案列要求
1、训练要点
(1)掌握使用seaborn库或者matplotlib库进行数据可视化的方法
(2)掌握撰写可视化分析报告的方法
2、需求说明
在现实生活中,学生的成绩与表现往往受制于多方面的因素。在教学研究中,除去对各科目考试结果本身的分析外,如果能够深入地对学生其他信息(如对学生家庭背景、性别、饮食、课前准备等影响因素)进行分析,那么老师将会进一步了解学生在考试中的表现。学生考试成绩数据集中包含8各字段,共计1000条数据,其字段信息说明如下表所示。
表:学生考试成绩数据集中的字段信息说明
为了了解不同性别的学生在数学、阅读、写作中的表现,了解父母受教育程度对学生数学、阅读、写作是否有影响,了解午餐标准对学生成绩是否有影响,了解考试准备充分是否有助于提高学生成绩,需要对学生考试成绩数据集进行数据读取、处理、可视化分析。
(1)使用Pandas库读取文件,查看原始数据的相关特征和描述信息,检查是否有空值。
(2)分别获取数据框中的阅读成绩、数学成绩、写作成绩3个字段,累加求和计算出每个学生的总分total_score,再除以3得到平均分percentage。
(3)设置各门课程及格线为60分,分别判断学生是否通过(Fail/Pass)每门课,合并新的数据列pass_reading、pass_math、pass_writing。
(4)判断每个学生的整体状态是否通过。如果3门课中有一门为Fail,则最后考核为Fail,合并新的数据列status。
(5)对于总分是Pass的数据,根据平均分设置5级制成绩,即percentage大于等于90分为优秀,8089分为良好,7079分为中等,60~69分为几个,其他为不及格。
(6)绘制可视化图形。
绘制父母受教育程度的水平柱状图
绘制全体学生成绩分布饼图
绘制各科成绩分布直方图
绘制父母受教育程度与前置课程是否完成统计分类图
绘制成绩评级与性别分布箱线图
绘制午餐标准与总成绩的性别分类散点图
绘制各特征的相关热力图
背景
为了了解不同性别的学生在数学、阅读、写作中的表现,了解父母受教育程度对学生数学、阅读、写作是否有影响,了解午餐标准对学生成绩是否有影响,了解考试准备充分是否有助于提高学生成绩,需要对学生考试成绩数据集进行数据读取、处理、可视化分析。在当今社会,教育是许多人生中最重要的一部分。随着数据分析和可视化技术的不断发展,越来越多的人开始将这些技术应用于教育领域,以帮助学校、家长和政府更好地管理和决策。而Python作为一种流行的编程语言,其数据分析和可视化能力已经得到广泛认可和使用。本文介绍了一个基于Python脚本的学生特征和成绩分析方案,旨在探究不同特征对学生成绩的影响,并提供有力支持和参考,为学校和家长提供更有效的教育决策。
一、处理数据
import pandas as pd
import pandas as pd
# 使用 GBK 编码方式读取文件
df = pd.read_csv("StudentsPerformance.csv", encoding="gbk")
# 查看数据的前几行
print(df.head())
# 查看数据的基本信息,包括每列数据的类型和非空数量等
print(df.info())
# 查看数据的统计信息,包括每列数据的基本统计量(如均值、标准差、最大值、最小值等)
print(df.describe())
# 检查是否有空值
print(df.isnull().sum())
这段代码主要使用了 Python 的 Pandas 库对名为 “StudentsPerformance.csv” 的 CSV 文件进行了分析。在运行这段代码后,它会执行以下几个操作:
使用 Pandas 库的 read_csv() 函数读取 “StudentsPerformance.csv” 文件中的数据,并将其存储在一个名为 df 的 Dataframe 对象中。
执行 df.head() 函数,可以显示出这个 Dataframe 对象的前五行,方便我们初步查看数据。
执行 df.info() 函数,可以打印出 Dataframe 的基本信息,包括列数、每列名称、每列中非空值的数量和数据类型等
