前言
- 在上篇文章《人工智能大模型之ChatGPT原理解析》中分享了一些大模型之ChatGPT的核心原理后,收到大量读者的反馈,诸如:在了解了核心原理后想进一步了解未来的发展趋势(比如生成式人工智能和元宇宙能擦出什么样的火花?),大模型如何优化现有技术(如:如何提高图像文档识别准确率等)…
- 近期有幸参加了中国图像图形学学会和合合信息共同举办的CSIG企业行活动,对活动中的干货自己花了一些精力进行系统性研究与整理,在此与大家共享
- 此次活动邀请了图像描述与视觉问答、图文公式识别、自然语言处理的自注意力模型、视觉创造的机器学习等领域的优秀学者前来分享交流;旨在面向文档图像分析与识别的前沿研究领域为学者们、从业者们提供交流与研讨的机会,促进产学研交流与合作
- 本文站在大模型之ChatGPT的实际应用以及促进未来发展方向与大家共享,希望得到更多读者的反馈
学完本篇博文,你将学到哪些内容
- 生成式人工智能和元宇宙相互促进
- 生成式人工智能技术趋势
- 文档结构建模(部首建模、SEM表格建模、训练模型)
- 文档图像中底层视觉技术(扫描、矫正、去除阴影、防篡改)
全景一张图
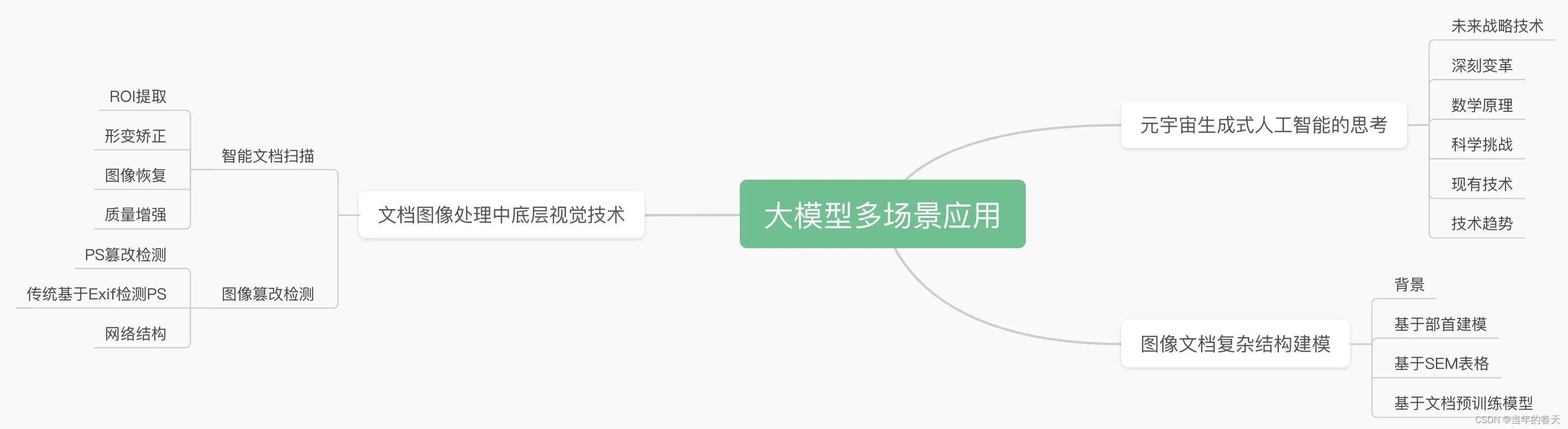
元宇宙&生成式人工智能思考
生成式人工智能是什么?
一类能够生成新的、原创的内容的人工智能模型。这些模型通常基于深度学习技术,能够通过学习输入的数据,生成新的数据或者文本。这些模型已经在许多领域取得了成功,如图像生成、自然语言处理等。在元宇宙中,生成式人工智能可以用来创造新的虚拟物品、环境、角色等,丰富元宇宙的内容。
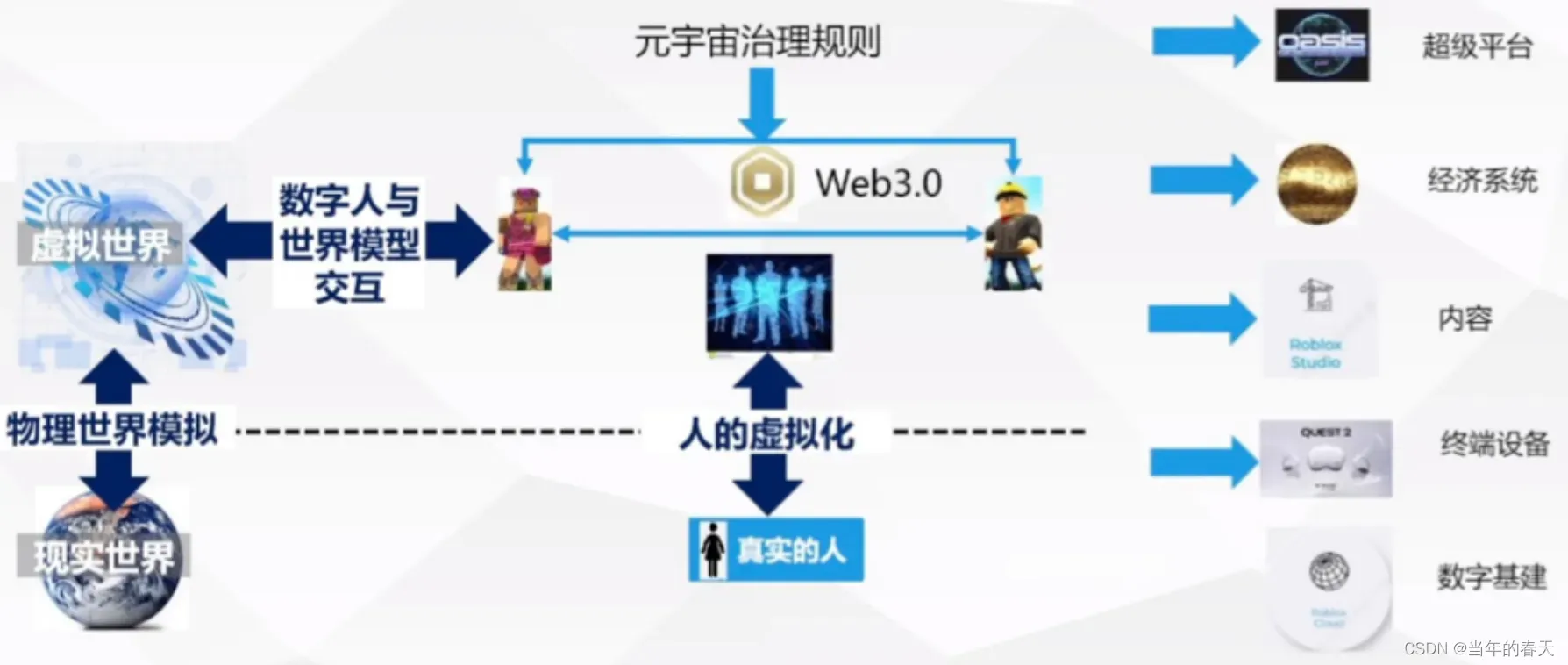
元宇宙是什么?
元宇宙是一个虚拟的、完全互联的世界,包括人工智能、虚拟现实、增强现实等技术的融合,使人们可以在其中进行各种活动。元宇宙是一个复杂的系统,需要大量的技术和资源来实现。
生成式人工智能和元宇宙的关系
