ONNX
https://onnx.ai/
GitHub:Open standard for machine learning interoperability
官方文档
概述
支持的算子
导出模型(安装pytorch的环境可直接运行一下代码):
pytorch官方的例子(可以看到笔记中将 device设置为”cpu”,方便兼容读者进行测试):
import torch
import torchvision
dummy_input = torch.randn(10, 3, 224, 224, device="cpu")
model = torchvision.models.alexnet(pretrained=True)# .cuda()
# 提供输入和输出名称设置模型图形中值的显示名称。设置这些不会改变图形的语义;这只是为了可读性。 也可指定部分名称
input_names = [ "actual_input_1" ] + [ "learned_%d" % i for i in range(16) ]
output_names = [ "output1" ]
torch.onnx.export(
model,
dummy_input,
"alexnet.onnx",
verbose=True,
input_names=input_names,
output_names=output_names
)
需要先下载模型:
Downloading: "https://download.pytorch.org/models/alexnet-owt-7be5be79.pth" to C:\Users\Administrator/.cache\torch\hub\checkpoints\alexnet-owt-7be5be79.pth
100%|██████████| 233M/233M [03:30<00:00, 1.16MB/s]
运行完成只后会输出:
graph(%actual_input_1 : Float(10, 3, 224, 224, strides=[150528, 50176, 224, 1], requires_grad=0, device=cpu),
%learned_0 : Float(64, 3, 11, 11, strides=[363, 121, 11, 1], requires_grad=1, device=cpu),
%learned_1 : Float(64, strides=[1], requires_grad=1, device=cpu),
%learned_2 : Float(192, 64, 5, 5, strides=[1600, 25, 5, 1], requires_grad=1, device=cpu),
%learned_3 : Float(192, strides=[1], requires_grad=1, device=cpu),
%learned_4 : Float(384, 192, 3, 3, strides=[1728, 9, 3, 1], requires_grad=1, device=cpu),
%learned_5 : Float(384, strides=[1], requires_grad=1, device=cpu),
%learned_6 : Float(256, 384, 3, 3, strides=[3456, 9, 3, 1], requires_grad=1, device=cpu),
%learned_7 : Float(256, strides=[1], requires_grad=1, device=cpu),
%learned_8 : Float(256, 256, 3, 3, strides=[2304, 9, 3, 1], requires_grad=1, device=cpu),
%learned_9 : Float(256, strides=[1], requires_grad=1, device=cpu),
%learned_10 : Float(4096, 9216, strides=[9216, 1], requires_grad=1, device=cpu),
%learned_11 : Float(4096, strides=[1], requires_grad=1, device=cpu),
%learned_12 : Float(4096, 4096, strides=[4096, 1], requires_grad=1, device=cpu),
%learned_13 : Float(4096, strides=[1], requires_grad=1, device=cpu),
%learned_14 : Float(1000, 4096, strides=[4096, 1], requires_grad=1, device=cpu),
%learned_15 : Float(1000, strides=[1], requires_grad=1, device=cpu)):
%input : Float(10, 64, 55, 55, strides=[193600, 3025, 55, 1], requires_grad=0, device=cpu) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[11, 11], pads=[2, 2, 2, 2], strides=[4, 4]](%actual_input_1, %learned_0, %learned_1) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\modules\conv.py:443:0
%18 : Float(10, 64, 55, 55, strides=[193600, 3025, 55, 1], requires_grad=1, device=cpu) = onnx::Relu(%input) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\functional.py:1440:0
%input.4 : Float(10, 64, 27, 27, strides=[46656, 729, 27, 1], requires_grad=1, device=cpu) = onnx::MaxPool[kernel_shape=[3, 3], pads=[0, 0, 0, 0], strides=[2, 2]](%18) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\functional.py:797:0
%input.8 : Float(10, 192, 27, 27, strides=[139968, 729, 27, 1], requires_grad=0, device=cpu) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[5, 5], pads=[2, 2, 2, 2], strides=[1, 1]](%input.4, %learned_2, %learned_3) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\modules\conv.py:443:0
%21 : Float(10, 192, 27, 27, strides=[139968, 729, 27, 1], requires_grad=1, device=cpu) = onnx::Relu(%input.8) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\functional.py:1440:0
%input.12 : Float(10, 192, 13, 13, strides=[32448, 169, 13, 1], requires_grad=1, device=cpu) = onnx::MaxPool[kernel_shape=[3, 3], pads=[0, 0, 0, 0], strides=[2, 2]](%21) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\functional.py:797:0
%input.16 : Float(10, 384, 13, 13, strides=[64896, 169, 13, 1], requires_grad=0, device=cpu) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[3, 3], pads=[1, 1, 1, 1], strides=[1, 1]](%input.12, %learned_4, %learned_5) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\modules\conv.py:443:0
%24 : Float(10, 384, 13, 13, strides=[64896, 169, 13, 1], requires_grad=1, device=cpu) = onnx::Relu(%input.16) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\functional.py:1440:0
