联邦学习论文阅读一:经典FedAvg
Communication-Efficient Learning of Deep Networksfrom Decentralized Data
论文地址:https://arxiv.org/pdf/1602.05629.pdf
[0]
1. Introduction
1.1 问题来源
移动设备中有大量数据适合机器学习任务,利用这些数据反过来可以改善用户体验。例如图像识别模型可以帮助用户挑选好的照片。但是这些数据具有高度私密性,并且数据量大,所以我们不可能把这些数据拿到云端服务器进行集中训练。论文提出了一种分布式机器学习方法称为联邦学习(Federal Learning),数据不出客户端,通过聚合本地计算更新来学习共享模型。
1.2 本文贡献
- 将移动设备去中心化数据的训练问题确定为重要的研究方向;
- 选择一个简单实用的算法,可以应用到设置中;
- 对所提出的方法进行广泛的实证评估。

1.3 Federal Learning理想模型
- 适合联邦学习的问题:很多问题都符合上述性质,例如:图像分类,预测未来哪些图像会被查看和共享;语言模型,改进语音识别和触摸屏文本输入

1.4 Privacy
- 与数据中心的集中训练相比,联邦学习具有明显的隐私优势。数据本身并不从客户端出来,每次只更新模型的梯度,包含的隐私内容要少得多。文末简要讨论了联邦学习和多方学习。将安全计算与差分隐私相结合的可能性。
1.5 联邦学习与传统分布式学习的区别
- 传统的分布式学习侧重于分布式学习,侧重于如何以分布式的方式训练一个大型神经网络,而数据可能仍然存储在几个大型训练中心。联邦学习更关注数据本身,利用联邦学习保证数据不是局部的,并根据数据的非IID、不平衡数据、大规模分布等特点改进联邦学习模型, 和通信限制。本文重点关注非独立同分布数据、非平衡数据和通信约束。

1.6 联邦学习公式描述
- 普通强化学习
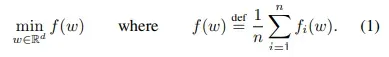
- 联合学习

K个客户端,表示第k个客户端上的数据索引
1.7 Related Work
先前的工作大部分都没有考虑到数据非独立同分布和非平衡的影响。在凸环境下一些算法考虑到了通信效率问题,本文是通过增加客户单并行性和增加客户端计算来降低通信。一些算法使用非同步的SGD算法,但在异常情况下需要大量更新。分布式一致性算法可以训练非独立同分布数据,但在有大量客户端的情况下不适合进行通信优化。
2. The FederatedAveraging Algorithm
该章节首先讨论了深度学习大部分都是基于SGD算法,在SGD算法上进行的优化改进。所以SGD可以简单直接用于联邦学习
2.1 Baseline
- Baseline: FedSGD在每一轮通信随机选择部分客户端进行单批次梯度计算,即Batch = 1,每一轮计算效率高但显然我们要进行更多轮训练,在不考虑客户端网络传输障碍等因素,FedSGD是一个同步训练模型(在中心化数据集情况下,同步模型优于异步模型)。
- Baseline训练过程: 首先根据本地数据和当前全局模型进行一次梯度下降计算本地梯度,然后服务器加权平均聚合这些梯度形成新一轮全剧模型。
2.2 FedAvg
- FedAvg: 在定义了Baseline这种训练方式之后,我们可以在本地进行多次训练,我们称这张方法为FedAvg,FedAvg的三个控制参数:
- C: 每轮执行计算的客户端比列
- E: 每一个客户端对本地数据训练次数
- B: 客户端批大小,我们设置B = ∞为单批次,即一批次训练所有本地数据
- FedSGD对应于B = ∞,E = 1
- 算法伪代码描述如下:

2.3 算法初始化
然后我们讨论当算法第一次训练时我们的模型是如何初始化的。每个客户端是单独初始化自己的训练参数还是所有客户端共享相同的初始化参数。实验验证共享初始化更好,可以减少总的训练损失。推测原因可能是客户端训练过拟合本地数据集。同时,在对梯度进行聚合时,作者发现原来的平均聚合方法也出奇的好。
3. Experimental Results
初步研究包括两个数据集三个模型族,前两个模型用于识别MNIST数据集,后一个用于实现莎士比亚作品集单词预测。
3.1 训练MNIST数据集设置
- 目的:识别图片中对应的数字
- 2NN: 一个简单的多层感知器具有两个隐藏层,每层有200个单元,使用Relu激活。总共有199210个参数。
- CNN: 两个卷积核大小为5✖️5的卷积层(第一个是32通道,第二个是64通道,每层后面都有一个2✖️2的最大池化层)。
- 数据集分区
- IDD模式: 数据先shuffe(随机打乱)然后分给100个客户端每个客户端600个样例。
- Non-IDD模型: 按数字标签,将数据集划分为200个大小为300的碎片,每个客户端两个碎片,这样绝大多数客户端就只有两位数实例。
3.2 训练莎士比亚作品集设置
- 目的:读完每一行单词后预测下一个单词
- LSTM: 将输入字符嵌入到一个已学习的8维空间中,然后通过两个LSTM层处理嵌入的字符,每层有256个节点,最后,第二个LSTM层的输出被发送到每个字符有一个节点的softmax输出层, 我们使用unroll的80个字符长度进行训练。总共有866578个参数。
- 数据集分区
- Unblanced-Non-IDD模式: 利用莎士比亚作品,按每个角色形成一个客户端,每个角色数据至少有两行,形成了1146个客户端,每个角色(客户端)前80%行数据用于训练,后20%行用于测试(四舍五入到至少一行)。
- Balanced-IDD模式: 直接将莎士比亚作品划分给1146个客户端。
3.3 Increasing parallelism
- 首先利用参数C实验客户端并行性表1显示了客户端并行性对达到目标准确率所需通信轮数的影响,C = 0表示每轮只选一个客户端进行训练(baseline),B = ∞即一批次训练所有本地数据,括号里的值表示相对应baseline的速度提升倍数,我们可以看到C = 0.1时速度有明显的提升,当C = 0.2即以上时速度并没有大的提升,所以我们基于此在收敛速度和通信效率之间做一个取舍,在接下来的实验中设置C = 0.1
3.4 Increasing computation per client
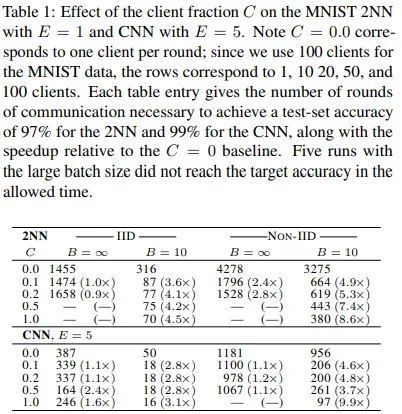
- 这个环节我们调整B和E来增加客户端计算。图2表明,每轮增加更多的本地SGD更新可以显著降低通信成本,表2量化了这些加速。B的调整对本地计算量影响不大,所以在实践中这是第一个要调整的参数。对于IDD数据每个客户端使用更多的计算将使CNN和2NN达到目标精度的轮数分别减少35倍和46倍,对于Non-IDD数据通信轮数也减少了2.8倍和3.7倍,这证明了我们的方法具有鲁棒性。
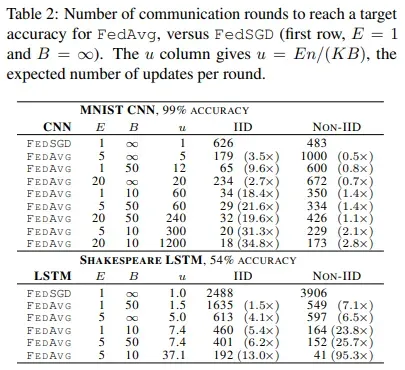

- 对于Unbalanced-Non-IDD的莎士比亚数据我们减少通信轮数倍数更多(95倍加速,而Balanced数据只有13倍加速),推测可能是某些角色有相对较大的本地数据集,使得他的训练非常有价值。
- FedAvg相比于FedSGD有更高的测试精度,不仅仅只是降低了通信轮数,精度甚至超过了中心化训练,我们推测是平均模型产生了类似Dropout的正则化效益。
3.5 Can we over-optimize on the client datasets?
- 当前模型仅仅影响每次客户端更新的初始化训练,当E -> ∞对于凸问题而言,初始条件是无关紧要的,因为最终我们都能达到最小值,即使是对于非凸问题而言,只要是初始值在同一位置,我们也会收敛到同一局部极小值。也就是说,某一轮平均可能使模型得到一个好的结果,但是另外几轮平均并不会使模型进一步改进。
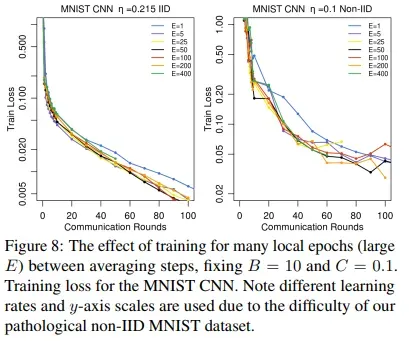
- 图3显示了E对莎士比亚数据集预测字符的影响,结果表明,在训练后期,减少本地训练周期将有助于收敛。
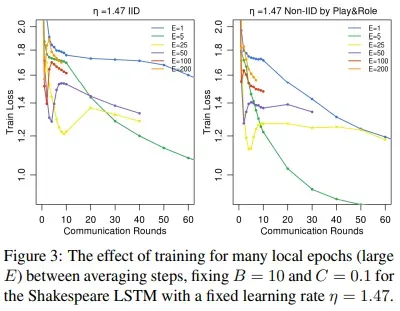
- 而在MNIST CNN上的实验,本地周期E对收敛速度影响不大如图8。
3.6 CIFAR experiments
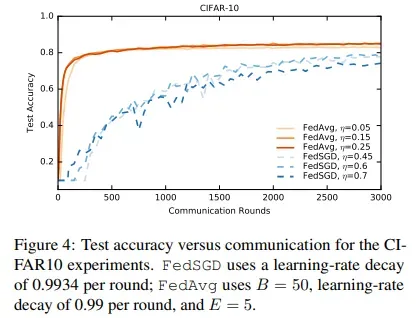
- 同时在CTFAR数据集上进行了实验,模型是TensorFlow教程中的模型包括两个卷积层,两个全连接层和一个线性传输层,大约10^6个参数。表3给出了baselineSGD、FedSGD和FedAvg达到三种不同精度目标的通信轮数。

