多模态特征融合
- 前言
- 输入层,数据集转为特征向量
- 图像
- 语音
- 什么是时域信号,什么是频域信号
- 语音信号转换 – 1.傅立叶变换
- 语音信号转换 – 2.梅尔频率倒谱系数
- 文本
- 词袋模型
- 词嵌入模型
- 输出层,多模态模型合并
前言
学习多模态的话题可以从深度学习的分类任务出发,因为分类任务是最直观的可以观察到不同模态的数据,通过输入数据到模型中,我们可以看到模型是如何学习到数据的特征向量的,同时分类任务的模型也是实现更复杂任务模型的基础。从分类任务中可以了解到图像、文本、语音在模型的特征向量是什么。
以飞浆的多模态视频分类模型为例,这个模型基于真实的短视频业务数据,融合文本、视频图像、音频三种模态进行视频多模标签分类,相比只使用视频图像特征,显著提升了高层语义标签的效果。模型架构图如下:
,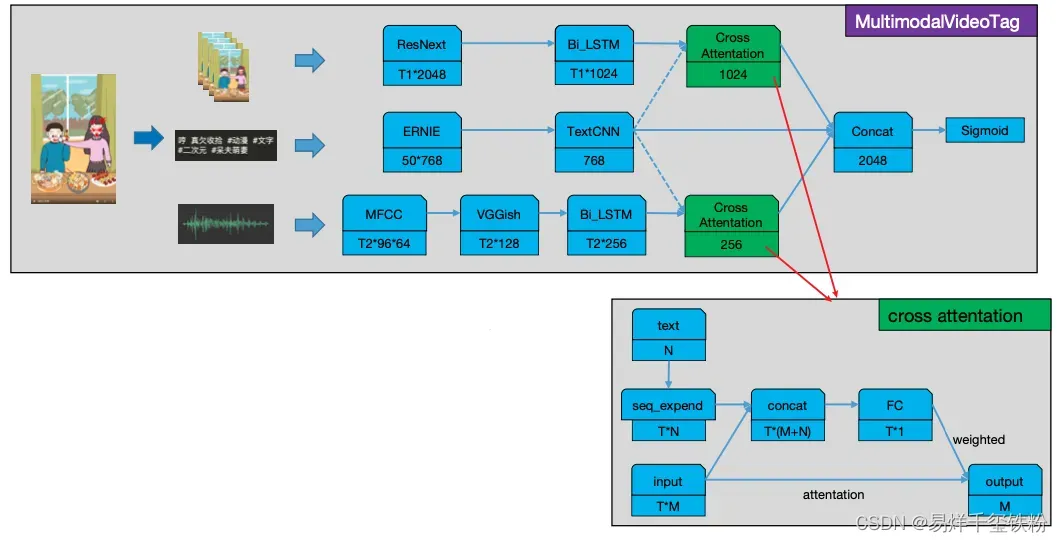
在该模型中,不同模态的数据通过不同的处理方式进行特征提取和融合。比如,文本数据可以通过词嵌入的方式转换为特征向量,视频和音频数据可以通过卷积神经网络和循环神经网络提取特征。这些特征向量经过融合层进行特征融合,最终输入到分类层进行分类。通过这个例子,我们可以看到如何将不同模态的数据转换为特征向量,以及如何通过特征融合提高模型的分类性能。
从上述段落中可以看出,该模型架构包含了三种数据类型的输入(图像、文本、语音),并且根据不同的数据类型拆分成不同的模型进行学习。为了能够将这些数据输入到深度学习模型中进行学习,需要先将它们转换成数字类型的向量。这个过程称为特征工程,其目的是将原始数据转换成能够被深度学习模型所理解的特征向量。具体来说,对于图像数据,可以使用卷积神经网络(CNN)来提取特征;对于文本数据,可以使用词嵌入(Word Embedding)等技术将单词转换成向量表示;对于语音数据,可以使用声学特征提取技术,如Mel频率倒谱系数(MFCC)等来提取特征。经过特征工程处理后,这些数据就可以被送入相应的模型进行学习。
在模型的输出层,需要将三种模型所学习到的特征向量进行合并,以获得最终的分类结果。合并方法通常使用简单的向量拼接(Concatenation)或者加权平均(Weighted Average)等方式进行。具体的合并方法可以根据实际情况进行选择,以获得最佳的性能。
输入层,数据集转为特征向量
图像
在计算机视觉中,图像通常以矩阵形式表示。
这个矩阵由多个向量组成,可以通过卷积、激活函数和池化等操作提取出图像的特征。在这个过程中,每个向量都代表着图像中的某些信息,如边缘、纹理等。最后,在全连接层中,所有的特征向量被展平成一个向量,用来表示整个图像的特征。可以将这个向量看做是将图像从左到右、从上到下拆分成若干块,按照顺序排列得到的。通过这种方式,我们可以将复杂的图像信息转换成一个向量表示,方便后续的机器学习模型进行处理。
语音
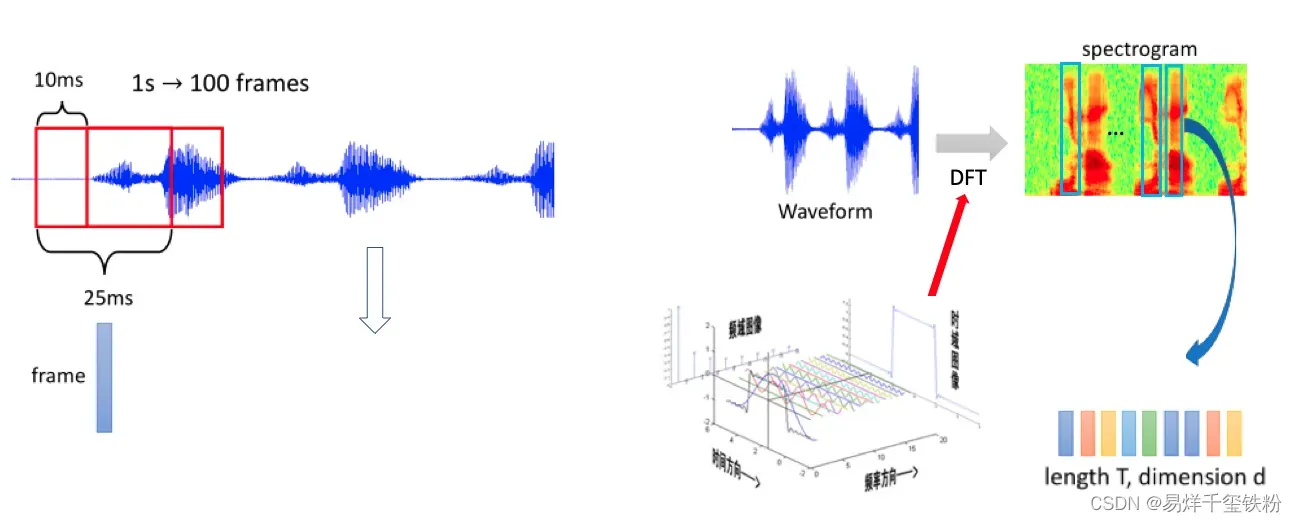
对于语音信号的处理,通常需要进行预处理和特征提取,以便为后续的语音识别模型提供高质量的输入语音预处理通常包括以下步骤:
- 语音信号的采集:通过麦克风或其他录音设备收集语音信号。
- 信号增益调整:根据录制环境和麦克风特性等因素,对信号进行增益调整,以保证信号的质量。
- 降噪处理:对信号进行降噪处理,去除录音中的噪声、杂音等干扰信号。
