Introduction
本文 对 OpenHands – Docs 统计FLOPs && Params 的相关事项 进行 补充说明
官方源码传送门: OpenHands – Github
Prepare
Dataset
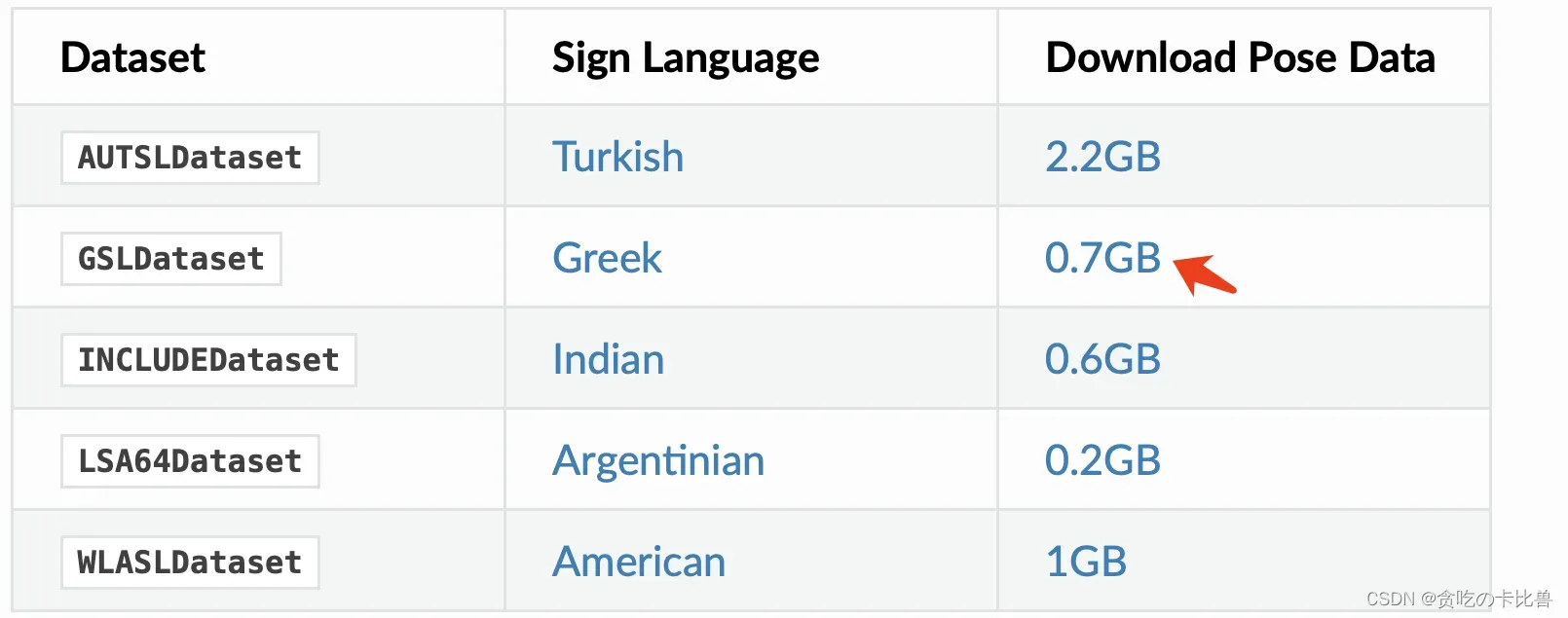
以 GSLDataset 为例,下载 && 解压 GSL.zip,目录如下:
.GSL
├── GSL_pose
│ ├── health1_signer1_rep1_glosses
│ ├── health1_signer1_rep2_glosses
│ ├── health1_signer1_rep3_glosses
│ ├── health1_signer1_rep4_glosses
│ ├── health1_signer1_rep5_glosses
... ...