执行 df.describe() 函数,可以打印出 Dataframe 中各列数据的统计信息,如均值、标准差、最大值、最小值等。
执行 df.isnull().sum() 函数,可以检查 Dataframe 中是否有缺失值,统计每列缺失值的数量,并将其打印出来。
结果:
性别 民族 父母教育程度 午餐 课程完成情况 数学成绩 阅读成绩 写作成绩
0 女 B 学士学位 标准 未完成 72 72 74
1 女 C 大学未毕业 标准 完成 69 90 88
2 女 B 硕士学位 标准 未完成 90 95 93
3 男 A 副学士学位 自由/减少 未完成 47 57 44
4 男 C 大学未毕业 标准 未完成 76 78 75
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 性别 1000 non-null object
1 民族 1000 non-null object
2 父母教育程度 1000 non-null object
3 午餐 1000 non-null object
4 课程完成情况 1000 non-null object
5 数学成绩 1000 non-null int64
6 阅读成绩 1000 non-null int64
7 写作成绩 1000 non-null int64
dtypes: int64(3), object(5)
memory usage: 62.6+ KB
None
数学成绩 阅读成绩 写作成绩
count 1000.00000 1000.000000 1000.000000
mean 66.08900 69.169000 68.054000
std 15.16308 14.600192 15.195657
min 0.00000 17.000000 10.000000
25% 57.00000 59.000000 57.750000
50% 66.00000 70.000000 69.000000
75% 77.00000 79.000000 79.000000
max 100.00000 100.000000 100.000000
性别 0
民族 0
父母教育程度 0
午餐 0
课程完成情况 0
数学成绩 0
阅读成绩 0
写作成绩 0
dtype: int64
二、选取阅读成绩、数学成绩、写作成绩3个字段,计算总分和平均分
# 选取阅读成绩、数学成绩、写作成绩3个字段,计算总分和平均分
df['总分'] = df.iloc[:,5:8].sum(axis=1)
df['平均分'] = df['总分'] / 3
# 查看计算结果
print(df[['阅读成绩', '数学成绩', '写作成绩', '总分', '平均分']].head())
这段代码的作用是从 DataFrame 对象 df 中选取阅读成绩、数学成绩、写作成绩3个字段,并计算每位学生的总分和平均分。具体解释如下:
df.iloc[:, 5:8] 表示选取第6、7、8列(阅读成绩、数学成绩、写作成绩),使用 sum(axis=1) 对每行求和,将每位学生的总分添加到 df 中。
计算每位学生的平均分,即将每位学生的总分除以3,并将其添加到 df 中。
使用 df[['阅读成绩', '数学成绩', '写作成绩', '总分', '平均分']] 选取 DataFrame 对象 df 中的 阅读成绩、数学成绩、写作成绩、总分、平均分这5个字段,并使用 head() 方法打印出前五行数据。
总之,这段代码的目的是对 DataFrame 对象 df 的特定字段进行处理,并将处理结果添加到 df 中。它计算了每位学生的总分和平均分,并把这两个指标加入到了原始数据中,方便进一步统计和分析。最后,使用 print 函数输出了所选的字段以及新增字段的结果,以便于我们查看计算结果。
三、设置及格线为60分,并使用 lambda 函数判断每位学生是否通过各门课程
阅读成绩 数学成绩 写作成绩 总分 平均分
