论文:Masked Autoencoders Are Scalable Vision Learners
别再无聊地吹捧了,一起来动手实现 MAE(Masked Autoencoders Are Scalable Vision Learners) 玩玩吧! – 知乎
本文是2021.11.11发布在Arxiv上的文章,主要工作是在Vision Transformer基础上,引入自监督训练,跟BERT一样通过完形填空来获取对于图片的理解,相当于将BERT应用到CV领域,把整个训练拓展到没有标号的数据上面。最终MAE只需要Vision Transformer百分之一规模的数据集上预训练,就能达到同样的效果。而且在目标检测、实例分割、语义分割等任务上,效果都很好。
1 标题
masked autoencoder are scalable vision learners:带掩码的自编码器是一个可拓展的视觉学习器
- scalable:可拓展的
- vision learner:这里没有写成classifier或者其他的东西,因为它能够用到的地方相对广一些,他是一个backbone模型
- masked:masked来源于BERT,每次挖掉一些东西然后去预测被挖掉的东西
- autoencoder:这里的auto不是自动的意思,而是“自”的意思,标号和样本(y和x)来自于同一个东西。在NLP中,大家都是可以理解的,但是在计算机视觉中,图片的标号很少来自图片本身,所以作者在这里加上了auto,意在指出和计算机视觉中其他的encoder相比,这里的标号也就是图片本身,这样能跟之前的很多工作区分开来
2 摘要
MAE的实现路径非常简单,随机地盖住图片中地一些块(patches),然后再去重构这些被盖住的像素(the missing pixels),这个思想来自于BERT中的带掩码的语言模型。
2.1 两个核心的设计
通过一下两个设计,MAE可以更高效地训练大的模型
1 非对称的encoder-decoder架构
实际上任何模型都有一个编码器和一个解码器,比如说在BERT中的解码器就是最后一个全连接输出层,因为BERT预测的东西相对来讲比较简单,所以它的解码器就是一个简单的全连接层就可以了,但是本文中可能相对复杂一点,因为需要预测一个块中所有的像素。
- 编码器只作用在可见的patch中,对于丢掉的patch,编码器不会对它进行编码,这样能够节省一定的计算时间
- 解码器是一个比较轻量的解码器,拿到编码器的输出之后,重构被遮挡住的块
