内容
1.实现效果
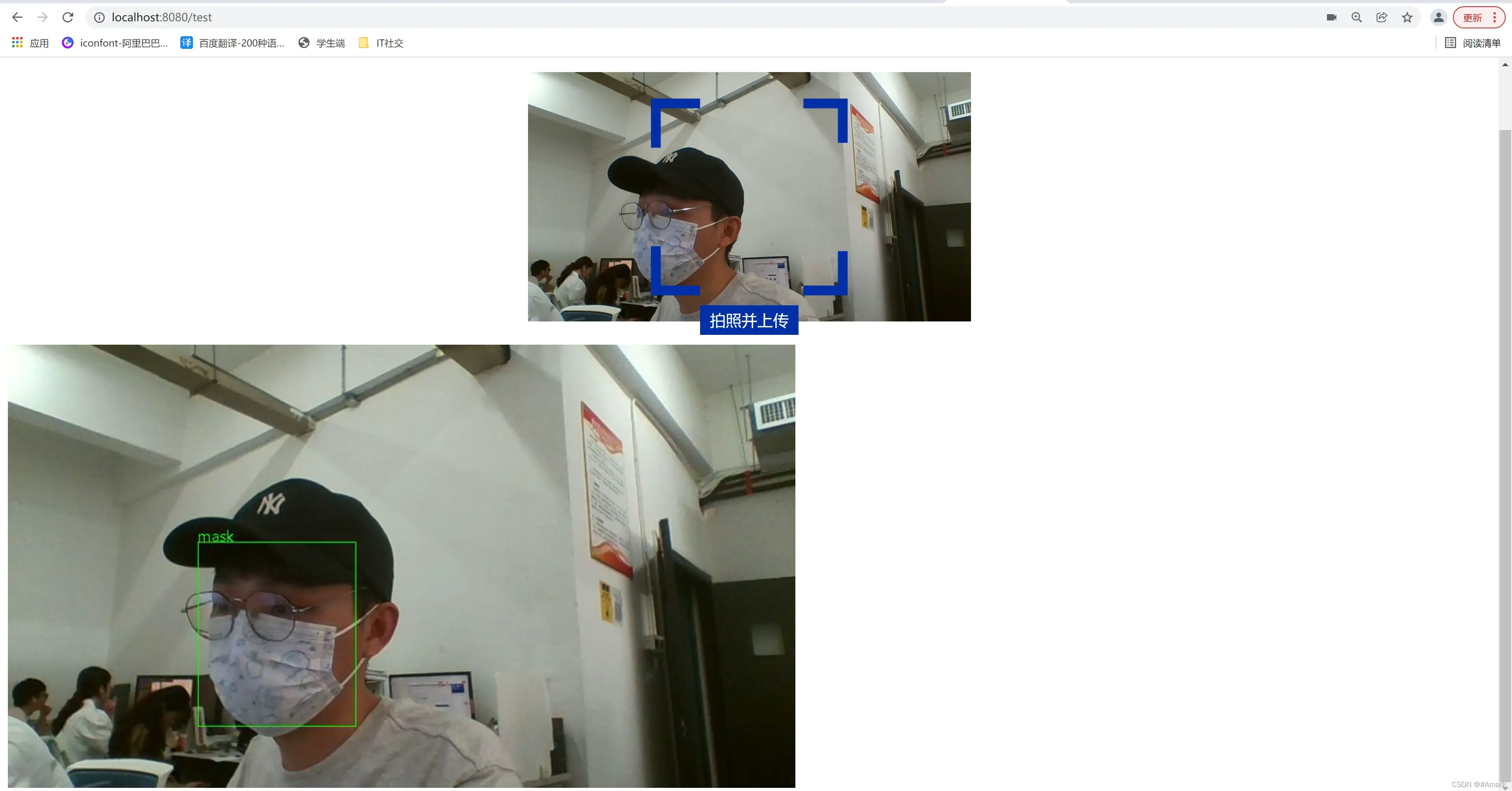
1.1、用户提交图片,检测是否带口罩
1.2、实时检测
1.3、数据集介绍
二、算法原理
2.1数据增强:Mosaic
2.2网路模型
2.2.1SPP
2.2.2Modified PAN
2.2.3完整结构
三、实验过程
3.1推理阶段
3.1.1读取并加载权重文件
3.1.2读取图片并将输入的图片按照要求的大小进行调整
3.1.4代码
3.2训练阶段
3.2.1 网络结构
4、结果分析
4.1:推理阶段效果
五、结论
6. 参考文献
1.实现效果
1.1、用户提交图片,检测是否带口罩

1.2、实时检测

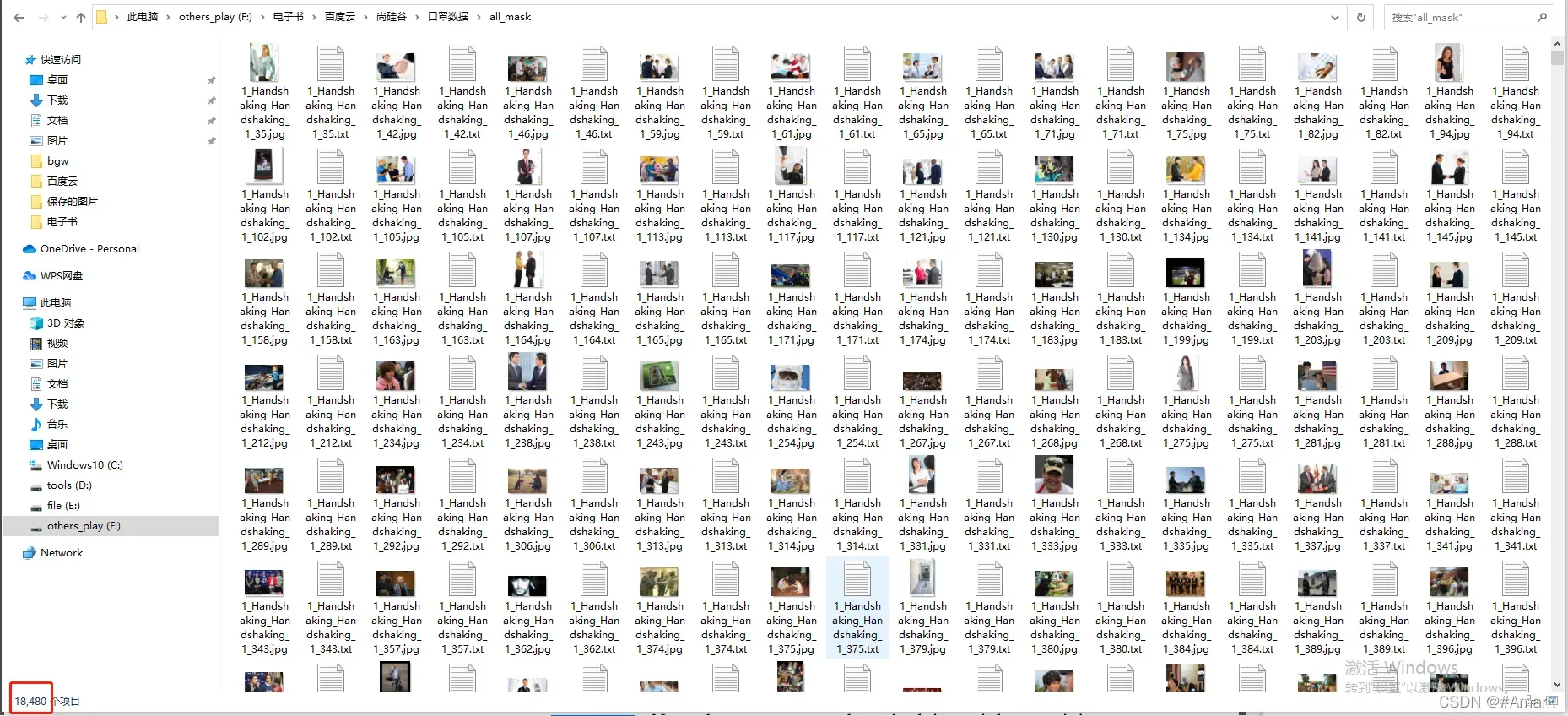
1.3、数据集介绍
训练集(下载地址(提取码:067d))
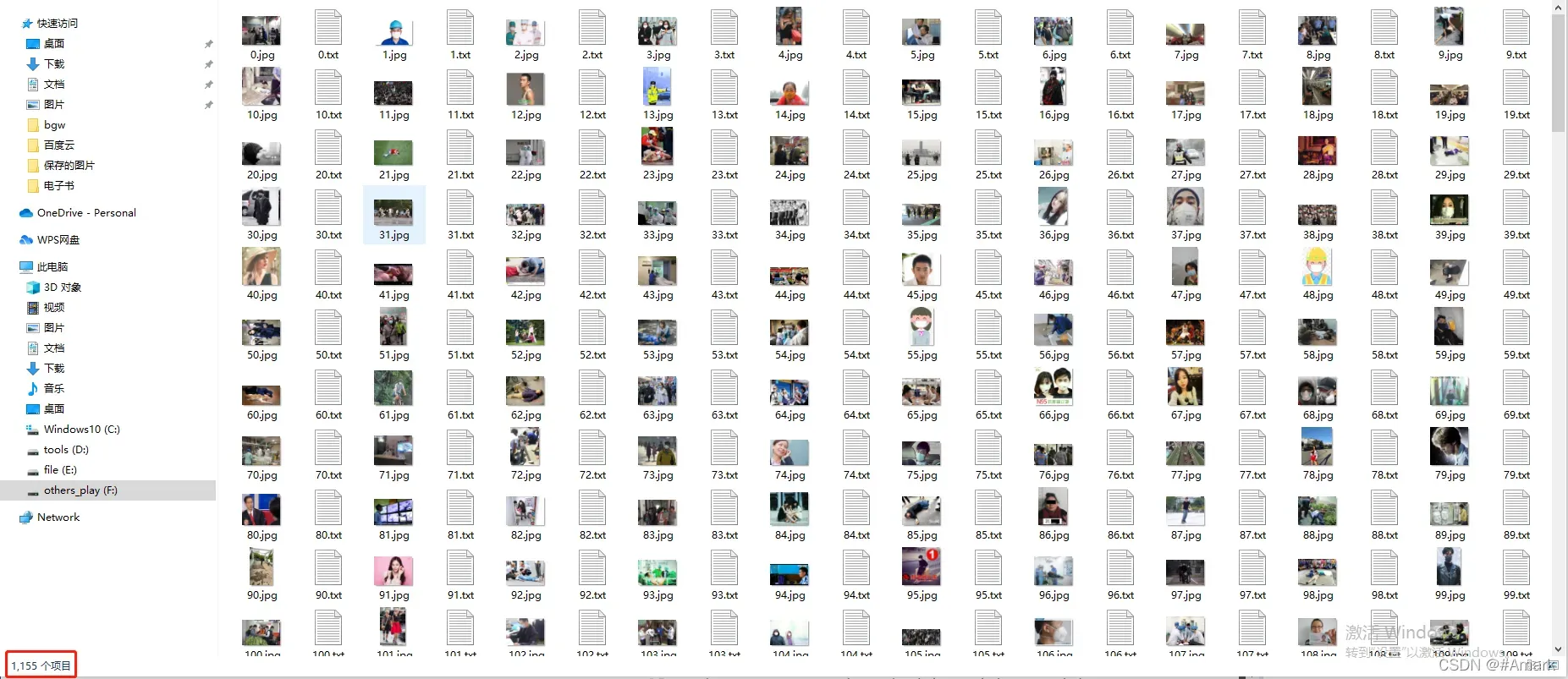
测试集
二、算法原理
以YOLOv4为例的深度学习的目标检测算法,是通过卷积神经网络学习预选框与真实框之间的坐标、长宽的回归模型和类别的分类模型,以此完成定位和分类任务。
2.1数据增强:Mosaic
YOLOv4中提出了新的数据增强方式。通过将四张随机选取的图片进行拼接得到一张新的图片。设要生成新图片大小为(W,H),随机得到左上图片的尺寸为(cutX,cutY),则在选取的四种图片中的第一张图片随机切割长宽为(cutX,cutY)的图片填充到左上角,其他三次同理,切割大小分别为(cutX,H-cutY),(W-cutX,cutY),(W-cutX,H-cutY)。
2.2网路模型
YOLOv4在先前的网络基础上进行了修改,加入SPP结构,将FPN结构改为采用Modified PAN结构。
2.2.1SPP
SPP全称为Spatial Pyramid Pooling ,即空间金字塔池化。如图二所示
YOLOv4中的实现是对进行 5 × 5 、 9 × 9 、 13 × 13 的最大池化,完成池化后,将三者进行concatenete,连接成一个特征图。SPP网络用在YOLOv4中的目的是增加网络的感受野。
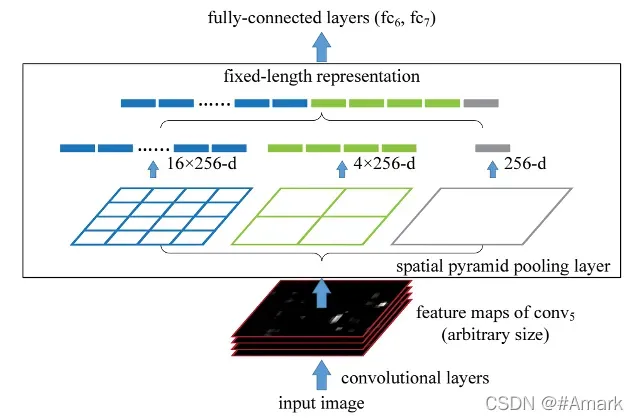
图二:SPP
2.2.2Modified PAN
PAN是在FPN的基础上新添加了一条由下至上的路径。FPN即特征金字塔网络,如图三(a)所示,PAN如图三(a)(b)所示