%input.20 : Float(10, 256, 13, 13, strides=[43264, 169, 13, 1], requires_grad=0, device=cpu) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[3, 3], pads=[1, 1, 1, 1], strides=[1, 1]](%24, %learned_6, %learned_7) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\modules\conv.py:443:0
%26 : Float(10, 256, 13, 13, strides=[43264, 169, 13, 1], requires_grad=1, device=cpu) = onnx::Relu(%input.20) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\functional.py:1440:0
%input.24 : Float(10, 256, 13, 13, strides=[43264, 169, 13, 1], requires_grad=0, device=cpu) = onnx::Conv[dilations=[1, 1], group=1, kernel_shape=[3, 3], pads=[1, 1, 1, 1], strides=[1, 1]](%26, %learned_8, %learned_9) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\modules\conv.py:443:0
%28 : Float(10, 256, 13, 13, strides=[43264, 169, 13, 1], requires_grad=1, device=cpu) = onnx::Relu(%input.24) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\functional.py:1440:0
%input.28 : Float(10, 256, 6, 6, strides=[9216, 36, 6, 1], requires_grad=1, device=cpu) = onnx::MaxPool[kernel_shape=[3, 3], pads=[0, 0, 0, 0], strides=[2, 2]](%28) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\functional.py:797:0
%30 : Float(10, 256, 6, 6, strides=[9216, 36, 6, 1], requires_grad=1, device=cpu) = onnx::AveragePool[kernel_shape=[1, 1], strides=[1, 1]](%input.28) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\functional.py:1241:0
%input.32 : Float(10, 9216, strides=[9216, 1], requires_grad=1, device=cpu) = onnx::Flatten[axis=1](%30) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torchvision\models\alexnet.py:51:0
%input.36 : Float(10, 4096, strides=[4096, 1], requires_grad=1, device=cpu) = onnx::Gemm[alpha=1., beta=1., transB=1](%input.32, %learned_10, %learned_11) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\modules\linear.py:103:0
%33 : Float(10, 4096, strides=[4096, 1], requires_grad=1, device=cpu) = onnx::Relu(%input.36) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\functional.py:1440:0
%input.40 : Float(10, 4096, strides=[4096, 1], requires_grad=1, device=cpu) = onnx::Gemm[alpha=1., beta=1., transB=1](%33, %learned_12, %learned_13) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\modules\linear.py:103:0
%35 : Float(10, 4096, strides=[4096, 1], requires_grad=1, device=cpu) = onnx::Relu(%input.40) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\functional.py:1440:0
%output1 : Float(10, 1000, strides=[1000, 1], requires_grad=1, device=cpu) = onnx::Gemm[alpha=1., beta=1., transB=1](%35, %learned_14, %learned_15) # C:\ProgramData\Anaconda3\envs\torch\lib\site-packages\torch\nn\modules\linear.py:103:0
return (%output1)
Process finished with exit code 0
并且可以发现文件夹目录下有新增文件:

安装部署模型
去安装网页根据系统执行安装即可。
pip install onnxruntime -i https://pypi.tuna.tsinghua.edu.cn/simple

(torch) C:\Users\Administrator>pip install onnxruntime -i https://pypi.tuna.tsi
nghua.edu.cn/simple
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting onnxruntime
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/64/b6/c138a42b5e58bbb91
67643d52a43b0698c6e511a0ae9b3b614a87653c319/onnxruntime-1.11.1-cp38-cp38-win_amd
64.whl (5.6 MB)
|████████████████████████████████| 5.6 MB 3.2 MB/s
Collecting numpy>=1.22.3
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/fa/f2/f4ec28f935f980167
740c5af5a1908090a48a564bed5e689f4b92386d7d9/numpy-1.22.3-cp38-cp38-win_amd64.whl
(14.7 MB)
|████████████████████████████████| 14.7 MB 2.2 MB/s
Requirement already satisfied: protobuf in c:\programdata\anaconda3\envs\torch\l
ib\site-packages (from onnxruntime) (3.19.1)
Collecting flatbuffers
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/3d/d0/26033c70d642fbc1e
35d3619cf3210986fb953c173b1226709f75056c149/flatbuffers-2.0-py2.py3-none-any.whl
(26 kB)
Installing collected packages: numpy, flatbuffers, onnxruntime
Attempting uninstall: numpy
Found existing installation: numpy 1.19.3
Uninstalling numpy-1.19.3:
Successfully uninstalled numpy-1.19.3
ERROR: pip's dependency resolver does not currently take into account all the pa
ckages that are installed. This behaviour is the source of the following depende
ncy conflicts.
