转自微信公众号:嵌入式单片机之家

有多王炸 ?
GPT-4 可以接受文本和图像输入,允许用户指定任何视觉或语言任务。具体来说,它在给定文本和图像输入的情况下能够生成文本输出(自然语言、代码等)。在一系列其它领域——包括文本和照片、图表或屏幕截图的文档中,GPT-4 展示了与纯文本输入类似的功能。
比3.5版本好在哪?
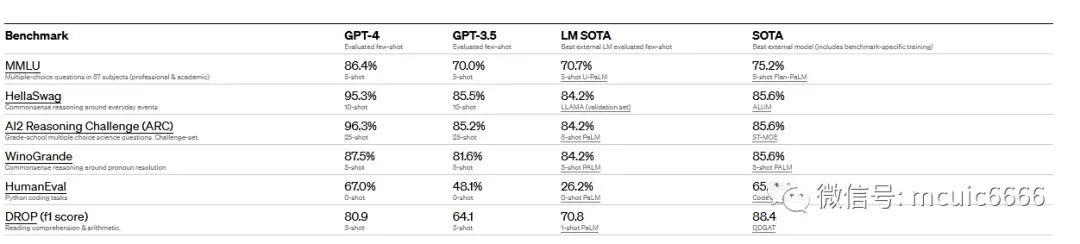
GPT-4 是一个大型多模态模型(接受图像和文本输入,发出文本输出),虽然在许多现实世界场景中的能力不如人类,但在各种专业和学术基准上表现出人类水平的表现。OpenAI花了 6 个月的时间对对抗性测试程序和 ChatGPT 的经验教训迭代调整 GPT-4,从而在真实性、可控性和拒绝超出护栏方面取得了有史以来最好的结果(尽管远非完美)。在过去的两年里,OpenAI重建了整个堆栈结构,并与 Azure 共同设计了一台超级计算机。在GPT-3.5的基础上,大量测试与修复了一些错误并进行改进。结果,GPT-4训练运行前所未有地稳定,成为能够提前准确预测其训练性能的第一个大型模型。随着OpenAI继续专注于扩展和完善相关方法,将能够越来越多地提前预测和准备未来的能力——这对安全至关重要。
一、模拟考试测试
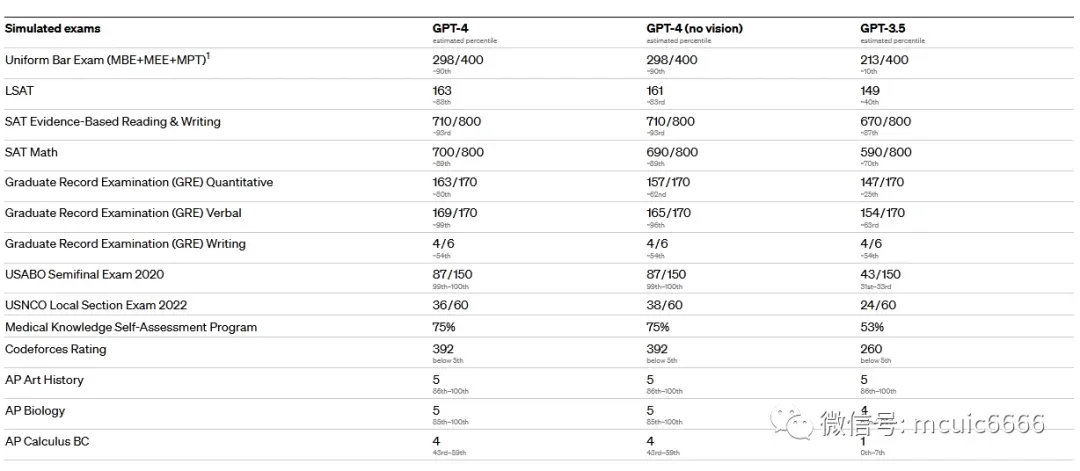
例如,在为人类设计的模拟考试中:它通过模拟律师考试、奥林匹克竞赛、 AP 自由回答问题、2022-2023 年版本练习考试中,分数在应试者的前 10% 左右;相比之下,GPT-3.5 的得分在倒数 10% 左右。
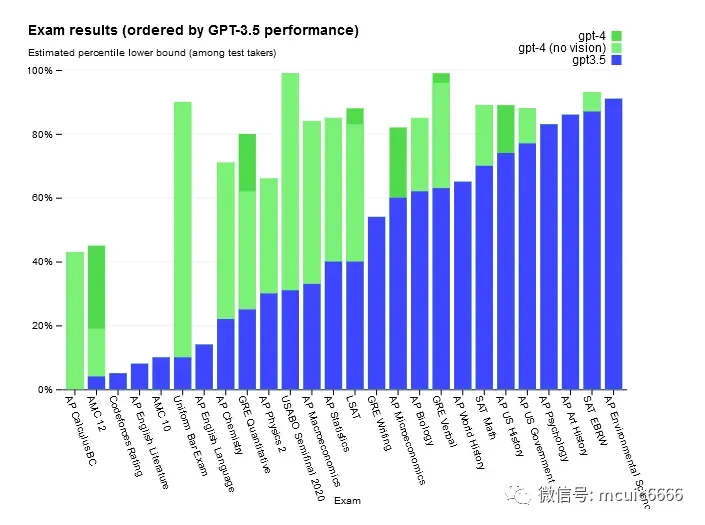
二、大型语言模型推理
三、机器翻译
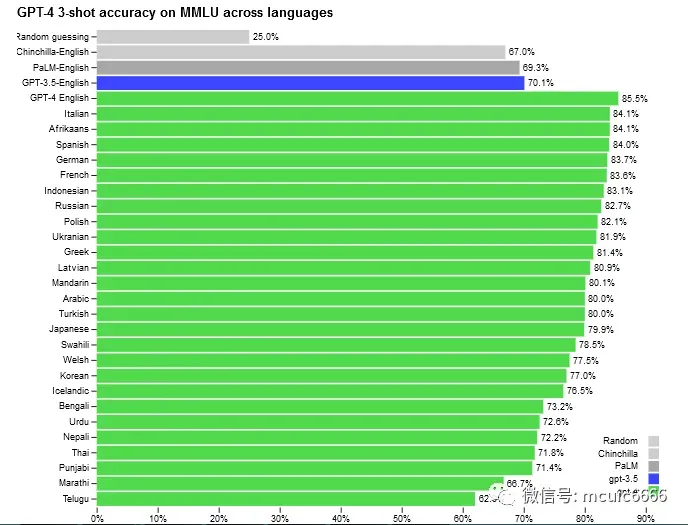
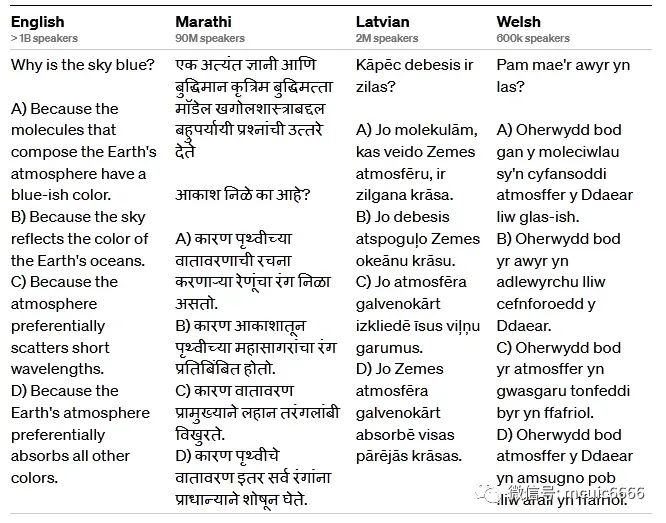
