前言
transformer火了这么久,在视觉,文本,多模态等领域各种刷榜,某天有空看到这篇推送 熬了一晚上,我从零实现了Transformer模型,把代码讲给你听
后来发现有点小问题, 以及代码风格可能自己不是特别喜欢,然后就动手改一改。
Anyway, 很感谢原作者本着开源和分享的精神,看他的代码确实很有收获。
TODO:本文暂时编码器解码器字典大小一样,其实要普适性强的话应该是不一样的,以后再改吧。下午要回家了…
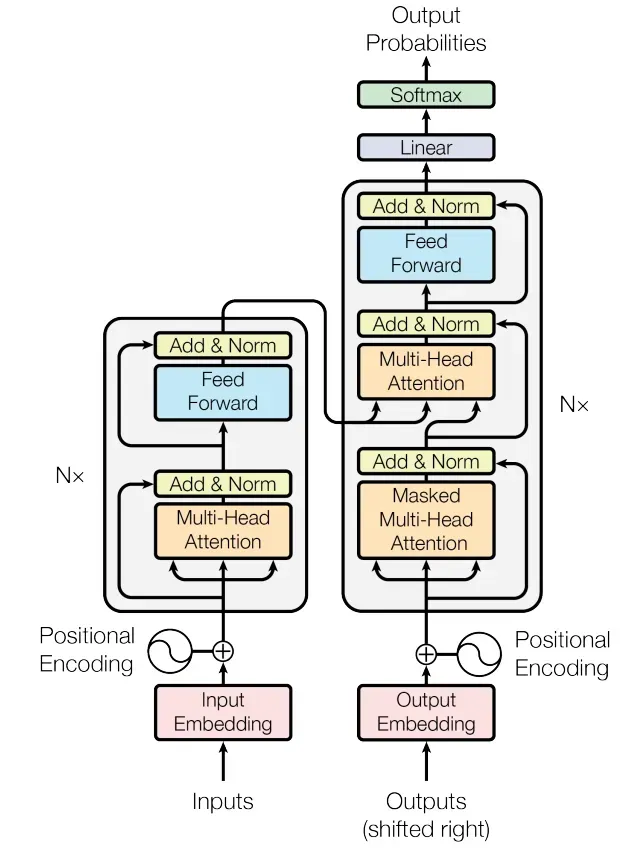
分析
首先定义config类,这里规定我们一些超参数。
class Config(object):
def __init__(self, vocab_size=2000, d_model=512, n_heads=8, padding_size=30, N=6,
dropout=0.1, output_dim=2000):
self.vocab_size = vocab_size
self.d_model = d_model # 模型隐式维度,论文是512
self.n_heads = n_heads # 多头注意力
assert self.d_model % self.n_heads == 0
self.dim_k = self.d_model // self.n_heads
self.dim_v = self.d_model // self.n_heads
self.padding_size = padding_size
self.PAD = 0 # 填充的词的idx
self.UNK = 1 # 词典没出现过的词的idx
self.N = N # 多少个transformer layer
self.p = dropout # Add&Norm那里的dropout率
self.output_dim = output_dim # 最终输出的隐式维度
然后我们定义padding工具函数,用于填充一个批次中的句子,使得这些句子一样长。
def padding_process(batch_ex, padding_size=None):
"""
batch_ex: list[Tensor], [batch_size, seq_len(x)], 注:可能样本sel_len间不同
return: batch_ex:Tensor, [batch_size, padding_size]
"""
assert type(batch_ex) == list
if padding_size is None:
max_len = 0
for ex in batch_ex:
max_len = max(len(ex), max_len)
padding_size = max_len
for i in range(len(batch_ex)):
if len(batch_ex[i]) < padding_size:
ex_padding = torch.tensor([config.PAD] * (padding_size - len(batch_ex[i])))
batch_ex[i] = torch.cat((batch_ex[i], ex_padding), dim=-1)
else:
batch_ex[i] = batch_ex[i][:padding_size]
