ClipCap: CLIP Prefix for Image Captioning
文章目录
- ClipCap: CLIP Prefix for Image Captioning
- 前言
- 一、原理
- 二、 方法
- 1.4 实验
- 三、运行记录
- 3.1 准备
- 3.2 模型训练
前言
本文主要目的是学习这篇paper,以及纪录相关的代码学习过程
论文:https://arxiv.org/abs/2111.09734
Github:
https://github.com/rmokady/CLIP_prefix_caption
https://github.com/yangjianxin1/ClipCap-Chinese
参考链接:
ClipCap:让计算机学会看图说话
一、原理
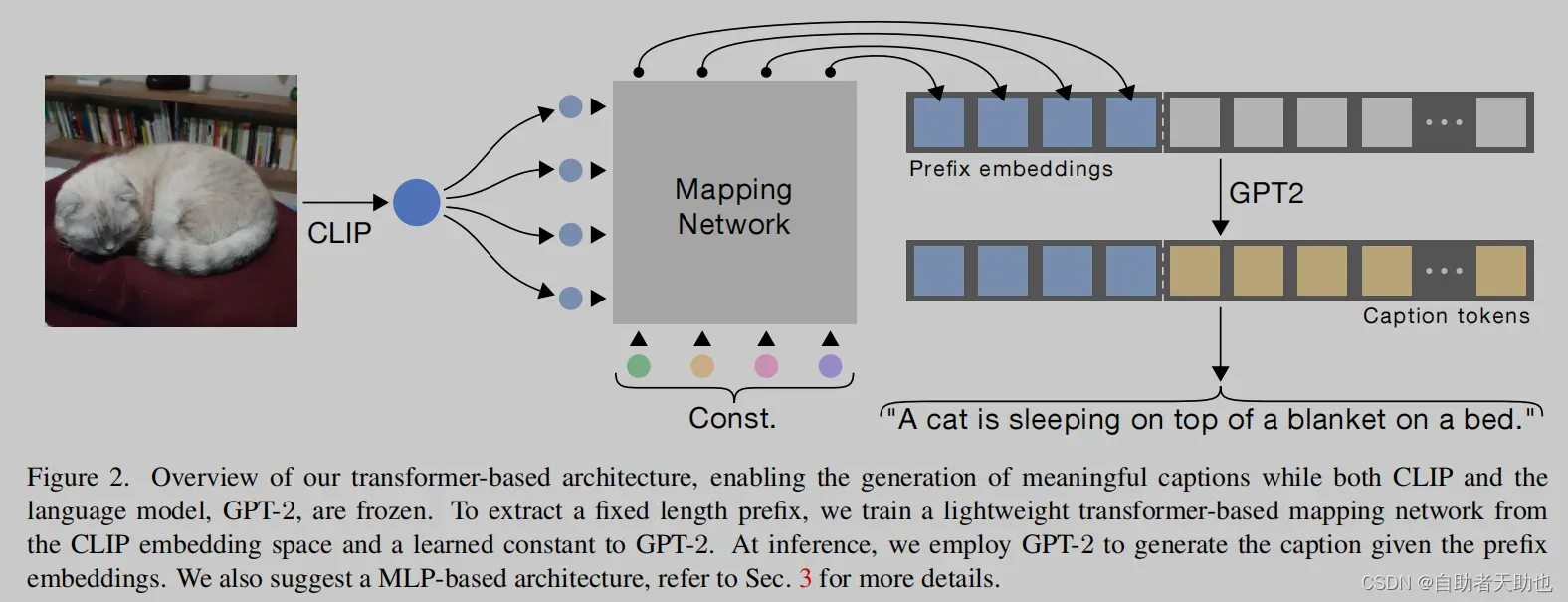
ClipCap提出一种基于Mapping Network的Encoder-Decoder模型,其中Mapping Network扮演了图像空间与文本之间的桥梁。模型主要分为三部分:
- Image Encoder : Clip编码图像,得到clip embedding
- Mapping Network: 将图片向量clip_embed映射到文本空间中,得到一个文本提示向量序列prefix_embedding
- Text Encoder:采用GPT2模型,根据提示向量序列prefix_embeds, 生成caption
有点像UNILM
二、 方法

给定x_i, 得到c_i,最大化(1)的序列概率。(2)是GPT2那部分的求解目标

最后的loss是交叉熵损失,整个模型比较简单。
Mapping Network 有两种:MLP or Transformer
1.4 实验
数据集:
- COCO-captions
- nocaps
- Conceptual Captions
Image Caption 2021最新整理:数据集 / 文献 / 代码
这个博客详细介绍了相关数据集的基本情况