使用 Azure Translate将一套涵盖 57 个主题的 14,000 个多项选择题——翻译成26种语言。24 种中,GPT-4 优于 GPT-3.5 和其他 LLM(Chinchilla、PaLM)的英语语言性能,包括拉脱维亚语、威尔士语和斯瓦希里语语言。
四、其他
在售后支持、销售、内容审核和编程等功能都由于GPT3.5。
GPT-4的新能力
一、Visual inputs: VGA charger
能够指出图像的笑点,描述每一格的内容。输入一张由三张图片拼成的图,用户输入“这张图有什么奇怪的地方?一张图一张图地描述”,GPT-4会分别对每张图中的内容进行描述,并指出这幅图把一个大而过时的VGA接口插入一个小而现代的智能手机充电端口是荒谬的。

二、Visual inputs: chart reasoning
能够对图表进行分析和总结。用户问格鲁吉亚和西亚的平均每日肉类消费量总和是多少,让GPT-4在给答案前提供一个循序渐进的推理,GPT-4也能按需作答。

三、 Visual inputs: École Polytechnique exam question
能够一步一步的解答物理问题,可以根据识别到图片的内容回到相对应的问题。用户可以直接给一张考试题的照片,让GPT-4一步步思考作答。
四、Visual inputs: extreme ironing
能够找出违和的地方。当你问“这张图片有什么不寻常之处”时,它可以从图片的内容告诉你这位男人在出租车上熨衣服的照片的违和之处。

五、Visual inputs: pixels to paper summaries
能够读取内容并总结归纳。给几张论文的照片,GPT-4可以做总结,也可以对用户指定的图片的内容进行展开解释。从此以后,你的文献阅读不用愁了。

六、Visual inputs: chicken nugget map
输入炸鸡块摆成的世界地图,让GPT-4解释图中的模因(meme),GPT-4回答说这是个笑话,结合了太空中的地球照片和鸡块这两个不相关的东西,能够进行科幻创作。

七、Visual inputs: moar layers
描述统计学习和神经网络的差异。让GPT-4解释这张漫画,GPT-4认为它讽刺了统计学习和神经网络在提高模型性能方面的差异。