2、遮住了大量的块(比如说把75%的块全部遮住),迫使模型去学习一些更好的特征,从而得到一个较好的自监督训练效果。如果只是遮住几块的话,只需要进行插值就可以出来了,模型可能学不到特别的东西。编码器只需要编码1/4大小的图片,可以降低计算量,训练加速3倍或者以上
结果:最终作者只使用一个最简单的ViT-Huge模型(模型来自ViT这篇文章),在ImageNet-1K(100万张图片)上预训练,精度也能达到87.8%
在ViT这篇文章的最后一段有提到过怎样做自监督学习,作者说效果并不是很好,结论是:用有标号的模型和更大的训练集可以得到很好的效果。本文亮点是,只使用小的数据集(ImageNet-1k,100万张图片),而且是通过自监督,就能够做到跟之前可能效果一样好的模型了。
这个模型主要是用来做迁移学习,它证明了在迁移学习的其他任务上表现也非常好
2.2 MAE模型的架构
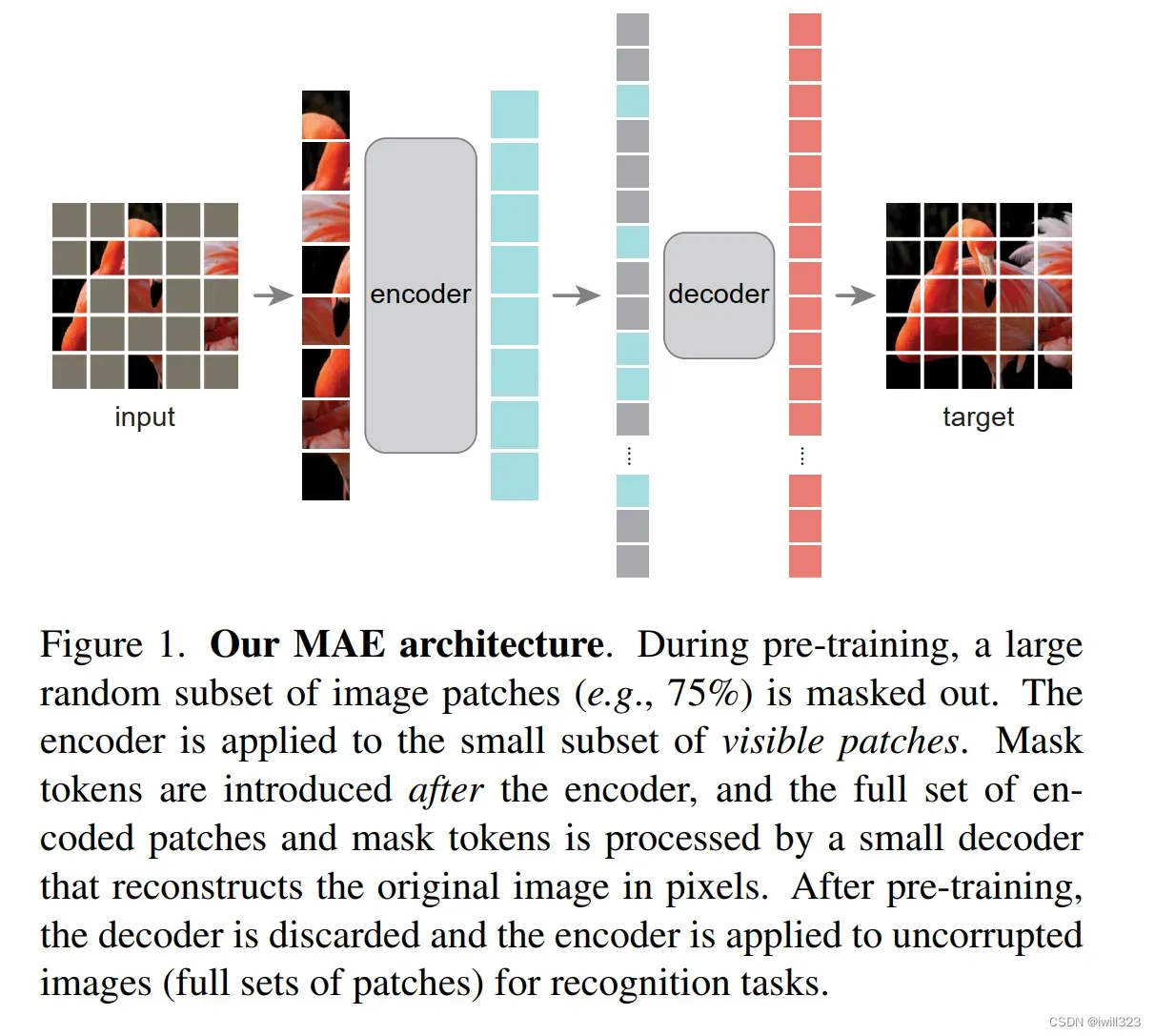
- 输入一张图,将它切成一个一个的小块,图中涂成灰色的小块就是被盖住的部分。去掉那些被盖住的块,剩下的小块已经不太多了,因为3/4的地方都已经被盖住了。
- 将剩下的小块放进encoder(也就是ViT)中,得到每一个块对应的特征。然后将输出拉长,把被盖住的那些块重新放回到原来的位置,得到原始图片拉成的一条向量
- 将得到的长向量输入到解码器中,解码器会尝试将里面的像素信息全部重构回来,使得训练出来的target就是原始图片
这里的编码器画的稍微比解码器要宽一点,意思是说模型主要的计算来自于编码器,因为最重要的就是对图片的像素进行编码,这是在预训练的时候所干的事情。对于下游任务,就只需要编码器就够了,直接切成一个一个的小块,然后放进ViT,就能得到输入图片的特征表达,然后用来做所要处理的任务
2.3.模型重构效果
下面是作者展示的一些模型重构效果图:

图2演示的是在ImageNet的验证集上通过MAE构造出来的图片,因为这些图片是没有参与训练的,所以只是测试结果
- 每张图片中,左边一列演示的是将图片patches的块被去掉,中间列是MAE构造出来的图片效果,最右边一列是原始图片
- 第一行第一张图片里的时钟上的指针基本上被遮住了,但是还原的时候还是基本上将两个指针整个还原出来了
- 第二行第一张图片中车的两头都没有,但是还原的效果跟真实的车的效果还是非常一致
- 第三行第一张图中的狗也是基本上看不出来狗在什么地方,但是还是能够大概的还原出来
- 这里的重构虽然在细节上比较模糊,因为原始图片的尺寸也不是很大,但是对图片内容的重构效果还是非常惊人的
