1,数据加载
PyTorch开发了与数据交互的标准约定,所以能一致地处理数据,而不论处理图像、文本还是音频。与数据交互的两个主要约定是数据集(dataset)和数据加载器(dataloader)。数据集是一个Python类,使我们能获得提供给神经网络的数据。数据加载器则从数据集向网络提供数据。
PyTorch通过torch.utils.data对一般常用的数据加载进行了封装,可以很容易地实现多线程数据预读和批量加载。并且torchvision已经预先实现了常用图像数据集,包括前面使用过的CIFAR-10,ImageNet、COCO、MNIST、LSUN等数据集,可通过torchvision.datasets方便的调用。
1.1,Dataset
Dataset是一个抽象类,为了能够方便的读取,需要将要使用的数据包装为Dataset类。 自定义的Dataset需要继承它并且实现两个成员方法:
- __getitem__()该方法定义用索引(0到len(self))获取一条数据或一个样本。
- __len__()该方法返回数据集的总长度。
from torch.utils.data import Datasetimport pandas as pd# 定义一个数据集class BulldozerDataset(Dataset): """ 数据集演示 """ def __init__(self, csv_file): """实现初始化方法,在初始化的时候将数据读载入""" self.df = pd.read_csv(csv_file) def __len__(self): ''' 返回df的长度 ''' return len(self.df) def __getitem__(self, idx): ''' 根据 idx 返回一行数据 ''' return self.df.iloc[idx].Titleif __name__ == '__main__': ds_demo = BulldozerDataset('Highest Holywood Grossing Movies.csv') print(len(ds_demo)) print(ds_demo[0])=================================================918Star Wars: Episode VII - The Force Awakens (2015)<
1.2,Dataloader
DataLoader为我们提供了对Dataset的读取操作,常用参数有:
- dataset(Dataset):传入的数据集。
- batch_size:每个batch的大小。
- shuffle:在每个epoch开始的时候,对数据进行重新排序。
- num_workers:加载数据的时候使用几个子进程,windows 下线程参数设为 0 安全。
dl = torch.utils.data.DataLoader(ds_demo, batch_size=10, shuffle=True, num_workers=0)<DataLoader返回的是一个可迭代对象,我们可以使用迭代器分次获取数据:
idata=iter(dl)print(next(idata))====================['Cars 3 (2017)', 'Dick Tracy (1990)', 'Click (2006)', 'Star Trek: The Motion Picture (1979)', 'Apocalypse Now (1979)', 'The Devil Wears Prada (2006)', 'The Divergent Series: Insurgent (2015)', 'As Good as It Gets (1997)', 'Safe House (2012)', 'Puss in Boots (2011)']<常见的用法是使用for循环对其进行遍历:
ds_demo = BulldozerDataset('Highest Holywood Grossing Movies.csv') dl = torch.utils.data.DataLoader(ds_demo, batch_size=10, shuffle=True, num_workers=0) for i, data in enumerate(dl): print(i, data)===================================0 ['Catch Me If You Can (2002)', 'Cast Away (2000)', "Miss Peregrine's Home for Peculiar Children (2016)", 'Django Unchained (2012)', 'xXx (2002)', 'Iron Man 2 (2010)', 'The Meg (2018)', 'Despicable Me 2 (2013)', 'Peter Rabbit (2018)', 'Bridesmaids (2011)']...<
1.3,torchvision
torchvision 是PyTorch中专门用来处理图像的库,torchvision.datasets 可以理解为PyTorch团队自定义的dataset,这些dataset帮我们提前处理好了很多的图片数据集,我们拿来就可以直接使用: – MNIST – COCO – Captions – Detection – LSUN – ImageFolder – Imagenet-12 – CIFAR – STL10 – SVHN – PhotoTour 我们可以直接使用。
torchvision的安装:pip install torchvision。
import torchvision.datasets as datasetstrainset = datasets.CIFAR10(root='./data', # 表示 MNIST 数据的加载的目录 train=True, # 表示是否加载数据库的训练集,false的时候加载测试集 download=True, # 表示是否自动下载 MNIST 数据集 transform=None) # 表示是否需要对数据进行预处理,none为不进行预处理<
torchvision.models:torchvision不仅提供了常用图片数据集,还提供了训练好的模型,可以加载之后,直接使用,或者在进行迁移学习 torchvision.models模块的 子模块中包含以下模型结构。 – AlexNet – VGG – ResNet – SqueezeNet – DenseNet。
#我们直接可以使用训练好的模型,当然这个与datasets相同,都是需要从服务器下载的import torchvision.models as modelsresnet18 = models.resnet18(pretrained=True)#True:加载模型,并设为预训练模式<
torchvision.transforms:transforms 模块提供了一般的图像转换操作类,用作数据处理和数据增强。
rom torchvision import transforms as transformstransform = transforms.Compose([ transforms.RandomCrop(32, padding=4), #先四周填充0,在把图像随机裁剪成32*32 transforms.RandomHorizontalFlip(), #图像一半的概率翻转,一半的概率不翻转 transforms.RandomRotation((-45,45)), #随机旋转 transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.229, 0.224, 0.225)), #R,G,B每层的归一化用到的均值和方差])<(0.485, 0.456, 0.406), (0.2023, 0.1994, 0.2010) :根据ImageNet训练的归一化参数,可以直接使用,认为这个是固定值就可以,也可以使用其他的值。
2,数学原理
2.1,损失函数
损失函数(loss function)是用来估量模型的预测值(我们例子中的output)与真实值(例子中的y_train)的不一致程度,它是一个非负实值函数,损失函数越小,模型的鲁棒性就越好。 我们训练模型的过程,就是通过不断的迭代计算,使用梯度下降的优化算法,使得损失函数越来越小。损失函数越小就表示算法达到意义上的最优。