# [tensor, tensor, ...] -> tensor, dim: [tensor_size, ...]
batch_ex = torch.stack(batch_ex)
return batch_ex
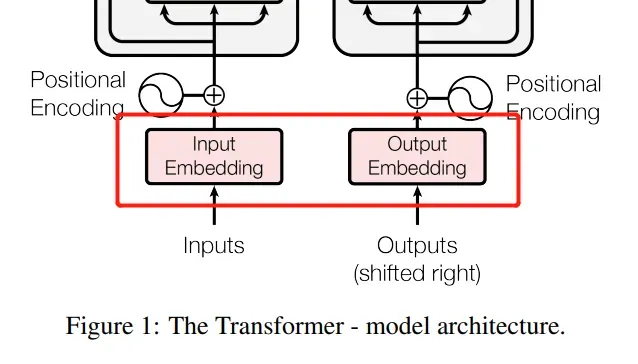
然后定义Embedding层,它可以从词的id映射到词的向量。由于我这里vocab_size默认Encoder字典和Decoder字典一样大,所以只需要定义一个。(最后会解释,先不必纠结这个细节)
class Embedding(nn.Module):
def __init__(self, config):
super(Embedding, self).__init__()
# 一个普通的 embedding层,我们可以通过设置padding_idx=config.PAD 来实现论文中的 padding_mask
self.embedding = nn.Embedding(
config.vocab_size, config.d_model, padding_idx=config.PAD)
def forward(self, x):
# 根据每个句子的长度,进行padding,短补长截
# x: [batch_size, seq_len, vocab_size]
x = self.embedding(x) # [batch_size, seq_len, d_model]
return x
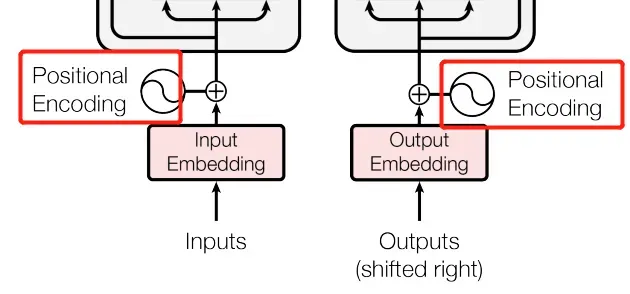
位置编码:
class Positional_Encoding(nn.Module):
def __init__(self, d_model):
super(Positional_Encoding, self).__init__()
self.d_model = d_model
def forward(self, seq_len, embedding_dim):
positional_encoding = torch.zeros(seq_len, embedding_dim)
for pos in range(positional_encoding.shape[0]):
for i in range(positional_encoding.shape[1]):
if i % 2 == 0:
positional_encoding[pos][i] = torch.sin(
