论文阅读:Deep multi-view learning methods: A review
因为方向原因,这里主要是其中的GNN部分
a b s t r a c t
多视点学习(MVL)通过利用多个特征或模式的互补信息,受到越来越多的关注,并取得了巨大的实践成功。近年来,由于深层模型的显著性能,深层MVL在机器学习、人工智能和计算机视觉等领域得到了广泛的应用。本文从深度学习领域的MVL方法和传统方法的深度MVL扩展两个角度对深度MVL方法进行了综述。具体地说,我们首先回顾了深度学习领域中具有代表性的MVL方法,如多视角自动编码器、传统神经网络和深度简明网络。然后,我们研究了当传统学习方法遇到深度学习模型时,MVL机制的改进,如深度多视点典型相关分析、矩阵分解和信息瓶颈。此外,我们还总结了深度MVL领域的主要应用、广泛使用的数据集和性能比较。最后,我们试图确定一些开放的挑战,以指导未来的研究方向。
1. Introduction
近几十年来,随着视频监控[1-3]、娱乐媒体[4-6]、社交网络[7]和医疗检测[8,9]等领域数据量的爆炸性增长,多视点数据已经成为互联网上的主要数据类型之一。基本上,多视点数据是指从不同的形态、来源、空间等形式捕获的数据,但具有相似的高级语义。如图1所示,一个对象可以用文本、视频、音频的形式来描述;一个事件通常会用不同的语言进行报道;一个产品可以用多个图形来表示;一个逼真的图像可以用不同的视觉特征来描述;一个社会图像可以包含视觉信息和用户标签;一个特定的人类行为可以被不同的摄像机从不同的视角捕捉到。尽管这些视图通常代表相同数据的不同和互补信息,但由于多个视图之间的偏差,直接将它们集成在一起并不能获得一致令人满意的性能。因此,如何恰当地整合多个视点是一个中心问题,也是多视点学习的目标。
多视图学习旨在通过组合多个不同的特征或数据源来学习共同的特征空间或共享模式[10]。在过去的几十年里,MVL在机器学习和计算机视觉领域获得了巨大的发展势头[11-15],并启发了许多有前途的算法,如协同训练机制[16]、子空间学习方法[17]和多核学习(MKL)[18]。最流行的MVL方法之一是将多个视图数据映射到一个公共特征空间中,最大化多个视图的相互一致性[19-22,7]。在这个研究方向中,最早也是最具代表性的是典型相关分析(CCA)[11],它是一种搜索两个特征向量的线性映射的统计方法。在此之后,CCA的各种扩展被用于学习多个模态或视图的共享低维特征空间,如核CCA[23,24]、共享核信息嵌入[18,25]。除了CCA,MVL的思想还渗透到了各种学习方法[10,26-28],如降维[13]、聚类分析[29]和集成学习[30]。虽然这些方法都取得了很好的效果,但它们使用的是手工构造的特征和线性嵌入函数,无法捕捉复杂多视角数据的非线性本质。非线性是一个数学术语,描述了自变量和因变量之间没有直线或直接关系的情况。在非线性关系中,输出的变化不与任何输入的变化成正比。在研究学习模型的输入和输出之间的关系时,非线性是一个常见的问题。在机器学习和计算机视觉领域,存在着各种类型的非线性数据,如文本、图像、视频和音频。随着信息技术的飞速发展,现实应用中每天都会产生海量的具有非线性性质的多视图数据,如图1所示。多视图数据的这种线性性质使得多视图数据的学习任务仍然具有挑战性。
近年来,由于深度学习方法强大的特征提取能力,深度学习方法已经广泛应用于许多性能优异的应用中,如计算机视觉[20,32-34]和人工智能[19,35,36,22]。深度学习方法通过允许多个层次,可以有效地学习目标数据的复杂、细微、非线性和抽象的表示。随着深度学习在许多应用领域的成功,深度MVL方法也得到了越来越多的开发,并取得了良好的结果[35,19,32,36,33,34,20,22]。
