
前面,我们就正则表达式一些常用的基本方法做了详细的介绍,本篇会讲解一些拓展性的知识,主要的就是常见的ERE模式符号以及shell脚本中常见的一些正则表达式例子。
一、正则表达式常用符号
本章示例着重于在gawk程序脚本中的较常见的ERE模式符号。
1.1 问号【?】
问号类似于星号,不过有点细微的不同。问号表明前面的字符可以出现 0 次或 1 次,但只限于 此。它不会匹配多次出现的字符。 示例展示:

脚本解说:
如果字符 e 并未在文本中出现,或者它只在文本中出现了 1 次,那么模式会匹配。
和星号一样,可以将问号和字符组一起使用。

脚本解说:
如果字符组中的字符出现了 0 次或 1 次,模式匹配就成立。但如果两个字符都出现了,或者其中一个字符出现了2 次,模式匹配就不成立。
1.2 加号【+】
加号是类似于星号的另一个模式符号,但跟问号也有不同。加号表明前面的字符可以出现 1次或多次,但必须至少出现1 次。如果该字符没有出现,那么模式就不会匹配。

示例解说:
如果字符 e 没有出现,模式匹配就不成立。加号同样适用于字符组,与星号和问号的使用方式相同。
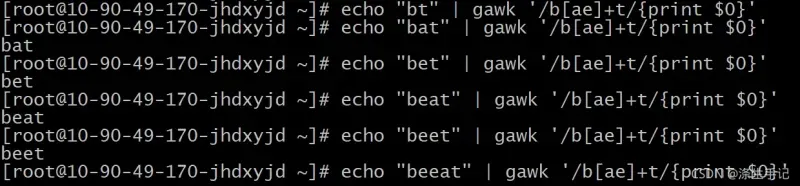
脚本解读:
如果字符组中定义的任一字符出现了,文本就会匹配指定的模式。
1.3 花括号{}
ERE 中的花括号允许为可重复的正则表达式指定一个上限。这通常称为 间隔 ( interval )。 可以用两种格式来指定区间。
- m:正则表达式准确出现m次。
- m, n:正则表达式至少出现m次,至多n次。
这个特性可以精确调整字符或字符集在模式中具体出现的次数。
重点说明:
默认情况下, gawk 程序不会识别正则表达式间隔。必须指定 gawk 程序的 –re- interval 命令行选项才能识别正则表达式间隔。
示例:

示例解读:
通过指定间隔为 1 ,限定了该字符在匹配模式的字符串中出现的次数。如果该字符出现多次, 模式匹配就不成立。
同样也可以指定上限和下限

示例解读:
字符 e 可以出现 1 次或 2 次,这样模式就能匹配;否则,模式无法匹配。
下面是字符组的示例:

示例解读:
如果字母 a 或 e 在文本模式中只出现了 1~2 次,则正则表达式模式匹配;否则,模式匹配失败。
1.4 管道符号【|】
管道符号允许在检查数据流时,用逻辑 OR 方式指定正则表达式引擎要用的两个或多个模式。如果任何一个模式匹配了数据流文本,文本就通过测试。如果没有模式匹配,则数据流文本匹配失败。
使用格式:
expr1 |expr2|…
示例:

示例解读:
这个例子会在数据流中查找正则表达式 cat 或 dog 。正则表达式和管道符号之间不能有空格, 否则它们也会被认为是正则表达式模式的一部分。
管道符号两侧的正则表达式可以采用任何正则表达式模式(包括字符组)来定义文本。看下面示例:

示例解读:
这个例子会匹配数据流文本中的 cat 、 hat 或 dog 。
1.5 小括号()
正则表达式模式也可以用圆括号进行分组。当将正则表达式模式分组时,该组会被视为一个标准字符。可以像对普通字符一样给该组使用特殊字符。
示例:

示例解读:
结尾的 urday 分组以及问号,使得模式能够匹配完整的 Saturday 或缩写 Sat 。
将分组和管道符号一起使用来创建可能的模式匹配组是很常见的做法。如下示例:
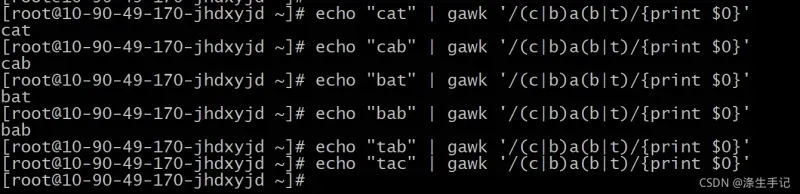
示例解读:
模式 (c|b)a(b|t) 会匹配第一组中字母的任意组合以及第二组中字母的任意组合。
二、正则表达式实战示例
示例1:
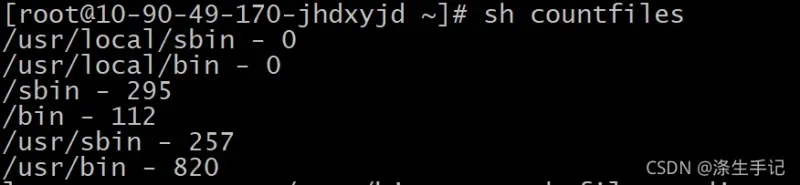
下面会有一个脚本,功能是对PATH环境变量中定义的目录里的可执行文件进行计数。
脚本内容如下:
#!/bin/bash
# count number of files in your PATH
mypath=$(echo $PATH | sed 's/:/ /g') #用空格来替换冒号,分割路径
count=0
for directory in $mypath
do
check=$(ls $directory)
for item in $check
do
count=$[ $count + 1 ]
done
echo "$directory - $count"
count=0
done执行结果:
示例2:
正则表达式解析邮件地址
邮件地址的基本格式为:username@hostname
username值可用字母数字字符以及以下特殊字符:(点号、单破折线、 加号、 下划线)
在有效的邮件用户名中,这些字符可能以任意组合形式出现。邮件地址的hostname部分由一个或多个域名和一个服务器名组成。服务器名和域名也必须遵照严格的命名规则,只允许字母数字字符以及以下特殊字符:(点号、下划线)
服务器名和域名都用点分隔,先指定服务器名,紧接着指定子域名,最后是后面不带点号的
顶级域名。
顶级域名的数量在过去十分有限,正则表达式模式编写者会尝试将它们都加到验证模式中。
然而遗憾的是,随着互联网的发展,可用的顶级域名也增多了。这种方法已经不再可行。
从左侧开始构建这个正则表达式模式。
过滤用户名中表达式模式。
^([a-zA-Z0-9_\-\.\+]+)@
这个分组指定了用户名中允许的字符,加号表明必须有至少一个字符。下一个字符很明显是@。
hostname模式使用同样的方法来匹配服务器名和子域名:
([a-zA-Z0-9_\-\.]+)
顶级域名用的正则表达式模式:
\.([a-zA-Z]{2,5})$
整体组合模式:
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$
封装到脚本中:
cat isemail.sh
#!/bin/bash
# script to filter out bad phone numbers
awk --re-interval '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})/{print $0}'注意:在awk程序中使用正则表达式间隔时,必须使用–re-interval命令行选项。
示例测试脚本:
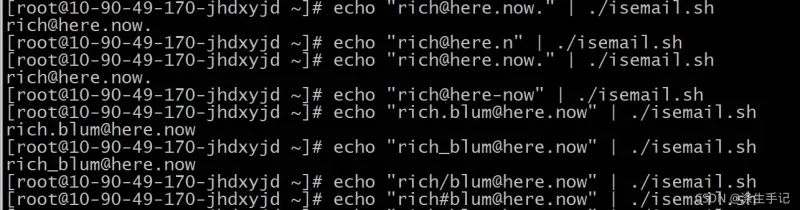
示例解读:
符合规则的邮件名会打印在屏幕,不符合的会被过滤掉,不会有内容输出。
到此这篇关于十分钟上手正则表达式 下篇的文章就介绍到这了,更多相关正则表达式 入门内容请搜索aitechtogether.com以前的文章或继续浏览下面的相关文章希望大家以后多多支持aitechtogether.com!