torch.tensor(pos / (10000 ** (2 * i / self.d_model)))
)
else:
positional_encoding[pos][i] = torch.cos(
torch.tensor(pos / (10000 ** (2 * i / self.d_model)))
)
return positional_encoding
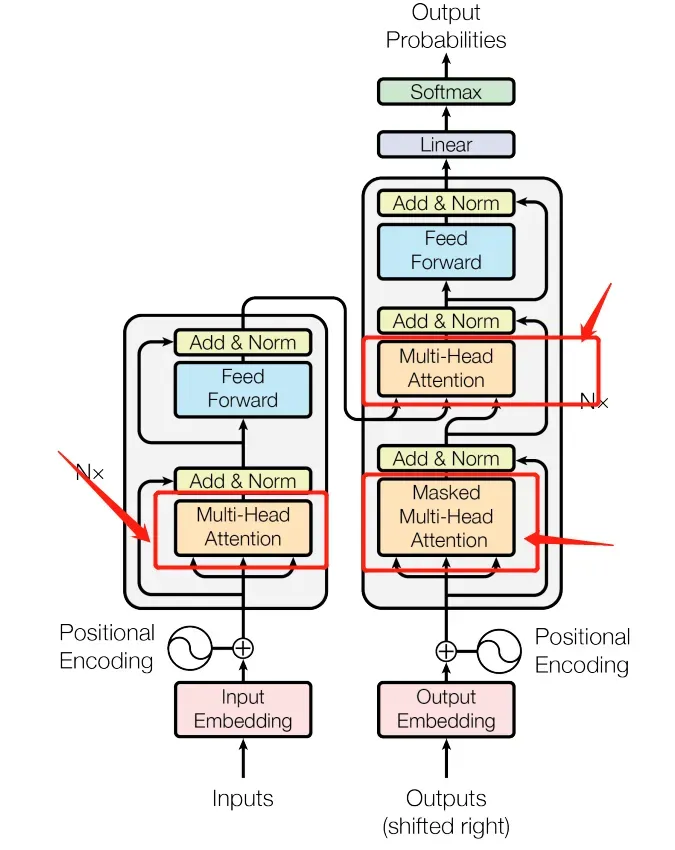
多头注意力机制(论文图中橙色部分, 包括mask和无mask的),这里由于multihead-attention和mask multihead-attention基本一样,就别就是有无mask而已,这里通过参数requires_mask控制即可。
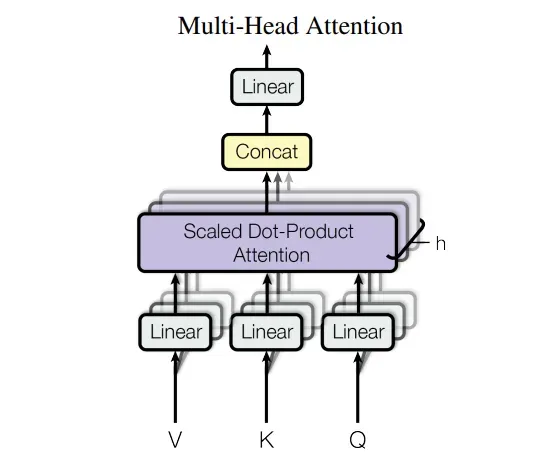
class Mutihead_Attention(nn.Module):
def __init__(self, d_model, dim_k, dim_v, n_heads):
super(Mutihead_Attention, self).__init__()
self.dim_v = dim_v
self.dim_k = dim_k
self.n_heads = n_heads
self.q = nn.Linear(d_model, dim_k)
self.k = nn.Linear(d_model, dim_k)
self.v = nn.Linear(d_model, dim_v)
self.fc = nn.Linear(dim_v, d_model)
self.norm_fact = 1 / (d_model ** 0.5)
self.softmax = nn.Softmax(dim=-1)
def generate_mask(self, dim):
# 此处是 sequence mask ,防止 decoder窥视后面时间步的信息。
# padding mask 在数据输入模型之前完成。
# matirx = np.ones((dim, dim))
# mask = torch.Tensor(np.tril(matirx))
matrix = torch.ones(dim, dim)
mask = torch.tril(matrix)
"""
[[1., 0., 0.],
[1., 1., 0.],
[1., 1., 1.]]
