大家好,今天和各位分享一下多智能体深度强化学习算法 ippo,并基于 gym 环境完成一个小案例。完整代码可以从我的 GitHub 中获得:https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model
1. 算法原理
多智能体的情形相比于单智能体更加复杂,因为每个智能体在和环境交互的同时也在和其他智能体进行直接或者间接的交互。因此,多智能体强化学习要比单智能体更困难,其难点主要体现在以下几点:
(1)由于多个智能体在环境中进行实时动态交互,并且每个智能体在不断学习并更新自身策略,因此在每个智能体的视角下,环境是非稳态的,即对于一个智能体而言,即使在相同的状态下采取相同的动作,得到的状态转移和奖励信号的分布可能在不断改变;
(2)多个智能体的训练可能是多目标的,不同智能体需要最大化自己的利益;
(3)训练评估的复杂度会增加,可能需要大规模分布式训练来提高效率。
iPPO 算法的模型部分和 PPO 类似,可以看我下面这篇博文:
https://blog.csdn.net/dgvv4/article/details/129496576?spm=1001.2014.3001.5501
IPPO(Independent PPO)是一种完全去中心化的算法,此类算法被称为独立学习。由于对于每个智能体使用单智能体算法 PPO 进行训练,所因此这个算法叫作独立 PPO 算法。
这里使用的 PPO 算法版本为 PPO-截断,其算法流程如下:

2. 代码实现
代码和 ppo 离散模型基本相同
# 和PPO离散模型基本一致
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np
# ----------------------------------------- #
# 策略网络--actor
# ----------------------------------------- #
class PolicyNet(nn.Module): # 输入当前状态,输出动作的概率分布
def __init__(self, n_states, n_hiddens, n_actions):
super(PolicyNet, self).__init__()
self.fc1 = nn.Linear(n_states, n_hiddens)
self.fc2 = nn.Linear(n_hiddens, n_hiddens)
self.fc3 = nn.Linear(n_hiddens, n_actions)
def forward(self, x): # [b,n_states]
x = self.fc1(x) # [b,n_states]-->[b,n_hiddens]
x = F.relu(x)
x = self.fc2(x) # [b,n_hiddens]-->[b,n_hiddens]
x = F.relu(x)
x = self.fc3(x) # [b,n_hiddens]-->[b,n_actions]
x = F.softmax(x, dim=1) # 每种动作选择的概率
return x
# ----------------------------------------- #
# 价值网络--critic
# ----------------------------------------- #
class ValueNet(nn.Module): # 评价当前状态的价值
def __init__(self, n_states, n_hiddens):
super(ValueNet, self).__init__()
self.fc1 = nn.Linear(n_states, n_hiddens)
self.fc2 = nn.Linear(n_hiddens, n_hiddens)
self.fc3 = nn.Linear(n_hiddens, 1)
def forward(self, x): # [b,n_states]
x = self.fc1(x) # [b,n_states]-->[b,n_hiddens]
x = F.relu(x)
x = self.fc2(x) # [b,n_hiddens]-->[b,n_hiddens]
x = F.relu(x)
x = self.fc3(x) # [b,n_hiddens]-->[b,1]
return x
# ----------------------------------------- #
# 模型构建
# ----------------------------------------- #
class PPO:
def __init__(self, n_states, n_hiddens, n_actions,
actor_lr, critic_lr,
lmbda, eps, gamma, device):
# 属性分配
self.n_hiddens = n_hiddens
self.actor_lr = actor_lr # 策略网络的学习率
self.critic_lr = critic_lr # 价值网络的学习率
self.lmbda = lmbda # 优势函数的缩放因子
self.eps = eps # ppo截断范围缩放因子
self.gamma = gamma # 折扣因子
self.device = device
# 网络实例化
self.actor = PolicyNet(n_states, n_hiddens, n_actions).to(device) # 策略网络
self.critic = ValueNet(n_states, n_hiddens).to(device) # 价值网络
# 优化器
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
# 动作选择
def take_action(self, state): # [n_states]
state = torch.tensor([state], dtype=torch.float).to(self.device) # [1,n_states]
probs = self.actor(state) # 当前状态的动作概率 [b,n_actions]
action_dist = torch.distributions.Categorical(probs) # 构造概率分布
action = action_dist.sample().item() # 从概率分布中随机取样 int
return action
# 训练
def update(self, transition_dict):
# 取出数据集
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device) # [b,n_states]
actions = torch.tensor(transition_dict['actions']).view(-1,1).to(self.device) # [b,1]
next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device) # [b,n_states]
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1,1).to(self.device) # [b,1]
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1,1).to(self.device) # [b,1]
# 价值网络
next_state_value = self.critic(next_states) # 下一时刻的state_value [b,1]
td_target = rewards + self.gamma * next_state_value * (1-dones) # 目标--当前时刻的state_value [b,1]
td_value = self.critic(states) # 预测--当前时刻的state_value [b,1]
td_delta = td_value - td_target # 时序差分 # [b,1]
