之前刷数独玩,出于偷懒的思想,总想着用计算机去解决。算法没少些,之前通过手工录入的9×9数据解数独,深度优先遍历算法,很容易。但总想更加方便一点,比如拍照直接解析一个数独的表格,自动解出来。
正好前几天休假,有空,就做了一些尝试,然后基本上给做出来了。
先上成果,截图如下:
 |  | 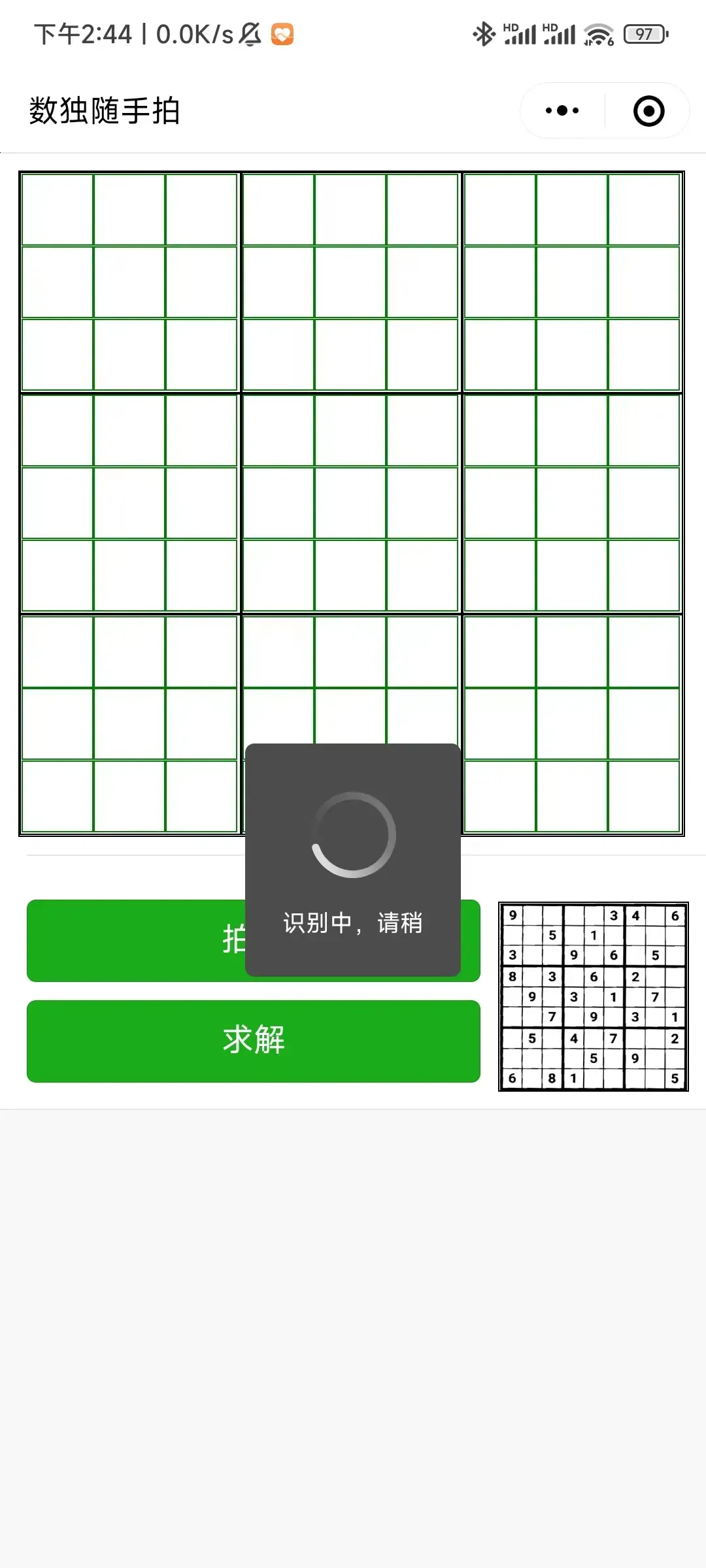 |
| 打开的空白界面 | 拍照,拍一张数独图片 | 识别过程 |
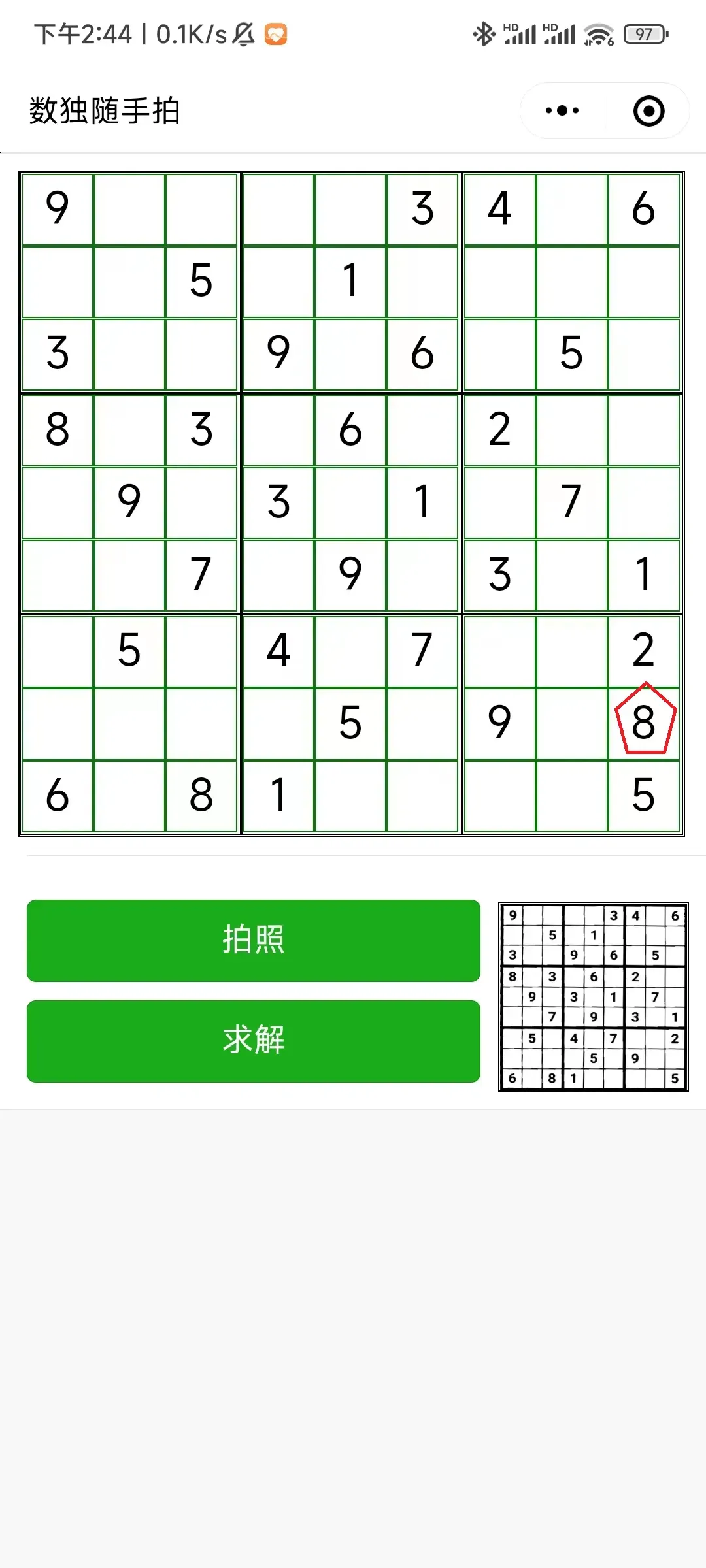 | 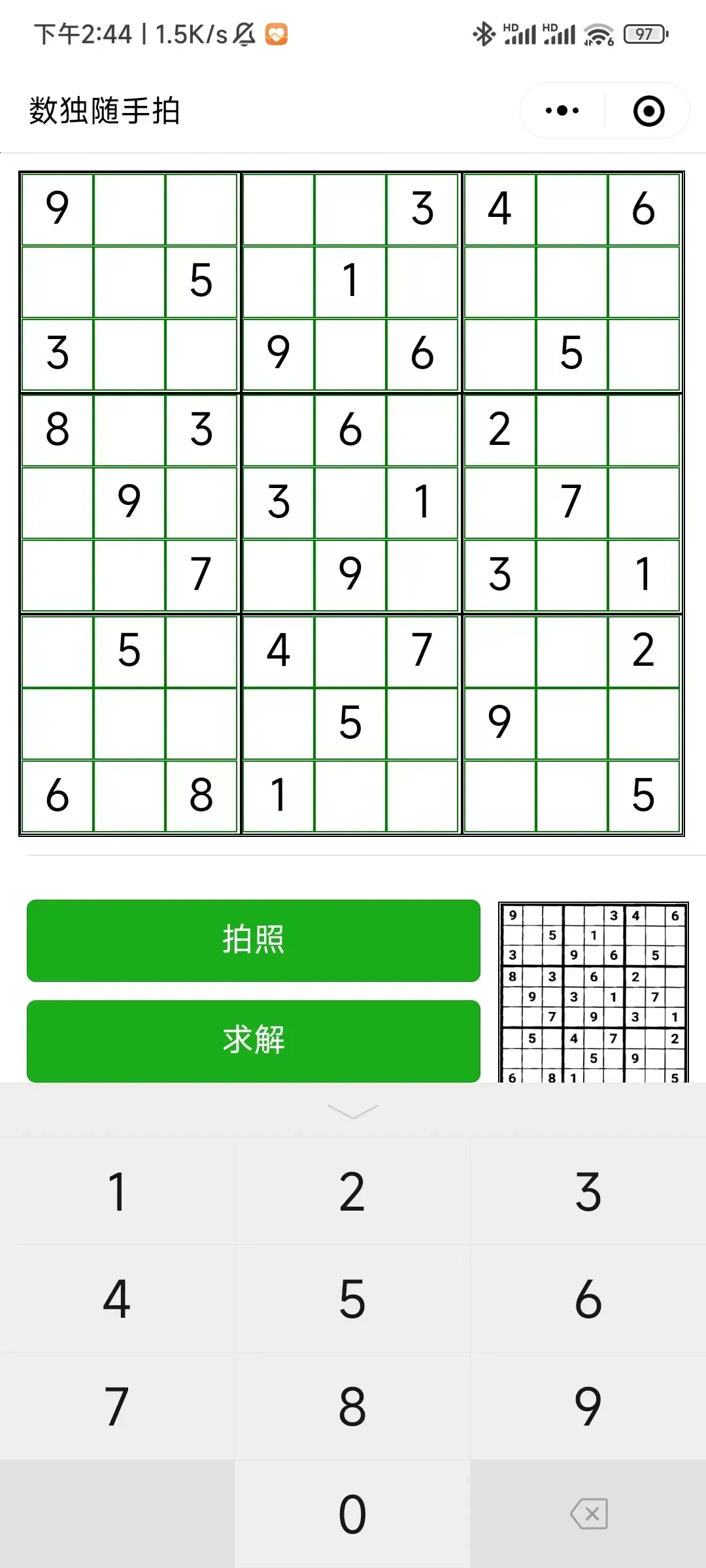 | 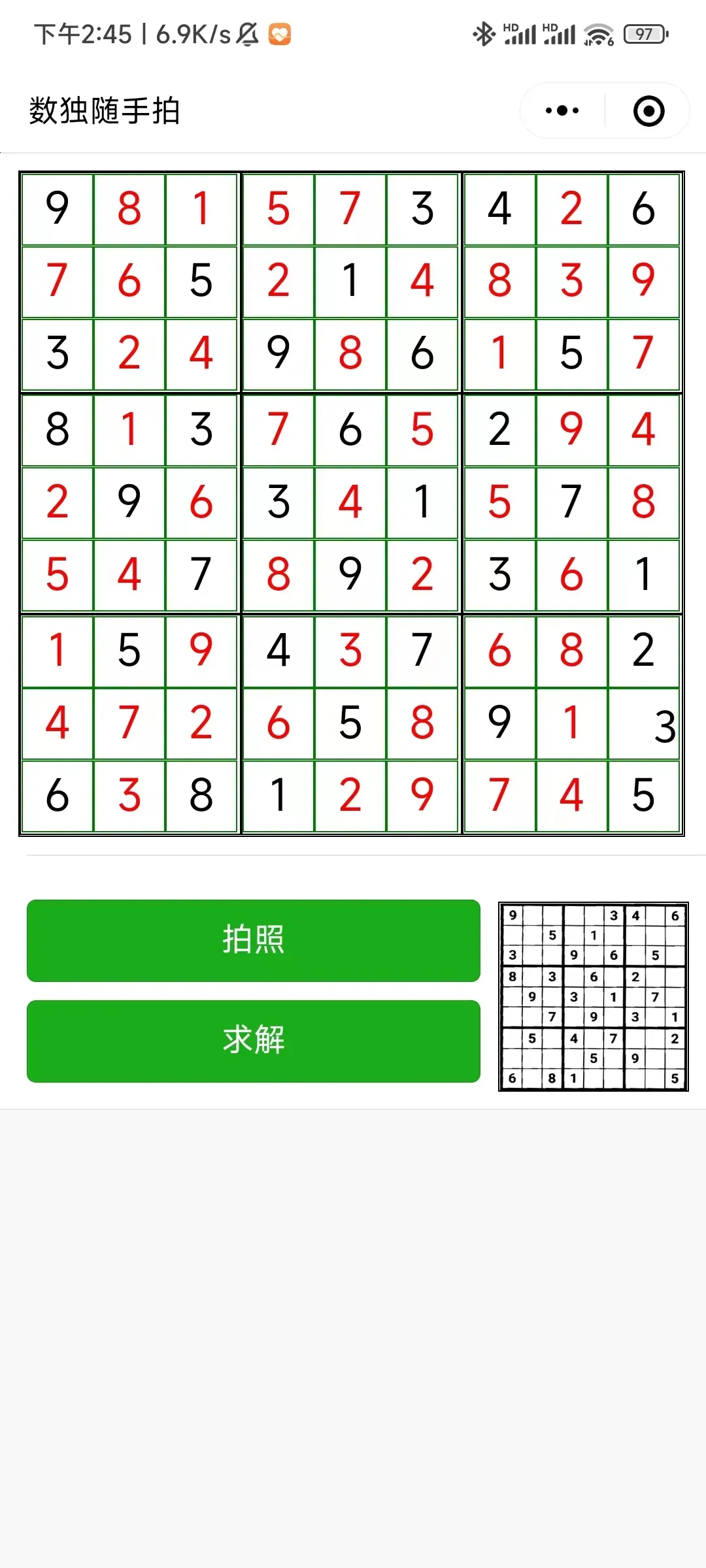 |
| 识别完成,但有错误 | 点击错误单元格,修改错误 | 完成求解 |
有感兴趣的同学可以到这里体验 :),当然bug是会有的,一切都是会有的 :),我也会不停地升级。

下面说一下思路
要实现这个功能,前面提到,早就想做,但无奈之前对图像识别入门太浅,没弄明白,这次也正好趁着休假,好好恶补了一下相关的知识,解决方案还是比较粗浅和粗暴的,有更好的方法,也欢迎大家来一起讨论。
涉及到的技术和工具:
1. 微信小程序开发
2. 图像处理,这里用OpenCV
3. 图像识别,用的Tesseract,在.NET core web服务器上实现
4. 解数独算法,用的.Net Core做的Web服务器
下面说详细的内容:
微信小程序开发不多说,也不是本文的重点。
图像处理涉及到OpenCV,最早是想直接图片扔到服务器端,由服务器端识别和后续处理,但考虑到那样太没有技术含量,加上服务器端毕竟是个人的环境,流量是按量收费的,所以考虑了把图像处理算法放到了微信小程序端。
这里感谢一下这位大大:sanyuered,以及他的github:github,提供了将opencv.js通过webassembly方式在小程序端执行的思路,按照大大的指引,使用了opencv 3.4.16版本的wasm文件的br压缩版,以及提供的相关接口opencv_exec.js文件。
有了这个,就在小程序里直接拍照和处理了,可以选择相册或者直接拍照。
async function takePhotoDirectly(_that, cameraContext) {
try {
// 拍照
var photoFilepath = await wx2sync.takePhoto(cameraContext);
_that.setData({ isTakePhoto: false });
console.debug("photoFilepath: ", photoFilepath);
wx.showLoading({ title: '识别中,请稍候...', mask: true });
_that.setData({
sampleImage1Url: photoFilepath,
})
sampleImage1 = photoFilepath;
await cvhelper.createImageElement(sampleImage1);
var srcMat = await cvhelper.getSrcMat();
var dstMat = await cvhelper.getTransform();
cv.imshow(_that.canvasDom, dstMat);
await recognize(_that);
wx.hideLoading();
