主成分分析(Principal components analysis,简称PCA)是无监督机器学习算法,用于发现主成分,即原始预测变量的组合形式,用于数据集中大部分变化。
PCA分析的目标是用比原数据集更少的变量解释数据集中的大多数可变性。假设数据集包括p个变量,每次取其中两个变量利用散点图检查相关性,要是变量较多,则散点图数量会变得非常大。p个变量则包括p*(p-1)个散点图,如果p=15,则需要105个散点图。
幸运的是,PCA提供了尽可能利用低维变量表示多维数据集的方式。如果能够在二维空间中获得大部分信息,则可以把原始数据投影在二维散点图中。
获取主成分的过程:给定数据集,包括p个预测变量:, 计算
共m个线性组合表示原始p个预测变量。
主成分线性组合公式:, 其中
, m = 1, …, M.
是包含最大方差的预测变量的线性组合。
是与
- 然后
是下一个捕捉最大的方差的预测变量的线性组合,并且正交于
- 等等。。。
计算原始变量的线性组合步骤如下:
- 把变量标准化为均值为0,标准差为1
- 对已标准化计算协方差矩阵
- 计算协方差矩阵的特征值
利用线性代数知识,可以获得最大特征值对应的特征向量,即为第一主成分。也就是说,这个预测变量的特别组合能够解释数据集的最大方差。同理第二大特征值对应的特征向量是第二个主成分,以此类推。下面通过示例说明实现过程。
主成分分析示例
1.加载数据
首先我们加载tidyverse包,它有几个有用的函数,用于可视化和处理数据:
library(tidyverse)
#load data
data("USArrests")
#view first six rows of data
head(USArrests)
# Murder Assault UrbanPop Rape
# Alabama 13.2 236 58 21.2
# Alaska 10.0 263 48 44.5
# Arizona 8.1 294 80 31.0
# Arkansas 8.8 190 50 19.5
# California 9.0 276 91 40.6
# Colorado 7.9 204 78 38.7
本示例使用R内置的USArrests数据集,它包括美国1973年每100000人犯罪记录信息,包括谋杀、人身攻击、强奸变量,WW还包括变量表示市区人口百分比。
2. 计算主成分
数据加载之后,我们利用R内置函数prcomp()函数计算数据集的主成分。需要指定参数 scale=TRUE,设定计算主成分之前现标准化数据集变量。
另外R计算出来的特征向量默认为负数,所以我们乘以-1反转符号。
# 计算主成分
results <- prcomp(USArrests, scale = TRUE)
# 反转符号
results$rotation <- -1*results$rotation
# 现实主成分
results$rotation
# PC1 PC2 PC3 PC4
# Murder 0.5358995 -0.4181809 0.3412327 -0.64922780
# Assault 0.5831836 -0.1879856 0.2681484 0.74340748
# UrbanPop 0.2781909 0.8728062 0.3780158 -0.13387773
# Rape 0.5434321 0.1673186 -0.8177779 -0.08902432
我们看到第一主成分(PC1)的 Murder、Assault、Rape值较高,表明第一主成分描述这些变量的大部分方差。第二主成分(PC2)的UrbanPop值较高,表明这一主要组成部分主要强调城市人口。
每个州的主成分得分存储在result$x中,我们也乘以-1反转其符号:
# 反转得分符号
results$x <- -1*results$x
# 现实前6个得分
head(results$x)
