机器学习流程
机器学习需要人工选取数据,提取数据。
深度学习是机器学习的一部分。
- 数据获取
- 特征工程
数据特征决定了模型的上限
预处理和特征提取是最核心的
算法与参数选择决定了如何逼近这个上限 - 建立模型
- 评估与应用
传统特征提取方法:
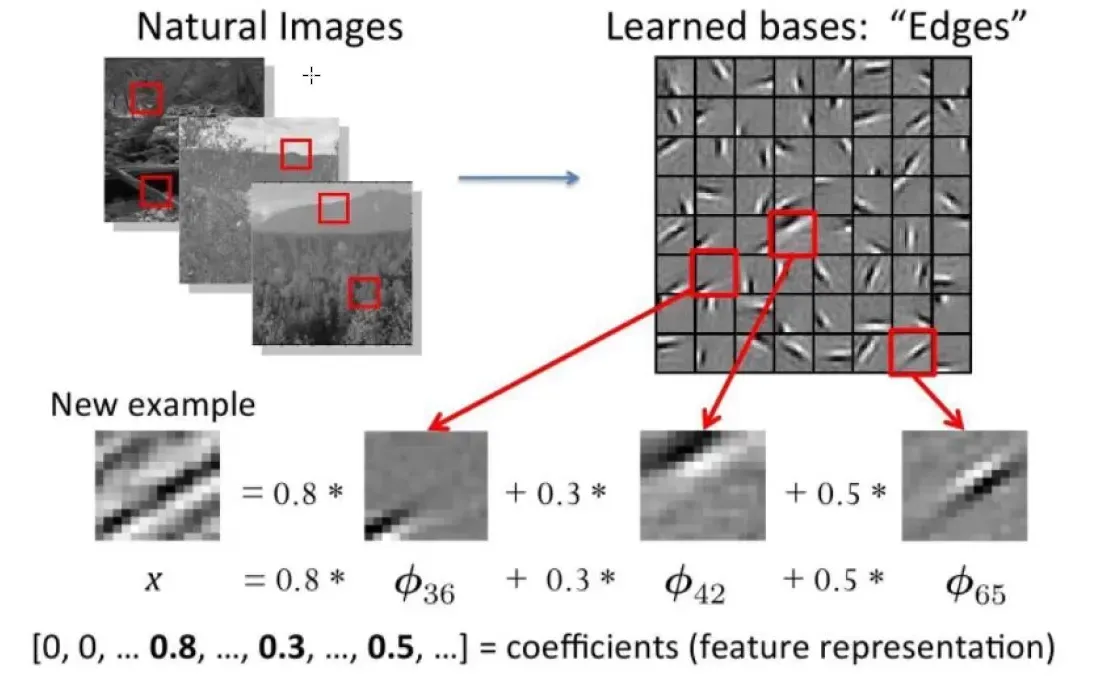
为什么需要深度学习
·解决核心是,如何去提取特征
图像分类
计算机视觉面临的挑战
- 照射角度
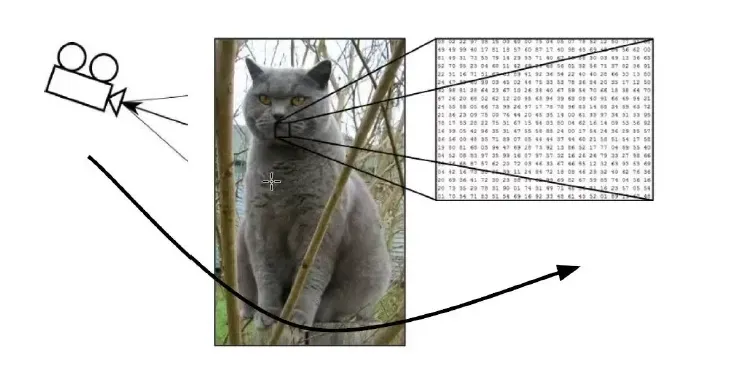
- 性状改变

- 部分遮蔽

- 背景混入

机器学习常规套路
- 收集数据并给定标签
- 训练一个分类器
- 测试,评估
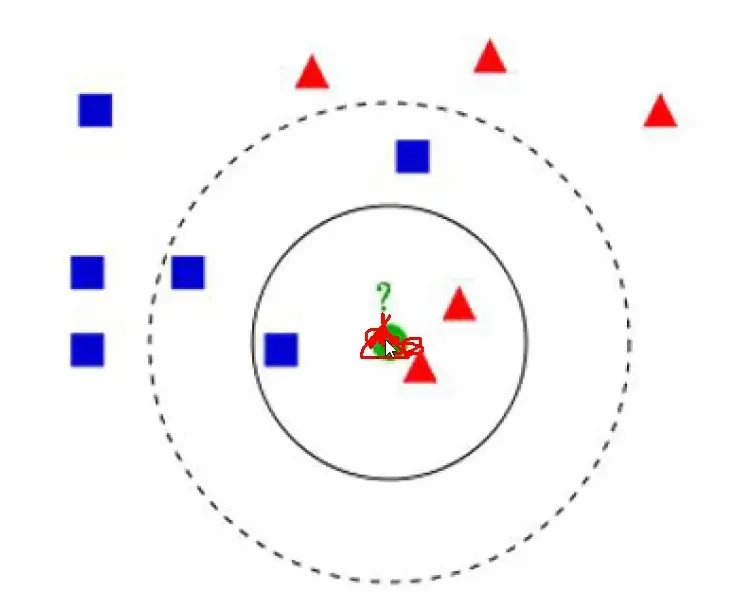
K近邻
K近邻算法
数据:两类点方块和三角
绿色的点属于方块还是三角呢?
K=3还是K=5?结果一样吗?
K近邻计算流程:
- 就算已知类别数据集中的点与当前点的距离
- 按照距离依次排序
- 选取与当前点距离最小的K个点
- 确定前K个点所在类别的出现概率
- 返回前K个点出现频率最高的类别作为当前点预测分类
K近邻分析
KNN 算法本身简单有效,它是一种 lazy-learning 算法。
分类器不需要使用训练集进行训练,训练时间复杂度为0。
KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为 n,那么 KNN 的分类时间复杂度为O(n)。
K 值的选择,距离度量和分类决策规则是该算法的三个基本要素。
距离的选择:
L1 distance: 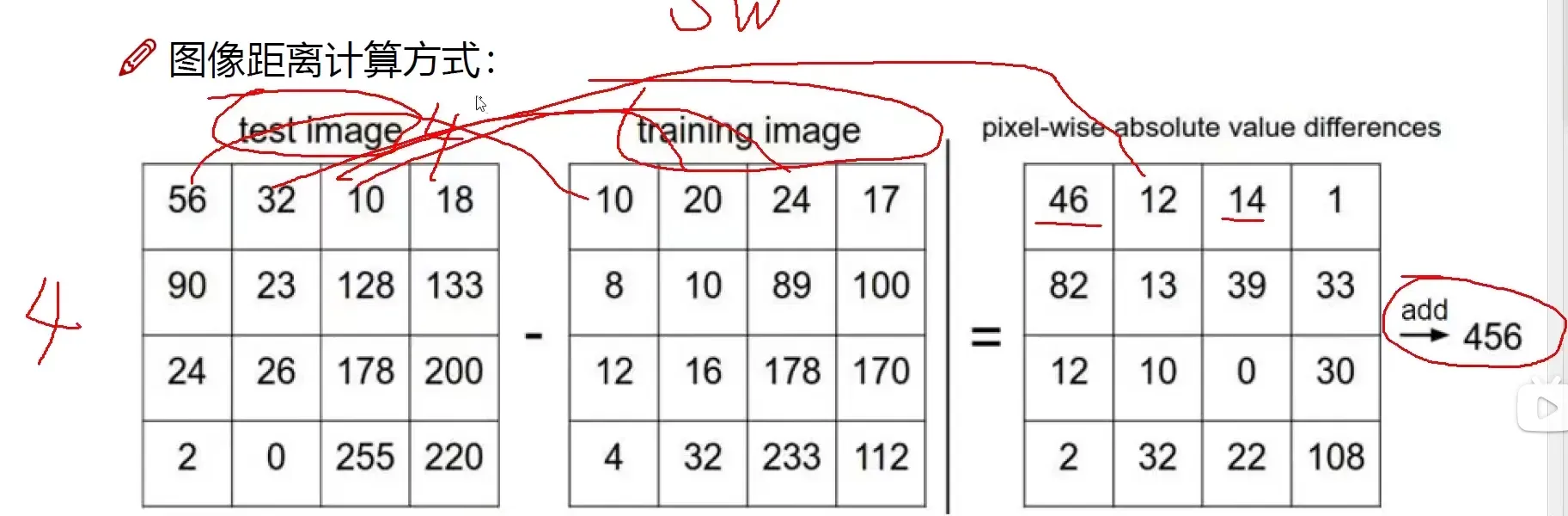
为什么K近邻不能用来图像分类?
