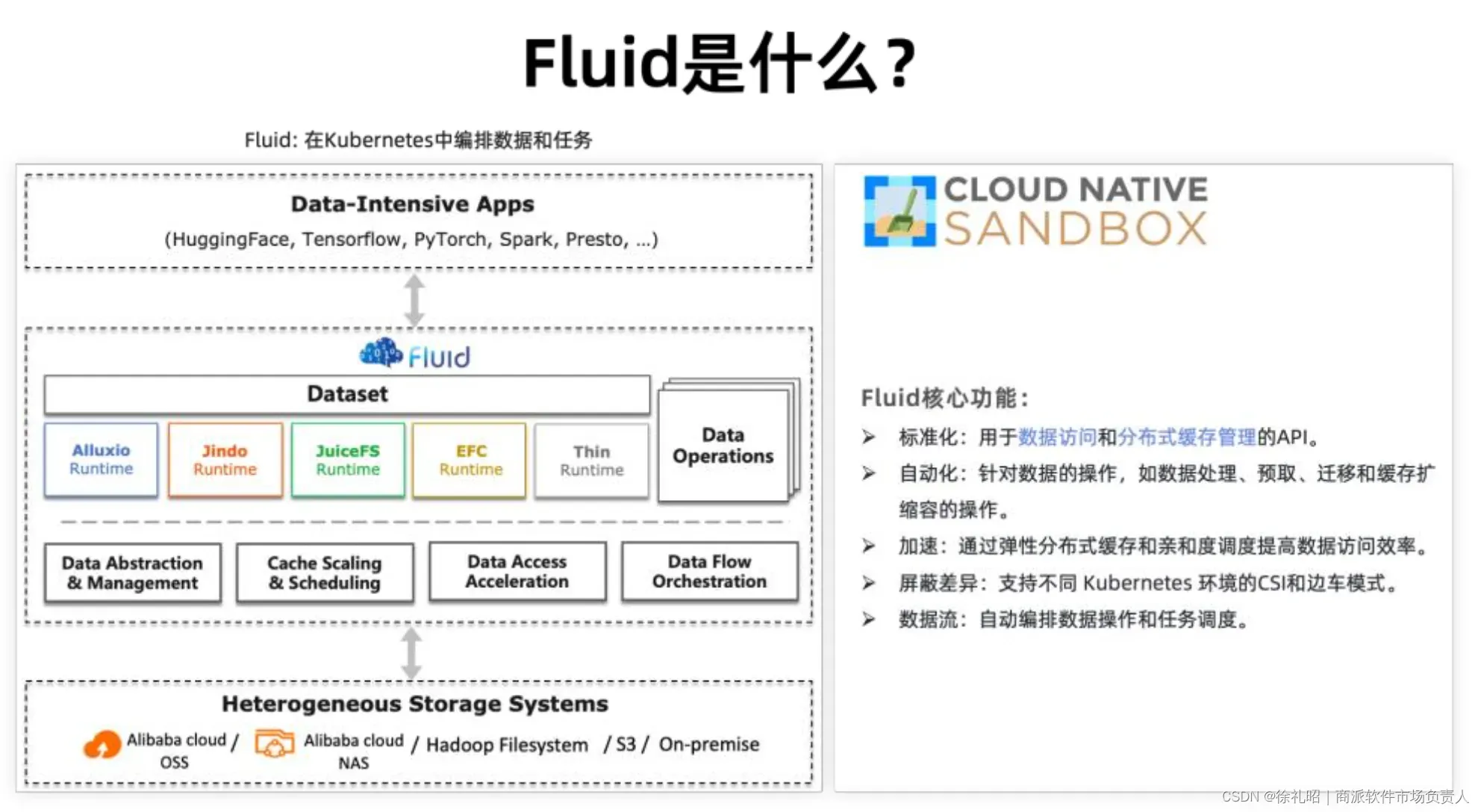
Fluid的介绍
Fluid是一个在Kubernetes环境中编排数据和使用数据的计算任务的工具。它的编排不仅涉及空间上的优化,还包括时间上的调度。从空间角度看,计算任务会优先被分配到存有缓存数据或靠近缓存的节点上,从而提升数据密集型应用的性能。从时间角度来说,Fluid允许同时提交数据操作和任务,但在任务执行前,会进行数据迁移和预热,确保任务在无人值守的情况下也能顺利运行,进而提高工程效率。
从 Fluid 的架构图来看,Fluid 向上对接各种 AI/大数据的应用,对下我们可以对接各种 异构的存储系统。Fluid 目前支持了包括 Alluxio、JuiceFS 还有阿里内部自研的 JindoFS、 EFC 等多种缓存系统。
Fluid的核心能力
- 数据使用与缓存编排的标准化:Fluid针对特定的应用场景(如大语言模型、自动驾驶仿真数据、图像识别小文件等)进行数据访问模式的标准化,并抽象出优化的数据访问方式。此外,随着分布式缓存系统(如JuiceFS、Alluxio、JindoFS、EFC)的增多,Fluid负责将这些系统转化为具有可管理性、弹性、可观测性和自我修复能力的缓存服务,并公开Kubernetes API。
