
网络工程师Python数据存储(第1节,CSV文件)
网络自动化运维演进的一个方向大致过程:网络工程师从关注配置制作脚本,完成后上设备刷配置,慢慢地演化为网络工程师关注和确定设备配置的某些重要控制参数,而把制作脚本任务交给Jinja2等去渲染生成,把下发脚本工作交由nornir等去完成。也就是说,网工从设备运维有转向数据运维的前景。
当然,演进过程溯洄从之,道阻且跻,溯游从之,宛若从入门到放弃。我觉得只能不紧急的时候多做点重要的事情,才能慢慢积累沉淀,沿途拾起几块属于自己的自动化碎片~发现那早已是遗落的感伤,于是挥挥衣袖,继续赶路~。
那么,数据运维中的数据存在哪,以什么形式存,怎么存放,怎么取用?接下来我将梳理一点关于Python数据存储的内容。这篇我们先来促促CSV文件。
〇、参考说明
文章出自:网络工程师Python数据存储(第1节,CSV文件)
如果你不知道从何读起,建议从这篇《目录》开始,连接如下:
【网工手艺】专栏入口(总目录 | 我全开源写作 | 你别买盗版书)
本文部分参考书籍《Python for network engineers》,纯英文,推荐移步阅读。
本文长期维护,欢迎参与勘误(包括知识点,错别字,文字表述)。
如有侵权行为,可私信删除
一、背景简介
一名网络工程师出差,能一直在机房或网管后台吗?当然不能,还得住酒店歇息啊。同理,Python处理的数据,总不能老待在程序内存中,最终得存储放置进硬盘的!那么以什么形式存放进硬盘呢?多数是结构化数据,如Python中的pickle(泡菜杂坛子)类、CSV、JSON、YAML形式,当然还有强大的数据库系统。
鉴于pickle是Pyhon特有内置形式,目前较少与其它系统直接对接;数据库系统又稍庞大,可能能单开一个系列来梳理。所以,这系列我们先聚焦CSV、JSON、YAML形式吧。
此次,我们先重点关注CSV吧。CSV说白了就是一种结构化的表格。表格大家都很熟悉了,如excel一打开就是一个表。结构化呢?简单理解就是,打开的excel表格您千万不要这里合并一下单元格,合并单元格操作,会破坏表的结构,它就失去结构化了。当然,我这么表述可能不严谨,关键是让你能有热乎乎的感受。
CSV (comma-separated value),顾名思义,逗号隔开的数据。这种数据从表格中获取,也可以从数据库中获取,可以用excel打开,还可以导入数据库。没错,它就是一种信息存储媒介。
二、CSV操作
2.1 初识CSV
在这种格式中,CSV文件中的一行,即是表格的一行。尽管它名字叫做“逗号分割数据”,但除了用逗号分割外,其实还可以使用其它的符号进行分割。使用不同符号分割的文件,文件名可能稍有不同,比如TSV(用制表符分割)。尽管如此,通常情况下,我们还是习惯性把他们都统称为“CSV”。
hostname,vendor,model,location
sw1,Huawei,5700,Beijing
sw2,Huawei,3700,Shanghai
sw3,Huawei,9300,Guangzhou
sw4,Huawei,9306,Shenzhen
sw5,Huawei,12800,Hangzhou
在Python的标准库中,有一个专门处理CSV文件的模块。题外话,啥叫“Python标准库”,就是您安装好Python后,无需再pip安装,就能直接import的那些库。
2.2 读取CSV
相对于其它IDE,我更倾向于用IDLE演示,因为只要安装Python了它就存在了,不用其它一些联调操作。此外,我还觉得它在很大程度上已经能满足网工Python行当里很多日常小应用了。
来,我们打开IDLE来敲指令。
使用下面这种形式的代码块。我可以有效防止你“偷懒”,直接把代码全部复制过去一run,以为自己就懂了。
这样的代码块,你只能自己手敲,至少只能一行一行复制。你只有自己敲起来,进而才能更好感受Python缩进等语法结构,从而真正入门。
你看我何等用心良苦,赶紧一起来敲吧。
>>> import csv
>>> csv_path = r'E:\***\csv-lab1.csv' #文件路径,可根据自己实际情况。
>>> with open(csv_path) as f:
reader = csv.reader(f)
for row in reader:
print(row)
['hostname', 'vendor', 'model', 'location']
['sw1', 'Huawei', '5700', 'Beijing']
['sw2', 'Huawei', '3700', 'Shanghai']
['sw3', 'Huawei', '9300', 'Guangzhou']
['sw4', 'Huawei', '9306', 'Shenzhen']
['sw5', 'Huawei', '12800', 'Hangzhou']
>>> 注意,csv.reader返回的是一个迭代器(iterator)。
