遮挡违禁物品检测:X 射线安全检查基准和去遮挡注意模块
摘要
近年来,目标检测利用深度卷积网络的进步带来了重大进展。尽管在行人检测、自动驾驶等多种情况下都取得了可喜的成果,但在机场等交通站点进行安检的 X 射线图像中违禁物品的检测却很少受到关注。同时,安检时常针对一件行李或手提箱,物品随意堆放、重重叠叠,因尺寸、视角、风格各异,导致X光图像中违禁物品的检测效果不尽如人意。这些图像。在这项工作中,首先,我们提出了一种名为 De-occlusion attention module (DOAM) 的注意机制,以处理检测 X 射线图像中某些部分被遮挡的违禁物品的问题。 DOAM 混合了两个注意子模块,边缘注意模块(EAM)和区域注意模块(RAM),分别关注不同的信息。对于我们想要检测的违禁物品,EAM强调整体的边缘信息,包括物品的被遮挡部分和可见部分,而RAM强调区域信息,如可见部分每个点的纹理。其次,我们针对该问题提出了一个定向良好的数据集,其中数据集中的图像由北京首都国际机场的专业检查员手动注释。我们的数据集名为 Occcluded Prohibited Items X-ray (OPIXray),专注于检测 X 射线图像中被遮挡的违禁物品,包含 5 类刀具的 8885 张 X 射线图像(图 1),考虑到事实刀具是最常见的违禁物品。我们在 OPIXray 数据集上评估我们的方法,并将其与几个基线进行比较,包括用于检测和注意机制的流行方法。与这些基线相比,我们的方法具有更好的检测我们想要的对象的能力。我们还通过根据不同的遮挡级别将测试集划分为三个子集来验证我们的方法处理遮挡的能力,结果表明我们的方法在遮挡级别更高的情况下取得了更好的性能。数据和代码链接是 https://github.com/OPIXray-author/OPIXray。
引言
随着公共交通枢纽人群密度的增加,安全检查在保护公共空间免受恐怖主义等安全威胁方面变得越来越重要。安检通常采用X光扫描仪检查行李中是否有违禁物品,如包或手提箱。然而,在这种情况下,对象是随机堆叠的,并且相互重叠,导致对象遮挡挑战。因此,在长时间不分心地在大量复杂的 X 射线图像中定位违禁物品后,安检人员难以准确检测所有违禁物品,这可能对公众造成严重危险。而且频繁换班会耗费大量人力资源,不可取。
因此,迫切需要一种快速、准确和自动的方法来帮助检查员检测 X 射线扫描图像中的违禁物品。随着深度学习 [14] 尤其是卷积神经网络 [3, 35] 技术的发展,从 X 射线图像中识别被遮挡的违禁物品可以看作是计算机视觉的目标检测问题,这是文献中广泛研究的问题。
有几项工作试图解决不同场景中的遮挡问题,例如行人重识别[37、42、43]、人脸识别[6、28、38]。 Person Reidentification或Face Recognition中的物体遮挡属于类内遮挡,每个被遮挡的物体都有对应的标注。因此,可以通过标注信息设计一个损失函数来降低遮挡的影响。然而,安检X射线图像中的物体遮挡往往存在于违禁物品和安全物品之间,属于类间遮挡。在这项工作中,我们获得的是违禁物品的注释,所以这些意义上的方法不能用于比较。
