1.前置白话
本博文一起学习使用 Pytorch 框架进行数据加载、 网络搭建、模型优化等基本模块,快速入手深度学习卷积神经网络的搭建。
- 学习相关视频:
链接:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】 . - 本博文涉及的本地运行测试代码及蚂蚁蜜蜂二进制数据集下载:
链接:https://pan.baidu.com/s/1gcMxR4Y_doBoO_QckTwLmQ.
提取码:z6e4
二、pytorch零基础搭建网络快速入门
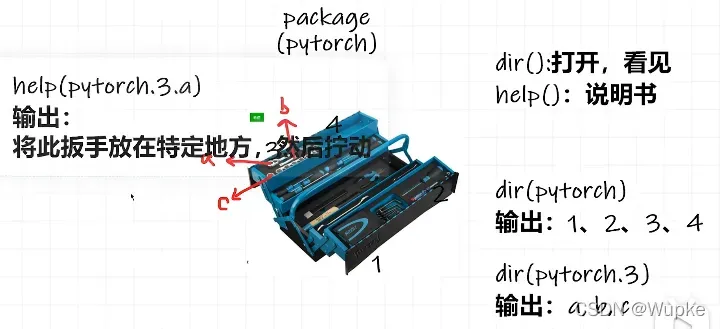
- torch使用过程中两个主要的函数:
- 1、dir()函数,返回工具箱以及工具箱中的分隔区有什么东西。
- 2、help()函数,返回每个工具是如何使用的,工具的使用方法。
1、数据加载:
Dateset
- 提供一种方式去获取数据及其lable值,将数据进行打包,提供后续 。
- 如何获取每一个数据及其label
- 总共有多少数据。
from cProfile import label
from operator import index
from torch.utils.data import Dataset
from PIL import Image # 获取读取图片
import os # 获取图片数据地址
class MyData(Dataset):
def __init__(self,root_dir,label_dir): # 初始化,self 是变量引用的全局化
self.root_dir = root_dir # 传入 数据集根文件夹
self.label_dir = label_dir # 传入 一类 label 文件夹
self.path = os.path.join(self.root_dir,self.label_dir) # 获取其中一张图片的地址
self.img_path = os.listdir(self.path) # 获取传入文件夹所有图片的列表
def __getitem__(self, index): # idx (按照传入的文件夹列表中图片的ID索引,就要得到图片的相对路径)
img_name = self.img_path[index] # 从传入图片文件夹的列表中取到一张图片
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name) # 该图片的相对路径
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
if __name__=="__main__":
root_dir = "hymenoptera_data/train/" # 数据集根目录
ants_label_dir = "ants" # 传入蚂蚁数据集类图片文件
ants_dataset = MyData(root_dir,ants_label_dir)
print('len_ants_dataset',len(ants_dataset))
# img,label = ants_dataset[0]
# print("img,label",img)
# img.show()
bees_label_dir = "bees" # 传入蜜蜂数据集类图片文件
bees_dataset = MyData(root_dir,bees_label_dir)
print('len_bees_dataset',len(bees_dataset))
train_dataset = ants_dataset + bees_dataset # 整个训练数据集是两个数据集相加
print('len_all_train_dataset',len(train_dataset))
Dataloader
- 官方文档地址:
- https://pytorch.org/docs/stable/data.html?highlight=dataloader#torch.utils.data.DataLoader