- 自动化能力:通过Custom Resource Definitions (CRDs),Fluid提供数据操作、数据预热、数据迁移、缓存扩容等多种操作的自动化,便于用户整合到自动化运维体系中。
- 加速能力:利用场景优化的分布式缓存和任务缓存亲和性调度来提高数据处理速度。
- 跨平台运行能力:Fluid与Kubernetes运行时平台无关,意味着它可以在原生Kubernetes、边缘计算环境、Serverless Kubernetes以及Kubernetes多集群等环境中运行。根据环境的差异,它可以选择CSI Plugin或sidecar模式来运行存储客户端。
- 数据与任务编排:Fluid支持以数据集为中心定义自动化操作流程,能够设定数据迁移、预热和任务的执行顺序和依赖关系。
总体而言,Fluid为Kubernetes中的数据管理和计算任务提供了一个全面且高效的解决方案,特别是在处理大规模数据集和复杂工作流程时。
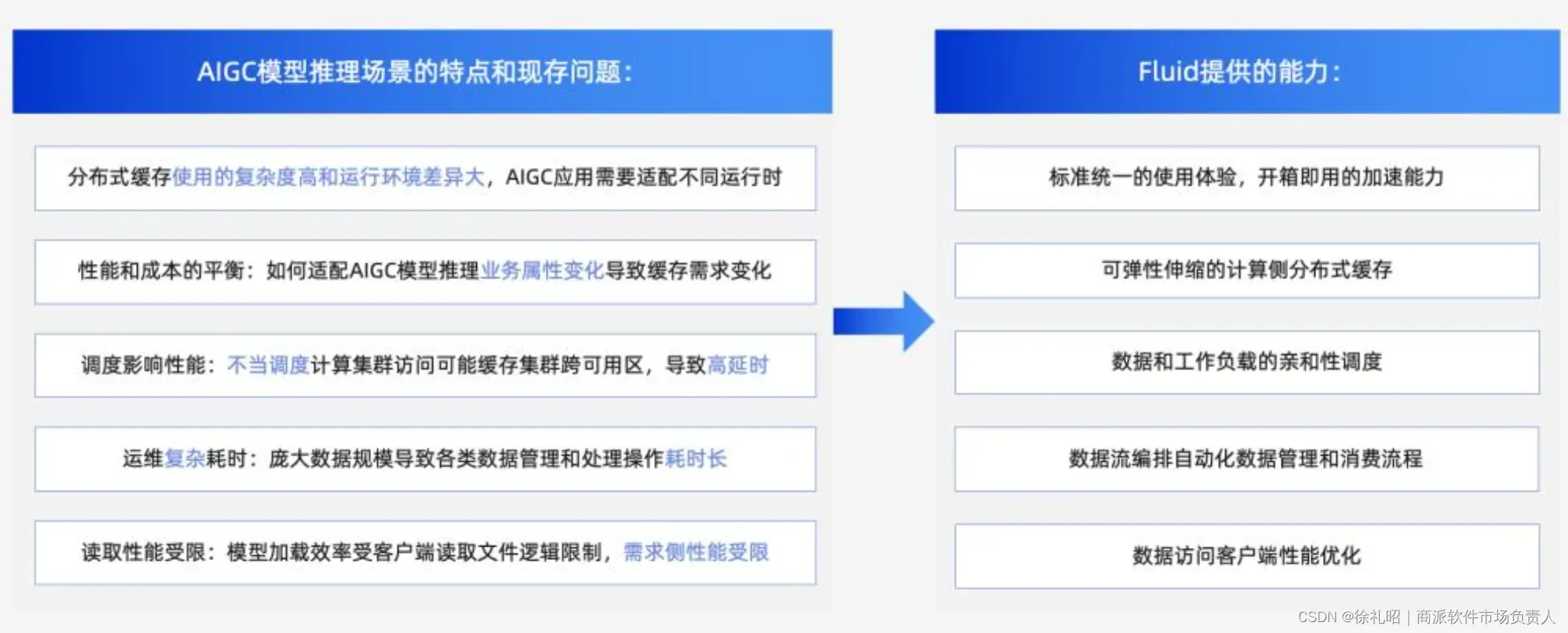
Fluid在AIGC模型推理场景中的优化方案
在AIGC模型推理场景中,Fluid带来了诸多优化策略,为复杂的数据处理和计算任务提供了高效的解决方案。