console.log("gridChoosed: ", _that.data.gridChoosed);
} catch (ex) {
console.error("ex: ", ex);
}
}忽略掉行为控制代码和界面显示代码,以下代码的注释
拍照,用wx2sync包装了微信的wx.takePhoto,用promise转成同步代码,方便代码控制
var photoFilepath = await wx2sync.takePhoto(cameraContext);
async function takePhoto(cameraContext) {
return await new Promise((resolve, reject) => {
console.debug("cameraContext created: ", cameraContext);
cameraContext.takePhoto({
quality: "high",
success: function (res) {
console.debug("take photo: ", res);
resolve(res.tempImagePath);
},
fail: (res) => {
console.debug("take photo failed: ", res);
reject(res);
},
complete: (res) => {
console.debug("take photo complete: ", res)
}
});
});
}获取到图片后,对图片进行处理
// 上面获取到的图片的临时地址
sampleImage1 = photoFilepath;
// 用opencv获取这个图片,创建对象
await cvhelper.createImageElement(sampleImage1);
// 这里就是转成opencv需要的mat
var srcMat = await cvhelper.getSrcMat();
// 这里面做了好多事,就是各种处理,最终黑白图片带边框,然后进行梯形矫正,最终处理成数独的表格100%的正式内容
var dstMat = await cvhelper.getTransform();
 | 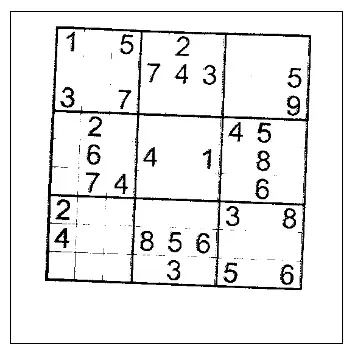 | 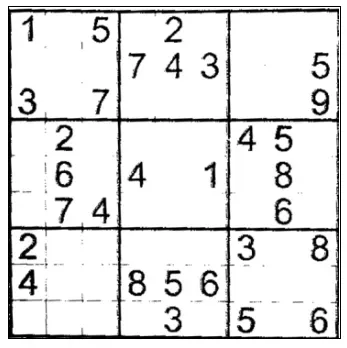 |
| 原始图片 | 灰度化、黑白处理后的图片 | 透视变换后的图片 |
接下来一步一步来
先是原始图片,然后处理成灰度图,再然后处理成黑白图
async getSrcMat() {
if (this.srcMat == null) {
this.srcMat = new cv.Mat();
this.srcMat = cv.imread(this.imageData);
// 设置画布的显示大小
this.canvas1Width = this.imageData.width;
this.canvas1Height = this.imageData.height;
}
return this.srcMat;
}
async getGrayMat() {
if (this.grayMat == null) {
var mat = new cv.Mat();
var srcMat = await this.getSrcMat();
cv.cvtColor(srcMat, mat, cv.COLOR_RGBA2GRAY, 0);
this.grayMat = mat;
}
