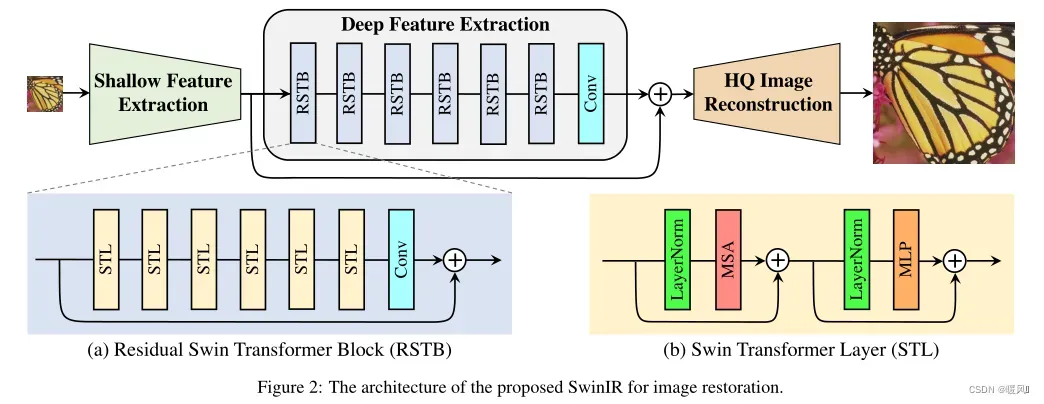
这篇文章结构比较简单,如果看过Swin-Transformer的话就没什么难点了。作者引入Swin-T结构应用于低级视觉任务,包括图像超分辨率重建、图像去噪、图像压缩伪影去除。SwinIR网络由一个浅层特征提取模块、深层特征提取模块、重建模块构成。重建模块对不同的任务使用不同的结构。浅层特征提取就是一个3×3的卷积层。深层特征提取是k个RSTB块和一个卷积层加残差连接构成。每个RSTB(Res-Swin-Transformer-Block)由L个STL和一层卷积加残差连接构成。
原文链接:SwinIR: Image Restoration Using Swin Transformer
源码地址:https://github.com/JingyunLiang/SwinIR
Abstract
图像超分问题最先进的方法是基于卷积神经网络的,很少有人尝试使用Transformer。Transformer在高级视觉任务中已经表现出令人印象深刻的性能。因此作者在本文引入了Transformer,提出了一种基于Swin-T的图像恢复模型SwinIR。SwinIR由三部分组成:浅层特征提取、深层特征提取和高质量图像重建。具体而言,深度特征提取模块由几个带残差连接的Swin Transformer块(RSTB)组成,每个块都有几个Swin Transformer层和一个残差连接。在三个具有代表性的任务上进行了实验:图像超分辨率(包括经典、轻型和真实世界的图像超分辨率)、图像去噪(包括灰度和彩色图像去噪)和JPEG压缩伪影去除。实验结果表明,在不同的任务上,SwinIR的性能比最先进的方法高出0.14个百分点∼0.45dB,而参数总数最多可减少67%。

1 Introduction
基于CNN的方法通常会遇到两个基本问题,这两个问题源于其基本构造块,即卷积层。
- 图像和卷积核之间的交互与内容无关。使用相同的卷积核来恢复不同的图像区域可能不是一个好的选择。
- CCN只能对局部信息进行处理,卷积对于长期依赖性建模是无效的。
作为CNN的替代方案,Transformer基于一种自注意力机制,以捕捉上下文之间的全局交互。用于图像恢复的视觉变换器ViT这种通常将输入图像分割成大小固定的小块,并独立处理每个小块。这种策略不可避免地会带来两个缺点。
- 恢复的图像可能会在每个小斑块周围引入
边界伪影。 - 每个patch的
边界像素会丢失信息。
Swin Transformer结合了CNN和Transformer的优点。
- 由于局部注意机制,它具有CNN处理大尺寸图像的优势。(相比于transformer,CNN的计算量小很多,所以可以处理大尺寸图像)