- 从Dataset中取数据图片,为后面的网络提供不同的数据形式。

- 大部分参数为默认值,少数需要自行设置。
- 例子:
- 示例代码:
import torchvision
from torch.utils.data import DataLoader # 准备的测试数据集
from torch.utils.tensorboard import SummaryWriter
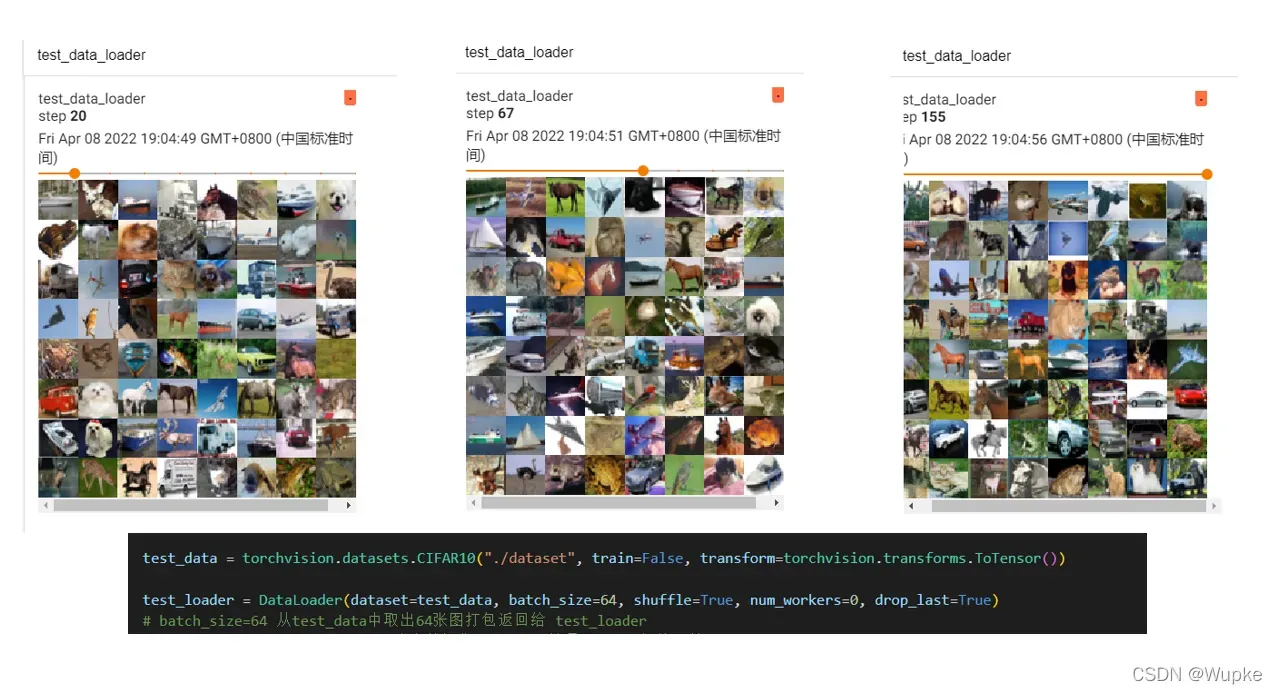
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# batch_size=64 从test_data中取出64张图打包返回给 test_loader
img, target = test_data[0] # 分类数据集,target 就是 label 标签属性
print('img.shape',img.shape)
print('target',target)
# 使用tensorboard 展示
writer = SummaryWriter("dataloader")
# 打包后取出
step = 0
for data in test_loader:
imgs, targets = data
# print('imgs.shape',imgs.shape)
# print('target',targets)
writer.add_images("test_data_loader", imgs, step)
step = step + 1
writer.close()
2、数据可视化工具
Tensorboard
- 1、 训练过程中展示 loss 的变化曲线,writer.add_scalar() 方法
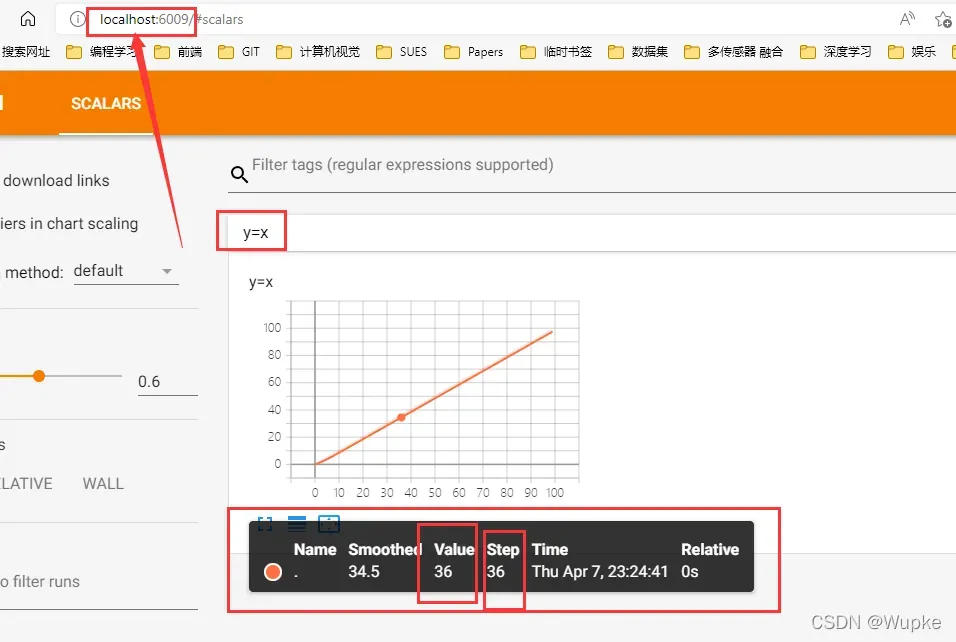
- 2、可视化输入训练的图片 writer.add_image() 方法
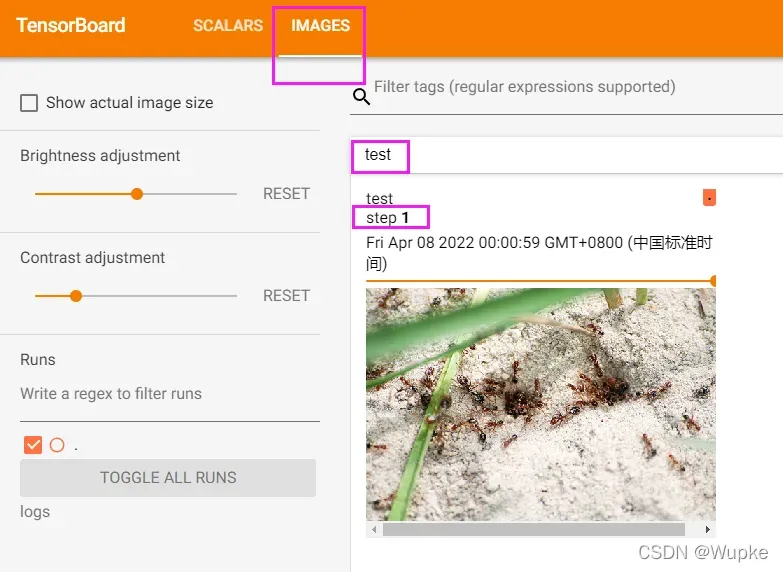
- 使用 Numpy 格式传入单张图片测试显示
# import torchvision
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs") # logs 为存储事件文件的文件夹
image_path = "../hymenoptera_data/train/ants/1030023514_aad5c608f9.jpg" # 输入单张图
img_PIL = Image.open(image_path) # 使用OpenCV加载图片
print("type(img_PIL)",type(img_PIL))
img_array = np.array(img_PIL) # 转换为numpy 格式
print("type(img_array)",type(img_array))
print("img_array.shape",img_array.shape)
# 用到两个方法 writer.add_image() 和 writer.add_scalar()
writer.add_image("test",img_array,1,dataformats='HWC') ## 导入的图片类型需要是 Tensor 或者 Numpy,PIL导入的图片一般为Jpeg格式,要进行格式转换
# writer.add_scalar() 写入标量,坐标轴关系曲线
for i in range(100):
writer.add_scalar('y=x',i,i) # i,i 依次代表 y轴 x轴
# 启动可视化命令: tensorboard --logdir=logs --port=6009 ## 创建指定的文件夹名称,指定端口号
writer.close()
- 终端启动命令:
tensorboard --logdir=logs --port=6009 ## 创建指定的文件夹名称,指定端口号