"""
return mask == 1
def forward(self, x, y, requires_mask=False):
assert self.dim_k % self.n_heads == 0 and self.dim_v % self.n_heads == 0
# size of x : [batch_size * seq_len * batch_size]
# 对 x 进行自注意力
# [n_heads, batch_size, seq_len, dim_k]
Q = self.q(x).reshape(-1, x.shape[0],
x.shape[1], self.dim_k // self.n_heads)
# print('Q.shape:', Q.shape)
# [n_heads, batch_size, seq_len, dim_k]
K = self.k(x).reshape(-1, x.shape[0],
x.shape[1], self.dim_k // self.n_heads)
# print('K.shape:', K.shape)
# [n_heads, batch_size, seq_len, dim_k]
V = self.v(y).reshape(-1, y.shape[0],
y.shape[1], self.dim_v // self.n_heads)
# print('V.shape:', V.shape)
# [n_heads, batch_size, seq_len, seq_len]
attention_score = torch.matmul(
Q, K.permute(0, 1, 3, 2)) * self.norm_fact
attention_score = self.softmax(attention_score)
if requires_mask:
mask = self.generate_mask(x.shape[1])
# masked_fill 函数中,对Mask位置为True的部分进行Mask
# 注意这里的小Trick,不需要将Q,K,V 分别MASK,只MASK Softmax之前的结果就好了
attention_score.masked_fill(mask, value=float("-inf"))
# print('attention_score.shape:', attention_score.shape)
# print('\n')
# [batch_size, seq_len, dim_k]
output = torch.matmul(attention_score, V).reshape(
y.shape[0], y.shape[1], -1)
# print("Attention output shape : {}".format(output.shape))
# [batch_size, seq_len, d_model]
output = self.fc(output)
# print('output.shape:', output.shape)
return output
前馈层
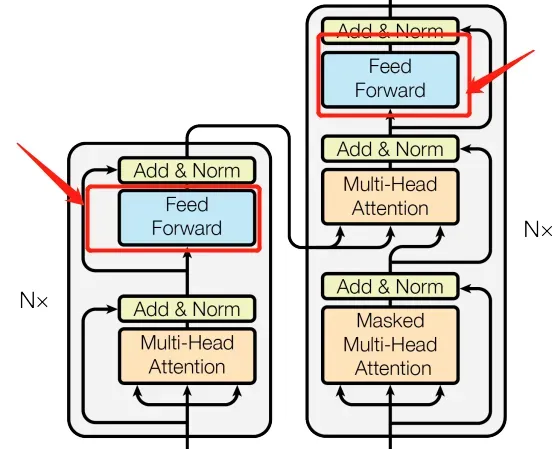
class Feed_Forward(nn.Module):
def __init__(self, input_dim, hidden_dim=2048):
super(Feed_Forward, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, input_dim)
self.relu = nn.ReLU()
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
add_norm层,就是残差和 加上 归一化, 虽然本身只有论文图中的黄色部分,但是为了方便起见,会把Feed Forward模块或者多头注意力模块也传进来。
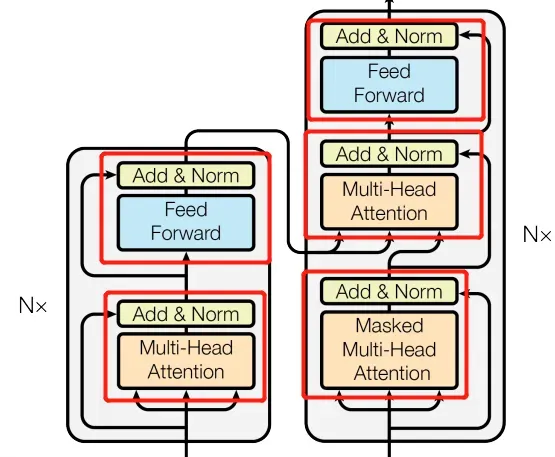
class Add_Norm(nn.Module):
def __init__(self, config):
super(Add_Norm, self).__init__()
self.dropout = nn.Dropout(config.p)
def forward(self, x, sub_layer, **kwargs):
sub_output = sub_layer(x, **kwargs)
x = self.dropout(x + sub_output)
layer_norm = nn.LayerNorm(x.shape[1:])
out = layer_norm(x)
return out
编码器
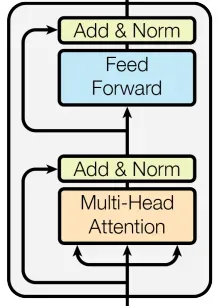
class Encoder(nn.Module):
def __init__(self, config):
super(Encoder, self).__init__()
self.config = config
self.positional_encoding = Positional_Encoding(config.d_model)
self.muti_atten = Mutihead_Attention(
config.d_model, config.dim_k, config.dim_v, config.n_heads)
self.feed_forward = Feed_Forward(config.d_model)
self.add_norm = Add_Norm(config=config)
def forward(self, x): # [batch_size, seq_len, d_model]
x += self.positional_encoding(x.shape[1], self.config.d_model)
x = self.add_norm(x, self.muti_atten, y=x)
x = self.add_norm(x, self.feed_forward)
return x
解码器
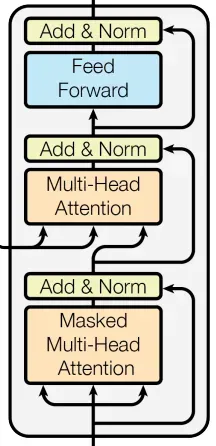
class Decoder(nn.Module):
def __init__(self, config):
super(Decoder, self).__init__()
self.config = config
self.positional_encoding = Positional_Encoding(config.d_model)
self.muti_atten = Mutihead_Attention(