│ ├── police5_signer7_rep1_glosses
│ ├── police5_signer7_rep2_glosses
│ ├── police5_signer7_rep3_glosses
│ ├── police5_signer7_rep4_glosses
│ └── police5_signer7_rep5_glosses
├── GSL_pose.zip
├── GSL_split
│ ├── GSL_continuous
│ │ ├── GSL-SD-test.txt
│ │ ├── GSL-SD-train.txt
│ │ ├── GSL-SD-val.txt
│ │ ├── bbox_for_gsl_continuous.txt
│ │ ├── greek_classes.txt
│ │ ├── gsl_split_SI_dev.csv
│ │ ├── gsl_split_SI_test.csv
│ │ └── gsl_split_SI_train.csv
│ └── GSL_isolated
│ ├── bbox_for_gsl_isolated.txt
│ ├── iso_classes.csv
│ ├── test_greek_iso.csv
│ ├── train_greek_iso.csv
│ └── val_greek_iso.csv
└── GSL_split.zip
Train checkpoints
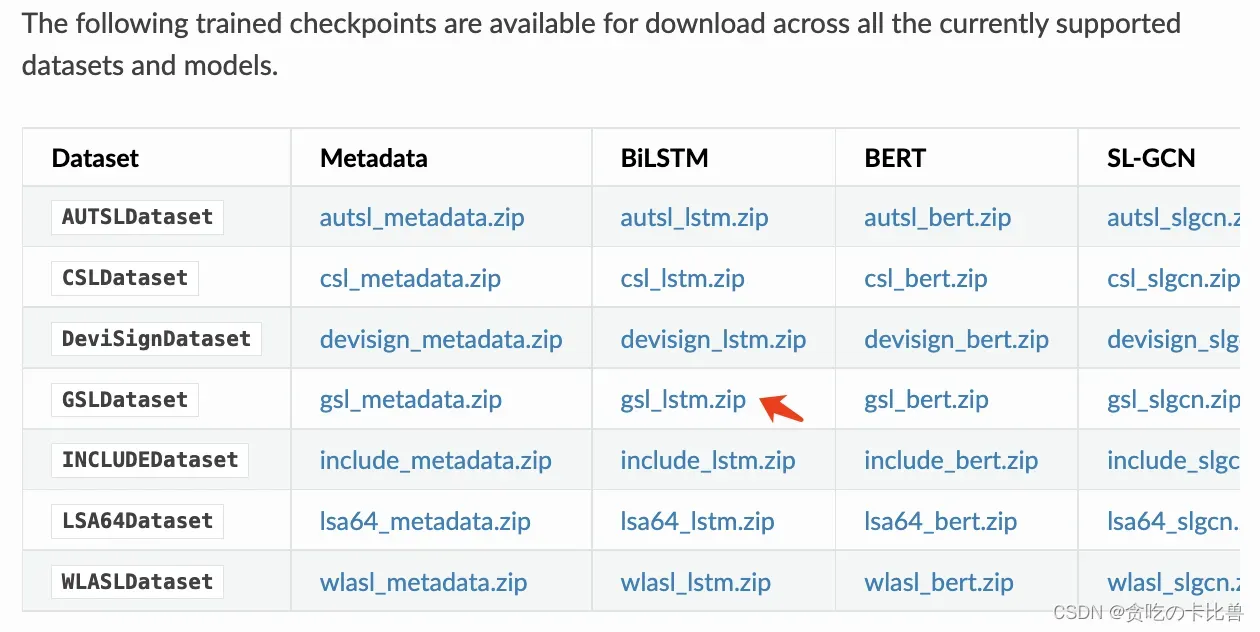
以 gsl_lstm.zip 为例,下载 && 解压,目录如下:
gsl
└── lstm
├── config.yaml
└── epoch=107-step=118043.ckpt
PS:should 自行 于 lstm/config.yaml 补充 test_pipeline 参数,如下:
data:
... ...
test_pipeline: # self-add.
dataset:
_target_: openhands.datasets.isolated.GSLDataset
split_file: "GSL/GSL_split/GSL_isolated/test_greek_iso.csv" # 解压`GSL.zip`可得
root_dir: "GSL/GSL_pose" # 解压`GSL.zip`可得
class_mappings_file_path: "GSL/GSL_split/GSL_isolated/iso_classes.csv" # 解压`GSL.zip`可得
splits: "test"
modality: "pose"
# inference_mode: true # self-add
inference_mode: false # self-add
transforms:
- PoseSelect:
preset: mediapipe_holistic_minimal_27
# - PoseTemporalSubsample:
# num_frames: 32
- CenterAndScaleNormalize:
reference_points_preset: shoulder_mediapipe_holistic_minimal_27
scale_factor: 1
FLOPs && Params
import omegaconf
from openhands.apis.inference import InferenceModel
def profile_func(model, input_dim=(1, 3, 224, 224)): # batchsize - 1
import torch
from thop import profile
input = torch.randn(input_dim)
flops, params = profile(model, inputs=(input, ))
print("flops: {} params: {} ".format(flops, params))
print("%.2fG" % (flops/1e9), "%.2fM" % (params/1e6))
if __name__ == "__main__":
cfg = omegaconf.OmegaConf.load("gsl/lstm/config.yaml")
model = InferenceModel(cfg=cfg)
"""
model: <class 'openhands.apis.inference.InferenceModel'>
model.model: <class 'openhands.models.network.Network'>
"""
profile_func(model.model, input_dim=(1, 2, 100, 27)) # 输入维度可自定义
Outputs
[WARN] Cannot find rule for <class 'openhands.models.encoder.graph.pose_flattener.PoseFlattener'>. Treat it as zero Macs and zero Params.