tensorboard 2.6.0 requires google-auth<2,>=1.6.3, but you have google-auth 2.6.0
which is incompatible.
paddlepaddle 2.2.2 requires numpy<=1.19.3,>=1.13; python_version >= "3.5" and pl
atform_system == "Windows", but you have numpy 1.22.3 which is incompatible.
Successfully installed flatbuffers-2.0 numpy-1.22.3 onnxruntime-1.11.1
执行
import numpy as np
import onnxruntime as ort
ort_session = ort.InferenceSession("alexnet.onnx")
outputs = ort_session.run(
None,
{"actual_input_1": np.random.randn(10, 3, 224, 224).astype(np.float32)},
)
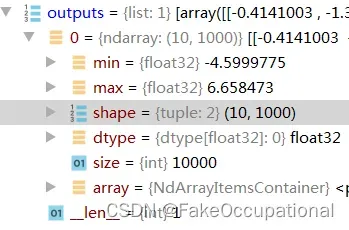
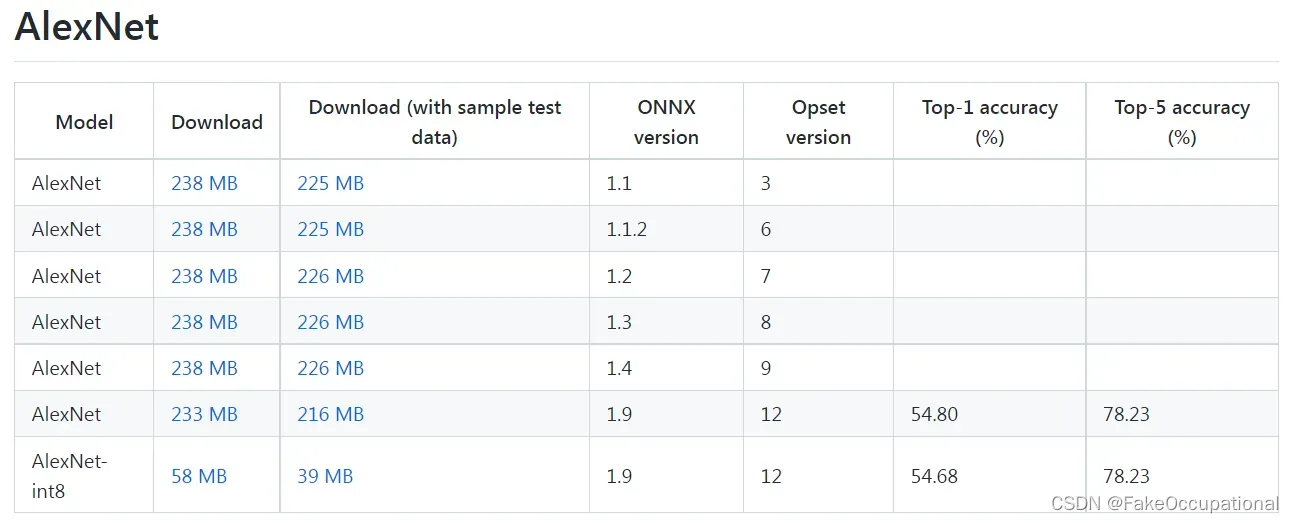
预训练的onnx模型下载
官方onnx模型 预训练的onnx模型下载 onnx/models
https://github.com/axinc-ai/ailia-models
在每个模型介绍页的底部提供了一个模型展示,比如https://github.com/axinc-ai/ailia-models/tree/master/image_classification/alexnet下:
官网
https://pypi.org/project/ailia/
参考
[ONNX介绍与使用教程](https://www.bilibili.com/video/BV1AU4y1t7Xi?p=31)
[一个带翻译的使用教程](https://www.bilibili.com/video/BV1p54y1i793?)