config.d_model, config.dim_k, config.dim_v, config.n_heads)
self.feed_forward = Feed_Forward(config.d_model)
self.add_norm = Add_Norm(config=config)
def forward(self, x, encoder_output): # [batch_size, seq_len, d_model]
x += self.positional_encoding(x.shape[1], self.config.d_model)
# 第一个 sub_layer
output = self.add_norm(x, self.muti_atten, y=x, requires_mask=True)
# 第二个 sub_layer, 不需要mask
output = self.add_norm(
x, self.muti_atten, y=encoder_output, requires_mask=False)
# 第三个 sub_layer
output = self.add_norm(output, self.feed_forward)
return output
一个Transformer_layer
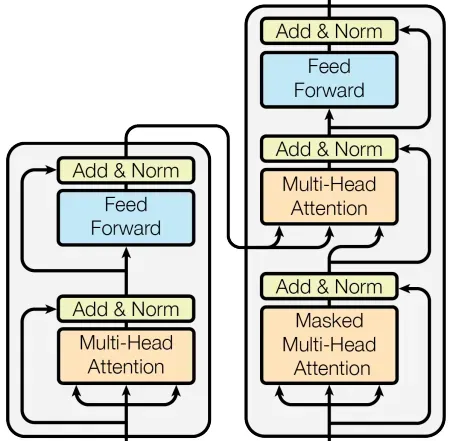
class Transformer_layer(nn.Module):
def __init__(self, config):
super(Transformer_layer, self).__init__()
self.encoder = Encoder(config)
self.decoder = Decoder(config)
def forward(self, x):
x_input, x_output = x
encoder_output = self.encoder(x_input)
decoder_output = self.decoder(x_output, encoder_output)
return (encoder_output, decoder_output)
Transformer模型
class Transformer(nn.Module):
def __init__(self, config):
super(Transformer, self).__init__()
self.embedding_input = Embedding(config=config)
self.embedding_output = Embedding(config=config)
self.output_dim = config.output_dim
self.linear = nn.Linear(config.d_model, config.output_dim)
self.softmax = nn.Softmax(dim=-1)
self.model = nn.Sequential(*[Transformer_layer(config=config) for _ in range(config.N)])
def forward(self, x):
x_input, x_output = x
x_input = self.embedding_input(x_input)
x_output = self.embedding_output(x_output)
_, output = self.model((x_input, x_output))
output = self.linear(output)
output = self.softmax(output)
return output
我们随机生成两个句子(编码器两个,解码器两个), 即此时batch_size=2
config = Config()
# 假设输入的句子单词个数为5
input_seq = 5
# 目标输出的句子单词个数为4
output_seq = 4
input_idx = [torch.randint(1, config.vocab_size, (input_seq,))]
input_idx.append(torch.randint(1, config.vocab_size, (input_seq + 2,)))
output_idx = [torch.randint(1, config.vocab_size, (output_seq,))]
output_idx.append(torch.randint(1, config.vocab_size, (output_seq + 2,)))
input_idx = padding_process(input_idx, padding_size=config.padding_size).long()
output_idx = padding_process(output_idx, padding_size=config.padding_size).long()
print('input_idx.shape: ', input_idx.shape)
print('output_idx.shape:', output_idx.shape)
喂给模型
model = Transformer(config=config)
model_output = model((input_idx, output_idx))
# [batch_size, seq_len, vocab_size]
print(model_output.shape)

这里想提一下,其实Encoder和Decoder字典大小vocab_size是可以不同的。(例如你在做中文 -> 英文的时候)本例子中的是相同的,面向的任务就是同种语言或者规定让两种语言字典大小一致。
其实只要修改一下config类的参数,然后在各个定义类想清楚是origin_vocab_size还是target_vocab_size就可以了。大致代码差不多。
完整代码
# -*- coding: UTF-8 -*-
"""
@Author: Yifx
@Contact: Xxuyifan1999@163.com
@Time: 2021/9/16 20:02
@Software: PyCharm
@Detail: origin author
https://mp.weixin.qq.com/s/FmlGr4t0Jr343JJyQTMDKQ
@Author: Andy Dennis
@Time: 2022/1/17
@Software: Vscode
@Detail: 修改了一些使用numpy实现的代码,以及一些代码风格等, 修改了代码一些小问题
"""
import torch