生成式人工智能可以为元宇宙提供新的内容和创意,使其更加生动和有趣。同时,元宇宙也可以为生成式人工智能提供更多的数据和场景,以便其能够更好地学习和生成内容。
如何促进元宇宙实现?
要促进元宇宙的实现,需要采取多种措施,包括技术研发、投资支持、政策引导等。其中,生成式人工智能可以为元宇宙提供独特的价值,可以通过以下方式促进元宇宙的实现:
- 提供丰富的内容和创意,使元宇宙更加生动和有趣;
- 优化元宇宙的交互和用户体验,提高用户参与度;
- 促进元宇宙的商业化和价值创造,推动元宇宙向着可持续发展的方向发展;
- 加强元宇宙的安全和隐私保护,保障用户权益。
未来战略技术
- 通过机器学习方法从数据中学习特征,进而生成全新的、原创的数据,这些数据与训练数据保持相似,而不是复制
- 预计到2025,生成式人工智能产生的数据将占据人类全部数据的10%
- 当生成式数据超过80%的时候,人类是否全面进入元宇宙?
- Gartner预测,预计未来几年,生成模型将会变得更加智能化、自适应、多模态、可解释性和控制性、创造性应用将得到增长、更快、更高效、个人化等方面得到进一步发展
深刻变革
- 推动内容开发、视觉艺术创作、数字孪生、自动编程等
- 为科学研究提供AI直觉,生成式人工智能是指可以生成类似于人类创造的东西(例如文字、图像、音乐等)的人工智能系统。这种系统使用机器学习算法,通过学习大量数据集中的模式来创造新的数据
- 促进虚实融合(效率提升、体验提升、精神提升)
数学原理
学习一个概率分布 p(x) 是指学习如何生成符合该分布的样本。一旦学习完成,我们可以通过采样来从该分布中生成新的样本,也可以通过呈现函数 f(x) 将样本呈现出来
![[图片]](https://aitechtogether.com/wp-content/uploads/2023/05/c5640349-4a3f-44dc-904d-c40d003b0de1.webp)
科学挑战
-