机器学习:概念_燕双嘤-CSDN博客1,机器学习概述1.1,机器学习概念机器学习即Machine Learning,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。目的是让计算机模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断完善自身的性能。简单来讲,机器学习就是人们通过提供大量的相关数据来训练机器。DataAnalysis:基本概念,环境介绍,环境搭建,大数据问题_燕双嘤-CSDN博客1,概述1.1,数据的性质所谓数据就是描述事物的符号,是对客观事物的性质、状态和相互关系等进行记载的
https://shao12138.blog.csdn.net/article/details/120507206#t8因为PyTorch是使用mini-batch来进行计算的,所以损失函数的计算出来的结果已经对mini-batch取了平均。
- nn.L1Loss(和方误差):输入x和目标y之间差的绝对值,要求 x 和 y 的维度要一样(可以是向量或者矩阵),得到的 loss 维度也是对应一样的。
- nn.NLLLoss:用于多分类的负对数似然损失函数。
- nn.CrossEntropyLoss:多分类用的交叉熵损失函数。
- nn.BCELoss:计算 x 与 y 之间的二进制交叉熵。
2.2,梯度下降
机器学习:梯度下降_燕双嘤-CSDN博客_机器学习梯度下降
https://shao12138.blog.csdn.net/article/details/121306952
在微积分中,对多元函数的参数计算
偏导数,得到的每个参数的偏导数写成向量的形式,就是梯度。例如函数
对
取偏导,得到的梯度向量为
,简写为
或
。
从几何上讲,梯度是函数变化增加最快的地方。沿着梯度向量的方向,更容易找到函数的最大值。相反,梯度沿着梯度向量的相反方向下降最快,这意味着更容易找到函数的最小值。
我们需要最小化损失函数,可以通过梯度下降法逐步迭代求解,得到最小化的损失函数和模型参数值。
梯度下降法的直观解释:梯度下降法就像下山。我们不知道下山的路,所以我们决定一步一步走。每到一个位置,求解当前位置的梯度,沿着梯度的负方向,也就是从当前最陡的位置往下走一步,然后继续求解当前位置的梯度,而沿着最陡和最容易的下坡位置迈出一步到这一步的位置。就这样一步一步地往前走,直到我们觉得已经到了山脚下。
再这样下去,有可能到不了山脚下,而是到了某个局部山的下部(局部最优解)。
这个问题在以前的机器学习中可能会遇到,因为机器学习中的特征比较少,所以导致很可能陷入到一个局部最优解中出不来,但是到了深度学习,动辄百万甚至上亿的特征,出现这种情况的概率几乎为0,所以我们可以不用考虑这个问题。
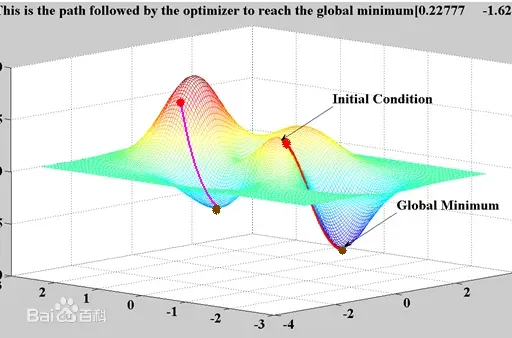
2.3,Mini-batch的梯度下降法
对整个训练集进行梯度下降法的时候,必须处理整个训练数据集,然后才能进行一步梯度下降,即每一步梯度下降法需要对整个训练集进行一次处理,如果训练数据集很大的时候处理速度会很慢,而且也不可能一次的载入到内存或者显存中,所以我们会把大数据集分成小数据集,一部分一部分的训练,这个训练子集即称为Mini-batch。
在PyTorch中就是使用这种方法进行的训练,可以看看关于dataloader的介绍里面的batch_size就是我们一个Mini-batch的大小。
对于普通的梯度下降法,一个epoch只能进行一次梯度下降;而对于Mini-batch梯度下降法,一个epoch可以进行Mini-batch的个数次梯度下降。
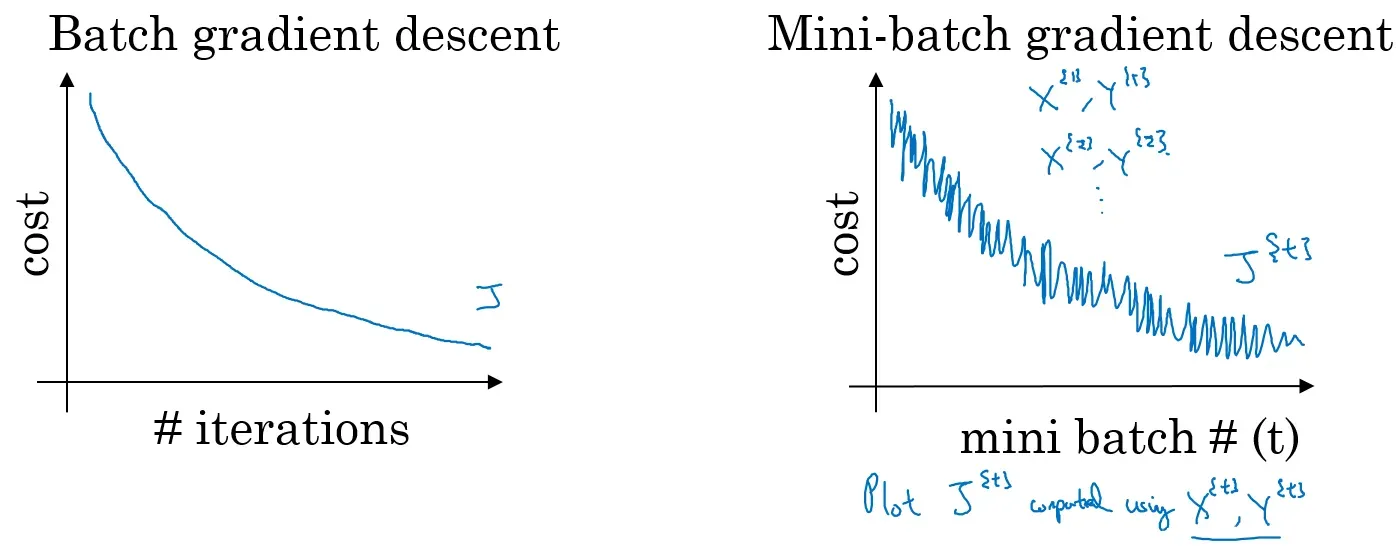
普通的batch梯度下降法和Mini-batch梯度下降法代价函数的变化趋势,如下图所示:
– 如果训练样本的大小比较小时,能够一次性的读取到内存中,那我们就不需要使用Mini-batch。
– 如果训练样本的大小比较大时,一次读入不到内存或者现存中,那我们必须要使用 Mini-batch来分批的计算 – Mini-batch size的计算规则如下,在内存允许的最大情况下使用2的N次方个size。
torch.optim是一个实现了各种优化算法的库。大部分常用优化算法都有实现,我们直接调用即可。


torch.optim.SGD
随机梯度下降算法,带有动量(momentum)的算法作为一个可选参数可以进行设置,样例如下:
#lr参数为学习率,对于SGD来说一般选择0.1 0.01.0.001,如何设置会在后面实战的章节中详细说明##如果设置了momentum,就是带有动量的SGD,可以不设置optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)<torch.optim.RMSprop
除了以上的带有动量Momentum梯度下降法外,RMSprop(root mean square prop)也是一种可以加快梯度下降的算法,利用RMSprop算法,可以减小某些维度梯度更新波动较大的情况,使其梯度下降的速度变得更快。
#我们的课程基本不会使用到RMSprop所以这里只给一个实例optimizer = torch.optim.RMSprop(model.parameters(), lr=0.01, alpha=0.99)<torch.optim.Adam
Adam 优化算法的基本思想就是将 Momentum 和 RMSprop 结合起来形成的一种适用于不同深度学习结构的优化算法。
# 这里的lr,betas,还有eps都是用默认值即可,所以Adam是一个使用起来最简单的优化方法optimizer = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999), eps=1e-08)<
2.4,方差&偏差
偏差衡量学习算法的预期预测与实际结果之间的偏差,它描述了学习算法本身的拟合能力。
方差衡量的是相同大小的训练集变化引起的学习性能变化,即模型的泛化能力。
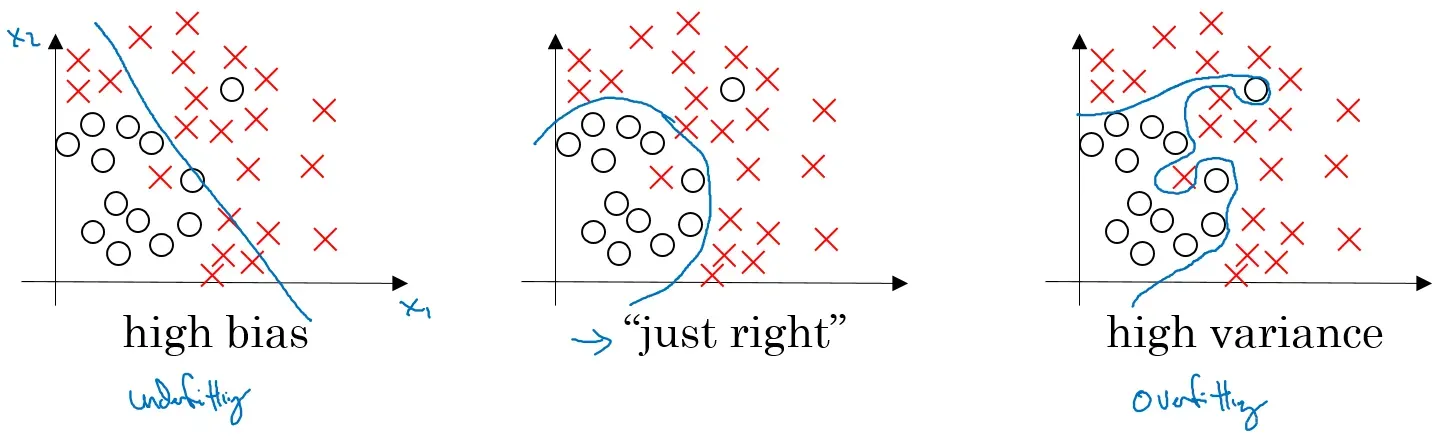
高偏差(high bias)的情况:一般称为欠拟合(underfitting),即我们的模型并没有很好的去适配现有的数据,拟合度不够。
高方差(high variance)的情况:一般称作过拟合(overfitting),即模型对于训练数据拟合度太高了,失去了泛化的能力。
欠拟合解决方案:
- 增加网络结构,例如增加隐藏层数;
- 训练时间更长;
- 寻找合适的网络架构,使用更大的NN结构;
过拟合解决方案:
- 使用更多数据;
- 正则化( regularization);
- 找到合适的网络结构;
#计算出偏差:print (5-w.data.item(),7-b.data.item())<
3,猫鱼图像分类
3.1,建立训练集
猫,鱼分类数据集,训练集,测试集和验证集-机器学习文档类资源-CSDN下载
接下来就需要把它们转换成PyTorch能理解的一种格式,torchvision包中有一个名为ImageFolder的类,它能很好地为我们完成一切,只要我们的图像在一个适当的目录结构中,其中每个目录分别是一个标签(例如所有的猫都在一个名为cat的目录中):
import torchvisionfrom torchvision import transformstrain_data_path = "/train/"transforms = transforms.Compose([ transforms.Resize(64), #将每个图像缩放为相同分辨率64*64 transforms.ToTensor(), #将图像转换成一个张量 transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) #根据特定的均值进行归一化处理,超参数。])train_data = torchvision.datasets.ImageFolder(root=train_data_path, transforms=transforms)<将图像大小调整为64*64,这是随意调整的,目的是让接下来第一个网络能很快地计算。一般来讲,大多数现有的框架都使用224*224或299*299的图像输入。而输入尺寸越大,网络学习的数据就越多,但通常GPU内存中职能容纳很小批量的图像。