最近,也有两个发布的X射线benchmark,即GDXray[17]和SIXray[18]。然而,GDXray[17]包含的图像是灰度的,而另一个数据集SIXray[18]只包含不到1%的有注释的违禁物品的图像。而GDXray[17]和SIXray[18]都是用于分类任务。因此,这两个数据集都与我们检测被遮挡的违禁物品的任务不一致。
为了解决上述问题,我们建立了一个名为 Occluded Prohibited Items X-ray (OPIXray) 的数据集,并提出了一个去遮挡注意模块来处理检测 X 射线图像中被遮挡的违禁物品的任务。 OPIXray 包含 8885 张标记的 X 射线图像,每张图像都有一个或多个我们希望检测的违禁物品。考虑到刀具是旅客最常携带的工具,我们选择了五类刀具作为违禁物品进行检测。我们的数据集在两个方面更具挑战性:首先,数据集中的项目被划分为五个类别,我们在其中找到属于不同类别的具有相似形状的项目,例如折叠刀和多功能刀,给机器区分物品带来了很大的困难。其次,我们想要检测的物品由于大小、视角等的不同,经常会成功地从视线中逃脱,因为它可能会被各种物品遮挡或重叠。它模仿了与真实世界场景类似的测试环境,其中总是存在复杂的视点或项目部件的随机遮挡。
X射线图像中被遮挡的部分仍然提供边缘信息,不同于自然图像中被遮挡部分的全部信息完全丢失,这启发了我们设计边缘注意模块。具体地,在X射线图像中查看刀具时,被遮挡部分的边缘信息与刀具可见部分的边缘信息对齐。因此,设计良好的模型可以更加关注边缘信息以提高检测性能。同时,人工检测人员主要通过未遮挡部分的纹理、颜色等来识别刀具,我们称之为区域信息。
基于以上考虑,在这项工作中,我们开发了一种混合注意力机制,称为去遮挡注意力模块(DOAM),由两个主要的注意力子模块,边缘注意力模块(EAM)和区域注意力模块(RAM)组成,以生成一个注意力分布图作为每个实例的高质量掩码。在EAM中,我们在建模过程中强调边缘特征的影响,通过使用sobel算子从输入的X射线图像中提取边缘图像,并使用边缘图像生成关注边缘信息的特征图 。
保留了输入图像中违禁物品的完整边缘信息,就像安检人员看到了物体的轮廓一样。在 RAM 中,引导模型学习感兴趣对象可见部分的区域信息,就像安全检查员看到对象的纹理、颜色等可识别属性一样。我们尝试通过利用平均池化聚合区域信息来构建可见部分的每个位置与其邻居之间的关系。这导致输入图像的每个位置都感知到与其相邻的区域。同时,我们在 RAM 中利用门控卷积网络,为点选择合适的区域大小以感知并生成关注区域信息的特征图
。
这项工作的主要贡献有以下两个方面:
- 我们为这项具有挑战性的任务的未来研究提供了一个benchmark ,即检测 X 射线图像中被遮挡的违禁物品以进行安全检查。
- 我们提出了一个名为DOAM 的混合注意力模块,它有效地整合了我们上面定义的边缘和区域信息,实现了优于流行检测方法和注意力机制的令人满意的性能。
相关工作
2.1 X 射线图像和Benchmarks
