
写在前面
Informer模型来自发表于AAAI21的一篇best paper《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》。Informer模型针对Transformer存在的一系列问题,如二次时间复杂度、高内存使用率以及Encoder-Decoder的结构限制,提出了一种新的思路来用于提高长序列的预测问题。下面的这篇文章主要带大家使用作者开源的Informer代码,并将其用于股票价格预测当中。
1
Informer模型
近年来的研究表明,Transformer具有提高预测能力的潜力。然而,Transformer存在几个严重的问题,使其不能直接适用于长期时序预测问题,例如二次时间复杂度、高内存使用量和编码器-解码器体系结构固有的局限性。为了解决这些问题,这篇文章中设计了一种基于Transformer的长期时序预测模型,即Informer模型,该模型具有三个显著特征:
-
一种ProbSpare self-attention机制,它可以在时间复杂度和空间复杂度方面达到 。
-
self-attention机制通过将级联层输入减半来突出主导注意,并有效地处理过长的输入序列。
-
生成式解码器虽然概念简单,但对长时间序列序列进行一次正向操作而不是step-by-step的方式进行预测,这大大提高了长序列预测的推理速度。
并且,在4个大规模数据集上的大量实验表明,Informer方法显著优于现有方法,为长期时序建模问题提供了一种新的解决方案。
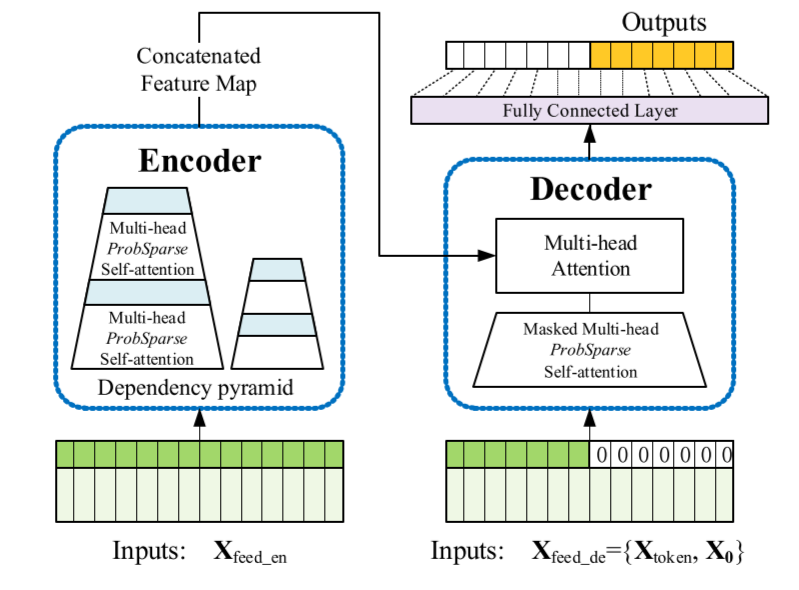
文中提出的模型的整体框架如下图所示,可以看出提出的Informer模型仍然保存了Encoder-Decoder的架构:
Self-attention mechanism
首先,传统的self-attention机制输入形式是 ,然后进行scaled dot-product。第i个Query的attention系数的概率形式是:
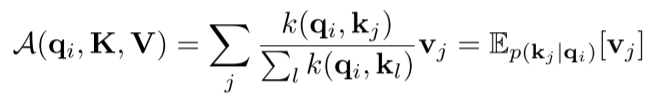
self-attention机制要求二次时间复杂度的点积运算来计算上面的概率 ,计算需要 的空间复杂度。因此,这是提高预测能力的主要障碍。另外,之前的研究发现,self-attention的概率分布具有潜在的稀疏性,并对所有的 都设计了一些“选择性”的计数策略,而不显著影响性能。因此,作者首先对典型的self-attention的学习模式进行定性评估。“稀疏性” self-attention的分布呈长尾分布,即少数点积对主要注意有贡献,其他点积对可以忽略。那么,下一个问题是如何区分它们?
