无论是loc还是iloc都是pandas中数据筛选的函数。
我们先聊一下loc函数,loc的全程是location,什么东西可以作为location?我们第一时间可能会想到标签。
在pandas读取文件的时候一般都是会把文件读成DataFrame的格式。
具体何为dataframe格式我举个例子:
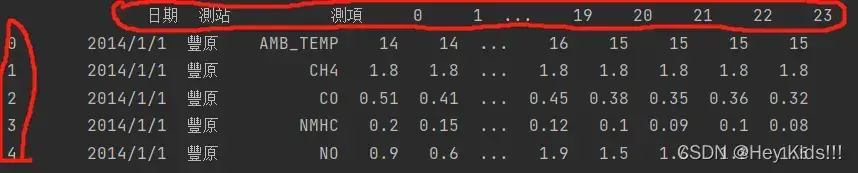
这里画红圈的部分都可以称作为标签
比如说我要只想看到第一行的数据
print(data.loc[0])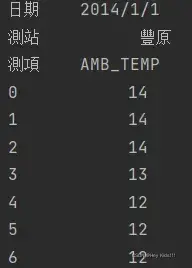
其中‘0’就是第一行的标签它会将第一行数据竖向排列给你看
如果我只想看某一项的数据,比如我只想知道第一行对应的日期是啥
print(data.loc[0,['日期']])![]()
这个‘日期’就是对应列的标签,其效果是对指定列进行检索
然后我们再讲一下iloc函数,这个i就是对应的单词index,index-location,就是对索引进行定位
这个其实和列表啊,numpy数组的切片没啥区别,下面举个例子:
print(data.iloc[0,0])
print(data.iloc[0,1])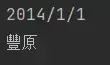
第一个打印的就是取到了第1行第1列对应的呢个数据
第二个打印的就是取到了第1行第2列对应的呢个数据
然后我们再对整行或整列切片:
print(data.iloc[0:2,0:2])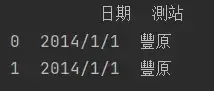
说白了其实和人眼检索excel的感觉是一样的,数到第几行再数到第几列:)
文章出处登录后可见!
已经登录?立即刷新