文本基于霹雳吧啦WZ的博客及视频,添加了部分自己的理解
0. 引言
自从ViT(Vision Transformer)在CV领域大放异彩,越来越多的研究人员开始拥入Transformer的怀抱。回顾近一年,在CV领域发的文章绝大多数都是基于Transformer的,比如2021年ICCV 的best paper Swin Transformer,而卷积神经网络已经开始慢慢淡出舞台中央。
CNN似乎进入到了一个瓶颈期。那么卷积神经网络要被Transformer取代了吗?
也许会在不久的将来。
今年(2022)一月份,Facebook AI Research和UC Berkeley一起发表了一篇文章A ConvNet for the 2020s,在文章中提出了ConvNeXt纯卷积神经网络,它对标的是2021年非常火的Swin Transformer,通过一系列实验比对,在相同的FLOPs下,ConvNeXt相比Swin Transformer拥有更快的推理速度以及更高的准确率,在ImageNet 22K上ConvNeXt-XL达到了87.8%的准确率,参看下图。
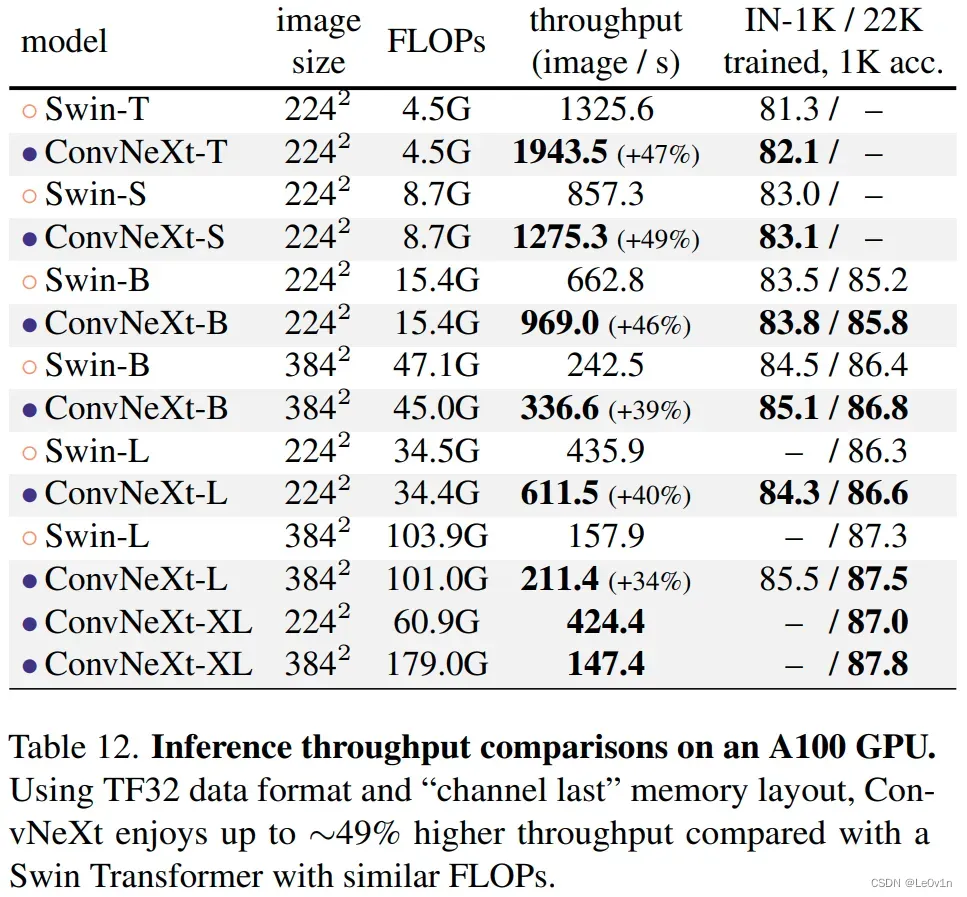
表 12. A100 GPU 上的推理吞吐量比较。 使用 TF32 数据格式和“通道最后”内存布局,与具有类似 FLOP 的 Swin Transformer 相比,ConvNeXt 的吞吐量提高了 49%。
网络都是基于ImageNet 22K上进行预训练,再使用ImageNet 1K上进行迁移学习和准确率的评估