X射线图像的成像原理是用X射线照射物体,并根据其光谱吸收率将其渲染为伪彩色。因此,X 射线图像中由不同材料制成的物体被分配了完全不同的颜色,例如,金属通常显示为蓝色,而难以穿透的物体通常显示为红色。 X 射线在医学影像分析 [1, 9, 16] 和安全检查 [11, 18] 等许多任务中提供了强大的能力。此外,物体重叠导致X射线图像与自然图像有很大差异,因为X射线通常应用于某些物体可能被其他物体严重遮挡的场景,例如,个人物品经常随机堆叠在一件行李中。
文献中的几项研究试图解决这一具有挑战性的问题,并设计了很多工作。不幸的是,由于安全检查的特殊性,很少有 X 射线数据集被发表用于研究,而这些技术受到物体重叠造成的遮挡的严重影响。最近发布的基准 GDXray[17] 包含 19407 张图像,属于枪支、手里剑和剃须刀片三类违禁物品。但是,GDXray 仅包含背景非常简单的灰度图像,以及杂乱和重叠。因此,很容易识别或检测图像中的项目。 SIXray[18] 是一个大规模的 X 射线数据集,大约是 GDXray 数据集[17] 的 100 倍。 SIXray 由 1059231 张 X 射线图像组成,但阳性样本不到 1%,以模拟与现实世界场景类似的测试环境,在这种场景中,检查员通常旨在识别以非常低的频率出现的违禁物品。与我们不同的是,SIXray 是一个用于分类任务的数据集,专注于数据不平衡的问题。
2.2 注意力机制
注意力可以解释为一种将可用计算资源的分配偏向于信号中信息量最大的组件的一种方式,这已在许多任务中得到广泛研究,例如图像检索 [30, 40],视觉问答 [20, 41] .它捕获远程上下文信息,并已广泛应用于各种任务,例如机器翻译 [34]、图像字幕 [2]、场景分割 [5] 和对象识别 [32]。工作[36]与self-attention模块有关,主要探索非局部操作在时空维度上对视频和图像的有效性。Jun Fu 等人[5]提出了一种用于场景分割的双重注意网络(DANet),通过基于自注意机制捕获上下文相关性,分别对空间和通道维度的语义相互依赖关系进行建模。 Squeeze-and-Excitation Networks (SENet) [10] 称为 Squeeze-and-Excitation 模块 (SE),它通过显式建模通道之间的相互依赖关系来自适应地重新校准通道方面的特征响应。
与之前的工作不同,我们在 X 射线图像中检测具有遮挡的违禁物品的任务中扩展了自注意力机制,并精心设计了两种类型的注意力模块来捕获丰富的上下文关系,以获得更好的特征表示。综合实证结果验证了我们提出的方法的有效性。
2.3 目标检测
目标检测是计算机视觉中的经典问题。随着深度学习的兴起,基于 CNN 的方法已成为主要的目标检测解决方案。大多数方法可以进一步分为两种通用方法:proposal-free检测器和proposal-based检测器。第一种方法遵循单阶段训练策略,不显式生成提议框,这是由 SSD [15] 和 YOLO [21-23] 开创的。另一方面,由 RCNN 系列 [7, 8, 24] 开创的第二种方法从给定图像中提取潜在对象的类别不可知区域建议。然后通过特定模块 [24, 26, 29, 31] 进一步细化这些框并将其分类为不同的类别。这种策略的一个优点是它可以通过 RPN 模块过滤掉许多负面位置,这有助于下一个检测器任务。最近,[4,12,13,33,39] 解决了传统方法严重依赖锚框的问题,仅有后处理的非最大值抑制[19]。在这项工作中,我们将我们的方法 DOAM 与从上述工作中选择的方法作为基线进行性能比较,以显示我们方法的有效性。
