开一个新坑!《CS224n 斯坦福深度自然语言处理课》2021最新版(NLP入门,妈妈我到斯坦福上学啦!)传送门:课程视频
Preface
2021年的课程相较于2017、2019年新增了很多前沿内容,例如预训练大模型、问答相关、生成相关。我打算用英语来记录本系列的学习过程,其一可以熟悉一下学术名词(首次出现会给出对应中文释义),其二也能提高一下英语写作水平。
Chapter 1 Introduction to NLP
1.1 Definition
NLP (Natural Language Processing)is a field at the interesection of
- computer science
- artificial intelligence
- linguistic
1.2 Goal of NLP
- get computers to process hunman language
- perform useful tasks
- realize AI-complete
1.3 Prospect
-
All the tech firms are furiously putting out products via NLP .
-
Fully understand and representing the meaning of language(or even defining it) have long way to go.
1.4 Task level
Example tasks come in varying level of difficulty.Thus,there are different levels of tasks in NLP, from speech processing to semantic interpretation and discourse processing respectively.

Chapter 2 Word Vectors
2.1 Trditional solution
Commonest Linguistic way of thinking of meaning is turning symbol into idea, which is so-called denotational semantics(指称语义).
Common NLP solution:
WordNet, a thesaurus(同义词典) containing lists of synonym sets (同义词集) and hypernyms(上位词) .
Problems with resources like WordNet:
- Great as a resource but missing nuance
- Missing new meanings of words
- Subjective
- Requires human labor to create and adapt
- Can’t compute accurate word similarity:
– one-hot (独热码) vectors

Vector dimension (向量维度)= number of words in vocabulary
Problems:
These two vectors are orthogonal(正交)
There is no natural notion of similarity for one-hot vectors
Solution:
• Try to rely on WordNet’s list of synonyms to get similarity→fail badly: incompleteness, etc.
• Instead: learn to encode similarity in the vectors themselves
2.2 Distributed representation
A word’s meaning is given by the words that frequently appear close-by.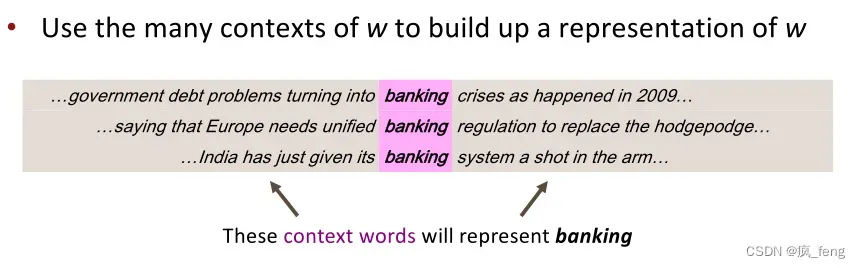
Word vectors—also called word embeddings(词嵌入) or (neural) word representations(词表征):
We will build a dense vector for each word, chosen so that it is similar to vectors of words that appear in similar contexts.

Chapter 3 Word2vec
3.1 Overview
Idea:
- We have a large corpus (语料库) of text
- Every word in a fixed vocabulary is represented by a vector
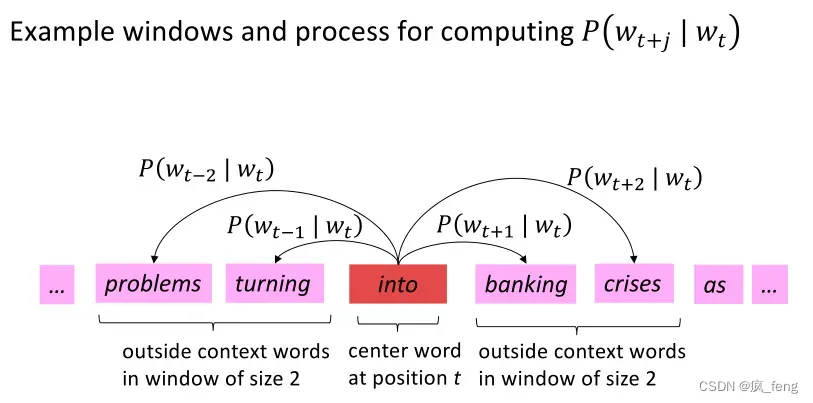
- Go through each position t in the text, which has a center word c
and context words o - Use the similarity of the word vectors for c and o to calculate
the probability of o given c - Keep adjusting the word vectors to maximize this probability
3.2 Objective function
Data likelihood(似然函数):
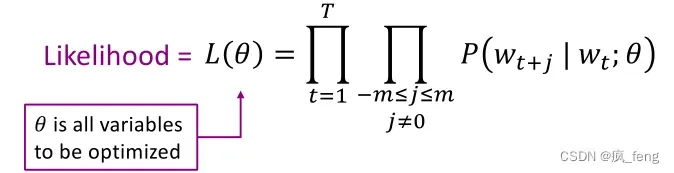
objective function(目标函数):also called a cost or loss function
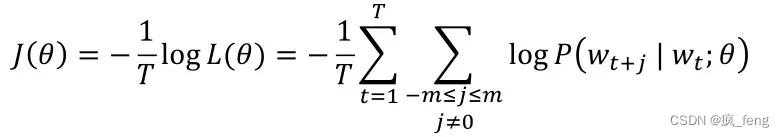
The loss function is the (average) negative log likelihood(负对数似然).
3.3 Minimizing objective function
3.3.1 Calculate probability
Use two vectors per word w