FPN认为网络路径中靠前的网络层,即采样倍数较小的层,图片更为清晰,但语义能力差,相反网络路径中靠后的网络层,即采样倍数较大的层,图片较模糊,但语义能力强。使用短接将二者连接起来形成一个特征金字塔。
而PAN的研究发现,靠前网络层的传播路径仍然很漫长,如红线所示。注意不能以图片看见的层数作为实际的层数。绿色框代表了网络中的很多层。于是又新添加了一条有下至上的路径,使得信息更快的传播。
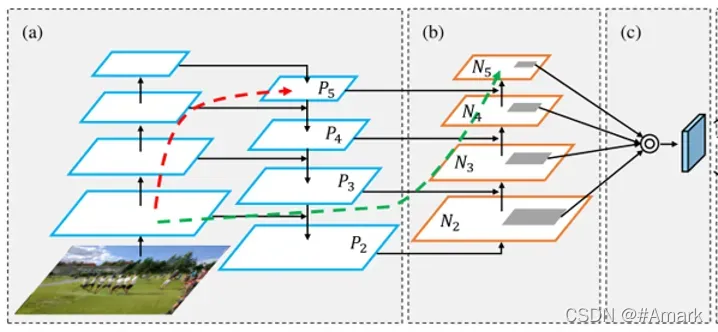
图三:FPN与PAN
YOLOv4对于原本的PAN又进行了修改,改变了原本的最终多层的特征融合方式,由数值的相加改为了维度的链接。使得多层的信息更好的融合保存下来。其如图 4所示
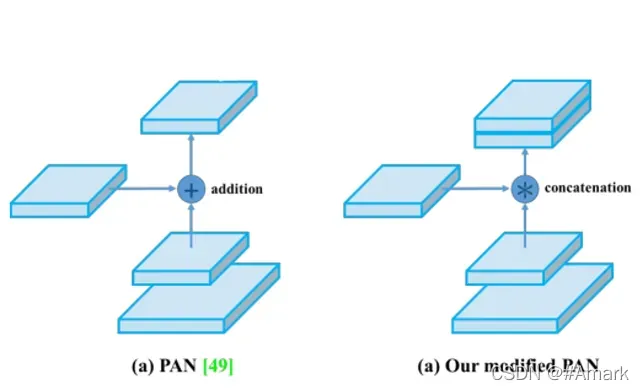
图四:PAN与Modifed PAN
2.2.3完整结构
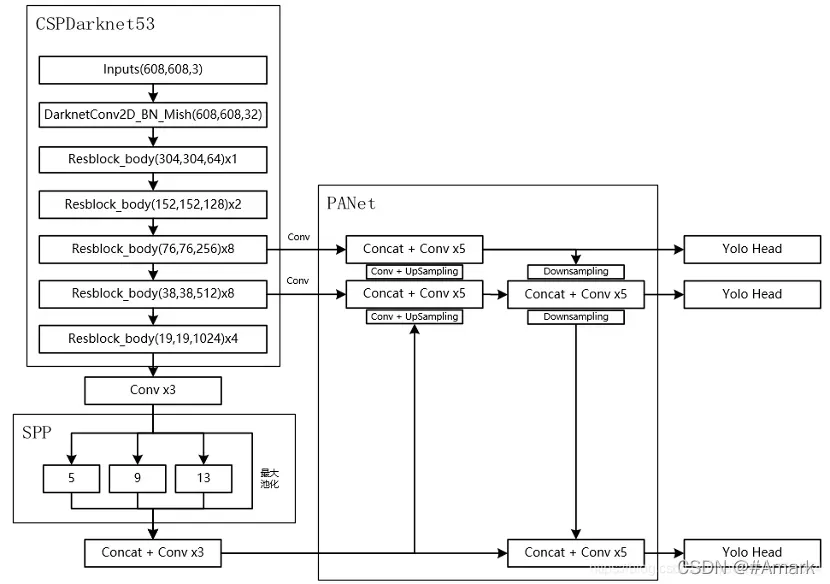
图五:YOLOvv4输入图片大小为608*608时的网络结构。
如图所示,YOLOv4的网络大致可以分为CSPDarknet53,SPP,PANet,和最终输出结果的YoLo Head四个部分组成。可以看到YOLOv4的最终输出是由三个YoLo Head的输出组成,它们分别在网络结构的不同地方采样,采样倍数分别为,8倍,16倍,32倍。靠前的采样感受野较小,更加倾向于检测小目标,靠后的采样感受野大,能更好的检测大目标。三者的联合便使得此算法对各种大小的目标都能很好的进行检测。
三、实验过程
3.1推理阶段
您需要指定运行时参数,设置要检测的类数、权重文件的位置、图像的位置以及检测结果图像的大小。如:
D:/cv/yolo4/pytorch-YOLOv4/models.py 80 weight/yolov4.pth data/dog.jpg 608 608需要指定表示检测dog.jpg这张图片中包含coco数据集中的80个类别中的目标。
3.1.1读取并加载权重文件
model = Yolov4(yolov4weight=None,n_classes=n_classes, inference=True)
#加载模型参数
pretrained_dict = torch.load(weightfile, map_location=torch.device('cuda' if use_cuda else 'cpu'))
model.load_state_dict(pretrained_dict)
if use_cuda:
model.cuda()3.1.2读取图片并将输入的图片按照要求的大小进行调整
img = cv2.imread(imgfile)
sizedimg = cv2.resize(img, (width, height))
sizedimg = cv2.cvtColor(sizedimg, cv2.COLOR_BGR2RGB)3.1.3根据模型输出的预测框信息进行 NMS 后绘制
NMS即非极大值抑制,抑制不是极大值的元素。通过NMS去除重复的预测框。
非极大值抑制的方法是:先假设有6个矩形框,根据分类器的类别分类概率做排序,假设从小到大属于某一类的概率分别为A、B、C、D、E、F。
(1)从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值;
(2)假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3)从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
以此类推,找到所有剩余的矩形。
NMS的代码如下:
def nms_cpu(boxes, confs, nms_thresh=0.5, min_mode=False):
# print(boxes.shape)
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
areas = (x2 - x1) * (y2 - y1)
order = confs.argsort()[::-1]
keep = []
while order.size > 0:
idx_self = order[0]
idx_other = order[1:]
keep.append(idx_self)
xx1 = np.maximum(x1[idx_self], x1[idx_other])
yy1 = np.maximum(y1[idx_self], y1[idx_other])
xx2 = np.minimum(x2[idx_self], x2[idx_other])
yy2 = np.minimum(y2[idx_self], y2[idx_other])
w = np.maximum(0.0, xx2 - xx1)
h = np.maximum(0.0, yy2 - yy1)
inter = w * h
if min_mode:
over = inter / np.minimum(areas[order[0]], areas[order[1:]])