torchvision允许指定一个转换列表,将图像输入到神经网络之前可以应用这些转换。默认转换是将图像转换为一个张量(transforms.ToTensor()方法),另外还可以做一些可能看起来不太明显的工作。
归一化很重要,因为输入通过神经网络层时会完成大量乘法;保证到来的值在0~1之间可以防止训练阶段中值变得过大(梯度爆炸)。这里使用的神奇参数是整个ImageNet数据集的均值和标准差。可以专门计算整个鱼和猫子集的均值和标准差,不过ImageNet数据集的这些参数已经足够了(如果你处理一个完全不同的数据集,就必须计算均值和标准差,直接使用ImageNet常量也是可接受的)。
3.2,建立验证集和测试集
深度学习面临的一个危险是过拟合:你的模型确实能很好地识别所训练的数据,不过不能泛化到它没见过的例子上面。它看到一个猫的图像后,除非其他猫的图像都与这个图像非常相似,否则模型不会认为那是猫,尽管它们是猫。为了防止网络出现这个问题,因此准备验证集,这是未出现在训练集中的一系列猫和鱼的图像。在每个训练周期(epoch)的最后,通过与这个验证集的比较来确保我们的网络没有做错。
除了验证集之外,您还需要创建一个测试集,用于在所有训练完成后测试模型。
train_data_path = "/train/"val_data_path = "/val/"test_data_path = "/test/"train_data = torchvision.datasets.ImageFolder(root=train_data_path, transforms=transforms)val_data = torchvision.datasets.ImageFolder(root=val_data_path, transforms=transforms)test_data = torchvision.datasets.ImageFolder(root=test_data_path, transforms=transforms)<构建数据加载器:
import torchvision.datasets as databatch_size = 64train_data_loader = data.DataLoader(train_data, batch_size=batch_size)val_data_loader = data.DataLoader(val_data, batch_size=batch_size)test_data_loader = data.DataLoader(test_data, batch_size=batch_size)<batch_size:在训练和更新网络之前将为这个网络提供多少图像。理论上讲,可以把batch_size设置为测试和训练集中的图像数,使网络在更新之前会看到每一个图像。但在实际中,我们并不会这么做,因为与存储数据集中每一个图像的所有相关信息相比,较小批量需要的内存更少,而且更小的批量会使训练速度更快,以便我们可以更快地更新网络。
PyTorch的数据加载器将batch_size默认设置为1,你几乎一定会改变这个。你还可以指定数据集如何采样,每次运行时是否将数据集打乱,另外从数据集取数据需要使用多少个工作进程。
3.3,搭建神经网络
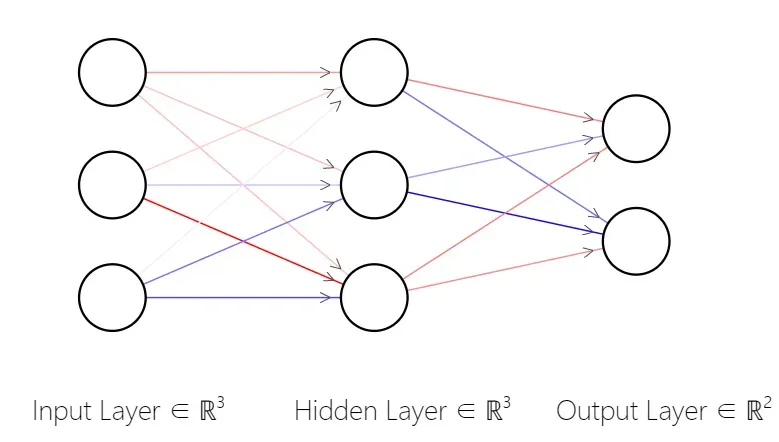
神经网络结构:一个输入层,它要处理输入张量(我们的图像);另外一个输出层,其大小为输出的类别的个数(2);介于这两者之间的一个隐藏层;层与层之间采用全连接。
图中的神经网络,它有一个包含3个节点的输入层,一个包含3个节点的隐藏层和一个包含2个节点的输出层。可以看出,在全连接中每一个节点都会影响下一层中各个节点,而且每个连接有一个权重,它确定了信号从这个节点进入下一层的强度(训练的主要目的就是更新这些权重,通常会随机化开始)。一个输入传入网络时,可以简单地对权重与这一层对输入的偏置完成矩阵乘法。
在PyTorch中创建神经网络需要继承一个名为torch.nn.Network的类,填写__init__和forward方法:
import torch.nn as nnimport torch.nn.functional as Fclass SimpleNet(nn.Module): def __init__(self): super(SimpleNet, self).__init__() #建立3个全连接层 self.fc1 = nn.Linear(12288, 84) self.fc2 = nn.Linear(84, 50) self.fc3 = nn.Linear(50, 2) def forward(self, x): #将图像中的3维向量转换为1维向量,从而能输入到第一个全连接层 x = x.view(-1, 12288) #调用激活函数 x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = F.softmax(self.fc3(x)) #返回softmax激活函数的结果作为分类结果 return xsimplenet = SimpleNet()<隐藏层的结点数可以任意,不过要求最后输出层节点数为2,这与我们的分类结果相对应。一般来讲,你会希望层中的数据向下传递时进行压缩。比如,如果一个层有50个输入对100个输出,那么网络在学习时,只需要把50个连接传递到100个输出中的50个,就认为它的工作完成了。根据输入减少输出的大小,就能要求这部分网络用更少的资源学习原始输入的一个表示,这往往意味着它会提取图像中对于我们要解决的问题很重要的一些特征。
3.4,损失函数和优化器
损失函数是有效深度学习解决方案的关键环节之一。PyTorch使用损失函数来确定如何更新网络从而达到期望的结果。根据你的需求,损失函数可以很复杂,也可以很简单。PyTorch提供了一个完备的损失函数集合,涵盖了你可能遇到的大多数应用,当然你也可以自定义损失函数。
import torch.optim as optimcriterion = nn.CrossEntropyLoss()optimizer = optim.Adam(simplenet.parameters(), lr=0.001)<Adam(以及RMSProp和AdaGrad)相较于SGD所做的重要改进之一是对每个参数使用一个学习率,并根据这些参数的变化率来调整学习率,它会维护一个指数衰减的梯度列表和这些梯度的平方,并用它们来调整Adam使用的全局学习率。根据经验,对于深度学习网络,Adam远胜于大多数其他优化器,不过你也可以把Adam换成SGD或RMSProp。
3.5,模型的训练
def train(model, optimizer, loss_fn, train_loader, val_loader, epochs=20, device=torch.device("cuda")): for epoch in range(1, epochs + 1): training_loss = 0.0 valid_loss = 0.0 model.train() for batch in train_loader: optimizer.zero_grad() inputs, targets = batch inputs = inputs.to(device) targets = targets.to(device) output = model(inputs) loss = loss_fn(output, targets) loss.backward() optimizer.step() training_loss += loss.data.item() * inputs.size(0) training_loss /= len(train_loader.dataset) model.eval() num_correct = 0 num_examples = 0 for batch in val_loader: inputs, targets = batch inputs = inputs.to(device) output = model(inputs) targets = targets.to(device) loss = loss_fn(output, targets) valid_loss += loss.data.item() * inputs.size(0) correct = torch.eq(torch.max(F.softmax(output, dim=1), dim=1)[1], targets) num_correct += torch.sum(correct).item() num_examples += correct.shape[0] valid_loss /= len(val_loader.dataset) print( 'Epoch: {}, Training Loss: {:.2f}, Validation Loss: {:.2f}, accuracy = {:.2f}'.format(epoch, training_loss, valid_loss, num_correct / num_examples))if torch.cuda.is_available(): device = torch.device("cuda") print("cuda")else: device = torch.device("cpu") print("cpu")simplenet.to(device)train(simplenet, optimizer,torch.nn.CrossEntropyLoss(), train_data_loader,val_data_loader, epochs=10, device=device)<