- 一键部署与无缝衔接:AIGC应用需要在不同的运行时环境中适配,如公共云、私有云、边缘云和Serverless云,同时还要兼容多种分布式缓存系统,例如Alluxio、JuiceFS和JindoFS。Fluid具备一键部署和无缝衔接的能力,大大简化了这一过程中的复杂性和差异性。
- 弹性缓存管理:AIGC模型推理服务具有多变的业务属性。借助Fluid提供的弹性缓存机制,用户可以在需要时扩展缓存容量,而在不需要时则可以缩减,从而在性能和成本之间达到最佳平衡。
- 数据感知调度:为了提升计算效率,Fluid引入了数据感知调度能力。这种能力确保计算任务被优先分配到离数据更近的节点上,从而减少了数据传输的延迟和开销。
- 数据流编排自动化:通过Fluid的数据流编排功能,用户可以轻松地将推理行为和数据消费行为自动化,显著降低了整个流程的复杂性。
- 云原生缓存读取优化:在性能优化方面,Fluid提供了针对云原生环境的缓存读取优化方案。这一方案充分利用了节点资源,进一步提升了数据读取和处理的效率。
总的来说,这些优化方案使得Fluid成为AIGC模型推理场景中的理想选择,它不仅可以简化数据管理和计算任务的复杂性,还能显著提高整体性能和效率。
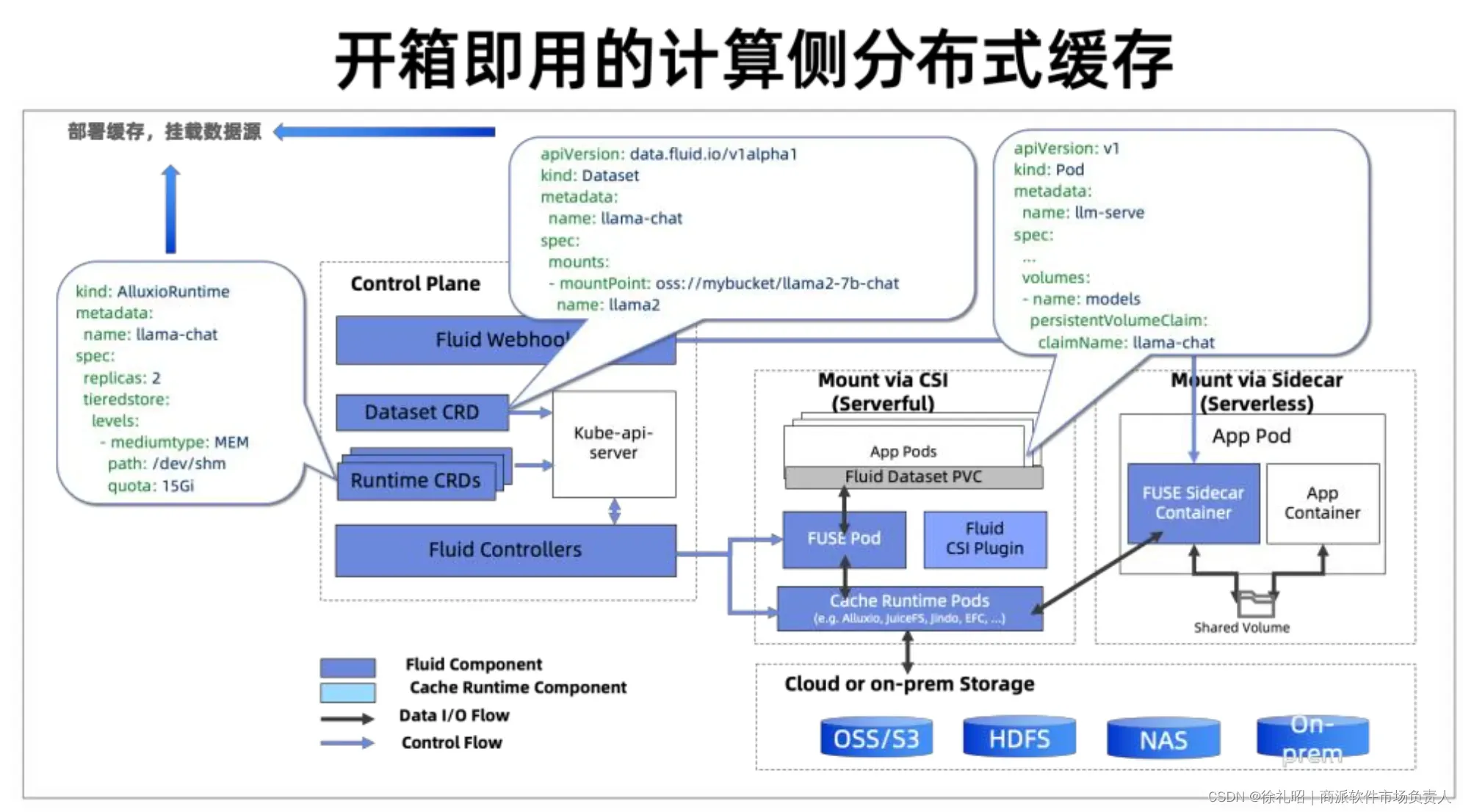