我们可以发现,对应体量的ConvNeXt和Swin-Transformer相比,Accuracy是更高的,而且推理速度要更快(平均大约42.5%),最大体量的ConvNeXt-XL在ImageNet 1K的准确率达到了87.8。
ConvNeXt不仅在图片分类上取得不错的效果,在目标检测(MS COCO)、分割(ADE20K)都取得在同等体量下比Swin Transformer要好的结果。
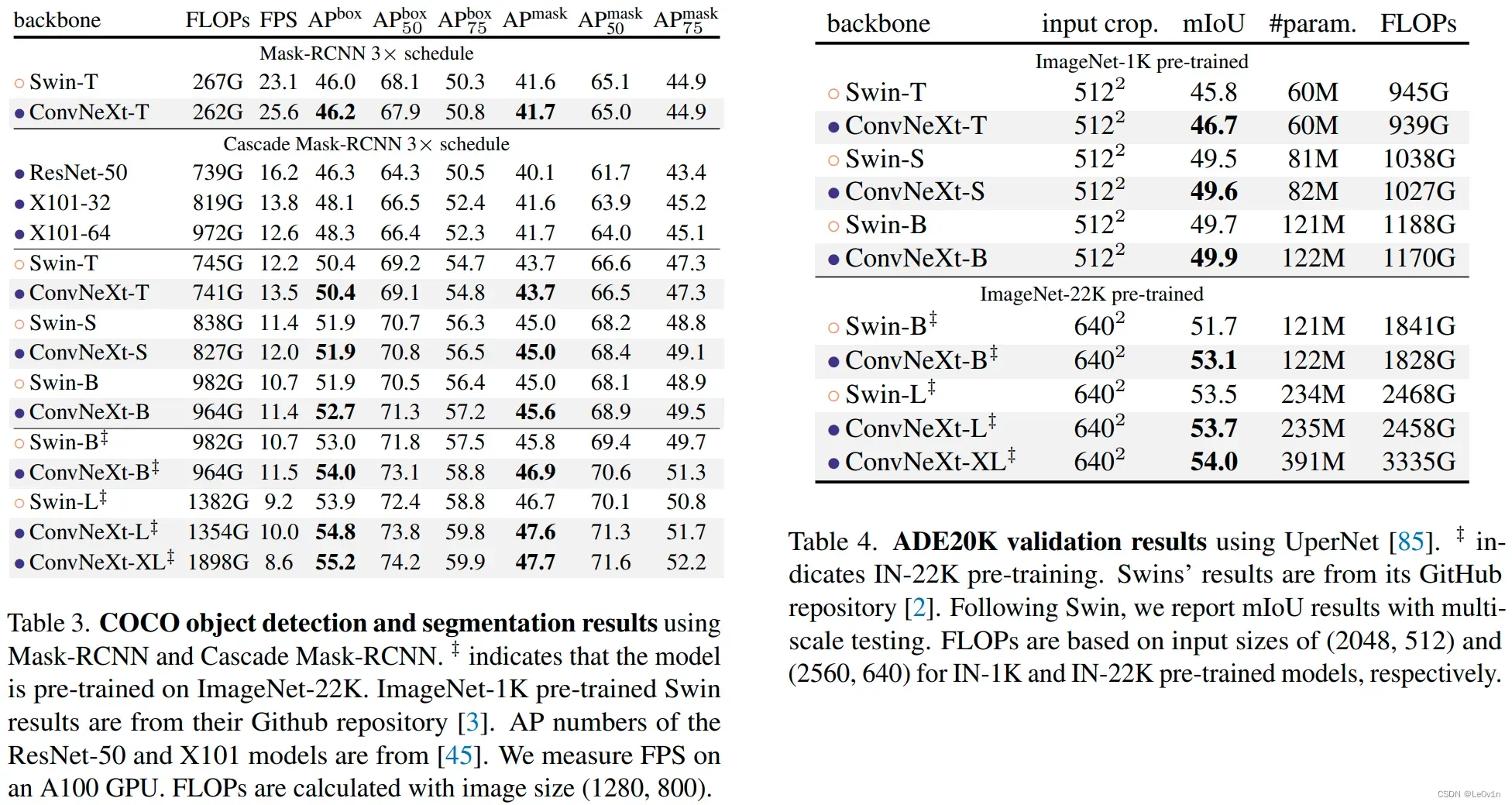
表 3. 使用 Mask-RCNN 和 Cascade Mask-RCNN 的 COCO 对象检测和分割结果。 ‡表示模型在 ImageNet-22K 上进行了预训练。 ImageNet-1K 预训练的 Swin 结果来自他们的 Github 存储库。 ResNet-50 和 X101 模型的 AP 编号来自 [45]。 我们在 A100 GPU 上测量 FPS。 FLOP 使用图像大小 (1280, 800) 计算。
表 4. 使用 UperNet [85] 的 ADE20K 验证结果。 ‡表示 IN-22K 预训练。 Swins 的结果来自其 GitHub 存储库。 在 Swin 之后,我们通过多尺度测试报告 mIoU 结果。 FLOP 分别基于 IN-1K 和 IN-22K 预训练模型的 (2048, 512) 和 (2560, 640) 输入大小。
看来ConvNeXt的提出强行给卷积神经网络续了口命。