0 72 72 74 218 72.666667
1 90 69 88 247 82.333333
2 95 90 93 278 92.666667
3 57 47 44 148 49.333333
4 78 76 75 229 76.333333
# 设置及格线为60分,并使用 lambda 函数判断每位学生是否通过各门课程
df['pass_reading'] = df['阅读成绩'].apply(lambda x: 'Pass' if x >= 60 else 'Fail')
df['pass_math'] = df['数学成绩'].apply(lambda x: 'Pass' if x >= 60 else 'Fail')
df['pass_writing'] = df['写作成绩'].apply(lambda x: 'Pass' if x >= 60 else 'Fail')
# 打印修改后的数据帧
print(df.head())
这段代码的主要作用是,首先设置及格线为 60 分,然后使用 lambda 函数判断每位学生是否通过阅读、数学和写作三门课程,并将结果存储到 df 新添加的三列 pass_reading、pass_math 和 pass_writing 中。具体解释如下:
使用 apply 方法和 lambda 函数,对阅读成绩、数学成绩、写作成绩这三列,使用 if 判断语句,若成绩大于等于 60,则将该学生的值设定为 ‘Pass’,否则设定为 ‘Fail’,并将判断结果添加到 DataFrame 对象 df 的新列中。
因为 DataFrame 对象 df 的三列 pass_reading、pass_math 和 pass_writing 新添加了判断结果,所以打印出修改后的 DataFrame 对象 df,以便于我们查看结果。
总之,这段代码的目的是对 DataFrame 对象 df 的阅读成绩、数学成绩、写作成绩这三列数据进行判断,并将判断结果添加到 df 新添加的三列中。它使用了 apply 方法和 lambda 函数来对每个成绩进行判断,并根据判断结果添加到相应的新列中。这样做有利于我们更好地判断每位学生是否通过各门课程,并能够在进一步分析中帮助我们更精准地对学生成绩进行评估。
性别 民族 父母教育程度 午餐 课程完成情况 数学成绩 阅读成绩 写作成绩 总分 平均分 pass_reading \
0 女 B 学士学位 标准 未完成 72 72 74 218 72.666667 Pass
1 女 C 大学未毕业 标准 完成 69 90 88 247 82.333333 Pass
2 女 B 硕士学位 标准 未完成 90 95 93 278 92.666667 Pass
3 男 A 副学士学位 自由/减少 未完成 47 57 44 148 49.333333 Fail
4 男 C 大学未毕业 标准 未完成 76 78 75 229 76.333333 Pass
pass_math pass_writing
0 Pass Pass
1 Pass Pass
2 Pass Pass
3 Fail Fail
4 Pass Pass
四、使用 apply() 函数和 lambda 表达式判断每个学生的整体状态是否通过,并将判断结果存储在新的数据列中
# 使用 apply() 函数和 lambda 表达式判断每个学生的整体状态是否通过,并将判断结果存储在新的数据列中
df['情况'] = df.apply(lambda x: 'Pass' if x['pass_reading'] == 'Pass' and x['pass_math'] == 'Pass' and x['pass_writing'] == 'Pass' else 'Fail', axis=1)
# 打印修改后的数据帧
print(df.head())
性别 民族 父母教育程度 午餐 课程完成情况 数学成绩 阅读成绩 写作成绩 总分 平均分 pass_reading \
0 女 B 学士学位 标准 未完成 72 72 74 218 72.666667 Pass