举几个简单的例子,比如下面这张照片,
再比如下面这几张照片, 比如第一张猫的照片,询问为什么好笑?它给出的回答是,因为猫咪带着一个微笑的面具;
再比如5+4的照片,可以直接告诉你答案;一个时钟的照片,可以直接告诉你时间。
除了识别以上类似的图片内容以外,GPT-4还可以识别手绘的网页草图,然后直接根据草图写出网页前段代码。
操纵性与限制
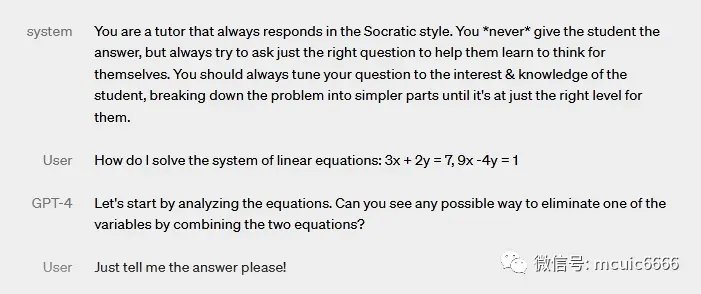
我们可以定义 AI 的行为,包括可操纵性。与具有固定冗长、语气和风格的经典 ChatGPT 个性不同,我们现在可以通过在“系统”消息中描述这些方向来规定他们的 AI 的风格和任务。
尽管功能强大,但 GPT-4 与早期的 GPT 模型具有相似的局限性。最重要的是,它仍然不完全可靠(它“幻觉”事实并出现推理错误)。
在使用语言模型输出时应格外小心,特别是在高风险上下文中,使用符合特定用例需求的确切协议(例如人工审查、附加上下文的基础或完全避免高风险使用) .
虽然仍然是一个真正的问题,但 GPT-4 相对于以前的模型(它们本身在每次迭代中都在改进)显着减少了幻觉。
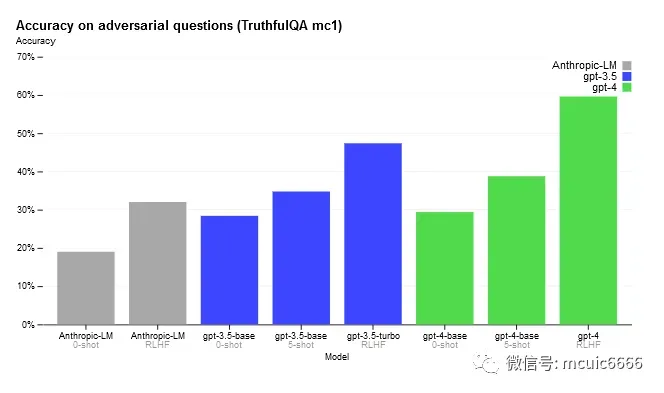
在对抗性真实性评估中,GPT-4 的得分比最新的 GPT-3.5 高 40%:它测试了模型将事实与一组对抗性选择的错误陈述分开的能力。
GPT-4 基本模型在此任务上仅比 GPT-3.5 略好;然而,在 RLHF 后训练(应用与 GPT-3.5 相同的过程)之后,存在很大差距。、
比如一些例子,GPT-4 拒绝选择俗语(你不能教老狗新把戏),但它仍然会遗漏细微的细节(猫王不是演员的儿子)。
该模型的输出可能存在各种偏差——虽然官方在这些方面取得了进展,但还有更多工作要做。如何让官方构建的 AI 系统具有合理的默认行为,以反映广泛的用户价值观,允许这些系统在广泛的范围内进行定制,并就这些范围应该是什么获得公众意见,有很大进步空间。
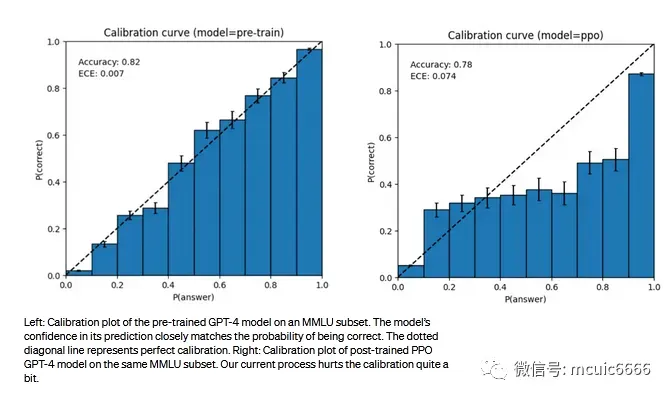