# PC1 PC2 PC3 PC4
# Alabama 0.9756604 -1.1220012 0.43980366 -0.154696581
# Alaska 1.9305379 -1.0624269 -2.01950027 0.434175454
# Arizona 1.7454429 0.7384595 -0.05423025 0.826264240
# Arkansas -0.1399989 -1.1085423 -0.11342217 0.180973554
# California 2.4986128 1.5274267 -0.59254100 0.338559240
# Colorado 1.4993407 0.9776297 -1.08400162 -0.001450164
3. 双标图可视化结果
接下来我们创建双标图 ———— 使用前两个主成分画每个州的散点图:
biplot(results, scale = 0)
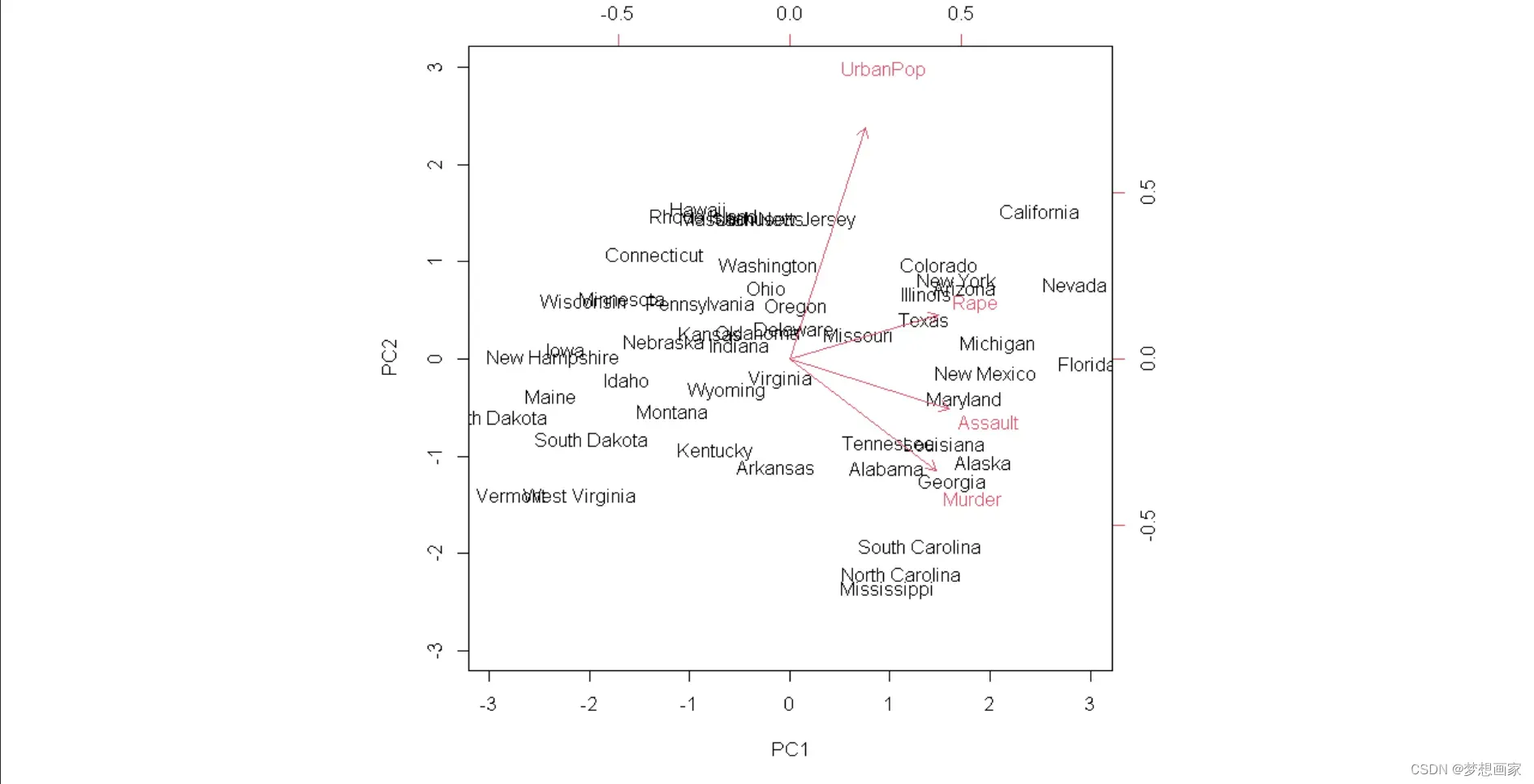
scale = 0确保图中的箭头被缩放以表示加载数据。该图把50州数据表示在简单二维空间中。对于原始数据集中记录,图中相互接近的状态具有类似的模式。我们看到某些州与特定犯罪关联较大,如Georgia州在图中最接近变量Murder。
如果查看原始数据中最好murder率的数据,可以看到Georgia排在前面:
head(USArrests[order(-USArrests$Murder),])
# Murder Assault UrbanPop Rape
# Georgia 17.4 211 60 25.8
# Mississippi 16.1 259 44 17.1
# Florida 15.4 335 80 31.9
# Louisiana 15.4 249 66 22.2
# South Carolina 14.4 279 48 22.5
# Alabama 13.2 236 58 21.2
4. 每个主成分能解释的方差
下面代码计算原数据集能够被每个主成分解释方差大小:
# 计算被每个主成分解释的总方差
results$sdev^2 / sum(results$sdev^2)
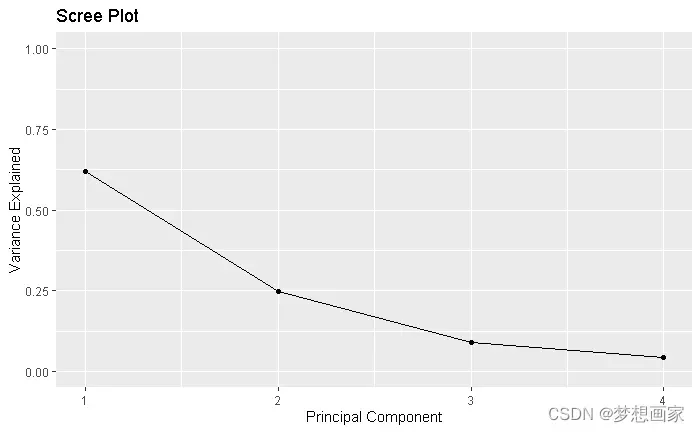
# [1] 0.62006039 0.24744129 0.08914080 0.04335752
从结果我们可以观察到以下几点:
第一个主成分解释了数据集中总方差的62%。
第二个主成分解释了数据集总方差的24.7%。
第三个主成分解释了数据集中总方差的8.9%。
第四个主成分解释了数据集总方差的4.3%。
这样前两个主成分就能够解释数据集中绝大部分方差。这和预想一致,因为之前双标图将原始数据中的每个观测结果投影到散点图上,散点图只考虑了前两个主要成分。因此通过查看双标图中可识别彼此相似的状态。
我们还可以创建碎石图来可视化PCA的结果,碎石图能够显示每个主成分能够解释总方差:
# 计算每个主成分能够解释总方差
var_explained = results$sdev^2 / sum(results$sdev^2)
# 创建碎石图
qplot(c(1:4), var_explained) +
geom_line() +
xlab("Principal Component") +
ylab("Variance Explained") +
ggtitle("Scree Plot") +
ylim(0, 1)
PCA的实际应用
-
探索性数据分析:当我们首次探索数据时,使用PCA能够了解数据中哪些观察结果彼此最相似。
-
主成分回归:我们也可以使用主成分分析来计算主成分,然后在主成分回归中使用。当数据集中的预测因子之间存在多重共线性时,通常使用这种类型的回归。
文章出处登录后可见!