解空间巨大(如何有效寻找并生成子空间);在高维空间中,解空间通常是巨大的,因此如何有效地搜索和生成子空间是一个重要的问题。常见的方法包括贪心搜索、遗传算法、蒙特卡罗方法和基于模型的优化
-
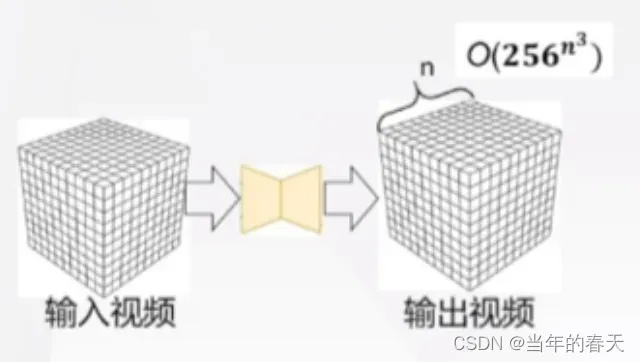
宏观一致性(如何预测目标及结构的长期运动变化);主要的解决方法包括基于光流的方法和基于深度学习的方法
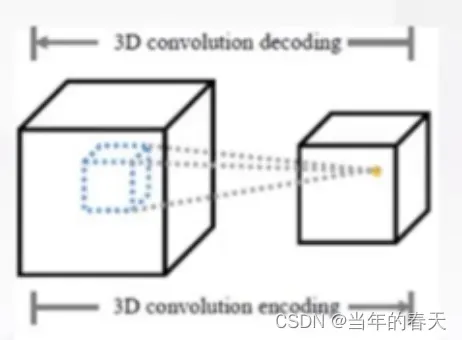
-
微观清晰度(如何有效逼近多模分布),其关键在于如何有效逼近多模分布;目前主要的解决方法包括基于插值的方法和基于深度学习的方法
现有技术
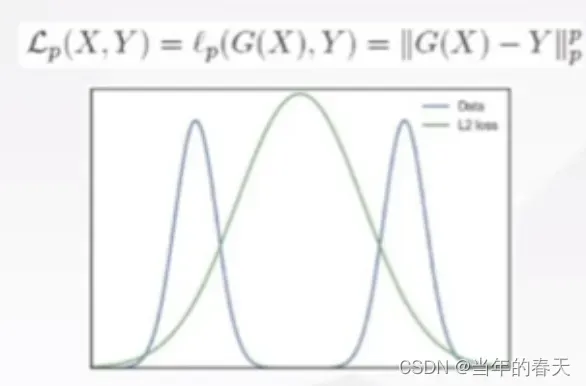
- 学习概率分布其目标是根据给定的数据,学习出符合数据分布的概率分布模型。一般来说,学习概率分布可以通过显式求解、近似求解和隐式求解三种方法来实现
- 神经网络渲染是指使用神经网络来合成高质量的图像或视频。其核心思想是将渲染问题建模为一个函数逼近问题,即输入场景描述和参数,输出合成的图像或视频。
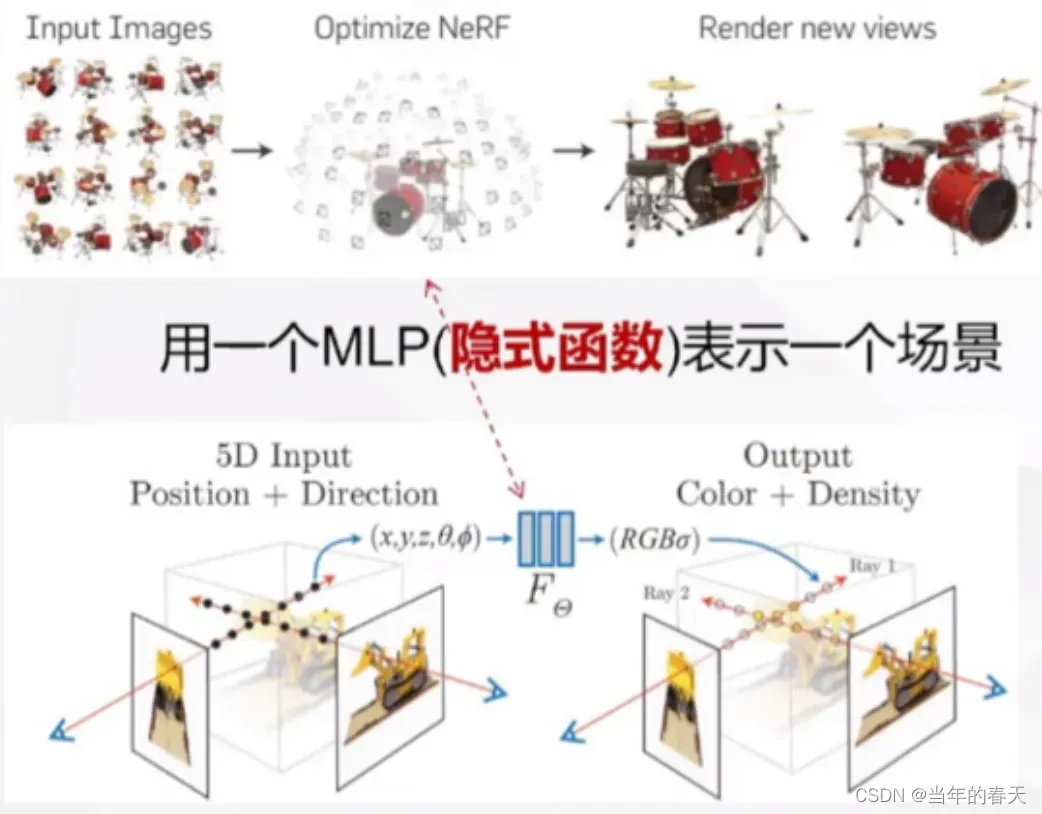
技术趋势
- 从生成到推断(表观模拟—>物理现象内部机理推断),世界模型更逼近物理现实
- 从平面到立体(立体视觉渲染、多模态驱动、动态模拟),数字人更逼真,更通用
- 数字人与世界模型交互(在世界模型上训练智能体,可反哺真实世界中的决策过程)
图像文档复杂结构建模
背景
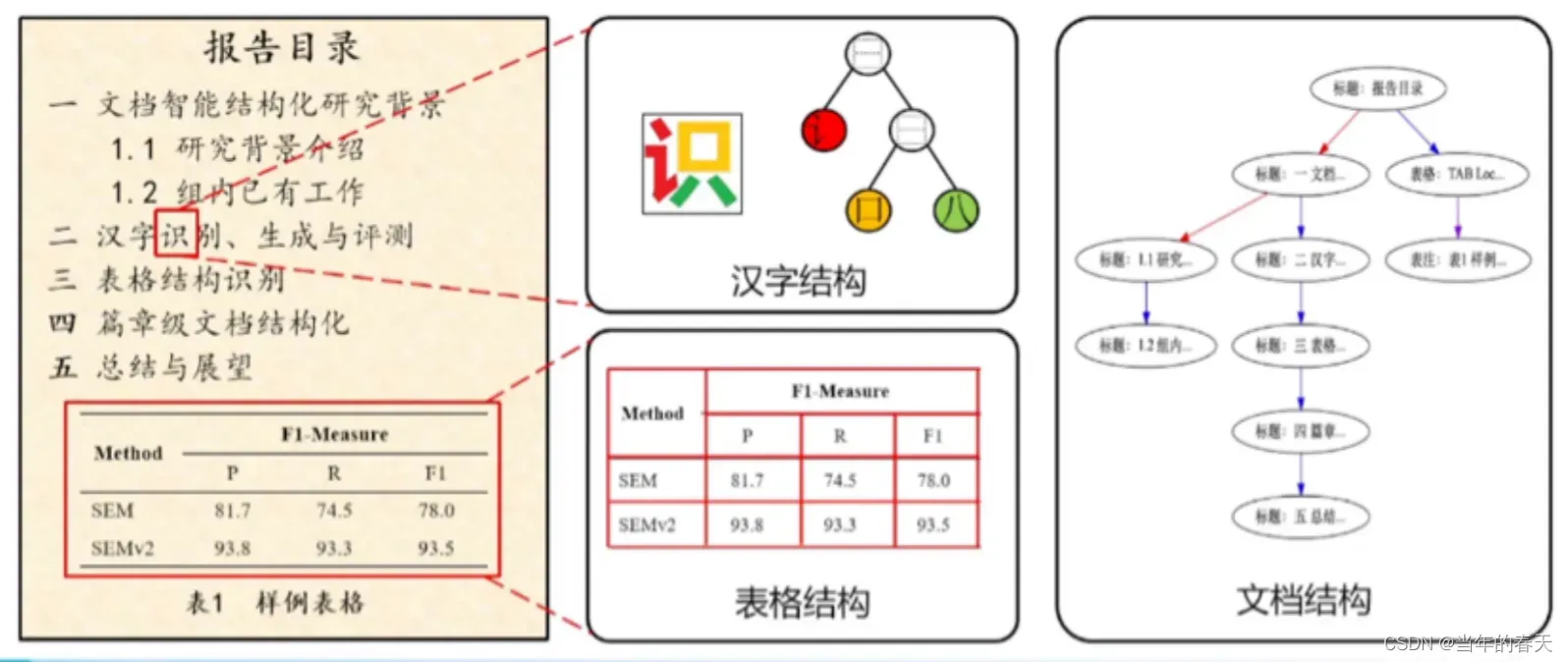
-
文档中不同要素的结构信息,通过扫描文档,将标题,内容(汉字,表格)进行识别
-
基于编码器模型的结构化建模
基于部首建模
-
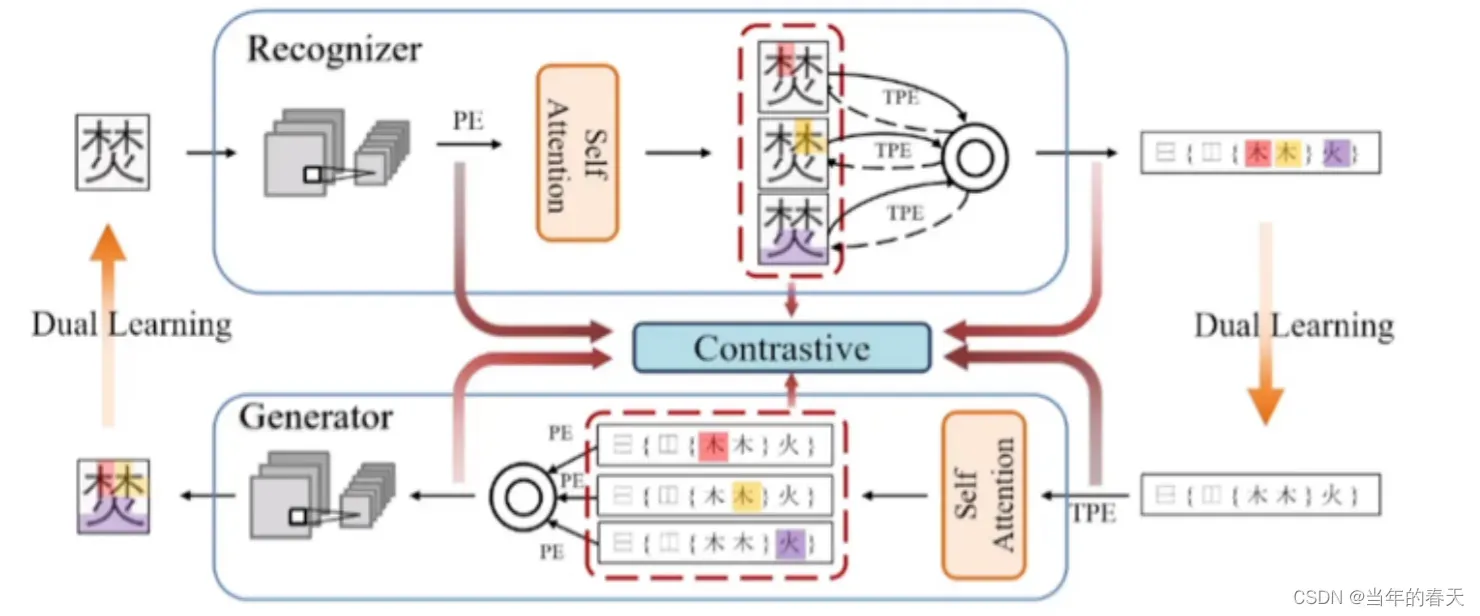