3.6,预测
simplenet = torch.load("simplenet")labels = ['cat','fish']import osi =0j =0for root, dirs, files in os.walk("test/cat"): for file in files: j+=1 img = Image.open("test/cat/"+file) img = transforms(img).to(device) img = torch.unsqueeze(img, 0) simplenet.eval() prediction = F.softmax(simplenet(img), dim=1) prediction = prediction.argmax() if(labels[prediction]=="cat"): i+=1print(i/j)<重用了前面的转换流水线,将图像准换为适用于这个神经网络的正确形式。不过,由于我们的网络使用了批次,实际上它希望得到一个4维张量,第一个维度指示一个批次中的不同图像。我们没有批次,不过可以使用unsqueeze(0)创建长度为1的一个批次,这回在张量最前面增加一个维度。
得到预测结果很简单,只需要把我们的批次传入模型,然后找出较大概率的类。在这里,可以简单地将张量转换为一个数组,并比较这两个元素,不过通常会有更多元素。PyTorch提供了argmax()函数,这很有用,它会返回张量中最大值的索引。然后使用这个索引访问我们的标签数组,打印结果。
我们可以使用save保存整个模型,也可以仅使用state_dict保存参数。使用state_dict通常更可取,因为它允许您重用参数,即使模型的结构发生变化(或将参数从一个模型应用到另一个模型)。
torch.save(simplenet, "/tmp/simplenet") simplenet = torch.load("/tmp/simplenet")<torch.save(simplenet.state_dict(), "/tmp/simplenet") simplenet = SimpleNet()simplenet_state_dict = torch.load("/tmp/simplenet")simplenet.load_state_dict(simplenet_state_dict)<
4,卷积神经网络
class CNNNet(nn.Module): def __init__(self, num_classes=2): super(CNNNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(64, 192, kernel_size=5, padding=2), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(192, 384, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), ) self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) self.classifier = nn.Sequential( nn.Dropout(), nn.Linear(256 * 6 * 6, 4096), nn.ReLU(), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(), nn.Linear(4096, num_classes) ) def forward(self, x): x = self.features(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.classifier(x) return x<
4.1,卷积:Conv2d
Conv2d层是一个二维卷积。如果有一个灰度图像,它会包含一个数组,宽度为x像素,高度为y像素,数组中的每个元素有一个值,指示这是黑色还是白色,或者介于两者之间(假设是一个8位图像,那么每个值可以在0~255之间)。例如:一个高度和宽度都是4像素的图像:
卷积核:这是另外一个矩阵,可能更小,我们会在图像上拖动这个过滤器。例如:一个2*2卷积核:
卷积结果:要生成输出,使用卷积核在原始输入上滑动,就像放大镜在一张纸上滑动一样。例如:从左上角开始,我们的第一台电脑结果是:
nn.Conv2d(in_channels,out_channel, kernel_size, stride, padding)in_channels:是这一层要接收的输入通道个数。开始时,网络接受RGB图像作为输入,所以输入通道数为3。out_channels:是这一层输出通道个数,对应卷积层中卷积核的个数。kernel_size:对应卷积核的大小。stride:表示将过滤器调整到一个新位置时要在输入上移动多少步。可以按1来移动,这样可以得到与输入大小相同的特征图输出。还可以传入一个元组(a,b),这允许每一步水平移动a并且向下移动b。padding:如果stride使用元组,可能出现数值丢失,padding就是用来指定缺失值。如果没有设置stride,则最后一列会被直接丢弃。<
4.2,池化:MaxPool2d
除了卷积层,池化层也很常见。这些层降低了前一个输入层的网络分辨率,是的,较低层的参数更少。首先,这种压缩使计算速度更快,并且有助于避免网络中的过度拟合。
在上述模型中,我们使用了MaxPool2d,内核大小为3,步长为2。例如:一个5*3的输入:
使用内核大小为3*3和步长为2,可以通过池化得到两个3*3的张量:
在MaxPool中,我们分别从这两个张量中取最大值,这样就得到一个输出张量
。与卷积层一样,MaxPool也有一个padding选项,可以在张量上创建一个0值组成的边框,以防跨出到张量窗口之外。
除了从内核取得最大值,还可以用其他函数池化。一个很受欢迎的函数是取张量平均值,这就使得所有张量数据都会对池化做出贡献,而不像max中那样只是一个值所贡献。
另外,PyTorch还提供了AdaptiveMaxPool和AdaptiveAvgPool层,它们的工作独立于接收的输入张量的维度。建议在你构造的模型架构中使用这些层而不是标准的MaxPool或AvgPool层,因为它们允许你创建可以处理不同输入维度的架构;在处理不同的数据集时,这回很方便。
4.3,Dropout
对于神经网络,一个反复出现的问题是它们很容易对训练数据过拟合,为此神经网络领域做了大量工作来寻找适当的方法,希望能够使网络学习和泛化到非训练数据,而不只是学习如何简单地应对训练输入。为了做到这一点,Droput(随机失活)层是一个极其简单的方法,好处是很容易理解而且很有效:在一个训练周期中,如果对网络中随机一组节点不做训练怎么样?因为他们不会更新,所以没有机会与输入数据过拟合,而且由于这是随机的,所以每个训练周期会忽略输入中不同的数据,这有助于进一步泛化。
默认地,在上述CNN网络中,Droupout层初始化为0.5,这表示50%的输入张量会随机地置为0。如果你想把它修改为20%,可以为初始化调用增加p参数:Dropout(p=0.2)。
4.4,训练模型