return this.grayMat;
}
async getBlackMat() {
if (this.blackMat == null) {
var mat = new cv.Mat();
var grayMat = await this.getGrayMat();
cv.threshold(grayMat, mat, 100, 255, cv.THRESH_BINARY);
this.blackMat = mat;
}
return this.blackMat;
}然后对黑白图进行查找轮廓(如果必要的话可以进行锐化等一系列处理,目的就是为了让黑白图更加清晰地突出我们需要的内容)
查找轮廓的目的是检测图片中的内容,检测出来会有多个轮廓,我这里就直接选取最大块的轮廓。
最大轮廓的处理方式是,对每一个轮廓计算面积,实际测试看来轮廓的列表中有一个是整个图像的轮廓,我这里通过面积大于原始图片95%的方式过滤掉,剩下的最大的轮廓,我就认为是整个数独区域了。
let hierarchy = new cv.Mat();
let contourVector = new cv.MatVector();
cv.findContours(mat, contourVector, hierarchy, cv.RETR_CCOMP, cv.CHAIN_APPROX_SIMPLE);
var contours = [];
var contoursWithId = [];
for (var i = 0; i < contourVector.size(); i++) {
var contour = contourVector.get(i);
contoursWithId.push({
id: i,
contour: contour
});
contours.push(contour);
}
// 轮廓排序
contoursWithId.sort(function (a, b) {
return cv.contourArea(b.contour) - cv.contourArea(a.contour);
});
var canvasArea = this.canvas1Width * this.canvas1Height;
for (var i = 0; i < contoursWithId.length; i++) {
var contourArea = cv.contourArea(contoursWithId[i].contour);
//console.debug("contourArea: ", contourArea, ", canvasArea: ", canvasArea, ", i: ", i, ", contoursWithId.length: ", contoursWithId.length);
if (contourArea > canvasArea * 0.95) {
//console.debug("deleting... contourArea: %d, %: %2.2f", contourArea, contourArea/canvasArea);
contoursWithId.splice(i, 1);
i--;
}
}
var mainContour = contoursWithId[0];接下来对最大的这个轮廓,取出里面所有的点,分别按照四个象限检测出四个角的点。
var points = [];
for (let j = 0; j < mainContour.contour.data32S.length; j += 2) {
