文件说明:Project given image to the latent space of pretrained network pickle
即将给定图像投影到预训练网络 的潜在空间
options
@click.option('--network', 'network_pkl', help='Network pickle filename', required=True)
@click.option('--target', 'target_fname', help='Target image file to project to', required=True, metavar='FILE')
@click.option('--num-steps', help='Number of optimization steps', type=int, default=1000, show_default=True)
@click.option('--seed', help='Random seed', type=int, default=303, show_default=True)
@click.option('--save-video', help='Save an mp4 video of optimization progress', type=bool, default=True, show_default=True)
@click.option('--outdir', help='Where to save the output images', required=True, metavar='DIR')
运行命令:python projector.py --network=/home/joselyn/workspace/0419-course/stylenerf_pkl/ffhq_256.pkl --target=/home/joselyn/workspace/0419-course/my_images/test_img1024.png --outdir=/home/joselyn/workspace/0419-course/logs/StyleNeRF-main/projector1
报错 line 211 xxx
调整synth_image = (synth_image + 1) * (255/2) 为synth_image = (synth_image['img'] + 1) * (255/2)
正式测试
命令:python projector.py --network=/home/joselyn/workspace/0419-course/stylenerf_pkl/ffhq_256.pkl --target=/home/joselyn/workspace/0419-course/my_images/test_img1024.png --outdir=/home/joselyn/workspace/0419-course/logs/StyleNeRF-main/projector_s2 --seed=2 --num-steps=1000
结果如下: (过拟合了。尝试调整num-steps更小)


命令:python projector.py --network=/home/joselyn/workspace/0419-course/stylenerf_pkl/ffhq_256.pkl --target=/home/joselyn/workspace/0419-course/my_images/test_img1024.png --outdir=/home/joselyn/workspace/0419-course/logs/StyleNeRF-main/projector_s4 --seed=4 --num-steps=500
结果如下:


命令:python projector.py --network=/home/joselyn/workspace/0419-course/stylenerf_pkl/ffhq_256.pkl --target=/home/joselyn/workspace/0419-course/my_images/test_img1024.png --outdir=/home/joselyn/workspace/0419-course/logs/StyleNeRF-main/projector_s3 --seed=3 --num-steps=300
结果如下:


debug了解projector
命令:--network=/home/joselyn/workspace/0419-course/stylenerf_pkl/ffhq_256.pkl --target=/home/joselyn/workspace/0419-course/my_images/test_img1024.png --outdir=/home/joselyn/workspace/0419-course/logs/StyleNeRF-main/projector_debug --seed=3 --num-steps=300
提取目标图像:
target_pil = PIL.Image.open(target_fname).convert('RGB') # 1024x1024
w, h = target_pil.size
s = min(w, h)
target_pil = target_pil.crop(((w - s) // 2, (h - s) // 2, (w + s) // 2, (h + s) // 2))
target_pil = target_pil.resize((G.img_resolution, G.img_resolution), PIL.Image.LANCZOS) # resize 为256,256
target_uint8 = np.array(target_pil, dtype=np.uint8) # 256,256,3
优化w
projected_w_steps = project(
G,
target=torch.tensor(target_uint8.transpose([2, 0, 1]), device=device), # pylint: disable=not-callable
num_steps=num_steps,
device=device,
verbose=True
)
返回的projected_w_steps shape为(num_steps,17,512)
合成视频: 对于projected_w_steps 中的每一个 w 利用 G. synthesis 来合成图像。
for projected_w in projected_w_steps:
synth_image = G.synthesis(projected_w.unsqueeze(0), noise_mode='const')
synth_image = (synth_image['img'] + 1) * (255/2) # 1,3,256,256
synth_image = synth_image.permute(0, 2, 3, 1).clamp(0, 255).to(torch.uint8)[0].cpu().numpy()
video.append_data(np.concatenate([target_uint8, synth_image], axis=1))
保存目标图像和 projector的图像
target_pil.save(f'{outdir}/target.png')
projected_w = projected_w_steps[-1] # 取最后一个w
synth_image = G.synthesis(projected_w.unsqueeze(0), noise_mode='const')
synth_image = (synth_image['img'] + 1) * (255/2)
synth_image = synth_image.permute(0, 2, 3, 1).clamp(0, 255).to(torch.uint8)[0].cpu().numpy()
PIL.Image.fromarray(synth_image, 'RGB').save(f'{outdir}/proj.png')
Renderer.py 中line73, kwargs["camera_matrices"] = self.get_camera_traj(t, ws.size(0), device=ws.device) 都是随机生成的,传ws进入只是为了获取batch。 ws 和latent_code有什么关系呢
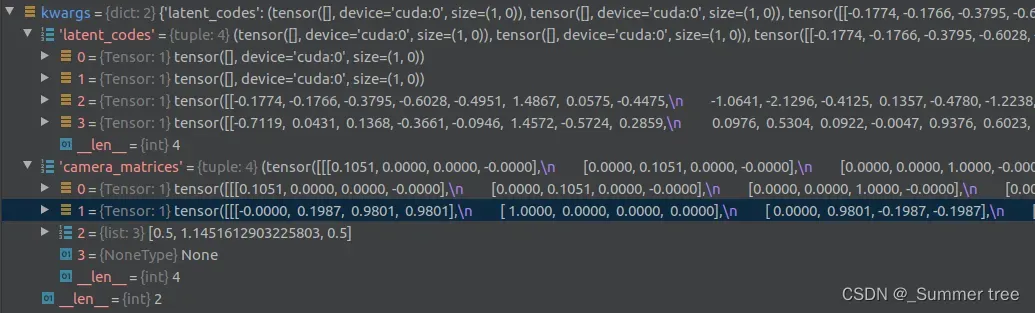
networks,py line 1084 进行img = self.synthesis(ws, **synthesis_kwargs) 时,ws shape (1,17,512)

文章出处登录后可见!