- 实际训练过程中,传入的应当是每一个 step 训练对应的图片,不是单单一张图片,而且图片格式输入为Tensor 格式。
- 代码:(Tensor 格式传入)
在这里插入代码片
3、Transform
- Transform的结构和用法:
Tensor 数据类型
通过transforms.ToTensor了解两个问题:
1、transforms 如何去使用(Python)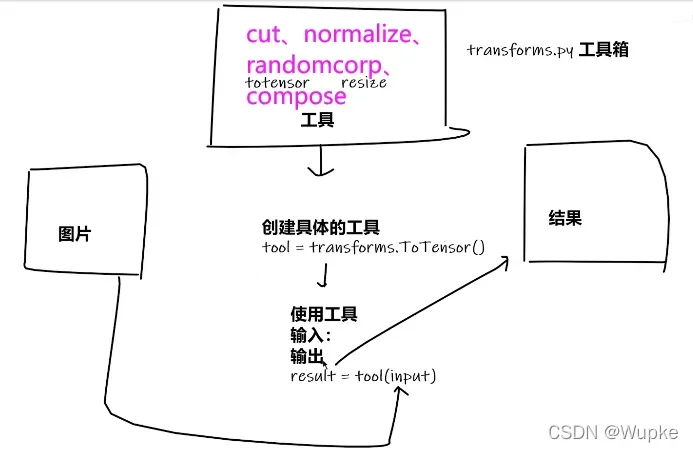

transform的实际应用: 进行数据预处理和数据增强
from torchvision import datasets,transforms
# 使用Composes将transforms组合在一起,tranforms子类进行数据预处理和数据增强
data_transforms = {
'train':transforms.Compose([transforms.ToTensor(), # 图像转换成pytorch中的张量
transforms.RandomHorizontalFlip(p=0.5), # 图像依概率随机翻转
transforms.RandomGrayscale(p=0.2), # 图像依概率随机灰度化
transforms.RandomAffine(5), # 图像中心保持不变的随机仿射变换
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)), # 归一化
]),
'val':transforms.Compose([transforms.ToTensor(), # 图像转换成pytorch中的张量
transforms.RandomHorizontalFlip(p=0.5), # 图像依概率随机翻转
transforms.RandomGrayscale(p=0.2), # 图像依概率随机灰度化
transforms.RandomAffine(5), # 图像中心保持不变的随机仿射变换
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)), # 归一化
])
}
2、为什么需要Tensor数据类型:
主要是Tensor类型与神经网络结构的数据有关。
- 使用 transforms.ToTensor() 输入单张图
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
img_path = "../hymenoptera_data/train/ants/132478121_2a430adea2.jpg" # 输入单张图
img = Image.open(img_path)
Writer = SummaryWriter("logs") # 保存日志
# Tensor 的使用
trans_toTensor = transforms.ToTensor() # 实例化对象
tensor_image = trans_toTensor(img)
# print('tensor_image',tensor_image)
Writer.add_image("Tensor_image",tensor_image)
Writer.close()
下载并在官网展示数据集
- Pytorch官网的数据集官方文档:
- https://pytorch.org/vision/stable/datasets.html
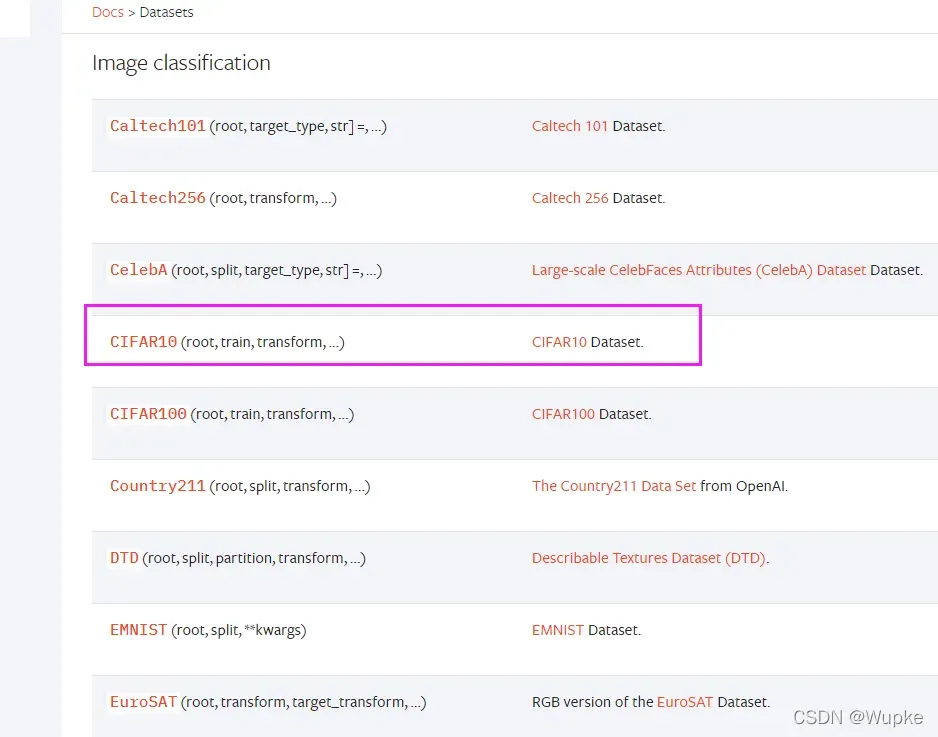
- 点击进入对应的数据集介绍,可以查看下载代码参数的设置。
数据集下载:一个较小 的 CIFAR10 分类数据集
- 下载数据的参数代码:
import torchvision
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,download=True)
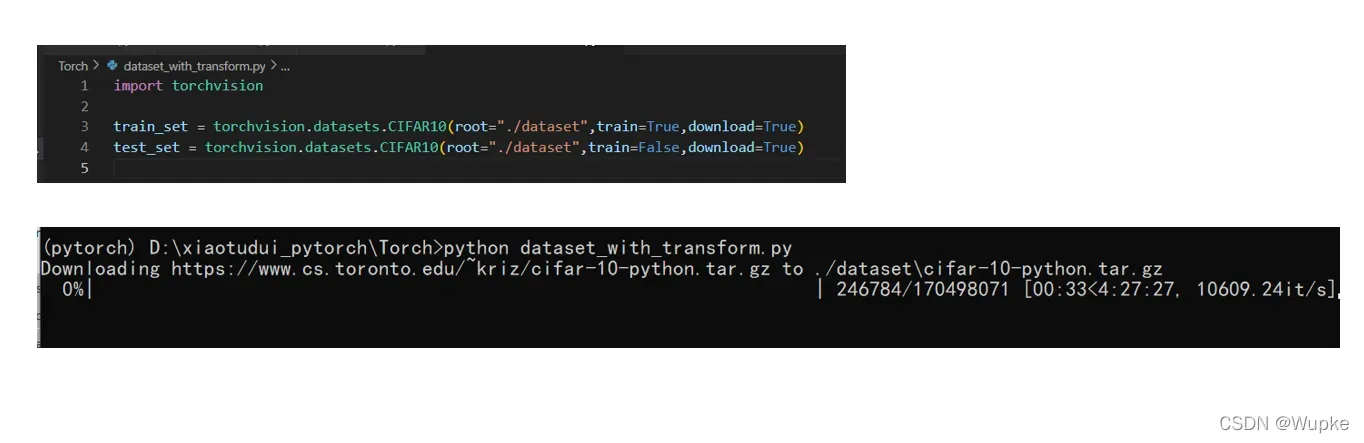