生成系统的联合优化策略设计,在文档智能处理领域,涉及到了多个方面的问题和技术,比如文档结构建模、错字检测、表格检测、PDF解析、神经网络渲染等。这些技术通过联合使用,可以实现文档智能处理的各种任务,例如文本识别、表格识别、图像识别、文档分析等
-
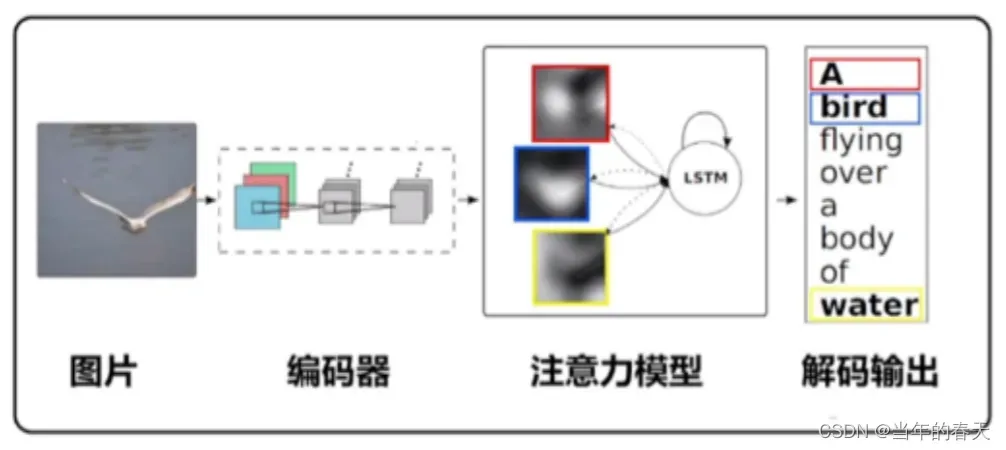
识别与生成任务中的注意力可视化,注意力机制被广泛应用于识别和生成任务中,用于将不同部分的文本信息分配给相应的建模单元

-
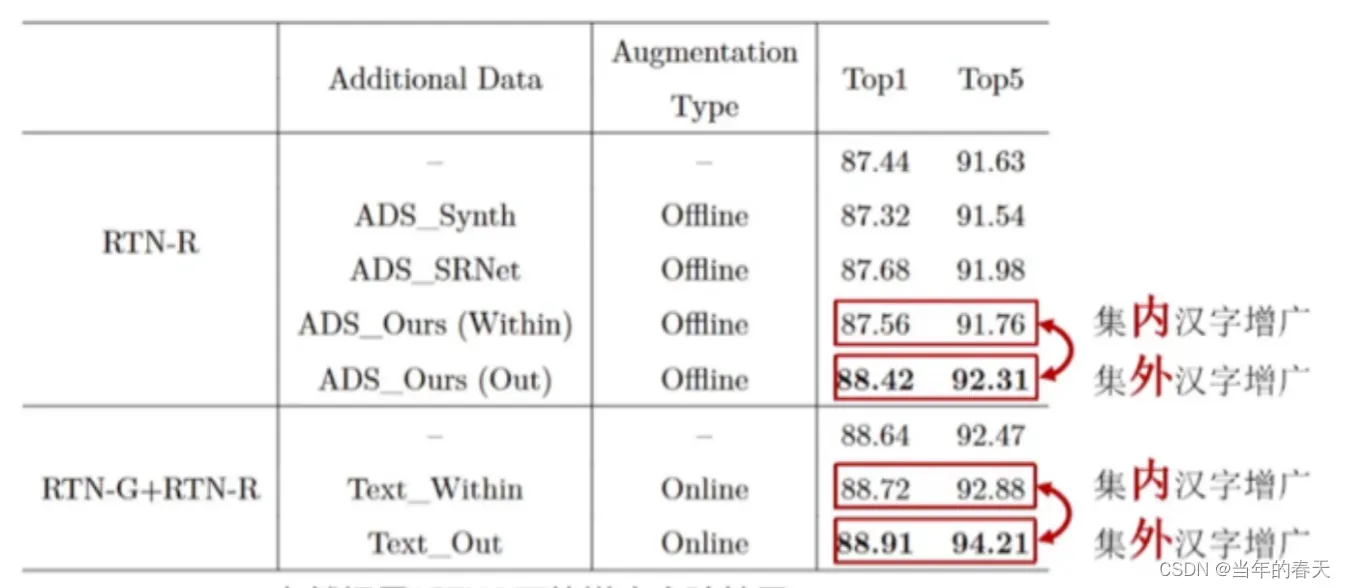
集外汉字生成对识别性能的影响,传统的汉字识别系统通常基于已知的汉字集合来训练和测试模型,这些汉字集合是事先确定的。如果集外汉字出现在测试集中,传统的汉字识别系统很可能无法正确识别这些汉字,因为这些汉字不在训练集合中。因此,集外汉字的出现会严重影响汉字识别系统的性能。
-
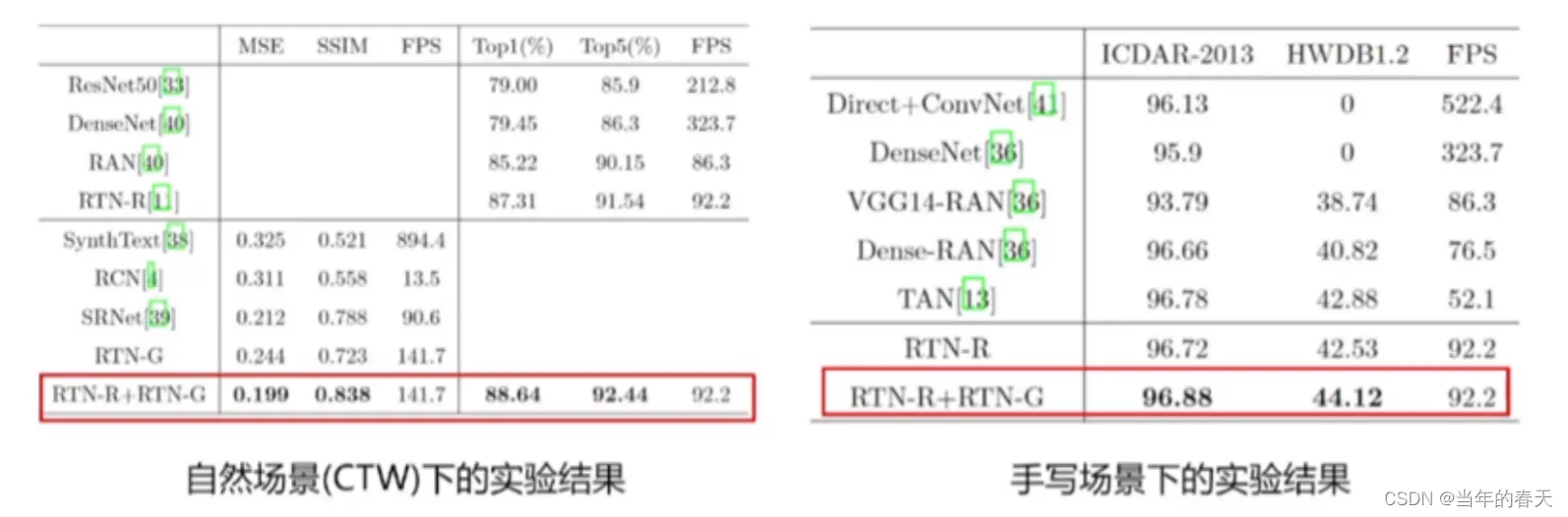
联合优化策略的性能分析,首先联合优化策略可以提高模型的泛化能力,即在新的数据上也能取得较好的性能;其次联合优化策略也可以提高计算效率;最后联合优化策略的收敛速度也需要进行分析。
-
弱化语言模型,提高错字的识别的召回率;由于语言模型对语言的先验知识和模式的强依赖性,当输入数据的领域和语言模型的训练领域不匹配时,语言模型可能会出现错误的纠正结果。因此,弱化语言模型的影响,提高错字的识别的召回率,是一种可行的方法
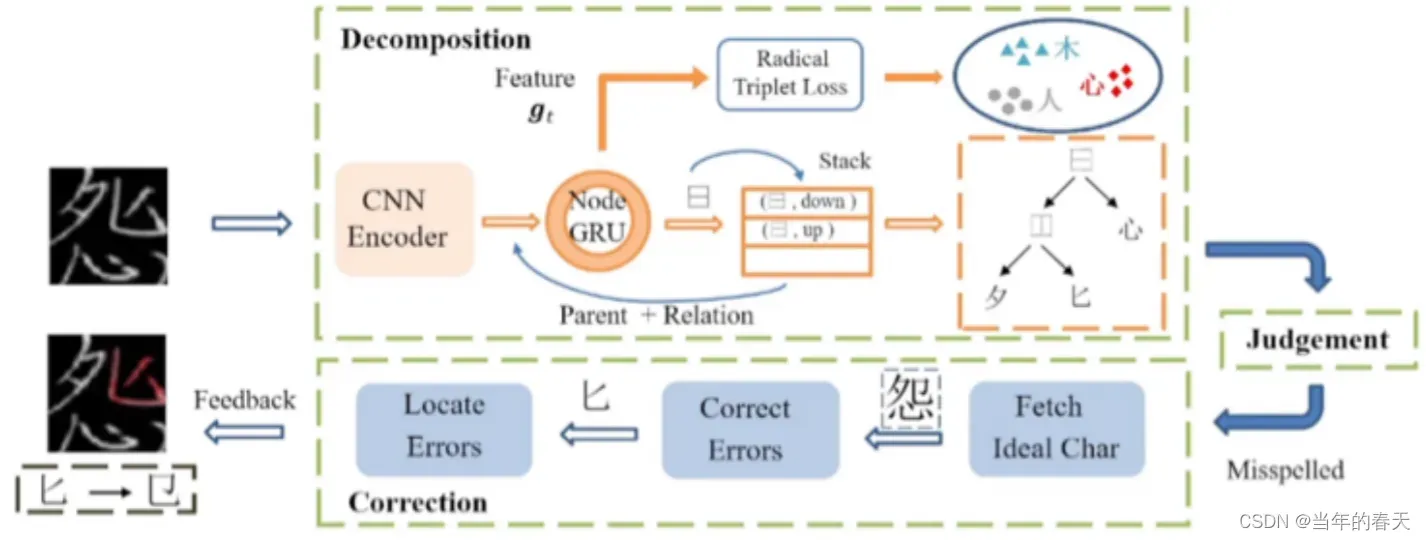
-
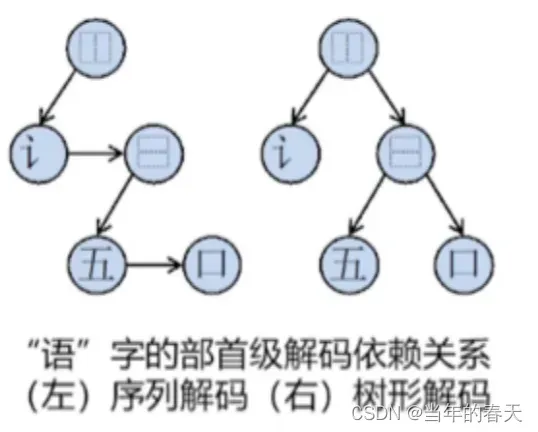
树型解码器原理,基本原理是将错字的识别问题转化为序列标注问题,通过建立错字候选集合和正确词典,来进行错误字符的纠正
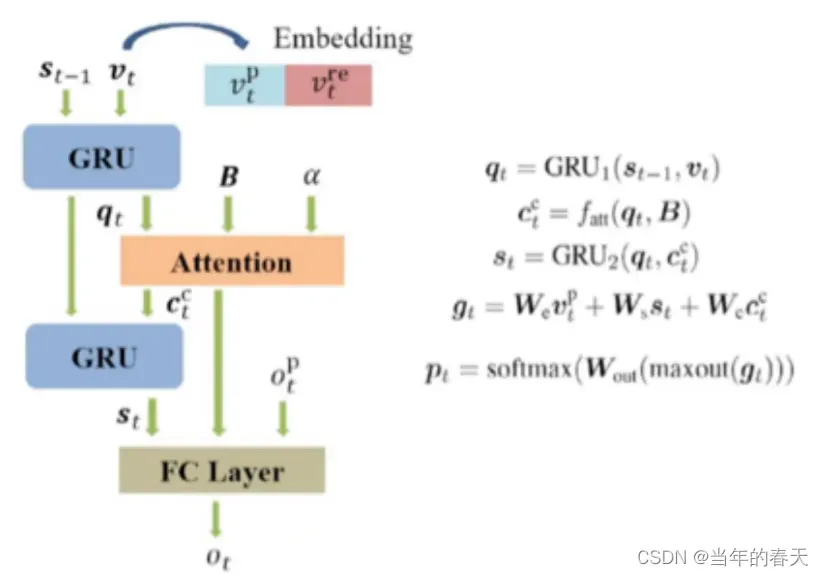
-
解码依赖关系指的是在序列标注等任务中,当前标签的预测可能会受到之前预测标签的影响
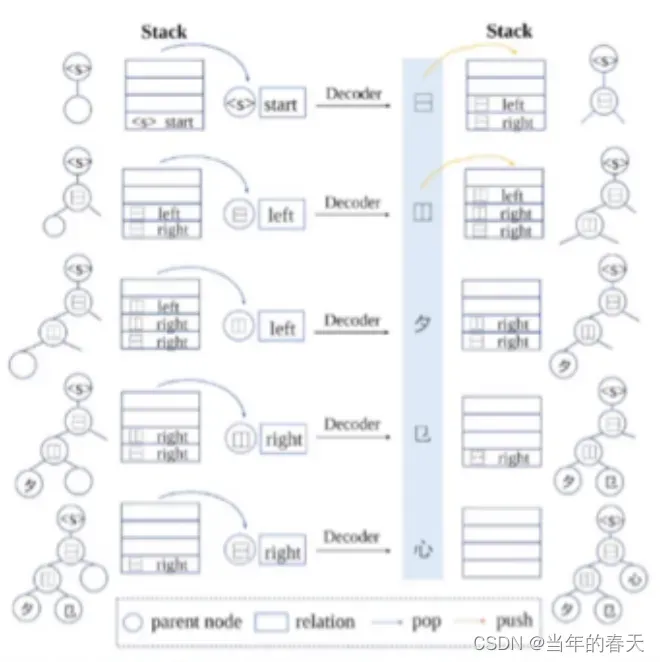