3 OPIXRAY数据集
3.1 数据采集
在本部分中,我们将介绍OPIXray数据集的构建。这些图像是由该软件生成的,该软件是为专业安检人员专门使用的培训。数据标注工作由我们从北京首都国际机场聘请的专业安检员完成。合成安检机扫描的每个原始X射线图像(其中包含指定的违禁品)。该合成仍然保留了为X射线图像中由不同材料制成的对象分配不同颜色的特性,并使用边界框来定位图像中的box-level注释。
3.2 数据集属性
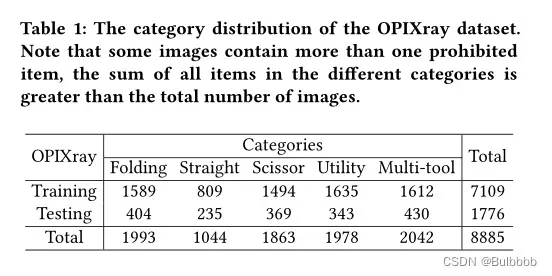
OPIXray 数据集共包含 8885 张 X 射线图像。为了评估不同模型检测不同类别违禁物品的能力,将数据集划分为训练集和测试集,前者包含 80% 的图像(7109),后者包含 20%(1776),其中比率约为 4 : 1。数据集进一步划分为五个常见的违禁物品类别,即折叠刀、直刀、剪刀、美工刀、多工具刀。类别分布和统计数据如表1所示。
3.3 数据集分析
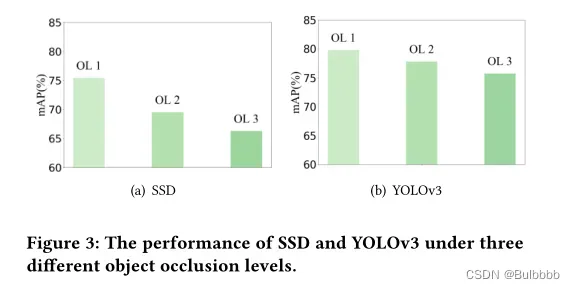
OPIXray数据集给视觉检测带来了几个具有挑战性和意义的工作。首先,该数据集主要模拟了与现实世界场景相似的环境,即个人行李中的物品通常是随机堆放的,正如安检站的X光图像所显示的那样。违禁物品可以出现在各种视点、尺度等,都导致视觉任务的困难。第二,当行李在X光扫描下通过时,X光具有穿透物体的能力,提供了有关违禁物品被遮挡部分的信息。这导致了最重要的属性,即X射线图像中的物体遮挡,我们试图在这项工作中详细讨论这个问题。如图3所示,两种著名的检测方法SSD[15]和YOLOv3[23]的性能在违禁物品的不同遮挡程度上有所下降。SSD和YOLOv3的性能分别只达到66.30%和75.72%(平均平均精度)。观察这些模型在OL3测试集的表现,其中包含有严重遮挡的项目,我们发现我们的数据集在有遮挡的物体检测中确实带来了挑战。第三,数据集可以通过比较不同遮挡级别设置下的方法比其他方法的改善量来评估一种旨在解决目标遮挡问题的方法的能力。随着遮挡程度的增加,方法的改善量也随之增加,说明了该方法对目标遮挡问题的有效性。
4 去遮挡注意模块
在本节中,我们首先介绍 DOAM 的总体框架,它由两个注意力子模块 EAM 和 RAM 组成,分别捕获边缘信息和区域信息。此外,描述了融合两个子模块的特征图的过程。最后,我们讨论了两个注意力子模块中网络块的参数。
4.1 DOAM 的总体框架
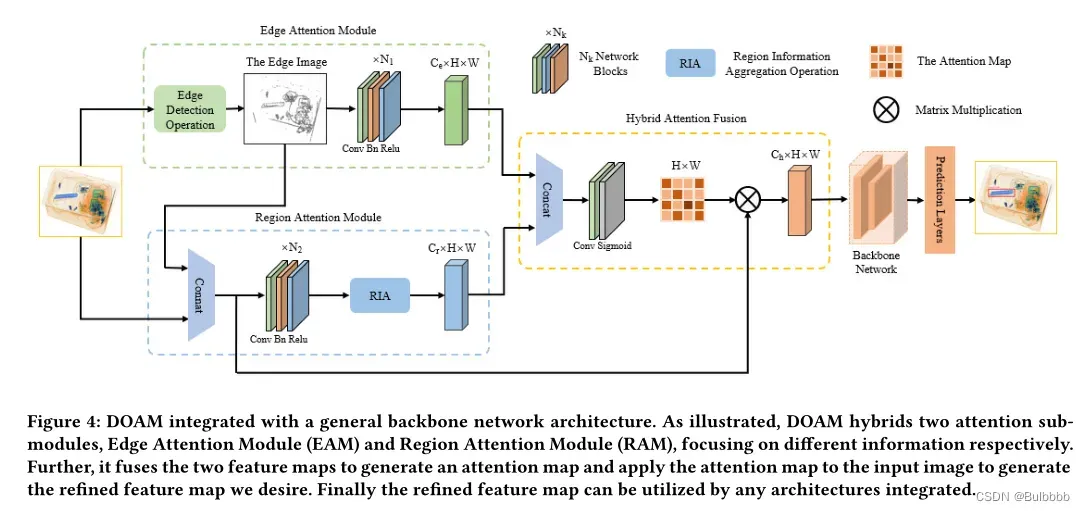
如图 4 所示,给定一张 X 射线图像,模拟真实世界场景,其中行李中的物体随机放置,包括我们希望检测的违禁物品。我们采用了一个以dilated策略为骨干的预训练网络。输入图像被送入两个并行的注意模块,以根据违禁物品的边缘和区域信息生成混合注意图。