- 找到源码中函数定义的下载链接,使用迅雷下载更快,将download先设置为TRUE,下载好的文件会自动解压。
下载数据集并将数据集图片转化为 Tensor 格式在tensorboard 中展示:
from cv2 import transform
import torchvision
from torch.utils.tensorboard import SummaryWriter
# 将载入的数据集图片转换为Tensor格式
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_set = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=dataset_transform, download=True)
# print(test_set[0])
# print(test_set.classes)
# img,target = test_set[0]
# print(img)
# print(target)
# print(test_set.classes[target])
# img.show()
# print(test_set[0])
writer = SummaryWriter("logs_CIFAR10") # 保存日志的文件夹
for i in range(10):
img,target = test_set[i]
writer.add_image("test_set", img, i) # 标签,输入Tensor图片,step
writer.close()
- 可以设置分批次:Epoch 将数据集图片输入到神经网络中进行训练。
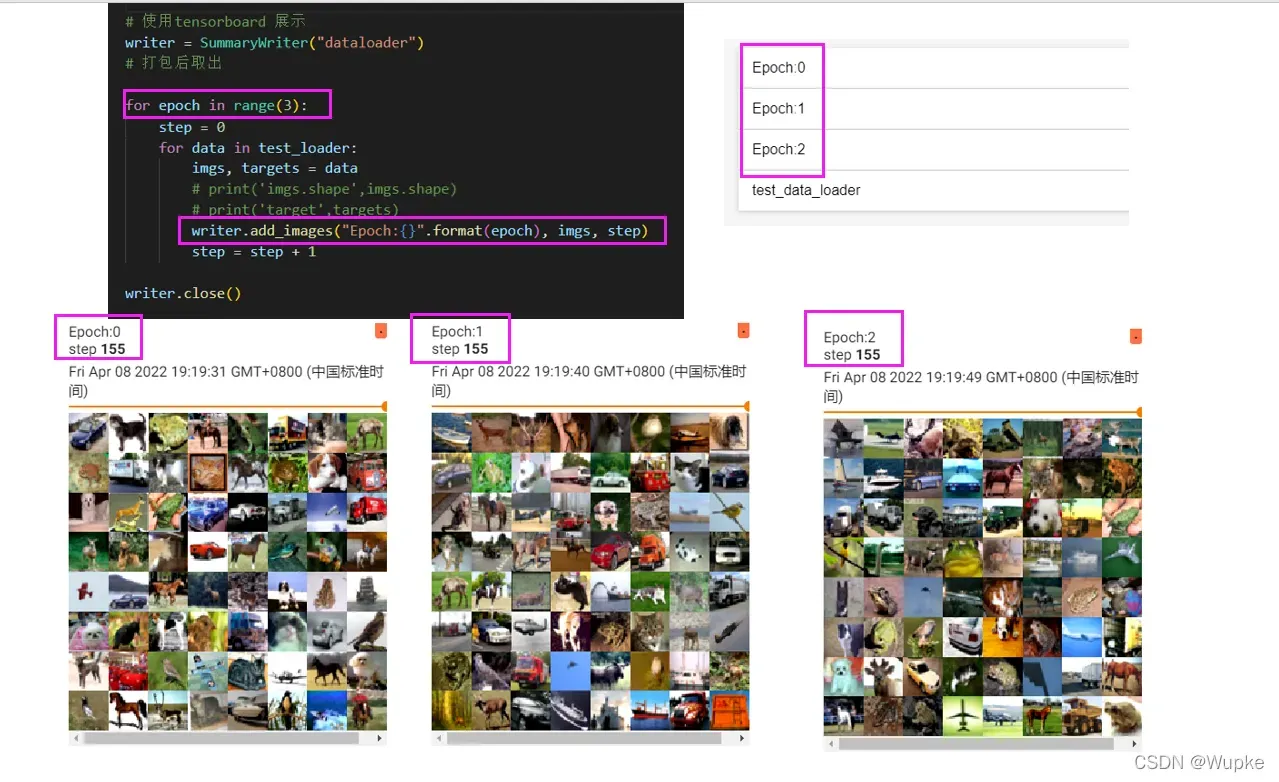
- 实际应用:
4、model 模型搭建
- 官网文档页:https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2d
- 所有的重写的网络都要继承 Pytorch 的nn.module 类。
- 卷积

model.py
- 简单构建一个卷积网络代码实现:
'''
# Author :
# Time:2022年4月8日20:57:55
# Description:搭建神经网络模型
#
'''
import torch
import torchvision
from torch.nn import Conv2d, MaxPool2d
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 引入数据集
dataset = torchvision.datasets.CIFAR10("./dataset",train=False, transform=torchvision.transforms.ToTensor(),
download=True) # CIFAR10已下载好
dataloader = DataLoader(dataset, batch_size=64)
class MyModel(nn.Module):
def __init__(self):
super(MyModel,self).__init__() # 初始化,继承父类
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self,x):
# x = self.conv1(x)
x = self.maxpool1(x)
return x
mymodel1 = MyModel()
# tensorboard可视化
writer = SummaryWriter("model_dataloader")
step = 0
for data in dataloader:
imgs, labels = data
output = mymodel1(imgs)
print('imgs.shape',imgs.shape)
print('output.shape',output.shape)