-
解码算法流程以及实验结果;其中解码是自然语言处理中的一个重要环节,其目的是根据模型预测的得分,得到最优的输出序列或者结构;在实际应用中,根据任务的不同以及解码算法的特点,需要选择合适的解码算法。同时,针对不同的任务和模型,可以进行解码依赖关系的分析和解码算法的优化,以提高模型的性能。
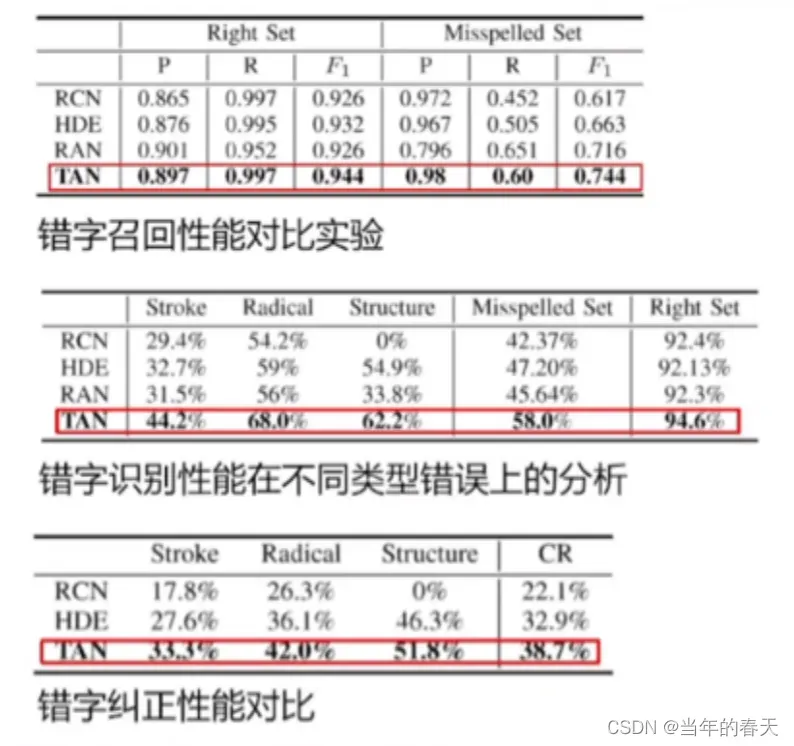
-
错字检测与错误定位的可视化分析,其中可视化分析在错字检测和错误定位任务中具有重要的作用,可以帮助我们更好地理解和分析数据和模型的结果,从而提高任务的效率和准确性
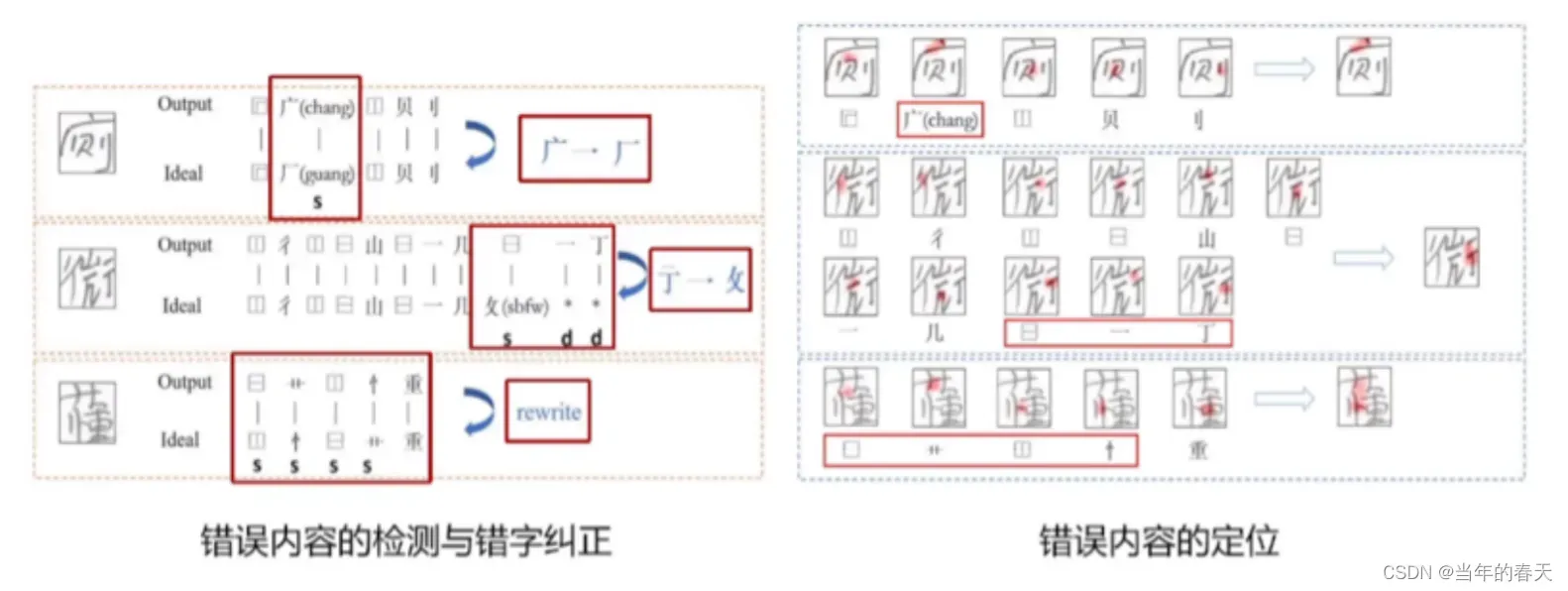
基于SEM表格
-
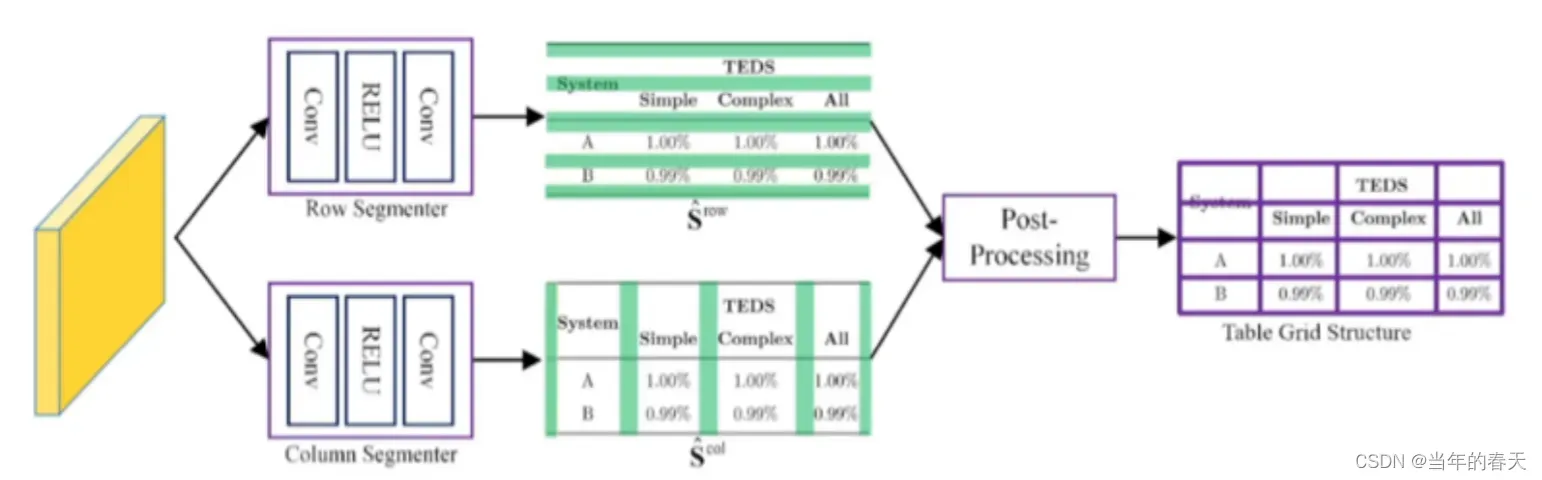
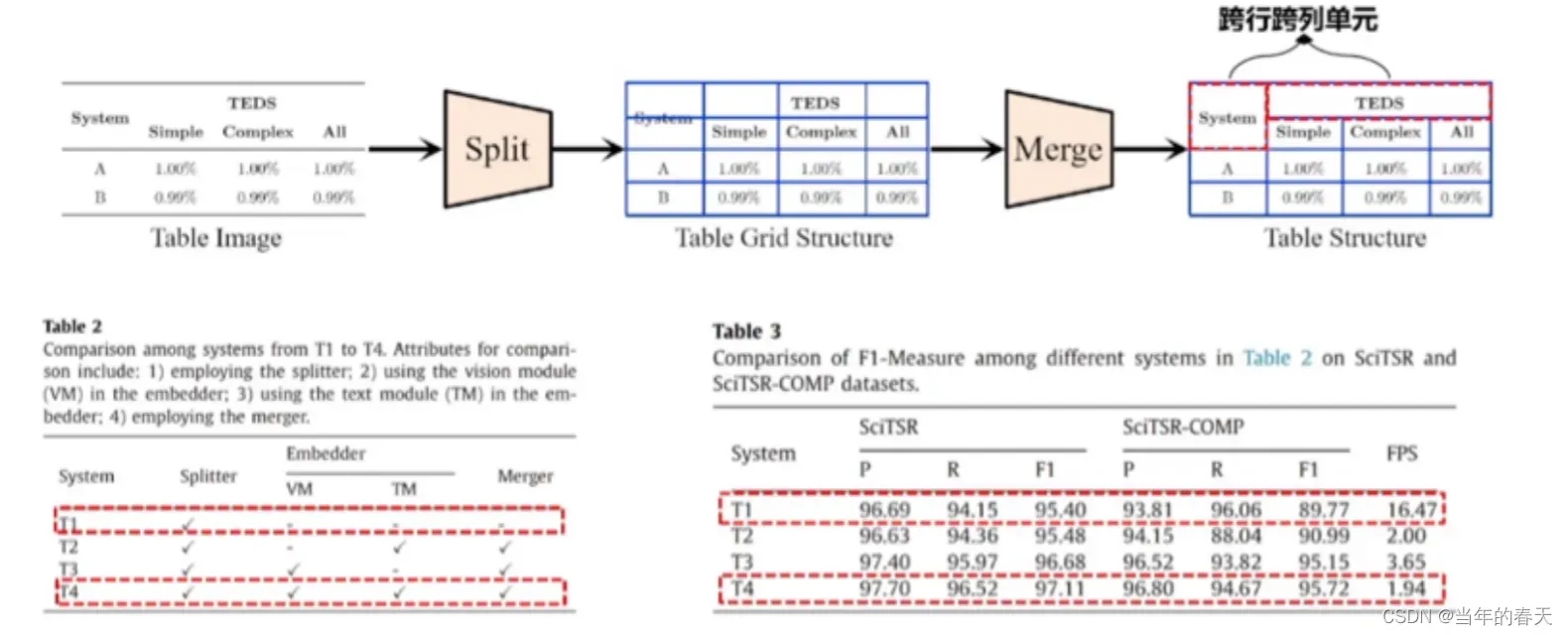
split:将表格图像拆分成基础网格是表格识别和理解中一个重要的预处理步骤,其目的是将表格图像划分成基本的单元格,为后续的表格结构分析和内容识别提供基础
-
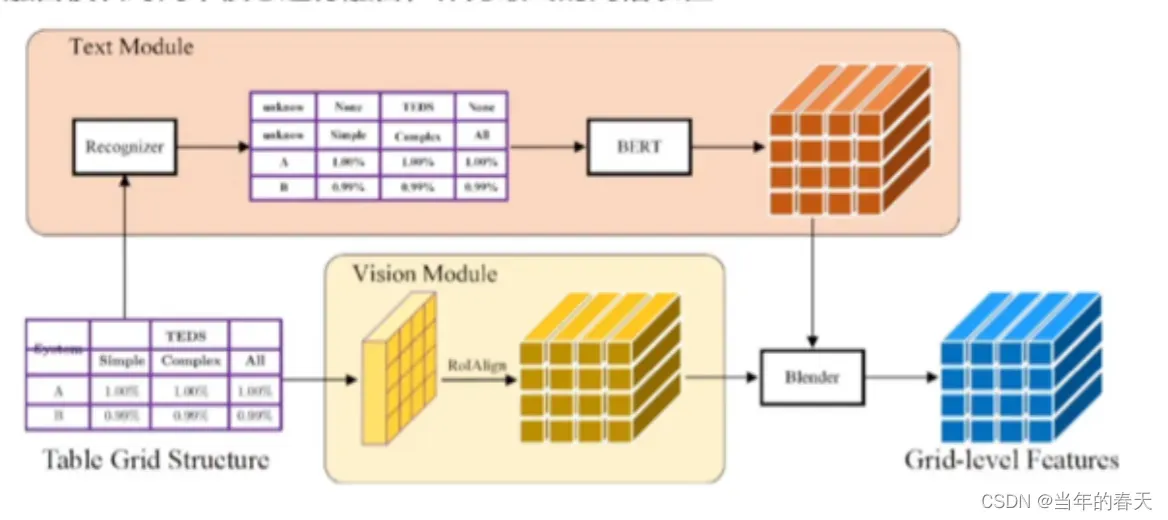
提取网格级别的多模态特征是表格识别和理解中的一个关键问题。表格中的内容通常包含文本、图像、公式等多种类型,因此需要利用不同类型的特征来描述单元格的内容,以便后续的内容识别和结构分析
-
merge:完成基础网格归并并预测,在表格图像中,每个单元格可能由多个基础网格组成,因此需要将相邻的基础网格归并为单个单元格,以便后续的内容识别和结构分析
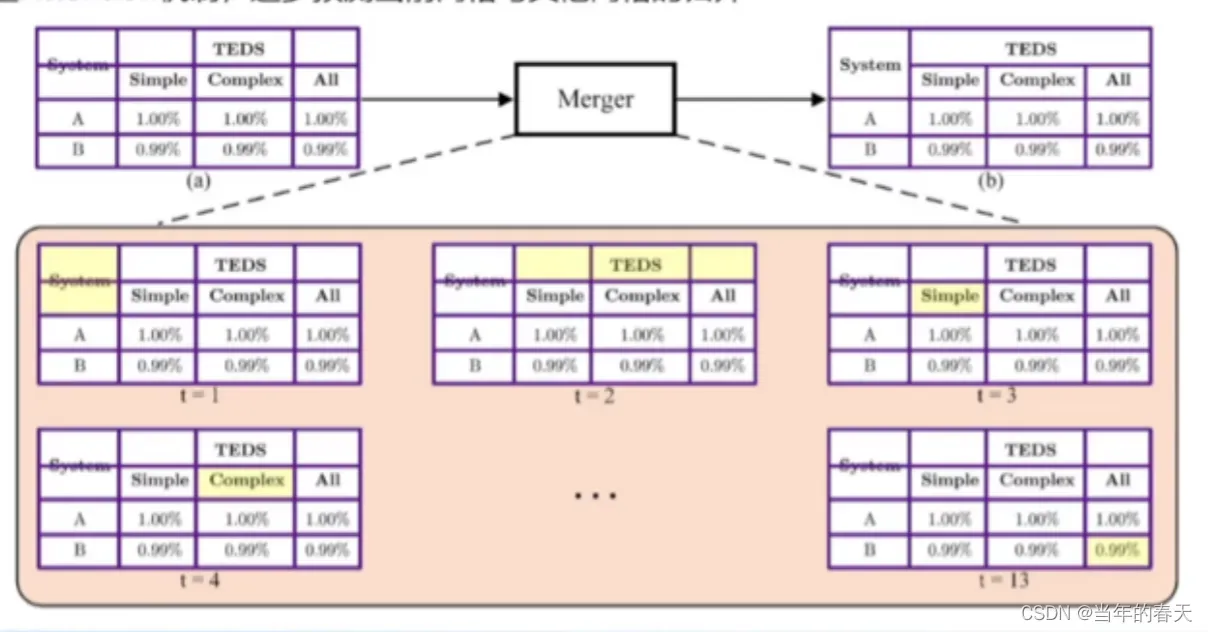
-
处理跨行跨列表格单元是表格识别和理解中的一项关键任务,涉及到单元格的合并和拆分,对表格结构的分析和内容识别有着重要的影响
-