[Deploy Machine Learning anywhere with ONNX](https://www.youtube.com/watch?v=ECYCYS49III)
[修改:ONNX修改算子和连接](https://zhuanlan.zhihu.com/p/378083258)
[ONNX 浅析:如何加速深度学习算法工程化?](https://baijiahao.baidu.com/s?id=1711748925703810732&wfr=spider&for=pc)
[Android手机部署-导出ONNX模型](https://www.bilibili.com/video/BV1eU4y1U7Bn)
[How to install ONNX Runtime on Raspberry Pi](https://www.youtube.com/watch?v=fGikHcBze_I)
[TensoRT以及onnx插件实现细节](https://www.bilibili.com/video/BV1Pe411x7qr?)
[使用Protobuf存储,对机器更为友好,Protobuf 是一种类似于 JSON 或 XML 的数据序列化协议](https://mnwa.medium.com/what-the-hell-is-protobuf-4aff084c5db4)
[Protobuf格式的介绍](https://www.ionos.com/digitalguide/websites/web-development/protocol-buffers-explained/)
[可视化:netron](https://github.com/lutzroeder/Netron)
[旷视「逃离」ONNX](https://www.bilibili.com/video/BV14L411L7QR?)
## 其他部署工具
ncnn,tflite(移动端模型),paddlelite(移动端模型),tengine , mnn ,tnn ,Libtorch ,ONNX Runtime ,TensorRT,TensorFlow Serving ,TorchServe
## 各厂商的格式转换工具
TENSORFLOW: https://www.tensorflow.org/
[Convert TensorFlow, Keras, Tensorflow.js and Tflite models to ONNX](https://github.com/onnx/tensorflow-onnx)
import tf2onnx
frozen_graph_def = tf.graph_util.convert_variables_to_constants(sess,sess.graph.as_graph_def(),["vgg16/predictions/Softmax"])
graph1 = tf.Graph()
with graph1.as_default():
tf.import_graph_def(frozen_graph_def)
onnx_graph = tf2onnx.tfonnx.process_tf_graph(graph1, input_names=["import/block1_conv1/kernel:0"], output_names=["import/vgg16/predictions/Softmax:0"],opset=10)
model_proto = onnx_graph.make_model("vgg16_tensorflow")
with open("vgg16_tensorflow.onnx", "wb") as f:
f.write(model_proto.SerializeToString())
import keras2onnx
onnx_model = keras2onnx.convert_keras(model, model.name, target_opset=10)
temp_model_file = 'vgg16_keras.onnx'
onnx.save_model(onnx_model, temp_model_file)
[PaddleOCR转ONNX推理](https://www.4k8k.xyz/article/favorxin/113838901)
ONNX: https://github.com/onnx/onnx
CNTK: https://github.com/Microsoft/CNTK
PYTORCH: https://pytorch.org/
[ONNX(Pytorch) 模型转换为 TNN 模型](https://github.com/Tencent/TNN/blob/master/doc/cn/user/onnx2tnn.md)
TNN: https://github.com/Tencent/TNN
[MNNConvert](https://github.com/alibaba/MNN/blob/master/tools/converter/README.md)
MNN: https://github.com/alibaba/MNN
CUDNN: https://developer.nvidia.com/zh-cn/cudnn
TENSORRT: https://developer.nvidia.com/zh-cn/tensorrt
COREML: https://developer.apple.com/documentation/coreml
NCNN: https://github.com/Tencent/ncnn
NNAPI: https://developer.android.com/ndk/guides/neuralnetworks
Protocol Buffers: https://developers.google.com/protocol-buffers
Dilated Convolutions https://arxiv.org/abs/1511.07122
Dynamic Group Convolutions https://arxiv.org/abs/2007.04242
文章出处登录后可见!
已经登录?立即刷新