let p = {};
p.x = mainContour.contour.data32S[j];
p.y = mainContour.contour.data32S[j + 1];
points.push(p);
}
var centerX = this.canvas1Width / 2;
var centerY = this.canvas1Height / 2;
this.box.leftTopPoint = getPoints(points, false, false, centerX, centerY);
this.box.rightTopPoint = getPoints(points, true, false, centerX, centerY);
this.box.rightBottomPoint = getPoints(points, true, true, centerX, centerY);
this.box.leftBottomPoint = getPoints(points, false, true, centerX, centerY);
function getPoints(points, positiveX, positiveY, centerX, centerY) {
var newPoints = [];
points.forEach(a => {
if (a.x - centerX > 0 == positiveX && a.y - centerY > 0 == positiveY) {
newPoints.push(a);
}
});
newPoints.sort(function (a, b) {
return ((b.x - centerX) * (positiveX ? 1 : -1) + (b.y - centerY) * (positiveY ? 1 : -1)) - ((a.x - centerX) * (positiveX ? 1 : -1) + (a.y - centerY) * (positiveY ? 1 : -1));
});
return newPoints[0];
}这样这个数独的4个点就计算出来了,然后根据这4个点,进行透视变换,将四边形的图片缩放成正方形。
var mat = this.srcMat;
let dst = cv.Mat.zeros(mat.cols, mat.rows, cv.CV_8UC3);
let dsize = new cv.Size(mat.cols, mat.rows);
let srcTri = cv.matFromArray(4, 1, cv.CV_32FC2, [this.box.leftTopPoint.x, this.box.leftTopPoint.y, this.box.rightTopPoint.x, this.box.rightTopPoint.y, this.box.leftBottomPoint.x, this.box.leftBottomPoint.y, this.box.rightBottomPoint.x, this.box.rightBottomPoint.y]);
let dstTri = cv.matFromArray(4, 1, cv.CV_32FC2, [0, 0, this.canvas1Width, 0, 0, this.canvas1Height, this.canvas1Width, this.canvas1Height]);
let M1 = cv.getPerspectiveTransform(srcTri, dstTri);
