达:两个点的距离≤Eps
- 密度可达:经过一系列直接密度可达的中间点,可连接,则为密度可达。
- 密度连接:经过一个直接密度可达的中间点,可连接。
-
算法
Step1:任意选取一个点p
Step2:根据EPs取出由p密度可达的点
Step3:如果p是一个中心点,则一个簇形成
Step4:如果p是一个边缘点,或者没有点是密度可达的,则访问下一个点重复2,3,直到所有点都被处理。
-
参数选取(半径Eps和半径内数量MinPts)
对于簇中的任意一个点,他们第k个最近点距离大致相同的,据此绘图找出折线剧烈变化的地方,可以找到合适的Eps
10.8 聚类评估
量化评估主要有三类:
- 外部索引(External Index):熵(Entory),有分类标签这一外部信息可用于度量
- 内部索引(Internal Index):SSE,cohesion,separation;没有分类标签时的评估。
- 相关索引(Relative Index):用于比较两个簇或者两个聚类算法。
相关指标:
-
相似性矩阵和索引矩阵(行列代表节点,属于同一个簇则为1,否则为0),关联分析
-
Cohesion: WSS
,与SSE一样
-
Separation:BSS=
,其中
为簇i的个数
-
轮廓系数:对于第i个点,a为该点到簇内其他点的平均距离,b为到其他簇点平均距离的最小值;
s=
s=
越接近1越好
十一、关联分析
11.1. 概念:项集,频繁项集,支持度,置信度,极大频繁项集,闭频繁项集
- 项集:一个或多个项目(东西)的集合
- 支持度:一个项集的出现次数/事务数
- 频繁项集:支持度≥最小支持度阈值(minsup)的项集
- 置信度:包含A事务同时也包含B的百分比。
- 极大频繁项集:若一个频繁项集的所有超集都是非频繁的,则该频繁项集为极大频繁项集(所有的频繁项集都由最大频繁项集集合导出,频繁项集的稠密表示)
- 闭频繁项集:若一个频繁项集的所有超集的支持度都与它不同(小于),则该频繁项集为闭频繁项集(极大频繁项集)。
11.2. Apriori 算法
Apriori规则:如果一个项集是频繁的,则它的所有子集都是频繁的;借此大幅度减少候选项集的数量
Step1:初始化参数k=1,支持度和置信度阈值
Step2 :扫描事务库生成k项频繁项集;(或者采用hash树的方式进行比较)
Step3 :生成(k+1)候选项集,多采用
方法:
- 频繁项集按照字典排序法存储
- 每一个频繁项集仅与字典序大于自己的进行扩展,扩展方法为前(k-1)项均相同,最后一项不相同,二者取并集作为(k+1)候选项集
重复Step2,Step3直至候选项集为空,得到频繁项集,进而生成关联规则。
- 关联规则生成时有如下性质,对于同一个项集
11.3 FP 增长算法
-
构建FP树
扫描第一趟,对每一个事务的商品进行排序(根据商品出现的次数,并丢弃非频繁的商品项)
扫描第二趟,每次读取一个事务构建一条路径,若路径前缀相同,则进行合并
最后给予存在的每个商品一个指针,该指针将以包含商品的路径联系了起来
-
挖掘频繁项集
在FP树构建完成的基础上,从路径末尾开始递归挖掘。
频繁关联规则挖掘之FP树_wustdatamining的博客-CSDN博客
11.4 关联模式评估
