前文:https://www.cnblogs.com/odesey/p/16902836.html
介绍了混淆矩阵。本文旨在说明其他机器学习模型的评价指标。
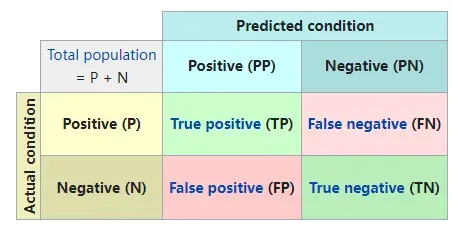
1. 准确率(Accuracy-Acc)
显然,Acc 表示模型预测正确(混淆矩阵的对角线)与全部样本(所有加一起)的比值。
Acc 评价指标对平等对待每个类别,即每一个样本判对 (0) 和判错 (1) 的代价都是一样的。
问题 : 精度有什么缺陷?什么时候精度指标会失效?
- 对于有倾向性的问题,往往不能用 ACC 指标来衡量。比如,判断空中的飞行物是导弹还是其他飞行物,很显然为了减少损失,我们更倾向于相信是导弹而采用相应的防护措施。此时判断为导弹实际上是其他飞行物与判断为其他飞行物实际上是导弹这两种情况的重要性是不一样的;
- 对于样本类别数量严重不平衡的情况,也不能用 ACC 指标来衡量。比如银行客户样本中好客户990个,坏客户10个。如果一个模型直接把所有客户都判断为好客户,得到精度为99%,但这显然是没有意义的。
样本类别数不平衡指的是:所有样本中的大部分都是正样本,或负样本。如入职体检中,未患癌症的样本是占优的;所有投保客户中的非欺诈客户是占优的。
2. 查准率(Precision)
Precision 统计 “预测为 Positive 且预测正确(TP) 的样本”中,有多少预测是正确的。
从公式可以看出,Precision 从 预测为 Positive 结果 出发,计算 模型预测为 Positive且预测正确(TP) 占 模型预测的所有 Positive 样本(TP+FP) 的比例。
Precision 越高意味着模型对 “预测为 Positive ” 的判断越可信。
3. 查全率/召回率(Recall)
从公式可以看出,Recall 从 真实标签为 Positive 出发,计算 模型预测为 Positive 且预测正确(TP) 占 真实的所有 Positive 样本(TP+FN) 的比例。
Recall 越高越好,越高意味着模型对 “实际为正” 的样本误判越少,漏判的概率越低。
在 混淆矩阵的 列是预测值的前提下,Precision 和 Recall 的简记为 “竖准横全”。
4. Precision 和 Recall 之间的关系
业务场景下,对模型对查准率和查准率的侧重,可能有所不同。
例子:
-
地震的预测 对于地震的预测,我们希望的是 Recall 非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲 Precision。情愿发出 1000 次警报,把 10 次地震都预测正确了;也不要预测 100 次对了 8次 漏了两次。
-
在 量化投资 的场景下,错标的成本很高,所以 Precision 要高。即使,模型会错失很多的投资机会,但如果因为误标记,做了一笔错误的交易,公司就会产生重大资损。
“宁错拿一万,不放过一个”,分类阈值较低
-
嫌疑人定罪 基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。即使有时候放过了一些罪犯,但也 是值得的。因此我们希望有较高的 Precision 值,可以合理地牺牲 Recall。
-
在恶意骗保识别的场景下,漏标的代价很大,所以查全率要高。即使,把一些正常的客户标记为了高风险的客户,也可以在后续的人工复核中做二次审核,继续理赔流程。但如果漏标了恶意骗保客户,公司就会产生重大资损。
“宁放过一万,不错拿一个”,“疑罪从无”,分类阈值较高
● 所以在建模实操当中,我们不可避免的要对查全率和查准率两者进行权衡。权衡的方式之一,就是对两者进行调和平均,即F值。
问题 :
某一家互联网金融公司风控部门的主要工作是利用机器模型抓取坏客户。互联网金融公司要扩大业务量,尽量多的吸引好客户,此时风控部门该怎样调整Recall和Precision?如果公司坏账扩大,公司缩紧业务,尽可能抓住更多的坏客户,此时风控部门该怎样调整Recall和Precision?
答: 如果互联网公司要扩大业务量,为了减少好客户的误抓率,保证吸引更多的好客户,风控部门就会提高阈值,从而提高模型的查准率Precision,同时,导致查全率Recall下降。如果公司要缩紧业务,尽可能抓住更多的坏客户,风控部门就会降低阈值,从而提高模型的查全率Recall,但是这样会导致一部分好客户误抓,从而降低模型的查准率 Precision。
当然 Precision 越高越好,Recall 也是越高越好。但根据以上几个案例,我们知道随着阈值的变化 Recall 和 Precision 变化的方向是往往是相悖的,因为:
- 提高 Precision ,意味着模型要更加精准的、更加确定性的标记“正值”,这就意味着标记更少的正样本;
- 而提高 Recall ,意味着要圈选更多的正样本,以避免漏判,这就意味着标记更多的正样本。
建模实操当中,我们不可避免的要对查全率和查准率两者进行权衡。权衡的方式之一,就是对两者进行调和平均,即 F-Score 。
5. F-Score
β 表示权重。β 越大,Recall 的权重越大; 越小,Precision 的权重越大。
特别的,β = 1,称为 F1-Score。
的物理意义就是将 Precision 和 Recall 这两个分值合并为一个分值,在合并的过程中,Recall 的权重是 Precision 的 β 倍 。 F1 分数认为 Recall 和 Precision 同等重要,F2 分数认为 Recall 的重要程度是 Precision 的 2 倍,而 F0.5 分数认为 Recall 的重要程度是 Precision 的一半。
应用领域
F 分数被广泛应用在信息检索领域,用来衡量检索分类和文档分类的性能。早期人们只关注 F1 分数,但是随着谷歌等大型搜索引擎的兴起,Precision 和 Recall 对性能影响的权重开始变得不同,人们开始更关注其中的一种,所以 分数得到越来越广泛的应用。
F 分数也被广泛应用在自然语言处理领域,比如命名实体识别、分词等,用来衡量算法或系统的性能。
几张不错的图:

文章出处登录后可见!