论文名称:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
论文下载:https://arxiv.org/abs/1905.11946
论文年份:2019
论文被引:6433(2022/05/11)
论文代码:https://github.com/lukemelas/EfficientNet-PyTorch/blob/2eb7a7d264344ddf15d0a06ee99b0dca524c6a07/efficientnet_pytorch/model.py#L143
Abstract
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
To go even further, we use neural architecture search to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. In particular, our EfficientNet-B7 achieves state-of-the-art 84.3% top-1 accuracy on ImageNet, while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet. Our EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters.
卷积神经网络 (ConvNets) 通常在固定资源预算下开发,然后在有更多资源可用时进行扩展以获得更好的准确性。在本文中,我们系统地研究了模型缩放(model scaling),并确定仔细平衡网络深度、宽度和分辨率可以带来更好的性能。基于这一观察,我们提出了一种新的缩放方法,该方法使用简单但高效的复合系数统一缩放深度/宽度/分辨率的所有维度。我们证明了这种方法在扩展 MobileNets 和 ResNet 方面的有效性。
更进一步,我们使用神经架构搜索来设计一个新的基线网络并将其放大以获得一系列模型,称为 EfficientNets,它们比以前的 ConvNets 实现了更好的准确性和效率。特别是,我们的 EfficientNet-B7 在 ImageNet 上实现了最先进的 84.3% 的 top-1 准确度,同时比现有最好的 ConvNet 小 8.4 倍,推理速度快 6.1 倍。我们的 EfficientNets 在 CIFAR-100 (91.7%)、Flowers (98.8%) 和其他 3 个迁移学习数据集上也能很好地迁移并实现最先进的准确度,参数少一个数量级。
1. Introduction