我们提出了边缘注意模块(EAM),利用自注意机制在检测过程中注意模块的边缘信息。为了引导EAM关注感兴趣对象的边缘,而不是图像中的所有对象,我们对输入图像中边缘检测操作提取的边缘图像进行操作,并优化特定的损失函数以生成特征图强调违禁物品的边缘信息。
保留了输入图像中违禁物品的完整边缘信息,就像安检人员看到了物体的轮廓一样。
为了模仿安检员通过识别可见部分的纹理、颜色等属性来识别违禁物品,我们提出了区域注意模块(RAM)来增强学习可见部分区域信息的能力。区域信息的聚合使得特征图的每个点都能感知到其周围某个区域(区域大小可以自己定义)的信息,增强了该点与周围某个区域的关系。与EAM一样,生成了强调违禁物品区域信息的特征图,剩余的违禁物品可见部分的可识别属性信息。
我们将和
这两个特征图融合在一起,通过一系列操作生成注意力图,最后将注意力图应用到原始数据上,生成我们想要的特征图。注意机制的整个过程在算法1中有详细说明。
4.2 边缘注意模块(EAM)
接下来,我们详细阐述了 EAM 使用的过程,以自适应地关注违禁物品的整个边缘信息。假设数据集中有n张训练图像。对于每个输入图像
,我们利用卷积神经网络,其水平和垂直核表示为 Sobel 算子的
、
,分别计算水平和垂直方向的边缘图像
和
。我们通过综合以上两个结果
和
进一步生成输入图像
的边缘图片
。但是,此操作会检测图像中所有item的边缘,包括禁止item和安全item。因此,将 PE 和输入的RGB 图像
连接起来,作为一种特征融合操作,加强了图像中所有对象的边缘信息。为了引导 EAM 只放大感兴趣对象的边缘信息,我们使用
个网络块(这里,我们将
定义为 EAM 的注意力强度,表示注意力模块的性能随着
的值而变化,而
的合适值将在后面讨论),其中每个块由一个 3×3 大小的卷积层、一个batch normalization层和一个 relu 层组成,用于提取边缘图像 PE 的特征图
。操作可以表述如下:
其中 表示操作重复
次,
,
是卷积层的参数。提取特征图
后,如等式1所示。在上面的图 1 中,我们通过优化特定的损失函数来自适应地关注特征图
中违禁物品的边缘信息。
4.3 区域注意模块(RAM)
对于特征图的每个点,为了构建每个位置与其周围某个区域之间的关系,我们使用 个网络块(正如我们在 EAM 中所说,
是 RAM 的注意力强度,稍后将讨论
的值稍后),其中每个块包含一个卷积层,内核大小为 3 × 3,一个batch normalization层,一个 relu 层,用于从拼接的图像(将输入图像
与其对应的边缘图像
拼接)中提取特征图
,如下:
其中表示拼接操作。我们进一步通过区域信息聚合(RIA)操作提炼
来生成所得到的RAM的特征映射
。
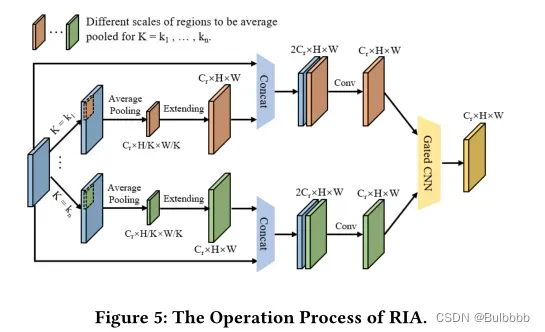
图5说明了RIA操作的结构。对于输入的特征图,RIA操作利用不同尺度的核函数和平均池化运算对其周围不同尺度的区域信息进行聚合。为了便于后续拼接,我们将平均池层后的特征图进一步扩展为原始特征图
的大小,生成相应的特征图集
。这些操作可以用以下公式表示:
其中代表特征图
的第
行和第
列的特征,当平均池化算子的核的尺度为
时。
我们进一步将两个特征图在通道的维度上串联起来,生成一个新的特征图,其维度为
