Stable Diffusion 原理介绍与源码分析(一)
文章目录
前言(与正文无关,可以忽略)
Stable Diffusion 是 Stability AI 公司开源的 AI 文生图扩散模型。之前在文章 扩散模型 (Diffusion Model) 简要介绍与源码分析 中介绍了扩散模型的原理与部分算法代码,满足基本的好奇心后便将其束之高阁,没成想近期 AIGC 的发展速度之快大大出乎我的意料,尤其是亲手跑出下面这张 AI 生成的图像, Stable Diffusion 终又重新回到我的视野:

作为一名算法工程师,需要有一双能看透事物本质的眼睛,这张图片最先吸引我的不是内容,而是其生成质量:图像高清、细节丰富,非之前看到的一些粗陋 Toy 可比,红框中标注出来的不协调之处,也是瑕不掩瑜。因此,进一步分析 Stable Diffusion 整个工程框架的原理,实在是迫在眉睫,期待日后能修复红框中的不协调之处,为 AIGC 的进一步发展做出一个技术人员应有的贡献。
总览
Stable Diffusion 整个框架的源码有上万行,没有必要全部分析。本文以 “文本生成图像(text to image)” 为主线,考察 Stable Diffusion 的运行流程以及各个重要的组成模块,在介绍时采用 “总-分” 的形式,先概括整体框架,再分析各个组件(如 DDPM、DDIM 等),另外针对代码中的部分非主流逻辑,比如 predict_cids、return_ids 这些小细节谈谈我的看法。文章内容较长,准备拆分成多个部分。
源码地址:Stable Diffusion
说明
之前我写过很多代码分析文章,但在我遇到问题重新去翻阅时,发现要快速定位到目标位置并准确理解代码意图,仍然存在很大困难,密密麻麻的整块代码,每一次阅读都仿若初见,不易理解,原因在于摘录时引入过多的实现细节,降低了信息的传播效率。
经过一番思考,我不再图省事,决定采用伪代码的方式记录核心原理。平时我深度分析代码时会采用这种方式,对代码进行额外的抽象,相对会耗些时间,但私以为这是有益处的。举个例子,比如 DDPM 模型前向 Diffusion 的代码,如果我用伪代码的方式去写,将是如下的效果:

可以看到,刨除掉无关的实现细节之后,DDPM 的实现是如此的简洁,倘若再配合一定的注释,可方便快速理解,让人获得一种整体而全面的掌控感。此外还应该在文中多增加框图、模型图等来对代码的实现细节进行更直观的展示。
可以在微信中搜索 “珍妮的算法之路” 或者 “world4458” 关注我的微信公众号, 可以及时获取最新原创技术文章更新.
另外可以看看知乎专栏 PoorMemory-机器学习, 以后文章也会发在知乎专栏中.