鉴于近年来提出的大量基于深度学习的MVL方法,我们试图对这些工作进行全面的回顾并提出我们的分析。如图2所示,本文首先回顾了深度学习领域中具有代表性的MVL方法,如多视点自动编码器(AE)、传统神经网络(CNN)和深度简明网络(DBN)。然后,我们研究了当传统学习方法遇到深度学习模型,如深度多视点典型相关分析(CCA)、矩阵分解(MF)和信息瓶颈(IB)时,MVL机制的进步。最后,我们回顾了深层MVL方法的几个重要应用、广泛使用的数据集和存在的问题,以供进一步研究和探索。
1.1. Comparison with Previous Reviews
最近,一些重要的关于MVL的相关调查相继发表,总结了现有的MVL方法的理论、方法、分类和应用[10,26-28,37-40]。这些研究集中在特定MVL方法的问题上,如多视图融合[10,27,28]、多模式学习[37,38]、多视图聚类[26]和多视图表示学习[39,40]。
与以往的研究相比,本文侧重于从深度学习和语言学习的交叉角度回顾文献,因为直接总结深度语言学习方法的调查很少。特别是,[10,26-28]中的调查侧重于传统学习方法领域中的MVL方法。例如,Baltrusaitis等人。[38]和Li等人。[39]总结了具有代表性的多视点特征学习方法的浅层学习模型,其中基于深度学习的MVL方法在其研究中被忽略或只是总结了一小部分。相比之下,我们重点介绍了近年来得到更多关注的深度MVL方法。从深层模型的角度来看,与本文最相关的努力是[37,40]。然而,它们都集中在多通道表示融合的模型和应用上。我们的审查与上述两次审查的主要区别概括为以下两个方面。首先,这篇综述涉及到MVL的更多方面,而另外两篇综述则集中在多视角特征学习上。其次,我们还回顾了传统方法的深度多视点扩展,如深度多视点MF、深度多视点谱学习和深度多视点IB,这些方法从未被研究过。
我们的审查与上述两次审查的主要区别概括为以下两个方面。首先,这篇综述涉及到MVL的更多方面,而另外两篇综述则集中在多视角特征学习上。其次,我们还回顾了传统方法的深度多视点扩展,如深度多视点MF、深度多视点谱学习和深度多视点IB,这些方法从未被研究过。
2. Multi-view Learning Methods in The Deep Learning Scope
2.4. Multi-view graph neural networks
图神经网络(GNN)[73]在学习表示方面协调了图与深层模型交互建模的表达能力,并因其对图结构数据的建模能力而受到越来越多的关注。它们处理可变大小的置换不变图,并通过从拓扑邻居那里传递、变换和聚集表示的迭代过程来学习低维表示。近年来,GNN在图结构数据分析方面取得了突出的表现,如社会网络[74]和知识图[75]。首先,我们简要回顾了GNN的基本背景知识。设G1/4FV;例如表示一个图,它是GNN的输入数据,变量V1/4FVIGAND E1/4FIJG表示节点和边的集合。每个edgeeij 1/4üvi;主播?连接vi和主播,每个节点vi包含一个表示其属性的特征xi。GNN的聚合过程可以表示如下
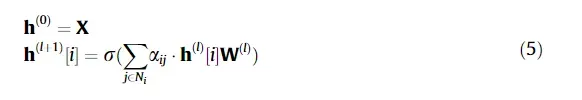
其中,变量X表示图G中所有节点的输入特征;r是像Relu这样的非线性函数,1/2i表示第l层中节点i的隐藏特征,a是邻接矩阵的变种,W是可学习的线性转移矩阵。
近年来,GNN在MVL场景中也取得了良好的性能,如多图聚类和多视点图传统网络。我们以图上的多视点表示学习为例。Hassani等人。[76]提出了一种基于图的对比式多视点特征学习方法,指出将视图数增加到两个以上并不能提高性能。如图8所示,所提出的模型在节点和图两个级别上执行。首先,采用图扩散的方法生成目标视点的附加图视图,该图被馈送到两个GNN中,然后由共享的多层感知器(MLP)学习节点表示。然后,学习的特征表示被馈送到图池中,随后是共享的MLP以学习图表示。
基于广义神经网络的多图聚类是一个活跃的研究方向,近年来得到了广泛的关注。例如,Fan等人。[77]设计了一种1/2多图自动编码器,该编码器通过利用内容信息从多个视图重建图结构来学习节点嵌入。该模型主要由两部分组成:多图自动编码器和图的自监督聚类机制。如图9所示,one2more由一个基于图的编码器体系结构和一个基于多视图的解码器体系结构组成,在该体系结构中,通过启发式度量模块化来选择信息最丰富的视图。