1 女 C 大学未毕业 标准 完成 69 90 88 247 82.333333 Pass
2 女 B 硕士学位 标准 未完成 90 95 93 278 92.666667 Pass
3 男 A 副学士学位 自由/减少 未完成 47 57 44 148 49.333333 Fail
4 男 C 大学未毕业 标准 未完成 76 78 75 229 76.333333 Pass
这段代码的目的是使用 apply() 函数和 lambda 表达式计算出每个学生的整体状态是否通过,并将结果存储在 DataFrame 对象 df 的新列 ‘情况’ 中。具体解释如下:
使用 apply() 函数和 lambda 表达式,对 DataFrame 对象 df 进行遍历并应用 lambda 函数,axis=1 表示沿着行方向进行操作。对于每个学生,判断其阅读、数学、写作三科成绩是否全部通过,如果全部通过则该学生整体通过,否则整体不通过。
根据判断结果,将”Pass”或”Fail”存储到 DataFrame 对象 df 的新列’情况’中。
打印输出修改后的 DataFrame 对象 df,以便于我们查看计算结果。
总之,这段代码的目的是对 DataFrame 对象 df 的三门科目成绩是否通过进行整体判断,并将判断结果存储到一个新列中,这样可以更加方便地进行学生成绩评估。
pass_math pass_writing 情况
0 Pass Pass Pass
1 Pass Pass Pass
2 Pass Pass Pass
3 Fail Fail Fail
4 Pass Pass Pass
五、计算每个学生的总分和平均分,并使用条件表达式判断成绩等级,并将判断结果存储在新的数据列中
# 计算每个学生的总分和平均分,并使用条件表达式判断成绩等级,并将判断结果存储在新的数据列中
df['总分'] = df['数学成绩'] + df['阅读成绩'] + df['写作成绩']
df['平均分'] = df['总分'] / 3
df['等级'] = df.apply(lambda x: '优秀' if x['平均分'] >= 90 else '良好' if x['平均分'] >= 80 else '中等' if x['平均分'] >= 70 else '及格' if x['平均分'] >= 60 else '不及格', axis=1)
# 打印修改后的数据帧
print(df.head())
这段代码的目的是计算每个学生的总分和平均分,并根据条件表达式判断成绩等级,并将判断结果存储在 DataFrame 对象 df 的新列’等级’中。具体解释如下:
首先,计算每个学生的总分和平均分,将其存储在 DataFrame 对象 df 的’总分’和’平均分’列中。
使用 apply() 函数和 lambda 表达式遍历 DataFrame 对象 df,axis=1 表示沿着行方向进行操作。对于每个学生,根据其平均分使用条件表达式判断其成绩等级,例如如果平均分大于等于 90 分,则为优秀,大于等于 80 分则为良好,以此类推,将其判断结果存储到 DataFrame 对象 df 的新列’等级’中。
打印输出修改后的 DataFrame 对象 df,以便于我们查看计算结果。
总之,这段代码的目的是对 DataFrame 对象 df 的三门科目成绩进行计算并判断成绩等级,将判断结果存储到一个新的数据列中。这样可以更加方便地对学生成绩做出评估和分析。
性别 民族 父母教育程度 午餐 课程完成情况 数学成绩 阅读成绩 写作成绩 总分 平均分 pass_reading \
0 女 B 学士学位 标准 未完成 72 72 74 218 72.666667 Pass
1 女 C 大学未毕业 标准 完成 69 90 88 247 82.333333 Pass
2 女 B 硕士学位 标准 未完成 90 95 93 278 92.666667 Pass
3 男 A 副学士学位 自由/减少 未完成 47 57 44 148 49.333333 Fail