- 分帧处理:将信号划分成若干小段,每一小段称为一帧,通常每帧的长度在10ms-30ms之间。
- 加窗:对每帧信号应用窗函数(例如汉明窗),以减少频谱泄漏的影响。
- 傅里叶变换:对每帧信号进行快速傅里叶变换(FFT),以将时域信号转换为频域信号。
- Mel滤波器组:将频域信号通过一组Mel滤波器,得到每个滤波器的输出能量。
- 对数变换:对每个滤波器的输出能量取对数,以提高计算精度并将能量值范围缩小。
- 倒谱变换:对每个滤波器的对数能量值进行离散余弦变换(DCT),以提取频率特征,得到MFCC系数。 8. 特征归一化:对提取出的特征进行归一化处理,以消除不同说话人、不同录制设备等因素对特征的影响。
- 特征拼接:将相邻帧的特征进行拼接,以提高特征的时序信息。
- 数据增强:通过对语音信号进行变换、扰动等操作,增加数据量和多样性,提高模型的泛化能力。
从上面步骤来看语音转换主要涉及到的技术是时域信号转频域信号,和mel滤波器转换,这里补充这二个部分的内容。
什么是时域信号,什么是频域信号
时域分析是指将信号看作是时间的函数,通过对信号在时间轴上的变化进行分析
频域分析则是将信号看作是频率的函数,通过对信号在频率轴上的分解和重建来分析信号的特征
图像
信号就是我们的数据,以图像来说信号就是不同的像素级,也可以说不同值的像素,图像在时域上看表示的是信号的空间位置关系,也就是我们人眼看到一张图片,就是图像的时域信号,
图像的频域,就类似于图像直方图一样,将不同的像素级结合像素级在图像中的数量,绘制出的图。
对应到语音同理
语音跟图像像素级一样也有区分,语音按不同的声音频率区分不同的语音数据,
在时域上抽象看,就是我们听到的一段声音,如果把它放到2维图像中,就一段语音(不同频率的语音信号叠加到一起),在时间维度上的振幅大小和变换。语音信号在时域上是一个连续的波形,由多个频率成分叠加而成
语音频域,将语音信号分解为不同频率的正弦波成分,并计算每个频率成分的幅度、相位等特征
将一个语音信号转换为频域表示通常需要进行傅立叶变换。
语音信号转换 – 1.傅立叶变换
傅立叶变换是一种将时域信号转换为频域信号的数学方法。
下面是一个简单的例子,用于说明如何将一个简单的声音信号进行傅立叶变换。假设我们有一个长度为1000个采样点的声音信号,其中每个采样点的值在-1到1之间。我们可以将这个信号看作一个在时间上连续的函数,用表示。
为了将转换为频域表示,我们需要计算它的傅立叶变换。傅立叶变换将
分解为不同频率的正弦波的和。
具体来说,它将表示为以下形式:
其中,
是一个复数系数,
是频率,
是信号的周期。这个公式意味着,原始信号可以表示为许多频率为
的正弦波的加权和,其中权重由
给出。我们可以使用离散傅立叶变换(Discrete Fourier Transform, DFT)将
转换为频域表示,得到一个包含1000个复数值的向量
,其中每个值对应于一个频率。具体来说,
表示信号中频率为
的正弦波的复数系数。
在实践中,我们可以使用现有的计算库来执行傅立叶变换,而无需手动计算每个系数。在Python中,可以使用NumPy库的fft函数来计算DFT。以下是一个示例代码
import numpy as np
# 生成一个简单的声音信号
t = np.linspace(0, 1, 1000)
f = 440 # 频率为440Hz
signal = np.sin(2 * np.pi * f * t)
# 计算DFT
dft = np.fft.fft(signal)
