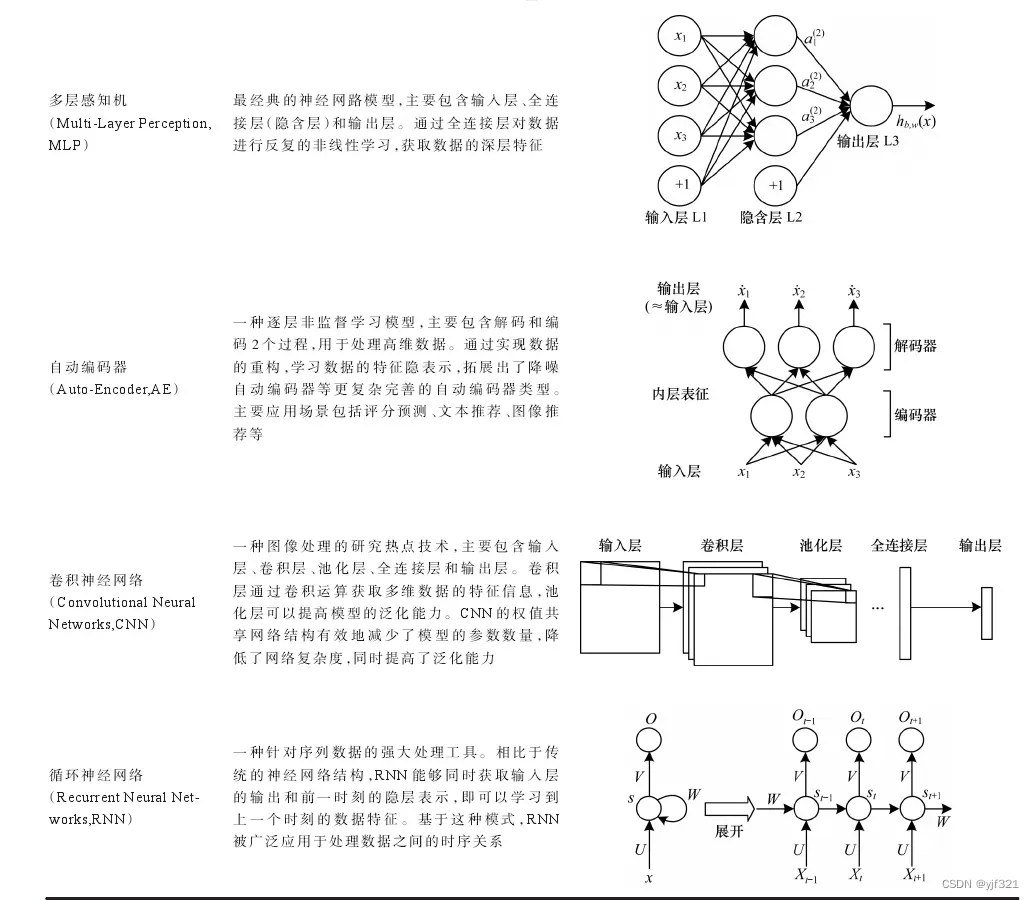
典型的深度学习技术:
为什么要去研究推荐算法:
对于初级开发人员来说,会在社区中搜索自己在开发过程中所遇到的问题,将这些问答内容整理,随着时间积累,用户开始不止在社区中提出问题,并相应回答一些问题,根据这些为用户(打上标签),
可用的推荐算法:
基于内容的推荐算法一般只依赖于用户自身的行为为用户提供推荐,不涉及到其他用户的行为
基于内容的推荐算法示意图:
(1)基于用户历史行为记录做推荐(可以从社区论坛中用户之间的交流入手)
将标的物特征转化为向量化表示,有了向量化表示,我们就可以通过cosine余弦相似度计算两个标的物之间的相似度了。然后将用户历史记录中的标的物的相似标的物推荐给用户。
(2)用户和标的物特征都用显式的标签表示,利用该表示做推荐
标的物用标签来表示,那么反过来,每个标签就可以关联一组标的物,那么根据用户的标签表示,用户的兴趣标签就可以关联到一组标的物,这组通过标签关联到的标的物,就可以作为给用户的推荐候选集。这类方法就是所谓的倒排索引法,是搜索业务通用的解决方案。
(3)用户和标的物嵌入到同一个向量空间,基于向量相似做推荐
当用户和标的物嵌入到同一个向量空间中后,我们就可以计算用户和标的物之间的相似度,然后按照标的物跟用户的相似度,为用户推荐相似度高的标的物。还可以基于用户向量表示计算用户相似度,将相似用户喜欢的标的物推荐给该用户,这时标的物嵌入是不必要的。
怎么表示用户特征、怎么表示标的物特征以及怎么为用户做推荐
1. 构建用户特征表示
1)用户行为记录作为显示特征
2)显示的标签特征
3)向量式的兴趣特征
可以基于标的物的信息将标的物嵌入到向量空间中,利用向量来表示标的物,我们会在后面讲解嵌入的算法实现方案。有了标的物的向量化表示,用户的兴趣向量就可以用他操作过的标的物的向量的平均向量来表示了。这里表示用户兴趣向量有很多种策略,可以基于用户对操作过的标的物的评分以及时间加权来获取用户的加权偏好向量,而不是直接取平均。另外,我们也可以根据用户操作过的标的物之间的相似度,为用户构建多个兴趣向量(比如对标的物聚类,用户在某一类上操作过的标的物的向量均值作为用户在这个类别上的兴趣向量),从而更好地表达用户多方位的兴趣偏好。
有了用户的兴趣向量及标的物的兴趣向量,可以基于向量相似性计算用户对标的物的偏好度,再基于偏好度大小来为用户推荐标的物。
4)通过交互方式获取用户兴趣标签
很多APP在用户第一次注册时让用户选择自己的兴趣标签,一旦用户勾选了自己的兴趣标签,那么这些兴趣标签就是系统为用户提供推荐的原材料。具体推荐策略与上面的(3)一样。
5)用户的人口统计学特征(用户的年龄、性别、地域、收入等)
2.构建标的物特征表示
标的物的特征,一般可以利用显式的标签表示,也可以用隐式的向量(one-hot编码,用向量表示,但不是隐式的),向量的每个维度就是一个隐式的特征项,某些推荐算法需要计算标的物之间的相似度,标的物进行特征表示时,也要考虑一下标的物之间的相似度计算方法。(标的物关联标的物的推荐范式也需要知道标的物之间的相似度)
1)标的物包含标签信息