背景主导是一个最大的问题,我们关注的却是主体(主要成分)
如何才能让机器学习到哪些是重要的成分呢?
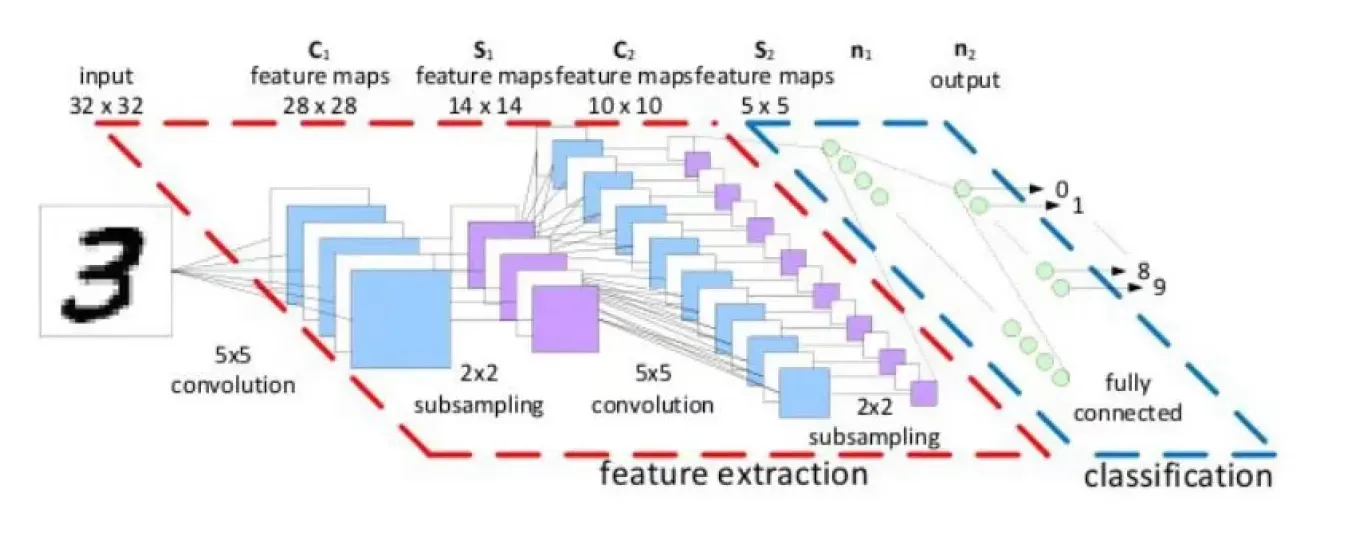
神经网络基础
线性函数
从输入 –> 输出的映射
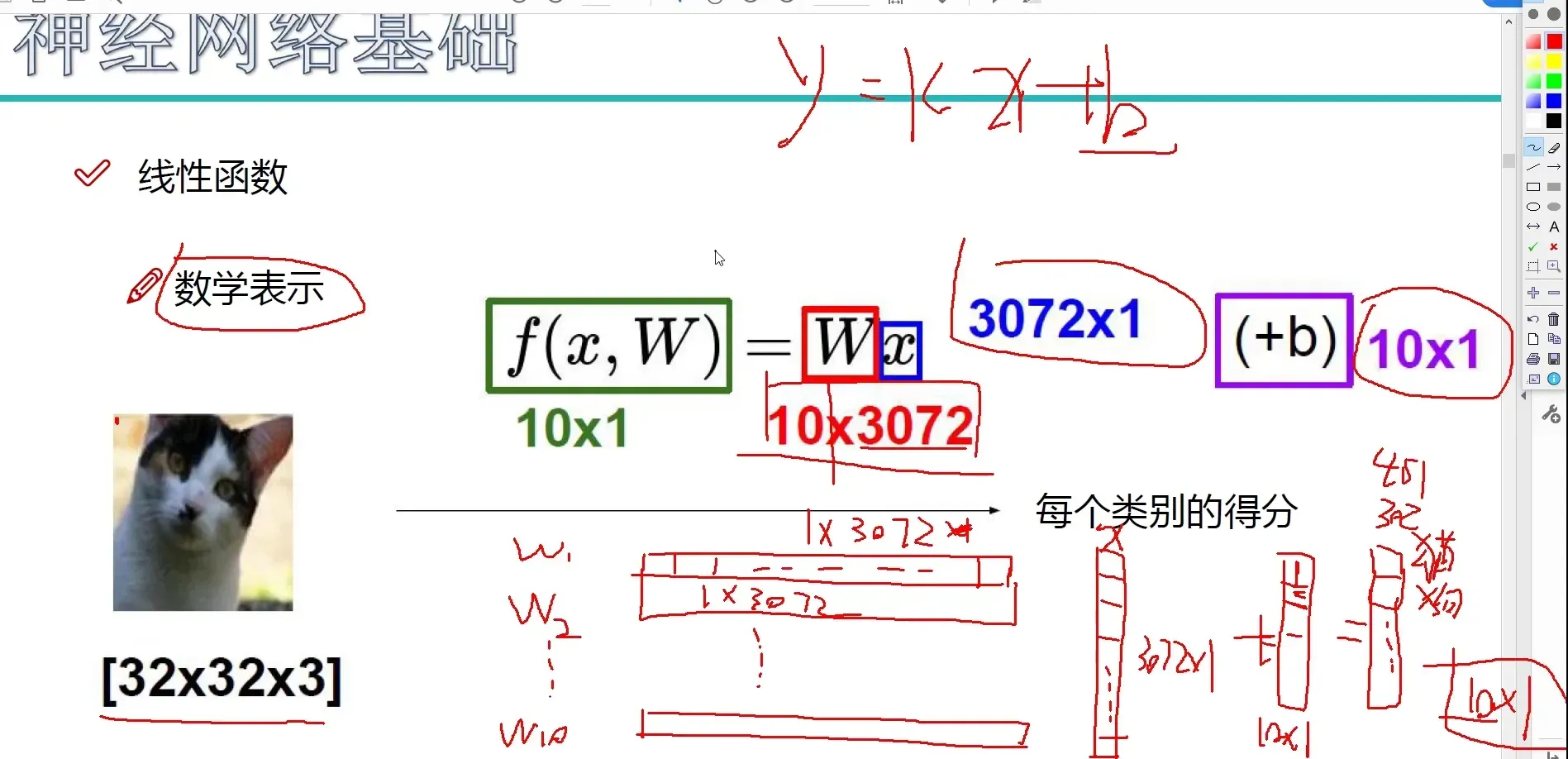
计算方法
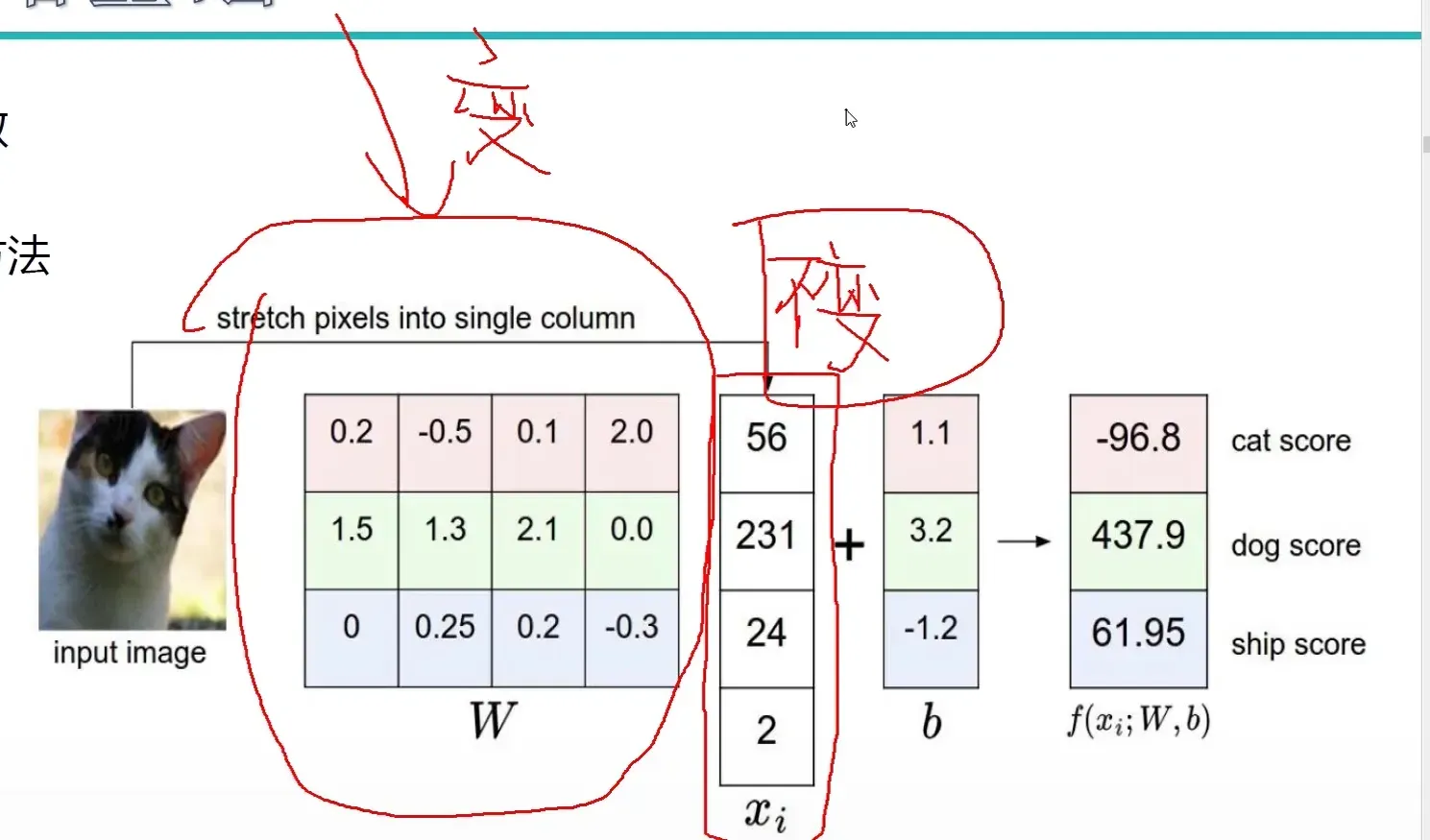