else:
over = inter / (areas[order[0]] + areas[order[1:]] - inter)
inds = np.where(over <= nms_thresh)[0]
order = order[inds + 1]
return np.array(keep)3.1.4代码
"""
Run a rest API exposing the yolov5s object detection model
"""
import argparse
import io
import torch
from PIL import Image
from flask import Flask, request
app = Flask(__name__)
DETECTION_URL = "/v1/object-detection/yolov5s"
@app.route(DETECTION_URL, methods=["POST"])
def predict():
if not request.method == "POST":
return
if request.files.get("image"):
image_file = request.files["image"]
image_bytes = image_file.read()
img = Image.open(io.BytesIO(image_bytes))
results = model(img, size=640) # reduce size=320 for faster inference
return results.pandas().xyxy[0].to_json(orient="records")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Flask API exposing YOLOv5 model")
parser.add_argument("--port", default=5000, type=int, help="port number")
args = parser.parse_args()
# model = torch.hub.load("ultralytics/yolov5", "yolov5s", force_reload=True) # force_reload to recache
model=torch.hub.load('../../', 'custom', path='./best.pt', source='local')
app.run(host="0.0.0.0", port=args.port) # debug=True causes Restarting with stat
3.2训练阶段
需要指定学习率,预训练模型参数,类别数量,训练数据。其他通用设定都已在cfg文件中指定。如输入:
D:/cv/yolo4/pytorch-YOLOv4/train.py -l 0.001 -pretrained weight/yolov4.pth -classes 3 -dir D:/cv/yolo4/pytorch-YOLOv4/data1表示训练了一个二分类网络模型,这个实验就是检测有没有。
3.2.1 网络结构
按照图示搭建网络。
因为每次卷积后都要进行Batch Normalization操作,所以将其抽象出来为一个模块。以及每个残差块的构建。每个残差块都为3层,将输入进行两次卷积,第三层为输入和两次卷积后结果的和。
卷积BN模块代码
class Conv_Bn_Activation(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, activation, bn=True, bias=False):
super().__init__()
# N = (W − F + 2P )/S+1步长为1时图片卷积后的尺寸不变
#步长为2时图片卷积后的尺寸减半
pad = (kernel_size - 1) // 2
self.conv = nn.ModuleList()
if bias:
self.conv.append(nn.Conv2d(in_channels, out_channels, kernel_size, stride, pad))
else:
self.conv.append(nn.Conv2d(in_channels, out_channels, kernel_size, stride, pad, bias=False))
if bn:
self.conv.append(nn.BatchNorm2d(out_channels))
if activation == "mish":
self.conv.append(Mish())
elif activation == "relu":
self.conv.append(nn.ReLU(inplace=True))