最简单的方式是将将标签按照某种序排列,每个标签看成一个维度,那么每个标的物就可以表示成一个N维的向量了(N是标签的个数),如果标的物包含某个标签,向量在相应标签的分量上的值为1,否则为0,即所谓的one-hot编码。有可能N非常大(如视频行业,N可能是几万、甚至几十万上百万),这时向量是稀疏向量(一般标的物只有少量的几个或者几十个标签),我们可以采用稀疏向量的表示来优化向量存储和计算,提升效率。有了标的物基于标签的向量化表示,很容易基于cosine余弦计算相似度了 。
标签可以通过算法获取, 比如通过NLP技术从文本信息中提取关键词作为标签。对于图片/视频,它们的描述信息(标题等)可以提取标签,另外可以通过目标检测的方法从图片/视频中提取相关对象构建标签。
2)标的物具备结构化的信息
有些行业标的物是具备结构化信息的,如视频行业,一般会有媒资库,媒资库中针对每个节目会有标题、演职员、导演、标签、评分、地域等维度数据,这类数据一般存在关系型数据库中。这类数据,我们可以将一个字段(也是一个特征)作为向量的一个维度,这时向量化表示每个维度的值不一定是数值,但是形式还是向量化的形式,即所谓的向量空间模型(Vector Space Model,简称VSM)
假设两个标的物的向量表示分别为:
![]()
![]()
这时这两个标的物的相似性可以表示为:
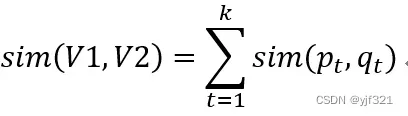
其中
![]()
代表的是向量的两个分量
![]()
之间的相似度。可以采用Jacard相似度等各种方法计算两个分量之间的相似度。上面公式中还可以针对不同的分量采用不同的权重策略,见下面公式,其中wt是第t个分量(特征)的权重,具体权重的数值可以根据对业务的理解来人工设置,或者利用机器学习算法来训练学习得到。
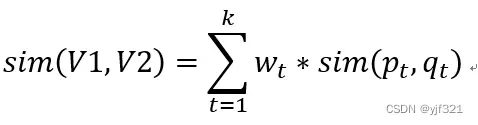
3)包含文本信息的标的物的特征表示
像今日头条和手机百度APP这类新闻资讯或者搜索类APP,标的物就是一篇篇的文章(其中会包含图片或者视频),文本信息是最重要的信息形式,构建标的物之间的相似性有很多种方法
a)利用TF-IDF将文本信息转化为特征向量
b) 利用LDA算法构建文章(标的物)的主题
c) 利用doc2vec算法构建文本相似度
(4)图片、音频、或者视频信息
如果标的物包含的是图片、音频或者视频信息,处理起来会更加复杂。一种方法是利用它们的文本信息(标题、评论、描述信息、利用图像技术提取的字幕等文本信息等等,对于音频,可以通过语音识别转化为文本)采用上面(3)的技术方案获得向量化表示。对于图像或者视频,也可以利用openCV中的PSNR和SSIM算法来表示视频特征,也可以计算视频之间的相似度。另外一种可行的方法是采用图像、音频处理技术直接从图像、视频、音频中提取特征进行向量化表示,从而容易计算出相似度。总之,图片、图像、音频都可以转化为NLP问题或者图像处理问题(见下面图6),通过图像处理和NLP获得对应的特征表示,从而最终计算出相似度,这里不详细讲解。
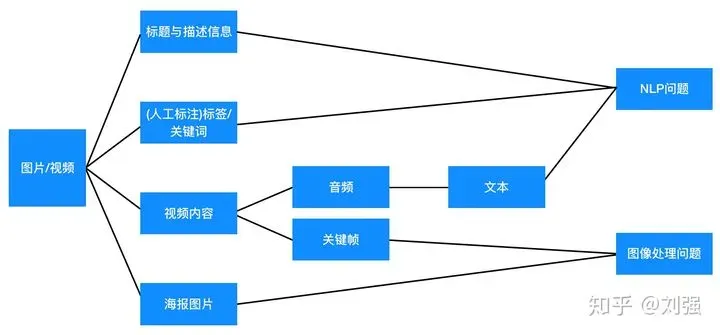
视频,图像问题都可以转化为NLP或者图像处理问题
1)采用跟基于物品的协同过滤类似的方式推荐