处理多行文本的表格单元,主要涉及到如何将跨行的文本合并到同一个表格单元中进行识别和分析;处理多行文本的表格单元需要充分考虑表格中的语义信息和排版信息,以保证合并后的表格单元具有良好的可读性和结构性。同时,表格单元中可能存在多种文本类型和样式,因此需要综合利用多种特征进行跨行文本合并,以提高表格识别和理解的准确性和鲁棒性
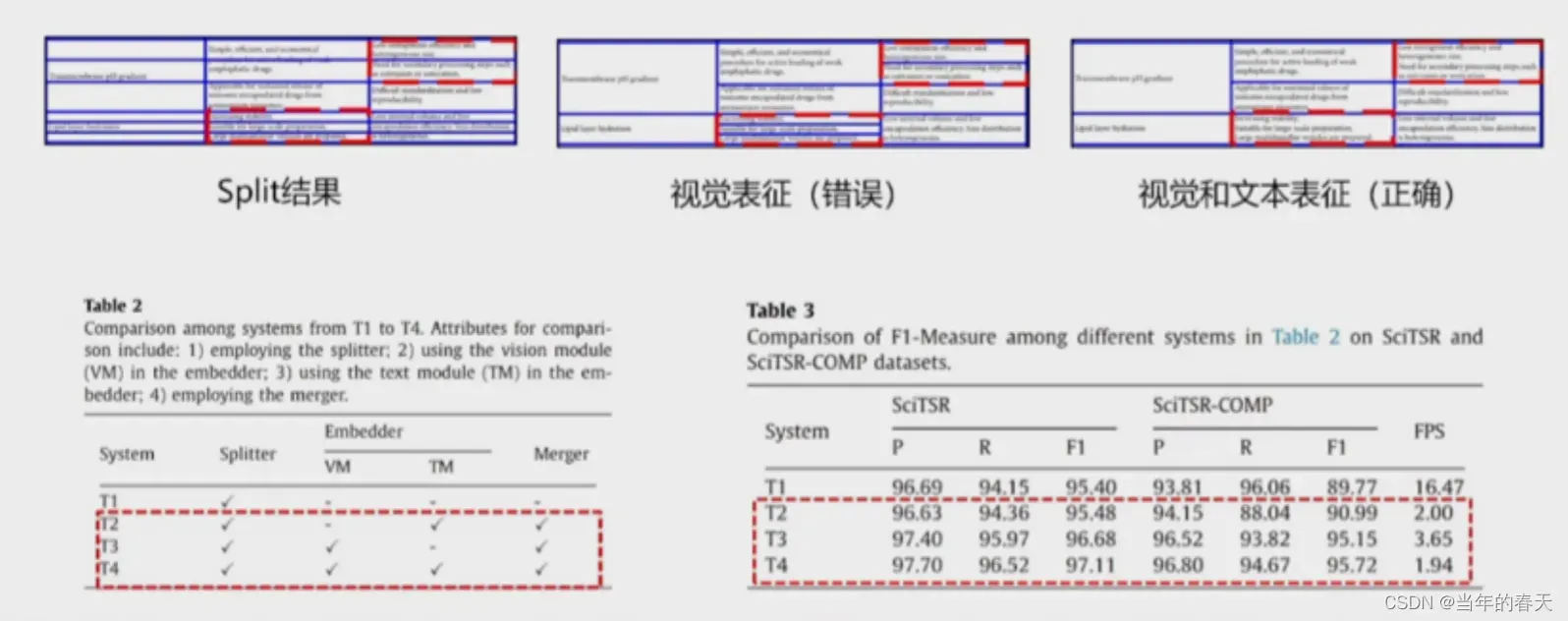
-
SOTA比对;在表格识别领域,目前的SOTA算法主要是基于深度学习的方法
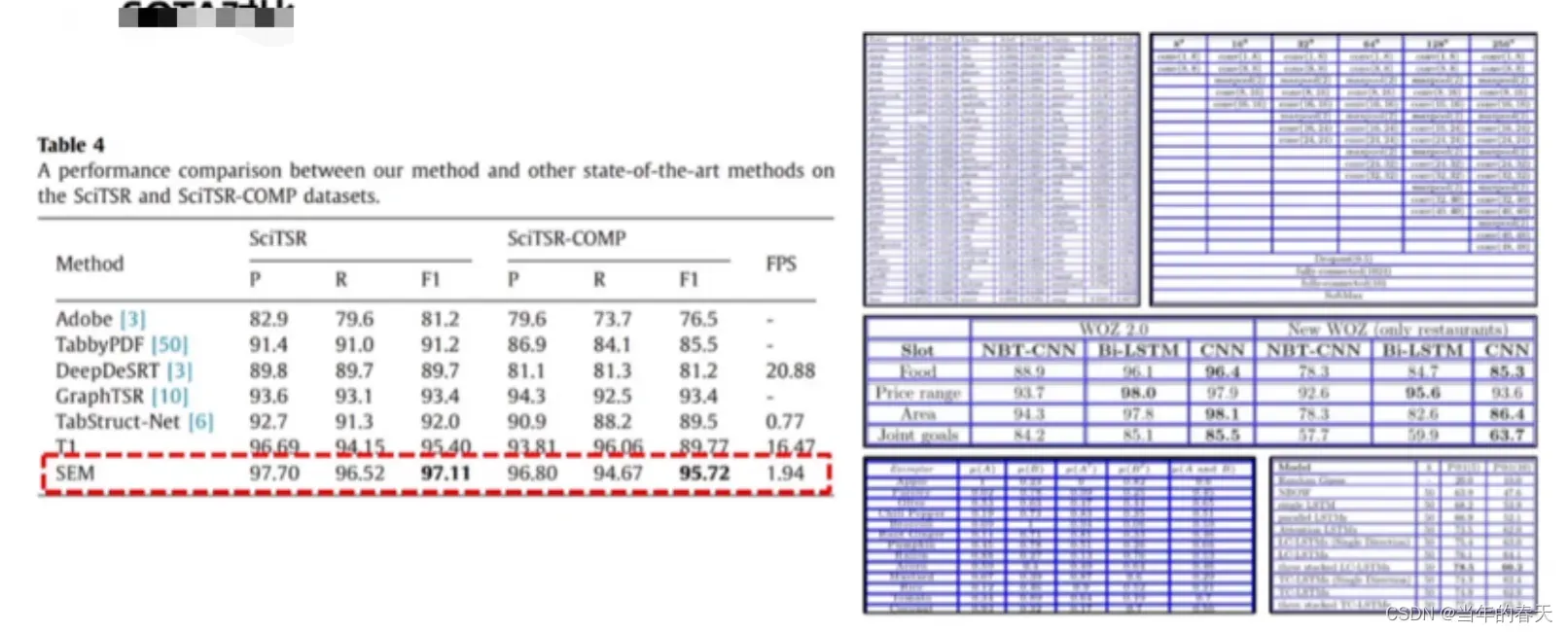
基于文档预训练模型
-
文档结构:文本行级别树状可视化是一种常用的文档结构表示方式,它可以将文本行级别的结构关系呈现为树状结构,方便用户进行文档理解和编辑
-
文档结构化任务是将文档中的非结构化或半结构化数据转化为结构化数据的过程,以方便后续的处理和分析
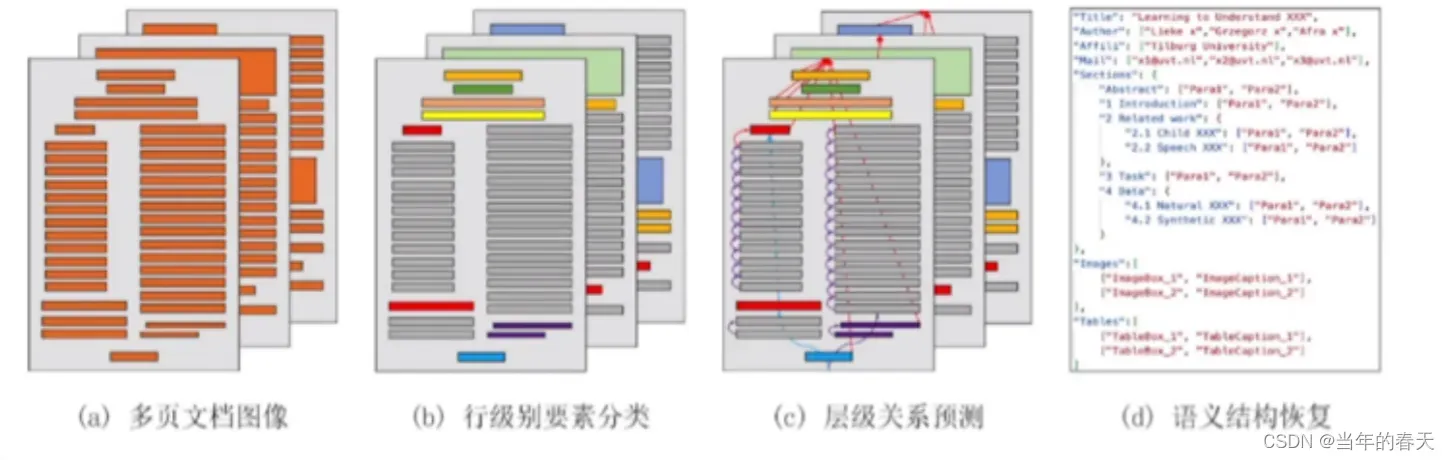
-
PDF解析系统+图表检测模型可以实现自动化地解析PDF文档中的图表,从而方便后续的数据分析和处理

-
模型设置:将整体任务拆解是一种常见的模型设置技巧,它可以将一个复杂的任务分解为多个简单的子任务,并针对每个子任务分别设计不同的模型或者模型组合,从而提高整体模型的性能和可解释性
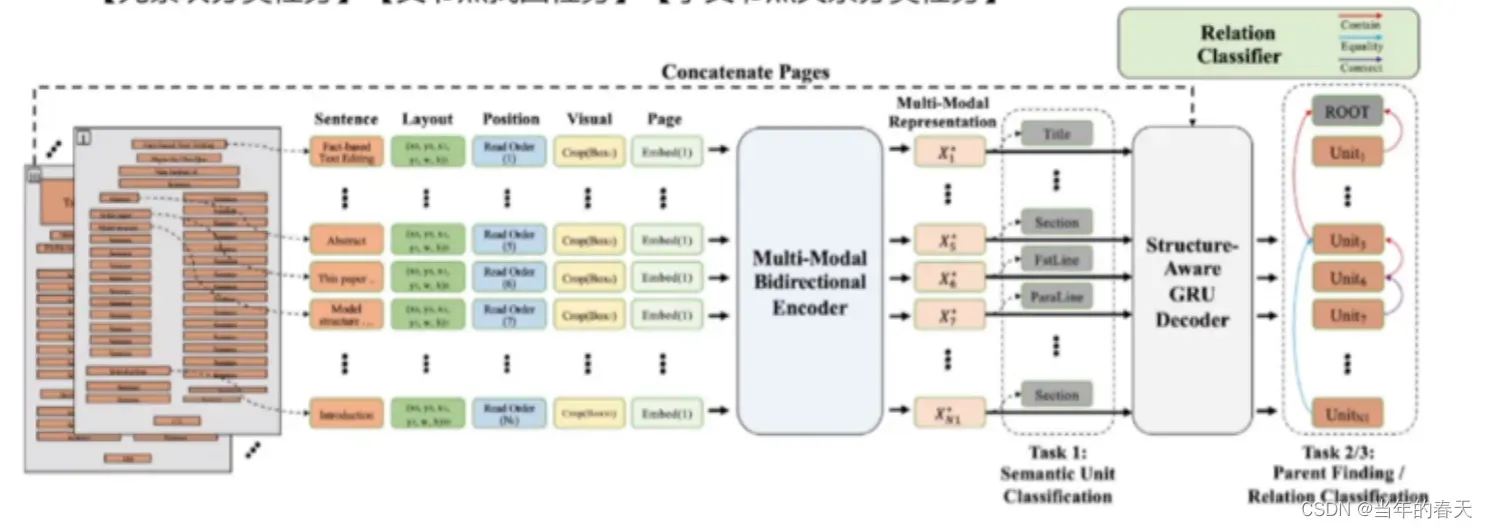
-
训练设置:联合学习是一种利用多个相关任务或多个数据源进行联合训练的方法。在训练过程中,模型同时考虑了多个任务或多个数据源的信息,从而可以提高模型的泛化能力和性能

-
结果
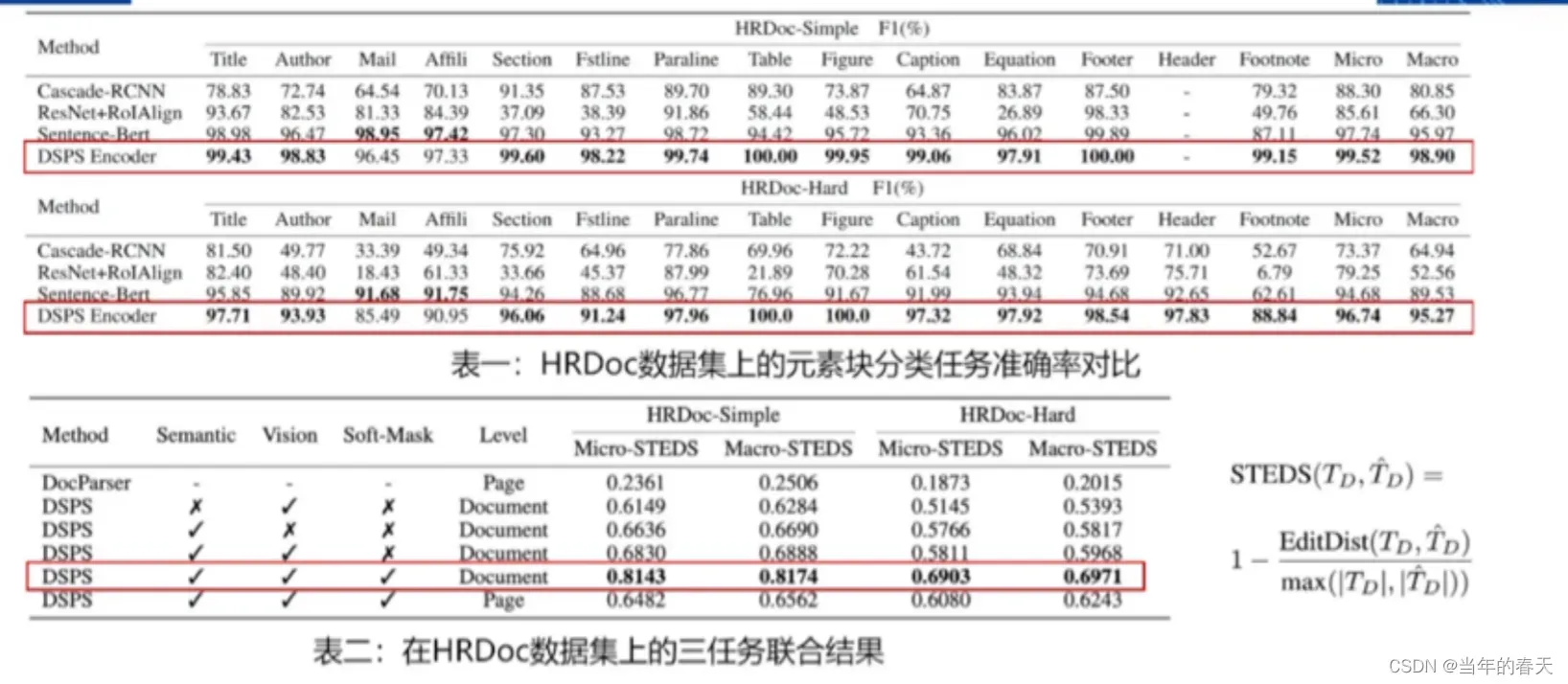
文档图像处理中底层视觉技术
下面文档图像处理技术是合合信息公司重点技术,合合信息图像算法研发总监郭丰俊博士针对目前底层视觉技术在处理形变、模糊、阴影遮盖、背景杂乱的文档时遇到的典型问题,就公司技术团队在智能图像处理技术模块、融合技术典型应用、图像安全领域等领域的研究成果进行了分享;合合信息在智能文字识别、图像处理、自然语言处理(NLP)、知识图谱、大数据挖掘等核心技术领域深耕十余年,拥有百余项自主知识产权的发明专利
