在正则表达式中,[...]代表1个字符,不管里面有多少字符,最终这个东西的结果都是1个字符。
对于表达式[^a]表达的匹配除了a之外的字符,并且是1个字符。
需要注意的是,有些特殊字符是不会被匹配的。
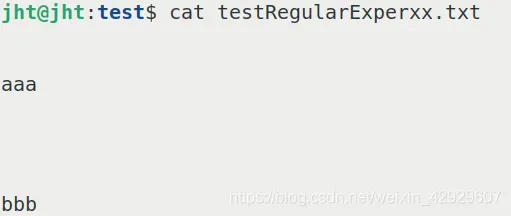
我们看一个示例,对于txt文件testRegularExperxx.txt
aaa
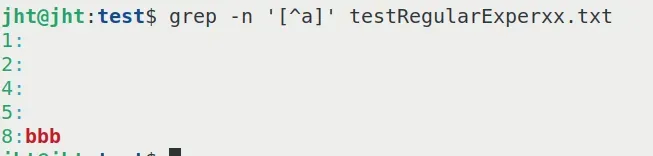
bbb对于该文件,输入命令grep -n '[^a]' testRegularExperxx.txt
得到的结果是:

你会发现,对于看起来的“空行”的处理似乎是不一样的,为什么呢?
仔细看看文件,虽然都是空行,但是,有的是空格,有的是 \t,有的是 \n。它们看起来都是空的,但是处理方式不一样。
这里,对于[^]a除了a之外的1个字符,能够识别空格和 \t,而忽略掉 \t。
我们换一个新的文件,看看文件的内容


选中的时候颜色不同,也可以看出端倪来。
HexCharDescriptionEscape Character09HTHorizontal Tab\t0aLFLine Feed\n20spaceSpace
所以,你就知道了[...]的特殊的地方了。
那么如何识别空行呢?也就是仅包含\n的行。
使用^$识别!这也是比较特殊的点了。

小结 [...]不能识别\n^$可以识别\n,但是注意,是识别一行仅有\n的空行
另外,正则表达式的不同规则,是可以进行花样排列组合,从而识别复杂单词!进一步也可以作为词法分析的实用工具。
到此这篇关于正则表达式特别需要注意的点:“空“字符的匹配的文章就介绍到这了,更多相关正则表达式匹配空白内容请搜索aitechtogether.com以前的文章或继续浏览下面的相关文章希望大家以后多多支持aitechtogether.com!