- MAE不一定对所有图片的重构都有很好的效果,这里可能只是挑选出来了一些比较好的样例做了展示。如果想要将任意打码的图片还原出来,后续可能还需要很多工作进行改进
图3是在COCO数据集上,跟之前的处理完全一样,效果上来说也是非常惊人
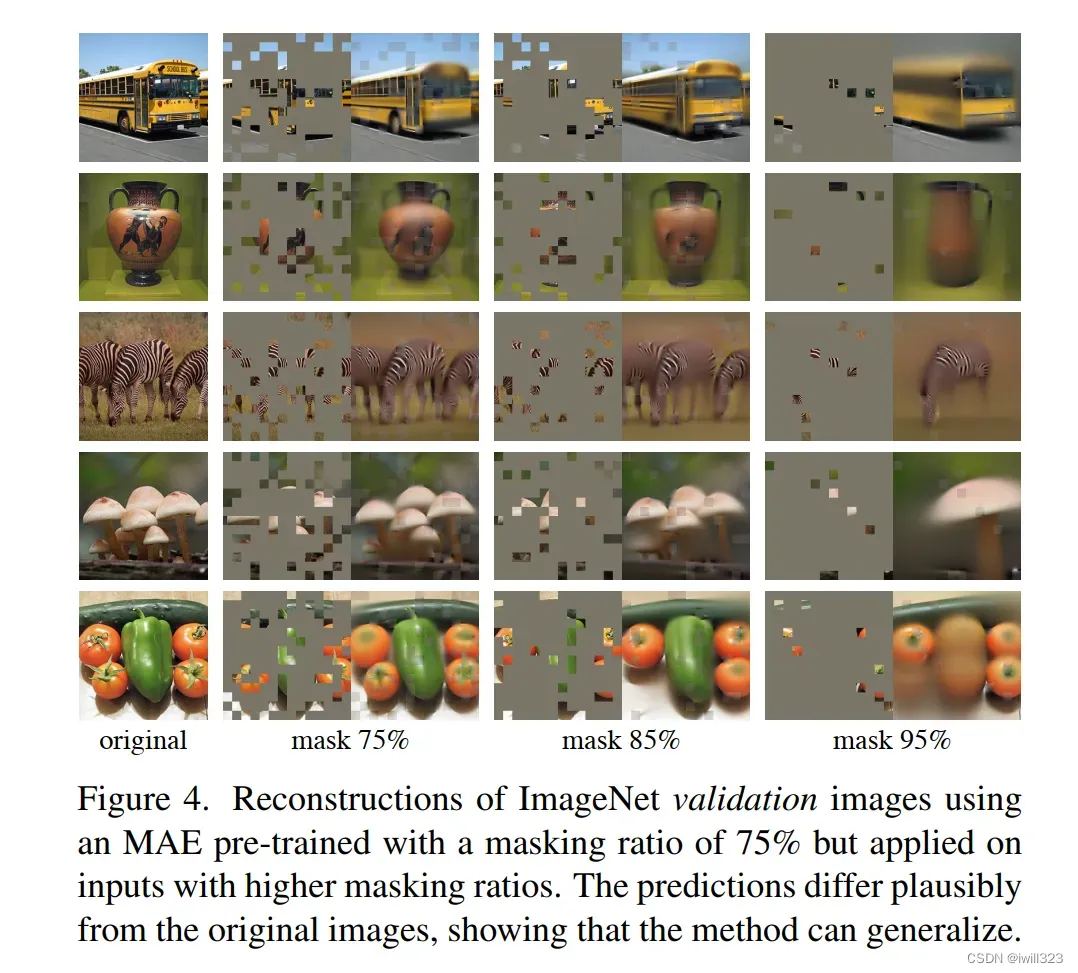
图四演示的是对同一张图片遮盖不同比例的区域时的结果
- 可以看到即使mask比例达到95%,还是能还原出大致图像,很玄乎。
3 结论
简单且拓展很好的算法是整个深度学习的核心
- 简单:整个MAE是基于ViT,ViT是基于transformer,在ViT的基础上,本文所提出来的东西相对来说比较简单
- 拓展性很好:能够跑比较大的数据集
自监督学习在最近几年是比较火的,但是在计算机视觉中,还是主要靠有标号的数据作为训练。这篇文章的工作通过在ImageNet数据集上通过自编码器学习到可以媲美有标号的时候的效果,所以是一个非常强有力的工作。
需要注意到的是图片和语言之间的一些区别,因为本文可以认为是BERT在计算机视觉上的拓展。对于语言来说,一个词是一个语义的单元,它里面所包含的语义信息比较多,在图片中虽然一个patch也含有一定的语义信息,但它不是语义的分割(也就是说这个patch中并不含有特定的物体),但是即使是在这样的情况下,MAE也能做很复杂的一些任务。作者认为MAE或者说是transformer确实能够学到隐藏的比较好的语义表达。
最后一段讲的是broder impacts
- 因为只用了图片本身的信息去进行学习,如果图片里面有bias,就可能有一些负面的社会影响
- 这个模型可以用来生成不存在的内容,所以它和GAN一样确实可能误导大家,所以这个工作如果想用在更多的地方的时候,一定要去考虑这些潜在的影响
4 导言
深度学习在过去一些年里有飞快的进展,但是对于计算机视觉来讲,还是依赖于需要百万级别的、甚至是更多的带有标注的图片。在自然语言处理中,自监督学习已经做的非常好了,比如BERT,可以使用没有标注的数据训练得到千亿级别的可学习参数的模型
在计算机视觉中,使用带掩码的自编码也不是那么新鲜,比如denoising autoencoder,在一个图片中加入很多噪音,然后通过去噪来学习对这个图片的理解。最近有很多工作将BERT拓展到计算机视觉上面,但是BERT在计算机视觉上的应用是落后于NLP的。
为何masked自编码模型在CV和NLP领域应用不一样
- 架构差异