扩大 ConvNets 被广泛用于实现更好的准确性。例如,ResNet (He et al., 2016) 可以通过使用更多层从 ResNet-18 扩展到 ResNet-200;最近,GPipe (Huang et al., 2018) 通过将基线模型扩大了四倍,实现了 84.3% 的 ImageNet top-1 准确率。然而,扩大 ConvNets 的过程从未被很好地理解,目前有很多方法可以做到这一点。最常见的方法是通过深度 (He et al., 2016) 或宽度 (Zagoruyko & Komodakis, 2016) 来扩展 ConvNet。另一种不太常见但越来越流行的方法是通过图像分辨率放大模型(Huang et al., 2018)。在以前的工作中,通常只缩放三个维度中的一个——深度、宽度和图像大小。尽管可以任意缩放两个或三个维度,但任意缩放需要繁琐的手动调整,并且仍然经常产生次优的精度和效率。
在本文中,我们想要研究和重新思考扩大 ConvNets 的过程。特别是,我们研究了中心问题:是否有一种原则性的方法来扩大卷积网络,从而实现更好的准确性和效率?我们的实证研究表明,平衡网络宽度/深度/分辨率的所有维度至关重要,令人惊讶的是,这种平衡可以通过简单地以恒定比例缩放它们中的每一个来实现。基于这一观察,我们提出了一种简单而有效的复合缩放方法。与任意缩放这些因素的传统做法不同,我们的方法使用一组固定的缩放系数统一缩放网络宽度、深度和分辨率。例如,如果想使用 2N 倍的计算资源,那么我们可以简单地将网络深度增加 αN,宽度增加 βN,图像大小增加 γN,其中 α、β、γ 是由小网格搜索确定的常数系数在原来的小模型上。图 2 说明了我们的缩放方法与传统方法之间的区别。
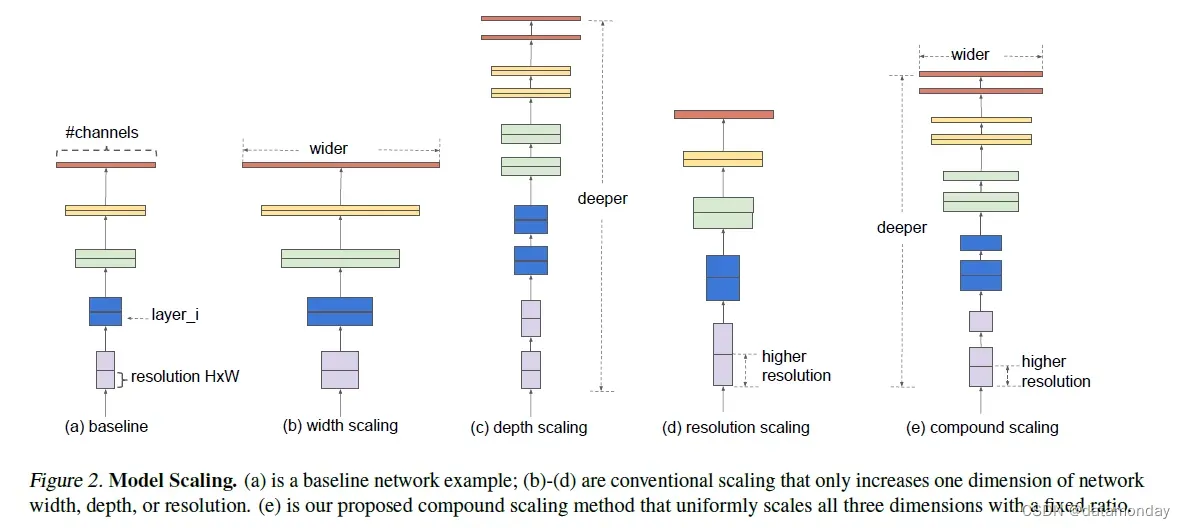
直观地说,复合缩放方法是有意义的,因为如果输入图像更大,那么网络需要更多的层来增加感受野,需要更多的通道来在更大的图像上捕获更细粒度的模式。事实上,之前的理论(Raghu et al., 2017; Lu et al., 2018)和实证结果(Zagoruyko & Komodakis, 2016)都表明网络宽度和深度之间存在一定的关系,但据我们所知,我们是第一个根据经验量化网络宽度、深度和分辨率这三个维度之间关系的人。
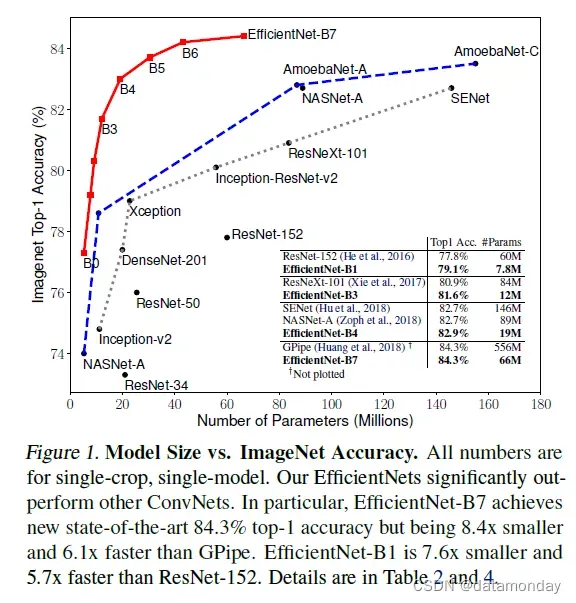
我们证明了我们的缩放方法在现有的 MobileNets (Howard et al., 2017; Sandler et al., 2018) 和 ResNet (He et al., 2016) 上运行良好。值得注意的是,模型缩放的有效性在很大程度上取决于基线网络;更进一步,我们使用神经架构搜索 (Zoph & Le, 2017; Tan et al., 2019) 来开发一个新的基线网络,并将其放大以获得一系列模型,称为 EfficientNets。图 1 总结了 ImageNet 的性能,我们的 EfficientNets 明显优于其他 ConvNets。特别是,我们的 EfficientNet-B7 超过了现有的最佳 GPipe 精度(Huang et al.,,2018 年),但使用的参数减少了 8.4 倍,推理速度提高了 6.1 倍。与广泛使用的 ResNet-50 (He et al., 2016) 相比,我们的 EfficientNet-B4 将 top-1 准确率从 76.3% 提高到 83.0% (+6.7%),并具有相似的 FLOPS。除了 ImageNet,EfficientNets 还可以在 8 个广泛使用的数据集中的 5 个上实现良好的传输并实现最先进的准确度,同时比现有的 ConvNets 减少高达 21 倍的参数。
