下面是源代码中打印的整体网络结构,然后将其分为ResNet和FPN两部分描述进行描述
Sequential(
(body): ResNet(
(stem): StemWithFixedBatchNorm(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): FrozenBatchNorm2d()
)
(layer1): Sequential(
(0): BottleneckWithFixedBatchNorm(
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): FrozenBatchNorm2d()
)
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(1): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(2): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
)
(layer2): Sequential(
(0): BottleneckWithFixedBatchNorm(
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d()
)
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(1): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(2): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(3): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
)
(layer3): Sequential(
(0): BottleneckWithFixedBatchNorm(
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d()
)
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(1): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(2): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(3): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(4): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(5): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
)
(layer4): Sequential(
(0): BottleneckWithFixedBatchNorm(
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): FrozenBatchNorm2d()
)
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(1): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
(2): BottleneckWithFixedBatchNorm(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): FrozenBatchNorm2d()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): FrozenBatchNorm2d()
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): FrozenBatchNorm2d()
)
)
)
(fpn): FPN(
(fpn_inner2): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_layer2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_inner3): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_layer3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_inner4): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_layer4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(top_blocks): LastLevelP6P7(
(p6): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(p7): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
)
)
)1)ResNet部分
上面的ResNet骨干网络采用的是表1中的50-layer结构,对照着ResNet的网络结构表格(见下面表格),接下来细节描述一下:
表1 ResNet结构表
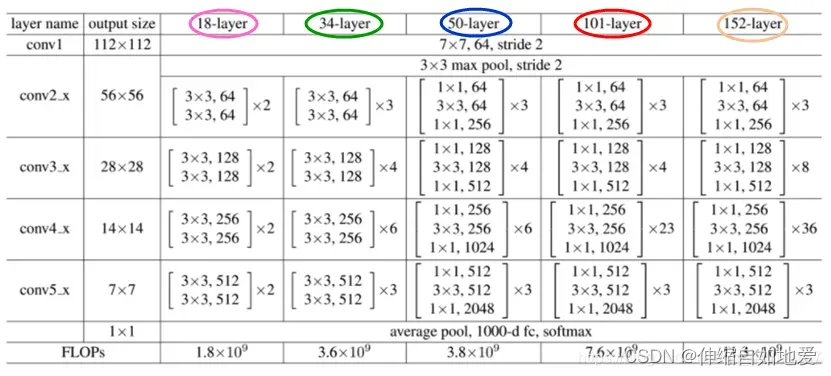
i. StemWithFixedBatchNorm 类:
为表1中conv1 表示的模块外下面的3×3 max pool,由于这个模块各种结构都是通用的,并且接受图片输入(输入通道都是3,输出通道因不同的结构而异),所以名字带有stem(茎干),其代码定义如下,从中可以看出与表1conv1 的部分完全吻合(forward conv1 后接F.max_pool2d)
class BaseStem(nn.Module):
def __init__(self, cfg, norm_func):
super(BaseStem, self).__init__()
out_channels = cfg.MODEL.RESNETS.STEM_OUT_CHANNELS
self.conv1 = Conv2d(
3, out_channels, kernel_size=7, stride=2, padding=3, bias=False
)
self.bn1 = norm_func(out_channels)
for l in [self.conv1,]:
nn.init.kaiming_uniform_(l.weight, a=1)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = F.relu_(x)
x = F.max_pool2d(x, kernel_size=3, stride=2, padding=1)
return x
class StemWithFixedBatchNorm(BaseStem):
def __init__(self, cfg):
super(StemWithFixedBatchNorm, self).__init__(
cfg, norm_func=FrozenBatchNorm2d
)ii. FrozenBatchNorm2d 类
定义如下,一些相关参数的形状如后面注释所示(n值为前面相邻卷积的输出通道数),与正常的BatchNorm 层的作用一样,使一批Batch 的 feature map 满足均值为0,方差为1的分布规律。区别是它使用了 self.register_buffer ,参数固定,训练时不更新,参考pytorch 中register_buffer()
class FrozenBatchNorm2d(nn.Module):
"""
BatchNorm2d where the batch statistics and the affine parameters
are fixed