# imgs.shape torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# output.shape torch.Size([64, 6, 30, 30])--> [xxx, 3, 30, 30]
output = torch.reshape(output, (-1, 3, 30, 30)) # -1 ,自动计算channel的数值
writer.add_images("output", output, step)
step = step + 1
writer.close()
- 搭建一个以 CIFAR10 数据集分类的网络模型:
网络架构: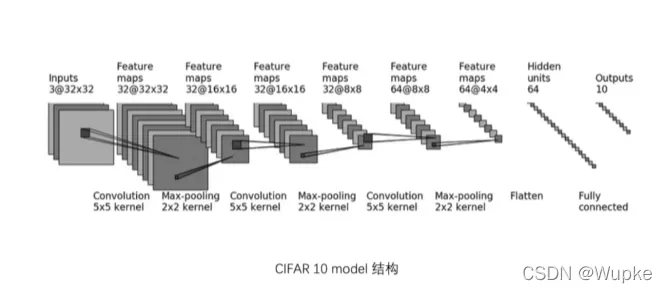
- 代码:
'''
# Author :
# Time:2022年4月9日08:26:33
# Description:搭建CIFAR10数据集分类的神经网络模型
#
'''
from torch import nn
import torch
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
##### 一般的定义网络形式 ######
class CIFAR10_model(nn.Module):
def __init__(self):
super(CIFAR10_model,self).__init__() # 初始化继承父类
self.conv1 = Conv2d(3, 32, 5, padding=2) # channels, (w,h), kernel
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32,32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32,64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten() # 展平
self.linear1 = Linear(1024, 64) # 线性层
self.linear2 = Linear(64, 10)
def forward(self,x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
# ###### 等价的利用 sequential 结构表示网络结构,看起来网络更简洁 ######
# class CIFAR10_model2(nn.Module):
# def __init__(self):
# super(CIFAR10_model2,self).__init__() # 初始化继承父类
# self.model2 = Sequential(
# Conv2d(3, 32, 5, padding=2),
# MaxPool2d(2),
# Conv2d(32, 32, 5, padding=2),
# MaxPool2d(2),
# Conv2d(32, 64, 5, padding=2),
# MaxPool2d(2),
# Flatten(x),
# Linear(1024, 64),
# Linear(64, 10),
# )
# def forward(self, x):
# x = self.model2(x)
# return x
if __name__=="__main__":
cifar10_model = CIFAR10_model()
print(cifar10_model)
## 测试网络正确与否
input = torch.ones((64, 3, 32, 32) )
output = cifar10_model(input)
print(output.shape)
writer = SummaryWriter("log_model")
writer.add_graph(cifar10_model,input)
writer.close()
- tensorboard 结构可视化:
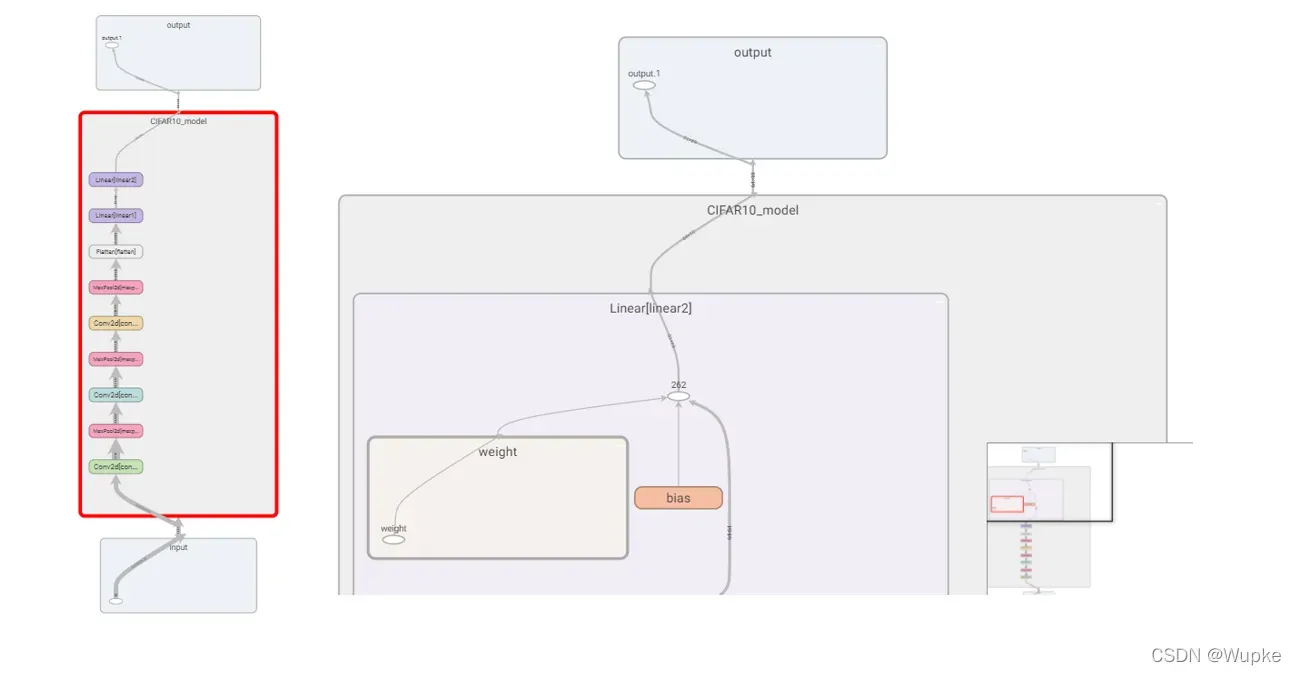
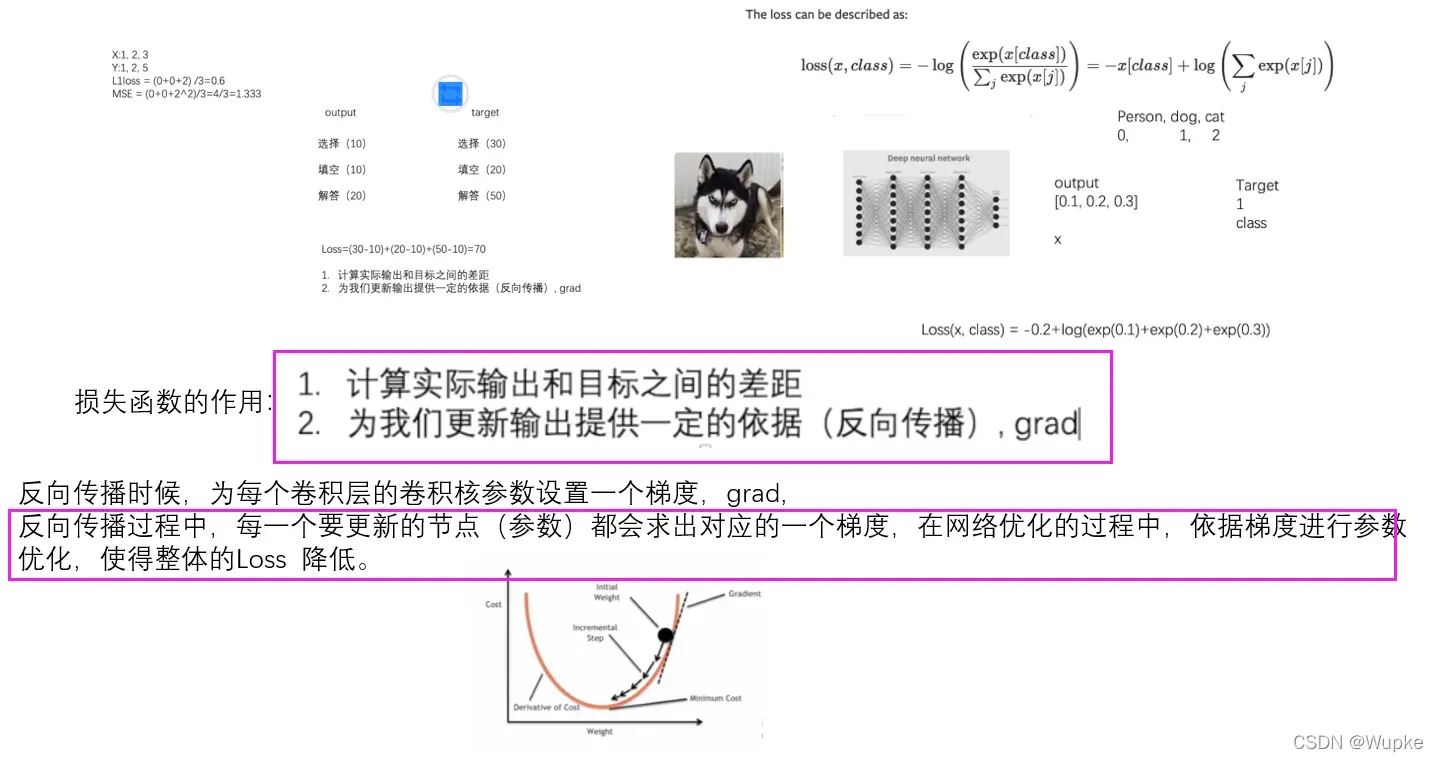
- 损失函数:
L1Loss——-线性平均损失
MSE——–平方平均损失函数
CrossEntropyLoss ———交叉熵损失函数:
- 结合不同的优化器,就可以依据梯度变化进行整体 Loss 优化。
- 优化器优化过程:
5、对现有的网络模型进行加载、修改
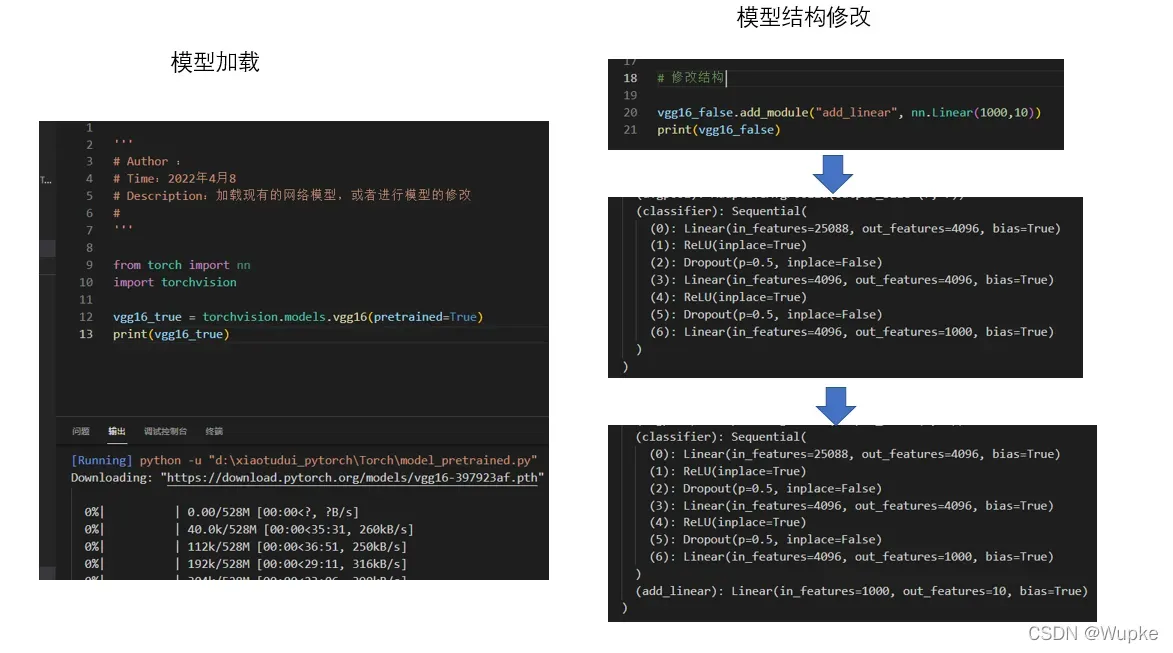
vgg16 为例 网络模型的加载与修改
- 参考代码:
'''
# Author :
# Time:2022年4月9
# Description:加载现有的网络模型,或者进行模型的修改
#
'''
from torch import nn
import torchvision
# 下载模型
vgg16_false = torchvision.models.vgg16(pretrained=False)
print(vgg16_false)
# vgg16_true = torchvision.models.vgg16(pretrained=True)
# print(vgg16_true)
# 加载数据集
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor())
# 修改结构一些操作
vgg16_false.add_module("add_linear", nn.Linear(1000,10))
print(vgg16_false)
vgg16_false.classifier.add_module("add_linear", nn.Linear(1000,10))
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
6、模型的保存 与 加载
- 模型保存:
# 保存方法1 (模型结构+模型参数)
torch.save(vgg16, "vgg16_method1.pth")
# 保存方法2 (模型参数---官方推荐)
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
- 如何加载模型
# 加载方法1
model = torch.load("vgg16_method1.pth")
print(model)
- 按照方法1加载模型的时候,需要在加载前放置 网络的类:
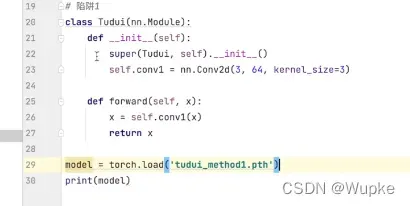
- 其实在工程项目中,把网络结构写成单独的文件引用是没有问题的。
# 加载方法2
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
# model = torch.save(vgg16.state_dict(), "vgg16_method2.pth")
print(model)
7、完整的模型训练套路
- 以上述的CIFAR10数据集分类为例。
train.py
- train.py文件
'''
# Author :
# Time:2022年4月10日
# Description:完整的搭建CIFAR10数据集分类的神经网络模型训练流程
#
'''
import torch
import torchvision
from torch import device, nn
from torch.utils.data import DataLoader
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
import time
# 设定训练使用设备 Cpu/Gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root = "dataset", train= True,
transform=torchvision.transforms.ToTensor(),