智能文档扫描
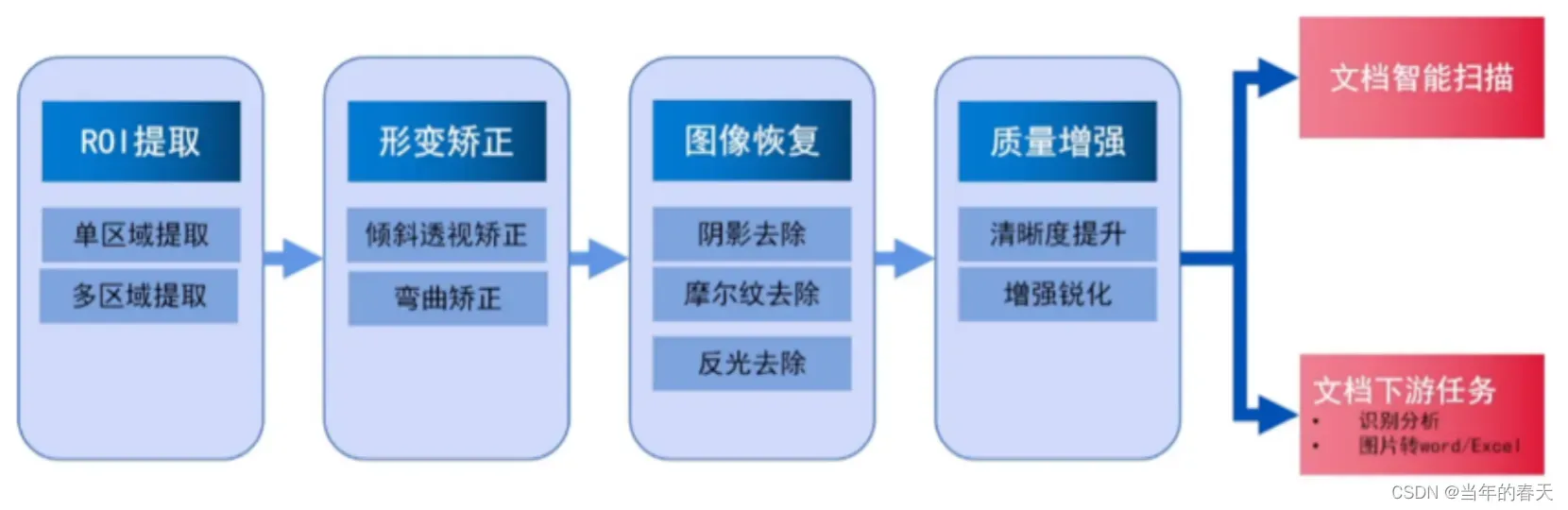
ROI提取
-
票据ROI提取

-
多名片ROI提取
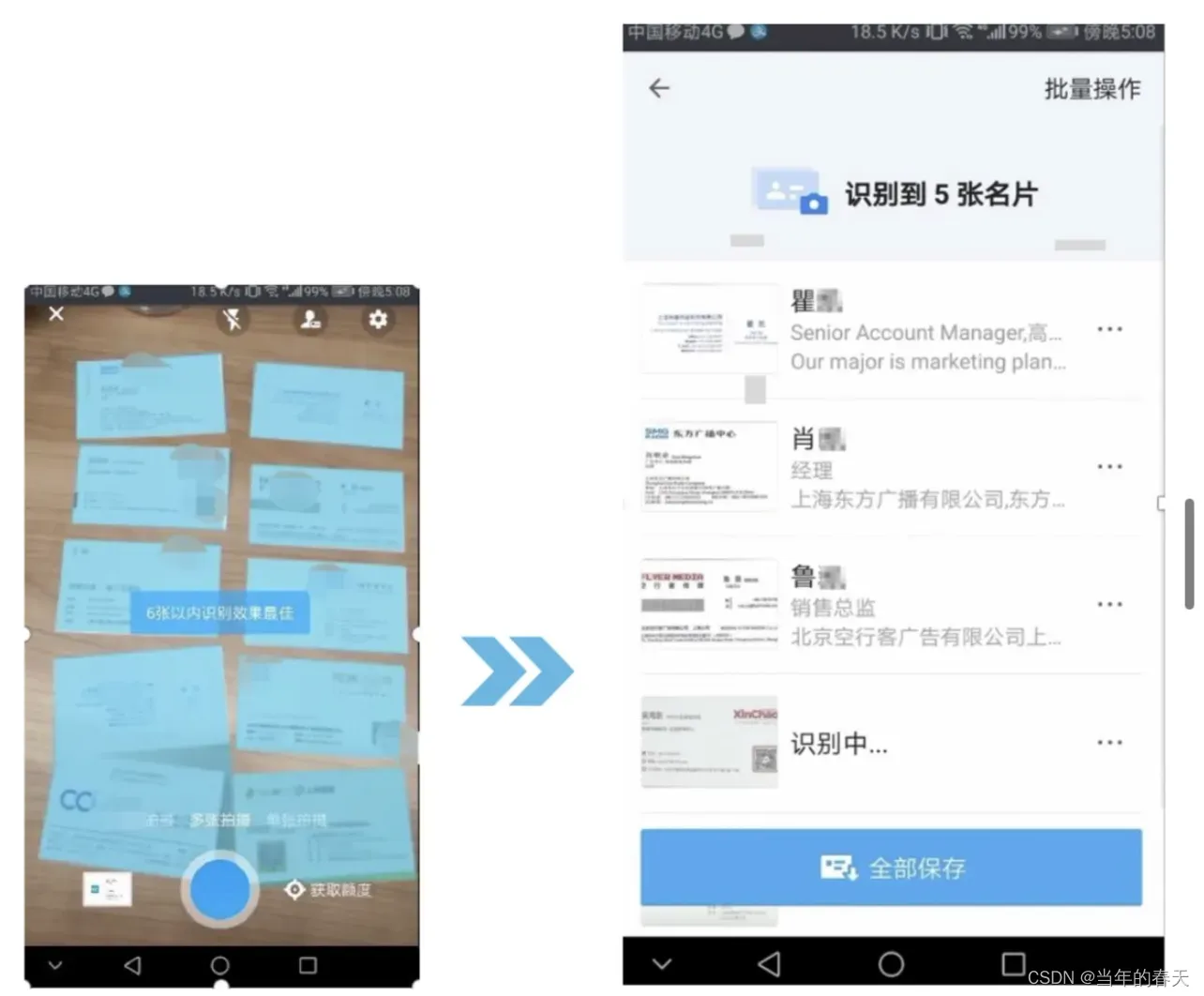
形变矫正
-
形变矫正(deformation correction)是图像识别中的一个重要预处理步骤,目的是对输入图像进行矫正,使得其形状、大小、方向等与模板图像一致,从而提高后续识别模型的准确性和稳定性
-
文档还原
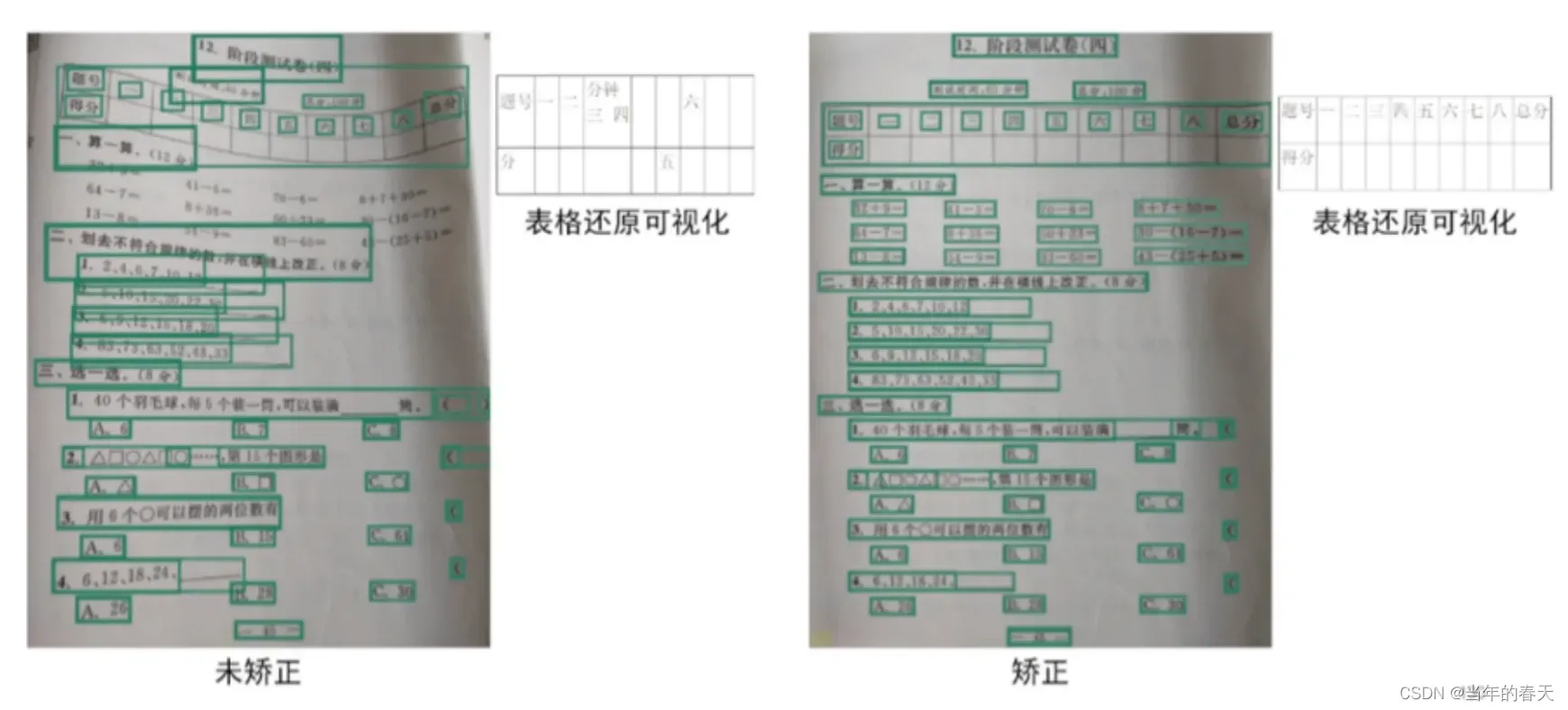
-
矫正网络,基于矫正网络的矫正方法则是通过训练一个矫正网络来实现形变矫正。这类方法通常使用卷积神经网络(CNN)或循环神经网络(RNN)等深度学习模型,将输入图像映射到与模板图像相似的形状。这种方法不需要进行特征点匹配,因此具有较高的计算效率和稳定性,但需要大量的训练数据和模型调优,且准确度受到模型设计和训练数据的影响
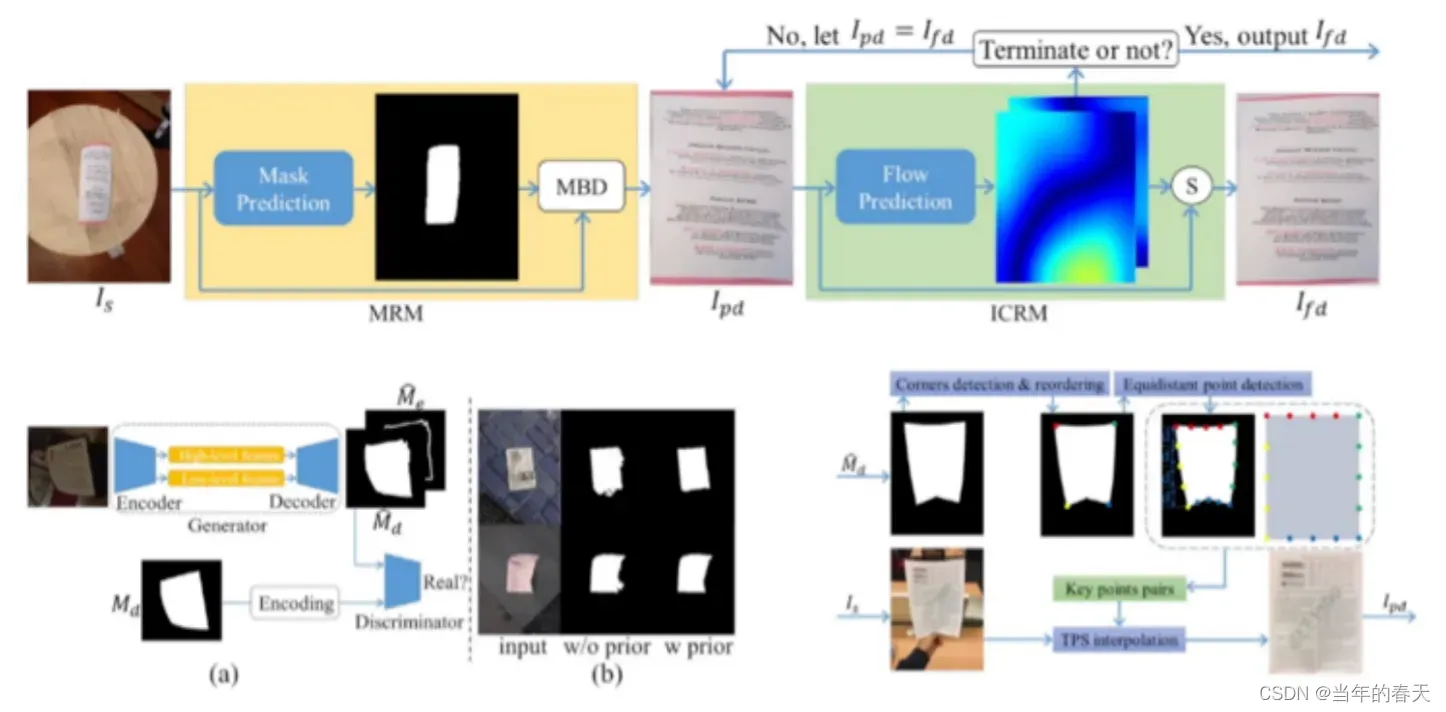
-
结果评价
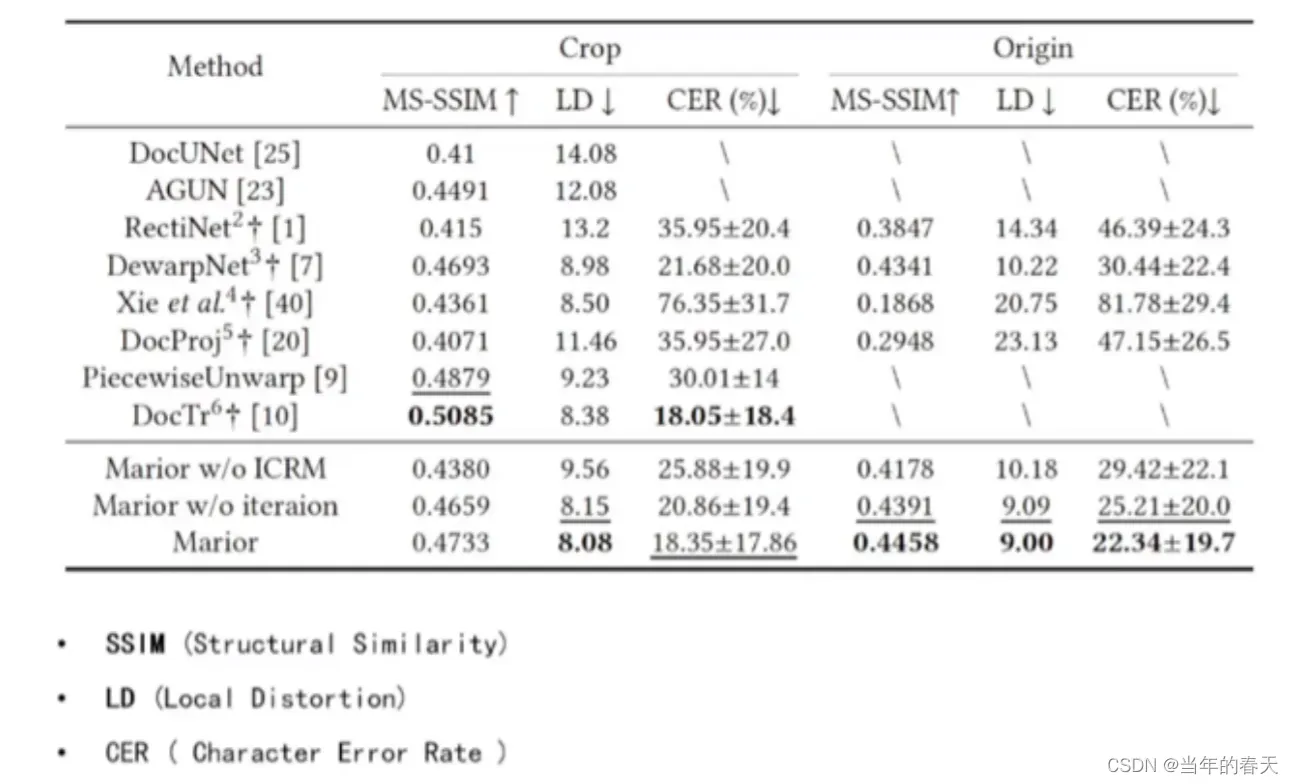
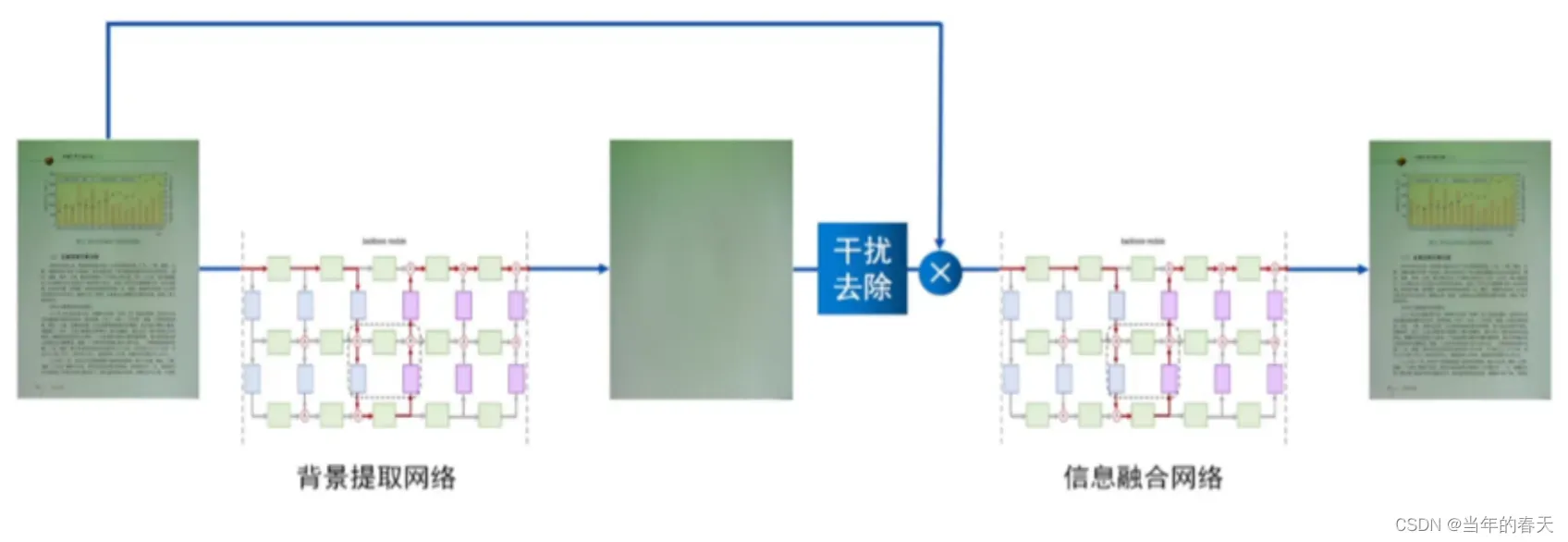
图像恢复-阴影去除
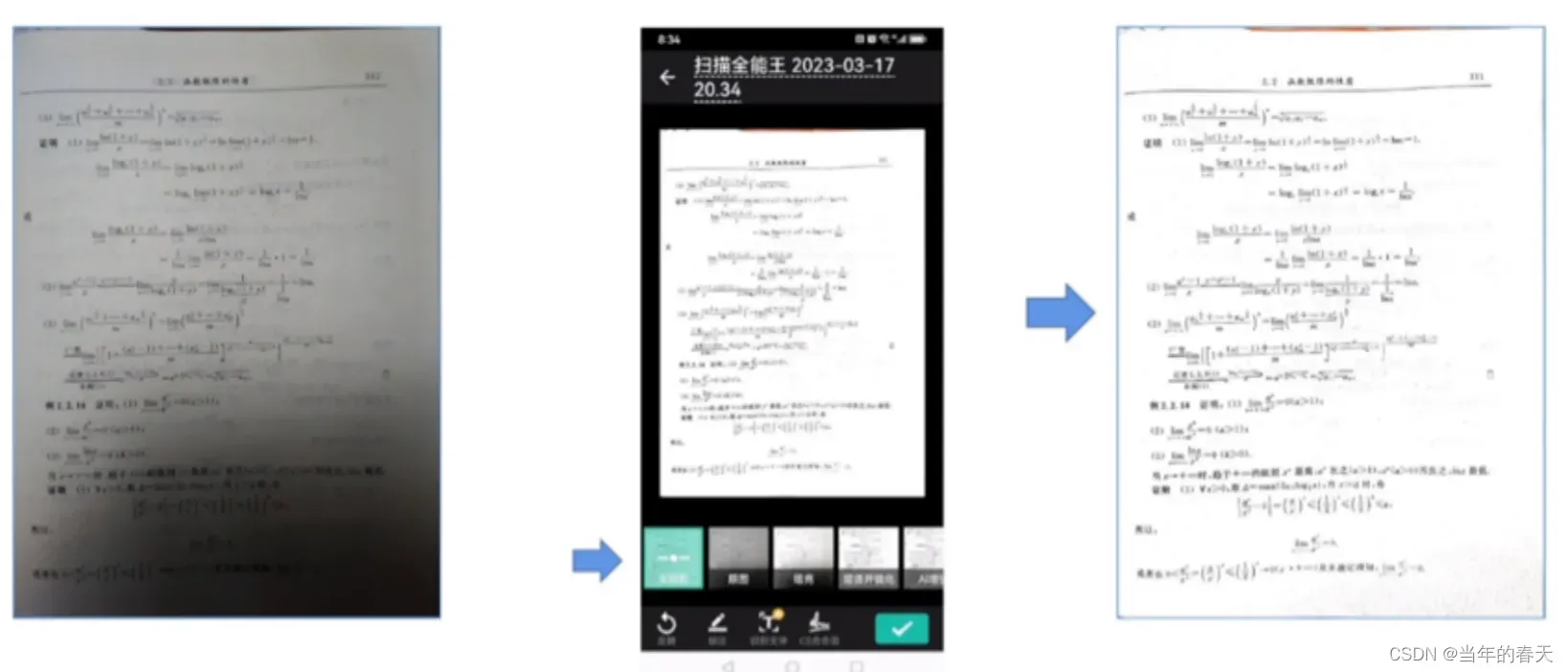
质量增强
-
智能高清使用超分辨率和其他技术来增加图像的分辨率和清晰度,通常通过机器学习算法实现

-
去除摩尔纹框架,摩尔纹是数字图像中常见的一种干扰,可以采用图像处理方法去除。其中,去除摩尔纹的方法之一是去除摩尔纹框架,通过将图像进行小波变换、去除低频分量以及调整高频分量来实现。