之前的CV领域都是用的CNN网络,而CNN中的卷积,是不好做掩码操作的,因为卷积核滑动时,无法识别遮盖的边界,不好将masked patches单独剔除,导致后面不好将图片还原(Transformer中,和其他词区分开来)。但是作者说,ViT成功将Transformer应用到计算机视觉领域,所以这个问题不再有了。
- 信息密度(information density)不同
在自然语言中,一个词就是一个语义的实体,比如说字典中对一个词的解释就是很长的一段话,所以一句话中很难去去掉几个词(这样做完形填空才有意义)。
在图片中,像素是比较冗余的,取决于相机的分辨率有多大。如果只是简单去掉一些块的话,很有可能通过邻居的像素值进行插值还原出来。
作者的做法是,mask很高比例的像素块(比如75%),将图片中一大片都去掉, 剩下的块离得比较远,他们跟这个块的关系就不那么冗余了,大大降低图片的冗余性。这样的话就创造了一个非常有挑战性的任务,压迫模型必须学习全局信息,而不是仅仅学一个局部模型就可以进行插值还原。
关于此点论证,看上面图2.3.4就可以发现:仅仅一些局部的,很稀疏的块,就可以重构全局图片。
- 解码差异
NLP中需要预测masked tokens,token本身就是一种比较高级一些的语义表示,而来自编码器的特征也是高度语义的,与需要解码的目标之间的 gap 较小,所以只需要一个简单的全连接层就可以解码这些tokens。ViT最后需要的是图片特征,所以也只需要MLP就可以解码
MAE中需要还原the missing pixels,这些像素是比较低层次的表示,所以一个MLP可能是不够的。在图片分类、目标检测等任务上,输出层,也就是解码器,就是一个全连接层就够了;要将自编码器的高级语义特征解码至低级语义层级,比如语义分割对每个像素做像素级别的输出,需要比较复杂的转置卷积网络才能完成解码。
正是基于以上分析,作者才提出本文的两个核心设计:高掩码率以及非对称编-解码器。
实验结果
使用了MAE预训练之后,就可以只使用ImageNet-1K(100万数据)训练ViT large和ViThuge,达到在ViT中要使用100倍大小以上的训练数据才能做出来的效果,而且MAE预训练是不用标号的
而且在迁移学习上的效果也是很好的,MAE预训练出来的模型在物体检测、实例分割、语义分割上效果都非常好。也就是说在大量的没有标号的数据上通过自监督学习训练出来的模型。在迁移学习上效果也是非常不错的
5 相关工作
带掩码的语言模型
自编码器在视觉中的应用
- MAE其实也是一种形式上的带去噪的自编码,因为将图片中的某一块遮住,就等于是在图片中加入了很多噪音,但是它跟传统的DAE(Denoising autoencoder)不太一样,因为它毕竟基于ViT