- 又具有Transformer的优点,可以用移位窗口方案来建模长期依赖关系。
本文提出了一种基于Swin-T的图像恢复模型SwinIR。更具体地说,SwinIR由三个模块组成:浅特征提取、深特征提取和高质量图像重建模块。浅层特征提取模块使用卷积层提取浅层特征,并通过长跳跃连接将其直接传输到重构模块,以保留低频信息。深度特征提取模块主要由带有残差连接的Swin Transformer块(RSTB)组成,每个块利用多个Swin Transformer层进行局部注意力计算和跨窗口交互。每个RSTB块的末尾添加了一个卷积层以增强特征,并使用残差连接为特征聚合提供快捷方式。最后,在重建模块中融合了浅层和深层特征,实现了高质量的图像重建。
与基于CNN的图像恢复模型相比,基于Transformer的SwinIR有几个优点:
- 图像内容和注意权重之间基于内容的交互作用,可以解释为空间变化的卷积。
- 通过移位窗口机制可以实现长期依赖性建模。
- 性能更好,参数更少。
2 Method
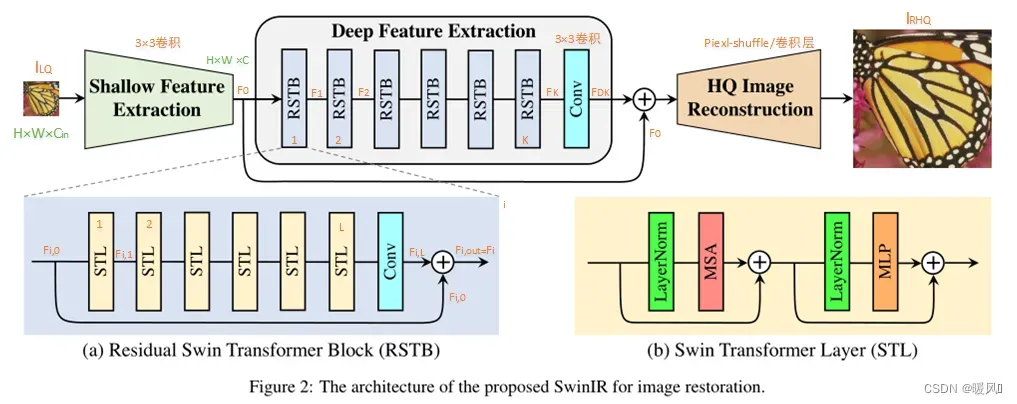
SwinIR由三个模块组成:浅特征提取、深特征提取和高质量(HQ)图像重建模块。对所有恢复任务使用相同的特征提取模块,但对不同的任务使用不同的重建模块。
2.1 OVerview
SwinIR由三个模块组成:浅层特征提取、深层特征提取和高质量(HQ)图像重建模块。对所有恢复任务使用相同的特征提取模块,但对不同的任务使用不同的重建模块。输入图像为
浅层特征提取:
使用一个3×3卷积层来提取浅层特征
。卷积层在早期视觉处理方面很好,能引导网络更稳定的优化和更好的结果,更简单的将输入图像空间映射到更高维特征空间。
![]()
深层特征提取:
代表深度特征提取模块的算子,包含K个Swin-T块(RSTB)和一个3×3卷积层,最后用残差连接。
表示第i个RSTB,
是最后一个卷积层。每个块的输出F1,F2,…,FK和输出深度特征
按如下方式逐块提取:
![]()
在特征提取的最后使用一个卷积层可以将卷积运算的归纳偏置引入Transformer网络,为以后浅层和深层特征的聚合奠定更好的基础。
图像重建模块:
①图像超分:
通过聚集浅层和深层特征来重建高质量的图像,
是重建模块的功能。浅层特征主要包含低频,而深层特征则侧重于恢复丢失的高频。通过长跳跃连接,SwinIR可以将低频信息直接传输到重建模块,从而帮助深层特征提取模块聚焦高频信息,稳定训练。对于重建模块的实现,使用亚像素卷积层对特征进行上采样。
![]()
②图像去噪和JPEG压缩伪影去除
对于不需要上采样的任务,使用单个卷积层进行重建。此外,额外使用一个残差学习来重建LQ和HQ图像之间的残差,而不是HQ图像。表示SwinIR的功能。公式是:
![]()
LOSS:
①超分任务:L1loss
![]()
② 图像去噪和JPEG压缩伪影去除:Charbonnier loss
![]()
2.2 Residual Swin Transformer Block
残差Swin Transformer block(RSTB)是由L个Swin Transformer层和1个卷积层加残差连接构成的。给定第i个RSTB的输入特征,中间特征
,
s 第
个RSTB中的第
个Swin-T层。公式表示为:
![]()
- 尽管Transformer可以被视为空间变化卷积的一个具体实例,但带有空间不变性的卷积层可以增强SwinIR的平移不变性。
- 残差连接提供了从不同块到重建模块短跳跃短连接,允许不同级别的特征聚合。
2.3 Swin Transformer layer
(看过Swin-T的话,这个层就是单纯的Swin-T的使用。)
Swin Transformer layer(STL)来自于原始Transformer layer的标准多头自注意力的变体。详细介绍可以看这篇Swin Transformer。主要不同点在于在局部窗口内计算注意力和移动窗口的划分机制。
Swin Transformer首先通过将输入图像进行patch划分,每个patch作为一个token。再在patch的基础上划分为不重叠的M×M局部窗口,在窗口路内分别计算每个patch和其他patch的注意力,h个头。注意力模块后接多层感知器(MLP)进行进一步的特征变换,该感知器具有两个全连接层,层之间具有GELU激活函数。在MSA和MLP之前添加LayerNorm(LN)层,两个模块都使用残差连接,如上图2(b)就是一个标准的Swin-T Block。在连续的Swin-T Block间交替使用常规和移位窗口分区来启用跨窗口连接。
![]()
3 Experiments
setting:
RSTB数K = 6 (轻量级图像SR,RSTB数 K= 4)
STL数L = 6
窗口大小M = 8 (减少JPEG压缩伪影,窗口大小M = 7)
通道数C = 180 (轻量级图像SR,通道数C = 60)
注意头数h = 6
自集成策略用“+”表示
3.1 Ablation Study and Discussion
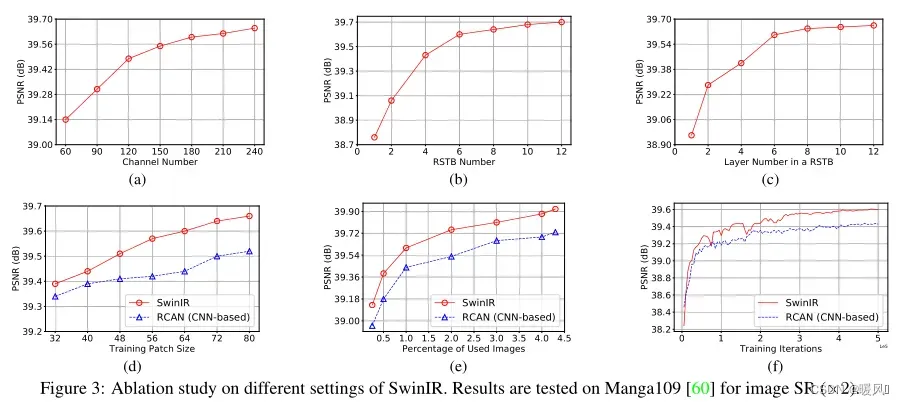
在DIV2K上训练SwinIR获得经典图像SR(×2),并在Manga109上进行测试。
①通道数、RSTB数和STL数的影响:
图3中(a)、(b)和(c)展示了RSTB中通道数、RSTB数和STL数对模型性能的影响。可以看到到峰值信噪比与这三个超参数正相关。虽然对于大通道数,性能会不断提高,但参数总数会以二次方的方式增长。为了平衡性能和模型尺寸,在接下来的实验中选择180作为通道数。对于RSTB数和STL层数,性能增益逐渐趋于饱和,选择参数均为6,以获得一个相对较小的模型。
②patch大小和训练图像数量的影响;模型收敛性比较。
SwinIR与一个具有代表性的基于CNN的模型RCAN进行比较,以探索基于Transformer的模型和基于CNN的模型的差异。
- 从图3(d)可以看出,在不同的patch大小上,SwinIR的性能优于RCAN,并且当patch大小增大时,PSNR增益变得更大。
- 图3(e)显示了训练图像的数量的影响。当百分比大于100%(800张图像)时,Flickr2K的图像用于训练。有两个观察结果。首先,SwinIR的性能随着训练图像的数量而提高。其次,与IPT中基于Transformer的模型使用大量训练数据不同,SwinIR比使用相同训练数据的基于CNN的模型获得更好的结果,即使数据集很小(即25%,200张图像)。
- 图3(f)中绘制了SwinIR和RCAN训练期间的峰值信噪比。SwinIR的收敛速度比RCAN更快(这与以往的结论矛盾,即基于Transformer的模型往往存在缓慢的模型收敛)。
- RSTB中的残差连接很重要,它将PSNR提高了0.16dB。
- 使用1×1卷积带来的改善很小,可能是因为它不能像3×3卷积一样提取局部邻域信息。
- 虽然使用三个3×3卷积层可以减少参数数量,但性能略有下降。

3.2 Results on Image SR
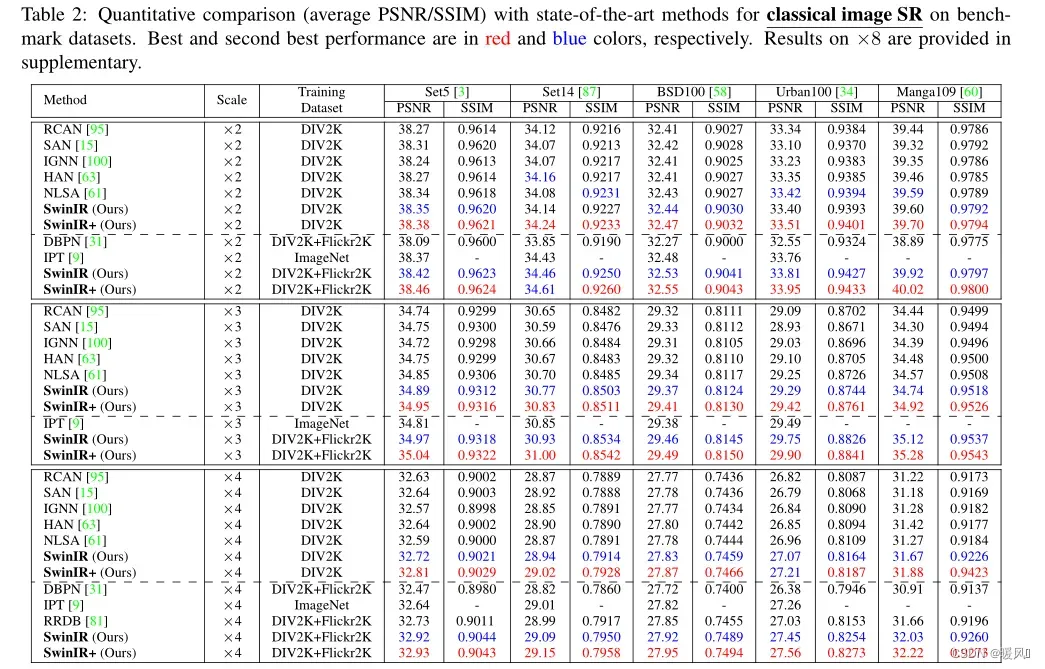
Classical image SR:
表2显示了SwinIR(中等规模)和最先进方法的定量比较。
- 当在DIV2K上训练时,SwinIR在所有五个基准数据集的所有放大因子上都取得了最佳性能。RCAN和HAN引入了通道和空间注意,IGNN提出了自适应patch特征聚合,NLSA基于非局部注意机制。 但所有这些基于CNN的注意机制的表现都不如所提出的基于Transformer的SwinIR,这证明了所提出模型的有效性。
- 当在更大的数据集上训练SwinIR时,性能进一步大幅提高,实现了比基于Transformer的同一模型IPT更好的精度,(IPT在训练中使用ImageNet(超过130万张图像),并且有大量参数(115.5M)),相比之下,SwinIR只有少量参数(11.8M),比最佳的基于CNN的模型还要少。在运行时间方面,在1024×1024图像上进行测试,RCAN、IPT和SwinIR分别需要大约0.2、4.5和1.1秒。SwinIR可以恢复高频细节,并减轻模糊的效果,能产生尖锐和自然的边缘。相比之下,大多数基于CNN的方法无法恢复正确的纹理,并产生模糊的图像,甚至不同的结构。与基于CNN的方法相比,IPT生成的图像更好,但它存在图像失真和边界伪影。