为了度量query的稀疏性,作者用到了KL散度。其中第i个query的稀疏性的评价公式是:
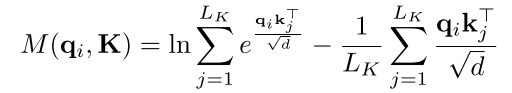
其中第一项是 对于所有的key的Log-Sum-Exp (LSE),第二项是它们的算数平均值。
基于上面的评价方式,就可以得到ProbSparse self-attetion的公式,即:
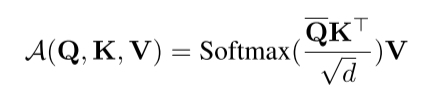
其中, 是和 具有相同尺寸的稀疏矩阵,并且它只包含在稀疏评估 下top-u的queries。其中,u的大小通过一个采样参数来决定。这使得ProbSparse self-attention对于每个query-key只需要计算 点积操作。另外经过文章Lemma 1的证明,其对稀疏评估进行了上边界的计算,从而保证了计算的时间和空间复杂度为 。
Encoder
Encoder的设计目的是提取长序列输入的远期依赖性。作为ProbSpare自注意机制的结果,encoder的特征映射存在值V的冗余组合,因此,这里利用distilling操作对具有主导特征的优势特征进行赋予更高权重,并在下一层生成focus self-attention特征映射。从j到j+1层的distilling操作的过程如下:
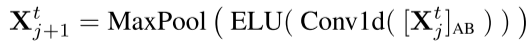
其中, 包含了multi-head probsparse self-attention以及在attention block中的关键操作。Conv1d表示时间序列上的一维卷积操作,并通过ELU作为了激活函数。
Decoder
Decoder部分中使用了一个标准的decoder结构 (Vaswani et al. 2017),它由两个相同的多头注意层组成。另外,生成推理被用来缓解长期预测的速度下降。我们向decoder提供如下输入向量:
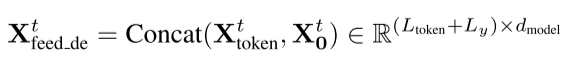
其中,将masked multi-head attention应用于probsparse self-attention的计算中。它防止每个位置都注意到下一个位置,以此避免了自回归。最后,一个全连接层获得最终的输出,它的输出维度取决于我们是在进行单变量预测还是多变量预测。
Loss Function
模型选取MSE作为loss function以将decoder的输出与目标序列的误差进行反向传播。
2
环境配置
本地环境:
Python 3.7
IDE:Pycharm库版本:
numpy 1.18.1
pandas 1.0.3
sklearn 0.22.2
matplotlib 3.2.1
torch 1.10.1Informer源码Github链接:https://github.com/zhouhaoyi/Informer2020
3
代码实现
首先将Informer的源码下载到本地,然后将我们的数据集放到某个路径下,这里用到了上证指数14到17年四年的开高低收成交量数据。在将Informer的代码用于我们的股票数据预测任务时,由于我们的任务是基于高低收成交量来预测收盘价,这是一个多变量输入,单变量输出的预测任务。所以主要需要修改下面几个参数的设置。针对其他不同预测任务要求,如增加某些特征,预测多个目标变量等则可通过修改features,target,enc_in,dec_in以及c_out参数进行实现。
-
data:设置为custom,用于调用Dataset_Custom类,从而可以自定义数据集。
-
root_path:指定数据集存放的文件夹。
-
data_path:指定csv数据集的名称。
-
features:设置为MS,这是因为我们是用开高低收成交量来预测收盘价,所以是多变量输出来预测单变量。
-
target:表示预测变量,设置为Close,对应我们csv文件预测变量的列名。
-
freq:表示预测频率,设置为d,因为我们用到的是日线级别的数据。
-
seq_len:表示输入encoder的序列长度,这里设置为20。
-
label_len:表示输入decoder中的token的长度,这里设置为10,即通过前10个真实值来辅助decoder进行预测。
-
pred_len:表示预测序列的长度,这里设置为5,即表示预测后5个时刻的序列值。
-
enc_in:表示encoder的输入维度,这里设置为5,因为我们用到了开高低收以及成交量5个特征。
-
dec_in:表示decoder的输入维度,同enc_in。
-
c_out:表示输出序列的维度,这里设置为1,因为我们的目标变量只有收盘价。
其他参数像模型层数,维度之类的可以根据自己的电脑配置进行修改。下面是进行上证指数预测实验的参数配置:
args = dotdict()
args.model = 'informer' # model of experiment, options: [informer, informerstack, informerlight(TBD)]
args.data = 'custom' # data
args.root_path = './data/stock/' # root path of data file
args.data_path = 'SH000001.csv' # data file
args.features = 'MS' # forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate
args.target = 'Close' # target feature in S or MS task
args.freq = 'd' # freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h
args.checkpoints = './checkpoints' # location of model checkpoints
args.seq_len = 20 # input sequence length of Informer encoder
args.label_len = 10 # start token length of Informer decoder
args.pred_len = 5 # prediction sequence length