如果你仔细阅读了这篇文章,你会发现ConvNeXt“毫无亮点”,ConvNeXt使用的全部都是现有的结构和方法,没有任何结构或者方法的创新。而且源码也非常的精简,100多行代码就能搭建完成,相比Swin Transformer简直不要太简单。之前看Swin Transformer时,滑动窗口,相对位置索引,不光原理理解起来有些吃力,源码多的也挺让人绝望的(但无法否认Swin Transformer的成功以及设计的很巧妙)。
Q: 为什么现在基于Transformer架构的模型效果比卷积神经网络要好呢?
A: 论文中的作者认为可能是随着技术的不断发展,各种新的架构以及优化策略促使Transformer模型的效果更好,那么使用相同的策略去训练卷积神经网络也能达到相同的效果吗?抱着这个疑问作者就以Swin Transformer作为参考进行一系列实验。
In this work, we investigate the architectural distinctions between ConvNets and Transformers and try to identify the confounding variables when comparing the network performance. Our research is intended to bridge the gap between the pre-ViT and post-ViT eras for ConvNets, as well as to test the limits of what a pure ConvNet can achieve.
1. 设计方案
作者首先利用训练vision Transformers的策略去训练原始的ResNet50模型,发现比原始效果要好很多,并将此结果作为后续实验的基准baseline。然后作者罗列了接下来实验包含哪些部分:
- Macro design —— 宏观设计
- ResNeXt —— ResNeXt网络结构
- Inverted bottleneck —— 逆残差模块
- Large kerner size —— 大卷积核
- Various layer-wise Micro designs —— 各种分层微设计
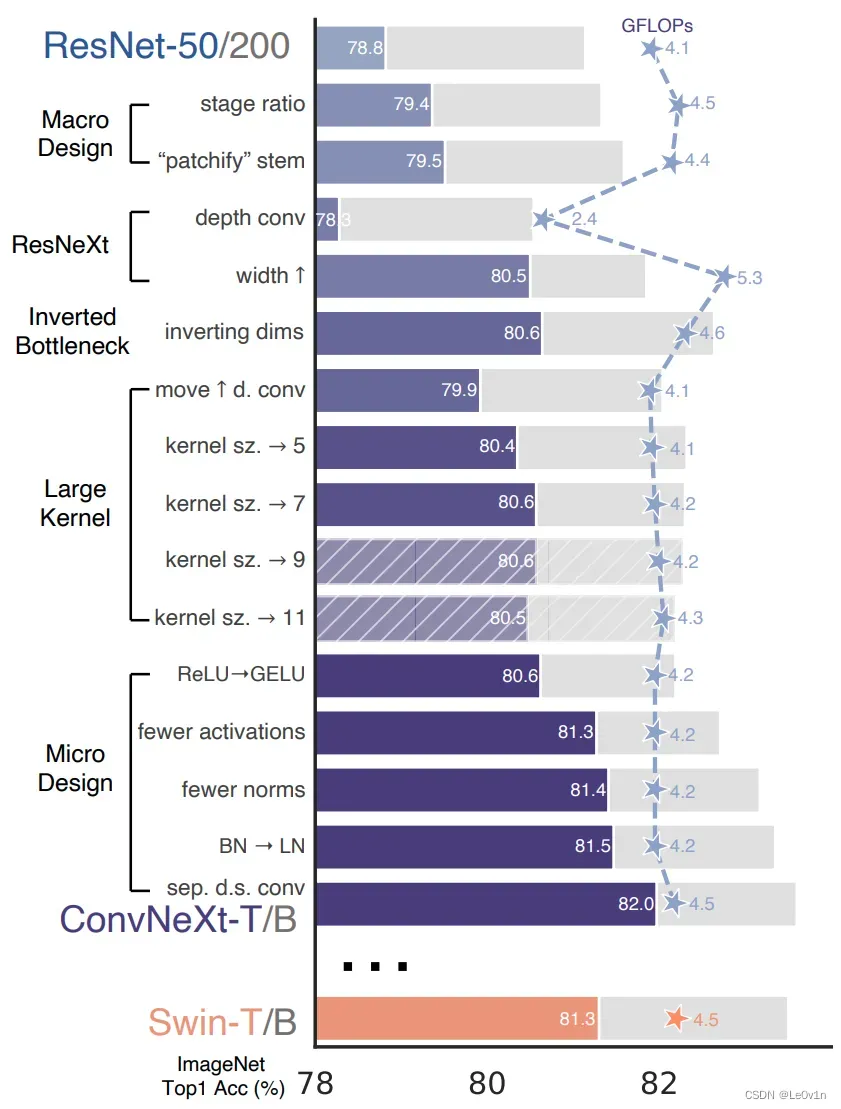
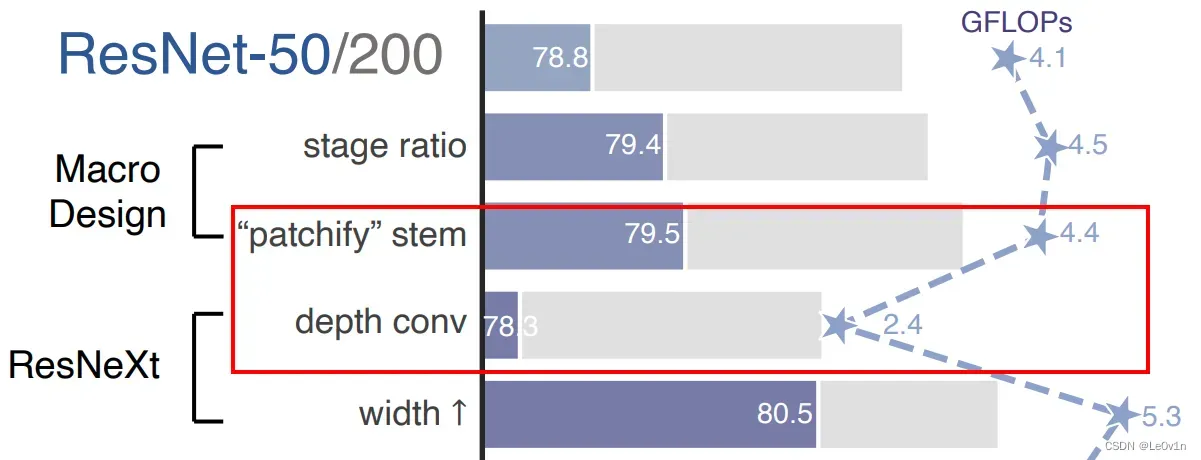
图 2. 我们对标准 ConvNet (ResNet) 进行现代化改造,以设计分层视觉 Transformer (Swin),而不引入任何基于注意力的模块。 前景条是 ResNet-50/Swin-T FLOP 机制中的模型精度; ResNet-200/Swin-B 方案的结果用灰色条显示。 阴影条表示未采用修改。 两种方案的详细结果见附录。 许多 Transformer 架构选择可以合并到 ConvNet 中,它们会带来越来越好的性能。 最后,我们的纯 ConvNet 模型,名为 ConvNeXt,可以胜过 Swin Transformer。
横坐标:
-
紫色为准确率
-
灰色为GFLOPs,⭐️为具体的数值
-
第一行:作者用训练VIsion Transformer的方法去训练ResNet -> 准确率为78.8, GFLOPs为4.1 -> 将其作为Baseline
-
trick 1