。然后,新的特征图中的每一个点都有能力感知它周围大小为
的区域,这意味着我们已经成功构建了关系。
请注意,感知到的区域的大小对检测性能有很大的影响,其大小随着不同规模的违禁物品而变化。为了使操作在不同尺度的违禁物品上表现良好,有必要设计一种机制来自适应地选择
的最佳值。我们在
中利用具有
内核的门控卷积神经网络
,从特征图集
中选择合适的特征图
作为输出。这些操作表述如下:
其中表示串联操作。
4.4 混合注意力融合
如算法 1 所示,对于 EAM 和 RAM 分别输出的结果特征图 和
,其中
,
,我们将它们连接起来进行信息融合。进一步我们将连接的特征输入卷积层,其中内核大小为 1×1,以生成特征图
,它混淆了边缘信息和区域信息,两者都加强了。该操作可表述如下:
其中 代表concatenating的操作,
,
是卷积层的参数。然后我们利用特征图
作为
函数的输入来生成注意力图
,如下所示:
其中 。最后,我们计算注意力图
和拼接图像(拼接输入图像
和边缘图像 PE)的内积如下:
其中 ,这是我们想要的特征图,其中放大了对违禁物品检测有很大贡献的特征。
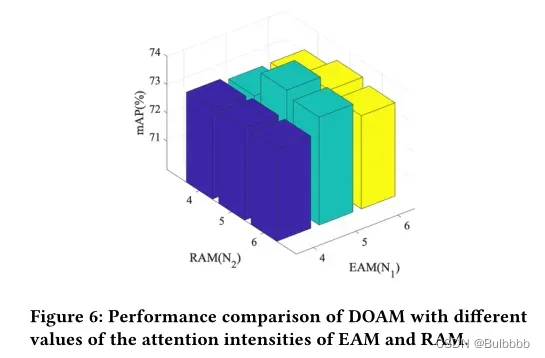
4.5 注意力强度的讨论
在本节中,我们分析了上述部分定义的两个注意力强度, 的
和
的
。注意强度的值表示卷积层的数量。选择合适的
和
值不仅可以提高性能,还可以有效降低
的复杂度,提高执行效率。因此,我们设计了实验来研究不同
和
值对性能的影响,性能如图 6 所示。
5 实验
在本节中,我们进行了广泛的实验来评估我们提出的 DOAM。为了更好地进行apple-to-apple的比较,我们在 PyTorch 框架中复制了所有评估的网络,并在整个实验中报告了我们的复制结果。
我们首先验证 DOAM 在不同类别和不同遮挡级别上优于上述所有注意机制。为了彻底评估 DOAM 的有效性,我们进一步进行了消融实验。最后,我们展示了 DOAM 在不同架构中的普遍适用性以及 DOAM 集成后的有效性。可以将 DOAM 无缝集成到任何 CNN 架构中,并联合训练组合的 DOAM 集成网络。图 4 以 DOAM 与基础架构 SSD 的集成图为例。
在接下来的所有实验中,所有模型都由 SGD 优化器优化,学习率设置为 0.0001。批量设置为 24,动量和权重衰减分别设置为 0.9 和 0.0005。我们评估目标检测的平均平均精度(mAP)来衡量模型的性能,IOU 阈值设置为 0.5。我们进一步选择最佳性能模型来计算每个类别的 AP,以观察不同类别的性能提升。此外,为了避免图像数据修改对边缘图像生成的影响,我们不使用任何数据增强方法来扩展数据或修改原始图像的像素值,这有助于我们更好地分析边缘信息的影响.
5.1 与不同注意力机制的比较
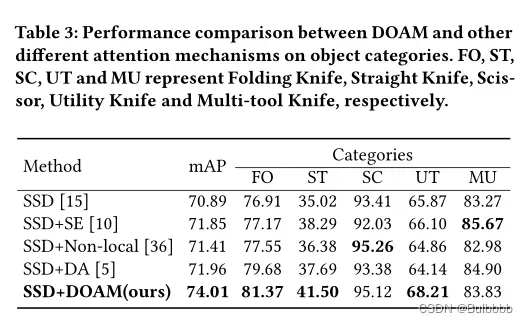