带掩码的编码器在计算机视觉中的应用
- 本文不是第一个做这个工作的,之前已经有很多工作了。比如说iGPT就是GPT在image上的应用;ViT的论文在最后一段也讲了怎样用BERT来训练模型;另外还有BEiT,它也是BERT在image上的应用,它和MAE的不同之处在于,它对每一个patch都给了一个离散标号,更接近于BERT,但是在MAE中直接还原的是原始的像素信息
自监督学习
比如最近一两年特别火的contrast learning,它在这一块主要使用的是数据增强,而MAE所用的和它不一样
6 MAE模型
MAE跟所有的编码器一样,将观察到的信号映射到一个latnet representation(潜表示)中,这个潜表示可以认为是语义空间上的表示,然后再通过解码器将这个潜表示用来重构出原始的信号。与经典的自动编码器不同,我们采用了一种非对称设计,自编码器看到了部分数据,然后用它来重构完整的原始信号,模型设计图如下:
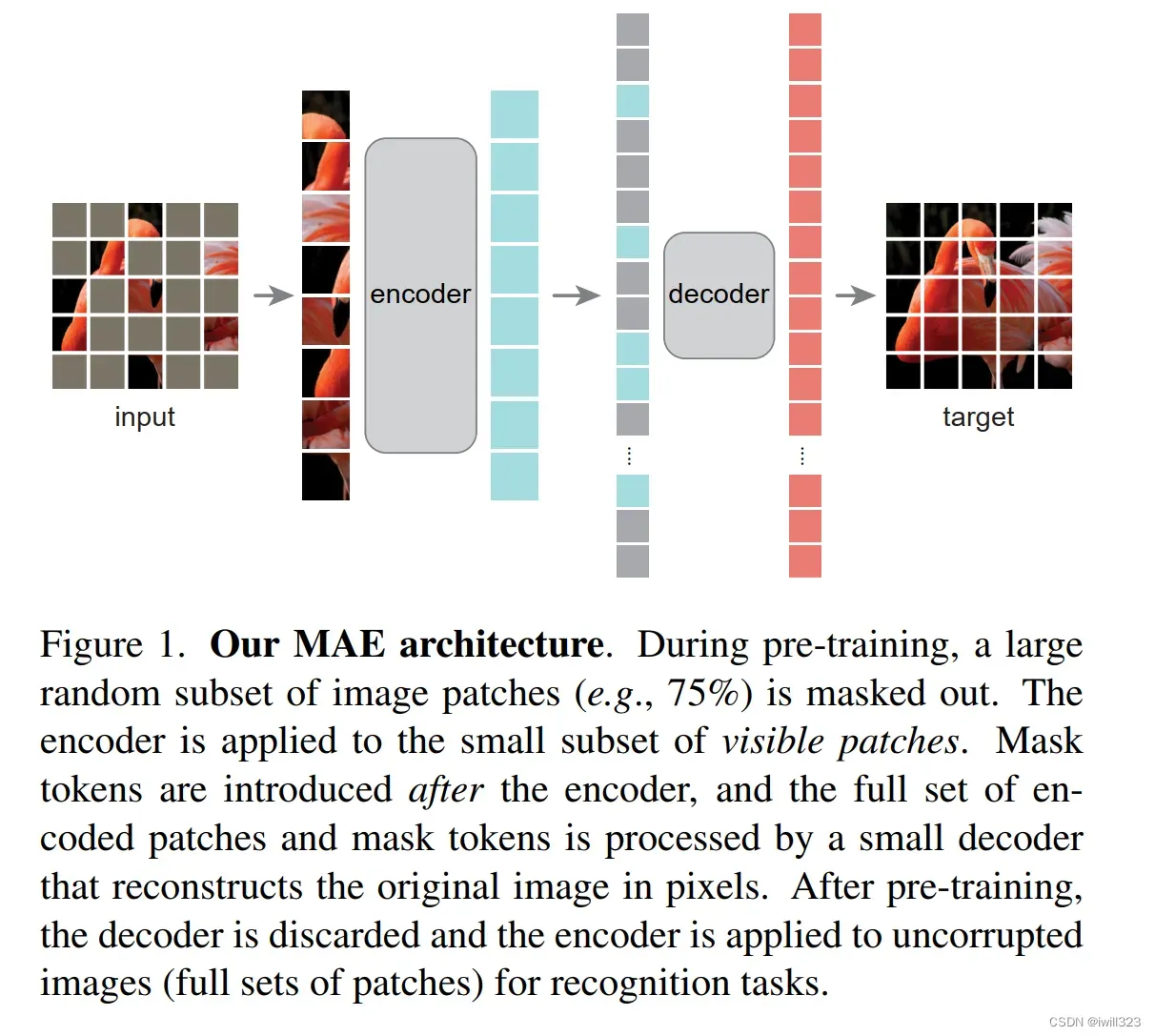
掩码是如何工作的
- 随机均匀采样:在不替换的情况下,按照均匀分布对patches进行随机采样,采到的样本保留,剩下的全部mask掉。
- 采样少量的块,使得它们的冗余度不是很高,任务就不是那么简单(不会说是用简单的插值就能解决问题了)
编码器
- 没有做任何改动的vit,只作用于可见的那些块中,具体的做法跟vit是一样的:对每一块做线性的投影,再加上位置信息,作为输入
- 被盖住的patch就不会进去了。如果有25%被选中,那么进入vit的话就只有25%的样本,降低计算量
解码器
- 需要看到所有的块,包括没有被盖住的块(已经通过编码器表示成了潜表示)和被盖住的块(没有进入编码器)
- 对被盖住的块,解码器通过同一个向量来表示,这个向量通过学习得到
- 解码器其实就是另外一个transformer,所以需要加入位置信息,不然就无法区分它对应的到底是哪一个是掩码(这里有一点不确定:要不要对那些编码器输出的潜表示也加上位置信息,因为它们其实已经加上过一次了,那么这个地方要不要再加上一次?)
- 解码器主要只在预训练的时候使用,当将模型用于做一些别的任务的时候,只需要用编码对一个图片进行编码就可以了
- 解码器的架构比较小,计算开销不到编码器的1/10
怎样重构出原始的像素
- 解码器的最后一层是一个线性层。如果所切割成的一块中是16*16的像素的话,那么这个线性层就会投影到长为256的这样一个维度,再reshape成16*16,就能还原出原始的像素信息了
