专栏链接:
深度学习知识点总结_Mr.小梅的博客-CSDN博客本专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
本章介绍从RNN到Attention到Transformer系列-Transformer介绍及代码实现。
目录
3.5 Transformer介绍
参考论文《Attention is All You Need》。
Transformer最初应用到机器翻译中,首先简单看一个机器翻译所用的简单的结构。
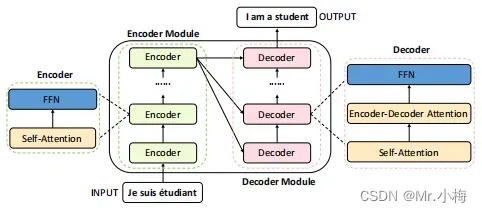
主要由一个编码模块(encoder module)和一个解码模块(decoder module)组成 ,每一个模块分别由多个编码器或者解码器构成,每一个编码器是由一个self-attention layer和一个feed-forward NN组成,每一个解码器是由一个self-attention layer、一个encoder decoder attention layer和一个feed-forward NN组成,多了一个encoder decoder attention layer。对于每一个输入待翻译的句子,都会生成一个d_model=512维的向量,然后再将这些向量重新解码后输出翻译结果。
3.5.1 Self-Attention
在self-attention layer中输入的向量将统一转换成三个向量,query vector(q)、key vector(k)和value vector(v)。它们的维度都是512,。同理对多个不同的输入则统一编码成三个对应的矩阵Q、K、V,之后通过以下步骤进行计算:
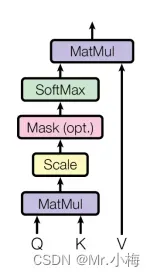
- Step 1:计算不用输入向量之间的分数:
- Step 2:将梯度稳定性的分数标准化:
-
Step 3:使用softmax将分数转换为概率:
-
上一步计算得到的可以理解成权重值,最后得到加权矩阵
,整合在一起得到:
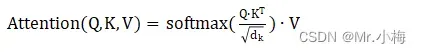
注意:分母是为了归一化,避免造成进入softmax函数的饱和区,其梯度较小。
论文中对这一部分介绍的不是很清楚,理解起来比较麻烦,接下来就按照自己的理解,详细介绍一下到底Q、T、V都代表什么,又有什么含义,整个算法可训练的weights又是哪些?
首先,我们输入一句话“我是中国人”,其中每个字通过编码可以生成一个向量,假设向量维度8,则这句话的矩阵尺寸X就是(5,8),Step 1计算的则是每个字与每个字之间的关系,则输出S的shape应该为(5,5),Q和K一起使用以获取注意力向量,用于获取V的加权总和。Q和K可以理解成对输入的矩阵(5,8)进行全连接,对每个字的特征进行转换,现在输入的每个字的维度是8,假设转换后的维度是10,则Q和K的shape是(5,10)。那么Q和K是怎么得到的,这就出现了可优化学习的权重值和
| P | 我 | 是 | 中 | 国 | 人 |
| 我 | 0.1904 | 0.2463 | 0.2027 | 0.1952 | 0.1654 |
| 是 | |||||
| 中 | |||||
| 国 | |||||
| 人 |
我们那其中一行来看,第一行,代表“我”这个字与其他字之间的关系,可以理解成权重,根据公式即可得到最终的输出,同样V和Q、K也一样,可以理解成把输入X进行一定的变换,得到新的表示方式,现在输入的X每个字的维度是8,假设我们想要输出维度512,
的shape为(8,512),
,即V的shape为(5,512),则输出Z的shape为(5,512)。这样一个句子输入的矩阵(5,8)就转换成(5,512),相当于把每个独立字的向量,通过self-attention转换成字与字之间关系的向量。
3.5.2 位置编码
从上面的示例也可以看出,上述过程与每个字的位置无关,既然位置无关,说明self-attention缺乏捕捉单词位置信息的能力,但我们知道在一句话中每个词的位置是很重要的,为了解决这一问题,一个常见的解决方案是向输入端附加一个额外的位置向量,称之为位置编码,位置编码有很多种可以选择,一个典型的编码方式如下:
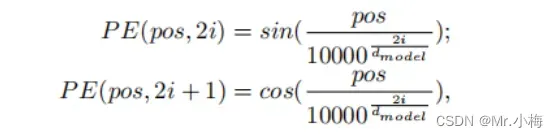