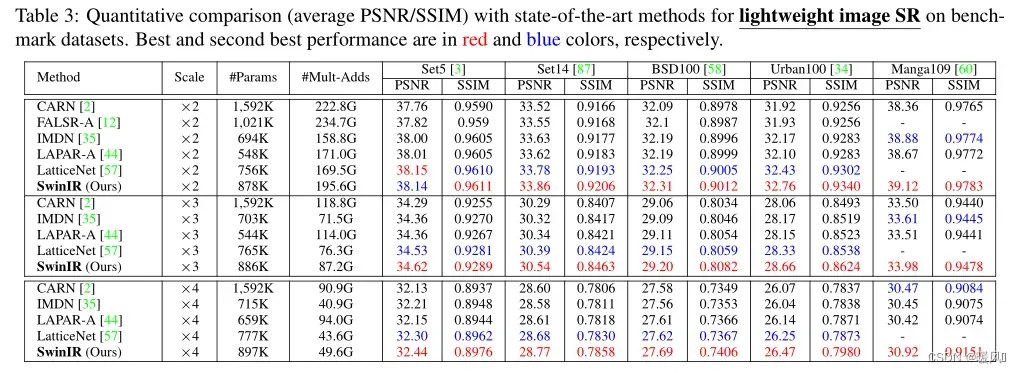
Lightweight image SR:
还进行了SwinIR(小尺寸)与最先进的轻型图像SR方法的比较。除了PSNR和SSIM,还计算了参数总数和乘法累加运算(在1280×720 HQ图像上评估),以比较不同模型的模型大小和计算复杂度。如表3所示,在不同的基准数据集上,SwinIR比竞争方法的PSNR优势高达0.53dB,具有相似的参数总数和多次累积操作。这表明SwinIR体系结构是高效的。
Real-world image SR:
图像SR的最终目标是用于实际应用。Zhang等人为真实世界的图像SR提出了一个实用的退化模型BSRGAN,并在现实场景中取得了令人惊讶的结果。为了测试SwinIR在现实世界SR中的性能,使用与BSRGAN相同的退化模型对SwinIR进行了重新训练,用于低质量的图像合成,并在现实世界SR基准数据集RealSRSet上进行了测试。由于没有真实的高质量图像,只提供与代表性的双三次模型ESRGAN和最先进的现实世界图像SR模型FSSR、RealSR和BSRGAN的视觉比较。如图5所示,SwinIR生成的图像具有清晰锐利的边缘,视觉上令人愉悦,而其他比较方法可能存在不令人满意的伪影。

3.3 Results on JPEG Compression Artifact Reduction & 3.4 Results on Image Denoising
这两部分的实验就不详述了
4 Coclusion
总的来说这篇文章结构比较简单,是对Swin-T的下游任务应用。基于Swin-T的提出的图像恢复模型SwinIR。
该模型由三部分组成:浅层特征提取、深层特征提取和HR重构模块。
使用一堆残差结构的Swin Transformer块(RSTB)进行深度特征提取,每个RSTB由Swin Transformer层、卷积层和残差连接组成。
最主要是学习Swin-T的部分,可以看详细解说:Swin-Transformer。看懂Swin-T,这篇就是一个很常规的结构。
实验证明,SwinIR在经典图像SR、轻量化图像SR、真实图像SR、灰度图像去噪、彩色图像去噪和JPEG压缩伪影去除等三种典型图像恢复任务都取得了最先进的性能,这证明了该算法的有效性和通用性。在未来,作者还将继续把该模型扩展到其他恢复任务,如图像去模糊和去模糊。
最后祝各位科研顺利,身体健康,万事胜意~
文章出处登录后可见!