- 图4给出了在不同学习率下FedSGD和FedAvg的曲线。
3.7 Large-scale LSTM experiments
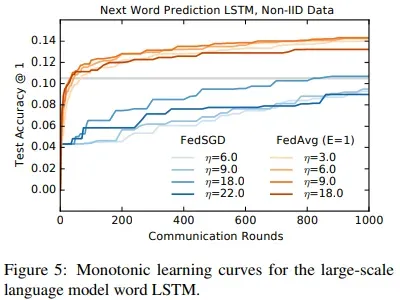
- 为了证明我们的方法解决现实问题的有效性,我们进行了大规模的单词预测任务
- 训练集包含来自大型社交网络的100万个公共帖子。我们根据作者对帖子进行分组,总共有超过50个客户端。我们将每个客户的数据集限制为最多5000个单词。模型是一个256节点的LSTM,其词汇量为10000个单词。每个单词的输入和输出嵌入为192维,并与模型共同训练;总共有4950544个参数,使用10个字符的unroll。
- 图5显示了最佳学习率曲线。
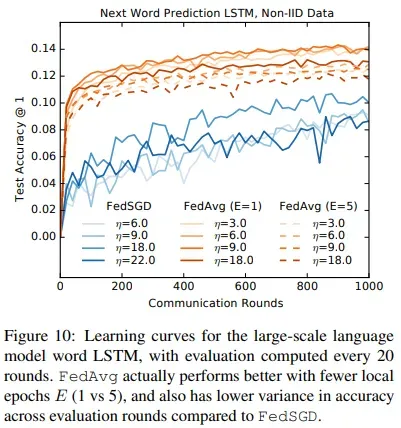
- 图10显示了FedAvg方差较低,同时E = 1取得了比E = 5更好的结果
4. Conclusions and Future Work
我们的实验表明,联邦学习可以在实践中实现,因为它可以使用相对较少的几轮通信来训练高质量的模型,这一点在各种模型体系结构上得到了证明:一个多层感知器、两个不同的卷积NNs、一个两层LSTM和一个大规模LSTM。虽然联邦学习提供了许多实用的隐私保护,但是通过差分隐私、安全多方计算提供了可以提供更有力的保障,或者他们的组合是未来工作的一个有趣方向。请注意,这两类技术最自然地应用于像FedAvg这样的同步算法。
5. 代码实现
https://github.com/WHDY/FedAvg[0]
6. 疑问
- 什么是凸神经网络目标,什么是非凸神经网络目标?
- 凸神经网络意味着可以在梯度下降的方向上找到最优解。大多数传统的机器学习问题都是凸神经网络问题。
- 非凸神经网络意味着跟随梯度下降的方向,可能找不到全局最优解,但会找到局部最优解。深度神经网络和少数传统机器学习问题是非凸神经网络问题。
- 论文中:Recent work indicates that in practice, the loss surfaces of sufficiently over-parameterized NNs are surprisingly well-behaved and in particular less prone to bad local minima than previously thought. 是什么意思?
- over-parameterized:在普通卷积层中加入depthwise卷积操作构成的over-parameterized卷积层,加速网络训练,在计算机视觉任务方面取得了不错的效果
- 这部分个人讨论参数初始化是服务端模型共享还是客户端独立进行参数初始化。结论是服务端共享初始化参数比较好,因为独立初始化可能会导致客户端模型过拟合本地训练集(局部看起来可能没有过拟合,但全局过拟合)。这句话可能只是介绍了最新的结果,提到了过拟合的解决方法。
- LSTM中unroll的含义
- unroll: 布尔值 (默认 False)。 固定LSTM输入输出数目(个人对LSTM不太了解如有错误欢迎指正)
文章出处登录后可见!