我们以全球贫困分析、分子性质预测、多视角摄像机重定位和压缩伪影消除为例,对多视角广义神经网络的应用进行了综述。具体地说,Khan等人。[78]提出了一种基于图结构的卷积网络来分析全球贫困。这一方法被应用于三项任务:(1)预测采用金融包容性;(2)预测一个人是否生活在贫困线以下;(3)预测手机用户的性别。对于分子性质的预测,Ma等人。[79]从以下几个方面提出了一个多视点图神经网络:原子和键对分子的化学性质都有显著的影响,因此同时利用节点(原子)和边(键)信息来建立表达模型是明智的。薛等人。[80]重新设计的GNN与CNN合作指导特征提取和信息传播过程,以获得多视角图像的特征表示。
4. Applications
在过去的几十年里,深度MVL方法由于其在对象检索、社会视频/图像分析、生物信息学和健康信息学、自然语言处理和推荐系统等特征表示方面的卓越能力,在计算机视觉和模式识别领域取得了令人满意的结果。其中,前三个领域在最近几年相当繁荣,因此我们在下文中对它们进行了详细的调查。
4.1. Cross-modal Retrieval
跨模式检索是一个基础性的研究课题,其目的是从语义相似的其他模式中搜索数据实例,例如使用文本检索相关图像[90]。近年来,基于跨模式检索的深度学习模式取得了很大的进展。现有的深度交叉模式检索方法通常可以分为两类:散列法和子空间法。
基于散列的深度CMR方法旨在找到能够在不同模式之间进行转换的散列函数。深度跨模式散列方法涉及两种设置:无监督方法和有监督方法。具体地说,非监督散列的目的是通过探索未标记源数据的模态信息来学习散列函数,例如深度连接语义重构散列(DJSRH)[90]、无监督深度跨模式散列(UDCMH)[159]、自监督对抗性散列(SSAH)[160]和无监督耦合散列(UCH)[161]。有监督的算法旨在利用可用的监督信息(如标签)来提高检索性能,如图卷积散列(GCH)[162]、基于三元组的深度散列(TDH)[163]、循环一致的深度生成散列(CyC-DGH)[164]和等导区分性散列(EGDH)[165]。
基于公共子空间的CMR方法试图发现一个共同的特征空间,在那里可以直接计算不同模态之间的距离。例如,甄子丹等人。[166]提出了一种深度监督CMR(DSCMR)方法,该方法在子空间和标签空间都最小限度地保留了区分损失,以监督多个模态的公共特征学习
4.2. Cross-modal video/image analysis
深度MVL方法已成功地应用于跨通道图像或视频的分析。接下来,我们将展示一些有代表性的。
4.2.1. 3D reconstruction
由于DNN良好的性能和广泛的应用,基于学习算法的三维重建方法得到了广泛的应用[168,169,60]。窦等人。[168]针对人脸图像变化大的主要问题,提出了一种用于多视角三维人脸重建的深度RNN模型。Yang等人没有使用RNN模型,而是使用RNN模型。[60]设计了一种新的前馈神经网络和专用的训练方法,用于从多个视角获取三维物体重建的深度特征,从而避免了在输入图像排列的情况下对二维形状估计不一致的问题。
4.2.2. Facial detection and recognition
多视图源数据中的人脸检测是一个有价值的研究课题和具有挑战性的任务,因为姿态和光照存在很大的视点变化[170,171,173,174,176,177]。为了解决MVL场景中的人脸检测问题,Farfade等人提出了一种新的人脸检测算法。[170]提出了一种基于深度细胞神经网络的密集人脸检测器,不需要对人脸标志点进行标注,也不需要训练多个模型来捕获不同方向的人脸。白等人。[171]从非刚性多视点立体的角度对三维人脸检测问题进行了阐述,从而提出了通过保持多视点外观的一致性来优化三维人脸形状。Li等人。[172]目的提出一种结合数据清洗和多视点深度表征学习的稳健两阶段人脸识别方法,解决大规模人脸识别问题。夏等人[175]打算使用CNN网络估计眼睛中心。赵等人。[176]通过对人脸区域进行编码,压缩高维学习特征,设计联合贝叶斯分类框架,提出了一种新的DNN结构,以提高多视角人脸识别的性能。