import torchvision.models as modelsimport torch.nn as nnimport torchvisionimport torchvision.models as modelsimport torchfrom torchvision import transformsfrom PIL import Imageimport torch.nn.functional as Fimport torch.optim as optimclass CNNNet(nn.Module): def __init__(self, num_classes=2): super(CNNNet, self).__init__() self.features = nn.Sequential( nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(64, 192, kernel_size=5, padding=2), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), nn.Conv2d(192, 384, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(256, 256, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(kernel_size=3, stride=2), ) self.avgpool = nn.AdaptiveAvgPool2d((6, 6)) self.classifier = nn.Sequential( nn.Dropout(), nn.Linear(256 * 6 * 6, 4096), nn.ReLU(), nn.Dropout(), nn.Linear(4096, 4096), nn.ReLU(), nn.Linear(4096, num_classes) ) def forward(self, x): x = self.features(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.classifier(x) return xdef train(model, optimizer, loss_fn, train_loader, val_loader, epochs=20, device="cpu"): for epoch in range(1, epochs + 1): training_loss = 0.0 valid_loss = 0.0 model.train() for batch in train_loader: optimizer.zero_grad() inputs, targets = batch inputs = inputs.to(device) targets = targets.to(device) output = model(inputs) loss = loss_fn(output, targets) loss.backward() optimizer.step() training_loss += loss.data.item() * inputs.size(0) training_loss /= len(train_loader.dataset) model.eval() num_correct = 0 num_examples = 0 for batch in val_loader: inputs, targets = batch inputs = inputs.to(device) output = model(inputs) targets = targets.to(device) loss = loss_fn(output, targets) valid_loss += loss.data.item() * inputs.size(0) correct = torch.eq(torch.max(F.softmax(output, dim=1), dim=1)[1], targets) num_correct += torch.sum(correct).item() num_examples += correct.shape[0] valid_loss /= len(val_loader.dataset) print( 'Epoch: {}, Training Loss: {:.2f}, Validation Loss: {:.2f}, accuracy = {:.2f}'.format(epoch, training_loss, valid_loss, num_correct / num_examples))img_transforms = transforms.Compose([ transforms.Resize((64, 64)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])train_data_path = "./train/"train_data = torchvision.datasets.ImageFolder(root=train_data_path, transform=img_transforms)val_data_path = "./val/"val_data = torchvision.datasets.ImageFolder(root=val_data_path, transform=img_transforms)batch_size = 64train_data_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True)val_data_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, shuffle=True)if torch.cuda.is_available(): device = torch.device("cuda")else: device = torch.device("cpu")cnnnet = CNNNet()cnnnet.to(device)optimizer = optim.Adam(cnnnet.parameters(), lr=0.001)train(cnnnet, optimizer, torch.nn.CrossEntropyLoss(), train_data_loader, val_data_loader, epochs=10, device=device)<
5,预训练
5.1,预训练模型
显然,如果每次都要使用一个模型都必须定义模型,这会很麻烦,特别是如果你的起点是AlexNet,PyTorch默认地在torchvision库中提供了很多流行的模型。对于AlexNet,所做的只是:
import torchvision.models as modelsalexnet = models.alexnet(num_classes=1000, pretrained=True)print(alexnet)<另外还提供了不同版本的VGG,ResNet,Inception,DenseNet和SqueezeNet的定义。这里提供了模型定义,不过你还可以更进一步调用models.alexnet(pretrained=True)为AlexNet下载一个预训练的权重集,这样你就能立即用它进行分类而不需要额外的训练(大部分情况下还需要做一些训练,来提高特定数据集上的准确度)。
PyTorchHub:PyTorch提供了另外一个途径来获取模型:PyTorchHub。未来这应该会成为所有发布模型的中心,无论是用于处理图像、文本、音频视频还是其他类型的数据。要以这种方式得到一个模型,需要使用torch.hub模块:
resnet50 = torch.hub.load('pytorch/vision', 'resnet50')print(resnet50)<第一个参数只是一个GitHub所有者和存储库(这个字符串还可以有一个可选的tag/branc标识符);第二个参数是所请求的模型(resnet50);第三个参数指示是否下载预训练的权重。还刻意使用torch.hub.list(‘pytorch/vision’)发现存储库可以下载的所有模块。
5.2,BatchNorm
BatchNorm:是批归一化,这是只有一个任务的简单层:使用两个学习参数(这意味着它将随其余网络进行训练),努力确保通过网络的每个小批次(minibatch)均值以0为中心(零均值化),并且方差为1。
[问题] 在我们通过转换链团队来规范化输入之前,为什么我们还需要这项工作?