Fluid技术架构图解析
从Fluid的技术架构图中,我们可以清晰地看到其关键组成部分。Fluid主要提供两种Custom Resource Definitions(CRDs):Dataset和Runtime。这两者分别代表需要访问的数据源和与之对应的缓存系统。
以示例中的Alluxio缓存系统为例,与之对应的是AlluxioRuntime的CRD。在Dataset中,用户需要描述模型所需访问的数据路径,这可能是一个OSS存储桶中的特定子目录。一旦创建了Dataset和与之对应的Runtime,Fluid会自动进行缓存的配置、初始化缓存组件,并自动为用户创建一个Persistent Volume Claim(PVC)。
对于希望访问此模型数据的推理应用,只需简单地挂载这个PVC,即可直接从缓存中读取模型数据。这种操作方式与Kubernetes(K8s)的标准存储方式保持高度一致,从而确保了用户体验的连续性和简便性。通过这种方式,Fluid极大地简化了在Kubernetes环境中管理和访问缓存数据的复杂性。
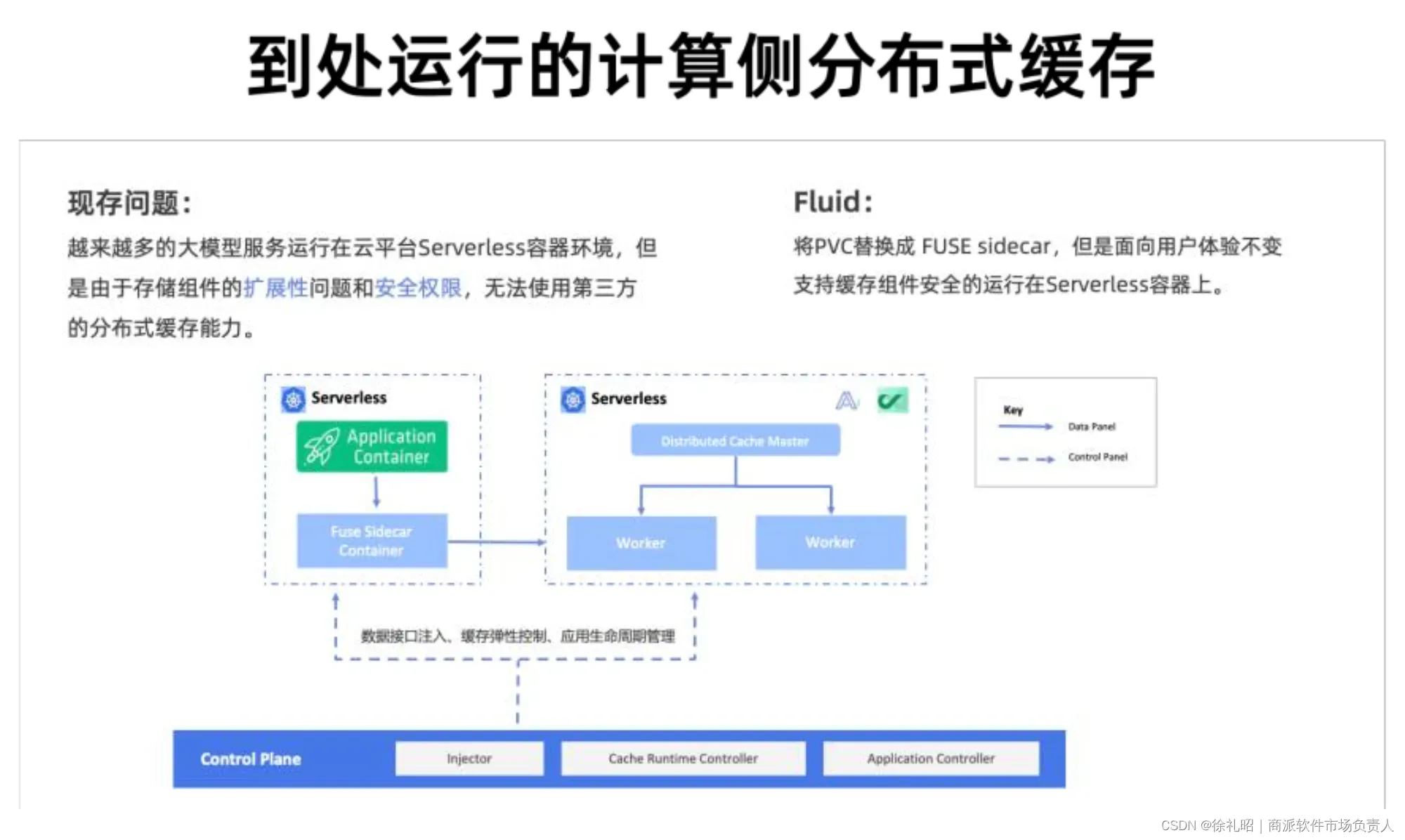
Fluid在多样化的AIGC推理运行平台上的适应性