扩展该方向的创新点 - 曝光偏差问题
- 物体对应问题
- 效果问题
三、运行记录
3.1 准备
- 数据
官网:http://hockenmaier.cs.illinois.edu/DenotationGraph/
填写表单,然后下载:
1、flickr30k.tar:压缩后是名为results_20130124.token的图片标注文件
2、flickr30k-images:共计约31783张照片
- 模型权重
Clip的权重
_MODELS = {
"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
"RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt",
"RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt",
"RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt",
"RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt",
"ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
"ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt",
"ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt",
}
GPT2 中文模型
https://github.com/Morizeyao/GPT2-Chinese gpt2通用中文模型
3.2 模型训练
python train.py \
--data_path datasets/clip_caption.pkl \
--gpt2_path pretrain_models/gpt2 \
--bert_path pretrain_models/bert \
--output_path output/finetune \
--lr 2e-5 \
--epochs 40 \
--prefix_len 10 \
--constant_len 10 \
--clip_size 512 \
--bs_train 40 \
--dev_size 1000 \
--bs_eval 128 \
--max_len 100 \
--warmup_steps 5000 \
--save_step 1000 \
--eval_step 500 \
--finetune_gpt2 \
--mapping_type mlp \
--do_train
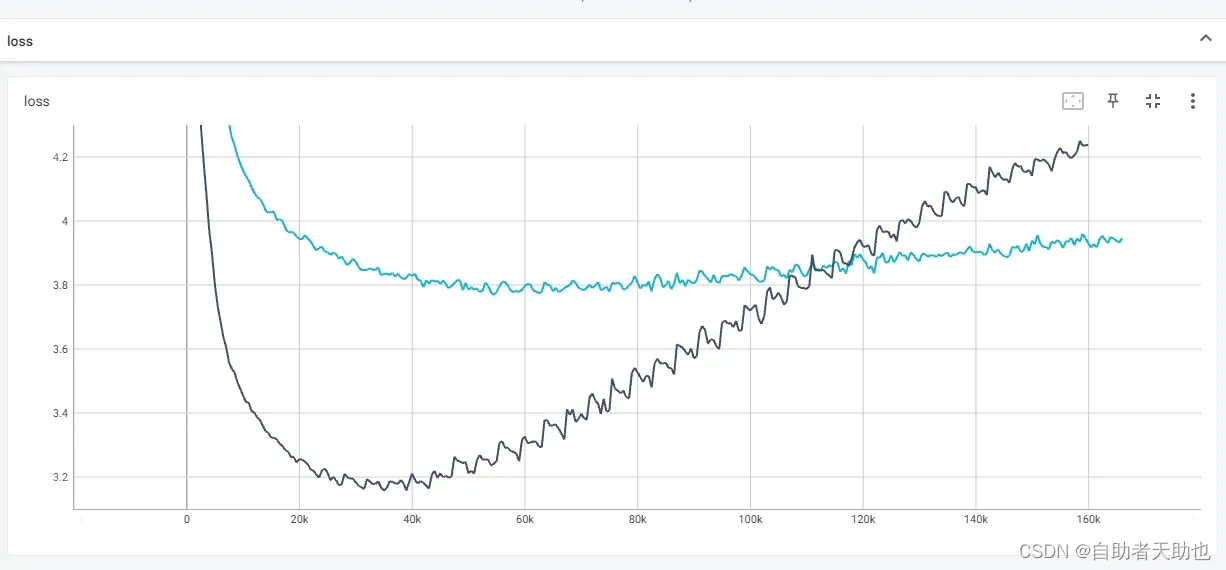
蓝色:bert no finetune + gpt2
黑色:mlp finetune + gpt2
MLP的loss下降更快,也更低
BERT的loss下降慢,收敛的不好
因为:黑色是,MLP和GPT2是一起微调的,蓝色是只微调BERT,训练难度更大,GPT2是固定的。
对topk和topp的理解:
语言生成:搜索 or 采样,that is the question
总结:
Flickr30中文caption数据是由机器翻译获得的,质量上存在缺陷,后续可以考虑使用更加高质量的数据进行模型训练。并且根据训练过程分析可以知道,由于训练数据量较小,模型存在过拟合的风险,后续可以考虑使用更高量级的数据进行训练,相信能够获得更好的效果。
- 更高质量的数据集
- CLIP模型可以考虑换成中文的Chinese-CLIP模型,对中文的感知能力强点
- Mapping Network在小的数据集上MLP比较优秀, 也比较轻量化
- 文本生成部分,可以尝试GPT2更强的作为baseline来进行
- 论文中采用topk, topp的采样,可以尝试其他语言模型采样的方法: A Contrastive Framework for Neural Text Generation
文章出处登录后可见!