什么样的 W 更适合我们的预期目标
损失函数
如何衡量分类的结果呢?
结果的得分值有着明显的差异,我们需要明确的指导模型的当前效果,有多好或是多差!
如果损失函数的值相同,那么意味着两个模型一样吗?
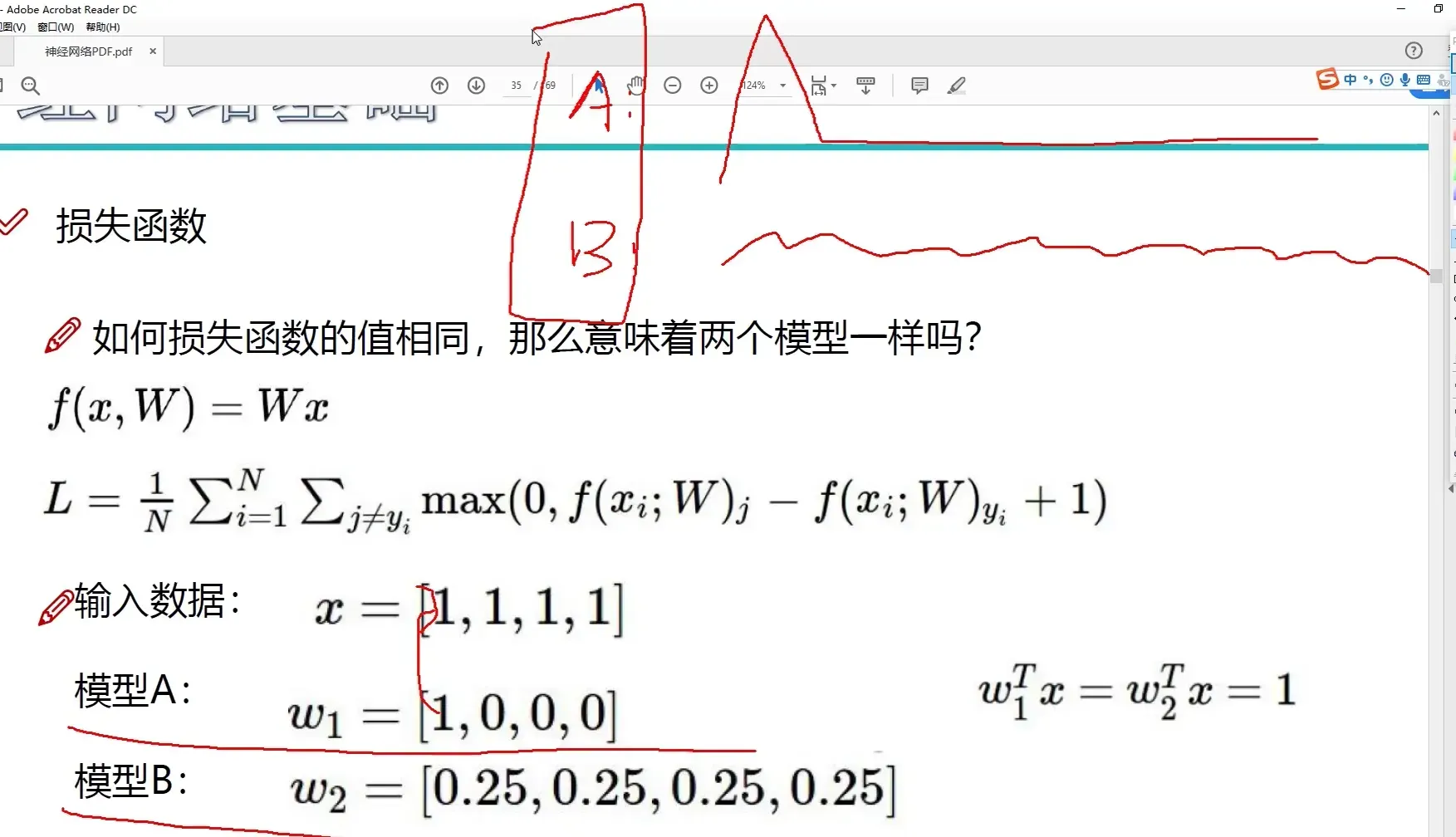
在训练过程中,关注权重参数是否会发生变异,发生过拟合
损失函数 