我们通过实验验证了 DOAM 在 OPIXray 数据集的不同类别和不同遮挡级别上的有效性。我们比较了注意力机制的三种变体,包括 SENet [10]、Non-local Net [36] 和 DANet [5],其中注意力模块分别称为 SE、Non-local 和 DA。三种注意力机制分别侧重于通道注意力、空间注意力以及将通道注意力和空间注意力结合起来。本小节中的所有实验都是在 SSD [15] 的基础架构上设计的。标签。图 3 和图 4 分别展示了各种模块集成网络在不同类别和不同遮挡级别上的实验结果。从两张表中我们可以看出,DOAM 明显超越了这些当前流行的注意力网络。
对象类别的实验。我们通过实验验证 DOAM 在不同对象类别上的有效性,所有模块集成网络的训练和测试数据如表1所示。正如我们可以从 Tab 中观察到的那样。如图 3 所示,与 SENet [10]、Non-local Net [36] 和 DANet [5] 相比,DOAM 的性能分别提高了 2.16%、2.60%、2.05%。注意机制 DOAM 优于针对不同对象类别的一般注意机制。
DOAM 带来的性能提升取决于遮挡的级别。表3 显示 DOAM 的改进主要体现在直刀、折叠刀和美工刀上,这些都是我们预期的高级别遮挡。尤其是直刀,这是具有最高级别遮挡的刀具类别,其性能与基线相比提高了 6.48%,与 SENet [10] 相比提高了 3.21%,在三种注意力机制中的直刀。对于最轻的遮挡类别剪刀,与基线相比,性能仅提高了 1.71%,与Non-local Net [36] 相似,与其他四种类型的刀相比,在剪刀上实现了最佳性能。 DOAM通过加强违禁物品的整体边缘信息和视觉部分区域信息,极大地缓解了X射线图像中因遮挡导致的特征信息丢失问题。
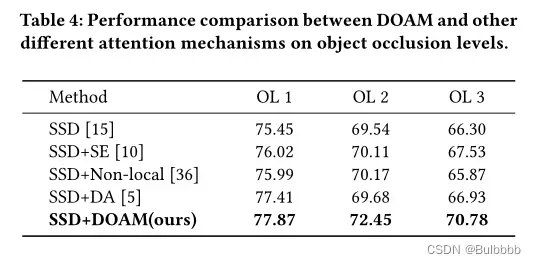
对象遮挡级别的实验。我们通过实验验证了 DOAM 在不同遮挡级别上的有效性。我们根据遮挡级别将测试集划分为三个子集,如表 2所示。所有模块集成的网络都通过 Tab 1中的训练集数据进行训练。其中每个类别的数据分布是均匀的,包含所有三个遮挡级别。每个训练好的模型分别在 OL1、OL2 和 OL3 上进行测试。实验结果如表4所示。我们不仅观察了对基线 SSD [15] 的改进,而且观察了在相应遮挡级别中具有最佳性能的一般注意机制。我们希望看到 DOAM 在所有遮挡级别上都超过了这些当前流行的注意力网络,并且随着遮挡级别的增加而改进,验证了我们的模型解决对象遮挡的有效性。
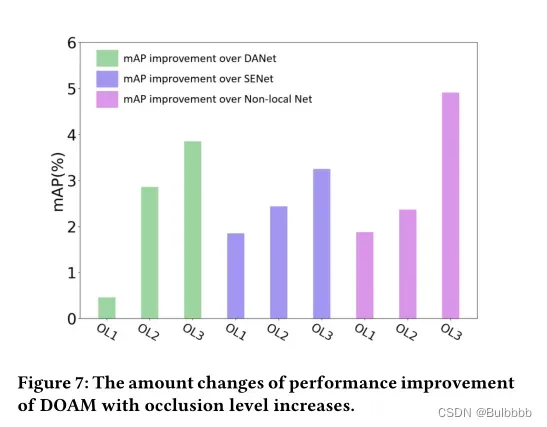
在图 7 中,我们可以清楚地得出一个结论,即 DOAM 可以实现比基线和其他注意机制更高的性能,而 X 射线图像遭受更高级别的遮挡。它验证了 DOAM 的有效性,它对检测 X 射线图像中被遮挡的违禁物品的性能有显着影响。
5.2 消融实验
在本小节中,我们凭经验展示了我们的设计选择的有效性。对于消融研究,我们使用 OPIXray 数据集并采用 SSD 作为基础架构。结果显示在表5中。
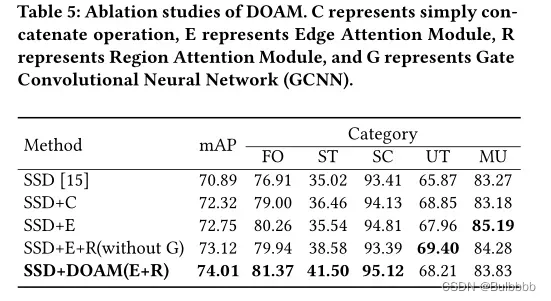
我们观察到,与没有任何注意机制操作的简单连接输入图像和相应边缘图像的方法相比,EAM 将性能提高了 0.43%。我们认为这主要是因为 EAM 能够通过优化损失函数专门增加边缘信息的权重,从而自适应地关注我们希望检测的违禁物品。然而,简单的连接对图像中的所有对象进行同等操作,无论对象是否是我们想要检测的对象以进行特征融合。