-
trick 2
-
…
-
ConvNeXt-T
我们的起点是 ResNet-50 模型。 我们首先使用用于训练视觉 Transformer 的类似训练技术对其进行训练,并与原始 ResNet-50 相比获得了很大改进的结果。 这将是我们的基线。 然后我们研究了一系列设计决策,我们总结为 1) 宏观设计,2) ResNeXt,3) 倒置瓶颈,4) 大内核大小,以及 5) 各种分层微设计。
2. Macro design —— 宏观设计
在这个部分作者主要研究两方面:
- Changing stage compute ratio —— 改变阶段计算比例
- Changing stem to “Patchify” ——
2.1 stage ratio
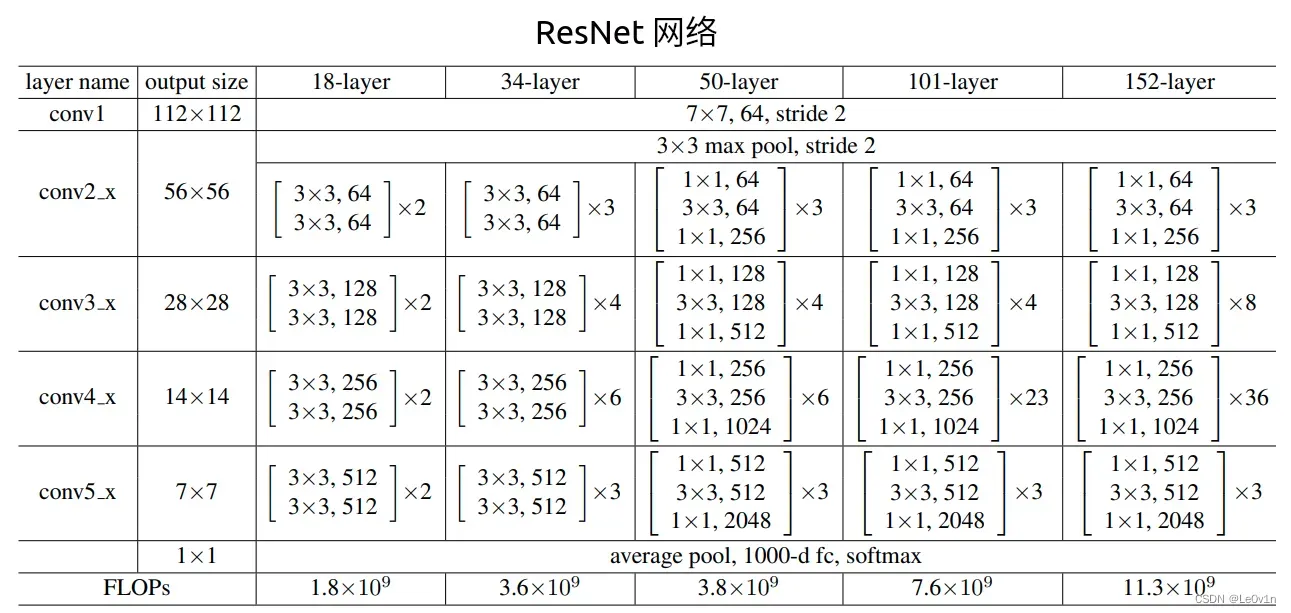
在原ResNet网络中,一般conv4_x(即stage3)堆叠的block的次数是最多的。如下图中的ResNet50中stage1到stage4堆叠block的次数是(3, 4, 6, 3)比例大概是1:1:2:1,但在Swin Transformer中,比如Swin-T的比例是1:1:3:1,Swin-L的比例是1:1:9:1。很明显,在Swin Transformer中,stage3堆叠block的占比更高。所以作者就将ResNet50中的堆叠次数由(3, 4, 6, 3)调整成(3, 3, 9, 3),和Swin-T拥有相似的FLOPs。进行调整后,准确率由78.8%提升到了79.4%。
2.2 “Patchify”
Q:什么是stem?
