
1 案例描述
案例:加载Transformers库中的BERT模型,并用它实现完形填空任务,即预测一个句子中缺失的单词。
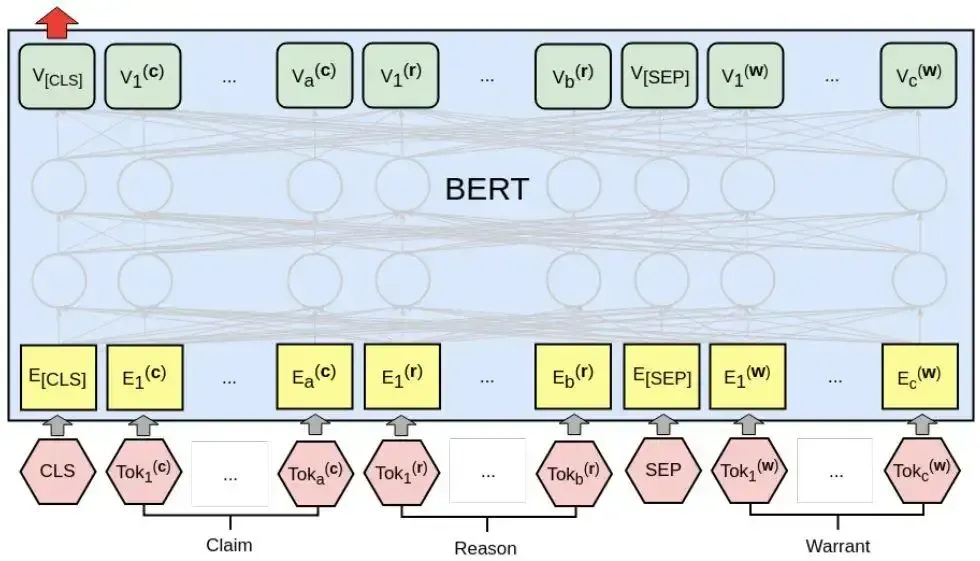
2 代码实现:使用BERT模型实现完形填空任务
2.1 代码实现:载入词表,并对输入的文本进行分词转化—BERT_MASK.py(第1部分)
import torch
from transformers import BertTokenizer, BertForMaskedLM
# 1.1 载入词表,并对输入的文本进行分词转化
# 加载预训练模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 输入文本,BERT模型需要特殊词来标定句子:
# [CLS]:标记一个段落的开始。一个段落可以有一个或多个句子,但是只能有一个[CLS]。[CLS]在BERT模型中还会被用作分类任务的输出特征。
# [SEP]:标记一个句子的结束。在一个段落中,可以有多个[SEP]。
text = "[CLS] Who is Li BiGor ? [SEP] Li BiGor is a programmer [SEP]"
tokenized_text = tokenizer.tokenize(text)
# 使用词表对输入文本进行转换。与中文分词有点类似。由于词表中不可能覆盖所有的单词,因此当输入文本中的单词不存在时,系统会使用带有通配符的单间(以“#”开头的单词)将其拆开。
print("词表转化结果:",tokenized_text)
# 词表转化结果:['[CLS]','who','is','li','big','##or','?','[SEP]','li','big','##or','is','a','programmer','[SEP]']
2.2 代码实现:遮蔽单词,并将其转换为索引值—BERT_MASK.py(第2部分)
# 1.2 遮蔽单词,并将其转换为索引值,使用标记字符[MAS]代替输入文本中索引值为8的单词,对“Li”进行遮蔽,并将整个句子中的单词转换为词表中的索引值。
masked_index = 8 # 掩码一个标记,再使用'BertForMaskedLM'预测回来
tokenized_text[masked_index] = '[MASK]' # 标记字符[MASK],是BERT模型中的特殊标识符。在BERT模型的训练过程中,会对输入文本的随机位置用[MASK]字符进行替换,并训练模型预测出[MASK]字符对应的值。
print("句子中的索引:",tokenized_text)
# 句子中的索引:['[CLS]','who','is','li','big','##or','?','[SEP]','[MASK]','big','##or','is','a','programmer','[SEP]']
# 将标记转换为词汇表索引
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
# 将输入转换为PyTorch张量
tokens_tensor = torch.tensor([indexed_tokens])
print("句子中的向量:",tokens_tensor)
# 句子中的向量:tensor([[101,2040,2003,5622,2502,2953,1029,102,103,2502,2953,2003,1037,20273,102]])2.3 代码实现:加载预训练模型,并对遮蔽单词进行预测—BERT_MASK.py(第3部分)
# 1.3 加载预训练模型,并对遮蔽单词进行预测
# 指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
# 加载预训练模型 (weights)
model = BertForMaskedLM.from_pretrained('bert-base-uncased') # 用BertForMaskedLM类加载模型,该类可以对句子中的标记字符[MASK]进行预测。
model.eval()
model.to(device)
# 段标记索引:定义输入的BertForMaskedLM类句子指示参数,用于指示输入文本中的单词是属于第一句还是属于第二句。属于第一句的单词用0来表示(一共8个),属于第二句的单词用1来表示(一共7个)。
segments_ids = [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
segments_tensors = torch.tensor([segments_ids]).to(device)
tokens_tensor = tokens_tensor.to(device)
# 预测所有的tokens
with torch.no_grad():
# 将文本和句子指示参数输入模型进行预测。
# 输出结果是一个形状为[1,15,30522]的张量。其中,1代表批次个数,15代表输入句子中的15个单词,30522是词表中单词的个数。
# 模型的结果表示词表中每个单词在句子中可能出现的概率。
outputs = model(tokens_tensor, token_type_ids=segments_tensors)
predictions = outputs[0] # [1, 15, 30522]
# 预测结果:从输出结果中取出[MASK]字符对应的预测索引值。
predicted_index = torch.argmax(predictions[0, masked_index]).item()