2. Related Work
ConvNet Accuracy:自从 AlexNet(Krizhevsky et al., 2012)赢得 2012 年 ImageNet 比赛以来,ConvNets 变得越来越准确:而 2014 年 ImageNet 冠军 GoogleNet(Szegedy et al.,,2015 年)实现了 74.8% 的 top-1 准确率2017 年 ImageNet 获胜者 SENet(Hu et al., 2018)使用大约 6.8M 参数,在 1.45M 参数下实现了 82.7% 的 top-1 准确率。最近,GPipe (Huang et al., 2018) 使用 557M 参数进一步将最先进的 ImageNet top-1 验证准确率推至 84.3%:它太大了,只能使用专门的管道并行库进行训练通过划分网络并将每个部分分散到不同的加速器。虽然这些模型主要是为 ImageNet 设计的,但最近的研究表明,更好的 ImageNet 模型在各种迁移学习数据集(Kornblith et al., 2019)以及其他计算机视觉任务(例如目标检测(He et al., 2016; Tanet al., 2019)中也表现得更好。尽管更高的精度对许多应用程序来说至关重要,但我们已经达到了硬件内存限制,因此进一步提高精度需要更高的效率。
ConvNet Efficiency:Deep ConvNets 经常被过度参数化。模型压缩(Han et al., 2016; He et al., 2018; Yang et al., 2018)是通过以精度换取效率来减小模型大小的常用方法。随着手机变得无处不在,手工制作高效的移动尺寸卷积网络也很常见,例如
-
SqueezeNets (Iandola et al., 2016; Gholami et al., 2018)
-
MobileNets (Howard et al., 2017; Sandler et al., 2018)
-
ShuffleNets (Zhang et al., 2018; Ma et al., 2018)
最近,神经架构搜索在设计高效的移动尺寸卷积网络中变得越来越流行(Tan et al., 2019; Cai et al., 2019),并且通过广泛调整网络宽度、深度实现了比手工制作的移动卷积网络更好的效率,卷积核类型和大小。然而,目前尚不清楚如何将这些技术应用于具有更大设计空间和更昂贵调整成本的大型模型。在本文中,我们旨在研究超越最先进精度的超大型 ConvNet 的模型效率。为了实现这一目标,我们求助于模型缩放。
模型缩放:有很多方法可以针对不同的资源限制来缩放 ConvNet:
-