import torch.nn as nn
import numpy as np
import math
class Config(object):
def __init__(self, vocab_size=2000, d_model=512, n_heads=8, padding_size=30, N=6,
dropout=0.1, output_dim=2000):
self.vocab_size = vocab_size
self.d_model = d_model # 模型隐式维度,论文是512
self.n_heads = n_heads # 多头注意力
assert self.d_model % self.n_heads == 0
self.dim_k = self.d_model // self.n_heads
self.dim_v = self.d_model // self.n_heads
self.padding_size = padding_size
self.PAD = 0 # 填充的词的idx
self.UNK = 1 # 词典没出现过的词的idx
self.N = N # 多少个transformer layer
self.p = dropout # Add&Norm那里的dropout率
self.output_dim = output_dim # 最终输出的隐式维度
def padding_process(batch_ex, padding_size=None):
"""
batch_ex: list[Tensor], [batch_size, seq_len(x)], 注:可能样本sel_len间不同
return: batch_ex:Tensor, [batch_size, padding_size]
"""
assert type(batch_ex) == list
if padding_size is None:
max_len = 0
for ex in batch_ex:
max_len = max(len(ex), max_len)
padding_size = max_len
for i in range(len(batch_ex)):
if len(batch_ex[i]) < padding_size:
ex_padding = torch.tensor([config.PAD] * (padding_size - len(batch_ex[i])))
batch_ex[i] = torch.cat((batch_ex[i], ex_padding), dim=-1)
else:
batch_ex[i] = batch_ex[i][:padding_size]
# [tensor, tensor, ...] -> tensor, dim: [tensor_size, ...]
batch_ex = torch.stack(batch_ex)
return batch_ex
class Embedding(nn.Module):
def __init__(self, config):
super(Embedding, self).__init__()
# 一个普通的 embedding层,我们可以通过设置padding_idx=config.PAD 来实现论文中的 padding_mask
self.embedding = nn.Embedding(
config.vocab_size, config.d_model, padding_idx=config.PAD)
def forward(self, x):
# 根据每个句子的长度,进行padding,短补长截
# x: [batch_size, seq_len, vocab_size]
x = self.embedding(x) # [batch_size, seq_len, d_model]
return x
class Positional_Encoding(nn.Module):
def __init__(self, d_model):
super(Positional_Encoding, self).__init__()
self.d_model = d_model
def forward(self, seq_len, embedding_dim):
positional_encoding = torch.zeros(seq_len, embedding_dim)
for pos in range(positional_encoding.shape[0]):
for i in range(positional_encoding.shape[1]):
if i % 2 == 0:
positional_encoding[pos][i] = torch.sin(
torch.tensor(pos / (10000 ** (2 * i / self.d_model)))
)
else:
positional_encoding[pos][i] = torch.cos(
torch.tensor(pos / (10000 ** (2 * i / self.d_model)))
)
return positional_encoding
class Mutihead_Attention(nn.Module):
def __init__(self, d_model, dim_k, dim_v, n_heads):
super(Mutihead_Attention, self).__init__()
self.dim_v = dim_v
self.dim_k = dim_k
self.n_heads = n_heads
self.q = nn.Linear(d_model, dim_k)
self.k = nn.Linear(d_model, dim_k)
self.v = nn.Linear(d_model, dim_v)
self.fc = nn.Linear(dim_v, d_model)
self.norm_fact = 1 / (d_model ** 0.5)
self.softmax = nn.Softmax(dim=-1)
def generate_mask(self, dim):
# 此处是 sequence mask ,防止 decoder窥视后面时间步的信息。
# padding mask 在数据输入模型之前完成。
# matirx = np.ones((dim, dim))
# mask = torch.Tensor(np.tril(matirx))
matrix = torch.ones(dim, dim)
mask = torch.tril(matrix)
"""
[[1., 0., 0.],
[1., 1., 0.],
[1., 1., 1.]]