-
摩尔纹去除效果


-
手写擦除架构是一种用于手写字符识别中的方法,通过在神经网络中引入可学习的擦除操作,可以减轻数据噪声对识别性能的影响
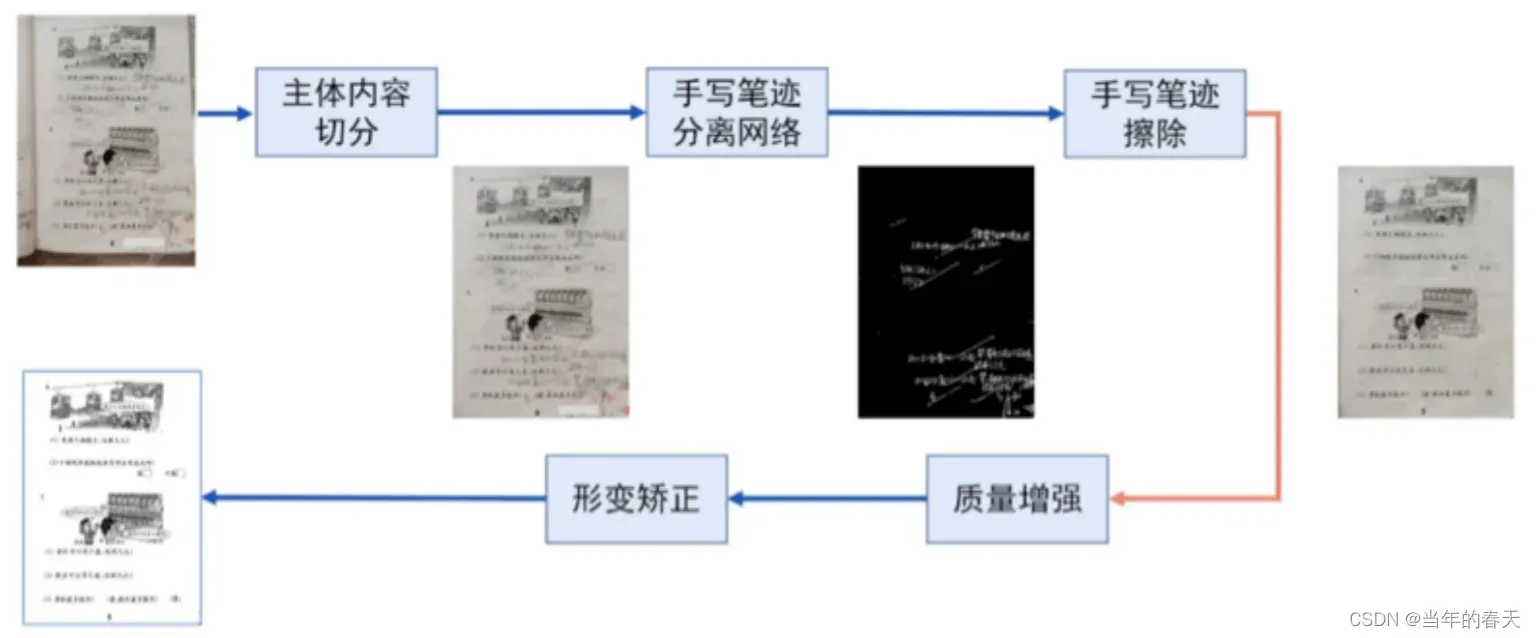
-
手写擦除效果

图像篡改检测
PS篡改检测

传统基于Exif检测PS
- 是一种通过检查图像的Exif信息来判断其是否使用Photoshop等工具进行过编辑的方法
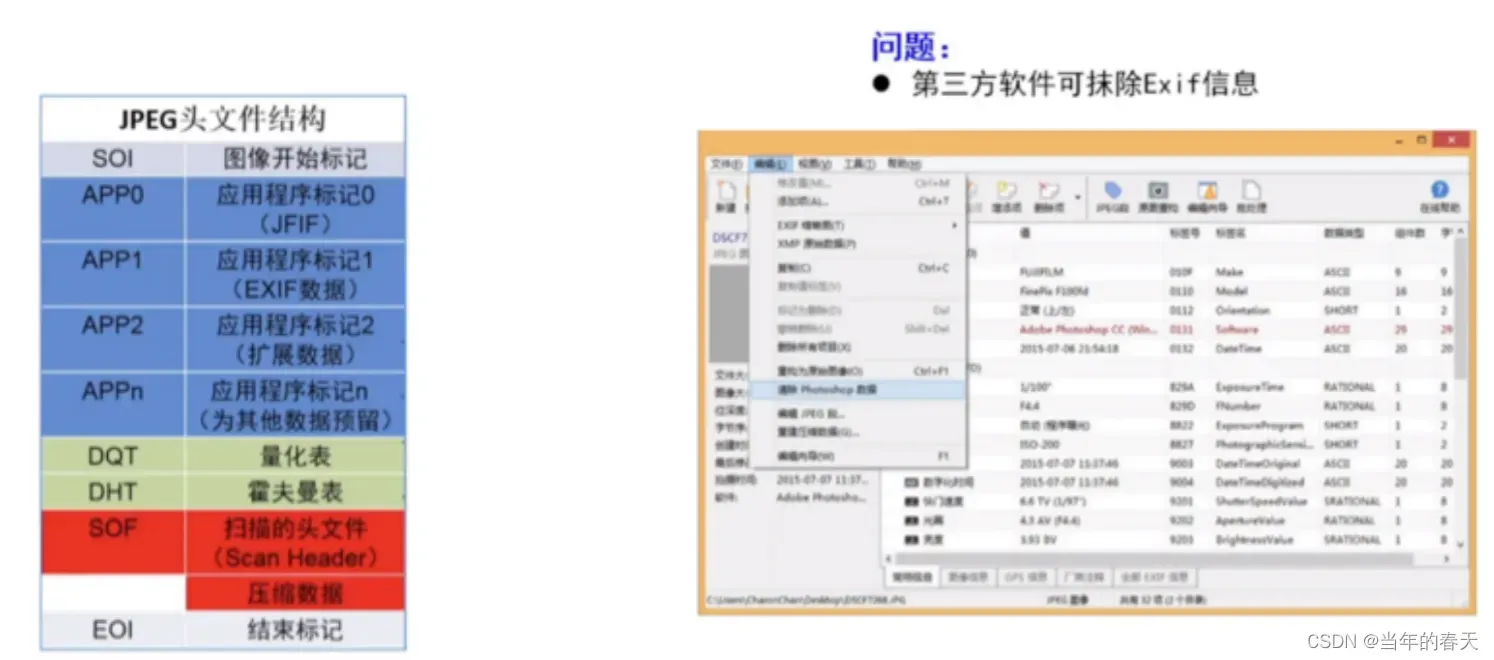
网络结构
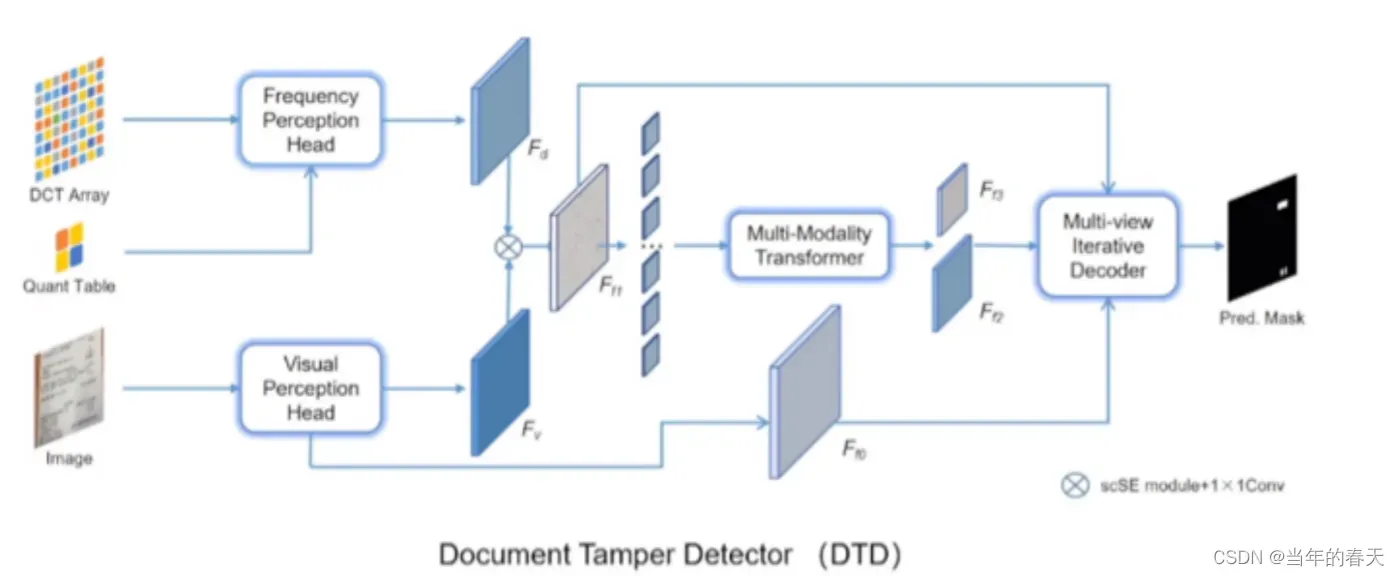
PS-篡改检测体验
更多功能体验地址

总结
- 生成式人工智能是一种基于深度学习的AI技术,其通过学习海量数据中的规律和模式,能够生成新的数据、图像、语言等内容。这种技术在各个行业的应用都能够带来巨大的商业价值
- 作为一个普通人我们应该如何把握住这次技术变革的浪潮呢?可以从以下四点入手:
- 关注相关新闻和发展动态:保持关注人工智能领域的相关新闻和发展动态,了解最新的技术进展和应用场景,这有助于更好地把握人工智能的发展趋势和未来的应用方向。
- 学习相关知识和技能:学习相关的知识和技能,如机器学习、深度学习、编程等,这有助于了解人工智能的基本原理和实现方式,为未来的发展做好准备。
- 参与相关社区和活动:加入相关的人工智能社区和参加相关的活动,与其他爱好者和专业人士交流,分享自己的经验和观点,扩大自己的视野和网络,了解更多的信息和机会。
- 创新和实践:尝试利用现有的技术和工具创新和实践,如尝试使用生成式人工智能技术生成一些有趣的图像、音乐或文字,这有助于提高自己的技能水平和创造力,同时也为自己未来的发展积累经验。
- 把握生成式人工智能浪潮需要不断学习、实践和创新,同时也需要保持开放的心态和积极的态度,与时俱进地掌握人工智能的最新进展和应用场景,为自己的未来发展打下坚实的基础。
文章出处登录后可见!