4.2.3. Human action recognition
视频或图像中的人类动作通常由高度关节的运动、人与物体的交互和复杂的时间结构组成[178-182]。宋等人[178]提出了一种基于深层CNN和RNN结构的多通道场景下的动作识别框架,能够更好地学习有效的特征表示进行动作分类。在智能家居环境中对不平衡的多模式传感器数据进行分类以进行活动识别是一项相当具有挑战性的工作。为此,Alani等人。[179]首先考察使用多模式数据的有效性,然后将深度学习方法与其他方法在处理不平衡的多模式数据方面进行比较。Trumble等人。[180]针对多视点视频中具有挑战性的无标记姿势估计问题,提出了一种基于深度CNN的人体行为捕获系统。Huang et al.[181]提出了一种结合人体佩戴的惯性测量单元(IMU)数据和横视图像的两级3D神经网络,其中第一阶段用于视觉估计,第二阶段用于融合早期的IMU数据和视觉数据,而不需要骨骼模型。
4.2.4. Person re-identification
物体或人的重新识别在图像处理领域受到了极大的关注,这里我们展示了两个典型的图。20.无监督深度多视点信息瓶颈(MIB)方法.严晓东,胡松山,毛勇,等.Neuroculation448(2021年)106-129121多视图聚类范例,其中可靠的数据点被用于通过引入一种新的正则化来最小化识别损失和排名损失来微调CNN模型。
4.3. Bioinformatics and health informatics
由于深度模型在特征表示任务上的成功,许多流行的基于DNN的网络(如CNN)已被应用于具有挑战性但有益的医学分析[186-190],如生物信息学和健康信息学。更具体地说,它已被广泛应用于脑问题[8,9]、乳房诊断[191,192,?]等三个典型领域。和扣押识别[194,195]。例如,魏等人。[8]提出了一种深度神经网络结构,用于多模式/大小/视图场景下的脑图像分割,使得冠状面或矢状面的MR切片可以被清晰地分割。Jonnalagedda等人对乳腺癌的放大不变诊断。[192]针对数据集的多样性和数据量小的问题,提出了一种多视点路径DNN和数据增强方法,并进一步融合了局部和全局特征以实现更有效的诊断。通过结合DNN和支持向量机两种流行的模型,Gong et al.[193]提出了一种基于多视角DNN结构的支持向量机分类方法,用于B超和超声心动图模式下的乳腺癌诊断。袁等人。[194]尝试使用多通道头皮脑电信号与多视点深通道感知注意网络来检测癫痫发作。为了改进模型,袁等人对模型进行了改进。[195]进一步设计了一种改进的端到端模型,用于无监督脑电联合重建和有监督发作检测。
5. Datasets
下面,我们列出了一些流行的多视图文本、图像和视频数据集,并在表2中展示了详细信息。请注意,对于图像数据集,每种特征,如形状、纹理或颜色,总是被视为一个视图,所以我们不在表中显示它们。以下是用于评估多视点学习方法的一些流行的图像数据集:Caltech 101/256[199]、NUSWIDE[200]、COIL20/100 1、17Flowers[201]、足球2、Scene-15[202]和ORL 3数据集。
在过去的几年里,出现了各种各样的深度多视角学习方法,而路透社、MNIST和NUS-Wide等标准基准的集合使得在准确性方面比较这些深度多视角学习方法变得更容易。虽然对所有已提出的方法进行比较可能不切实际,但有必要以统一的方式比较典型的深度MVL方法。参见表3。