pos代表每个词在句子中的位置,i代表目前位置编码的当前维度,这样下来,位置编码中的每个元素都对应于一个正弦曲线,它允许Transformer模型通过相对位置学习参与,并在推断期间推断出更长的序列长度。
class PositionwiseFeedforwardLayer(nn.Module):
def __init__(self, hid_dim, pf_dim, dropout):
super().__init__()
self.fc_1 = nn.Linear(hid_dim, pf_dim)
self.fc_2 = nn.Linear(pf_dim, hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# x = [batch size, seq len, hid dim]
x = self.dropout(torch.relu(self.fc_1(x)))
# x = [batch size, seq len, pf dim]
x = self.fc_2(x)
# x = [batch size, seq len, hid dim]
return x将输入序列编码后的X再加上位置编码即可。
总结一下:
| 假设词编码维度是256 | |||
| 输入单词:我是中国人 | 词编码后输出5×256 | 位置编码输出5×256 | 词编码+位置编码输出5×256 |
3.5.3 Multi-Head Attention
采用multi-head attention为的就是让不同head学习到不同的子空间语义。显然实验也证实这种形式的结果较好。
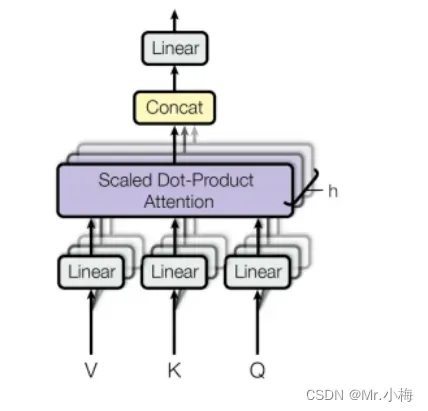
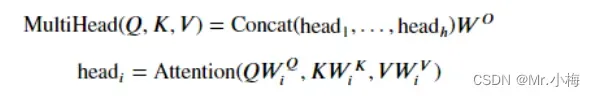
Wo是应用于多头注意力层末端的线性层WQ,WK,WV是线性层。
class MultiHeadAttentionLayer(nn.Module):
def __init__(self, hid_dim, n_heads, dropout, device):
super().__init__()
assert hid_dim % n_heads == 0
self.hid_dim = hid_dim
self.n_heads = n_heads
self.head_dim = hid_dim // n_heads
self.fc_q = nn.Linear(hid_dim, hid_dim)
self.fc_k = nn.Linear(hid_dim, hid_dim)
self.fc_v = nn.Linear(hid_dim, hid_dim)
self.fc_o = nn.Linear(hid_dim, hid_dim)
self.dropout = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([self.head_dim])).to(device)
def forward(self, query, key, value, mask=None):
batch_size = query.shape[0]
# query = [batch size, query len, hid dim]
# key = [batch size, key len, hid dim]
# value = [batch size, value len, hid dim]
Q = self.fc_q(query)
K = self.fc_k(key)
V = self.fc_v(value)
# Q = [batch size, query len, hid dim]
# K = [batch size, key len, hid dim]
# V = [batch size, value len, hid dim]
Q = Q.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
K = K.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
V = V.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3)