elif activation == "leaky":
self.conv.append(nn.LeakyReLU(0.1, inplace=True))
elif activation == "linear":
pass
else:
print("activate error !!! {} {} {}".format(sys._getframe().f_code.co_filename,
sys._getframe().f_code.co_name, sys._getframe().f_lineno))
def forward(self, x):
for l in self.conv:
x = l(x)
return x将真实框和预选框之间进行IoU计算,将真实框和预选框对应起来,每个真实框与和其Iou值最大的预选框所对应,得到target数据,与预测数据output之间进行loss计算。
loss_xy += F.binary_cross_entropy(input=output[..., :2], target=target[..., :2],weight=tgt_scale * tgt_scale, reduction='sum')
loss_wh += F.mse_loss(input=output[..., 2:4], target=target[..., 2:4], reduction='sum') / 2
loss_obj += F.binary_cross_entropy(input=output[..., 4], target=target[..., 4], reduction='sum')
loss_cls += F.binary_cross_entropy(input=output[..., 5:], target=target[..., 5:], reduction='sum')
loss = loss_xy + loss_wh + loss_obj + loss_cls3.2.2迁移学习模型加载
由于目标检测coco数据集数量还是较少,与用于分类的ImageNet数量相比差距很多。于是先在ImageNet上训练模型的前一段,作为目标检测的初始参数,从而达到迁移学习。本次实验下载的是论文中作者已经预训练好的权重模型darknet.pth。
代码:
_model = nn.Sequential(self.down1, self.down2, self.down3, self.down4, self.down5, self.neek)