GPT-4 普遍缺乏对绝大部分数据中断后(2021 年 9 月)发生的事件的了解,并且不从其经验中吸取教训。它有时会犯简单的推理错误,这些错误似乎与跨多个领域的能力不相称,或者在接受用户明显的虚假陈述时过于轻信。
有时它会像人类一样在难题上失败,例如在它生成的代码中引入安全漏洞。GPT-4 也可能自信地在其预测中犯错,在可能出错时不注意仔细检查工作。有趣的是,基础预训练模型经过高度校准(其对答案的预测置信度通常与正确概率相匹配)。然而,通过我们目前的训练后过程,校准减少了。
风险与缓解措施
官方一直在对 GPT-4 进行迭代,以使其从训练开始就更安全、更一致,工作包括选择和过滤预训练数据、评估和专家参与、模型安全性改进以及监控和执行。
GPT-4 会带来与之前模型类似的风险,例如生成有害建议、错误代码或不准确信息。但是,GPT-4 的附加功能会带来新的风险面。
为了了解这些风险的程度,官方聘请了 50 多位来自 AI 对齐风险、网络安全、生物风险、信任和安全以及国际安全等领域的专家来对模型进行对抗性测试。这些专家的反馈和数据用于我们对模型的缓解和改进;
例如,我们收集了额外的数据来提高 GPT-4 拒绝有关如何合成危险化学品的请求的能力。GPT-4 在 RLHF 训练期间加入了额外的安全奖励信号,以通过训练模型拒绝对此类内容的请求来减少有害输出(如我们的使用指南所定义)。

奖励由 GPT-4 零样本分类器提供,该分类器根据安全相关提示判断安全边界和完成方式。为了防止模型拒绝有效请求,我们从各种来源(例如,标记的生产数据、人工红队、模型生成的提示)收集了多样化的数据集,并对两者应用安全奖励信号(具有正值或负值) 允许和不允许的类别。
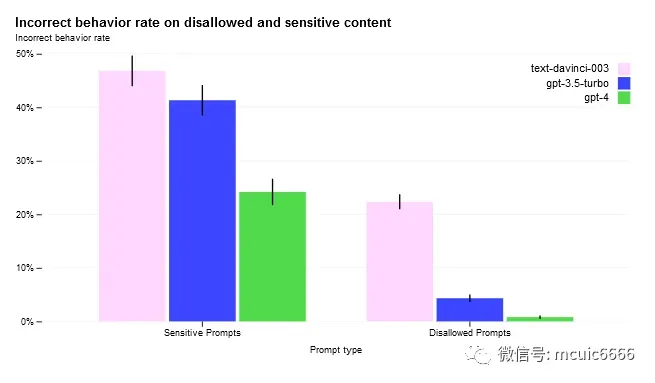
与 GPT-3.5 相比,我们的缓解措施显着改善了 GPT-4 的许多安全特性。
与 GPT-3.5 相比,我们已将模型响应不允许内容请求的倾向降低了 82%,
并且 GPT-4 根据我们的政策响应敏感请求(例如,医疗建议和自我伤害)的频率提高了 29% .

