和分类算法一样,都是用于样本的类别划分的
区别:
分类算法是有监督的算法,也就是算法找到是特征属性x和类别属性y之间的关系,基于这样的关系,
对样本数据x做类别的划分预测
聚类算法是无监督的算法,也就是说训练数据中只有特征属性x,没有类别属性y,模型是通过找x的
特征信息,将数据划分为不同的类别,基于这样的划分,对于样本数据x认为和那个类别最接近来产生预
测。
##注意:如果特征工程做的不是很好,会导致一个样本属于两个以上的分类(因为特征上面有很高的相
似性)
备注:**分类算法的效果要比聚类算法的好,如果可以的情况下,一般选择分类算法
##聚类算法的用法:没有标签值,人工赋值又比较麻烦。这时候可以使用聚类算法做一次大的聚类,看下
具体属于哪个标签(一般做前期处理)
常用的聚类算法:KMeans、GMM高斯混合聚类、LDA
聚类算法的一般用法:作为前期的数据处理过程的一种数据标注的方01_聚类算法概述

 02_聚类算法中相似度度量方式讲解
02_聚类算法中相似度度量方式讲解
02:05-02:24

注意:
1、用的比较多的是曼哈顿距离(又称城市距离)


03_KMeans算法原理讲解


解析:
1、两个类别选择两个中心点
2、每个样本与中心点的距离的大小决定属于哪个类别
3、通过均值更新中心点
4、循环执行上述步骤,直至中止
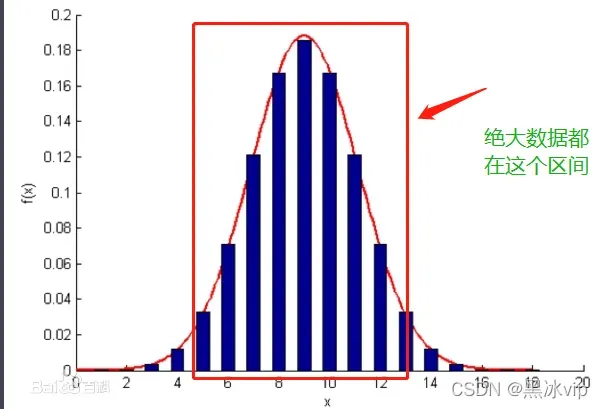
中心点特性:绝大数数据都是在中心点附近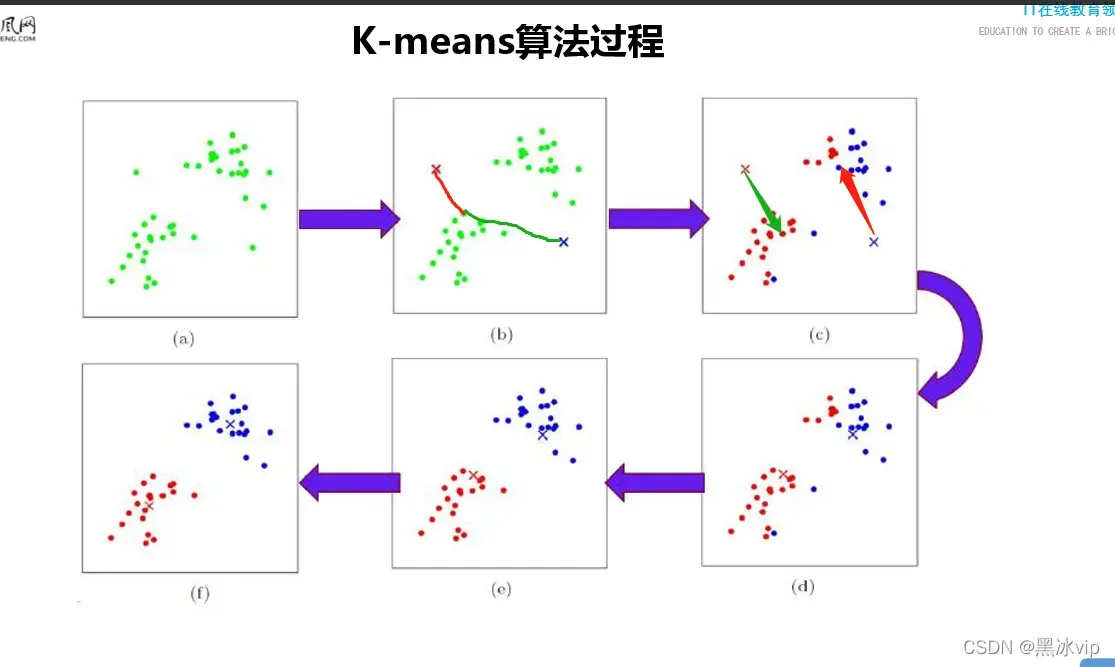



第一个问题:
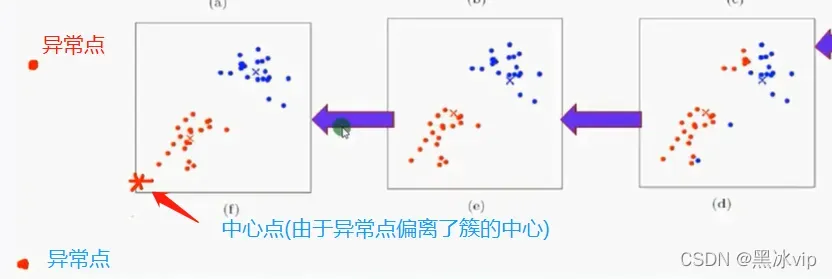
中心点一旦偏离的簇的中心,原来本属于改簇的点(由于欧式距离较大),错分到别的簇中导致不准确
这时候用中值当簇的中心值比均值效果要好(建议使用K中值聚类,但是一般情况下用的比较少)第二个问题:
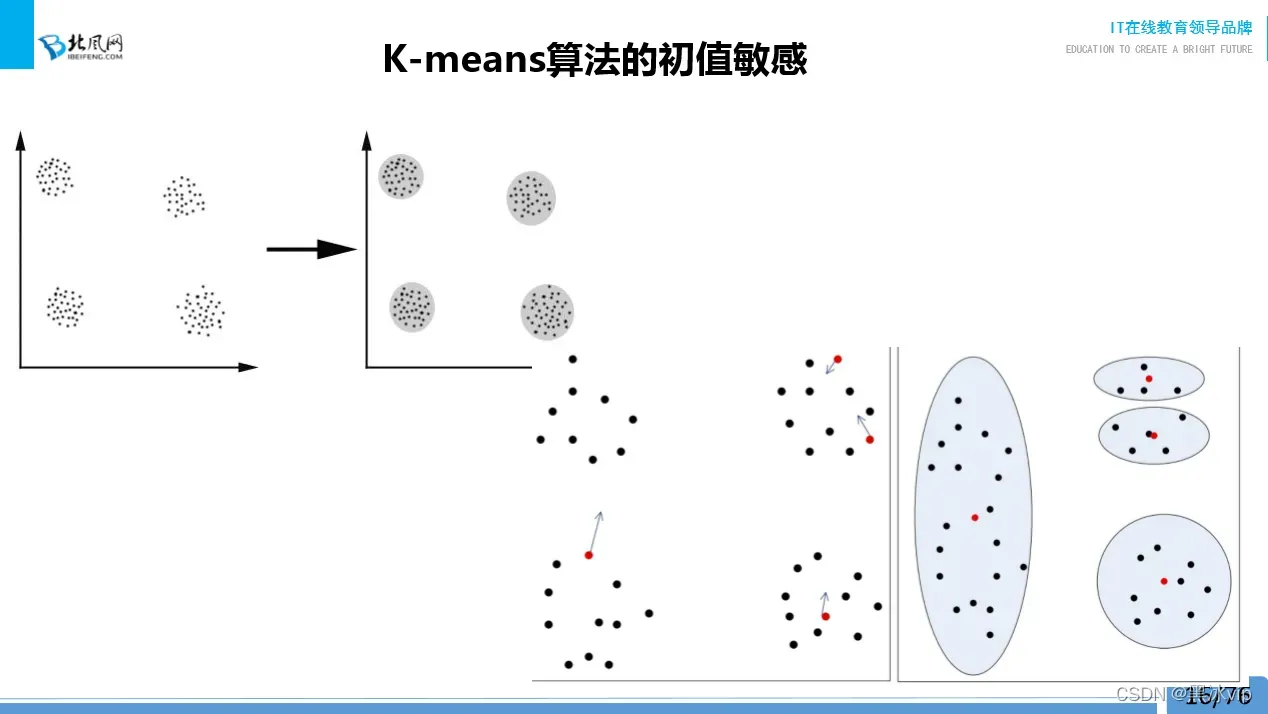
解析:上图如果初始值给的不准确 ,这时候分的簇也不准确
初始值敏感问题也是后面要解决的问题
如果两个中心点在同个簇中,旁边的簇离得很远,会导致这个簇一直无法收敛,长期处于分为两个
簇的状态
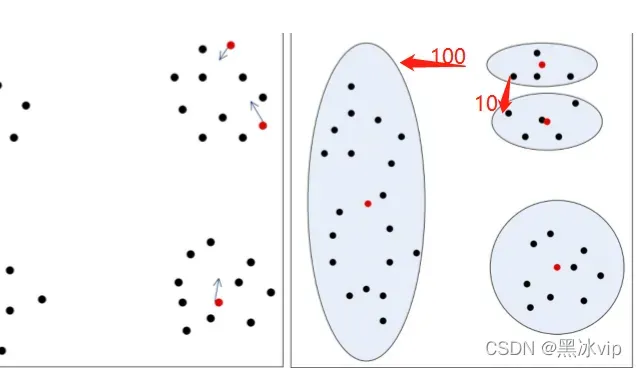
如果距离不是100是10,反复迭代。中心点会向左边边更新最终往正确的方向更新。
但是如果一开始一个簇就有两个以上中心点且其他簇较远就无法正确更新。
04_案例代码:KMeans案例代码实现讲解
03:00- 03:32
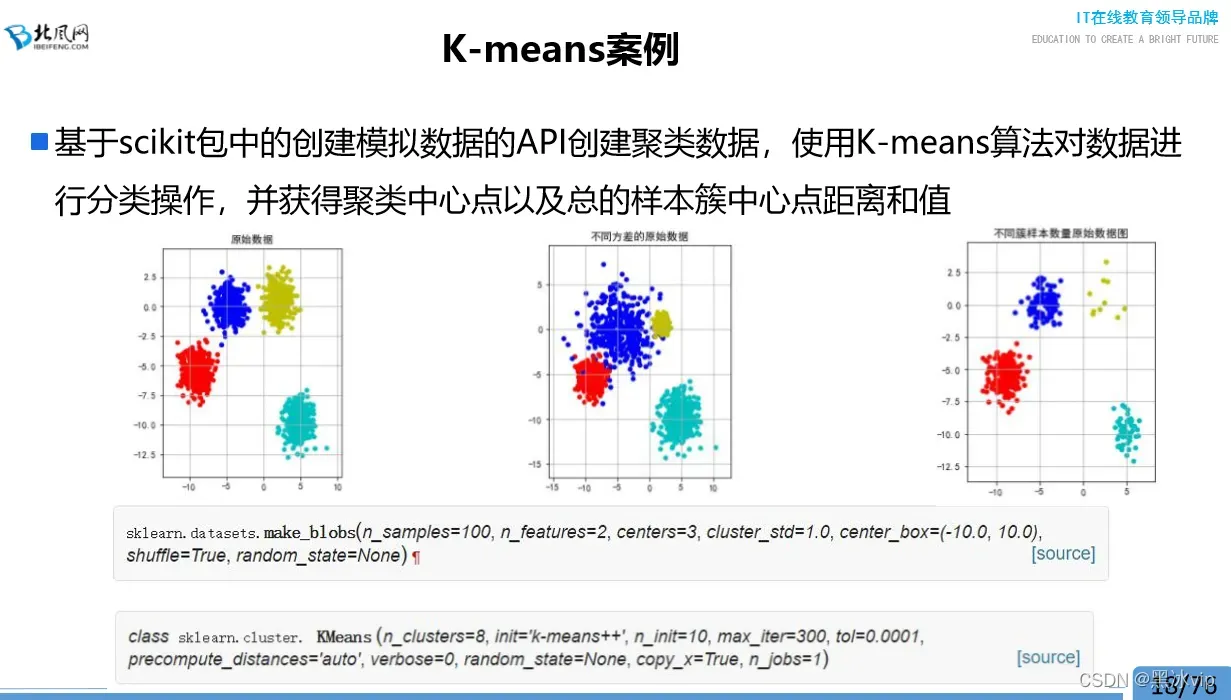
make_blobs:创建高斯分布的数据集
J( k+1)-J( k) < tol 的时候就是停止收敛( 因为再迭代下去用处不大)
