实验|Aircloud 算力支持|幻方萤火二号
CLIP(Contrastive Language-Image Pre-Training,以下简称 CLIP) 模型是 OpenAI 在 2021 年初发布的用于匹配图像和文本的预训练神经网络模型,可以说是近年来在多模态研究领域的经典之作。该模型直接使用大量的互联网数据进行预训练,在很多任务表现上达到了目前最佳表现(SOTA)💯。
本次我们尝试使用 Google 开源的 Conceptual Captions 数据集来训练 CLIP 模型,并对其效果进行一定的验证。
本次体验接入的是幻方萤火二号。
CLIP模型介绍
在目前图像分类领域中,我们训练的模型通常会遇到以下问题:
-
模型需要用到大量的格式化标注数据,这些标注数据获取通常成本高昂。
-
模型在当前数据集的效果比较好,但是可能模型的泛化能力较差,同时迁移到新的训练任务也比较困难。
与此同时,互联网上面已经存在了大量的图像文本对(在网页中,开发者一般都会为图片添加一段文字备注),实际上这些素材可以作为已经标注好的数据集,利用这些数据集进行训练,既能解决获取标注数据成本高昂的问题,同时也因为互联网上的数据量比较大和数据本身差异较大,更容易让我们获得泛化能力较强的模型。