# Q = [batch size, n heads, query len, head dim]
# K = [batch size, n heads, key len, head dim]
# V = [batch size, n heads, value len, head dim]
energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
# energy = [batch size, n heads, query len, key len]
if mask is not None:
energy = energy.masked_fill(mask == 0, -1e10)
attention = torch.softmax(energy, dim=-1)
# attention = [batch size, n heads, query len, key len]
x = torch.matmul(self.dropout(attention), V)
# x = [batch size, n heads, query len, head dim]
x = x.permute(0, 2, 1, 3).contiguous()
# x = [batch size, query len, n heads, head dim]
x = x.view(batch_size, -1, self.hid_dim)
# x = [batch size, query len, hid dim]
x = self.fc_o(x)
# x = [batch size, query len, hid dim]
return x, attention
3.5.4 整体结构
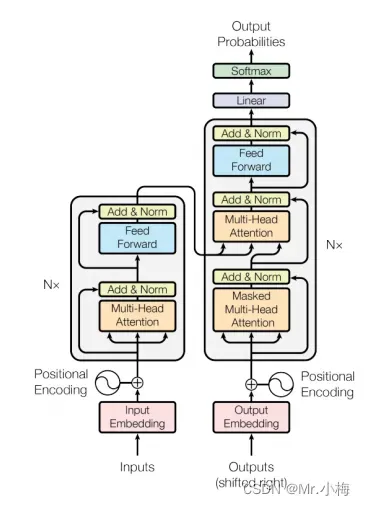
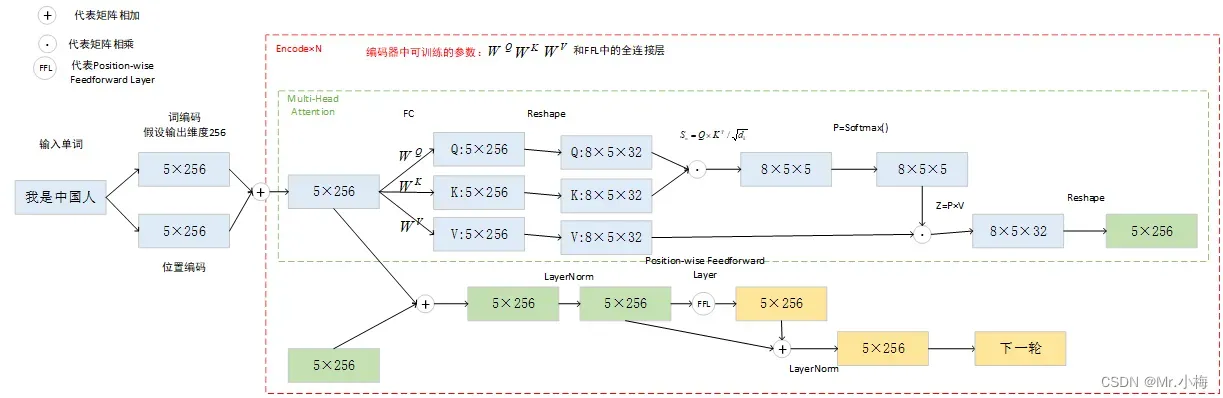
3.5.5 编码器中间计算过程示意图
高清图见下载链接
代码实现:
class Encoder(nn.Module):
def __init__(self,
input_dim,
hid_dim,
n_layers,
n_heads,
pf_dim,
dropout,
device,
max_length=100):
super().__init__()
self.device = device
self.tok_embedding = nn.Embedding(input_dim, hid_dim)
self.pos_embedding = nn.Embedding(max_length, hid_dim)
self.layers = nn.ModuleList([EncoderLayer(hid_dim,
n_heads,
pf_dim,
dropout,
device)
for _ in range(n_layers)])
self.dropout = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([hid_dim])).to(device)
def forward(self, src, src_mask):
# src = [batch size, src len]
# src_mask = [batch size, 1, 1, src len]
batch_size = src.shape[0]
src_len = src.shape[1]
pos = torch.arange(0, src_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
# pos = [batch size, src len]
src = self.dropout((self.tok_embedding(src) * self.scale) + self.pos_embedding(pos))
# src = [batch size, src len, hid dim]
for layer in self.layers:
src = layer(src, src_mask)
# src = [batch size, src len, hid dim]
return src
class EncoderLayer(nn.Module):
def __init__(self,
hid_dim,
n_heads,