损失函数其实有很多种,我们来实验一个
错误类别,
正确类别
表示容忍程度

正则化惩罚项
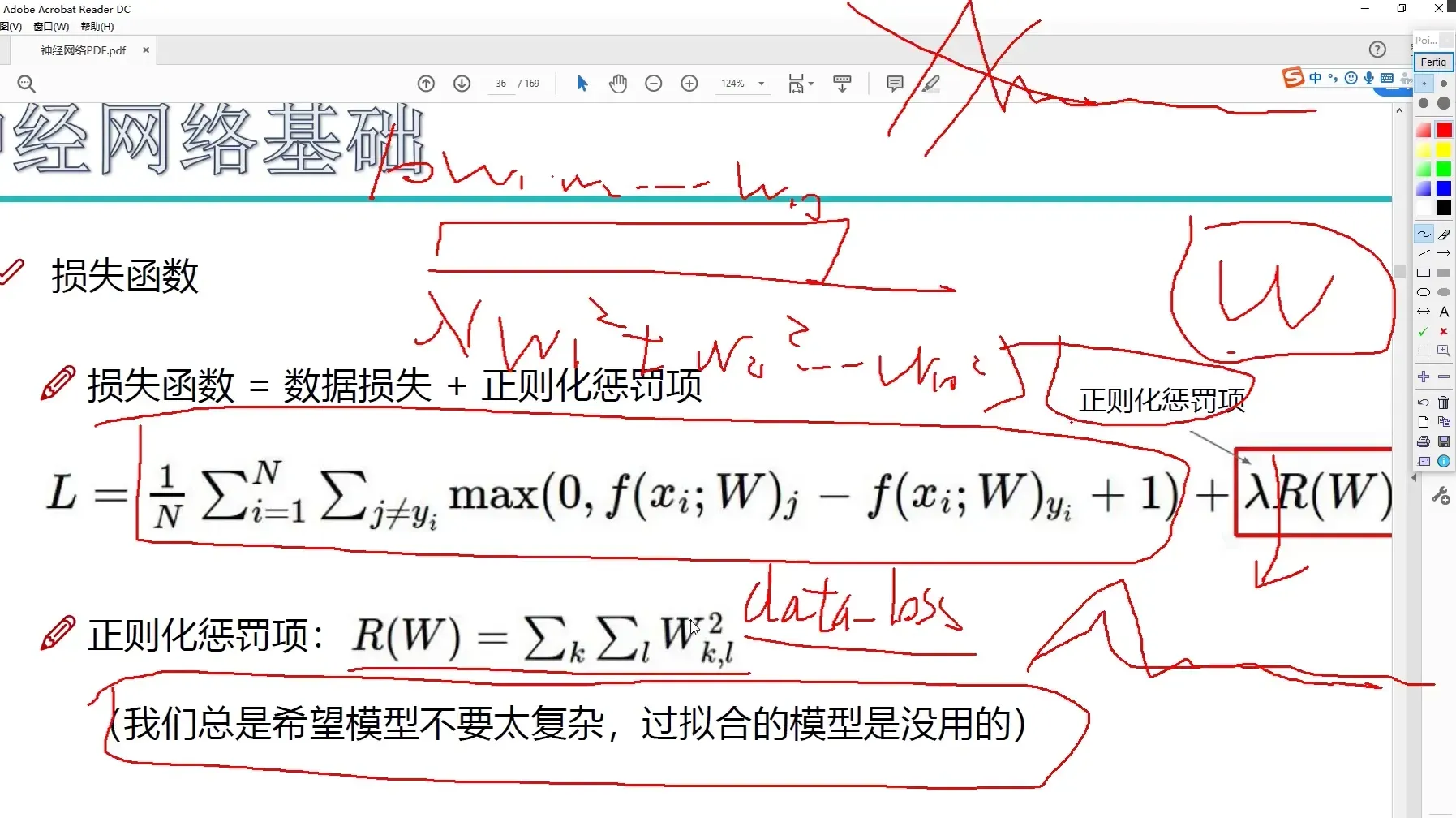
越大,抑制效果越强
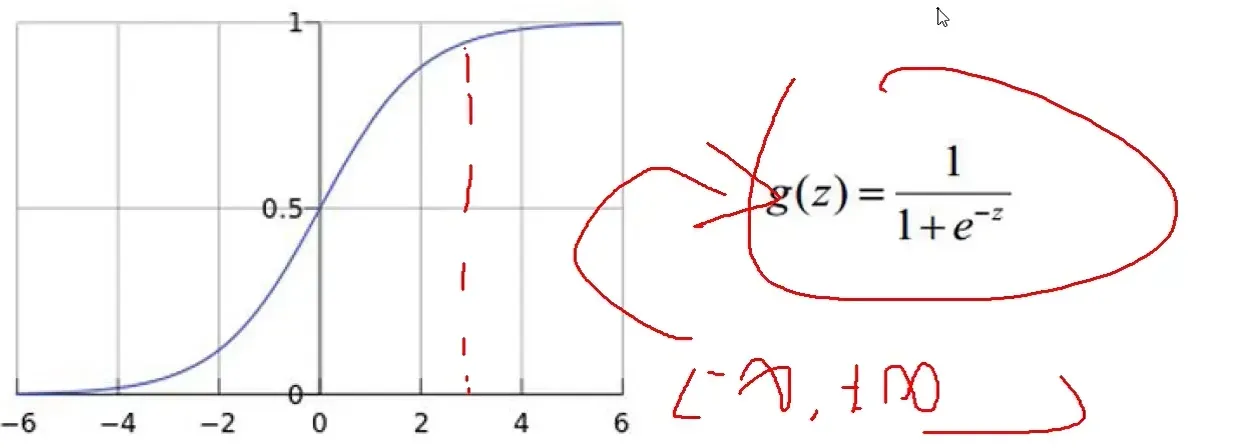
Softmax分类器
现在我们得到的是一个输入的得分值,但如果给我一个概率值岂不更好!
如何把一个得分值转换成一个概率值呢?