# Informer decoder input: concat[start token series(label_len), zero padding series(pred_len)]
args.enc_in = 5 # encoder input size
args.dec_in = 5 # decoder input size
args.c_out = 1 # output size
args.factor = 5 # probsparse attn factor
args.padding = 0 # padding type
args.d_model = 256 # dimension of model
args.n_heads = 4 # num of heads
args.e_layers = 2 # num of encoder layers
args.d_layers = 1 # num of decoder layers
args.d_ff = 256 # dimension of fcn in model
args.dropout = 0.05 # dropout
args.attn = 'prob' # attention used in encoder, options:[prob, full]
args.embed = 'timeF' # time features encoding, options:[timeF, fixed, learned]
args.activation = 'gelu' # activation
args.distil = True # whether to use distilling in encoder
args.output_attention = False # whether to output attention in ecoder
args.batch_size = 32
args.learning_rate = 0.0001
args.loss = 'mse'
args.lradj = 'type1'
args.use_amp = False # whether to use automatic mixed precision training
args.num_workers = 0
args.train_epochs = 20
args.patience = 3
args.des = 'exp'
# args.use_gpu = True if torch.cuda.is_available() else False
args.use_gpu = False
args.gpu = 0
args.use_multi_gpu = False
args.devices = '0,1,2,3'按照设置的参数,然后对模型进行训练跟测试:
Exp = Exp_Informer
#%%
# setting record of experiments
setting = '{}_{}_ft{}_sl{}_ll{}_pl{}_dm{}_nh{}_el{}_dl{}_df{}_at{}_fc{}_eb{}_dt{}_{}'.format(args.model, args.data, args.features,
args.seq_len, args.label_len, args.pred_len,
args.d_model, args.n_heads, args.e_layers, args.d_layers, args.d_ff, args.attn, args.factor, args.embed, args.distil, args.des)
# set experiments
exp = Exp(args)
# train
print('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting))
exp.train(setting)
# test
print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.test(setting)经过训练,可以看出模型的训练集上的loss不断下降,因为加入了early stop机制,所以经过8个epoch模型就停止训练了。经过在测试集上的测试,informer实现了0.021的mse跟0.123的mae(归一化后的结果)。需要注意的是,模型经过训练跟测试之后,会在当前路径的./checkpoints中保存模型参数,在./results/{settings}/下生成pred.npy以及true.npy文件用来分别存放测试集上的预测结果跟ground truth。
>>>>>>>start training : informer_custom_ftMS_sl20_ll10_pl5_dm256_nh4_el2_dl1_df256_atprob_fc5_ebtimeF_dtTrue_exp>>>>>>>>>>>>>>>>>>>>>>>>>>
train 659
val 95
test 191
Epoch: 1 cost time: 1.8236503601074219
Epoch: 1, Steps: 20 | Train Loss: 0.4227553 Vali Loss: 0.0319062 Test Loss: 0.0245216
Validation loss decreased (inf --> 0.031906). Saving model ...
Updating learning rate to 0.0001
Epoch: 2 cost time: 1.803605556488037
Epoch: 2, Steps: 20 | Train Loss: 0.1243612 Vali Loss: 0.0671695 Test Loss: 0.0823020
EarlyStopping counter: 1 out of 3
Updating learning rate to 5e-05
Epoch: 3 cost time: 1.8560359477996826
Epoch: 3, Steps: 20 | Train Loss: 0.0910275 Vali Loss: 0.0242387 Test Loss: 0.0311569
Validation loss decreased (0.031906 --> 0.024239). Saving model ...