CLIP 模型就是基于上述概念,使用 OpenAI 收集到的 4 亿对图像文本对,分别将文本和图像进行编码,之后使用 metric learning 进行训练,其目标是将图像与文本的相似性提高,核心流程比较简洁,可以直接参考下述伪代码:
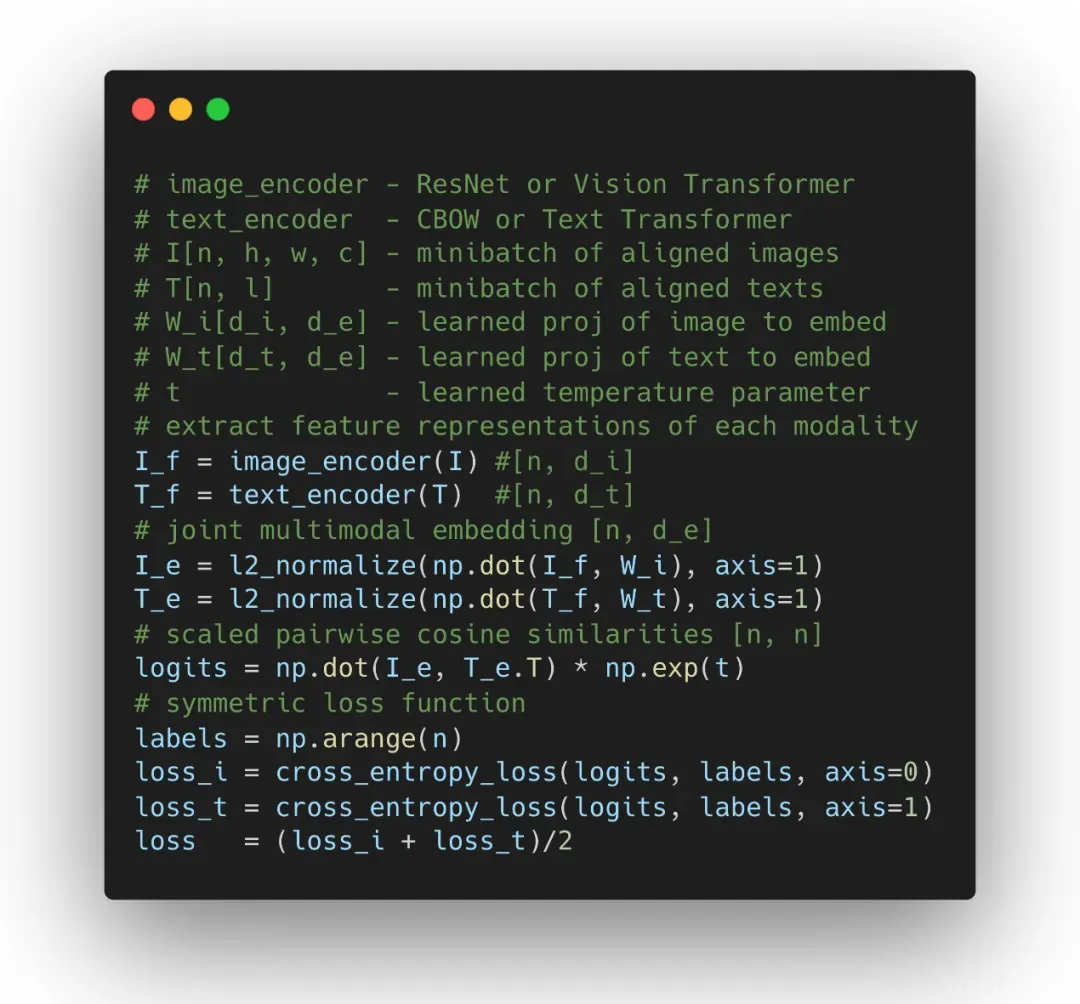
在预测阶段,也是通过一系列生成的文本对和目标图像,计算余弦相似度从而获取预测值:
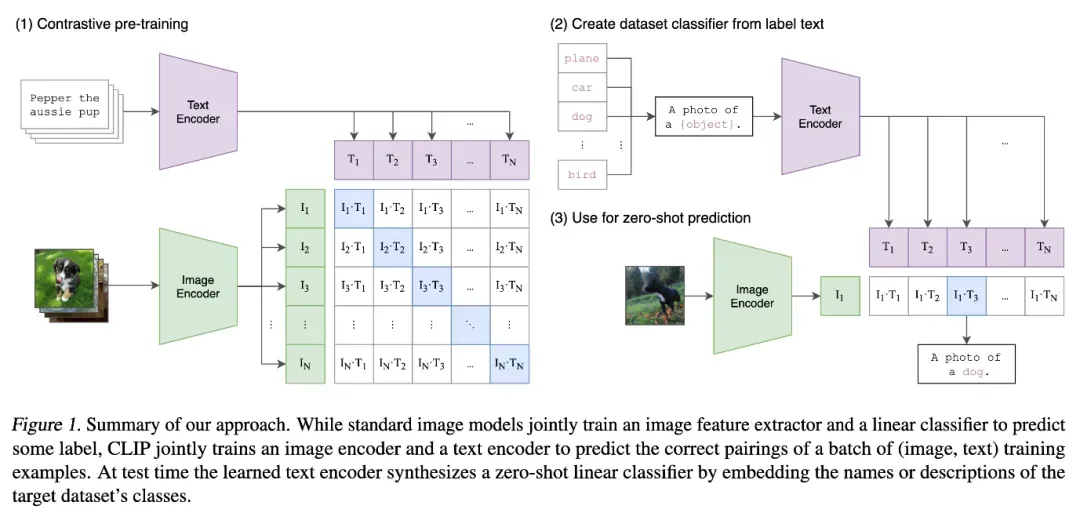
CLIP 通过以上过程,取得的效果还是比较惊艳的。OpenAI 官方开源了 CLIP 模型部分的代码,不过如果想完整的的复现训练,还需要写不少训练相关的代码,这里我们基于 github 上的另外一个开源实现,通过一定的修改,来完成在萤火平台上训练的整个过程。
数据预处理下载和清洗
模型训练用到的Conceptual Captions 数据集是 Google 从数十亿互联网网页提取的图像文本信息数据,并进行了若干种类型的过滤,使得数据集具有较高的质量和准确度,总共约 300 万个测试数据和 8000 多个验证数据。