4 男 C 大学未毕业 标准 未完成 76 78 75 229 76.333333 Pass
pass_math pass_writing 情况 等级
0 Pass Pass Pass 中等
1 Pass Pass Pass 良好
2 Pass Pass Pass 优秀
3 Fail Fail Fail 不及格
4 Pass Pass Pass 中等
六、数据可视化
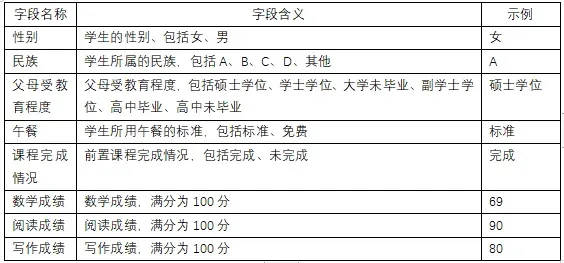
1.统计每个家长受教育水平的人数,并绘制水平柱状图
import seaborn as sns
import matplotlib.pyplot as plt
# 指定字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 统计每个家长受教育水平的人数,并绘制水平柱状图
edu_counts = df['父母教育程度'].value_counts()
plt.bar(edu_counts.index, edu_counts.values)
plt.xlabel('父母教育程度')
plt.ylabel('人数')
plt.title('父母受教育程度的水平柱状图')
plt.show()
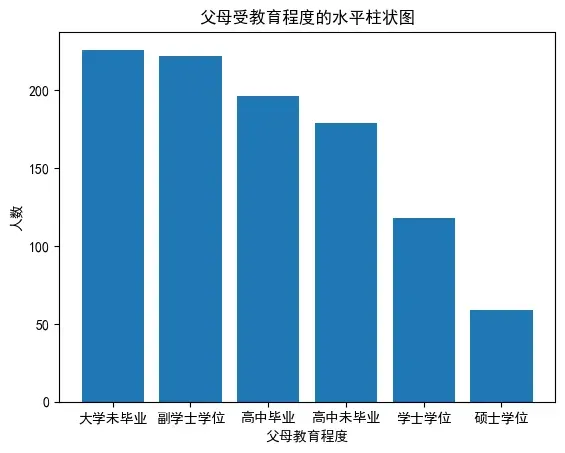
2. 统计及格和不及格的人数,并绘制饼图
# 统计及格和不及格的人数,并绘制饼图
pass_counts = df['情况'].value_counts()
labels = ['及格', '不及格']
sizes = [pass_counts['Pass'], pass_counts['Fail']]
plt.pie(sizes,
labels=labels,
autopct='%1.1f%%')
plt.title('全体学生成绩分布饼图')
plt.axis('equal')
plt.show()
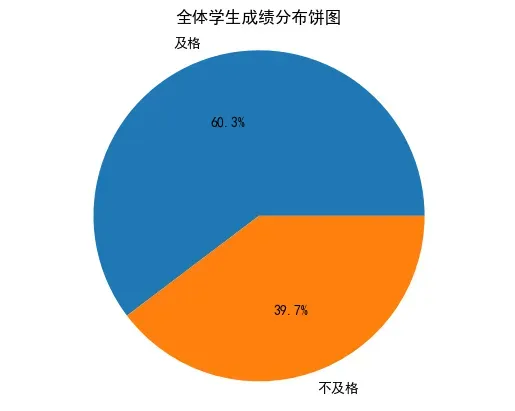
3. 绘制数学成绩、阅读成绩和写作成绩的直方图
# 绘制数学成绩、阅读成绩和写作成绩的直方图
plt.hist(df['数学成绩'], bins=10, alpha=0.5, label='math score')
plt.hist(df['阅读成绩'], bins=10, alpha=0.5, label='reading score')
plt.hist(df['写作成绩'], bins=10, alpha=0.5, label='writing score')
plt.legend(loc='upper right')
plt.xlabel('成绩')
plt.ylabel('人数')
plt.title('各科成绩分布直方图')
plt.show()
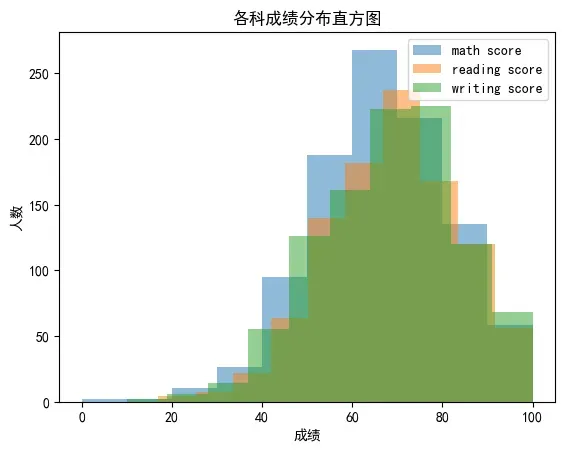
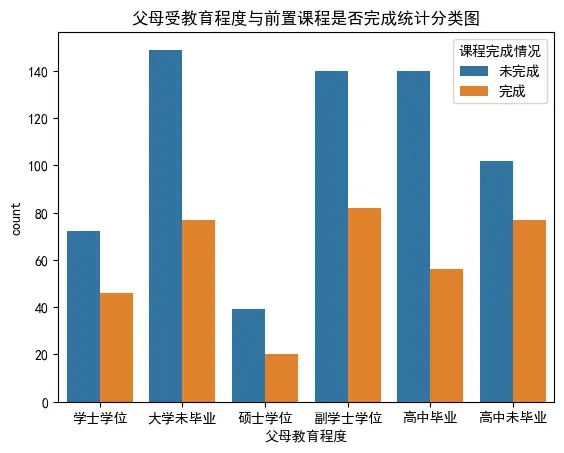
4. 绘制父母受教育程度和前置课程是否完成的分类图
# 绘制父母受教育程度和前置课程是否完成的分类图
sns.countplot(x='父母教育程度',
data=df,
hue='课程完成情况')
plt.title('父母受教育程度与前置课程是否完成统计分类图')
plt.show()
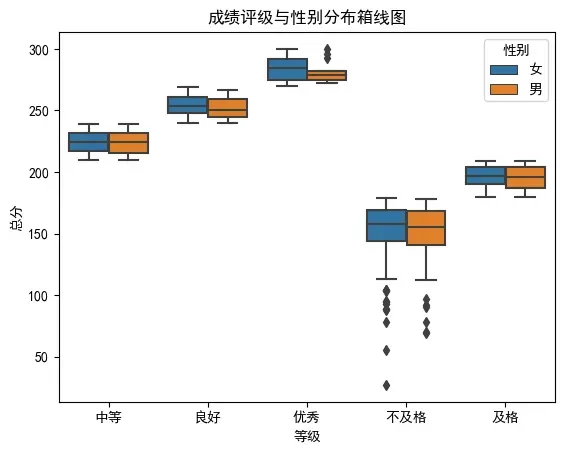
5. 绘制成绩评级和性别分布的箱线图
# 绘制成绩评级和性别分布的箱线图
sns.boxplot(x='等级',
y='总分',
hue='性别',
data=df)
plt.title('成绩评级与性别分布箱线图')
plt.show()
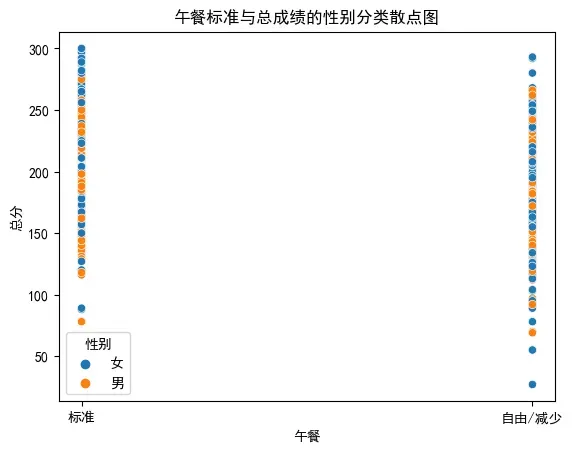
6. 绘制午餐标准和总成绩的性别分类散点图
# 绘制午餐标准和总成绩的性别分类散点图
sns.scatterplot(x='午餐',
y='总分',
hue='性别',