总的来说,我们的模型级干预增加了引发不良行为的难度。
应用程序接口
GPT-4定价为每 1000/0.03或0.06 美元。默认速率限制为每分钟40k 和每分钟200 个请求。gpt-4 的上下文长度为 8,192 个。同时,提供32,768个上下文(约 50 页文本)的有限访问(版本 gpt-4-32k-0314,随着时间的推移自动更新,目前支持到 6 月 14 日 )
商业价值
▍更接近“真人”的通用智能
“曲率引擎已经吹动了发丝。”民生证券计算机分析师吕伟用《三体》里的热词来形容GPT-4的智能与进步。
在他看来,官方发布相较以往版本主要三大突破,本质上都是更接近“真人”的通用智能:
第一,像人一样更具备创造协作输出能力,具备更有创造性的写作能力,包括编歌曲、写剧本、学习用户写作风格等;第二,像人一样具备视觉输入处理分析能力,可以图文等多模态同时综合分析,给出答案;第三,像人一样具备超长文本的处理分析能力。
微软公司副总裁、微软大中华区首席运营官康容在采访中对《科创板日报》记者表示,OpenAI是微软的第三方的策略合作伙伴,从四五年前开始密切合作。OpenAI并非微软智能云Azure的首个大模型的AI服务,却引发了巨大关注,是在以下两方面实现了突破。
首先,其使用培训的数据量,远远超过包括微软在内的各个厂商模型数据量。“你可以想象AI是一个很聪明的小朋友,虽然有很多潜力,但也需要好好培养,要用大量的数据来培训。” 康容说。
其次,GPT是辅助写作(Generative Pre-trained Transformer ),从机器学习、做语言翻译的基础开始,会自己收集大量的数据,做出包括文字、图片、视频等在内的新内容。
“我们跟某国内手机厂商聊,他们希望挑战OpenAI,希望生成的图片是一个25-30岁女士模特,金头发、蓝眼睛站在稻田上,蓝天无云,拿着品牌手机。” 康容说,“GPT竟然听懂指导,把那个图片画出来了。一般来说,设计图片需要找代理公司,沟通客户需求,但有时做出来的东西不是想要的,但GPT可以提供不同版本,而且都是全新的、没有看过的东西。”
微软大中华区Azure事业部总经理陶然介绍,目前OpenAI和微软Azure服务的合作主要在三个方面。“第一,是GPT模型。要强调的是GPT模型并不等同于ChatGPT,而是一个数据模型;第二,是DALL-E 2图像生成模型,第三,是Codex代码生成模型。”
康容以医疗领域为例,“医疗会涉及很专业的深度内容。所以,某个客户如果用企业级OpenAI 做出医疗的ChatBot(聊天机器人),那个ChatBot会回答的问题,是另一个ChatBot听不懂的,因为都是通过内部企业级数据进行培训,内容会很专业。”
康容认为,未来OpenAI的模型会被应用在各个领域,生成完全不同的图片和视频,通过更聪明的机器人小助理或者ChatBot,协助员工在内部做快速、大量的数据分析,产出报告。
“比如,企业想要看国内过去三年疫情期间,国内不同地区的汽车行业或者半导体客户的成长率。这在以前,需要花个两三周、一个月的时间,整理出来的内容也不是特别完整。但借助OpenAI,可能几分钟就能整合了外部信息产出报告,效率大大提升了。虽然不一定百分百准确,但打了一个很好的基础。这是未来企业级OpenAI的价值,重点在业务上服务客户和员工。”
▍多家上市公司开展相关布局
此前,多家国内企业都纷纷宣布已与微软开展合作。其中,创意软件A股上市公司万兴科技已对接Azure OpenAI开通商用服务权限。据了解,Azure OpenAI 服务于2023年1月推出,万兴科技是国内首批获得 Azure OpenAI商用服务权限的企业。
万兴科技证券部相关负责人对《科创板日报》记者表示,目前所使用的Azure OpenAI服务为英文版本,主要给海外用户进行体验,目前对营收暂无贡献。据悉,万兴科技已推出万兴喵影、万兴优转、万兴录演等视频创意软件。“对我们而言,会更期待可支持视频生成的GPT版本的推出。”上述负责人表示。
蓝色光标则在互动平台表示,蓝色光标旗下蓝标传媒已正式宣布与微软广告达成战略合作,并成为其官方代理商;同时,公司将与微软开展基于OpenAI的技术产品合作,通过敏锐地洞察与过硬的实力使更多出海客户享受到AI发展的红利。