它提供的是描述和图片的下载地址,其数据格式如下:
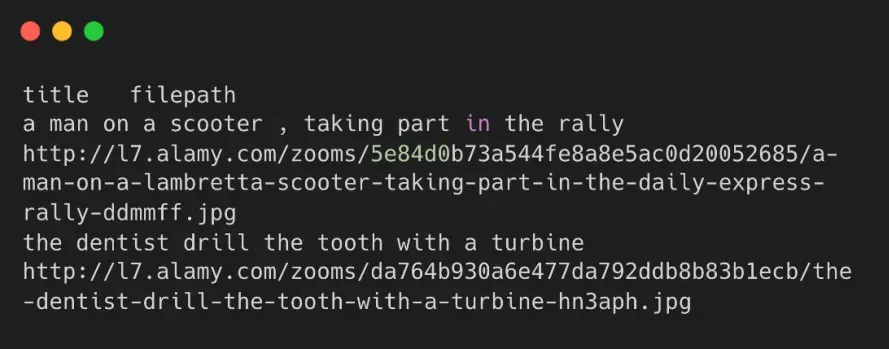
我们可以将该数据集通过 python 脚本下载和统一存放,下载完之后,我们需要将该数据集进行清洗,将下载的空图片或者不完整的图片数据过滤之后才可以使用。
这部分下载和清洗,我们简单编写 python 脚本即可完成,我们完全下载清洗后得到的 csv 文件格式为:
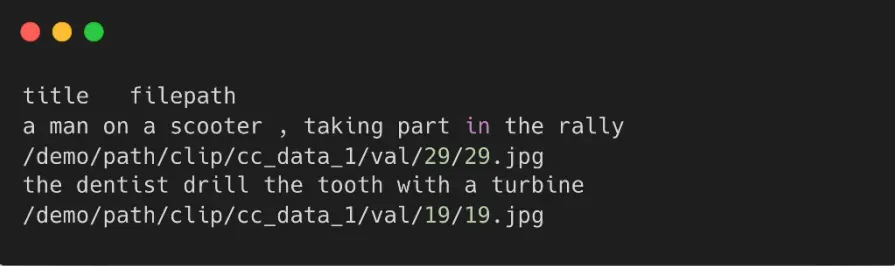
实际上,这个数据集由于比较大,而且都是分散在各个 URL 而不是一个完整的压缩包, 我们下载会花费不少时间,累计接近 100G 的解压大小也会对我们的数据存放造成一定负担。但是本次实验可以直接跳过上述数据下载和清洗过程,调用幻方AI数据集仓库。
▶幻方AI数据集仓库
幻方AI团队目前正在基于自研的高性能平行文件系统进行数据集仓库的建设:对于一些常用的数据集和已经在集群上训练过的公开数据集(包括以上 Conceptual Captions 数据集),都会经过处理后放在可访问的公开文件目录。后续在萤火二号上使用相同的数据集进行训练或模型开发,可以直接跳过繁琐的下载和预处理步骤,一键调用,极大地减轻数据科学家与开发者们的负担。