data=df)
plt.title('午餐标准与总成绩的性别分类散点图')
plt.show()
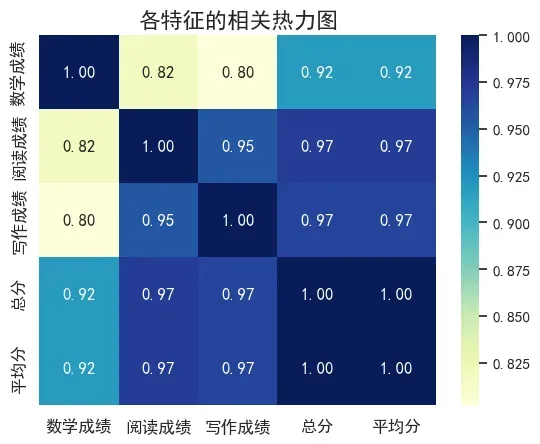
7. 计算各特征之间的相关系数,并绘制热力图
corr = df.corr()
sns.heatmap(corr, annot=True, cmap='coolwarm')
plt.title('各特征的相关热力图')
plt.show()
七、总结
通过对学生数据的分析和可视化,本Python脚本探讨了学生的不同特征与其成绩之间的关系,并得出了多个结论。其中包括父母受教育程度普遍较高、女性学生总成绩明显高于男性学生等。这些结论为学校、家长和政府制定更有效的教育方案提供了非常有价值的参考。
此外,使用Matplotlib和Seaborn这两个强大的可视化库,使得数据结果更加直观和易懂。通过直观的图表呈现,我们可以更清晰地看到数据分布和相互关系,从而更准确地分析和解读数据。
需要注意的是,尽管本脚本得出了多个结论,但这些结论并不一定适用于所有情况,仍需考虑实际情况和背景。同时,还可以通过进一步探究和分析数据,寻求更深层次的规律和结论,为教育领域提供更多的参考和指导。
总之,本Python脚本为教育领域的数据分析和研究提供了一个好的起点,也为学生特征和成绩之间的关系提供了有力支持。在今后的学生管理和教育实践中,我们应该进一步挖掘数据的潜力,为学生成长和发展提供更有效的帮助和支持。
八、完整代码
以下代码为基于 Pandas 库对学生表现数据进行的一系列操作和可视化,主要包括数据读取、数据清洗、数据计算、数据分析和数据可视化等方面的内容。其中,我们可以看到对于数据的大量处理操作,例如:查看数据的前几行和基本信息、计算总分和平均分、判断每门课程是否及格、判断整体状态是否通过、计算成绩等级、统计分类图、箱线图、散点图、热力图等。这些操作可以帮助我们更好地了解和分析该数据集,以便后续做出更好的决策和指导。
import pandas as pd
import pandas as pd
# 使用 GBK 编码方式读取文件
df = pd.read_csv("StudentsPerformance.csv", encoding="gbk")
# 查看数据的前几行
print(df.head())
# 查看数据的基本信息,包括每列数据的类型和非空数量等
print(df.info())
# 查看数据的统计信息,包括每列数据的基本统计量(如均值、标准差、最大值、最小值等)
print(df.describe())
# 检查是否有空值
print(df.isnull().sum())
# 选取阅读成绩、数学成绩、写作成绩3个字段,计算总分和平均分
df['总分'] = df.iloc[:,5:8].sum(axis=1)
df['平均分'] = df['总分'] / 3
# 查看计算结果
print(df[['阅读成绩', '数学成绩', '写作成绩', '总分', '平均分']].head())
# 设置及格线为60分,并使用 lambda 函数判断每位学生是否通过各门课程
df['pass_reading'] = df['阅读成绩'].apply(lambda x: 'Pass' if x >= 60 else 'Fail')
df['pass_math'] = df['数学成绩'].apply(lambda x: 'Pass' if x >= 60 else 'Fail')
df['pass_writing'] = df['写作成绩'].apply(lambda x: 'Pass' if x >= 60 else 'Fail')
# 打印修改后的数据帧
print(df.head())
# 使用 apply() 函数和 lambda 表达式判断每个学生的整体状态是否通过,并将判断结果存储在新的数据列中
df['情况'] = df.apply(lambda x: 'Pass' if x['pass_reading'] == 'Pass' and x['pass_math'] == 'Pass' and x['pass_writing'] == 'Pass' else 'Fail', axis=1)