>>> with open(csv_path) as f:
reader = csv.reader(f)
print(reader)
<_csv.reader object at 0x0000017F1B24CBA8>
>>> 如有需要,可以用list函数将这个迭代器处理成列表。
>>> with open(csv_path) as f:
reader = csv.reader(f)
print(list(reader))
[['hostname', 'vendor', 'model', 'location'], ['sw1', 'Huawei', '5700', 'Beijing'], ['sw2', 'Huawei', '3700', 'Shanghai'], ['sw3', 'Huawei', '9300', 'Guangzhou'], ['sw4', 'Huawei', '9306', 'Shenzhen'], ['sw5', 'Huawei', '12800', 'Hangzhou']]
>>> 通常情况下,表头需单独使用,可以特殊处理一下。
>>> with open(csv_path) as f:
reader = csv.reader(f)
headers = next(reader)
print('Headers: ',headers)
for row in reader:
print(row)
Headers: ['hostname', 'vendor', 'model', 'location']
['sw1', 'Huawei', '5700', 'Beijing']
['sw2', 'Huawei', '3700', 'Shanghai']
['sw3', 'Huawei', '9300', 'Guangzhou']
['sw4', 'Huawei', '9306', 'Shenzhen']
['sw5', 'Huawei', '12800', 'Hangzhou']
>>> 有时候,我们还需要表头信息与每一行的数据相结合,那此时可以用上字典数据类型。
>>> with open(csv_path) as f:
reader = csv.DictReader(f)
for row in reader:
# print(row)
print(row['hostname'],row['model'])
sw1 5700
sw2 3700
sw3 9300
sw4 9306
sw5 12800为了简洁一点,print(row)代码行,被我注释了。如若你有兴趣,可去掉注释行再运行试试。
2.3 写入CSV(writerow)
我们已体验了CSV的读取操作,并不难吧?那CSV的写入操作如何呢?我们马上来尝试一下。
>>> import csv
>>> data = [['hostname','vendor','model','location'],
['sw1','Huawei','5700','Beijing'],
['sw2','Huawei','3700','Shanghai'],
['sw3','Huawei','9300','Guangzhou'],
['sw4','Huawei','9306','Shenzhen'],
['sw5','Huawei','12800','Hangzhou']]
>>> csv_path = r'E:\……\csv-lab1-writing.csv' #存放文件路径,可根据自己实际情况。
>>> with open(csv_path,'w',newline='') as f:
writer = csv.writer(f)
for row in data:
writer.writerow(row)回车后,后面会有一些杂杂的返回,属于干扰项无需理会,我们关注的是生成CSV文件。
注意几点:
- 参数
w,表示写入,不加则默认是读r。 newline='',不加这个参数的话,结果会有冗余的空行,可以尝试一下。- 如果有中文等,可能还要留意编解码问题,否则容易出现乱码。
文件生成之后,回过头来,我们同样可以用Python脚本来读取。
>>> with open(csv_path) as f:
print(f.read())
hostname,vendor,model,location
sw1,Huawei,5700,Beijing
sw2,Huawei,3700,Shanghai
sw3,Huawei,9300,Guangzhou
sw4,Huawei,9306,Shenzhen
sw5,Huawei,12800,Hangzhou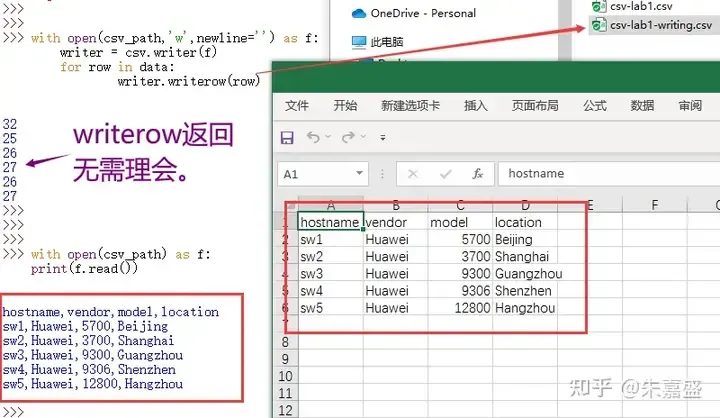
2.4 写入CSV(文本带逗号)
>>> import csv
>>> data = [['hostname','vendor','model','location'],