该方法采用基于用户行为记录的显式特征表示用户特征,通过将用户操作过的标的物最相似的标的物推荐给用户,算法原理跟基于物品的协同过滤类似,计算公式甚至是一样的,但是这里计算标的物相似度是基于标的物的自身信息来计算的,而基于物品的协同过滤是基于用户对标的物的行为矩阵来计算的。
2)采用跟基于用户协同过滤类似的方法计算推荐( )
3)基于标的物聚类的推荐
有了标的物的向量表示,我们可以用kmeans等聚类算法将标的物聚类,有了标的物的聚类,推荐就好办了。从用户历史行为中的标的物所在的类别挑选用户没有操作行为的标的物推荐给用户,这种推荐方式是非常直观自然的。电视猫的个性化推荐就采用了类似的思路。具体计算公式如下,其中
![]()
是给用户u的推荐,H是用户的历史操作行为集合,Cluster(s)是标的物s所在的聚类。
![]()
4)基于向量相似的推荐
5)基于标签的返向倒排索引做推荐
基于内容的过滤算法优缺点:
优点:(1)可以很好的识别用户的口味 缺点:(1)推荐范围狭窄,新颖性不强
(2)非常直观易懂,可解释性强 (2)需要知道相关的内容信息且处理起来较难
(3)可以更加容易的解决冷启动 (3)较难将长尾标的物分发出去
(4)算法实现相对简单 (4)推荐精准度不太高
(5)对于小众领域也能有比较好的推荐效果
(6)非常适合标的物快速增长的有时效性要求的产品
算法落地需要关注的重要问题
负向反馈代表用户强烈的不满,因此如果推荐算法可以很好的利用这些负向反馈就能够大大提升推荐系统的精准度和满意度。基于内容的推荐算法整合负向反馈的方式有如下几种:
(1) 将负向反馈整合到算法模型中
在构建算法模型中整合负向反馈,跟正向反馈一起学习,从而更自然地整合负向反馈信息。
(2) 采用事后过滤的方式
先给用户生成推荐列表,再从该推荐列表中过滤掉与负向反馈关联的或者相似的标的物。
(3) 采用事前处理的方式
从待推荐的候选集中先将与负向反馈相关联或者相似的标的物剔除掉,然后再进行相关算法的推荐。
协同过滤算法:
(目标是将用户和项目间的关系转化为评分预测问题,然后根据用户对项目的评分信息进行过滤和排序,进而得到推荐列表)
分为三种:基于用户、项目及模型的3种推荐算法
协同过滤算法分为四个步骤:
step1 获取节点信息
step2 构建节点评分矩阵,并查询当前节点的最近临界点评分
step3 根据最近邻节点评分向量,预测该节点评分向量;
step4 根据具体策略生成推荐列表
1)基于用户的推荐算法
该算法依赖于用户对项目的评分,根据用户兴趣相似度进行项目推荐(如电影),存在数据稀疏(冷启动问题),对于未作出评价的用户以及新用户来说,无法做到有效的推荐。
2)基于项目的推荐算法(Item_Based Approach)
与基于用户的相似,采取“用户倾向于喜欢历史项目”的策略,将相似性高的项目推荐给用户,更适用于电商推荐领域,且较容易获得项目信息特征;但该算法推荐的用户感兴趣的物品不具有新颖性,推荐信息趋于大众化。
3)基于模型的推荐算法(Model-Based Approach)
该算法可分为基于图的模型、贝叶斯网络及矩阵分解等,是一种采用统计或机器学习的方法;采用降维的方式将高维用户-项目评分矩阵降为两个低维特征向量矩阵乘积。
模型的学习过程可以使用数据挖掘或机器学习完成,如奇异值的分解技术、降维技术、聚类、决策树和关联规则挖掘。
第一步,获取用户数据,构建用户-项目评分矩阵;