- 损失函数使用的是MSE。预测和原始的真正的像素相减再平方。只在被盖住的那些块上面使用MSE
- 对要预测的像素值做一次normalization。对每一个块里面的像素使它的均值变为0、方差变为1,使得在数值上更加稳定一点(这里并没有写清楚在预测的时候怎么办,在训练的时候当然知道标号的那些东西,可以把均值和方差算出来,但是预测的时候呢)
简单实现
- 将图像划分成 patches:(B,C,H,W)->(B,N,PxPxC);
- 对各个 patch 进行 embedding(实质是通过全连接层),生成 tokens,并加入位置信息(position embeddings):(B,N,PxPxC)->(B,N,dim);
- 随机均匀采样。将序列随机打乱(shuffle),前25%作为unmask tokens 输入 Encoder,后面的丢掉
- 编码后的 tokens 与 masked tokens( 可以学习的向量,加入位置信息)unshuffle,还原到原来的顺序,然后喂给 Decoder。
- 如果 Encoder 编码后的 token 的维度与 Decoder 要求的输入维度不一致,则需要先经过 linear projection 将维度映射到符合 Decoder 的要求
- Decoder 解码后取出 masked tokens 对应的部分送入到全连接层,对 masked patches 的像素值进行预测,最后将预测结果(B,N’,PxPxC)与 masked patches 进行比较,计算 MSE loss。
7、实验
- 在ImageNet-1K数据集(100万张数据集)上先做自监督的预训练,然后在同样的数据集上做有标号的监督训练
- 两种做法
- end to end的微调:允许该整个模型所有的可学习的参数
- linear probing:只允许改最后一层的线性输出层
- 在验证集上报告top1的精度,所使用的是中心剪裁的24*24的图片,基线用的是vit large(vit-l/16,16表示的是图片块是16*16的)。vit-l是一个非常大的模型,很容易overfitting
ImageNet实验
下图表格中比较的是三种情况
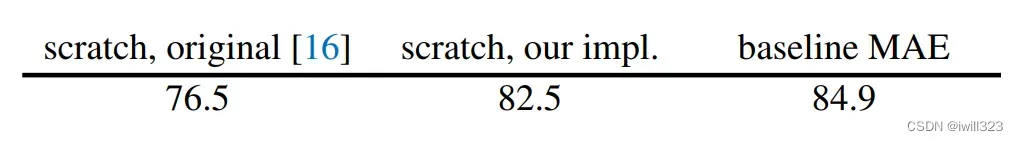
- scratch,original:ViT-L/16模型在ImageNet-1k上从头训练,效果其实不是很稳定。(200epoch)