Stable Diffusion 整体框架
首先看下 Stable Diffusion 文本生成图像整体框架(文章绘图吐血…希望有一天 AI 能进行辅助):
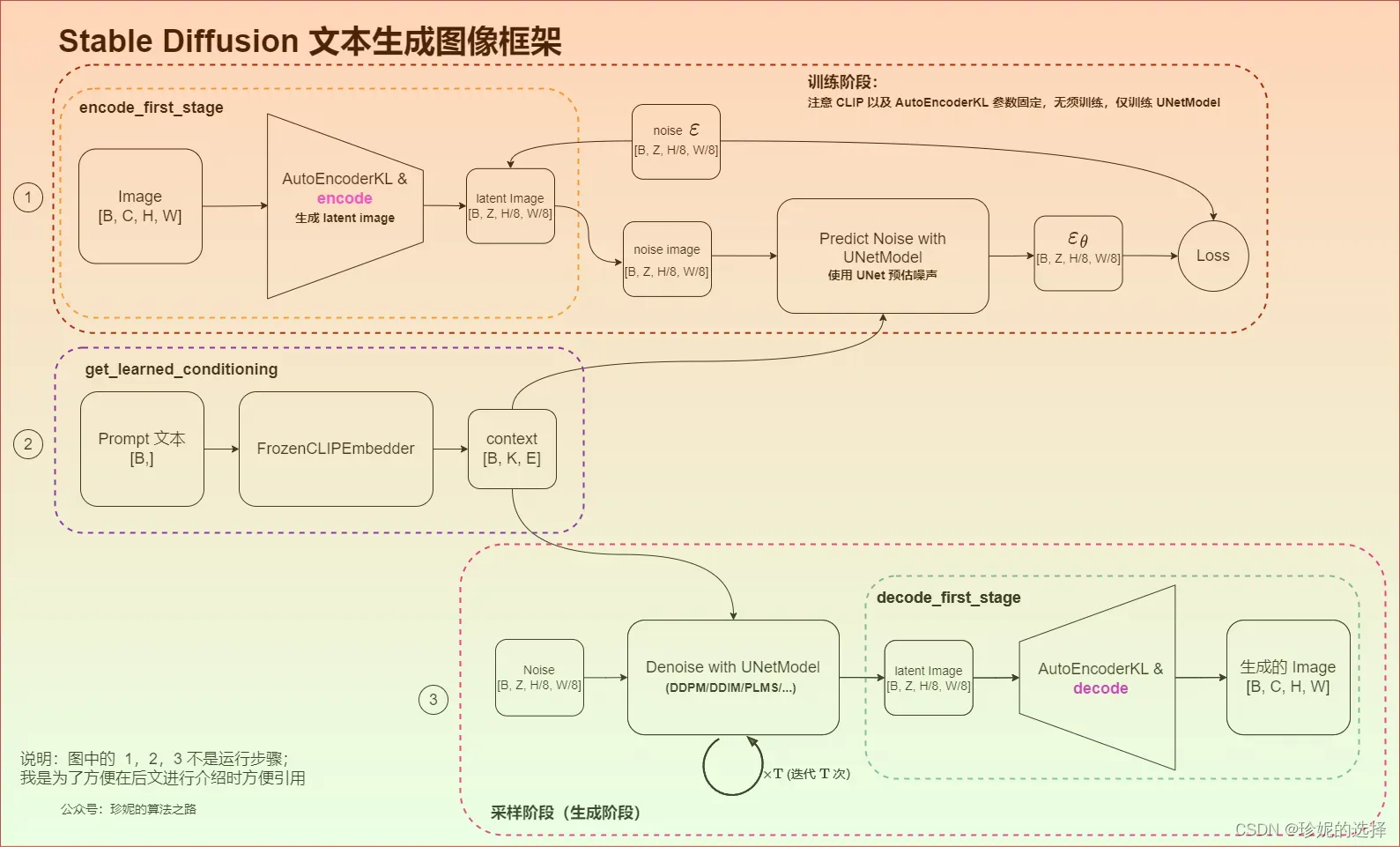
上图框架内的模块较多,从上到下分为 3 块,我在图中使用 Part 1、2、3 进行了标注。框架包含训练 + 采样两个阶段,其中:
-
训练阶段 (查看图中 Part 1 和 Part 2),主要包含:
- 使用 AutoEncoderKL 自编码器将图像 Image 从 pixel space 映射到 latent space,学习图像的隐式表达,注意 AutoEncoderKL 编码器已提前训练好,参数是固定的。此时 Image 的大小将从
[B, C, H, W]转换为[B, Z, H/8, W/8],其中Z表示 latent space 下图像的 Channel 数。这一过程在 Stable Diffusion 代码中被称为encode_first_stage; - 使用 FrozenCLIPEmbedder 文本编码器对 Prompt 提示词进行编码,生成大小为
[B, K, E]的 embedding 表示(即context),其中K表示文本最大编码长度 max length,E表示 embedding 的大小。这一过程在 Stable Diffusion 代码中被称为get_learned_conditioning; - 进行前向扩散过程(Diffusion Process),对图像的隐式表达进行不断加噪,该过程调用 UNetModel 完成;UNetModel 同时接收图像的隐式表达 latent image 以及文本 embedding
context,在训练时以context作为 condition,使用 Attention 机制来更好的学习文本与图像的匹配关系; - 扩散模型输出噪声