ResNet (He et al., 2016) 可以通过调整网络深度 (#layers) 来缩小 (ResNet-18) 或放大 (ResNet-200)
-
WideResNet (Zagoruyko & Komodakis, 2016) 和 MobileNets (Howard et al., 2017) 可以通过网络宽度 (#channels) 进行缩放
众所周知,更大的输入图像大小将有助于提高 FLOPS 开销的准确性。尽管先前的研究(Raghu et al., 2017; Lin & Jegelka, 2018; Sharir & Shashua, 2018; Lu et al., 2018)表明网络深度和宽度对于 ConvNets 的表达能力都很重要,但它仍然是关于如何有效扩展卷积网络以实现更好的效率和准确性的开放性问题。我们的工作系统地和经验地研究了网络宽度、深度和分辨率的所有三个维度的 ConvNet 缩放。
3. Compound Model Scaling
在本节中,我们将制定缩放问题,研究不同的方法,并提出我们新的缩放方法。
3.1. Problem Formulation
一个 ConvNet 层 可以定义为一个函数:
,其中
是算子,
是输出张量,
是输入张量,张量形状为
(为了简单起见,省略了批量维度),其中
和
是空间维度,
是通道维度。一个 ConvNet N 可以用一个组合层的列表来表示:
。在实践中,ConvNet 层通常被划分为多个阶段,每个阶段中的所有层共享相同的架构:例如,ResNet (He et al., 2016) 有五个阶段,每个阶段中的所有层都具有相同的卷积类型,除了第一层执行下采样。因此,可以将 ConvNet 定义为:
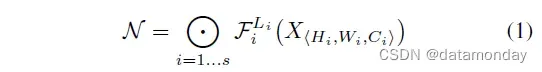
与主要专注于寻找最佳层架构 Fi 的常规 ConvNet 设计不同,模型缩放尝试在不更改基线网络中预定义的 Fi 的情况下扩展网络长度 (Li)、宽度 (Ci) 和/或分辨率 (Hi, Wi)。通过固定 Fi,模型缩放简化了针对新资源约束的设计问题,但对于每一层探索不同的 Li、Ci、Hi、Wi 仍然是一个很大的设计空间。为了进一步减少设计空间,我们限制所有层必须以恒定比例均匀缩放。我们的目标是最大化任何给定资源约束的模型精度,这可以表述为一个优化问题:

3.2. Scaling Dimensions
问题 2 的主要难点是最优的 d、w、r 相互依赖,并且在不同的资源约束下值会发生变化。由于这个困难,传统方法大多在以下维度之一中缩放 ConvNet:
深度(d):缩放网络深度是许多 ConvNet 最常用的方式 (He et al., 2016; Huang et al., 2017; Szegedy et al., 2015; 2016)。直觉是,更深的 ConvNet 可以捕获更丰富、更复杂的特征,并且可以很好地概括新任务。然而,由于梯度消失问题,更深层次的网络也更难训练 (Zagoruyko & Komodakis, 2016)。尽管跳过连接 (He et al., 2016) 和批量归一化 (Ioffe & Szegedy, 2015) 等多种技术缓解了训练问题,但非常深的网络的准确度增益降低了:例如,ResNet-1000 具有相似的准确度与 ResNet-101 一样,尽管它有更多的层。图 3(中)显示了我们对具有不同深度系数 d 的基线模型进行缩放的实证研究,进一步表明非常深的 ConvNets 的准确度回报递减。