Updating learning rate to 2.5e-05
Epoch: 4 cost time: 2.1183347702026367
Epoch: 4, Steps: 20 | Train Loss: 0.0757393 Vali Loss: 0.0215489 Test Loss: 0.0264782
Validation loss decreased (0.024239 --> 0.021549). Saving model ...
Updating learning rate to 1.25e-05
Epoch: 5 cost time: 2.111354351043701
Epoch: 5, Steps: 20 | Train Loss: 0.0707515 Vali Loss: 0.0184724 Test Loss: 0.0211690
Validation loss decreased (0.021549 --> 0.018472). Saving model ...
Updating learning rate to 6.25e-06
Epoch: 6 cost time: 1.6446027755737305
Epoch: 6, Steps: 20 | Train Loss: 0.0712520 Vali Loss: 0.0198189 Test Loss: 0.0230161
EarlyStopping counter: 1 out of 3
Updating learning rate to 3.125e-06
Epoch: 7 cost time: 1.7283775806427002
Epoch: 7, Steps: 20 | Train Loss: 0.0701941 Vali Loss: 0.0202722 Test Loss: 0.0219292
EarlyStopping counter: 2 out of 3
Updating learning rate to 1.5625e-06
Epoch: 8 cost time: 1.8929383754730225
Epoch: 8, Steps: 20 | Train Loss: 0.0698262 Vali Loss: 0.0195256 Test Loss: 0.0222712
EarlyStopping counter: 3 out of 3
Early stopping
>>>>>>>testing : informer_custom_ftMS_sl20_ll10_pl5_dm256_nh4_el2_dl1_df256_atprob_fc5_ebtimeF_dtTrue_exp<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
test 191
test shape: (5, 32, 5, 1) (5, 32, 5, 1)
test shape: (160, 5, 1) (160, 5, 1)
mse:0.021161550655961037, mae:0.1239549070596695调用模型的predict()方法可以直接预测所有数据后面的未知数据,因为这里预测长度为5,所以直接调用就相当于预测后5天的收盘价走势了。预测的结果会保存在./results/{settings}/下面的real_prediction.npy文件中。
setting = 'informer_custom_ftMS_sl20_ll10_pl5_dm256_nh4_el2_dl1_df256_atprob_fc5_ebtimeF_dtTrue_exp'
exp = Exp(args)
exp.predict(setting, True)