pf_dim,
dropout,
device):
super().__init__()
self.self_attn_layer_norm = nn.LayerNorm(hid_dim)
self.ff_layer_norm = nn.LayerNorm(hid_dim)
self.self_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout, device)
self.positionwise_feedforward = PositionwiseFeedforwardLayer(hid_dim,
pf_dim,
dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src, src_mask):
# src = [batch size, src len, hid dim]
# src_mask = [batch size, 1, 1, src len]
# self attention
_src, _ = self.self_attention(src, src, src, src_mask)
# dropout, residual connection and layer norm
src = self.self_attn_layer_norm(src + self.dropout(_src))
# src = [batch size, src len, hid dim]
# positionwise feedforward
_src = self.positionwise_feedforward(src)
# dropout, residual and layer norm
src = self.ff_layer_norm(src + self.dropout(_src))
# src = [batch size, src len, hid dim]
return src
3.5.6 解码器中间计算过程示意图
高清图见下载链接
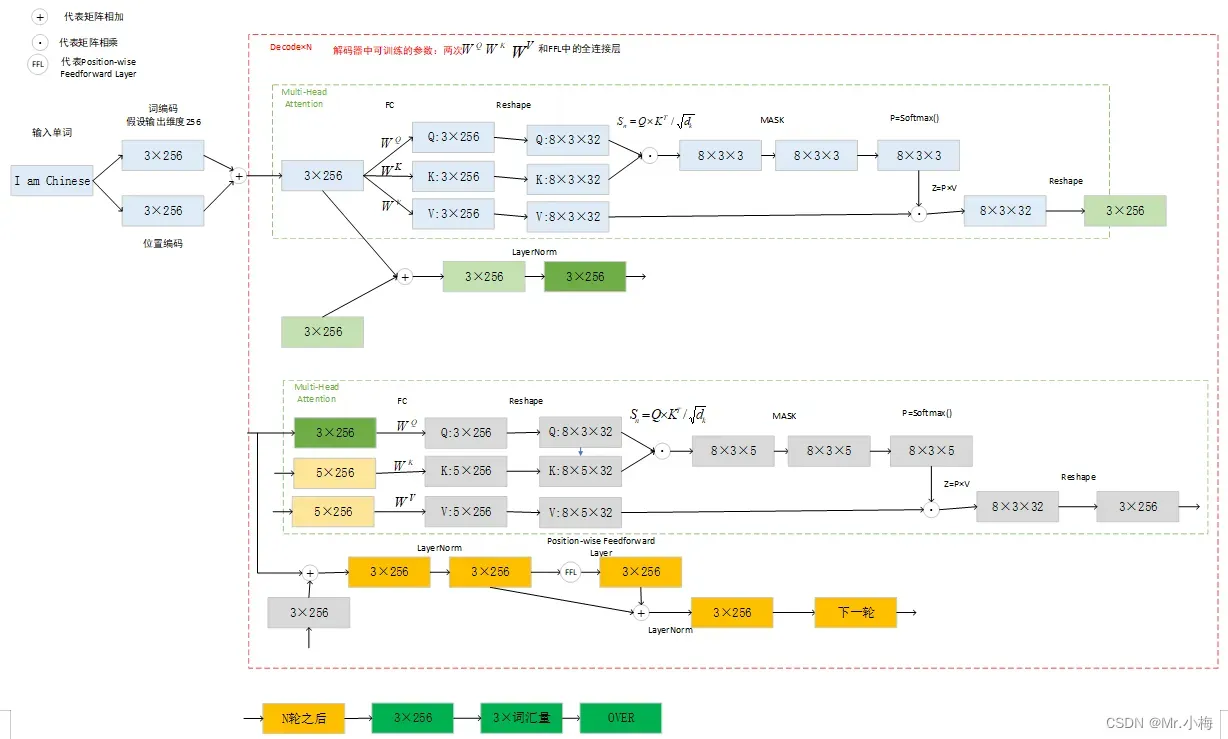
代码实现:
class Decoder(nn.Module):
def __init__(self,
output_dim,
hid_dim,
n_layers,
n_heads,
pf_dim,
dropout,
device,
max_length=100):
super().__init__()
self.device = device
self.tok_embedding = nn.Embedding(output_dim, hid_dim)
self.pos_embedding = nn.Embedding(max_length, hid_dim)
self.layers = nn.ModuleList([DecoderLayer(hid_dim,
n_heads,
pf_dim,
dropout,
device)
for _ in range(n_layers)])
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
self.scale = torch.sqrt(torch.FloatTensor([hid_dim])).to(device)
def forward(self, trg, enc_src, trg_mask, src_mask):
# trg = [batch size, trg len]
# enc_src = [batch size, src len, hid dim]
# trg_mask = [batch size, 1, trg len, trg len]
# src_mask = [batch size, 1, 1, src len]
batch_size = trg.shape[0]
trg_len = trg.shape[1]
pos = torch.arange(0, trg_len).unsqueeze(0).repeat(batch_size, 1).to(self.device)
# pos = [batch size, trg len]
trg = self.dropout((self.tok_embedding(trg) * self.scale) + self.pos_embedding(pos))