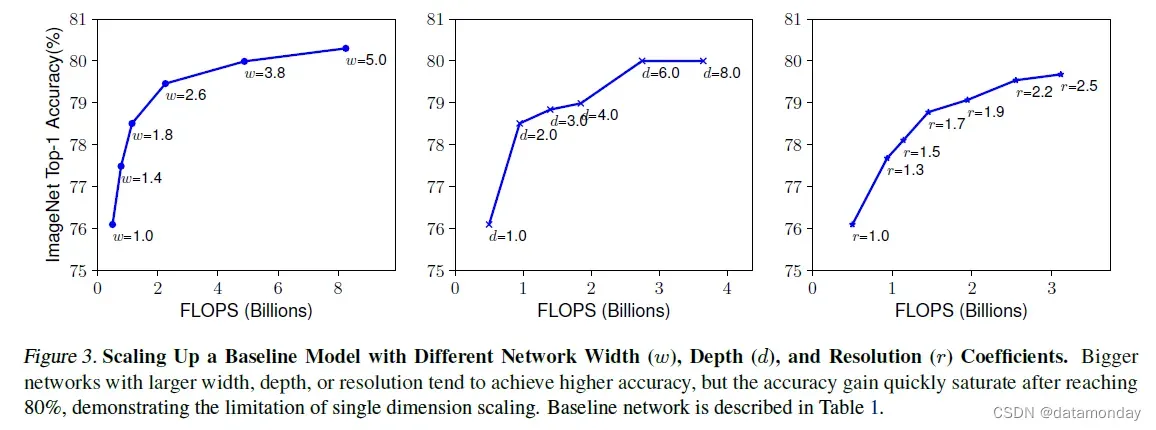
分辨率(r):使用更高分辨率的输入图像,ConvNets 可以潜在地捕获更细粒度的模式。从早期 ConvNet 的 224×224 开始,现代 ConvNet 倾向于使用 299×299(Szegedy et al.,,2016)或 331×331(Zoph et al.,,2018)以获得更好的精度。最近,GPipe (Huang et al., 2018) 以 480×480 的分辨率实现了最先进的 ImageNet 精度。更高的分辨率,例如 600×600,也广泛用于目标检测 ConvNets(He et al., 2017; Lin et al., 2017)。图 3(右)显示了缩放网络分辨率的结果,其中确实更高的分辨率提高了精度,但精度增益对于非常高的分辨率会降低(r = 1.0 表示分辨率 224×224,r = 2.5 表示分辨率 560×560)。上述分析使我们得出第一个观察结果:
观察 1——扩大网络宽度、深度或分辨率的任何维度都可以提高准确性,但对于更大的模型,准确性增益会降低。
3.3. Compound Scaling
我们凭经验观察到不同的缩放维度不是独立的。直观地说,对于更高分辨率的图像,我们应该增加网络深度,这样更大的感受野可以帮助捕捉更大图像中包含更多像素的相似特征。相应地,我们也应该在分辨率较高时增加网络宽度,以便在高分辨率图像中捕获更多像素更多的细粒度图案。这些直觉表明,我们需要协调和平衡不同的缩放维度,而不是传统的单维度缩放。
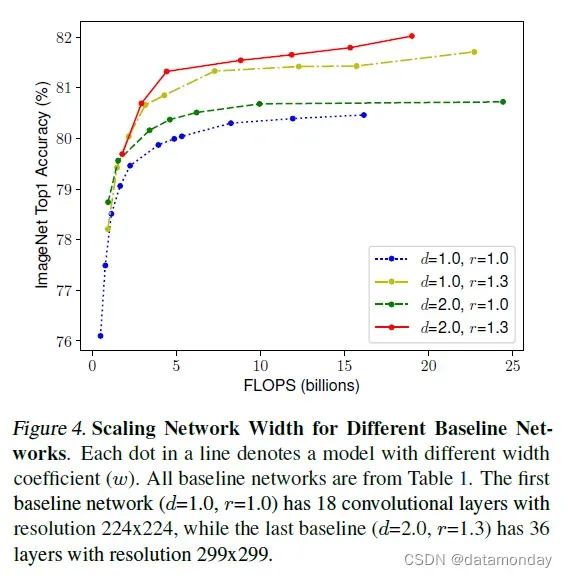
观察 2——为了追求更好的准确性和效率,在 ConvNet 缩放期间平衡网络宽度、深度和分辨率的所有维度至关重要。
事实上,之前的一些工作(Zoph et al., 2018; Real et al., 2019)已经尝试过任意平衡网络宽度和深度,但它们都需要繁琐的手动调整。
在本文中,我们提出了一种新的复合缩放方法,它使用复合系数 φ 以有原则的方式统一缩放网络宽度、深度和分辨率:
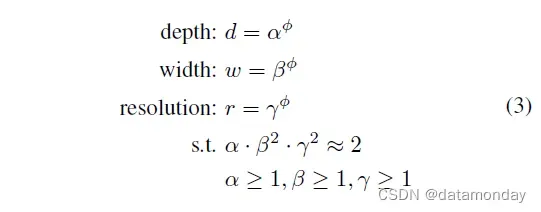
4. EfficientNet Architecture
由于模型缩放不会改变基线网络中的层算子 ,因此拥有良好的基线网络也很关键。我们将使用现有的 ConvNet 评估我们的缩放方法,但为了更好地展示我们的缩放方法的有效性,我们还开发了一个新的移动尺寸基线,称为 EfficientNet。