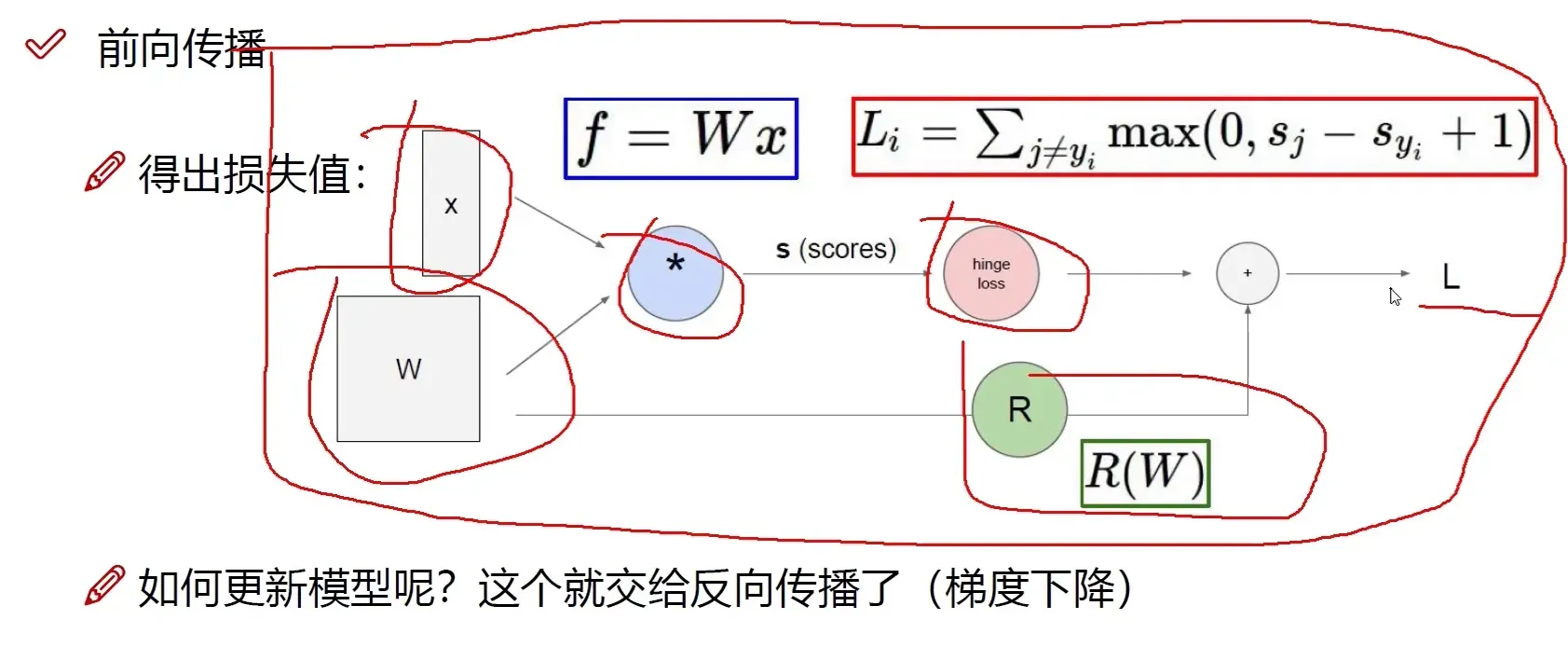
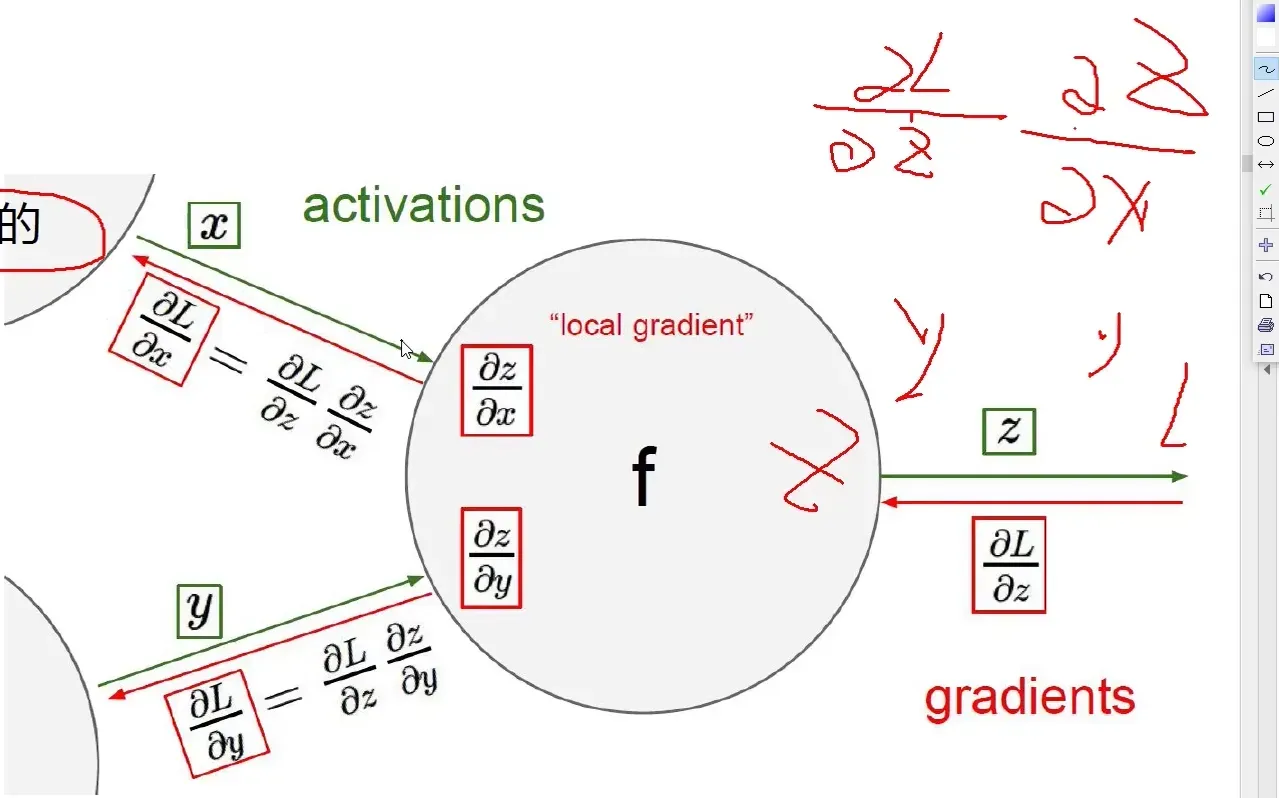
前向传播
反向传播
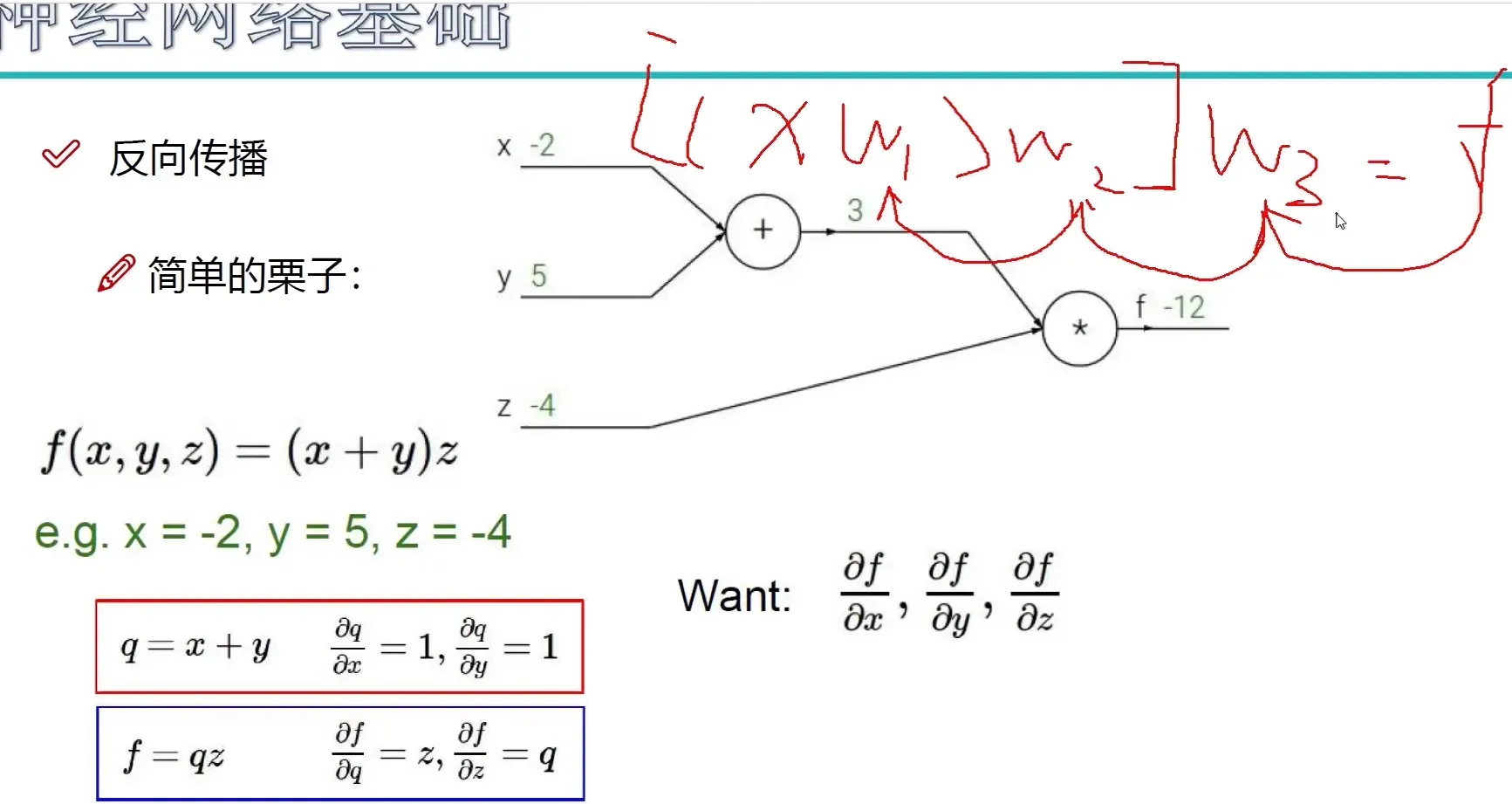
从后往前,逐层逐步传播
加法门单元:均等分配
MAX门单元:给最大的
乘法门单元:互换的感觉