# 计算GAE优势函数,当前状态下某动作相对于平均的优势
advantage = 0 # 累计一个序列上的优势函数
advantage_list = [] # 存放每个时序的优势函数值
td_delta = td_delta.cpu().detach().numpy() # gpu-->numpy
for delta in td_delta[::-1]: # 逆序取出时序差分值
advantage = self.gamma * self.lmbda * advantage + delta
advantage_list.append(advantage) # 保存每个时刻的优势函数
advantage_list.reverse() # 正序
advantage = torch.tensor(advantage_list, dtype=torch.float).to(self.device)
# 计算当前策略下状态s的行为概率 / 在之前策略下状态s的行为概率
old_log_probs = torch.log(self.actor(states).gather(1,actions)) # [b,1]
log_probs = torch.log(self.actor(states).gather(1,actions))
ratio = log_probs / old_log_probs
# clip截断
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1-self.eps, 1+self.eps) * advantage
# 损失计算
actor_loss = torch.mean(-torch.min(surr1, surr2)) # clip截断
critic_loss = torch.mean(F.mse_loss(td_value, td_target)) #
# 梯度更新
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward()
critic_loss.backward()
self.actor_optimizer.step()
self.critic_optimizer.step()3. 案例演示
ma-gym 库中的 Combat 环境。Combat 是一个在二维的格子世界上进行的两个队伍的对战模拟游戏,每个智能体的动作集合为:向四周移动格,攻击周围格范围内其他敌对智能体,或者不采取任何行动。起初每个智能体有 3 点生命值,如果智能体在敌人的攻击范围内被攻击到了,则会扣 1 生命值,生命值掉为 0 则死亡,最后存活的队伍获胜。每个智能体的攻击有一轮的冷却时间。
IPPO 代码实践的最主要部分。值得注意的是,在训练时使用了参数共享(parameter sharing)的技巧,即对于所有智能体使用同一套策略参数,这样做的好处是能够使得模型训练数据更多,同时训练更稳定。能够这样做的前提是,两个智能体是同质的(homogeneous),即它们的状态空间和动作空间是完全一致的,并且它们的优化目标也完全一致。感兴趣的读者也可以自行实现非参数共享版本的 IPPO,此时每个智能体就是一个独立的 PPO 的实例。
import numpy as np
import matplotlib.pyplot as plt
import torch
from ma_gym.envs.combat.combat import Combat
from RL_brain import PPO
import time
# ----------------------------------------- #
# 参数设置
# ----------------------------------------- #
n_hiddens = 64 # 隐含层数量
actor_lr = 3e-4
critic_lr = 1e-3
gamma = 0.9
lmbda = 0.97
eps = 0.2
device = torch.device('cuda') if torch.cuda.is_available() \
else torch.device('cpu')
num_episodes = 10 # 回合数
team_size = 2 # 智能体数量
grid_size = (15, 15)
# ----------------------------------------- #
# 环境设置--onpolicy
# ----------------------------------------- #
# 创建Combat环境,格子世界的大小为15x15,己方智能体和敌方智能体数量都为2
env = Combat(grid_shape=grid_size, n_agents=team_size, n_opponents=team_size)
n_states = env.observation_space[0].shape[0] # 状态数
n_actions = env.action_space[0].n # 动作数
# 两个智能体共享同一个策略
agent = PPO(n_states = n_states,
n_hiddens = n_hiddens,
n_actions = n_actions,
actor_lr = actor_lr,
critic_lr = critic_lr,
lmbda = lmbda,
eps = eps,
gamma = gamma,
device = device,
)
# ----------------------------------------- #
# 模型训练
# ----------------------------------------- #
for i in range(num_episodes):
# 每回合开始前初始化两支队伍的数据集
transition_dict_1 = {
'states': [],
'actions': [],
'next_states': [],
'rewards': [],
'dones': [],
}
transition_dict_2 = {
'states': [],
'actions': [],
'next_states': [],
'rewards': [],
'dones': [],
}
s = env.reset() # 状态初始化
terminal = False # 结束标记
while not terminal:
env.render()
# 动作选择
a_1 = agent.take_action(s[0])
a_2 = agent.take_action(s[1])
# 环境更新
next_s, r, done, info = env.step([a_1, a_2])
# 构造数据集
transition_dict_1['states'].append(s[0])
transition_dict_1['actions'].append(a_1)
transition_dict_1['next_states'].append(next_s[0])
transition_dict_1['dones'].append(False)
transition_dict_1['rewards'].append(r[0])
transition_dict_2['states'].append(s[1])
transition_dict_2['actions'].append(a_2)
transition_dict_2['next_states'].append(next_s[1])
transition_dict_2['dones'].append(False)
transition_dict_2['rewards'].append(r[1])
s = next_s # 状态更新
terminal = all(done) # 判断当前回合是否都为True,是返回True,不是返回False
time.sleep(0.1)
print('epoch:', i)
# 回合训练
agent.update(transition_dict_1)
agent.update(transition_dict_2)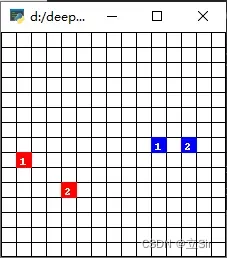
文章出处登录后可见!