受 (Tan et al., 2019) 的启发,我们通过利用优化准确性和 FLOPS 的多目标神经架构搜索来开发我们的基线网络。具体来说,我们使用与 (Tan et al., 2019) 相同的搜索空间,并使用 作为优化目标,其中
和
表示模型 m 的准确率和 FLOPS,T 是目标 FLOPS,w=-0.07 是用于控制准确率和 FLOPS 之间权衡的超参数。与(Tan et al., 2019; Cai et al., 2019)不同,这里我们优化 FLOPS 而不是延迟,因为我们没有针对任何特定的硬件设备。我们的搜索产生了一个高效的网络,我们将其命名为 EfficientNet-B0。由于我们使用与 (Tan et al., 2019) 相同的搜索空间,该架构类似于 MnasNet,除了我们的 EfficientNet-B0 由于更大的 FLOPS 目标(我们的 FLOPS 目标是 400M)而略大一些。表 1 显示了 EfficientNet-B0 的架构。它的主要构建块是移动倒置瓶颈(mobile inverted bottleneck) MBConv (Sandler et al., 2018; Tan et al., 2019),我们还添加了挤压和激励优化 (Hu et al., 2018)。
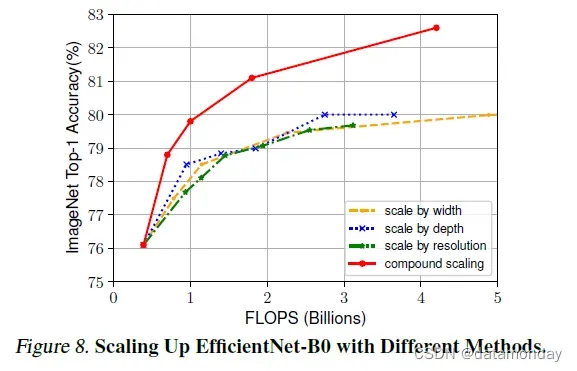
从基线 EfficientNet-B0 开始,我们应用复合缩放方法通过两个步骤对其进行缩放:
- 第 1 步:**首先固定 φ = 1,假设可用资源增加两倍,然后基于公式 2 和 3 对 α,β,γ进行小网格搜索 **。特别是,我们发现 EfficientNet-B0 的最佳值是 α = 1.2,β = 1.1,γ = 1.15,在 α · β2 · γ2 ≈ 2 的约束下。
- 第 2 步:将 α、β、γ 固定为常数,并使用公式 3 放大具有不同 φ 的基线网络,以获得 EfficientNet-B1 到 B7(详见表 2)。
5. Experiments
在本节中,我们将首先评估我们在现有 ConvNets 和新提出的 EfficientNets 上的缩放方法。
5.1. Scaling Up MobileNets and ResNets
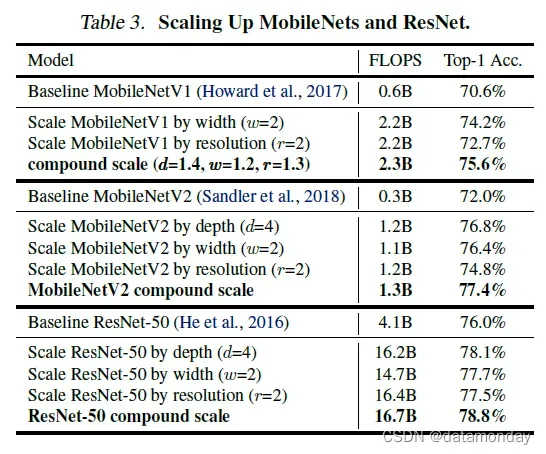
作为概念证明,我们首先将我们的缩放方法应用于广泛使用的 MobileNets (Howard et al., 2017; Sandler et al., 2018) 和 ResNet (He et al., 2016)。表 3 显示了 ImageNet 以不同方式缩放它们的结果。与其他单维缩放方法相比,我们的复合缩放方法提高了所有这些模型的准确性,表明我们提出的缩放方法对一般现有 ConvNets 的有效性。
5.2. ImageNet Results for EfficientNet