第二步,不断训练评分矩阵,构建推荐模型;
第三步,根据模型进行预测,产生推荐结果;
第四步,进行用户推荐。
4)基于混合模型的推荐算法(可参考)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OX42yTWf-1652665778116)(C:\Users\ASUS\AppData\Roaming\Typora\typora-user-images\1636680747565.png)]
社区划分可以根据(知识图谱进行划分)
重叠社区(SLPA算法)
协同过滤算法的优缺点:
优点:(1)算法原理简单,思想朴素 缺点:(1)冷启动问题
(2)算法易于分布式实现、可以处理海量数据集 (2)稀疏性问题
(3)算法整体效果很不错
(4)能够为用户推荐出多样性、新颖性的标的物
(5)协同过滤算法只需要用户的行为信息,不依赖用户及标的物的其他信息
基于深度学习的推荐算法
一、基于深度学习的社交网络推荐系统
二、基于深度学习的上下文感知推荐系统(递归神经网络RNN)
推荐算法存在的问题
1、冷启动问题, Towards latent context-aware recommendation systems【融合协同过滤和强化深度学习的 CCS 和 ICS 推荐模型。在 Netflix 上进行推荐的结果表明,协同过滤方法与深度学习神经网络的紧密耦合是可行的,对解决 物 品 冷 启 动 问 题 是 非 常 有 效 的】。
2、稀疏性问题 (典型代表性是双聚类算法、奇异值分解、非负矩阵分解)
采用降维技术进行矩阵压缩(采用奇异值分解去除噪音用户和项目)
利用潜在语义索引技术将两个用户投影到一个低维空间
**1、(在线问答社区-海川化工论坛的回答者推荐算法)**问答社区中的问题不能及时得到有效的解答,有两大难点:稀疏性和冷启动,提出了一种融合DeepFM与矩阵分解的混合推荐方法,以DeepFM作为辅助算法,矩阵分解作为主算法,通过结合用户的个人特征与问题的自身特征为论坛中的新问题推荐合适的回答者。
采用降维技术进行矩阵压缩(采用奇异值分解去除噪音用户和项目)
利用潜在语义索引技术将两个用户投影到一个低维空间
**1、(在线问答社区-海川化工论坛的回答者推荐算法)**问答社区中的问题不能及时得到有效的解答,有两大难点:稀疏性和冷启动,提出了一种融合DeepFM与矩阵分解的混合推荐方法,以DeepFM作为辅助算法,矩阵分解作为主算法,通过结合用户的个人特征与问题的自身特征为论坛中的新问题推荐合适的回答者。
2.(在线问答社区的问题答案推荐方法研究)(2)构建了基于注意力机制的 Bi-LSTM/CNN 模型,使用双向长短期神经网络提取文本特征,使用注意力机制给不同词设置权重,使用卷积神经网络深度提取特征,得到问题与答案之间的相似度,从而把候选答案排序列表推荐给用户。(3)收集了 Stack Overflow 的数据集,对数据集进行预处理,包括分词,去除停用词,单词转小写,词形还原等,生成预训练词向量。(4)在 Stack Overflow 数据集上进行了实验设计,并对实验结果进行了评估和分析,对模型结构以及参数影响进行了具体的实验分析。综合实验结果可以确定本文提出的答案推荐方法可以较大地提高答案推荐的准确率。
文章出处登录后可见!