"""
def __init__(self, n): # n=64
super(FrozenBatchNorm2d, self).__init__()
self.register_buffer("weight", torch.ones(n))
self.register_buffer("bias", torch.zeros(n))
self.register_buffer("running_mean", torch.zeros(n))
self.register_buffer("running_var", torch.ones(n))
def forward(self, x): # x= {Tensor:(1,64,400,560)}
scale = self.weight * self.running_var.rsqrt() # Tensor:(64,)
bias = self.bias - self.running_mean * scale # Tensor:(64,)
scale = scale.reshape(1, -1, 1, 1) # Tensor: (1,64,1,1)
bias = bias.reshape(1, -1, 1, 1) # Tensor: (1,64,1,1)
return x * scale + biasiii. BottleneckWithFixedBatchNorm 类
这个就是定义构成ResNet的基本模块类(如下面代码所示),从文章开头所示的整体网络结构中可以看见,每层(不同的layer表示)开头都有downsample 结构,这是由于ResNet残差网络结构由于需要每层的输入和输出进行加和,如果该层的输入通道数与输出通道数不一样(即形状不一致),则需要对输入进行一个转变使得通道数保持与输出通道数一致。可以参考CV脱坑指南(二):ResNet·downsample详解
class Bottleneck(nn.Module):
def __init__(
self,
in_channels,
bottleneck_channels,
out_channels,
num_groups,
stride_in_1x1,
stride,
dilation,
norm_func,
dcn_config
):
super(Bottleneck, self).__init__()
self.downsample = None # 输入通道与输出通道不相等则采用这个
if in_channels != out_channels:
down_stride = stride if dilation == 1 else 1
self.downsample = nn.Sequential(
Conv2d(
in_channels, out_channels,
kernel_size=1, stride=down_stride, bias=False
),
norm_func(out_channels),
)
for modules in [self.downsample,]:
for l in modules.modules():
if isinstance(l, Conv2d):
nn.init.kaiming_uniform_(l.weight, a=1)
if dilation > 1:
stride = 1 # reset to be 1
# The original MSRA ResNet models have stride in the first 1x1 conv
# The subsequent fb.torch.resnet and Caffe2 ResNe[X]t implementations have
# stride in the 3x3 conv
stride_1x1, stride_3x3 = (stride, 1) if stride_in_1x1 else (1, stride)
self.conv1 = Conv2d(
in_channels,
bottleneck_channels,
kernel_size=1,
stride=stride_1x1,
bias=False,
)
self.bn1 = norm_func(bottleneck_channels)
# TODO: specify init for the above
with_dcn = dcn_config.get("stage_with_dcn", False)
if with_dcn:
deformable_groups = dcn_config.get("deformable_groups", 1)
with_modulated_dcn = dcn_config.get("with_modulated_dcn", False)
self.conv2 = DFConv2d(
bottleneck_channels,
bottleneck_channels,
with_modulated_dcn=with_modulated_dcn,
kernel_size=3,
stride=stride_3x3,
groups=num_groups,
dilation=dilation,
deformable_groups=deformable_groups,
bias=False
)
else:
self.conv2 = Conv2d(
bottleneck_channels,
bottleneck_channels,
kernel_size=3,
stride=stride_3x3,
padding=dilation,
bias=False,
groups=num_groups,
dilation=dilation
)
nn.init.kaiming_uniform_(self.conv2.weight, a=1)
self.bn2 = norm_func(bottleneck_channels)
self.conv3 = Conv2d(
bottleneck_channels, out_channels, kernel_size=1, bias=False
)
self.bn3 = norm_func(out_channels)
for l in [self.conv1, self.conv3,]:
nn.init.kaiming_uniform_(l.weight, a=1)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = F.relu_(out)
out = self.conv2(out)
out = self.bn2(out)
out = F.relu_(out)
out0 = self.conv3(out)
out = self.bn3(out0)
if self.downsample is not None: # 采用downsample使输入和输出通道数相等
identity = self.downsample(x)
out += identity # 残差结构 输入与输出 相加
out = F.relu_(out)
return out
class BottleneckWithFixedBatchNorm(Bottleneck):
def __init__(
self,
in_channels,
bottleneck_channels,
out_channels,
num_groups=1,
stride_in_1x1=True,
stride=1,
dilation=1,
dcn_config=None
):
super(BottleneckWithFixedBatchNorm, self).__init__(
in_channels=in_channels,
bottleneck_channels=bottleneck_channels,
out_channels=out_channels,
num_groups=num_groups,
stride_in_1x1=stride_in_1x1,
stride=stride,
dilation=dilation,
norm_func=FrozenBatchNorm2d,
dcn_config=dcn_config
)2) FPN部分
文章出处登录后可见!