我们使用与 (Tan et al., 2019) 类似的设置在 ImageNet 上训练我们的 EfficientNet 模型:RMSProp 优化器,衰减为 0.9,动量为 0.9;批量标准动量 0.99;权重衰减 1e-5;初始学习率 0.256,每 2.4 个 epoch 衰减 0.97。我们还使用 SiLU (Swish-1) 激活 (Ramachandran et al., 2018; Elfwing et al., 2018; Hendrycks & Gimpel, 2016),AutoAugment (Cubuk et al., 2019) 和随机深度 (Huang et al., 2019),生存概率为 0.8。众所周知,更大的模型需要更多的正则化,我们将 dropout (Srivastava et al., 2014) 比率从 EfficientNet-B0 的 0.2 线性增加到 B7 的 0.5。我们从训练集中随机抽取 25K 幅图像作为 minival 集,并在这个 minival 上执行提前停止;然后,我们在原始验证集上评估 earlystopped 检查点,以报告最终验证的准确性。
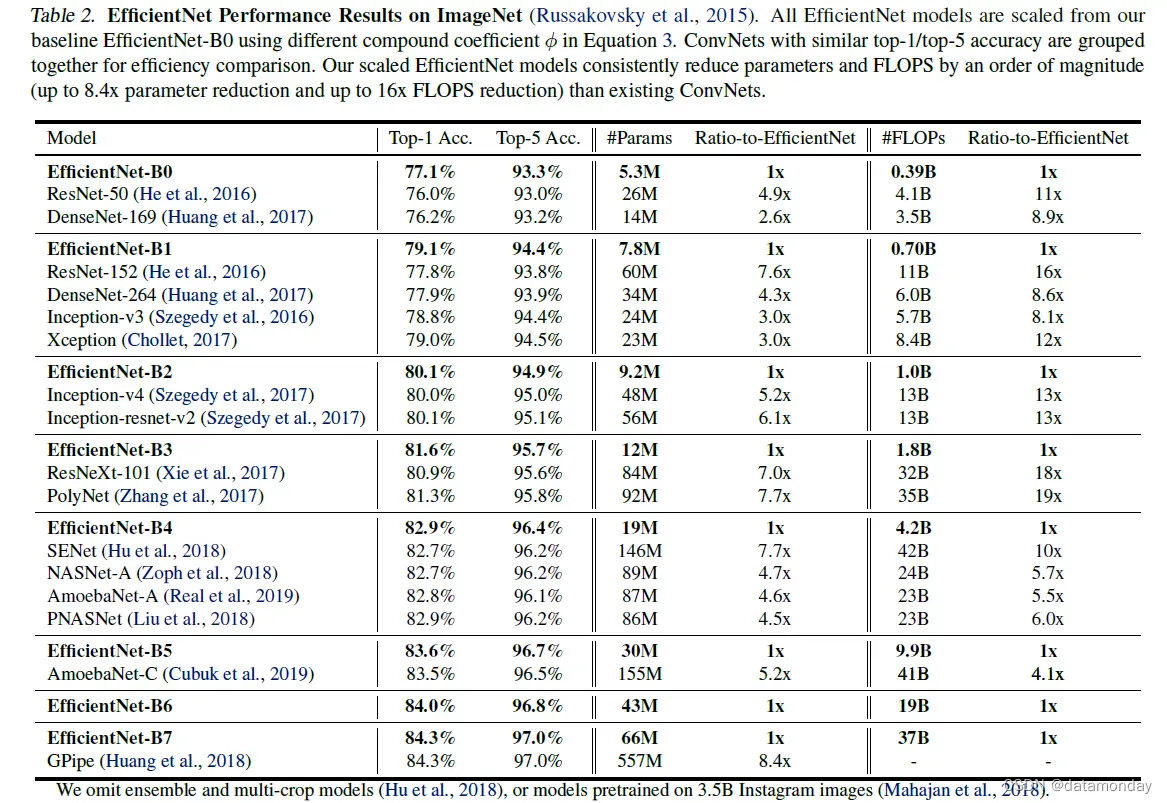
表 2 显示了从相同基线 EfficientNet-B0 扩展的所有 EfficientNet 模型的性能。我们的 EfficientNet 模型通常使用的参数和 FLOPS 比其他具有相似精度的 ConvNet 少一个数量级。特别是,我们的 EfficientNet-B7 在 66M 参数和 37B FLOPS 的情况下实现了 84.3% 的 top1 准确率,比之前最好的 GPipe(Huang et al.,,2018 年)更准确但小 8.4 倍。这些收益来自为 EfficientNet 定制的更好的架构、更好的扩展和更好的训练设置。
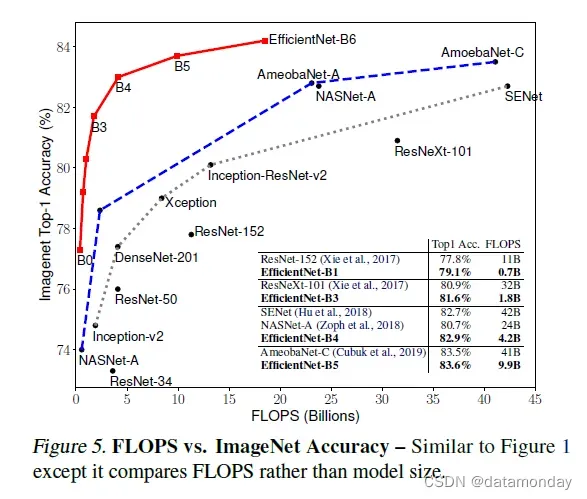
为了验证延迟,我们还测量了真实 CPU 上几个代表性 CovNet 的推理延迟,如表 4 所示,我们报告了 20 次运行的平均延迟。我们的 EfficientNet-B1 运行速度比广泛使用的 ResNet-152 快 5.7 倍,而 EfficientNet-B7 的运行速度比 GPipe 快约 6.1 倍(Huang et al.,,2018),这表明我们的 EfficientNets 在真实硬件上确实很快。

5.3. Transfer Learning Results for EfficientNet
6. Discussion
7. Conclusion
在本文中,我们系统地研究了 ConvNet 的缩放,并确定仔细平衡网络宽度、深度和分辨率是一个重要但缺失的部分,这使我们无法获得更好的准确性和效率。为了解决这个问题,我们提出了一种简单且高效的复合缩放方法,它使我们能够以更原则的方式轻松地将基线 ConvNet 扩展到任何目标资源约束,同时保持模型效率。在这种复合缩放方法的支持下,我们证明了移动大小的 EfficientNet 模型可以非常有效地进行缩放,在 ImageNet 和五个常用的迁移学习数据集上以更少的参数和 FLOPS 超过最先进的精度。
文章出处登录后可见!