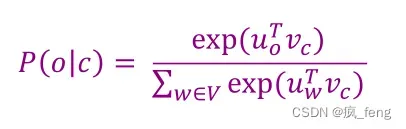
Dot product (点积)compares similarity of o and c.
Exponentiation (求幂) makes anything positive
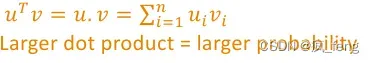
softmax function(柔性最大传输函数)
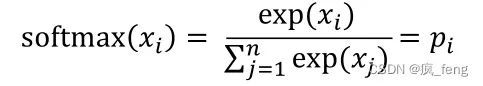
- “Max” because amplifies probability of largest x
- “Soft” because still assigns some probability to smaller x
- Return a distribution
3.3.2 Optimize value of parameters
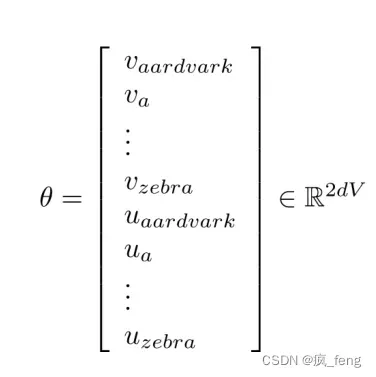
Optimize these parameters by walking down the gradient(梯度).
calculate gradient:
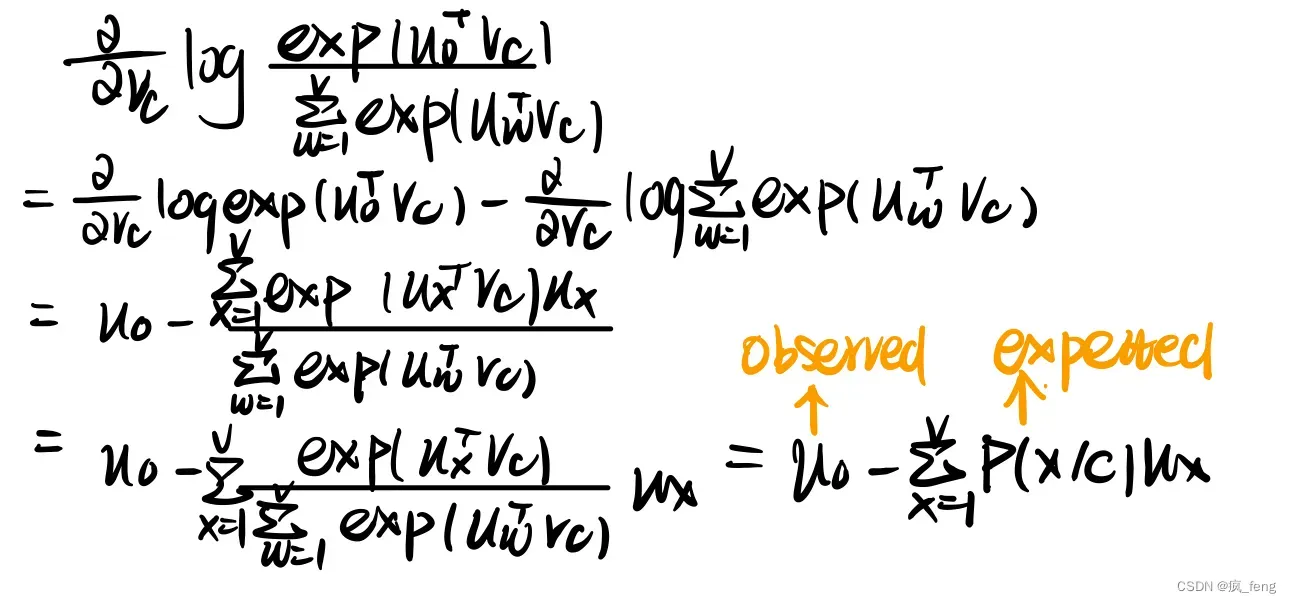
more details:
-
Two vectors per word
We can use the equation :
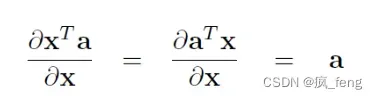
In order to avert the calculation of partial derivative(偏导数) of second power(二次幂).
-
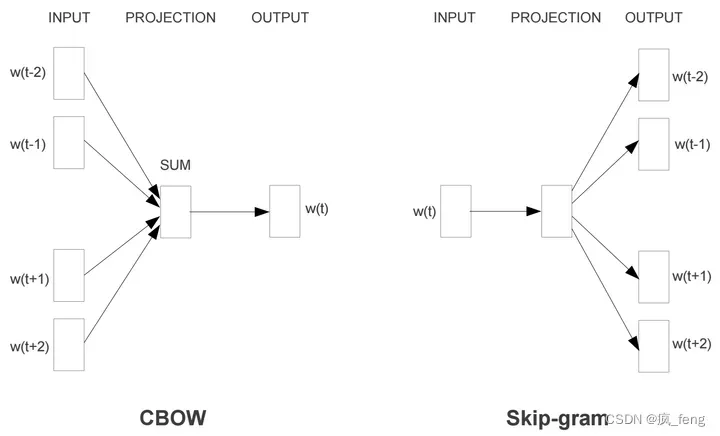
Two model variants:
1.Skip-grams (SG)
Predict context (“outside”) words (position independent) given center word
2.Continuous Bag of Words (CBOW 连续词袋模型)
Predict center word from (bag of) context words
-
Negative sampling(负采样)