链式法则
梯度是一步一步传的
·
复杂的例子
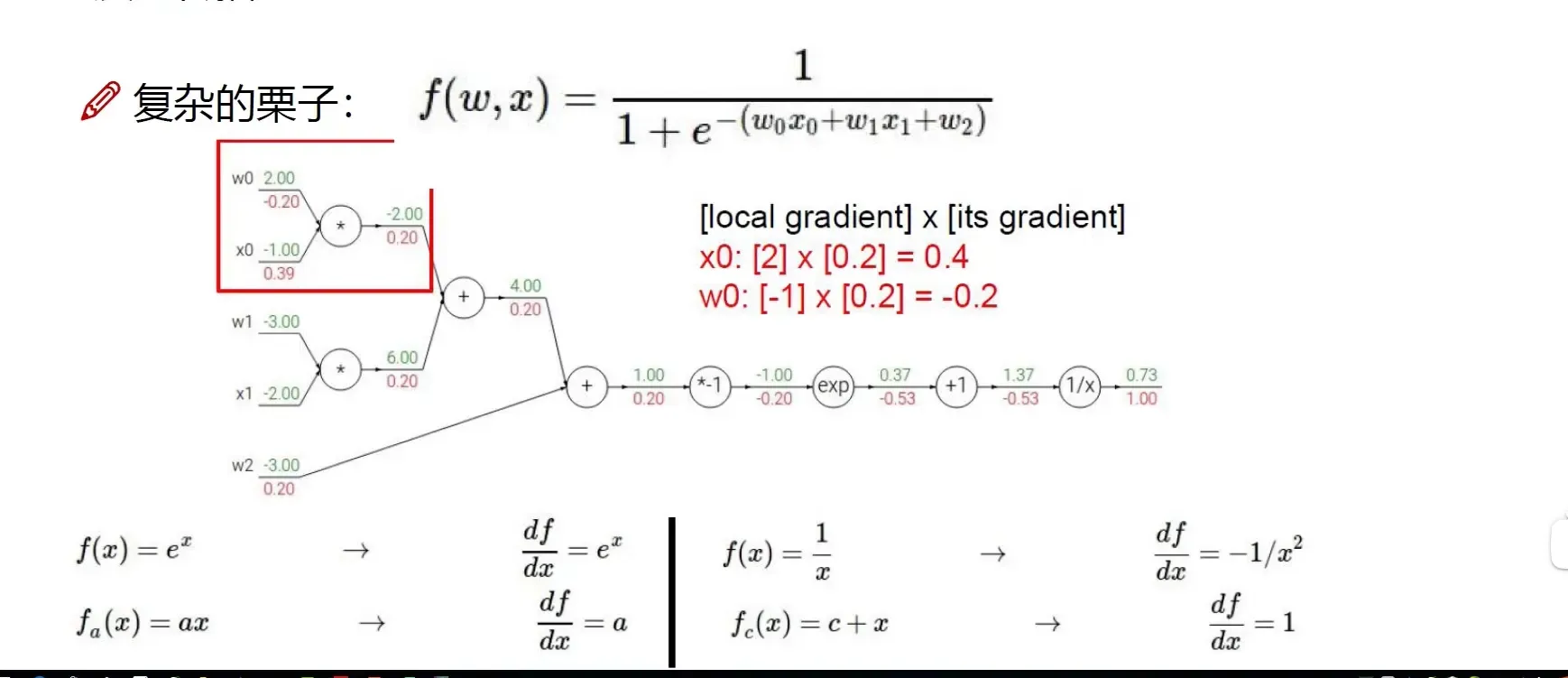
整体结构
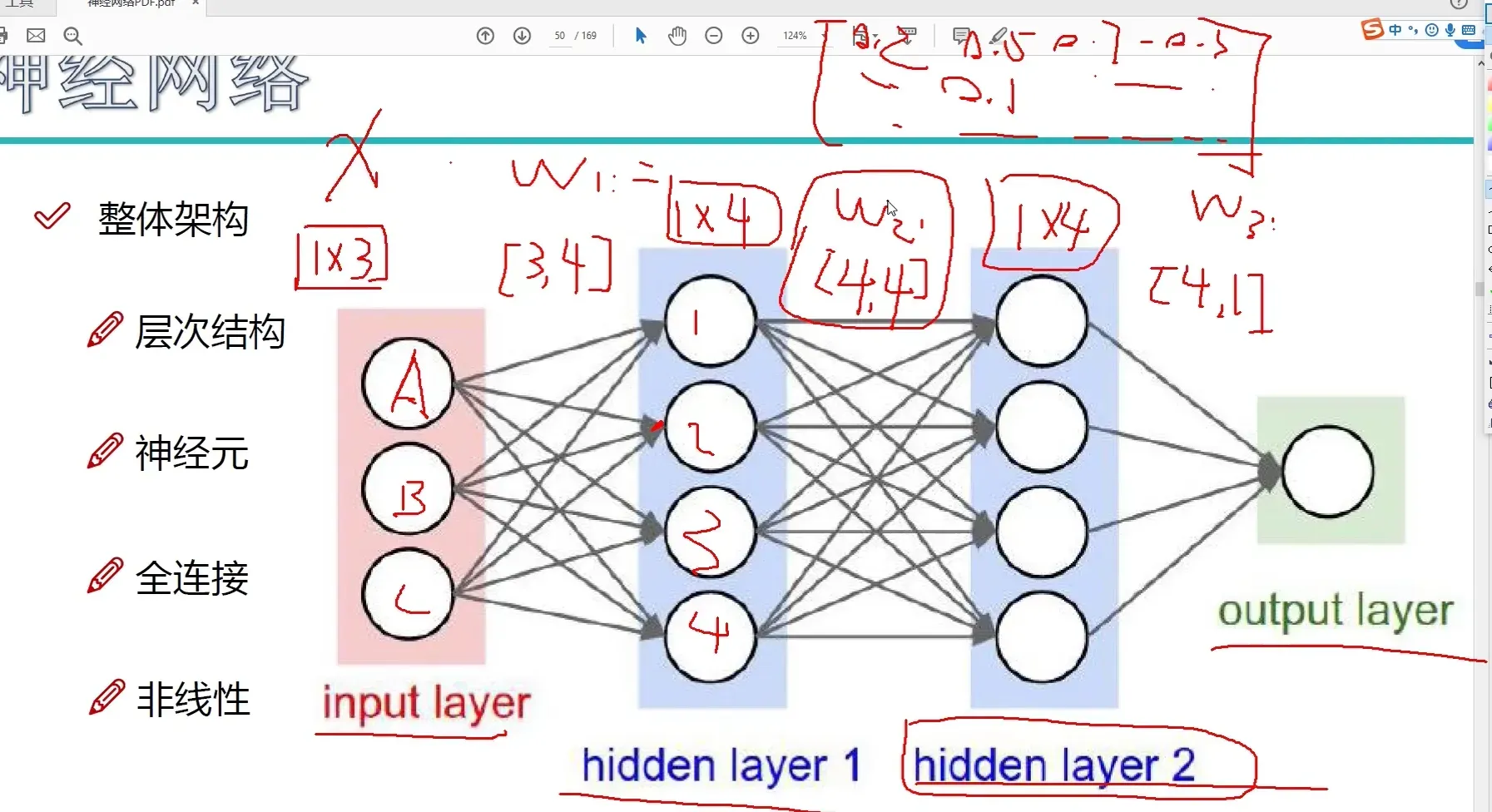
基本结构:
继续堆叠一层:
神经网络的强大之处在于,用更多的参数来拟合复杂的数据
(参数多到多少呢?百万级别都是小儿科,但是参数越多越好吗?)