接下来,我们通过实验验证,与单独使用边缘注意模块相比,使用边缘注意模块和区域注意模块可以实现更精细的注意推理。为了增强区域之间的关系,我们尝试使特征图的每个像素都具有感知周围某个区域信息的能力,因为这样有利于 RAM 集中在对象的非遮挡部分上通过损失函数优化时对预测的影响。请注意,我们观察到违禁物品的大小平均约为 10×10,因此我们选择 10×10 作为区域尺度来感知特征图的每个位置。选项卡中的结果。从图 5 可以看出,EAM + RAM 的性能比单独的 EAM 高 0.37%,这证实了我们假设的正确性。
鉴于区域细化的特征,我们探索了一种有效的方法来选择区域的最佳大小以自适应地感知。我们选择了三种不同尺度的区域(分别为 5×5、10×10、15×15),并将门控卷积神经网络(GCNN)绘制到 RAM 中,以自适应地选择通过平均池化操作生成的最佳特征图具有适当的池大小。实验结果表明,绘制 GCNN 后,性能提升了 0.9%。
5.3 与不同检测方法的比较
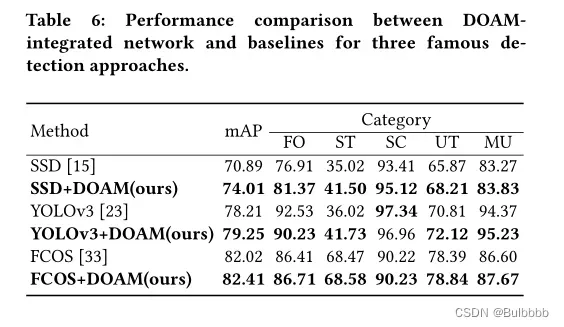
为了进一步评估 DOAM 的有效性并验证 DOAM 可以应用于各种检测网络,我们对著名的检测方法 SSD [15]、YOLOv3 [23] 和 FCOS [33] 进行了实验。结果显示在表6中。
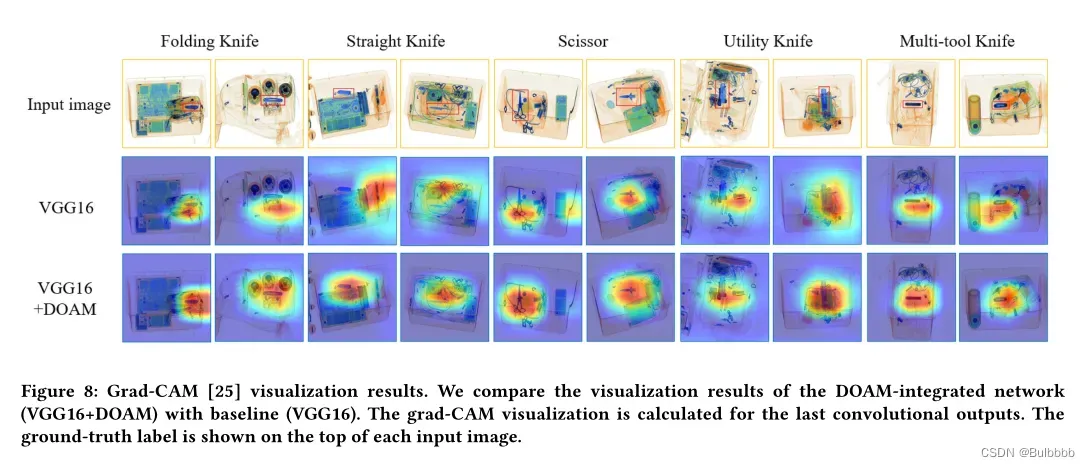
5.4 使用 Grad-CAM 进行网络可视化
对于可视化分析,我们将 Grad-CAM [25] 应用于两个网络,VGG16 网络 [27] 和 DOAM 集成网络 (VGG16+DOAM),并使用来自 OPIXray 数据集的图像。从图 8 中我们可以清楚地看到,DOAM 的 Grad-CAM 掩码比单个 VGG16 网络 [27] 更广泛地覆盖目标对象区域,这验证了 RAM 的有效性,利用 RIA 聚合区域信息。而 DOAM 的 Grad-CAM 掩膜更均匀地覆盖目标对象,围绕目标对象的形状,由于 EAM 的操作,它侧重于边缘信息。从观察结果来看,我们推测我们模型的特征细化过程最终会导致网络表现更好。
6 结论
在本文中,我们研究了 X 射线扫描图像中被遮挡的违禁物品检测,这是一个很有前途的工业应用,但在计算机视觉中的研究仍然较少。为了促进该领域的研究,我们提出了 OPIXray 数据集,该数据集主要关注图像中对象的遮挡。所有的背景都是从真实场景中捕获的,违禁物品是由我们从北京首都国际机场聘请的安检员插入的,这使得 OPIXray 数据集涵盖了复杂的场景和专业性。我们根据这些专业安全检查员提供的声明,手动将图像中的box-level 注释与边界框定位。
受过滤无关信息的启发,我们提出了一种名为 DOAM 的混合注意力机制,可应用于各种流行的检测方法,以细化特征。在实践中,我们设计了两个注意力子模块EAM和RAM,分别关注感兴趣的信息。如实验所示,DOAM 超越了流行的注意力机制,DOAM 集成网络明显超越了流行的检测方法,为所提出的任务建立了强大的基线。
文章出处登录后可见!