在分布式训练开始之前,虽然我们已经可以使用清洗好的图像数据进行训练了,但如果我们频繁打开小文件,对训练自身的性能和整个集群的性能影响都会比较大。为此,我们会使用幻方AI自研的 FFRecord 数据格式,来将多个小文件进行合并处理,以减少训练时磁盘IO的开销。
▶FFRecord 数据格式转换
FFRecord (FireFlyer Record) 数据格式是幻方AI自研的简单高效的存储二进制记录的文件格式,它的一些特点包括:
-
合并多个文件,减少了训练时打开大量小文件的开销,对存储后端更加友好。
-
支持随机读取,可以适应不同的样本读取模式。
-
包含数据校验,保证读取的数据完整可靠。
同时,为了更轻松的完成FFRecord格式的转化,幻方萤火二号平台还提供了数据格式转换套件——专为 PyTorch 设计的 FFDataset (FireFlyer Dataset) 和 FFDataLoader (FireFlyer DataLoader),带来的便利是:
-
高效读取,使用 Linux Asynchronous I/O 的接口,充分利用了自研存储系统的随机读取性能优势,单 Client 读取带宽最高可接近 200Gbps。
-
简单易用,只需要对使用原有 PyTorch DataLoader 的代码进行简单的修改即可切换为 FFDataLoader。
-
使用灵活,完全兼容 PyTorch Dataset 和 DataLoader 的相关接口,如 Sampler 等。
数据预处理和 FFRecord 转换部分的代码,均可在萤火二号访问。
开源代码调整
在转换为 FFRecord 之后,我们就可以开始调整开源代码,进行训练了。针对开源代码进行调整,主要调整的内容包括:
-
参数调整,包括超参数、文件路径等
-
入口文件微调,引入 hf_env、hfai
-
使用 FFDataset 代替原有的 Dataset
-
适配集群打断逻辑
Step1: 参数调整部分比较简单,我们可以根据自己的需要调整数据集和验证集的文件路径,以及 batch-size 和 epoches 等参数。
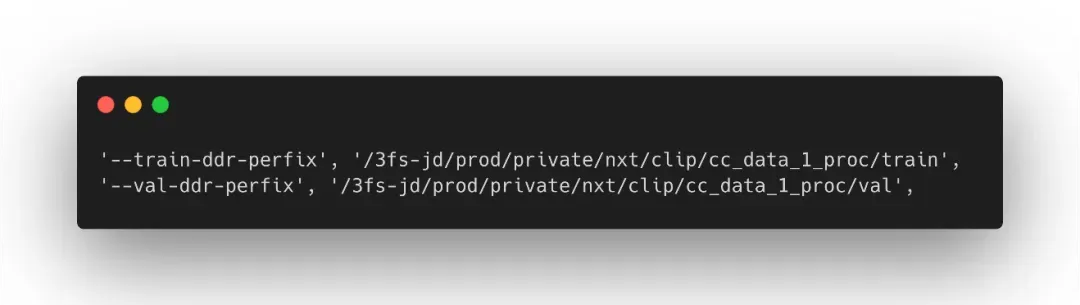
这里我们增加了两个参数,分别用于表示训练集和验证集的 FFRecord 文件地址
