一、相关背景
pytorch 从 1.3 开始增加了量化相关的接口,目前pytorch 最新版本已经到了1.11了,猜测其量化相关工具已经完善了(易用、模型速度提升,模型质量几乎不下降),所以开始记录量化相关知识。
注意
- 本文开始写于 20220521,pytorch 版本 1.11。如果时间相差太多或者版本相差太多,后面的信息可能会不适用。
- 相应资料均来自与pytorch官网
二、Quantization
量化相关知识就不介绍了,网上一大堆,pytorch也是一大堆介绍。这里就简单给出个pytorch的简介
https://pytorch.org/blog/introduction-to-quantization-on-pytorch/
pytorch 提供了三种量化方式,后面就这三种量化方式进行说明.
下面是动态量化和静态量化的支持的算子
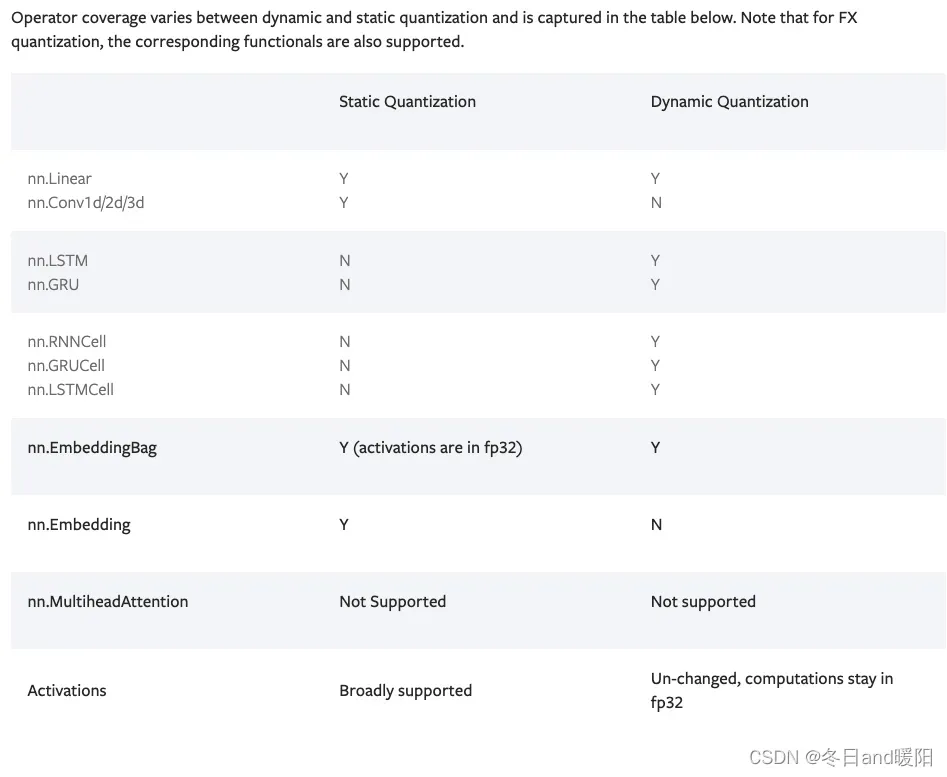
2.1 Dynamic Quantization
特点
- 会把模型的
weights量化, 读activation的时候是float,但是计算的时候会把activation转化为int8,再进行int8的矩阵计算,再转化为float写入memory - 量化策略:https://pytorch.org/docs/stable/quantization-support.html
优点
- 最简单的量化方法,无需校准数据(PQT/static quantization),更无须校准训练(QAT)。只需要简单的几行代码
import torch.quantization quantized_model = torch.quantization.quantize_dynamic(待量化的模型, {需要量化的算子集合}, dtype=torch.qint8)
缺点
- 目前仅支持几种算子, Linear, LSTM, LSTMCell, GRUCell, and RNNCell。居然连
nn.Conv2d都不支持(https://pytorch.org/tutorials/recipes/quantization.html),结果就是如果你自己试图量化官方的mobilenet,会发现模型的体积没有下降多少

- inference的时候有个int8和float转化的过程,所以推理性能可能不会大幅增加。
实验
原始mobilenet v2的大小为 14.25 MB , dynamic quantization之后的大小为10.41 MB
def print_size_of_model(model):
torch.save(model.state_dict(), "temp.p")
print('Size (MB):', os.path.getsize("temp.p")/1e6)
os.remove('temp.p')
mobilenetv2 = models.mobilenet_v2(pretrained=True)
quantized_model = torch.quantization.quantize_dynamic(mobilenetv2, {nn.Linear}, dtype=torch.qint8)
print_size_of_model(mobilenetv2) # Size (MB): 14.258573
print_size_of_model(quantized_model) # Size (MB): 10.419337
2.2 Static Quantization
关于static quantization两篇重要的参考
- A complete model definition and static quantization example :https://pytorch.org/docs/stable/quantization.html#quantization-api-summary
- A dedicated static quantization tutorial :https://pytorch.org/tutorials/advanced/static_quantization_tutorial.html
文章出处登录后可见!
已经登录?立即刷新