在这个例子中,我们生成了一个频率为440Hz的正弦波,并使用NumPy的fft函数计算了它的DFT。dft变量包含了信号的频域表示,其中每个值对应于一个频率
将傅立叶转换的信息用梅尔频率倒谱系数(Mel Frequency Cepstral Coefficients,MFCC)转换为语谱图。
语音信号转换 – 2.梅尔频率倒谱系数
在MFCC中,通常使用LogFBank来代替Mel滤波器组的输出。LogFBank计算公式如下:
其中,表示帧数,
表示Mel滤波器组的序号,
表示FFT输出的频率索引。
表示第
个Mel滤波器在第
个频率处的响应,
表示第
帧在第
个频率处的能量。LogFBank的结果是一个向量,其中每个元素代表一个Mel滤波器的输出能量取对数后的值。通常在MFCC中,还会进一步应用离散余弦变换(DCT)对LogFBank进行压缩,得到MFCC系数。
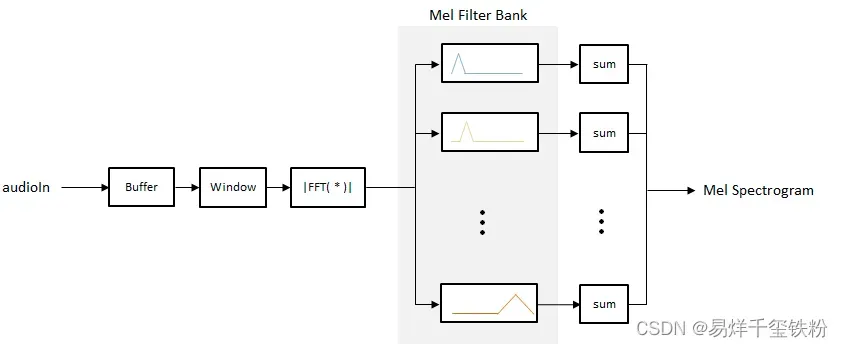
可以将语谱图视为一张图像,因为它具有图像的基本特征,例如宽度、高度、像素值等。
语谱图是由频谱分析的结果得到的,它将音频信号在时间和频率维度上分解,并用颜色来表示不同频率的能量强度,因此类似于图像中的像素。在语音识别中,将语谱图转换为特征向量是一种常见的方法,称为Mel频率倒谱系数(Mel Frequency Cepstral Coefficients, MFCCs)。
MFCCs是一种将语音信号的频率特征进行提取的方法,其基本思想是将语谱图转换为一组特征向量,这些特征向量可以用来训练分类器或进行其他的机器学习任务。因此,可以将语谱图看作是一种图像,并使用MFCCs将其转换为特征向量。这种方法已被广泛应用于语音识别和相关领域中。
文本

将文本转化为特征向量的原理是将文本中的词语映射为向量空间中的点,然后根据这些点的位置和距离来表示文本特征。常用的方法有词袋模型和词嵌入模型,下面分别介绍它们的原理和公式。
词袋模型
词袋模型将每个文本看作是一个词语的集合,忽略其词语出现的顺序和语法结构,只考虑文本中每个词语的出现次数。词袋模型可以用一个向量来表示文本,其中向量的每个元素对应一个词语,其取值表示该词语在文本中出现的次数。词袋模型的公式可以表示为:
其中,BOW(w)_i表示向量w中第i个元素的值,v_i表示第i个词语,n表示文本中词语的总数,[w_j=v_i]表示如果w中第j个词语等于v_i,则该项取值为1,否则取值为0。
词嵌入模型
词嵌入模型是一种将文本中的词语映射为向量空间中的向量的方法,它能够在保留词语语义信息的同时,还考虑了词语之间的相关性。常用的词嵌入模型有Word2Vec和GloVe,它们都是基于共现矩阵的方法。
以Word2Vec为例,其原理是通过神经网络将每个词语映射为一个固定长度的向量,使得在向量空间中相似的词语距离较近。Word2Vec包含两个模型:CBOW和Skip-gram,其中CBOW通过上下文预测目标词语,Skip-gram通过目标词语预测上下文。这里以Skip-gram为例,其公式可以表示为:
其中,v_c表示上下文词语的向量,v_w表示目标词语的向量,V表示词汇表中的总词语数。公式的意义是计算给定上下文情况下,目标词语为某个词语的概率,通过最大化所有目标词语的条件概率之和,训练出每个词语对应的向量。除了Word2Vec之外,还有一些其他的词嵌入模型,比如GloVe,其公式可以表示为:
其中,p_ij表示词语i和词语j在上下文中共现的次数占所有共现次数的比例,w_i和w_j表示词语i和词语j对应的向量,b_i和b_j表示词语i和词语j对应的偏置项,σ表示GloVe模型的超参数。下面是一个简单的Python代码实现,演示如何将文本转化为特征向量
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['this is a test', 'this is another test']
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(X.toarray())
#run result
[[1 1 1 0]
[1 1 0 1]]
可以看到,文本被转化为了一个二维矩阵,其中每行表示一个文本,每列表示一个词语,矩阵中的每个元素表示对应的词语在文本中出现的次数。这个矩阵就可以作为深度学习模型的输入特征。
输出层,多模态模型合并

输出层如何实现多模型合并的这里用代码演示一下,
- 首先,我们生成三个全连接层,分别为1024、768和256,并对它们分别进行sigmoid激活函数操作,得到它们的输出结果。
- 然后,我们将这三个输出结果合并为一个向量
。
- 接着,我们将这三个全连接层合并起来,即将它们的输出结果在特征维度上拼接起来,并对拼接后的结果进行sigmoid激活函数操作,得到
。
- 最后,我们比较
我将使用PaddlePaddle框架来实现这个过程。
import paddle
import numpy as np
# 创建三个全连接层,分别为1024、768和256
fc1 = paddle.nn.Linear(2048, 1024)
fc2 = paddle.nn.Linear(1024, 768)
fc3 = paddle.nn.Linear(768, 256)
# 创建输入数据
x = np.random.randn(1, 2048).astype('float32')
# 分别对三个全连接层进行sigmoid激活函数操作,并将它们的输出拼接起来
y1 = paddle.concat([paddle.to_tensor(fc1(x)), paddle.to_tensor(fc2(fc1(x))), paddle.to_tensor(fc3(fc2(fc1(x))))], axis=1)
s1 = paddle.nn.functional.sigmoid(y1)
# 将三个全连接层的输出拼接起来,并对拼接后的结果进行sigmoid激活函数操作
y2 = paddle.to_tensor(fc3(paddle.concat([fc2(paddle.concat([fc1(x), fc1(x)], axis=1)), fc1(x)], axis=1)))
s2 = paddle.nn.functional.sigmoid(y2)
# 比较两种方法得到的输出结果是否相等
print("s1:", s1.numpy())
print("s2:", s2.numpy())
print("s1 == s2:", np.allclose(s1.numpy(), s2.numpy(), rtol=1e-6))
在运行上述代码时,我们可以看到,和
的值非常接近,几乎相等,证明这两种方法得到的输出结果相同,而且从代码的逻辑来看,可以看到几乎一样的,只是修改了to_tensor和concat的顺序。
文章出处登录后可见!