神经元个数越多,得到的过拟合成对越大,在计算机上得到的效果可能会越好,运行速度相对会变慢。
https://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html
正则化的作用
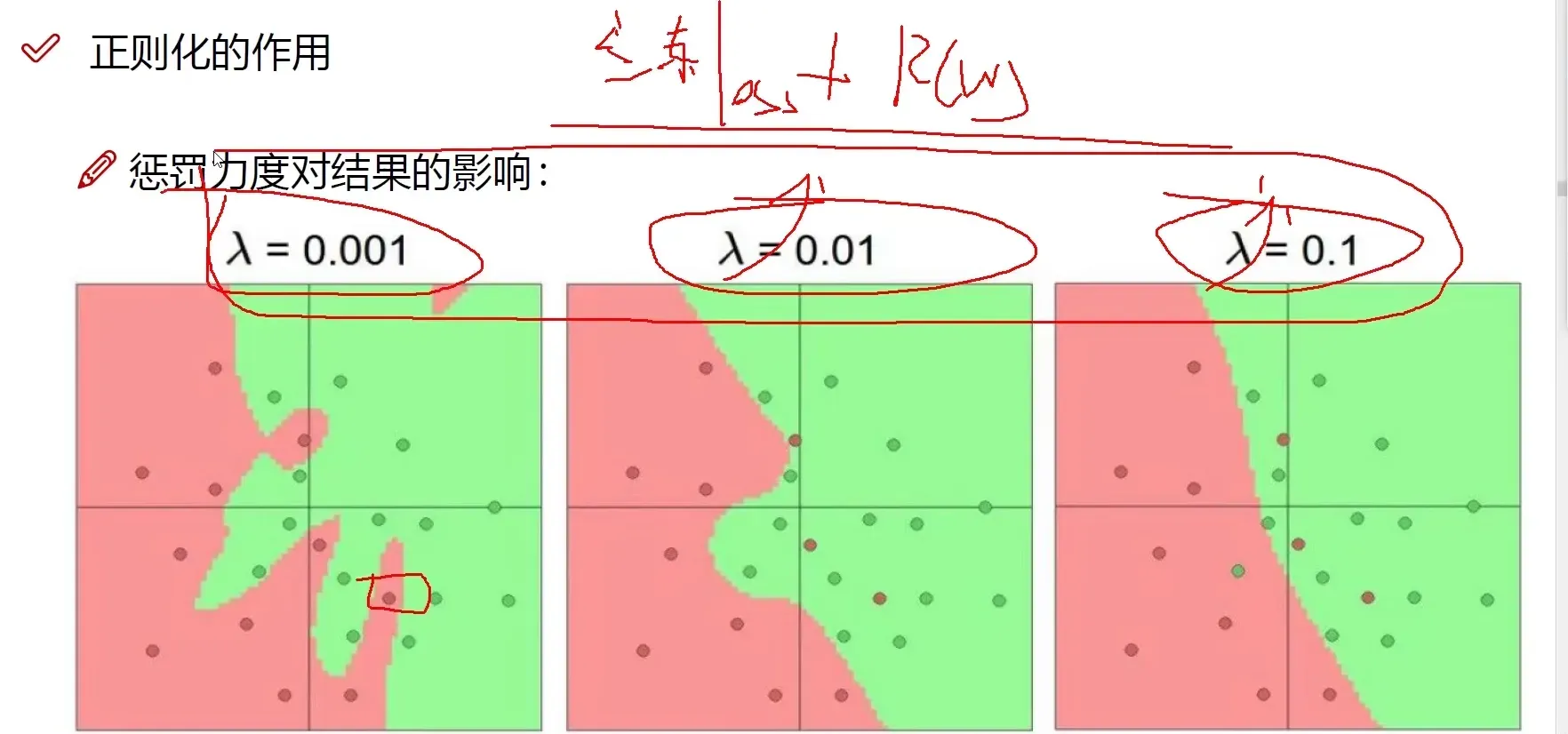
惩罚力度加大,W更加正常,边界更加平滑,防止过拟合
参数个数对结果的影响

激活函数
非常重要的一部分
常用的激活函数(Sigmoid,Relu,Tanh等)
激活函数对比
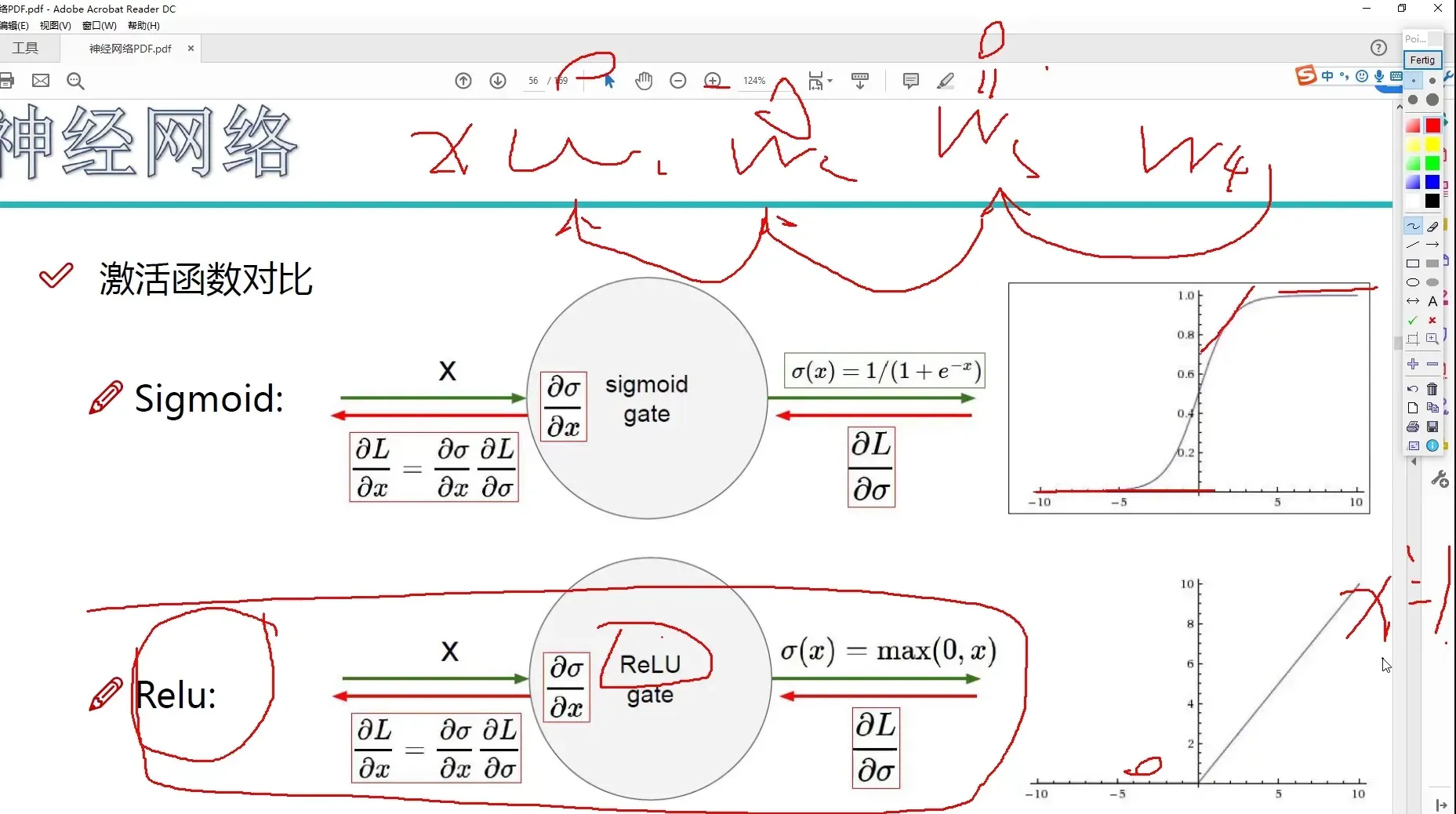
Sigmod 函数可能会造成梯度消失
现在市面上多采用 Relu 函数及其变式