cv.warpPerspective(this.blackMat, dst, M1, dsize, cv.INTER_LINEAR, cv.BORDER_CONSTANT, new cv.Scalar());
let resizeDSize = new cv.Size(360, 360);
cv.resize(dst, dst, resizeDSize, 0, 0, cv.INTER_AREA);
这样,就得到了最终的图片
接下来就相对简单了,我没再做更多的处理,直接将这个图片9×9裁剪,得到每一个小格子的内容,然后对小格子里的内容进行边缘检测,得到每个小格子里的图形的外接矩形边框(包围盒),将过小区域的格子内容删除,认为该格子里没有数字。有数字的格子,将包围盒中的图片裁剪出来,形成base64字符串,以便发送到服务器进行下一步图像数字识别。
var boundingRect = await cvhelper.getBoundingRect(ctxGrid);
// 如果面积过小,排除
if (boundingRect.width * boundingRect.height < 10) {
console.debug('too small');
base64Datas.push("");
continue;
}
// 计算rect中心,是否在至少当前区域中心
boundingRectCenterX = boundingRect.x + boundingRect.width / 2;
boundingRectCenterY = boundingRect.y + boundingRect.height / 2;
ctxCenterX = 20;
ctxCenterY = 20;
if ((boundingRectCenterX - ctxCenterX) * (boundingRectCenterX - ctxCenterX) > 100 ||
(boundingRectCenterY - ctxCenterY) * (boundingRectCenterY - ctxCenterY) > 100) {
console.debug('too small -2');
base64Datas.push("");
continue;
}
var canvas2 = await wx2sync.createSelectorQuery("canvas2");
canvas2.width = boundingRect.width;
canvas2.height = boundingRect.height;
var canvas2Ctx = canvas2.getContext("2d");
var imageData = ctxGrid.getImageData(boundingRect.x, boundingRect.y, boundingRect.width, boundingRect.height);
canvas2Ctx.putImageData(imageData, 0, 0);
var filename = await wx2sync.canvasToTempFilePath(canvas2);
var base64 = await wx2sync.readFile(filename, "base64");
base64Datas.push(base64.substring(0));最后,将81个格子发送给服务器,由服务器进行图像识别,识别后的81格的数字,在界面上显示出来