download=True )
test_data = torchvision.datasets.CIFAR10(root = "dataset", train= False,
transform=torchvision.transforms.ToTensor(),
download=True )
# 查看数据集数据量
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data))
print("测试数据集的长度为:{}".format(test_data))
# 使用 DateLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型 (可单独拎出去,引用模块)
class CIFAR10_model(nn.Module):
def __init__(self):
super(CIFAR10_model,self).__init__() # 初始化继承父类
self.model = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
# 创建模型对象
cifar10 = CIFAR10_model()
cifar10.to(device)
# 定义交叉熵损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
#优化器
# learning_rate = 0.01
learning_rate = 1e-2 # 1e-2 = 1 X (10)^(-2) = 1/100
optimizer = torch.optim.SGD(cifar10.parameters(), lr=learning_rate) # 传入网络的参数,学习率
# 设置网络训练过程中的参数
# 记录训练次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 设置训练的轮数
epochs = 10
# 训练时间
start_time = time.time()
# 添加 tensorboard 可视化
writer = SummaryWriter("log_train")
for epoch in range(epochs):
print("****************第{}轮开始训练**************".format(epoch + 1))
# 训练步骤开始
cifar10.train() ############### 此行细节,没有也可进行训练 ######################
for data in train_dataloader:
imgs,labels = data
####### 数据转移到 cuda 上加速
imgs = imgs.to(device)
labels = labels.to(device)
outputs = cifar10(imgs)
loss = loss_fn(outputs,labels) # 损失函数: 输出 与 真实的差别
# 优化器优化模型
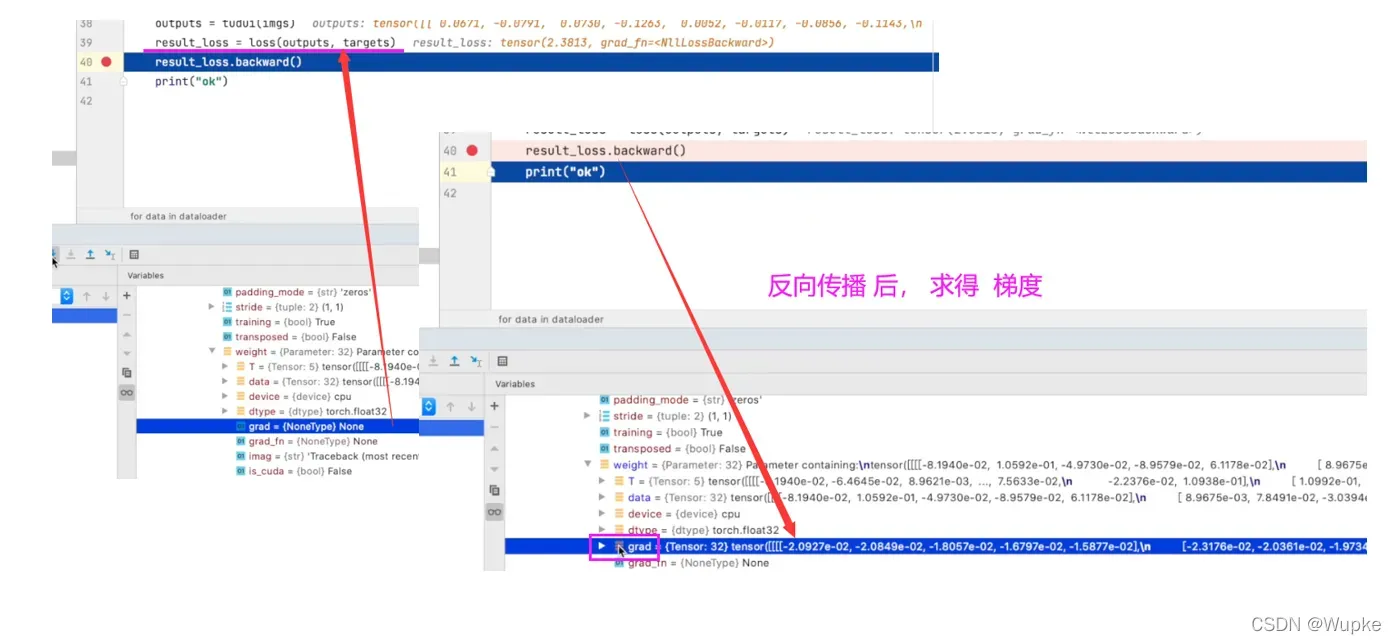
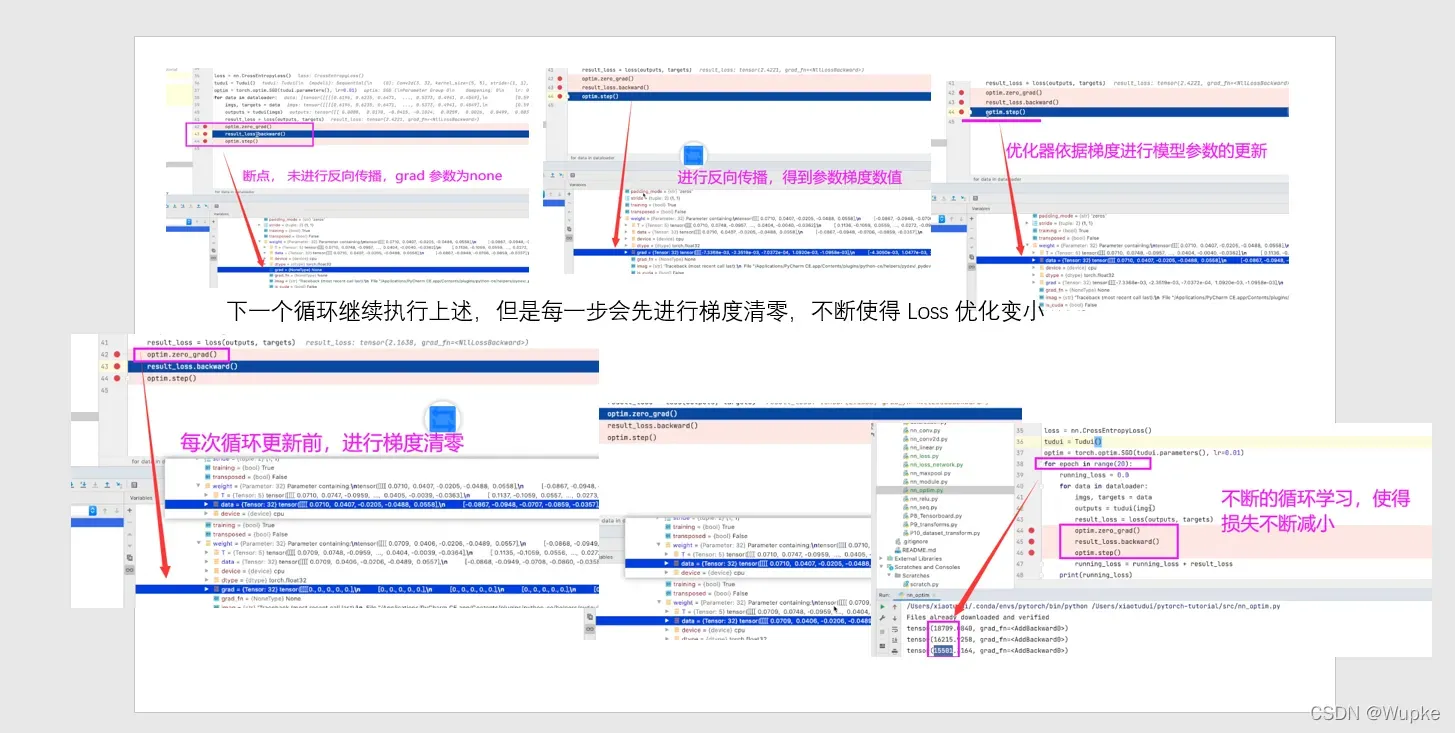
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 更新参数
total_train_step = total_train_step + 1
if total_train_step % 100 == 0: # 逢整百 打印
end_time = time.time()
print("训练时间为:",end_time-start_time) # 打印训练时间
print("训练次数为:{}, Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss",loss.item() ,total_train_step ) #