【答案】对于较小的网络,BatchNorm确实没有太大用处,但是随着网络越来越大,由于反复相乘,任意一层对另一层的影响是极大的,最终可能会遭遇梯度消失或梯度爆炸,这两个问题对于训练过程是致命的。BatchNorm层可以确保即使使用类似ResNet-152的模型,网络中的乘法也不会失控。
【问题】如果我们网络中有BatchNorm,为什么还要在训练循环的转换连中对输入归一化呢?难道BatchNorm不能为我们做这个工作吗?
[回答] 绝对!但这使得网络需要更长的时间来学习如何控制输入,因为它们必须自己发现初始转换,这使得训练时间更长。
6,迁移学习
6.1,用ResNet迁移学习
创建ResNet模型,然后进行训练,这完全可以。ResNet模型并没有什么神奇的地方:它同样由你已见过的构建模块组成。不过,这是一个很大的模型。另外,尽管用你的数据对一个基准ResNet做一些改进,但它还是需要大量数据来确保训练信号达到架构的所有部分,并针对新的分类任务进行训练。因此我们想避免在这个方法中使用大量数据。
现在的情况是:我们处理的架构不是用随机参数初始化,这与我们以前的做法不同。预训练的ResNet模型已经编码了一组信息来满足图像识别和分类需要,所以没必要进行重新训练。实际上,我们会微调(fine-tune)这个网络。对这个架构稍作修改,在最后包括一个新的网络模块,来取代正常情况下完成ImageNet分类(1000个类别)的标准线性层。然后冻结(freeze)所有现有的ResNet层,训练时,只更新新层中的参数,不过还使用要从冻结层得到激活值。这使得我们可以快速地训练新层,同时保留预训练已经包含的信息。
1,创建一个预训练的ResNet-50模型。
import torchvision.models as modelstransfer_model = models.resnet50(pretrained=True)<2,接下来需要冻结这些层。做法很简单:通过使用requires_grad()让它们停止累计梯度。需要对网络中的每一个参数都这么做,不过好在PyTorch提供了一个parameters()方法,可以很容易地完成这个工作。
for name, param in transfer_model.named_parameters(): param.requires_grad = False<你可能不想冻结模型中的BatchNorm层,因为这些层训练为逼近模型原先训练数据集的均值和标准差,而不是你想要微调的那个数据集。BatchNorm修正你的输入时,最后可能会丢失数据的一些信号。可以查看模型结构,只冻结不是BatchNorm的层:
for name, param in transfer_model.named_parameters(): if("bn" not in name): param.requires_grad = False<3,把最后的分类模块替换为一个新模块,就是我们要训练来检验是猫还是鱼的模块。在这个例子中,我们把她替换为两个Linear层、一个ReLU和Dropout,不过这里也可以有额外的CNN层。PyTorch中ResNet实现的定义把最后的分类器模块存储为一个实例变量fc,所以我们需要做的就是把它替换为我们的新结构:
transfer_model.fc = nn.Sequential(nn.Linear(transfer_model.fc.in_features,500),nn.ReLU(), nn.Dropout(), nn.Linear(500,2))<上面代码中,我们利用in_features变量,这可以用来得到进入一层的激活值数(这里是2048)。还可以使用out_features发现输出的激活值。想打砖块一样组合网络时,这些函数会很方便。如果一层的输入特征与前一层的输出特征不一致,程序会在运行时报错。
4,训练网络。应该可以看到,只用几个epoch,准确率就会大幅度提升。
import torchvision.models as modelsimport torch.nn as nnimport torchvisionimport torchvision.models as modelsimport torchfrom torchvision import transformsfrom PIL import Imageimport torch.nn.functional as Fimport torch.optim as optimtransfer_model = models.resnet50(pretrained=True)for name, param in transfer_model.named_parameters(): if("bn" not in name): param.requires_grad = Falsetransfer_model.fc = nn.Sequential(nn.Linear(transfer_model.fc.in_features,500),nn.ReLU(),nn.Dropout(), nn.Linear(500,2))def train(model, optimizer, loss_fn, train_loader, val_loader, epochs=20, device="cpu"): for epoch in range(1, epochs + 1): training_loss = 0.0 valid_loss = 0.0 model.train() for batch in train_loader: optimizer.zero_grad() inputs, targets = batch inputs = inputs.to(device) targets = targets.to(device) output = model(inputs) loss = loss_fn(output, targets) loss.backward() optimizer.step() training_loss += loss.data.item() * inputs.size(0) training_loss /= len(train_loader.dataset) model.eval() num_correct = 0 num_examples = 0 for batch in val_loader: inputs, targets = batch inputs = inputs.to(device) output = model(inputs) targets = targets.to(device) loss = loss_fn(output, targets) valid_loss += loss.data.item() * inputs.size(0) correct = torch.eq(torch.max(F.softmax(output), dim=1)[1], targets).view(-1) num_correct += torch.sum(correct).item() num_examples += correct.shape[0] valid_loss /= len(val_loader.dataset) print( 'Epoch: {}, Training Loss: {:.2f}, Validation Loss: {:.2f}, accuracy = {:.2f}'.format(epoch, training_loss, valid_loss, num_correct / num_examples))img_transforms = transforms.Compose([ transforms.Resize((64,64)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225] ) ])train_data_path = "./train/"val_data_path = "./val/"train_data = torchvision.datasets.ImageFolder(root=train_data_path,transform=img_transforms)val_data = torchvision.datasets.ImageFolder(root=val_data_path,transform=img_transforms)batch_size=64train_data_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True)val_data_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, shuffle=True)if torch.cuda.is_available(): device = torch.device("cuda")else: device = torch.device("cpu")print(len(val_data_loader.dataset))transfer_model.to(device)optimizer = optim.Adam(transfer_model.parameters(), lr=0.001)train(transfer_model, optimizer,torch.nn.CrossEntropyLoss(), train_data_loader, val_data_loader, epochs=5, device=device)<==================迁移学习===================Epoch: 1, Training Loss: 0.51, Validation Loss: 0.19, accuracy = 0.90Epoch: 2, Training Loss: 0.20, Validation Loss: 0.17, accuracy = 0.93Epoch: 3, Training Loss: 0.11, Validation Loss: 0.24, accuracy = 0.92Epoch: 4, Training Loss: 0.05, Validation Loss: 0.19, accuracy = 0.93Epoch: 5, Training Loss: 0.01, Validation Loss: 0.19, accuracy = 0.93==================卷积神经网络================Epoch: 1, Training Loss: 1.05, Validation Loss: 0.63, accuracy = 0.81Epoch: 2, Training Loss: 0.70, Validation Loss: 0.69, accuracy = 0.71Epoch: 3, Training Loss: 0.65, Validation Loss: 0.60, accuracy = 0.69Epoch: 4, Training Loss: 0.53, Validation Loss: 0.39, accuracy = 0.83Epoch: 5, Training Loss: 0.49, Validation Loss: 0.34, accuracy = 0.84==================全连接神经网络===============Epoch: 1, Training Loss: 0.63, Validation Loss: 0.56, accuracy = 0.74Epoch: 2, Training Loss: 0.54, Validation Loss: 0.51, accuracy = 0.79Epoch: 3, Training Loss: 0.49, Validation Loss: 0.51, accuracy = 0.81Epoch: 4, Training Loss: 0.46, Validation Loss: 0.59, accuracy = 0.71Epoch: 5, Training Loss: 0.44, Validation Loss: 0.51, accuracy = 0.81<