var result = await wx2sync.request(recognizeUrl, { base64Datas: base64Datas });
console.log(result);
// TODO: 获取到了数字,81个数字。在界面上给显示出来
let data = [];
result.forEach(item => {
data.push({
isGiven: item == 0 ? false : true,
data: item == 0 ? "" : item
});
});
_that.setData({ sudokuData: data });暂时跳过服务器端,最后一步就是“求解”,同样,将现有的9×9的数字发送给服务器,由服务器求解,然后将结果再显示在界面上。
async resolve() {
// 提交数字串,得到答案
wx.showLoading({ title: '求解中,请稍候...', mask: true });
let data1 = this.data.sudokuData;
let data2 = [];
data1.forEach((item) => {
data2.push(item.isGiven ? item.data : 0);
});
var result = await wx2sync.request(resolveUrl, { numbers: data2 });
if (!result.hasResult) {
wx.showToast({ title: '无解!' });
return;
}
var data = this.data.sudokuData;
for (var i = 0; i < 81; i++) {
data[i].data = result.numbers[i];
}
this.setData({ sudokuData: data });
wx.hideLoading();
},至此,微信小程序端,完事。
下面是.NET端的识别和数独解法。
先说图片识别,.NET引入了Tesseract 4。训练数据是网上找的一个全数字的训练库,直接导入到我们的traindata里。然后Controller接收一个全是base64图片的数组。针对每一个base64的内容进行图像识别。然后再按照81个数组返回给小程序端。
protected List<int> ScanSudoku(List<string> ss)
{
var numbers = new List<int>();
using (var engine = new TesseractEngine(System.AppDomain.CurrentDomain.BaseDirectory + "tessdata", "digits", EngineMode.Default))
{
engine.DefaultPageSegMode = PageSegMode.SingleChar;
for (var i = 0; i < 81; i++)
{
// 接受图片
if (string.IsNullOrEmpty(ss[i]))
{
numbers.Add(0);
continue;
}
var bytes = Convert.FromBase64String(ss[i]);
Bitmap srcBitmap = null;
using (MemoryStream ms = new MemoryStream(bytes))
{
srcBitmap = new Bitmap(ms);
ms.Close();