# 每训练完依次,查看有没有效果?
# 在测试集中测试
# 测试开始
cifar10.eval() ############### 此行细节,没有也可进行测试 ######################
total_test_loss = 0 # 测试的损失
total_accuracy = 0 # 测试准确率
with torch.no_grad():
for data in test_dataloader:
imgs, labels = data
####### 数据转移到 cuda 上加速
imgs = imgs.to(device)
labels = labels.to(device)
outputs = cifar10(imgs)
loss = loss_fn(outputs, labels)
total_test_loss = total_test_loss + loss.item()
# 测试的准确率
accuracy = (outputs.argmax(1)==labels).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的 Loss :{}".format(total_test_loss))
print("整体测试集上的准确率为:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accurary", total_accuracy/total_test_step,total_test_step )
total_test_step = total_test_step + 1
# # 保存每一轮的训练模型
# 保存方式1
torch.save(cifar10,"./Model/cifar10_{}.pth".format(epoch))
# 保存方式2
# torch.save(cifar10.state_dict(), "cifar10_{}.pth".format(epoch))
print("第{}轮模型已保存".format(epoch))
# # # 保存整数轮的训练模型
# if epoch % 10 == 0:
# torch.save(cifar10,"cifar10_{}.pth".format(data))
# print("第{}轮模型已保存".format(epoch))
writer.close()
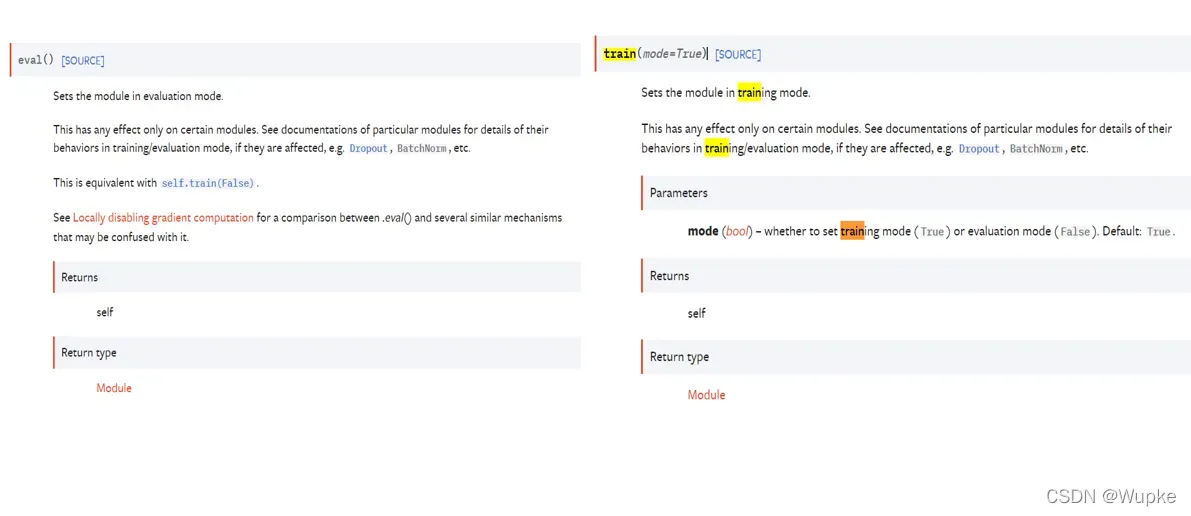
- 细节理解:
# 训练步骤开始
CIFAR10_model.train() ############### 此行细节,没有也可进行训练 ######################
# 测试步骤开始
cifar10.eval() ############### 此行细节,没有也可进行测试 ######################
- 将网络设置为特定状态模式只会影响网络中的特定结构。
- 官方文档解析:https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module
8、GPU 加速训练
方法1
- .cuda加速的数据
网络模型、数据(输入、标签)、损失函数 - 模型:
if torch.cuda.is_available():####### 数据转移到 cuda 上加速
cifar10 = cifar10.cuda()
- 数据:
if torch.cuda.is_available():####### 数据转移到 cuda 上加速
imgs = imgs.cuda()
labels = labels.cuda()
- 损失函数:
if torch.cuda.is_available():####### 数据转移到 cuda 上加速
loss_fn = loss_fn.cuda()
-google colab 谷歌账号免费使用 GPU 尝试小的项目*(大概每周30个小时,配置大概16G显存)
方法2
- .to(device)
- Device = torch.device(“cpu”)
- Device = torch.device(“cuda”)
- 多张显卡
- Device = torch.device(“cuda:0”)
- Device = torch.device(“cuda:1”)
- 如:模型和损失函数直接调用,无需重新赋值。
声明设备用途:
device = torch.device("cuda")
# 或者
device = torch.device("cuda:0")
# 或者
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 创建模型对象
cifar10 = CIFAR10_model()
#
cifar10.to(device)
# 定义交叉熵损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
- 数据应该被加速然后分配
####### 数据转移到 cuda 上加速
imgs = imgs.to(device)
labels = labels.to(device)
9、模型的测试、验证
- 也就是使用训练好的模型,提供输入,测试模型的准确性,然后应用它。
model_test.py
- 代码:
'''
# Author :
# Time:2022年4月10日
# Description:利用训练好的模型,提供输入,测试模型的准确性,进行应用
#
'''
from operator import mod
from PIL import Image
import torchvision
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
import torch
from torch import nn
# 测试图
image_path = "automobile.jpg"
image = Image.open(image_path)
print('image',image)
image.show()
imgage = image.convert("RGB") # PNG 是 4 通道
# 转换图片格式 和 输入 大小
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor() ])
# 应用转换
image = transform(image) #变为 3*32*32 的terson 格式
print('image',image)
# 加载网络模型
class CIFAR10_model(nn.Module):
def __init__(self):
super(CIFAR10_model,self).__init__() # 初始化继承父类
self.model = Sequential(
Conv2d(3, 32, 5, 1,padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, 1,padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, 1,padding=2),
MaxPool2d(2),
Flatten(),
Linear(64*4*4, 64),
Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
# 加载模型文件
model = torch.load("./Model/cifar10_1.pth", map_location = torch.device('cpu'))
# print("model",model)
# 如果数据格式不对,进行转换
image = torch.reshape(image,(1,3,32,32))
# 网络模型进入测试模式
model.eval()
with torch.no_grad():
# 将图片输入到模型得到预测的各类别输出结果
output = model(image)
print("output",output)
# 依据得到输出类别列表索引对应的最大值,确定预测结果
class_list=['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
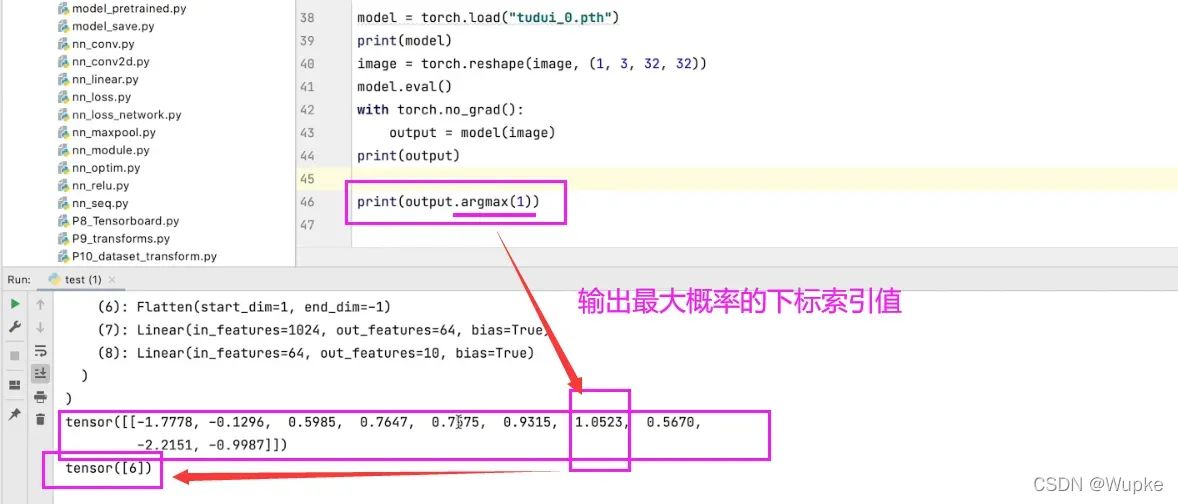
pre_res_index = output.argmax(1).item() # 输出最大概率的下标索引值
print("类别列表为: ",class_list)
print("图片测试类别结果class_list[pre_res_index]]为: ",class_list[pre_res_index])
详细了解
- output.argmax(1)
- 在 CPU 上加载 GPU 训练得到的模型时候,需要声明一下模型映射的形式
示例:如 cifar10_1.pth 权重文件是在GPU上训练得到的,此时要在CPU的设备上加载测试
model = torch.load("./Model/cifar10_gpu.pth",map_location = torch.device('cpu'))
文章出处登录后可见!
已经登录?立即刷新