['sw1','Huawei','5700','Beijing,Xicheng'],
['sw2','Huawei','3700','Shanghai'],
['sw3','Huawei','9300','Guangzhou,Tianhe'],
['sw4','Huawei','9306','Shenzhen'],
['sw5','Huawei','12800','Hangzhou']]
>>> csv_path = r'E:\……\csv-lab1-writing.csv' #存放文件路径,可根据自己实际情况。
>>> with open(csv_path,'w',newline='') as f:
writer = csv.writer(f)
for row in data:
writer.writerow(row)现在我们把'Beijing'改成了'Beijing,Xicheng',把'Guangzhou'改成了'Guangzhou,Tianhe'。请注意观察交互执行结果。

有意思吧?'Beijing,Xicheng'和'Guangzhou,Tianhe'这两处print时,自动戴上了“小耳朵”。
这是因为,字符串中本身有逗号,为了避免歧义,被当做分割符,所以csv模块自动做了特殊处理。
干脆,全部都戴上“小耳朵”吧,参数quoting=csv.QUOTE_NONNUMERIC来帮忙。
>>> with open(csv_path,'w',newline='') as f:
writer = csv.writer(f,quoting=csv.QUOTE_NONNUMERIC)
for row in data:
writer.writerow(row)
40
41
34
42
34
35
>>>
>>>
>>> with open(csv_path) as f:
print(f.read())
"hostname","vendor","model","location"
"sw1","Huawei","5700","Beijing,Xicheng"
"sw2","Huawei","3700","Shanghai"
"sw3","Huawei","9300","Guangzhou,Tianhe"
"sw4","Huawei","9306","Shenzhen"
"sw5","Huawei","12800","Hangzhou"
>>> 只要是字符串类型的,通通被括起来。
2.5 写入CSV(writerows)
除方法writerow外,我们还可以用方法writerows。我们调整一下原先的例子。
>>> import csv
>>> data = [['hostname','vendor','model','location'],
['sw1','Huawei','5700','Beijing,Xicheng'],
['sw2','Huawei','3700','Shanghai'],
['sw3','Huawei','9300','Guangzhou,Tianhe'],
['sw4','Huawei','9306','Shenzhen'],
['sw5','Huawei','12800','Hangzhou']]
>>> csv_path = r'E:\……\csv-lab1-writing.csv' #存放文件路径,可根据自己实际情况。
>>> with open(csv_path,'w',newline='') as f:
writer = csv.writer(f,quoting=csv.QUOTE_NONNUMERIC)
writer.writerows(data)
>>> with open(csv_path) as f:
print(f.read())
"hostname","vendor","model","location"
"sw1","Huawei","5700","Beijing,Xicheng"
"sw2","Huawei","3700","Shanghai"
"sw3","Huawei","9300","Guangzhou,Tianhe"
"sw4","Huawei","9306","Shenzhen"
"sw5","Huawei","12800","Hangzhou"
>>> 脚本正常执行后,在实验文件夹中,会重新生成文件。截图略。
看起来会不会简洁很多呢?证明writerows更好吗?Nonono,这些都是工具。工具并没有好坏之分。小刀大炮各有厉害之处,需要要适配具体的使用场景。
2.6 写入CSV(DictWriter)
我们还可以使用方法DictWriter,把字典类型的数据,直接写入到CSV文件。
DictWriter操作起来与writer类似, 但是,字典类型是无序的(确切地说,Python3.6之后字典类型就是有序的,但在我的应用范围内,我一直把它当成无序的来理解)。所以,我们又得引入一个参数fieldnames,来标识顺序。