}
var filename = System.AppDomain.CurrentDomain.BaseDirectory + "tmp\\" + i + ".png";
srcBitmap.Save(filename, System.Drawing.Imaging.ImageFormat.Png);
using (var img = Pix.LoadFromFile(filename))
{
using (var page = engine.Process(img))
{
var n = page.GetText();
int result = 0;
if (isNumberic(n, out result))
{
numbers.Add(result);
}
else
{
numbers.Add(0);
}
}
}
}
}
return numbers;
}小程序传过来的图片被处理过,都是纯粹数字的包围盒,长这样
最后一步就简单拉,数独解法 :) 完整版有一点长,我贴在这里,感兴趣的可以到我的github上看一眼。
using System.Collections.Generic;
using System.Linq;
public static class SolveSudokuService
{
public static int[] SolveSudoku(int[] board)
{
// 先转成int的一维数组
var boardint = new int[81];
// 先做一个大表格
var all = new Dictionary<int, List<int>>();
for (var i = 0; i < 81; i++)
{
if (board[i] == 0)
{
all.Add(i, new List<int>() { 1, 2, 3, 4, 5, 6, 7, 8, 9 });
}
else
{
boardint[i] = board[i];
}
}
var isSolved = Solve(boardint, all);
if (!isSolved)
{
throw new System.Exception("Not result");
}
return boardint;
}
private static bool Solve(int[] board, Dictionary<int, List<int>> unsolved)
{
if (unsolved.Count == 0)
{
// 解出来了
return true;
}
var isValid = false;
while (Filter(board, unsolved, out isValid)) ;
if (!isValid)
{
return false;
}
if (unsolved.Count == 0)
{
return true;
}
//if (isValid && unsolved.Count > 0)
//{
// 解不出来了,需要假设一个继续递归
// 找一个最少的开始循环
var less = 9;
var lessIndex = 0;
for (var i = 0; i < 81; i++)
{
if (unsolved.Keys.Contains(i))
{
var cnt = unsolved[i].Count;
if (cnt < less)
{
less = unsolved[i].Count;
lessIndex = i;
}
}
}
// 开始递归
foreach (var i in unsolved[lessIndex])