prediction = np.load('./results/'+setting+'/real_prediction.npy')
plt.figure()
plt.plot(prediction[0,:,-1])
plt.show()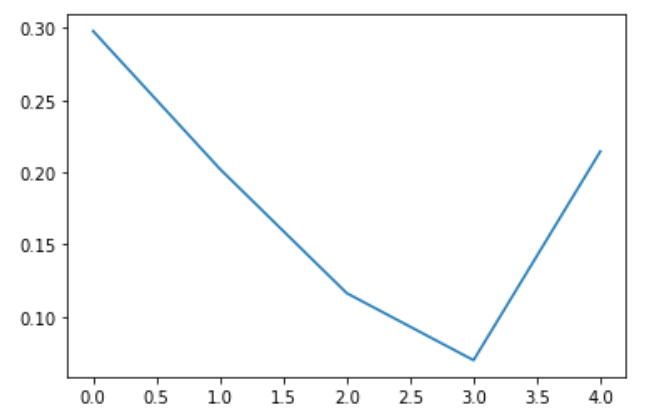
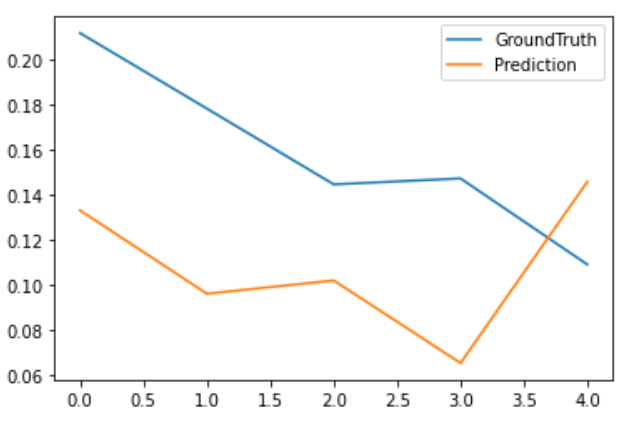
从测试集上随机选出几条预测结果以及ground truth进行可视化:
preds = np.load('./results/'+setting+'/pred.npy')
trues = np.load('./results/'+setting+'/true.npy')
plt.figure()
plt.plot(trues[20,:,-1], label='GroundTruth')
plt.plot(preds[20,:,-1], label='Prediction')
plt.legend()
plt.show()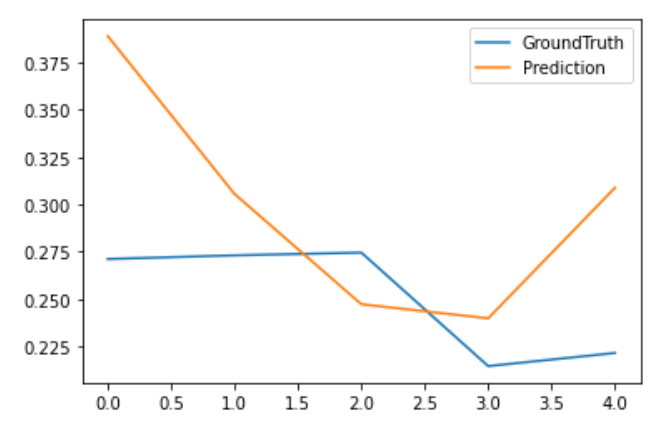
最后将完整的测试集上的预测结果进行可视化。
plt.figure()
plt.plot(trues[:,0,-1].reshape(-1), label='GroundTruth')
plt.plot(preds[:,0,-1].reshape(-1), label='Prediction')
plt.legend()
plt.show()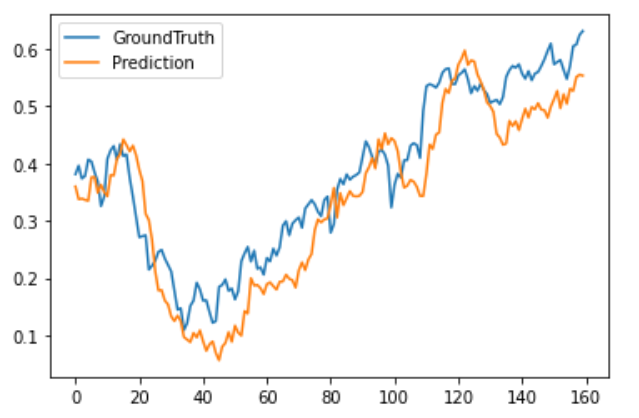
4
总结
作为AAAI 2021的best paper,Informer对Transformer在时序预测应用上从三个方面进行了改进,并取得了不错的长期预测效果。基于官网Informer的代码,本文简单介绍了Informer模型的基本原理,以及在股价预测方面的代码实现,并通过上证指数数据进行了实验验证,从实验结果中,可以看出informer大体拟合出了上证指数这段时间的走势,但仍然存在精度上的不足,这也说明了不同于其他天气,电力等周期性强的时序数据,股价数据存在的高噪声跟不确定性使得其预测的难度之大,尤其是进行高精度的多步预测更是难以实现。Informer官方提供了详细完整的代码,大家感兴趣的也可以进一步进行调参或者修改,来用于自己的预测任务。本文内容仅仅是技术探讨和学习,并不构成任何投资建议。
参考文献:
Zhou H, Zhang S, Peng J, et al. Informer: Beyond efficient transformer for long sequence time-series forecasting[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(12): 11106-11115.
https://colab.research.google.com/github/patoalejor/Workshop2021/blob/main/Informer.ipynb
获取完整代码以及其他历史文章完整源码可加入《人工智能量化实验室》知识星球。

《人工智能量化实验室》知识星球

加入人工智能量化实验室知识星球,您可以获得:(1)定期推送最新人工智能量化应用相关的研究成果,包括高水平期刊论文以及券商优质金融工程研究报告,便于您随时随地了解最新前沿知识;(2)公众号历史文章Python项目完整源码;(3)优质Python、机器学习、量化交易相关电子书PDF;(4)优质量化交易资料、项目代码分享;(5)跟星友一起交流,结交志同道合朋友。(6)向博主发起提问,答疑解惑。

文章出处登录后可见!