"""
return mask == 1
def forward(self, x, y, requires_mask=False):
assert self.dim_k % self.n_heads == 0 and self.dim_v % self.n_heads == 0
# size of x : [batch_size * seq_len * batch_size]
# 对 x 进行自注意力
# [n_heads, batch_size, seq_len, dim_k]
Q = self.q(x).reshape(-1, x.shape[0],
x.shape[1], self.dim_k // self.n_heads)
# print('Q.shape:', Q.shape)
# [n_heads, batch_size, seq_len, dim_k]
K = self.k(x).reshape(-1, x.shape[0],
x.shape[1], self.dim_k // self.n_heads)
# print('K.shape:', K.shape)
# [n_heads, batch_size, seq_len, dim_k]
V = self.v(y).reshape(-1, y.shape[0],
y.shape[1], self.dim_v // self.n_heads)
# print('V.shape:', V.shape)
# [n_heads, batch_size, seq_len, seq_len]
attention_score = torch.matmul(
Q, K.permute(0, 1, 3, 2)) * self.norm_fact
attention_score = self.softmax(attention_score)
if requires_mask:
mask = self.generate_mask(x.shape[1])
# masked_fill 函数中,对Mask位置为True的部分进行Mask
# 注意这里的小Trick,不需要将Q,K,V 分别MASK,只MASK Softmax之前的结果就好了
attention_score.masked_fill(mask, value=float("-inf"))
# print('attention_score.shape:', attention_score.shape)
# print('\n')
# [batch_size, seq_len, dim_k]
output = torch.matmul(attention_score, V).reshape(
y.shape[0], y.shape[1], -1)
# print("Attention output shape : {}".format(output.shape))
# [batch_size, seq_len, d_model]
output = self.fc(output)
# print('output.shape:', output.shape)
return output
class Feed_Forward(nn.Module):
def __init__(self, input_dim, hidden_dim=2048):
super(Feed_Forward, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, input_dim)
self.relu = nn.ReLU()
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
class Add_Norm(nn.Module):
def __init__(self, config):
super(Add_Norm, self).__init__()
self.dropout = nn.Dropout(config.p)
def forward(self, x, sub_layer, **kwargs):
sub_output = sub_layer(x, **kwargs)
x = self.dropout(x + sub_output)
layer_norm = nn.LayerNorm(x.shape[1:])
out = layer_norm(x)
return out
class Encoder(nn.Module):
def __init__(self, config):
super(Encoder, self).__init__()
self.config = config
self.positional_encoding = Positional_Encoding(config.d_model)
self.muti_atten = Mutihead_Attention(
config.d_model, config.dim_k, config.dim_v, config.n_heads)
self.feed_forward = Feed_Forward(config.d_model)
self.add_norm = Add_Norm(config=config)
def forward(self, x): # [batch_size, seq_len, d_model]
x += self.positional_encoding(x.shape[1], self.config.d_model)
x = self.add_norm(x, self.muti_atten, y=x)
x = self.add_norm(x, self.feed_forward)
return x
# 在 Decoder 中,Encoder的输出作为Query和KEy输出的那个东西。即 Decoder的Input作为V。此时是可行的
# 因为在输入过程中,我们有一个padding操作,将Inputs和Outputs的seq_len这个维度都拉成一样的了
# 我们知道,QK那个过程得到的结果是 [batch_size, seq_len, seq_len] .既然 seq_len 一样,那么我们可以这样操作
# 这样操作的意义是,Outputs 中的 token 分别对于 Inputs 中的每个token作注意力
class Decoder(nn.Module):
def __init__(self, config):
super(Decoder, self).__init__()
self.config = config
self.positional_encoding = Positional_Encoding(config.d_model)
self.muti_atten = Mutihead_Attention(
config.d_model, config.dim_k, config.dim_v, config.n_heads)
self.feed_forward = Feed_Forward(config.d_model)