,计算和真实噪声之间的误差作为 Loss,通过反向传播算法更新 UNetModel 模型的参数,注意这个过程中 AutoEncoderKL 和 FrozenCLIPEmbedder 中的参数不会被更新。
- 使用 AutoEncoderKL 自编码器将图像 Image 从 pixel space 映射到 latent space,学习图像的隐式表达,注意 AutoEncoderKL 编码器已提前训练好,参数是固定的。此时 Image 的大小将从
-
采样阶段(查看图中 Part 2 和 Part 3),也就是我们加载模型参数后,输入提示词就能产出图像的阶段。主要包含:
- 使用 FrozenCLIPEmbedder 文本编码器对 Prompt 提示词进行编码,生成大小为
[B, K, E]的 embedding 表示(即context); - 随机产出大小为
[B, Z, H/8, W/8]的噪声 Noise,利用训练好的 UNetModel 模型,按照 DDPM/DDIM/PLMS 等算法迭代 T 次,将噪声不断去除,恢复出图像的 latent 表示; - 使用 AutoEncoderKL 对图像的 latent 表示(大小为
[B, Z, H/8, W/8])进行 decode(解码),最终恢复出 pixel space 的图像,图像大小为[B, C, H, W]; 这一过程在 Stable Diffusion 中被称为decode_first_stage。
- 使用 FrozenCLIPEmbedder 文本编码器对 Prompt 提示词进行编码,生成大小为
经过上面的介绍,对 Stable Diffusion 整体会有个较清晰的认识,下面就可以按图索骥,将各个重点模块尽力去弄明白。限于个人精力与有限的空闲时间,目前除了 FrozenCLIPEmbedder 和 DPM 算法 (图中没写),Stable Diffusion 的其他模块都大致看了看,包括:
- UNetModel
- AutoEncoderKL & VQModelInterface (也是一种变分自动编码器,图上没画)