6.2,查找学习率
学习率是您可以修改的最重要的超参数之一,建议使用相当小的数字并自己尝试不同的值。这就是有多少人为他们的架构找到最佳学习率,通常使用一种称为网格搜索的技术,它详尽地搜索学习率值的子集,并将结果与验证数据集进行比较。 ,真的很费时间,导致大部分人选择相信从业者的经验。
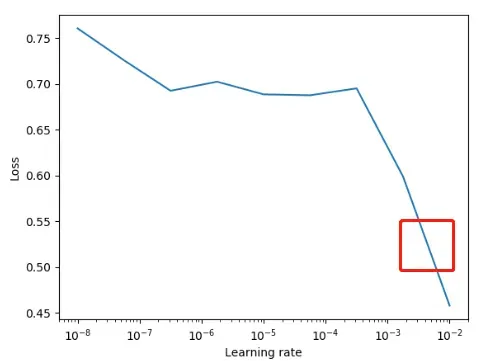
利用fast.ai技术可以快速找到适合的学习率:在一个epoch期间,首先从一个小的学习率开始,每一个小批次增加到一个更大的学习率,直到这个epoch结束时得到一个很大的学习率。计算每个学习率的响应损失,然后得到一个图,选择出使损失下降最大的学习率。
这里大约在
之间,因为梯度下降是中间最大的。
import torchvision.models as modelsimport torch.nn as nnimport torchvisionimport torchvision.models as modelsimport torchfrom matplotlib import pyplot as pltfrom torchvision import transformsfrom PIL import Imageimport torch.nn.functional as Fimport torch.optim as optimtransfer_model = models.resnet50(pretrained=True)for name, param in transfer_model.named_parameters(): if("bn" not in name): param.requires_grad = Falsetransfer_model.fc = nn.Sequential(nn.Linear(transfer_model.fc.in_features,500),nn.ReLU(),nn.Dropout(), nn.Linear(500,2))img_transforms = transforms.Compose([ transforms.Resize((64,64)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225] ) ])train_data_path = "./train/"val_data_path = "./val/"train_data = torchvision.datasets.ImageFolder(root=train_data_path,transform=img_transforms)val_data = torchvision.datasets.ImageFolder(root=val_data_path,transform=img_transforms)batch_size=64train_data_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True)val_data_loader = torch.utils.data.DataLoader(val_data, batch_size=batch_size, shuffle=True)if torch.cuda.is_available(): device = torch.device("cuda")else: device = torch.device("cpu")print(len(val_data_loader.dataset))transfer_model.to(device)optimizer = optim.Adam(transfer_model.parameters(), lr=0.001)def find_lr(model, loss_fn, optimizer, train_loader, init_value=1e-8, final_value=10.0, device="cpu"): number_in_epoch = len(train_loader) - 1 update_step = (final_value / init_value) ** (1 / number_in_epoch) lr = init_value optimizer.param_groups[0]["lr"] = lr best_loss = 0.0 batch_num = 0 losses = [] log_lrs = [] for data in train_loader: batch_num += 1 inputs, targets = data inputs = inputs.to(device) targets = targets.to(device) optimizer.zero_grad() outputs = model(inputs) loss = loss_fn(outputs, targets) # Crash out if loss explodes if batch_num > 1 and loss > 4 * best_loss: if(len(log_lrs) > 20): return log_lrs[10:-5], losses[10:-5] else: return log_lrs, losses # Record the best loss if loss < best_loss or batch_num == 1: best_loss = loss # Store the values losses.append(loss.item()) log_lrs.append((lr)) # Do the backward pass and optimize loss.backward() optimizer.step() # Update the lr for the next step and store lr *= update_step optimizer.param_groups[0]["lr"] = lr if(len(log_lrs) > 20): return log_lrs[10:-5], losses[10:-5] else: return log_lrs, losses(lrs, losses) = find_lr(transfer_model, torch.nn.CrossEntropyLoss(),optimizer, train_data_loader,device=device)plt.plot(lrs, losses)plt.xscale("log")plt.xlabel("Learning rate")plt.ylabel("Loss")plt.show()<这里所做的就是迭代各个批次,基本上照常训练,将输入传入模型,然后得到这个批次的损失。记录到目前为止的best_loss,将新损失值与它比较。如果新损失值大于best_loss的4倍,就退出函数,返回目前得到的结果(因为损失可能趋近于无穷大)。否则,继续追加这个损失以及当前学习率的对数,再在下一步更新学习率,直到循环结束时达到最大学习率。然后使用matplotlib plt函数绘图。
请注意,仅返回学习率和损失的对数片段。这样做只是因为第一次和最后几次训练往往不会告诉我们太多(特别是如果学习率很快变得非常大)。
fast.ai库中的实现还包含加权平滑,所以你会在图中得到一条平滑曲线,但这个代码段生成的输出是不平滑的。最后,要记住,因为这个函数确实会训练模型,会改变优化器的学习率设置,所以应该提前保存并重新加载你的模型,恢复到find_lr()之前的状态,还要重新初始化你选择的优化器。
6.3,差分学习率
在到目前为止的训练中,整个模型只应用了一种学习率。这在从头开始训练模型时可能是有意义的,但是通过迁移学习,您通常可以通过尝试不同的方法,通过以不同的学习率训练不同的层组来获得更好的准确性。
在前面我们冻结了模型中的所有预训练层,而只训练新的分类器,但我们也可能想要微调模型中的某些层,比如ResNet模型。对分类器前面的几层增加一些训练可能会让我们的模型更加准确一些。不过,由于前面这些层已经在ImageNet数据集上经过训练,与新的层相比,它们可能只需很少的一点训练。
optimizer = optim.Adam(transfer_model.parameters(), lr=0.001)#改为optimizer = optim.Adam([ {'params': transfer_model.layer4.parameters(), 'lr': found_lr / 3}, {'params': transfer_model.layer3.parameters(), 'lr': found_lr / 9}], lr=found_lr)<这会把layer4(分类器之前的那一层)的学习率设置为当前找到的学习率(found_lr)的1/3,并把layer3的学习率设置为found_lr学习率的1/9。从经验来看这种组合效果最好,当然你可以自由尝试。
我们冻结了所有这些预训练的层,可以给它们不同的学习率。不过,就目前而言,模型训练根本不涉及它们,因为它们不会累积梯度。
unfreeze_layers = [transfer_model.layer3,transfer_model.layer4]for layer in unfreeze_layers: for param in layer.parameters(): param.requires_grad=True<这些层中的参数现在再次接受梯度,并且在微调模型时将应用差分学习率。