To add efficiency in training:The idea is somewhat similar to SGD which will be mentioned. All calculations are expensive, so we do only a fraction calculation at one time and repeated many times.
Eg. If a vocabulary of 10,000 words. Model Output layer, we expect the probability of a word is 1, while for other 9, 999 words the output is 0 in taht case we need to calculate 9,999 times. And by negative sampling, samples for 5 ( that is, in other words 9,999 of 5 ) weights update, it will significantly reduce the amount of calculation.
Gradient Descent Algorithm(梯度下降算法) :
take small step in direction of negative gradient and repeat
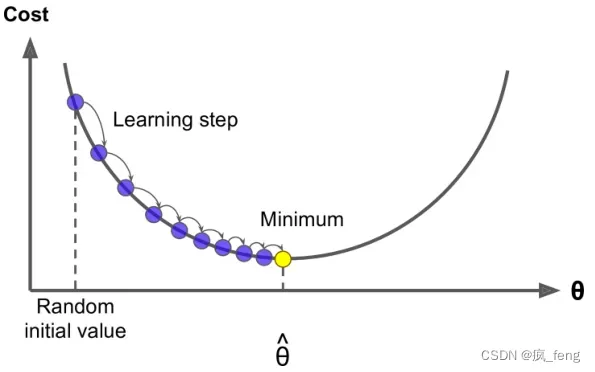

Problem: . LOSS is a function of all windows in the corpus
Promotion:Stochastic gradient descent (SGD随机梯度下降算法)
Repeatedly sample windows, and update after each one
while True:
window = sample_window (corpus)
theta_grad = evaluate_gradient(J,window ,theta)
theta = theta - alpha * theta_grad
A sample demonstration platform
The solution of relevant assignment will be presented in the next blog.
文章出处登录后可见!