# trg = [batch size, trg len, hid dim]
for layer in self.layers:
trg, attention = layer(trg, enc_src, trg_mask, src_mask)
# trg = [batch size, trg len, hid dim]
# attention = [batch size, n heads, trg len, src len]
output = self.fc_out(trg)
# output = [batch size, trg len, output dim]
return output, attention
class DecoderLayer(nn.Module):
def __init__(self,
hid_dim,
n_heads,
pf_dim,
dropout,
device):
super().__init__()
self.self_attn_layer_norm = nn.LayerNorm(hid_dim)
self.enc_attn_layer_norm = nn.LayerNorm(hid_dim)
self.ff_layer_norm = nn.LayerNorm(hid_dim)
self.self_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout, device)
self.encoder_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout, device)
self.positionwise_feedforward = PositionwiseFeedforwardLayer(hid_dim,
pf_dim,
dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, trg, enc_src, trg_mask, src_mask):
# trg = [batch size, trg len, hid dim]
# enc_src = [batch size, src len, hid dim]
# trg_mask = [batch size, 1, trg len, trg len]
# src_mask = [batch size, 1, 1, src len]
# self attention
_trg, _ = self.self_attention(trg, trg, trg, trg_mask)
# dropout, residual connection and layer norm
trg = self.self_attn_layer_norm(trg + self.dropout(_trg))
# trg = [batch size, trg len, hid dim]
# encoder attention
_trg, attention = self.encoder_attention(trg, enc_src, enc_src, src_mask)
# dropout, residual connection and layer norm
trg = self.enc_attn_layer_norm(trg + self.dropout(_trg))
# trg = [batch size, trg len, hid dim]
# positionwise feedforward
_trg = self.positionwise_feedforward(trg)
# dropout, residual and layer norm
trg = self.ff_layer_norm(trg + self.dropout(_trg))
# trg = [batch size, trg len, hid dim]
# attention = [batch size, n heads, trg len, src len]
return trg, attention
3.5.7 Transformer总体示意图
高清图见下载链接
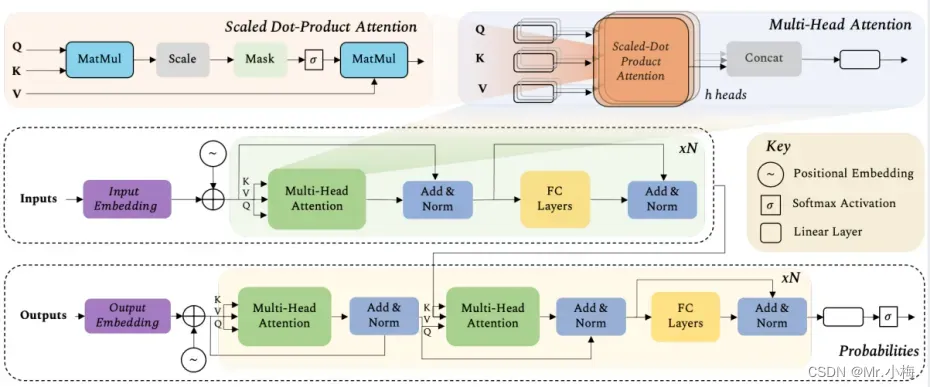
全部代码见下载链接。
文章出处登录后可见!