- DDPM、DDIM、PLMS 算法
后面会简单介绍一下,记录学习过程。
重要论文
在阅读代码的过程中,发现有些重量级的论文必须得阅读一下。扩散模型的理论推导还是有些复杂的,有时候公式推导和代码实现相互结合看,可以加深对知识的理解。这里列一下对我阅读代码有很大帮助的论文:
- Denoising Diffusion Probabilistic Models : DDPM,这个是必看的,推推公式
- Denoising Diffusion Implicit Models :DDIM,对 DDPM 的改进
- Pseudo Numerical Methods for Diffusion Models on Manifolds :PNMD/PLMS,对 DDPM 的改进
- High-Resolution Image Synthesis with Latent Diffusion Models :Latent-Diffusion,必看
- Neural Discrete Representation Learning : VQVAE,简单翻了翻,示意图非常形象,很容易了解其做法
重要组成模块分析
下面对 Stable Diffusion 中的重要组成模块进行简要分析。主要包含:
- UNetModel
- DDPM、DDIM、PLMS 算法
- AutoEncoderKL
- 对部分非主流的逻辑,如
predict_cids、return_ids等谈谈看法
首先介绍一下 UNetModel 结构,方便后续的文章直接进行引用。
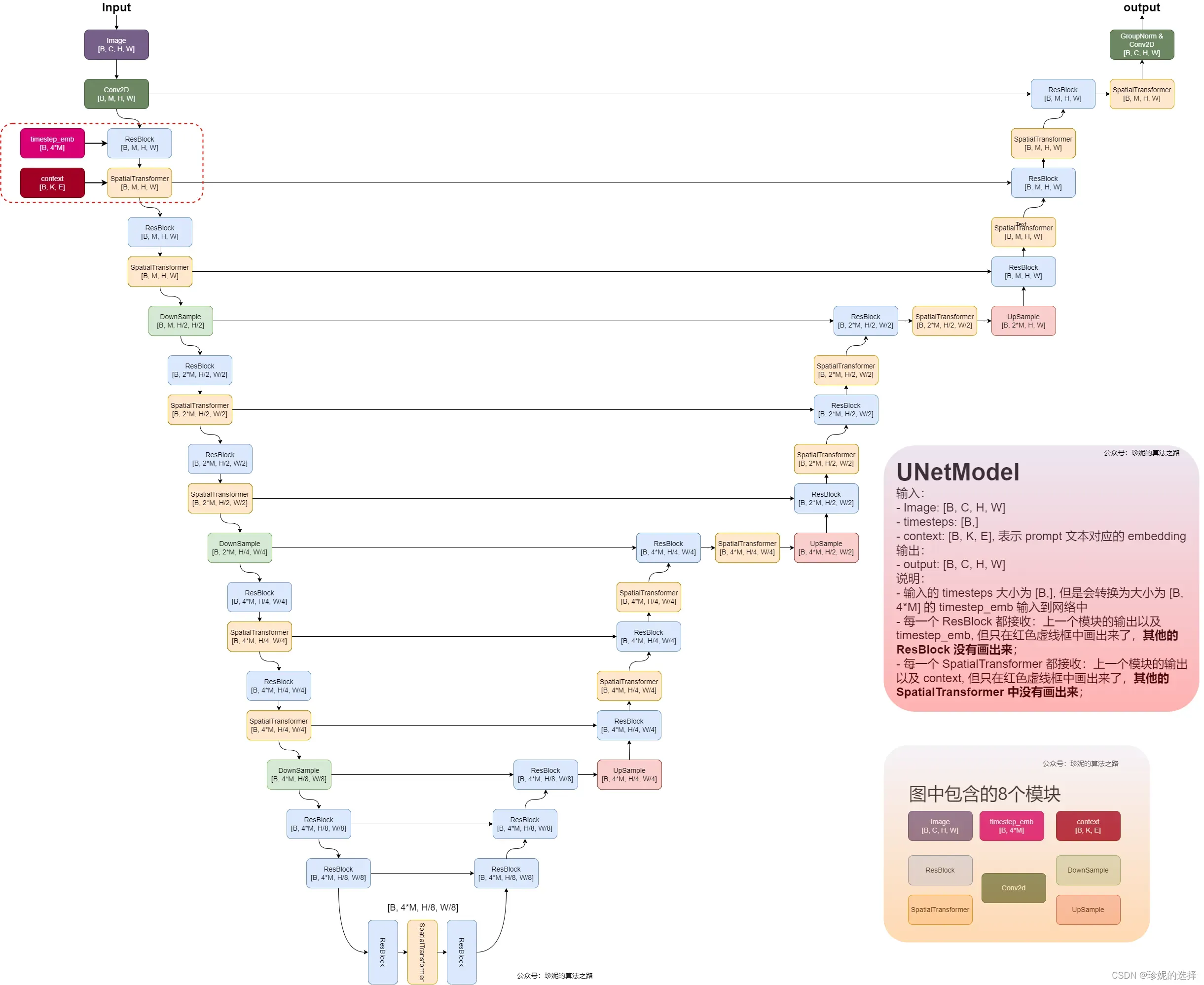
UNetModel 介绍
画了一下 Stable Diffusion 中使用的 UNetModel,就不分析代码了,看图很容易将代码写出来。Stable Diffusion 采用 UNetModel 这种 Encoder-Decoder 结构来实现扩散的过程,对噪声进行预估, 网络结构如下:
文章出处登录后可见!