{
// 复制现场环境
var newBoard = new int[81];
for (var j = 0; j < 81; j++)
{
newBoard[j] = board[j];
}
newBoard[lessIndex] = i;
var newUnsolved = new Dictionary<int, List<int>>();
foreach (var j in unsolved.Keys)
{
if (j == lessIndex)
{
continue;
}
var list = new List<int>();
newUnsolved.Add(j, list);
foreach (var e in unsolved[j])
{
list.Add(e);
}
}
// -- 现场环境复制完成
if (Solve(newBoard, newUnsolved))
{
for (var j = 0; j < 81; j++)
{
board[j] = newBoard[j];
}
return true;
}
}
//}
return false;
}
private static bool Filter(int[] board, Dictionary<int, List<int>> unsolved, out bool isValid)
{
var isChanged = false;
isValid = true;
// 然后针对每个格子,计算行、列、小方格的数字,进行排除
for (var i = 0; i < 81; i++)
{
if (!unsolved.Keys.Contains(i))
{
continue;
}
var m = i / 9;
var n = i % 9;
var list = unsolved[i];
for (var j = 0; j < 9; j++)
{
if (j == n)
{
continue;
}
var xx = m * 9 + j;
if (list.Contains(board[xx]))
{
list.Remove(board[xx]);
isChanged = true;
}
}
for (var j = 0; j < 9; j++)
{
if (j == m)
{
continue;
}
var xx = j * 9 + n;
if (list.Contains(board[xx]))
{
list.Remove(board[xx]);
isChanged = true;
}
}
for (var x = m - m % 3; x < m - m % 3 + 3; x++)
{
for (var y = n - n % 3; y < n - n % 3 + 3; y++)
{
if (x == m && y == n)
{
continue;
}
var xx = x * 9 + y;
if (list.Contains(board[xx]))
{
list.Remove(board[xx]);
isChanged = true;
}
}
}
if (isChanged && list.Count == 1)
{
board[i] = list[0];
unsolved.Remove(i);
}
if (unsolved.Count == 0)
{
// 无解,返回
isValid = false;
}
}
return isChanged;
}
}完整的源代码在这里,大家可以光临参考,也欢迎大家留言。
文章出处登录后可见!