A:在CNN中,最初的下采样模块称之为stem。在ResNet网络中,stem是由①7×7卷积和②3×3 Maxpooling共同组成。
stem 英[stem] 美[stem]
n. (花草的)茎; (花或叶的)梗,柄; (高脚酒杯的)脚; 烟斗柄; 有…茎(或梗)的; 词干;
vt. 阻止; 封堵; 遏止;
Changing stem to “Patchify”,在之前的卷积神经网络中,一般最初的下采样模块stem一般都是通过一个卷积核大小为7×7步距为2的卷积层以及一个步距为2的最大池化下采样共同组成,高和宽都下采样4倍。但在Transformer模型中一般都是通过一个卷积核非常大且相邻窗口之间没有重叠的(即stride等于kernel_size)卷积层进行下采样。比如在Swin Transformer中采用的是一个卷积核大小为4×4步距为4的卷积层构成patchify,同样是下采样4倍。所以作者将ResNet中的stem也换成了和Swin Transformer一样的patchify。替换后准确率从79.4% 提升到79.5%,并且FLOPs也降低了一点。
3. ResNeXt
3.1 Depth-wise Convolution
接下来作者借鉴了ResNeXt中的组卷积grouped convolution,因为ResNeXt相比普通的ResNet而言在FLOPs以及accuracy之间做到了更好的平衡。
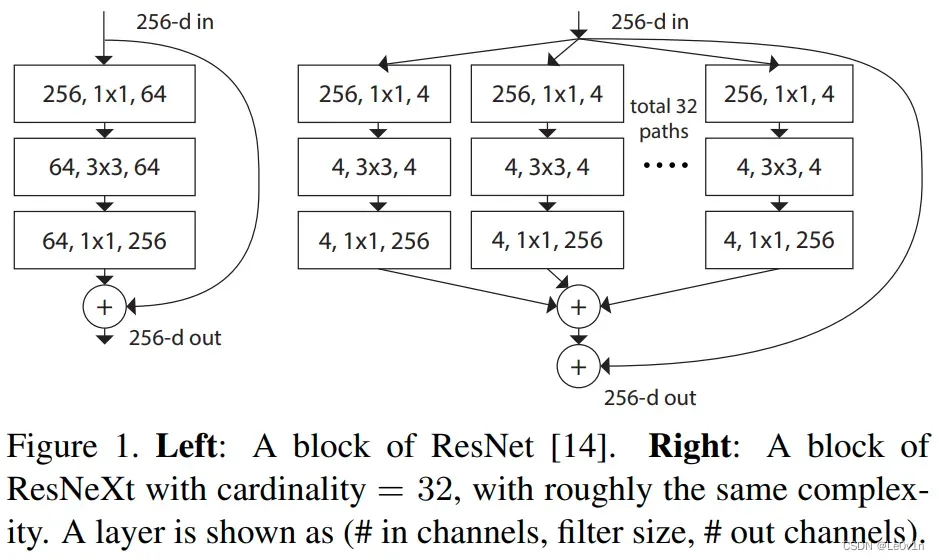
图 1. 左:ResNet 块。 右图:基数 = 32 的 ResNeXt 块,复杂度大致相同。 一层显示为(#in channels, filter size, #out channels)。
而作者采用的是更激进的depthwise convolution,即group数和通道数channel相同。这样做的另一个原因是作者认为depthwise convolution和self-attention中的加权求和操作很相似。
We note that depthwise convolution is similar to the weighted sum operation in self-attention.
我们注意到,深度卷积类似于自注意力中的加权求和操作。
使用深度卷积替换普通卷积后,准确率从79.5%降低到了78.3,但GFLOPs从原来的4.4降低到了2.4。
3.2 Expand width of feature map