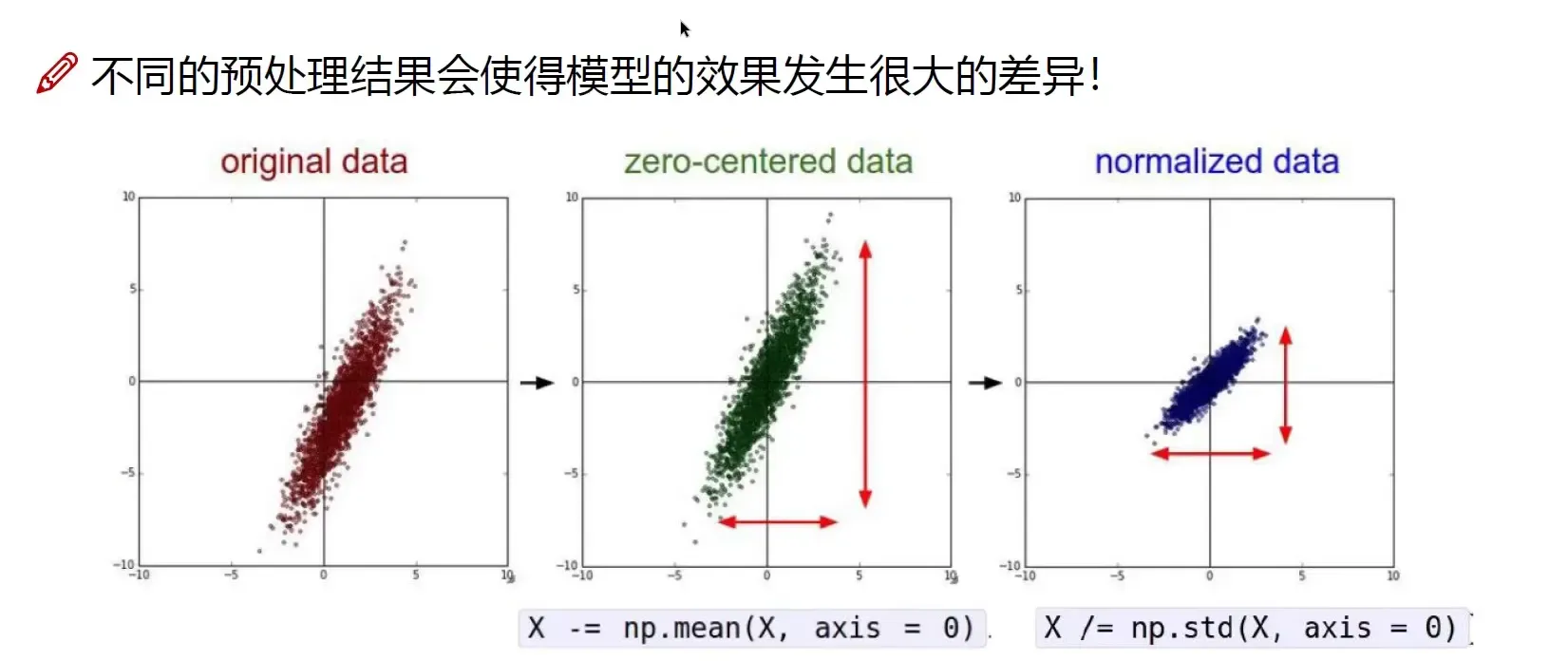
数据预处理
不同的预处理结果会使得模型的效果发生很大的差异。
参数初始化
参数初始化同样非常重要
通常我们都使用随机策略来进行参数初始化
让W值尽可能比较小,平滑
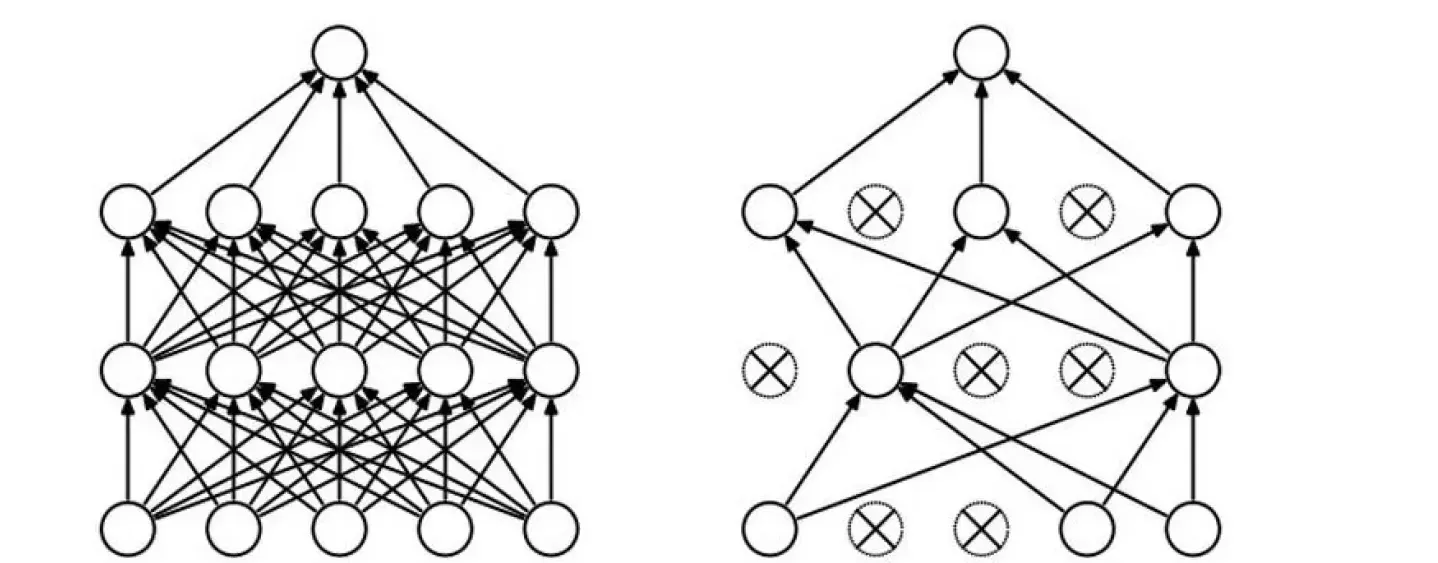
DROP-OUT(传说中的七伤拳)
过拟合是神经网络非常头疼的一个大问题!
线性回归
梯度下降
目标函数:
寻找山谷的最低点,也就是我们的目标函数终点(什么样的参数能使得目标函数达到极值点)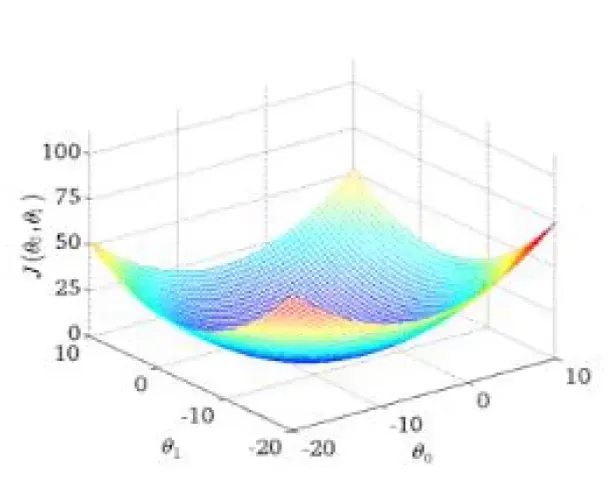
文章出处登录后可见!