- scratch,our impl.:ViT-L/16加上比较强的正则,从72.5提升到了82.5(详见附录A2)。
- VIT原文中一直说需要很大的数据集才预训练出好的模型,但是后来大家发现,如果加入合适的正则项,在小一点的数据集上(ImageNet-1k)也能够训练出好的效果。
- baseline MAE:先使用MAE做预训练,然后在ImageNet上做微调,这时候就不需要训练完整的200个epoches,只需要50个就可以了,从82.5提升到了84.9
- 因为数据集并没有发生变化(预训练和后面的微调都是用的ImageNet),这就表示MAE能够从图片上也能学到不错的信息,使得后面有所提升
深度宽度变化/mask策略/数据增强
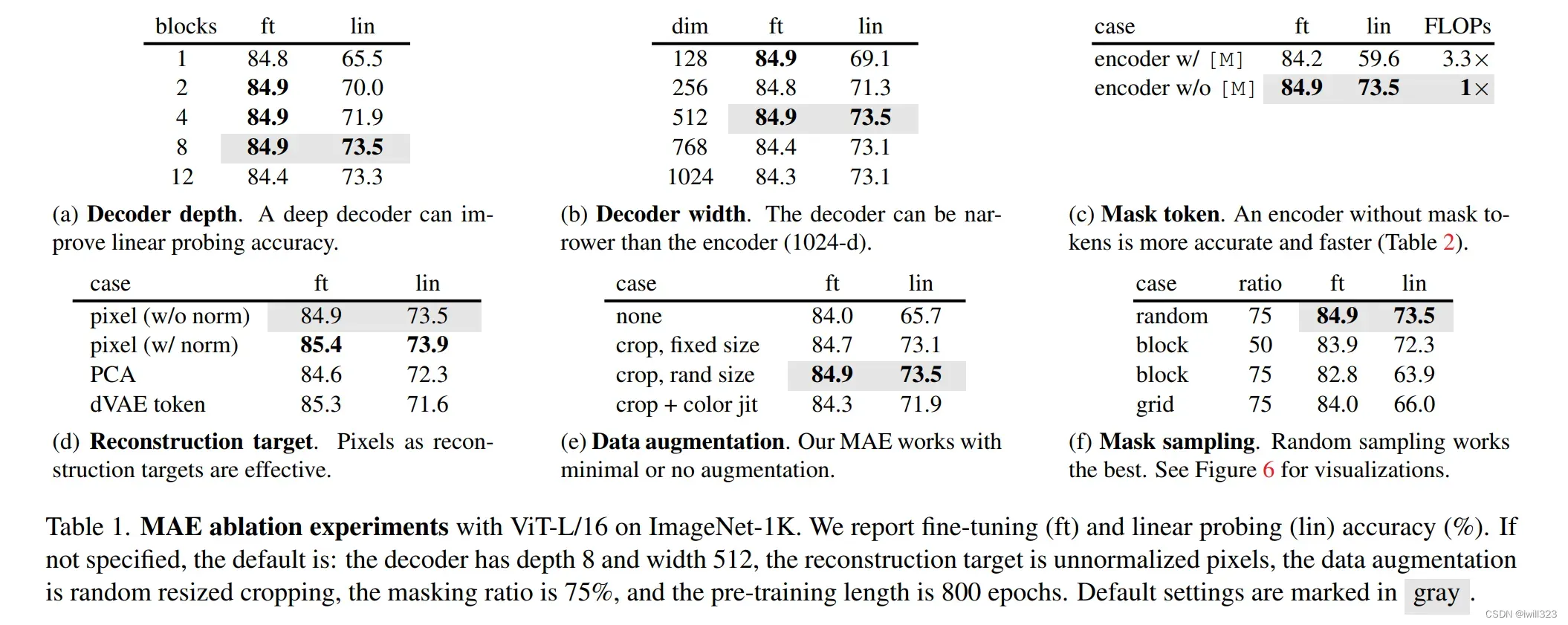
- 每个子表中,第一列(ft)表示所有可以学习的权重都跟着调,第二列(lin)表示只调最后一个线性层。
- 表a讲的是解码器的深度(需要用到多少个transformer块)。可以发现ft方式虽然比较贵,但是效果会好很多。使用8块比较好,不过解码器深度关系并不是很大,都是84左右。如果只调最后一层的话,用深一点的会比较好
- 表b讲的是解码器的宽度(每个token表示成一个多长的向量),512比较好
- 表c讲的是在编码器中要不要加入被盖住的那些块。结果显示,不加入被盖住的那些块,精度反而更高一些,而且计算量更少(降低3.3倍)。所以本文采用的非对称的架构,不仅是在性能上更好,在精度上也更好一些
- 表d讲的是重建目标对比。
- 第一行:MAE现行做法
- 第二行:预测时对每个patch内部做normalization,效果最好。
- 第三行:PCA降维
- 第四行:BEiT的做法,通过vit把每一块映射到一个离散的token上面再做预测。
- 从表中可以发现,在fine-tune的话,值都是差不多的,所以在值差不多的情况下,当然是倾向于使用更简单的办法
- 表e讲的是如何做数据增强。none表示什么都不做,第二行表示只裁剪(固定大小),第三行表示按照随机的大小裁剪,最后一行表示再加上一些颜色的变化。从表中可以发现,做简单的随即大小的裁剪,效果就已经很不错了,所以作者说MAE对于数据的增强不那么敏感
- 表f讲的是采样策略。随机采样,按块采样,按网格采样。发现随机采样这种做法最简单,效果也最好

mask比例
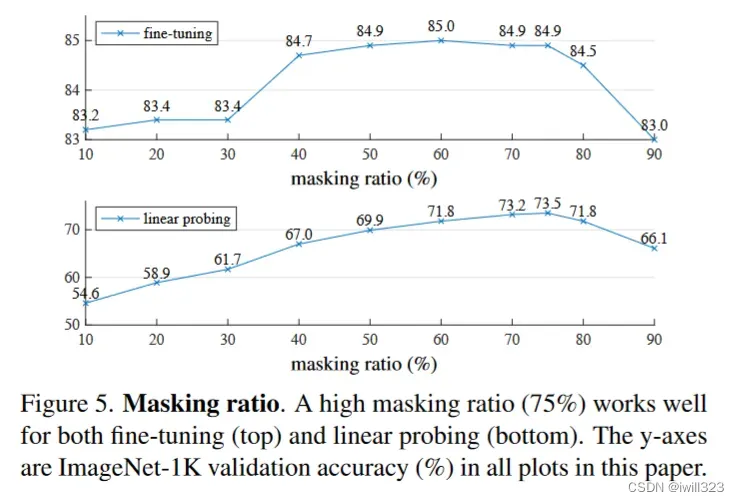
掩码率越大,不管是对fine-tune也好,还是对于只调最后一层来讲也好,效果都是比较好的。特别是只调最后一层的话,对掩码率相对来讲更加敏感一点