pretrained_dict = torch.load(yolov4weight)
model_dict = _model.state_dict()
# 过滤掉不需要的参数
pretrained_dict = {k1: v for (k, v), k1 in zip(pretrained_dict.items(), model_dict)}
model_dict.update(pretrained_dict)
_model.load_state_dict(model_dict)4、结果分析
4.1:推理阶段效果
输入图像进行测试
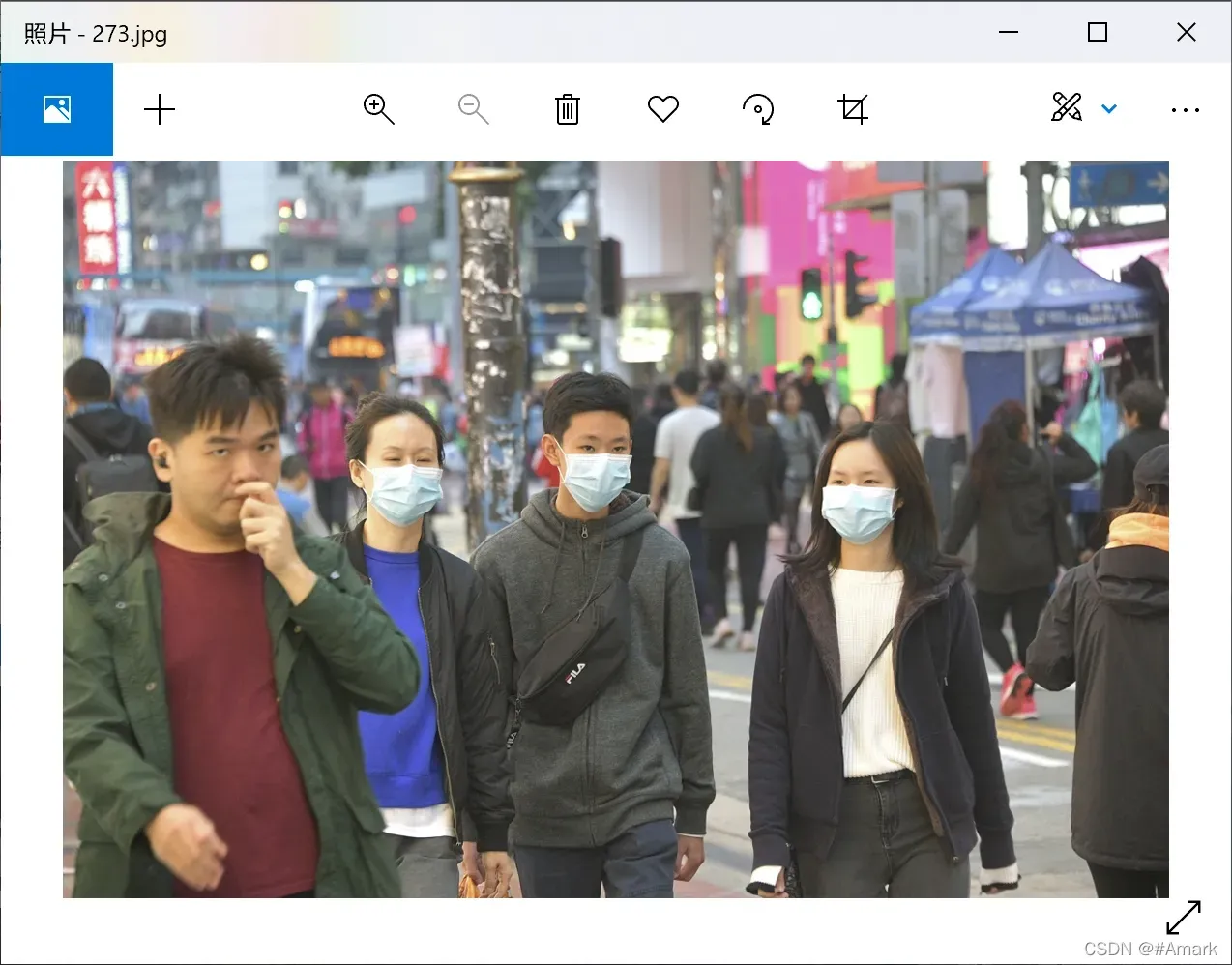

图 7:推理 左图是输入图,右图是输出图。
4.2训练阶段效果
输入命令
tensorboard.py --logdir=log可视化查看loss的下降效果
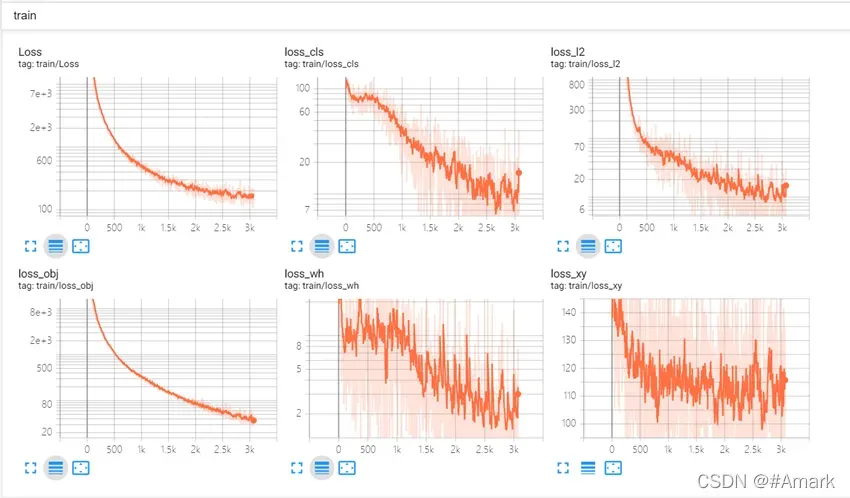 图 9:训练损失函数
图 9:训练损失函数
加载训练好的模型并输入图像进行推理测试
D:/cv/yolo4/pytorch-YOLOv4/models.py 3 checkpoints/Yolov4_epoch200.pth data/test.jpg 608 608五、结论
通过本次复现实现,更加入深入的了解了一阶段目标检测,特别是YOLO系列的一步步改进。YOLOv4论文中也做了大量的实验,通过此论文了解了很多实验技巧,网路的残差连接以融合特征,学习率的动态改变,新的激活函数等通用的技巧,还学习到YOLOv4中的loss的一步步修改变形和为什么要如此变化。理解预选框的作用和loss的设计,对将此通用目标检测算法用到特定任务上有了一定的经验。了解使用了Netron、tensorboard等可视化图形工具,使得网路模型可视化,理解起来更加清晰(完整的网路模型图见附件)。训练过程可视化,可以清晰的看见loss的变化,便于更好的调整。
6. 参考文献
1.Bochkovskiy, A., Wang, C.-Y., Liao, H.-Y.M., 2020。YOLOv4: Optimal Speed and Accuracy of Object Detection。CoRR abs/2004.10934.
2.Huang, Z., Wang, J., 2019。DC-SPP-YOLO: Dense Connection and Spatial Pyramid Pooling Based YOLO for Object Detection。CoRR abs/1903.08589.
3.Lin, T.-Y., Dollár, P., Girshick, R.B., He, K., Hariharan, B., Belongie, S.J., 2017。Feature Pyramid Networks for Object Detection., in: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017。pp。936–944.https://doi.org/10.1109/CVPR.2017.106
4.Lin, T.-Y., Goyal, P., Girshick, R., He, K., Dollar, P., 2020。Focal Loss for Dense Object Detection。IEEE Trans。Pattern Anal。Mach。Intell。42, 318–327.Focal Loss for Dense Object Detection | IEEE Journals & Magazine | IEEE Xplore
5.Liu, S., Qi, L., Qin, H., Shi, J., Jia, J., 2018。Path Aggregation Network for Instance Segmentation., in: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018。pp。8759–8768.
6.Misra, D., 2020。Mish: A Self Regularized Non-Monotonic Activation Function., in: 31st British Machine Vision Conference 2020, BMVC 2020, Virtual Event, UK, September 7-10, 2020.
7.Zheng, Z., Wang, P., Liu, W., Li, J., Ye, R., Ren, D., 2020。Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression., in: The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020。pp。12993–13000.
文章出处登录后可见!