-
原始评估是支持度和置信度
-
列联矩阵经常被用到
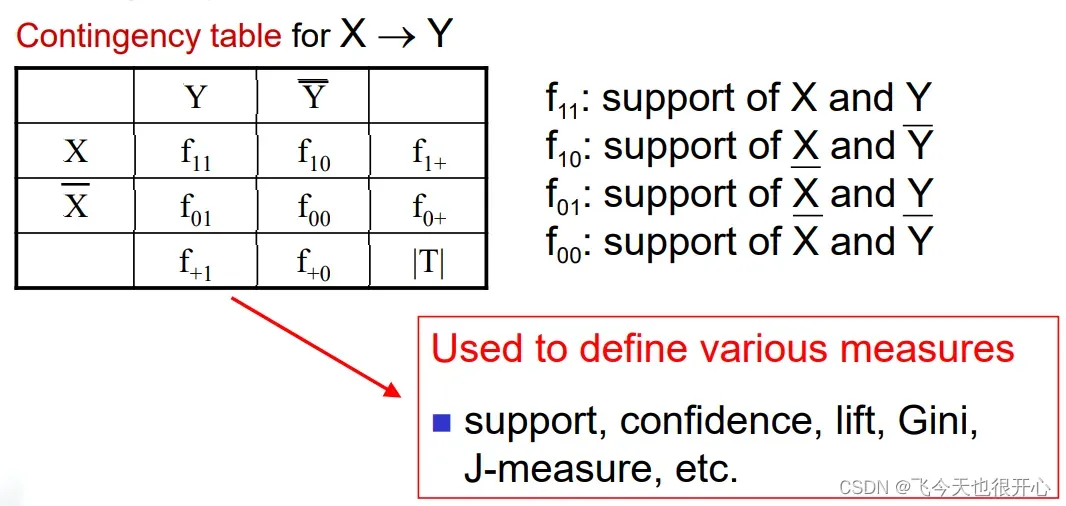
-
提升度(Lift)/Interest =
, 对于规则X→Y or Y→X
十二、 维度约减
12.1 过滤方法和包裹方法有何区别及优劣
过滤(Filter)方法和包裹(wrap)方法是评价特征选择好坏的两类重要方法
-
过滤方法:使用侧重于特征本身相关性的评估函数,无监督,独立于学习器。
Filter评估方法具体有4类:概率距离度量,概率依赖度量,熵度量,类间距离度量
优点:
- 计算代价小(非迭代,与分类器无关)
- 更具通用性(使用数据本身的固有属性,与分类器无关)
缺点:
- 往往选择较大的特征子集(由于filter评估函数单调,倾向于选择所有的特征),进而使得使用者不得自己选择截断策略。
-
包裹方法:使用专注于准确性的评估函数,往往学习器本身作为评估函数。
优点:
- 准确率更高(使用分类器与数据的具体交互)
- 泛化能力强(选择特征时使用交叉验证方法来避免过拟合)
缺点:
- 计算代价高(需要为每个特征子集训练一个分类器)
- 缺乏通用性(所选择特征强依赖于分类器)
12.2 五种不同的特征搜索方法,基本思想及其伪代码
-
朴素顺序特征选择(Naïve Sequential Feature Selection)
N特征逐个送入评价函数J,选择评分最高的M个特征;缺点没有考虑特征间的信息互补
-
前向顺序选择(Sequential Forward Selection (SFS))
初始最佳选择集Y=
,然后依次加入一个特征x, Y+x能够使分类器产生最高的分类准确率,直至Y加入剩余任何特征时分类准确不再改变。
1.Start Y_0 = {} 2.select best feature x_best = argmax_{x not in Y_k}[J(Y_k+x)] 3.Update Y_{k+1} = Y_k + x_best 4.GO to 2在特征数目较少时表现好,缺点是加入后不能够移除已经选择的特征(某个特征加入后,已选择的特征可能与分类结果无关)。
-
后向顺序选择(Sequential Backward selection (SBS))
与前向顺序选择正好相反,Y=X出发,每次移除一个最差特征,直至分类准确率开始下降。

在特征数目很多时表现好,缺点是一个特征一旦移除后续将不能重新评估该特征的影响。
-
双向搜索(Bidirectional Search (BDS))
前向,后向的并行执行,双向奔赴,收敛至同一个特征子集。
基本思想是:SFS选择的SBS不能移除,SBS移除的SFS不会再次进行选择。

-
前向浮动顺序选择(Sequential Floating Forward Selection, SFFS)
在SFS的基础上,允许回退,即加入一个特征后,选择最坏的一个特征,若移除该特征后分类准确率上升,则移除,并重复此操作直至无法移除特征再进行选择添加。

12.3 维度约减结果评估
使用降维后的特征选择自己,送入到SVM等模型中进行训练,测试查看模型准确率是否明显下降等。
十三、 Refer
- 本课程课件PPT
- 机器学习期末复习
文章出处登录后可见!