self.add_norm = Add_Norm(config=config)
def forward(self, x, encoder_output): # [batch_size, seq_len, d_model]
x += self.positional_encoding(x.shape[1], self.config.d_model)
# 第一个 sub_layer
output = self.add_norm(x, self.muti_atten, y=x, requires_mask=True)
# 第二个 sub_layer, 不需要mask
output = self.add_norm(
x, self.muti_atten, y=encoder_output, requires_mask=False)
# 第三个 sub_layer
output = self.add_norm(output, self.feed_forward)
return output
class Transformer_layer(nn.Module):
def __init__(self, config):
super(Transformer_layer, self).__init__()
self.encoder = Encoder(config)
self.decoder = Decoder(config)
def forward(self, x):
x_input, x_output = x
encoder_output = self.encoder(x_input)
decoder_output = self.decoder(x_output, encoder_output)
return (encoder_output, decoder_output)
class Transformer(nn.Module):
def __init__(self, config):
super(Transformer, self).__init__()
self.embedding_input = Embedding(config=config)
self.embedding_output = Embedding(config=config)
self.output_dim = config.output_dim
self.linear = nn.Linear(config.d_model, config.output_dim)
self.softmax = nn.Softmax(dim=-1)
self.model = nn.Sequential(*[Transformer_layer(config=config) for _ in range(config.N)])
def forward(self, x):
x_input, x_output = x
x_input = self.embedding_input(x_input)
x_output = self.embedding_output(x_output)
_, output = self.model((x_input, x_output))
output = self.linear(output)
output = self.softmax(output)
return output
# def one_hot_batch(batch_ex, vocab_size):
# # [tensor, tensor, ...] 不同tensor长度不等长
# # print(batch_ex[0])
# batch_ex_one_hot = torch.stack([
# nn.functional.one_hot(batch_ex[i].long(), num_classes=vocab_size) for i in range(batch_ex.shape[0])
# ])
# return batch_ex_one_hot
if __name__ == '__main__':
# pe = Positional_Encoding(4)
# print(pe(2, 3))
config = Config()
# 假设输入的句子单词个数为5
input_seq = 5
# 目标输出的句子单词个数为4
output_seq = 4
input_idx = [torch.randint(1, config.vocab_size, (input_seq,))]
input_idx.append(torch.randint(1, config.vocab_size, (input_seq + 2,)))
output_idx = [torch.randint(1, config.vocab_size, (output_seq,))]
output_idx.append(torch.randint(1, config.vocab_size, (output_seq + 2,)))
input_idx = padding_process(input_idx, padding_size=config.padding_size).long()
output_idx = padding_process(output_idx, padding_size=config.padding_size).long()
print('input_idx.shape: ', input_idx.shape)
print('output_idx.shape:', output_idx.shape)
# 有Embedding层不需要one-hot
# input_onehot_idx = one_hot_batch(input_idx, config.vocab_size)
# output_onehot_idx = one_hot_batch(output_idx, config.vocab_size)
# print('input_onehot_idx.shape: ', input_onehot_idx.shape)
# print('output_onehot_idx.shape:', output_onehot_idx.shape)
# embedding = Embedding(vocab_size=config.vocab_size)
# input_embedding = embedding(input_idx)
# print(input_embedding.shape)
model = Transformer(config=config)
model_output = model((input_idx, output_idx))
# [batch_size, seq_len, vocab_size]
print(model_output.shape)
版权声明:本文为博主Andy Dennis原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_43850253/article/details/122555264