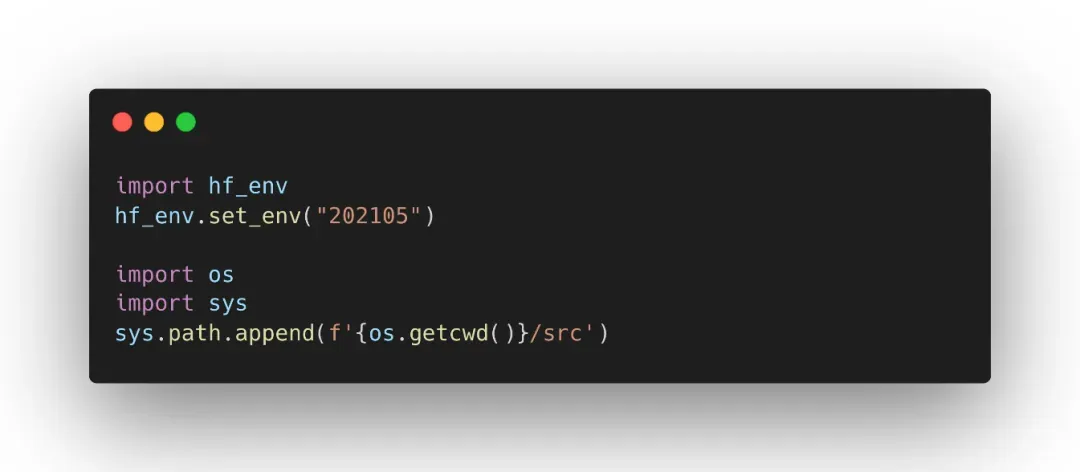
Step2: 引入 hf_env、hfai 的代码
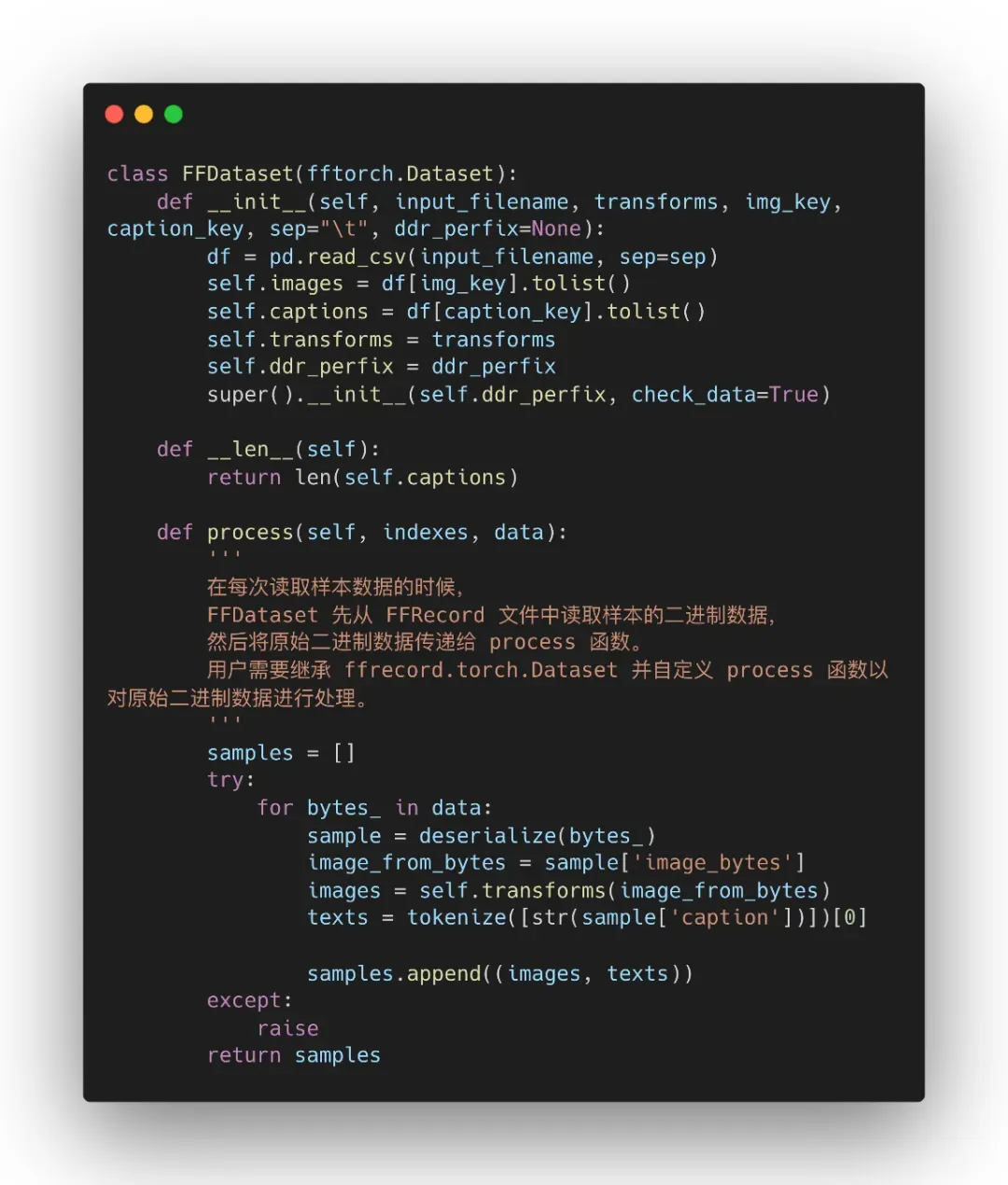
Step3: 为了提高训练性能,我们使用上文提到的 FFDataset 代替 torch 的 Dataset,这里我们给出一个实现代码,使用到了我们上文新增加的参数:
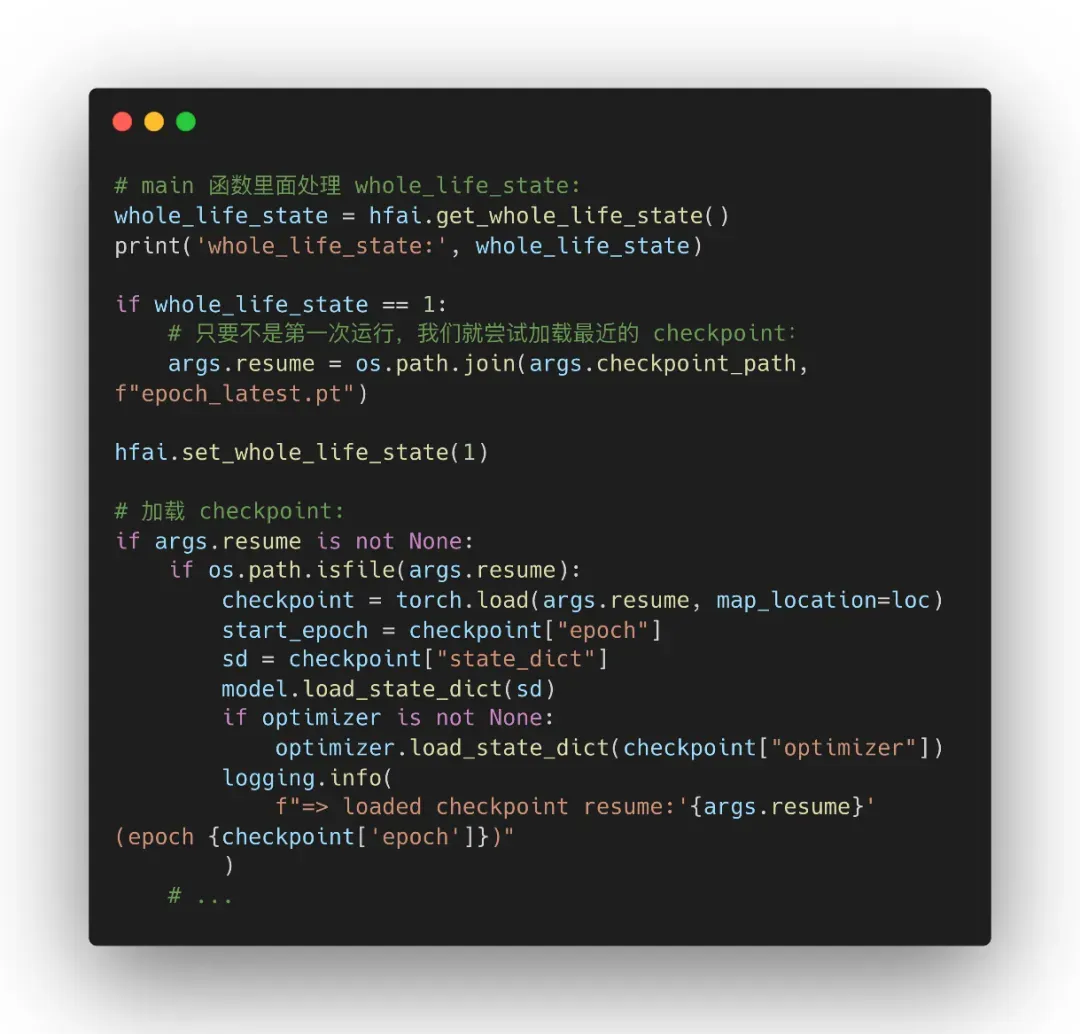
Step4: 由于萤火的任务调度规则为分时分优先级调度,也就是说任务提交以后,有可能会被平台打断暂停,任务打断实际上会强行结束当前进程,后续再启动的时候就又会再次执行初始化逻辑,为了能够在打断后恢复继续训练,我们需要及时保存我们的 checkpoint,并且在任务恢复的情况下加载之前的历史记录继续训练,同时,我们应该在整个训练结束之后对模型进行保存。
这里笔者提供一个比较简单的方式,我们利用萤火二号平台提供的 whole_life_state 标志来进行标记,第一次 whole_life_state 是 0,如果是打断恢复的场景,这个时候 whole_life_state 就是 1,因此我们加载最新的 checkpoint 进行继续训练,这里给出关键的代码:
经过以上处理,我们就可以验证和运行我们的任务了。
测试运行并提交训练
萤火二号提供的 hfai 命令行工具提供了测试运行的接口,我们可以通过:
来进行测试运行(一般来说,我们建议先测试运行,没有明显问题之后再提交训练)。
测试运行会在当前终端直接打印运行信息(如下):
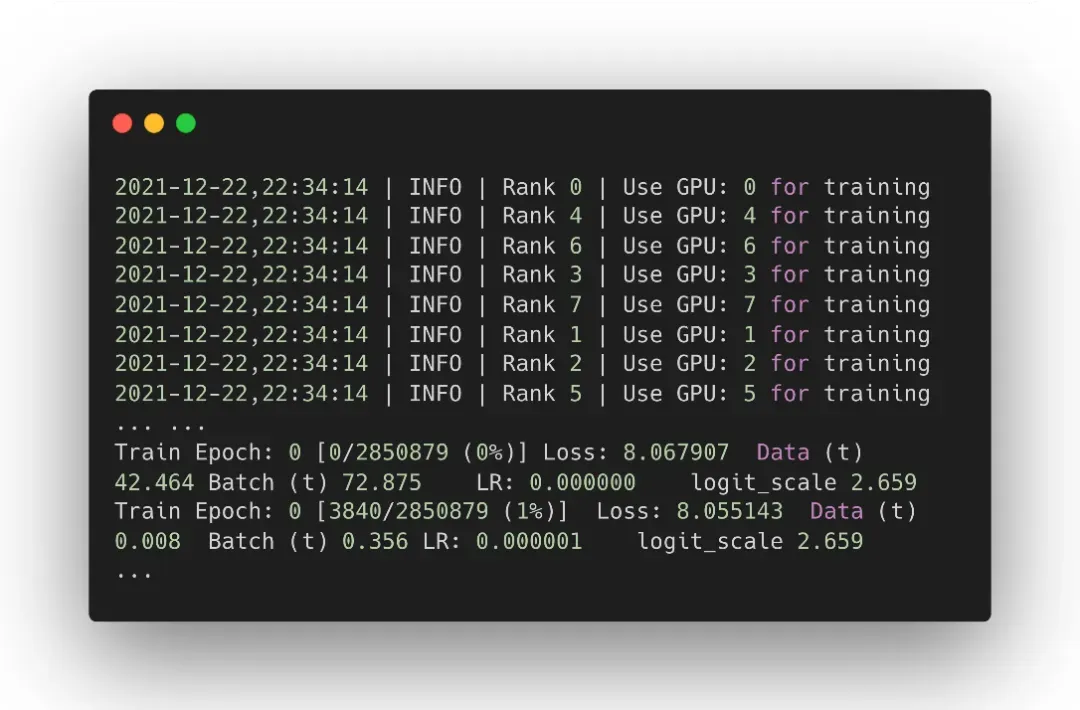
可以看到,我们的代码已经可以在单机 8 卡的场景下测试运行了,不过,由于数据集较多,这个训练还是比较慢的,此时我们可以利用萤火二号平台的弹性算力,进行多机多卡并行训练。
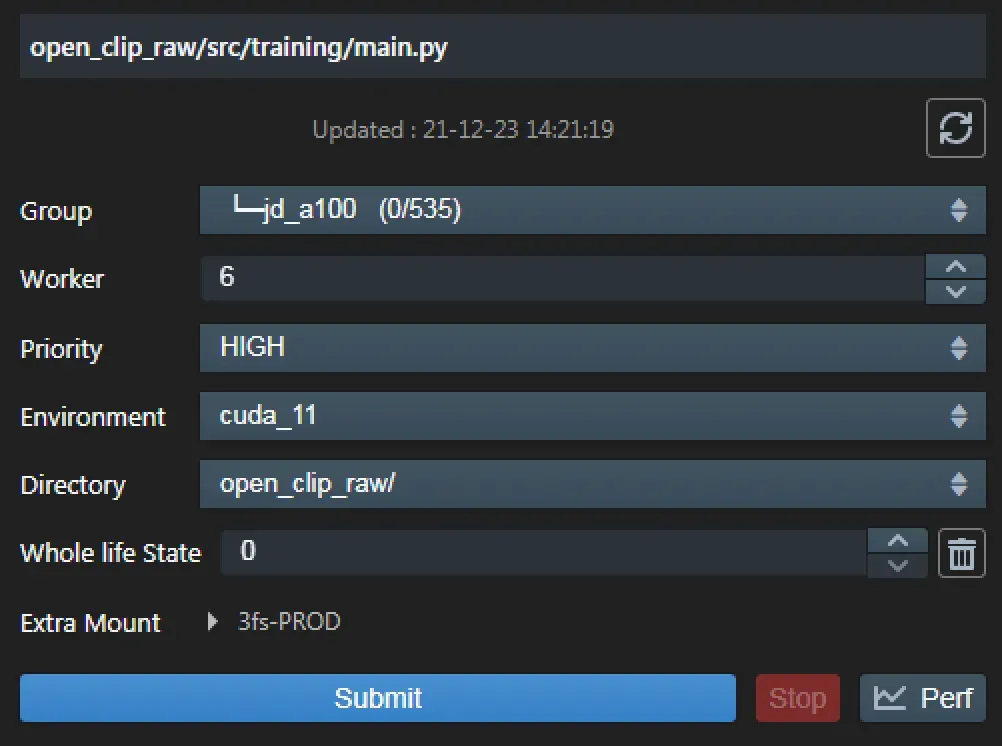
萤火二号平台的管理页面提交任务,选择 6 个节点
任务提交后,我们在萤火二号平台的管理页面,可以比较方便地看到任务的日志和状态
任务运行日志和状态
在 6 节点并行训练的过程中,单个 epoch 训练大约 6 分钟,我们如果训练 30 个 epoch,加上初始化时间,大约 3 个多小时后,我们训练成功!