# 将预测索引值转换为单词。
predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]
print('预测词为:', predicted_token)
# 预测词为: li3 代码总览—BERT_MASK.py
import torch
from transformers import BertTokenizer, BertForMaskedLM
# 1.1 载入词表,并对输入的文本进行分词转化
# 加载预训练模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 输入文本,BERT模型需要特殊词来标定句子:
# [CLS]:标记一个段落的开始。一个段落可以有一个或多个句子,但是只能有一个[CLS]。[CLS]在BERT模型中还会被用作分类任务的输出特征。
# [SEP]:标记一个句子的结束。在一个段落中,可以有多个[SEP]。
text = "[CLS] Who is Li BiGor ? [SEP] Li BiGor is a programmer [SEP]"
tokenized_text = tokenizer.tokenize(text)
# 使用词表对输入文本进行转换。与中文分词有点类似。由于词表中不可能覆盖所有的单词,因此当输入文本中的单词不存在时,系统会使用带有通配符的单间(以“#”开头的单词)将其拆开。
print("词表转化结果:",tokenized_text)
# 词表转化结果:['[CLS]','who','is','li','big','##or','?','[SEP]','li','big','##or','is','a','programmer','[SEP]']
# 1.2 遮蔽单词,并将其转换为索引值,使用标记字符[MAS]代替输入文本中索引值为8的单词,对“Li”进行遮蔽,并将整个句子中的单词转换为词表中的索引值。
masked_index = 8 # 掩码一个标记,再使用'BertForMaskedLM'预测回来
tokenized_text[masked_index] = '[MASK]' # 标记字符[MASK],是BERT模型中的特殊标识符。在BERT模型的训练过程中,会对输入文本的随机位置用[MASK]字符进行替换,并训练模型预测出[MASK]字符对应的值。
print("句子中的索引:",tokenized_text)
# 句子中的索引:['[CLS]','who','is','li','big','##or','?','[SEP]','[MASK]','big','##or','is','a','programmer','[SEP]']
# 将标记转换为词汇表索引
indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
# 将输入转换为PyTorch张量
tokens_tensor = torch.tensor([indexed_tokens])
print("句子中的向量:",tokens_tensor)
# 句子中的向量:tensor([[101,2040,2003,5622,2502,2953,1029,102,103,2502,2953,2003,1037,20273,102]])
# 1.3 加载预训练模型,并对遮蔽单词进行预测
# 指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
# 加载预训练模型 (weights)
model = BertForMaskedLM.from_pretrained('bert-base-uncased') # 用BertForMaskedLM类加载模型,该类可以对句子中的标记字符[MASK]进行预测。
model.eval()
model.to(device)
# 段标记索引:定义输入的BertForMaskedLM类句子指示参数,用于指示输入文本中的单词是属于第一句还是属于第二句。属于第一句的单词用0来表示(一共8个),属于第二句的单词用1来表示(一共7个)。
segments_ids = [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
segments_tensors = torch.tensor([segments_ids]).to(device)
tokens_tensor = tokens_tensor.to(device)
# 预测所有的tokens
with torch.no_grad():
# 将文本和句子指示参数输入模型进行预测。
# 输出结果是一个形状为[1,15,30522]的张量。其中,1代表批次个数,15代表输入句子中的15个单词,30522是词表中单词的个数。
# 模型的结果表示词表中每个单词在句子中可能出现的概率。
outputs = model(tokens_tensor, token_type_ids=segments_tensors)
predictions = outputs[0] # [1, 15, 30522]
# 预测结果:从输出结果中取出[MASK]字符对应的预测索引值。
predicted_index = torch.argmax(predictions[0, masked_index]).item()
# 将预测索引值转换为单词。
predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]
print('预测词为:', predicted_token)
# 预测词为: li文章出处登录后可见!
已经登录?立即刷新