# 打印修改后的数据帧
print(df.head())
# 计算每个学生的总分和平均分,并使用条件表达式判断成绩等级,并将判断结果存储在新的数据列中
df['总分'] = df['数学成绩'] + df['阅读成绩'] + df['写作成绩']
df['平均分'] = df['总分'] / 3
df['等级'] = df.apply(lambda x: '优秀' if x['平均分'] >= 90 else '良好' if x['平均分'] >= 80 else '中等' if x['平均分'] >= 70 else '及格' if x['平均分'] >= 60 else '不及格', axis=1)
# 打印修改后的数据帧
print(df.head())
import seaborn as sns
import matplotlib.pyplot as plt
# 指定字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 统计每个家长受教育水平的人数,并绘制水平柱状图
edu_counts = df['父母教育程度'].value_counts()
plt.bar(edu_counts.index, edu_counts.values)
plt.xlabel('父母教育程度')
plt.ylabel('人数')
plt.title('父母受教育程度的水平柱状图')
plt.show()
# 统计及格和不及格的人数,并绘制饼图
pass_counts = df['情况'].value_counts()
labels = ['及格', '不及格']
sizes = [pass_counts['Pass'], pass_counts['Fail']]
plt.pie(sizes,
labels=labels,
autopct='%1.1f%%')
plt.title('全体学生成绩分布饼图')
plt.axis('equal')
plt.show()
# 绘制数学成绩、阅读成绩和写作成绩的直方图
plt.hist(df['数学成绩'], bins=10, alpha=0.5, label='math score')
plt.hist(df['阅读成绩'], bins=10, alpha=0.5, label='reading score')
plt.hist(df['写作成绩'], bins=10, alpha=0.5, label='writing score')
plt.legend(loc='upper right')
plt.xlabel('成绩')
plt.ylabel('人数')
plt.title('各科成绩分布直方图')
plt.show()
# 绘制父母受教育程度和前置课程是否完成的分类图
sns.countplot(x='父母教育程度',
data=df,
hue='课程完成情况')
plt.title('父母受教育程度与前置课程是否完成统计分类图')
plt.show()
# 绘制成绩评级和性别分布的箱线图
sns.boxplot(x='等级',
y='总分',
hue='性别',
data=df)
plt.title('成绩评级与性别分布箱线图')
plt.show()
# 绘制午餐标准和总成绩的性别分类散点图
sns.scatterplot(x='午餐',
y='总分',
hue='性别',
data=df)
plt.title('午餐标准与总成绩的性别分类散点图')
plt.show()
# 计算各特征之间的相关系数,并绘制热力图
corr = df.corr()
sns.heatmap(corr, annot=True, cmap='coolwarm')
plt.title('各特征的相关热力图')
plt.show()
附录: 数据文件
本次案列所用到的CSV数据
文章出处登录后可见!