[INFO] Register count_lstm() for <class 'torch.nn.modules.rnn.LSTM'>.
[INFO] Register count_linear() for <class 'torch.nn.modules.linear.Linear'>.
[WARN] Cannot find rule for <class 'openhands.models.decoder.utils.AttentionBlock'>. Treat it as zero Macs and zero Params.
[WARN] Cannot find rule for <class 'openhands.models.decoder.rnn.RNNClassifier'>. Treat it as zero Macs and zero Params.
[WARN] Cannot find rule for <class 'openhands.models.network.Network'>. Treat it as zero Macs and zero Params.
flops: 145004032.0 params: 1650486.0
0.15G 1.65M
Extension
INCLUDE
源码:https://github.com/AI4Bharat/INCLUDE 修改 runner.py 文件
# ... ...
args = parser.parse_args()
def profile_func(model, input_dim=(1, 3, 224, 224)): # batchsize - 1
import torch
from thop import profile
input = torch.randn(input_dim)
flops, params = profile(model, inputs=(input, ))
print("flops: {} params: {} ".format(flops, params))
print("%.2fG" % (flops/1e9), "%.2fM" % (params/1e6))
if __name__ == "__main__":
from configs import TransformerConfig
from models import Transformer
config = TransformerConfig(size=args.transformer_size)
model = Transformer(config=config, n_classes=226)
# print(model)
profile_func(model, input_dim=(3, 256, 134))
$ python runner.py --dataset include --use_augs --model transformer --data_dir data_dir
[INFO] Register count_linear() for <class 'torch.nn.modules.linear.Linear'>.
[WARN] Cannot find rule for <class 'torch.nn.modules.sparse.Embedding'>. Treat it as zero Macs and zero Params.
[WARN] Cannot find rule for <class 'torch.nn.modules.normalization.LayerNorm'>. Treat it as zero Macs and zero Params.
[INFO] Register zero_ops() for <class 'torch.nn.modules.dropout.Dropout'>.
[WARN] Cannot find rule for <class 'models.transformer.PositionEmbedding'>. Treat it as zero Macs and zero Params.
[WARN] Cannot find rule for <class 'transformers.models.bert.modeling_bert.BertSelfAttention'>. Treat it as zero Macs and zero Params.
[WARN] Cannot find rule for <class 'transformers.models.bert.modeling_bert.BertSelfOutput'>. Treat it as zero Macs and zero Params.
[WARN] Cannot find rule for <class 'transformers.models.bert.modeling_bert.BertAttention'>. Treat it as zero Macs and zero Params.
[WARN] Cannot find rule for <class 'transformers.models.bert.modeling_bert.BertIntermediate'>. Treat it as zero Macs and zero Params.
[WARN] Cannot find rule for <class 'transformers.models.bert.modeling_bert.BertOutput'>. Treat it as zero Macs and zero Params.
[WARN] Cannot find rule for <class 'transformers.models.bert.modeling_bert.BertLayer'>. Treat it as zero Macs and zero Params.
[WARN] Cannot find rule for <class 'torch.nn.modules.container.ModuleList'>. Treat it as zero Macs and zero Params.
[WARN] Cannot find rule for <class 'models.transformer.Transformer'>. Treat it as zero Macs and zero Params.
flops: 2845091328.0 params: 3771362.0
2.85G 3.77M

写在最后:若本文章对您有帮助,请点个赞啦 ٩(๑•̀ω•́๑)۶
文章出处登录后可见!
已经登录?立即刷新