>>> import csv
>>> data = [{
'hostname': 'sw1',
'location': 'Beijing,Xicheng',
'model': '5700',
'vendor': 'Huawei'
}, {
'hostname': 'sw2',
'location': 'Shanghai',
'model': '3700',
'vendor': 'Huawei'
}, {
'hostname': 'sw3',
'location': 'Guangzhou,Tianhe',
'model': '9300',
'vendor': 'Huawei'
}, {
'hostname': 'sw4',
'location': 'Shenzhen',
'model': '9306',
'vendor': 'Huawei'
}, {
'hostname': 'sw5',
'location': 'Hangzhou',
'model': '12800',
'vendor': 'Huawei'
}]
>>>
>>> csv_path = r'E:\……\csv-lab1-writing.csv' #存放文件路径,可根据自己实际情况。
>>>
>>> with open(csv_path,'w',newline='') as f:
writer = csv.DictWriter(
f, fieldnames=list(data[0].keys()),quoting=csv.QUOTE_NONNUMERIC)
writer.writeheader()
for d in data:
writer.writerow(d)
41
34
42
34
35
>>> with open(csv_path) as f:
print(f.read())
"hostname","location","model","vendor"
"sw1","Beijing,Xicheng","5700","Huawei"
"sw2","Shanghai","3700","Huawei"
"sw3","Guangzhou,Tianhe","9300","Huawei"
"sw4","Shenzhen","9306","Huawei"
"sw5","Hangzhou","12800","Huawei"
>>> 这种看起来稍微有点绕,我们要把我一点,fieldnames是来控制表头的顺序的,比如第一项是hostname,最后一项是vendor。
2.7 自定义分割符(dictwriter)
我前面已提及TSV,分割符自然可以是其它的。
此时,需要参数delimiter来帮忙。

>>> import csv
>>> csv_path = r'E:\***\csv-lab1.csv' #文件路径,可根据自己实际情况。
>>> with open(csv_path) as f:
reader = csv.reader(f)
for row in reader:
print(row)
['hostname:vendor:model:location']
['sw1:Huawei:5700:Beijing']
['sw2:Huawei:3700:Shanghai']
['sw3:Huawei:9300:Guangzhou']
['sw4:Huawei:9306:Shenzhen']
['sw5:Huawei:12800:Hangzhou']
>>>
>>>
>>> with open(csv_path) as f:
reader = csv.reader(f, delimiter=':')
for row in reader:
print(row)
['hostname', 'vendor', 'model', 'location']
['sw1', 'Huawei', '5700', 'Beijing']
['sw2', 'Huawei', '3700', 'Shanghai']
['sw3', 'Huawei', '9300', 'Guangzhou']
['sw4', 'Huawei', '9306', 'Shenzhen']
['sw5', 'Huawei', '12800', 'Hangzhou']
>>> 本实验,我们用冒号做分隔符,因而需指定参数delimiter;如若不指定,默认分割符为逗号。
三、本文总结
CSV在运维各种应用系统中,常被作为数据导出导入的媒介,比如告警信息,资源表,日志等。
Python的csv模块相当于一个API,让我们可以通过脚本,调取到存放在硬盘中CSV文件里的数据,随后将其放入内存,进行数据处理,加工。数据处理之后,如果你暂时不知道要用什么形式进行存储,那就还用CSV吧。



网络工程师的Python之路:网络运维自动化实战(第2版
京东
¥93.60
去购买



我读过的书、用过的物(持续更新)
文章出处登录后可见!