AIGC推理的运行平台具有多样性,涵盖了云服务的Kubernetes、自建的Kubernetes、边缘Kubernetes以及Serverless形态的Kubernetes。其中,Serverless Kubernetes因其易用性和低维护负担而受到越来越多用户的青睐。然而,出于安全考虑,Serverless平台通常不开放第三方存储接口,仅支持其自身的存储解决方案。以阿里云为例,它仅提供NAS、OSS、CPFS等有限的存储选项。
在这个背景下,Fluid展现出了其独特的价值。在Serverless容器平台上,Fluid能够将PVC自动转换为适应底层平台的sidecar容器。更重要的是,Fluid开放了第三方配置接口,允许用户控制这个sidecar容器的生命周期。这确保了sidecar容器在应用容器启动之前就已经运行,并在应用容器结束后自动退出。通过这样的设计,Fluid提供了强大的可扩展性,能够支持多种分布式缓存引擎的运行。
这意味着,无论用户选择哪种运行平台,Fluid都能提供一致的、高效的缓存管理体验。尤其是在Serverless环境下,Fluid有效地解决了存储限制的问题,使得用户可以充分利用各种分布式缓存技术的优势,提升AIGC推理的性能和效率。
参考资料来源:2023 云栖大会容器服务 ACK 分享实录合辑
文章出处登录后可见!