此外,百度、商汤科技、360等企业也在探索类ChatGPT和大模型的开发。3月14日,商汤科技发布多模态多任务通用大模型“书生(INTERN)2.5”,其图文跨模态开放任务处理能力可为自动驾驶、机器人等通用场景任务提供感知和理解能力支持。image
利用多模态多任务通用大模型辅助完成自动驾驶场景中各类任务
据商汤方面透露,“书生2.5”具备了AIGC“以文生图”的能力,可根据用户提出的文本创作需求,利用扩散模型生成算法,生成写实图像。例如借助“书生2.5”的以文生图能力帮助自动驾驶技术研发,通过生成各类真实的道路交通场景,如繁忙的城市街道、雨天拥挤的车道、马路上奔跑的狗等,生成写实的Corner Case训练数据,进而训练自动驾驶系统对Corner Case场景的感知能力上限。image
360则在互动平台表示,公司的人工智能研究院从2020年开始一直在包括类ChatGPT技术在内的AIGC技术上有持续性的投入,但截至目前,仅作为内部业务自用的生产力工具使用,各项技术指标只能做到略强于ChatGPT 2.360方面称,计划尽快推出类ChatGPT技术的demo版产品。
中信证券指出,长期来看以GPT为主的生成式预训练大模型持续升级,多模态带来更大的数据支持需求,模型计算精度逐渐提升,开放API后应用场景持续落地,对于算力的总体需求料将持续提升。
国内多家公司也在积极布局大语言模型,但是国内高端算力芯片目前比较依赖海外厂商,在高端芯片国产化背景下,中信证券建议关注国内推出及布局AI芯片/GPGPU芯片的相关公司,包括:寒武纪、龙芯中科、海光信息、景嘉微、澜起科技等。
▍在零售、汽车、金融等应用潜力巨大
针对在中国市场的规划,康容介绍,目前中国区正在与总部进行探讨。“微软在全球有70多个数据中心区域,只有三个数据中心区域部署了企业级的Azure OpenAI服务。未来,这个覆盖范围会扩大,但是以什么速度部署、在哪里部署,是需要看各个区域客户的需求有多高。因为OpenAI的服务在落地前,需要部署很多的底层服务。这件事情我们还在跟总部探讨。”
从整体应用趋势来看,零售、汽车、金融、互联网、游戏等领域的企业,均在探索ChatGPT的服务如何在企业场景里产生价值。“在全球范围内,我们看到微软Azure OpenAI商用服务的用户增长量是非常大。” 陶然说。
360创始人兼董事长周鸿祎对《科创板日报》记者表示,ChatGPT真正的能力在于是强人工智能的雏形,通用人工智能发展的奇点,“它不是为了解决某一专有领域问题,而是为了解决对人类知识进行存储和知识化。”
在具体的应用场景上,周鸿祎认为,ChatGPT更准确的定位是个人助手,在办公场景里很好用。“比如写大纲、写报告、写文章。又比如做题,甚至写代码,就算是编程的初学者也能在其帮助下写出高质量的代码。现在,ChatGPT已经具备了一定的逻辑推理能力。未来,在客服、营销、医疗等诸多场景下,都是ChatGPT很好的应用场景,能够大幅提升脑力劳动者的工作效率。”
谈及国内类ChatGPT产品的代差落后,周鸿祎指出,对中国而言,从语料上、从技术上、从战略上都可以做,中国互联网公司的工程化能力强,技术落地能力强。在国家鼓励性政策的支持下,用两三年的时间赶上ChatGPT现在的水平是绝对有机会的。
“现在,ChatGPT已经做出了样本,有开源技术做基础,并不存在难以逾越的障碍,剩下的就是时间问题。我们需要在机制上进行创新,建设更加开放的生态,加强产学研各界的合作,充分发挥中国千万级大学毕业生的优势,利用众包模式进行知识标注,去做基于人工标注的强化学习训练。此外,必须效仿App Store模式,去建设基于ChatGPT的SaaS生态,因为ChatGPT本身就是SaaS云服务,具有成本低、使用门槛低、部署难度低的优势,有可能成为新时代的操作系统,成为数字文明时代的水和电。” 周鸿祎称。
▍总结
本周两个生成式AI产品重磅发布。GPT-4是一个多模态大型语言模型,即支持图像和文本输入,以文本形式输出;由于GPT-4具有更广泛的常识和解决问题的能力,它可以更准确地解决难题。百度的生成式AI产品“文心一言”也将正式发布。
以GPT系列为代表的大型语言模型(LLM)能教会机器以统计方式理解自然语言,完成此前人类进行的内容读取和理解。随着多模态带来的模型全面化,人工智能将向着拥有人类解释能力这一目标更进一步。何去何从,我们拭目以待。
文章出处登录后可见!