验证模型
针对 CLIP 模型的验证测试,openAI 提供了多种方式,比如使用 ImageNet 数据集进行 zero-shot 验证等,我们都可以比较方便地在萤火二号平台上对此进行复现。
这里为了便于我们理解模型,我们展示一种 CLIP 提及的比较可视化的方式对它进行简单的验证。
我们使用 skimage 的一些图片和文本信息,使用我们训练好的模型计算相似度,然后通过二维矩阵的方式打印出来,如下图
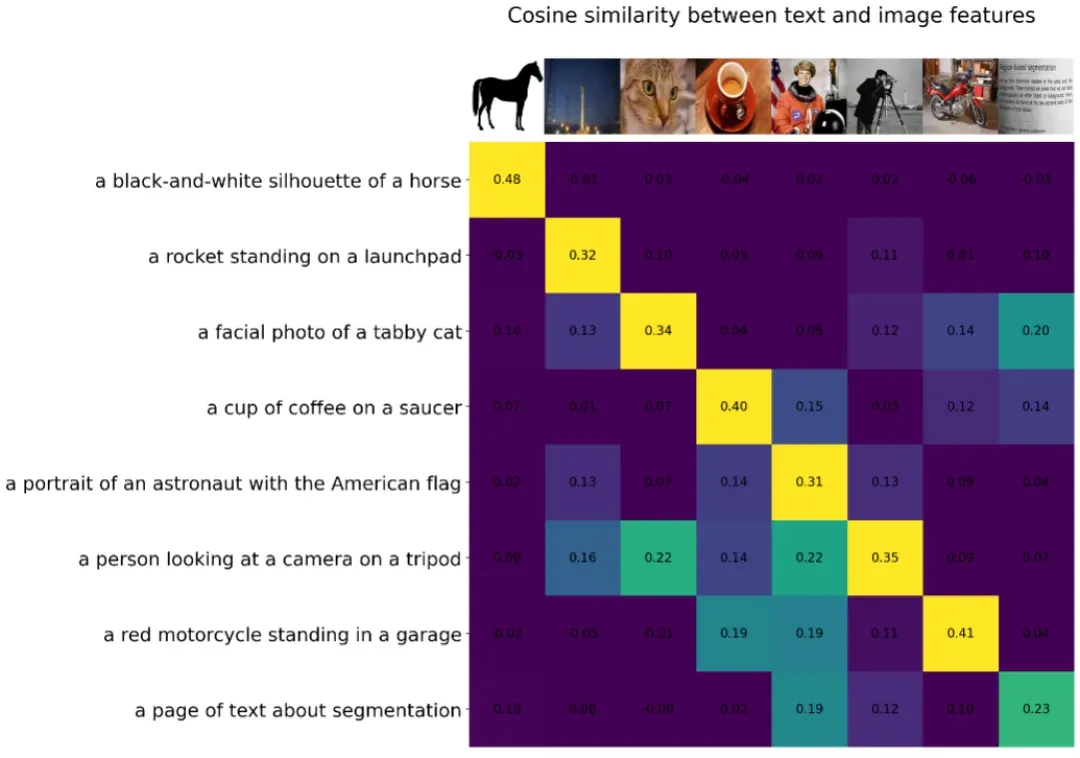
我们把相似度最高的,标记成了黄色,我们可以从上图看出,我们训练的模型在该情况下表现尚可。
体验总结
CLIP 模型思路新颖,同时比较容易理解,借助萤火二号和自研文件系统,我们可以比较高效地训练该模型,在训练的过程中,GPU 的平均使用率达到 80%+, GPU Memory 使用持续在 10GB+,总体训练效率也可以。
基于目前的数据和模型,我们后续还可以在萤火平台进行进一步的探索。
综合体验打分如下:
01:研究新颖度 ★★
该模型对图像文本分类领域提出了一个较为新颖的方法,有一定的技术推进性。
02:开源指数 ★★★★
官方开源了模型代码,并且 github 上有一些更加通用的开源代码参考,代码逻辑清晰可读性高。
03:算力需求 ★★★
解压后训练数据大小为 84 G,近 300 万条训练数据,6 节点大约需要 3 小时。
04:通用指数 ★★★
该模型虽然比较容易理解,但是在多模态领域还是比较有启发的,有可能会在一定程度上成为后续深入研究的 baseline。
05:模型适配度 ★★★★
额外依赖不多,在使用下载好的数据集的情况下我们只需要简单改一下 DataSet 等代码即可运行。
附录
论文 github:https://github.com/openai/CLIP
Clip 的一个开源实现:https://github.com/mlfoundations/open_clip
Google Conceptual Captions 数据集:https://ai.google.com/research/ConceptualCaptions/download
文章出处登录后可见!