训练时间
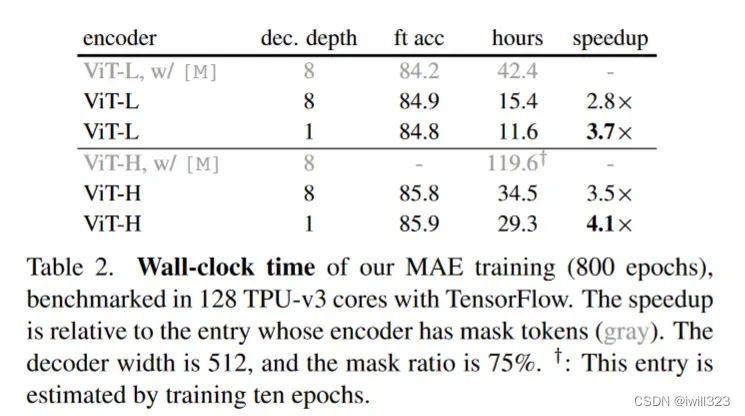
表中使用vit-large而且解码器只使用一层transformer块的时候,精度也是不错的,时间是最小的,和第一行(使用所有的带掩码的块)相比,加速是3.7倍。如果是vit-huge的话,加速时间也是比较多的
绝对时间:这里使用的是128个TPU v3的core,而且使用的是tensorflow实现,训练的时间是10个小时
预训练的轮数
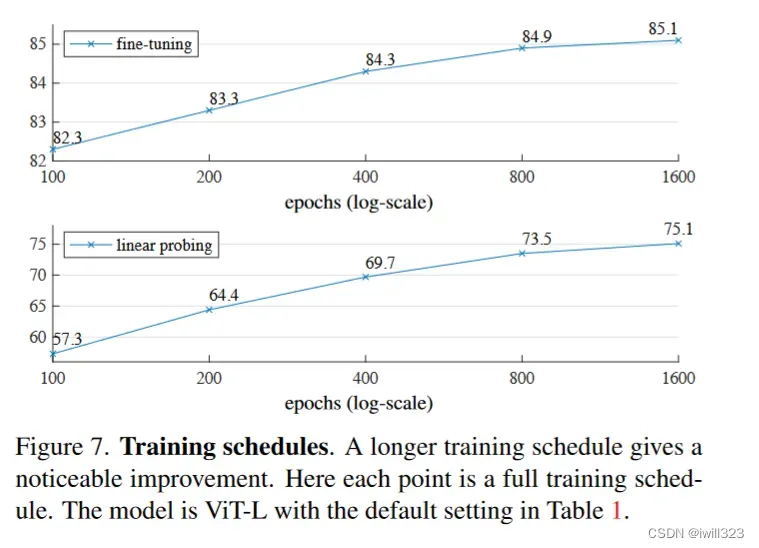
图中可以看到,在ImageNet-1k上训练1000个数据轮的话,能够看到精度的提升,这也是一个非常不错的性质,说明在一直训练的情况下,过拟合也不是特别严重(1000轮其实是非常多的,一般在ImageNet上训练200轮就差不多了)
跟前面一些工作对比
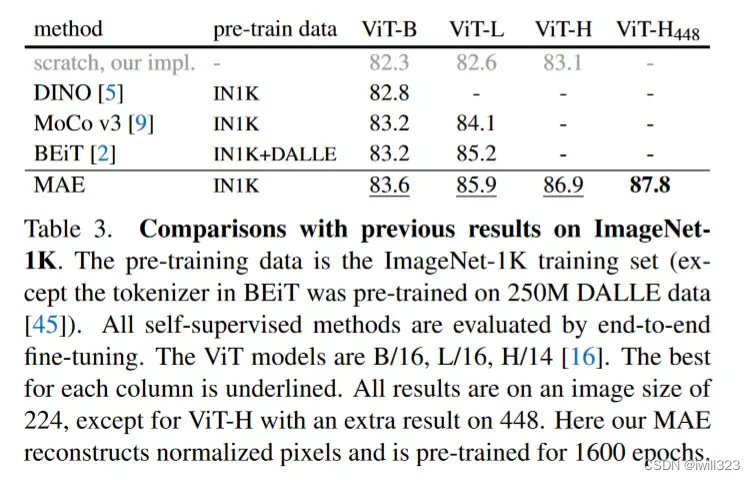
基本上MAE的效果是最好的
微调层数对比

预训练模型做微调的效果是比只做特征提取的效果更好的,但是训练时间会更长。所以作者试验了一下,微调不同的层数,模型的效果如何。
上图中,x轴表示的是有多少个transformer块要被调(这些层参数可以训练,剩下层被冻结),y轴表示的是精度。
可以看到,MAE基本只需要微调最后4层就可以了。这表示底部层学到的东西稍微是比较低层次一点,在换另外一个任务的时候也不需要变化太多,但是上面的层还是和任务比较相关的,最好还是做一些调整
迁移学习的效果
下图中的表四和表五做的是COCO数据集上的目标检测和分割
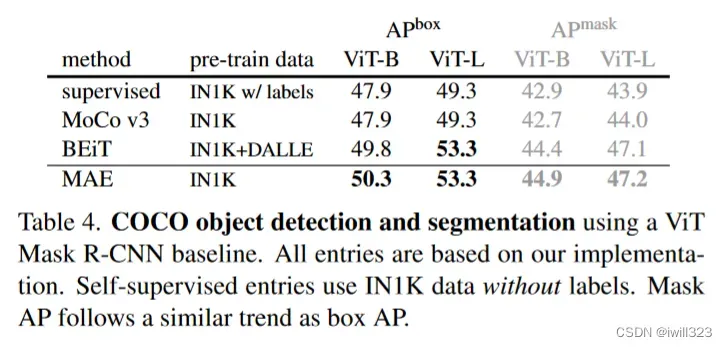
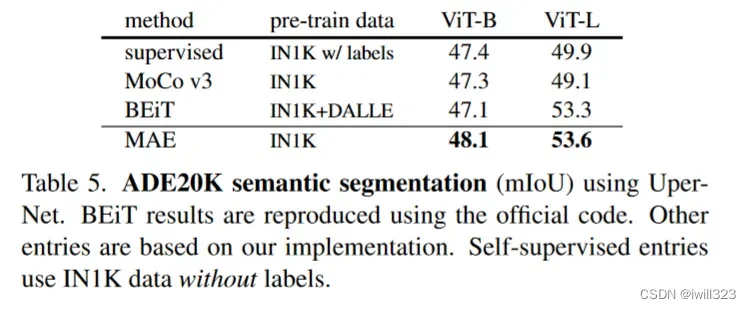
从表四中可以发现用MAE当作主干网络之后效果是最好的
9 评论
MAE的算法还是非常简单的,就是利用vit来做和BERT一样的自监督学习,本文在vit基础之上提出了两点
- 第一点是需要盖住更多的块,使得剩下的那些块,块与块之间的冗余度没有那么高,这样整个任务就变得复杂一点
- 第二个是使用一个transformer架构的解码器,直接还原原始的像素信息,使得整个流程更加简单一点
- 第三个是加上vit工作之后的各种技术,使得它的训练更加鲁棒一点
以上三点加起来,使得MAE能够在ImageNet-1k数据集上使用自监督训练的效果超过了之前的工作
文章出处登录后可见!