apply() 函数可以直接对 Series 或者 DataFrame 中元素进行逐元素遍历操作,方便且高效,apply() 使用时,通常放入一个 lambda 函数表达式、或一个函数作为操作运算。
DataFrame.apply(self, func, axis=0, raw=False, result_type=None, args=(), **kwds
参数说明:
- func 代表的是传入的函数或 lambda 表达式;
- axis 参数可提供的有两个,该参数默认为0/列
0 或者 index ,表示函数处理的是每一列;
1 或 columns ,表示处理的是每一行; - raw ;bool 类型,默认为 False;
False ,表示把每一行或列作为 Series 传入函数中;
True,表示接受的是 ndarray 数据类型;
apply() 最后的是经过函数处理,数据以 Series 或 DataFrame 格式返回。
先看Series的apply()使用:
s = pd.Series([1,2,3])
a = s.apply(lambda x: print(x))
b = s.apply(lambda x: print(type(x)))
输出结果:
1
2
3
<class ‘int’>
<class ‘int’>
<class ‘int’>
可以看出,在apply()中,会自动取出每个元素,相当于循环遍历了一遍调用的Series
a,b的输出结果为:
0, None
1, None
2, None
因为中间的lambda函数只是打印,所以返回的是None。
在DataFrame中apply()的使用:
DataFrame中传入的参数就是Series结构了,例如:
matrix = [
[1,2,3],
[4,5,6],
[7,8,9]
]
df = pd.DataFrame(matrix, columns=list('xyz'), index=list('abc'))
df的结构长这样:

a=df.apply(lambda x: print(type(x)))
输出如下:
<class ‘pandas.core.series.Series’>
<class ‘pandas.core.series.Series’>
<class ‘pandas.core.series.Series’>
可见传入lambda函数的参数类型是Series
现在求DataFrame中每个数的平方:
a=df.apply(lambda x: x*x)
输出:
 用apply()求指定行的平方:
用apply()求指定行的平方:
a=df.apply(lambda x: x*x if x.name=='a' else x, axis=1)
输出如下:

发现一种奇怪的现象:
a=df.apply(lambda x: x.mean() if x.name=='a' else None, axis=1)
输出如下:
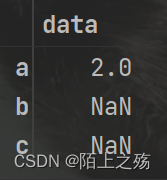
其实主要是看lambda函数返回的是什么,在DataFrame中,传入的是Series,返回的自然是Series的运算结果。例如上面求对第一行的Series求平方,结果还是一个Series(如下例),而对第一行求平均数返回的是一个数,自然结果的第一行就成了一个数。
s = pd.Series([1,2,3])
ss = s*s
print(ss)
print(type(ss))
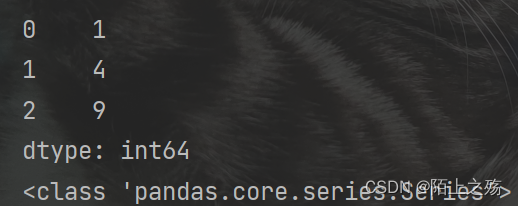
总的来说,apply()函数就是自动对Series或DataFrame中的每个元素执行指定的函数操作。特别注意DataFrame中的参数是Series,那么函数中自然就是对Series的操作了。
文章出处登录后可见!