为了增加准确率,作者增大了特征图的通道。作者参照Swin Transformer,将最初的通道数由64调整成96,和Swin Transformer保持一致,最终准确率达到了80.5%,GFLOPs也增加了很多。
4. Inverted Bottleneck
作者认为Transformer block中的MLP模块非常像MobileNetV2中的Inverted Bottleneck模块,即两头细中间粗。图(a)是ResNet中采用的Bottleneck模块,(b)是MobileNetV2采用的Inverted Bottleneck模块,©是ConvNeXt采用的是Inverted Bottleneck模块。
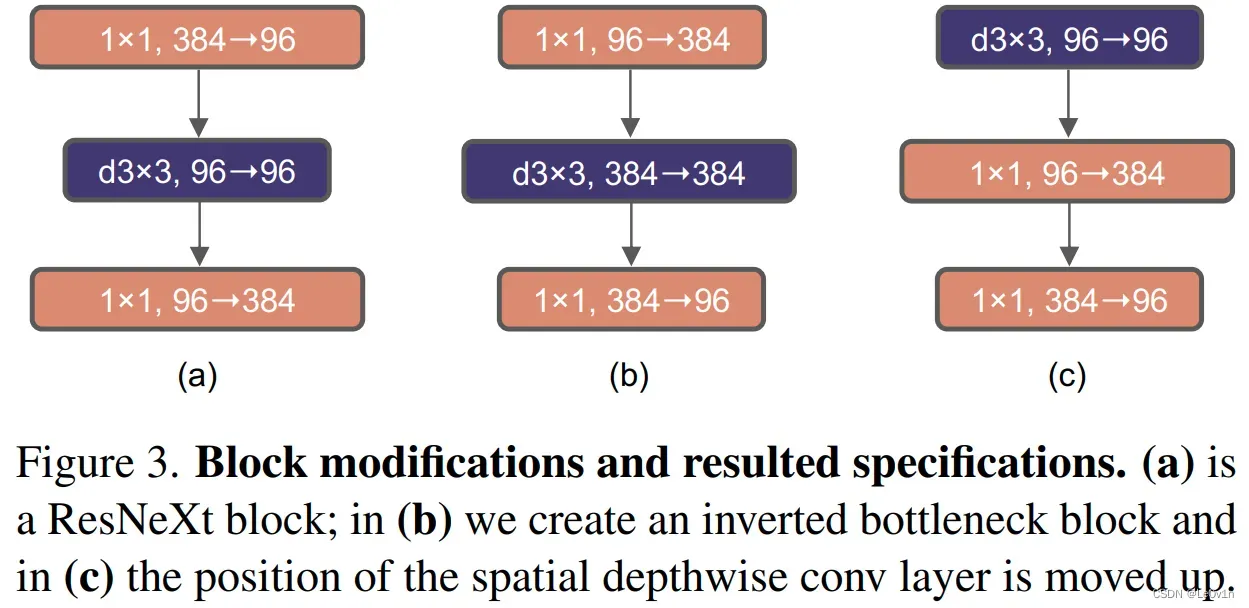
图 3. 模块修改和生成的规范。 (a) 是一个 ResNeXt 块; 在(b)中,我们创建了一个倒置的瓶颈块,在(c)中,空间深度卷积层的位置向上移动。
作者采用Inverted Bottleneck模块后:
- 在较小的模型上准确率由80.5%提升到了80.6%
- 在较大的模型上准确率由81.9%提升到82.6%
有趣的是,这会稍微提高性能(从 80.5% 提高到 80.6%)。 在 ResNet-200 / Swin-B 方案中,这一步带来了更大的收益(81.9% 到 82.6%),同时也减少了 FLOP。
这说明Inverted Bottleneck模块对于较大的模块提升效果还是比较明显的。
5. Large Kernel Sizes —— 大卷积核
在Transformer中一般都是对全局做self-attention,比如Vision Transformer。即使是Swin Transformer也有7×7大小的窗口。但现在主流的卷积神经网络都是采用3×3大小的窗口,因为之前VGG论文中说通过堆叠多个3×3的窗口可以替代一个更大的窗口,而且现在的GPU设备针对3×3大小的卷积核做了很多的优化,所以会更高效。接着作者做了如下两个改动:
- Moving up depthwise conv layer:上移深度卷积层
- Increasing the kernel size:增大卷积核尺寸
5.1 Moving up depthwise conv layer —— 上移深度卷积层
Moving up depthwise conv layer,即将depthwise conv模块上移:
- 原来是
1×1 conv -> depthwise conv -> 1×1 conv - 现在变成了
depthwise conv -> 1×1 conv -> 1×1 conv。