6.4,数据增强
为了防止过拟合,传统的做法是提供大量数据。通过查看更多数据,模型可以更全面地了解它试图解决的问题。如果将这种情况视为压缩问题,通过阻止模型存储所有答案(由于数据过多超出其存储容量而无法存储),将要求对输入进行压缩,并且可以进行更泛化相应地生成。解决方案,而不仅仅是存储答案。
可以使用的一种方法是数据增强,如果我们有一张图像,我们可以考虑对这张图像做很多不同的处理,这样可以避免过度拟合,使模型更通用。
torchvision提供了一个丰富的转换集合,包含可以用于数据增强的大量转换,另外还提供了两种构造新转换的方法。
改变图像的亮度、对比度、饱和度和色调。对于亮度、对比度和饱和度,可以提供一个float或一个float元组,都是0~1范围之内的非负数,随机性将介于0到所提供的float之间,或者使用元组来生成随机性将介于所提供的float对之间。对于色调,要求提供介于-0.5~0.5之间的一个float或一个float元组,会生成[-hue,hue]或[min,max]之间的随机色度调整。
import torchvisionimport torchimport numpy as npfrom matplotlib import pyplot as pltfrom torchvision import transformsimg_transforms = transforms.Compose([ transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), transforms.ColorJitter(brightness=0.1, contrast=0, saturation=0, hue=0)])train_data_path = "./train/"train_data = torchvision.datasets.ImageFolder(root=train_data_path, transform=img_transforms)batch_size = 1train_data_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True)def imshow(img): img = img/2 + 0.5 npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show()dataiter = iter(train_data_loader)images, labels = dataiter.next() #imshow(torchvision.utils.make_grid(images, nrow=10))<
翻转图像
transforms.RandomHorizontalFlip(p=0.9)transforms.RandomVerticalFlip(p=0.5)<灰度
transforms.RandomGrayscale(p=0.8)<裁剪:RandomCrop和RandomResizeCrop会根据size对图像完成随机的裁剪,这个size可以是一个表示高度和宽度的int,也可以是有不同高度和宽的一个元组。
这里有一个警告,因为如果你裁剪得太小,你可能会裁剪图像的重要部分,这可能会导致模型在错误的数据上进行训练。例如,如果图像中有一只猫在桌子上玩耍,如果裁剪移除了猫并留下了部分桌子,则将其分类为猫是不合适的。
RandomResizeCrop会调整裁剪以满足给定的大小,而RandomCrop会按这个大小裁剪,可能会在图像之外加入填充。默认地,会使用constant填充模式,也就是将图像之外的像素(否则为空)填充为fill中给定的值。不过,建议使用reflect填充模式,以你为从经验看,这种填充效果比简单地放入空常量要好一些。
RandomResizeCrop使用双线性插值,不过也可以修改interpolation参数选择最近邻或双三次插值。
transforms.RandomCrop(size,padding=None,pad_if_needed=False,fill=0,padding_mode='constant')transforms.RandomResizedCrop(size,scale=(0.08,1.0),ratio=(0.75,1.3333333),interpolation=2)<旋转:如果想要随机地旋转一个图像若degrees是一个float或int,RandomRotation会在[-degrees, degrees]之间变化,如果degrees是一个元组,RandomRotation就在(min, max)之间变化。
如果expand设置为True,这个函数会扩展输出图像,使它能包含整个图像;默认地,会设置为裁剪到输入维度以内。可以指定一个PIL重采用过滤器,还可以为旋转中心提供一个(x,y)元组,否则就会在图像中心旋转。
transforms.RandomRotation(degrees=50, resample=False, expand=False, center=None)<填充:Pad是一个通用的填充操作,会在图像边框上增加填充(额外的高度和宽度)。
如果padding只有一个值,会在所有方向上应用这个指定长度的填充。如果padding是一个包含两个值的元素,会生成长度为(left/right, top/bottom)填充。默认地,填充设置为constant模式,这回把fill的值复制到填充槽。填充模式还有另外一些选择,包括edge(这会用图像边缘的最后一个值填充指定的长度);reflect(这会将图像的值(除了边缘)反射到边框);symmetric(这也是一种reflection,不过包括图像边缘的最后一个值)。
transforms.Pad(padding=100,fill=0,padding_mode=symmetric)<仿射:RandomAffine允许指定图像的随即仿射转换(缩放、旋转、平移和/或切变或者它们的任意组合)。
degress参数是一个foloat或int,或者是一个元组。如果是单个值,会生成(-degrees,degress)之间的一个随机转换。如果是一个元组,则会生成(min, max)之间的随机旋转。如果要避免出现旋转,必须显示设置degrees,对此没有默认设置。
transforms.RandomAffine(degrees,translate=None,scale=None,shear=None,resample=False,fillcolor=0)<
另外,cv2也可以完成数据增强的操作。
import numpy as npimport cv2import osj = 0for info in os.listdir(r'D:\t'): j += 1 domain = os.path.abspath( r'D:\t') # 获取文件夹的路径,此处其实没必要这么写,目的是为了熟悉os的文件夹操作 info1 = os.path.join(domain, info) # 将路径与文件名结合起来就是每个文件的完整路径 img = cv2.imread(info1) # cv2.imshow("original", img) cv2.waitKey(1000) # 水平镜像,垂直镜像,水平垂直镜像 h_flip = cv2.flip(img, 1) v_flip = cv2.flip(img, 0) hv_flip = cv2.flip(img, -1) cv2.imwrite("D://data/A" + str(j) + "//" + info + '_h_flip.jpg', h_flip) cv2.imwrite("D://data/A" + str(j) + "//" + info + '_v_flip.jpg', v_flip) cv2.imwrite("D://data/A" + str(j) + "//" + info + 'hv_flip.jpg', hv_flip) # 平移矩阵[[1,0,-100],[0,1,-12]] # M = np.array([[1, 0, -100], [0, 1, -12]], dtype=np.float32) # img_change = cv2.warpAffine(img, M, (300, 300)) # cv2.imshow("translation", img_change) # cv2.imwrite(save_path+info+'img_change.jpg', img_change) # 角度 for i in range(1, 360): rows, cols = img.shape[:2] M = cv2.getRotationMatrix2D((cols / 2, rows / 2), i, 1) dst_90 = cv2.warpAffine(img, M, (cols, rows)) # cv2.imshow("dst_90", dst_90) cv2.imwrite("D://data/A" + str(j) + "//" + info + 'dst_' + str(i) + '.jpg', dst_90) # 缩放 # height, width = img.shape[:2] # print(height,width) # res = cv2.resize(img, (2 * width, 2 * height)) # # cv2.imshow("large", res) # cv2.imwrite("D://" + 'res' + str(j) + '.jpg', res) # 仿射变换 # 对图像进行变换(三点得到一个变换矩阵) # 我们知道三点确定一个平面,我们也可以通过确定三个点的关系来得到转换矩阵 # 然后再通过warpAffine来进行变换 # point1 = np.float32([[50, 50], [300, 50], [50, 200]]) # point2 = np.float32([[10, 100], [300, 50], [100, 250]]) # M = cv2.getAffineTransform(point1, point2) # dst1 = cv2.warpAffine(img, M, (cols, rows), borderValue=(255, 255, 255)) # # cv2.imshow("affine transformation", dst1) # cv2.imwrite("D://data/A" + str(j) + "//" + info + 'dst1.jpg', dst1)cv2.waitKey(0)<
版权声明:本文为博主燕双嘤原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_42192693/article/details/122583219