05_KMeans初值敏感问题解决方案讲解一(二分KMeans、KMeans++等)
 分析:弱化初始质心:通过中心点减少最终结果的弱化(但只是弱化,初始质心的问题仍然存在)
分析:弱化初始质心:通过中心点减少最终结果的弱化(但只是弱化,初始质心的问题仍然存在)
wj是权重,默认为1(不需要考虑)
xj是样本,aj是中心点( SSE就是第j个簇所有样本点到中心点的平方和)
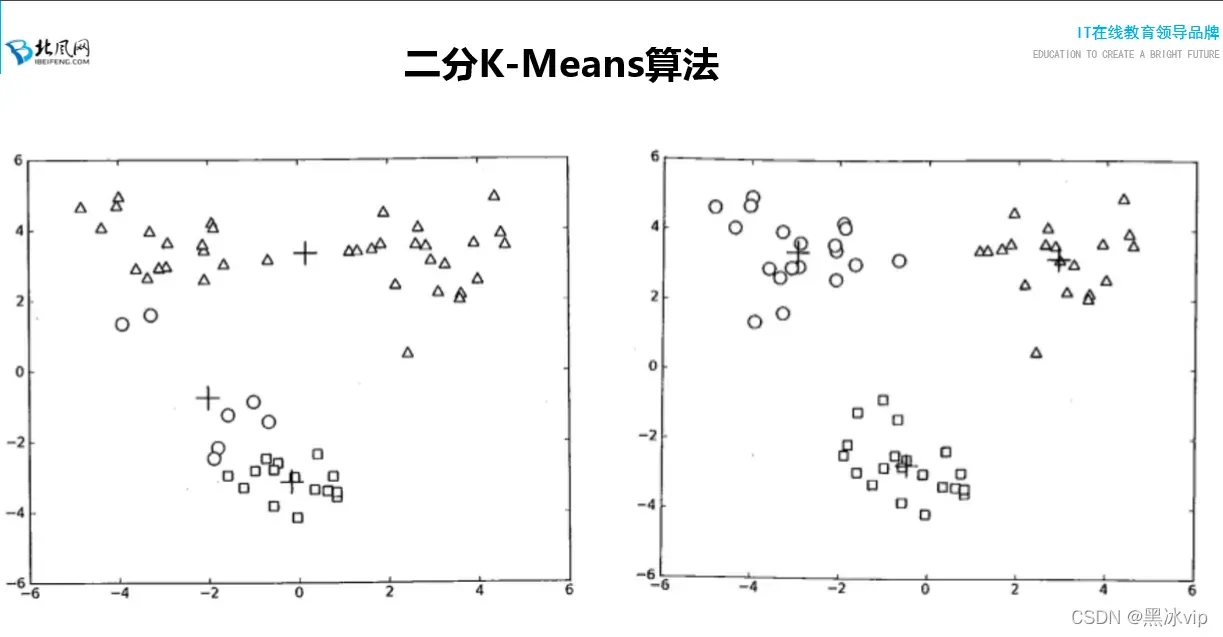
03:38-03:41 讲解 二分k-means如何划分
注意:优先 分2,因为中间间隔比较大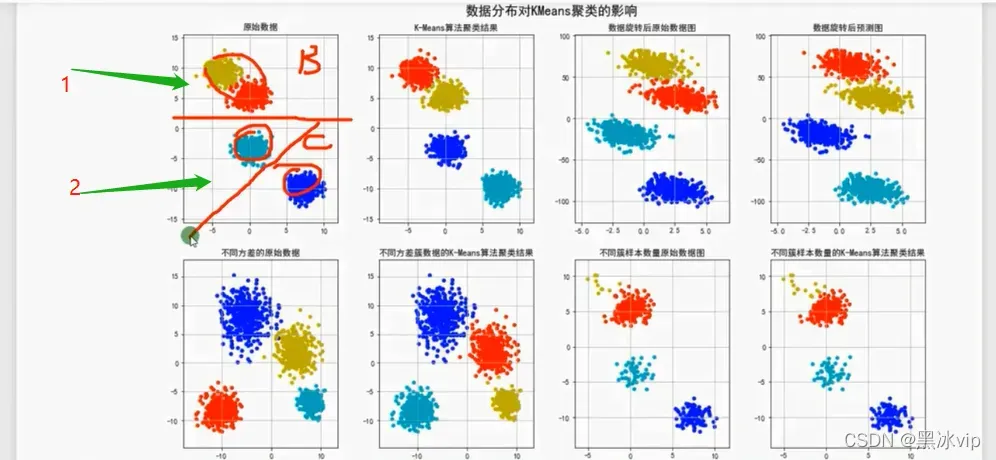
注意:到中心点的距离平方和越大,点越开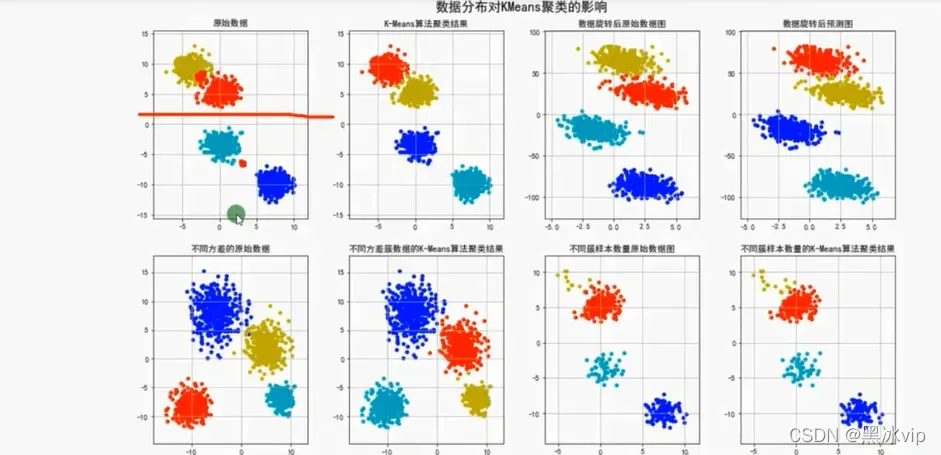
**03:44:33 – 03:47

解析:
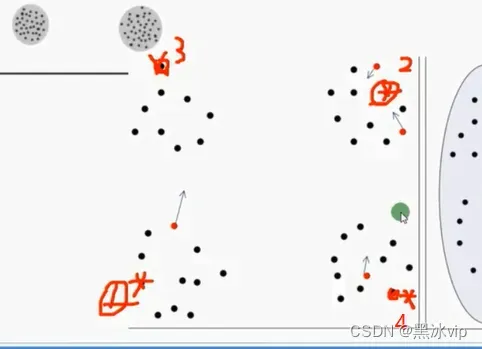
给定k=4
随机找到一个中心点1,遍历所有样本找到较远的中心点2
遍历所有样本找到中心点3(到1+2距离最远)
遍历所有样本找到中心点4(到1+2+3距离最远)
找到所有中心点
注意:1、这时候找出的中心点就比较分散了,很难出现一个簇出现两个中心点,避免错误拆分
2、采用线性概率选择下一个中心点( 避免选择异常点选做中心点,导致分簇不准确)
比如离1较远的点有【1,2,3,4,6】 这些点有可能是一个簇的点,有可能是异常点
随机取一个,1/6就是线性概率
3、缺点:有序性:2依赖1,3依赖1,2,4依赖1,2,3;所以在衍生方面效果不是特别好
工作中一般使用:k-means++和采用初始化多套节点构造不同的分类规则,然后选择最优的规则** 03:54:21-04:01:29 k-mean++ 算法api(官网)

文章出处登录后可见!
已经登录?立即刷新