在这一部分中,我们比较了深度MVL方法在三种常见任务上的性能:跨模式检索、多视点3D对象识别和多视点聚类(MVC)。MVL关注的是从由多个不同特征或数据源表示的数据中进行机器学习的问题,本质上是一种学习方法。因此,机器学习领域中的常见性能指标可以用来评估MVL方法的性能。对于深度跨模式检索方法,我们比较了以下几种方法的平均准确率(MAP)[162]:深度联合语义重建散列(DJSRH)[90]、自监督对抗性散列(SSAH)[160]、无监督深度跨模散列(UDCMH)[159]、无监督耦合散列(UCH)[161]、图卷积散列(GCH)[162]、基于三元组的深度散列(TDH)[163]、循环一致的深层生成性散列(CYCDGH)[164]、等导识别性散列(EGDH)[165]、深度监督跨模式检索(DSCMR)[166]和多模式神经机器翻译(MMT)[167]。
可解释人工智能是近年来出现的一个新兴领域,在深度MVL领域得到了广泛的关注。尽管现有的深MVL模型在各种应用中显示出了优越的优势,但它们不能对不同模型的决策提供解释。因此,没有解释的深层模型不容易应用于军事系统或医疗等关键领域。未来,我们相信可解释的深度模型将成为热门话题,并将扩展到更多领域。近年来,许多研究试图打开深度神经网络的黑匣子,并提出了各种理论来解释它。其中,信息瓶颈(IB)理论认为,在训练过程中存在两个不同的阶段,即适应阶段和压缩阶段[91]。这一命题由于成功地解释了前馈神经网络的内部行为而引起了人们的广泛关注。参见表5。
从多个视图捕获的数据点始终具有异质特征,但同时也说明了复杂的视图关系。因此,同时探索不同视图之间的共享信息和特定于视图的信息是非常具有挑战性的。现有的方法通常采用基于k-均值或谱的多视点学习方法来解决这一问题,而很少涉及深度学习模型。因此,通过联合打破视图间的异构性鸿沟并探索它们之间的关系来设计一个合理的深度模型将是一个很有前途的研究方向。实际上,对于异质数据,有几种实用的策略,如迁移学习和基于知识图的表示学习。具体地说,迁移学习的目标是从源域到目标域共享信息,其中两个域都拥有不同的特征空间,例如跨媒体智能的情况[35]。因此,在从异质数据中重建特征表示时,迁移学习有助于弥合数据分布、特征空间等方面的差距,从而能够很好地构造出强健的特征向量。
在多视图聚类中,由于相同的数据样本由多个视图从不同的角度描述,因此不同的视图必然密切相关。然而,视图之间的关系相当复杂,很难探索。现有的深度多视点学习方法大多通过简单的拼接或融合来学习共享嵌入特征来发现视点关系,然后应用交叉熵损失函数或传统的机器学习方法进行监督或非监督学习。然而,这些方法仍然不能充分探索观点之间的关系。因此,为深度多视点学习设计一种有效的视点关系探索策略具有重要意义,同时也是未来的挑战。我们认为,可以借用信息传播机制来传播视图之间的有用关系,以进行关系探索,如亲和力传播和标签传播[80]。
近年来,越来越多的多视图数据表现出复杂的图形结构,其中需要处理的最重要的问题之一就是图形特征表示。多视点图形数据的良好特征表示对于许多下游应用,例如分类/聚类、对象分割、对象检测或3D重建是重要的。然而,从社会网络或医疗诊断数据等各个实际领域获取多视图源数据的图形特征的工作寥寥无几。在接下来的几年里,多视点图形表示将成为一个热门话题,并在不同的应用领域显示出其优势。最近,图神经网络(GNN)[73]在学习表示方面协调了图与深层模型交互建模的表达能力,并因其对图结构数据的建模能力而受到越来越多的关注。利用GNN对复杂的多视点图形数据进行建模是一个值得研究的课题。
多模态(multi-modal)和多视图(multi-view)有什么区别?
简单来说 multiview一般指同一个对象不同的表现形式。比如一个3D物体不同角度或者不同频谱下的成像图像。
multimodality指不同模态,它们所表现的可能是不同的对象,但之间有联系。比如文本和对应的音视频。
这两者之间最关键的区别是后者可能不是描述完全一样的物体或对象,所以往往需要有个预对齐或者建立两者间的对应关系,既correspondence
,它们所表现的可能是不同的对象,但之间有联系。比如文本和对应的音视频。
这两者之间最关键的区别是后者可能不是描述完全一样的物体或对象,所以往往需要有个预对齐或者建立两者间的对应关系,既correspondence
文章出处登录后可见!