这么做是因为在Transformer中,MSA模块(multi-head self-attention module)是放在MLP模块之前的,所以这里进行效仿,将depthwise conv上移。
这样改动后,准确率下降到了79.9%,同时FLOPs也减小了。
5.2 Increasing the kernel size —— 增大卷积核尺寸
Increasing the kernel size,接着作者将depthwise conv的卷积核大小由3×3改成了7×7(和Swin Transformer一样),当然作者也尝试了其他尺寸,包括3, 5, 7, 9, 11发现取到7时准确率就达到了饱和。
这里作者通过实验获得的7和Swin Transformer中的7是一样的 —— 缘,妙不可言😂
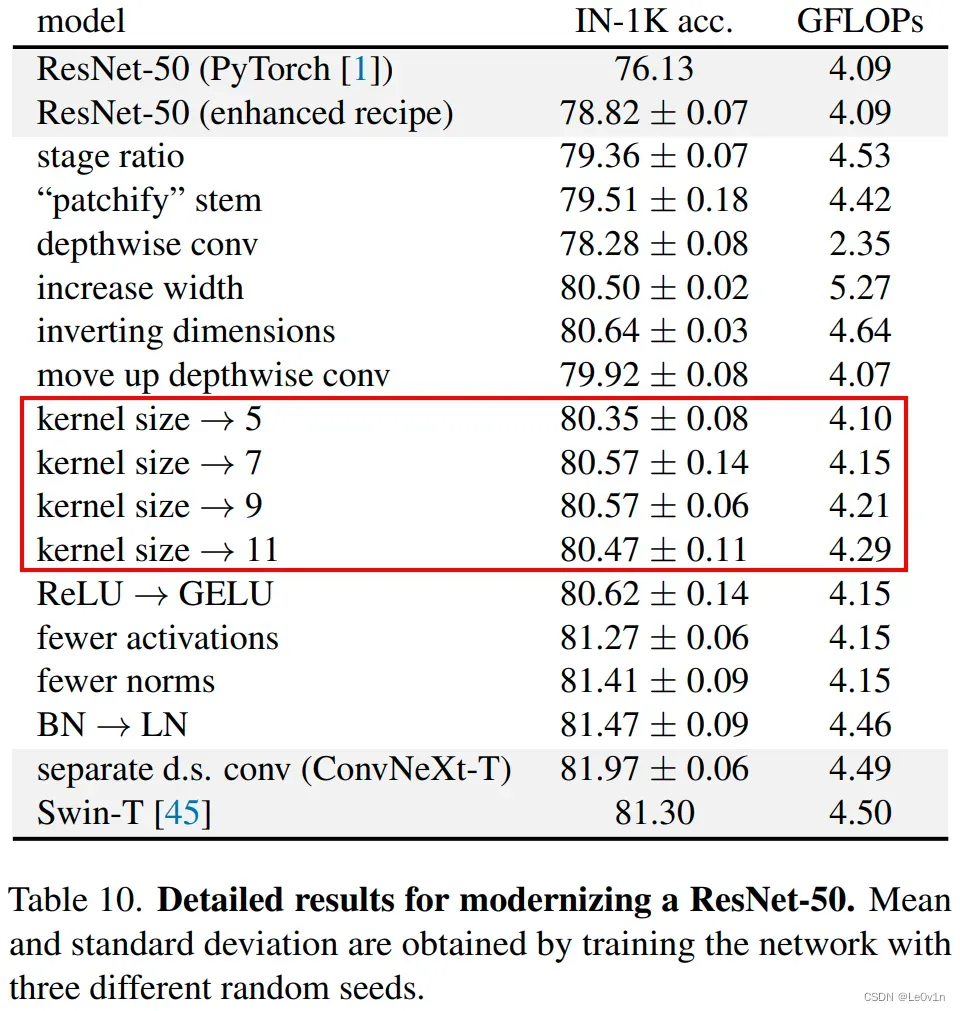
表 10. ResNet-50 现代化的详细结果。 通过使用三种不同的随机种子训练网络来获得均值和标准差。
改动卷积核后,准确率从79.9% (3×3) 增长到 80.6% (7×7)。
6. Micro Design —— 微观设计
接下来作者在聚焦到一些更细小的差异,比如激活函数以及Normalization。
- Replacing ReLU with GELU:将ReLU激活函数替换为GELU(GAUSSIAN ERROR LINEAR UNITS)激活函数
- Fewer activation functions:使用更少的激活函数
- Fewer normalization layers:使用更少的归一化层
- Substituting BN with LN:将BN替换为LN
- Separate downsampling layers:使用单独的下采样层
6.1 ReLU -> GELU
Replacing ReLU with GELU,在Transformer中激活函数基本用的都是GELU,而在卷积神经网络中最常用的是ReLU,于是作者又将激活函数替换成了GELU,替换后发现准确率没变化。
6.2 更少的激活函数
Fewer activation functions,使用更少的激活函数。在卷积神经网络中,一般会在每个卷积层或全连接后都接上一个激活函数。但在Transformer中并不是每个模块后都跟有激活函数,比如MLP中只有第一个全连接层后跟了GELU激活函数。
作者在ConvNeXt Block中也减少激活函数的使用,如下图所示,减少后发现准确率从80.6%增长到81.3%。
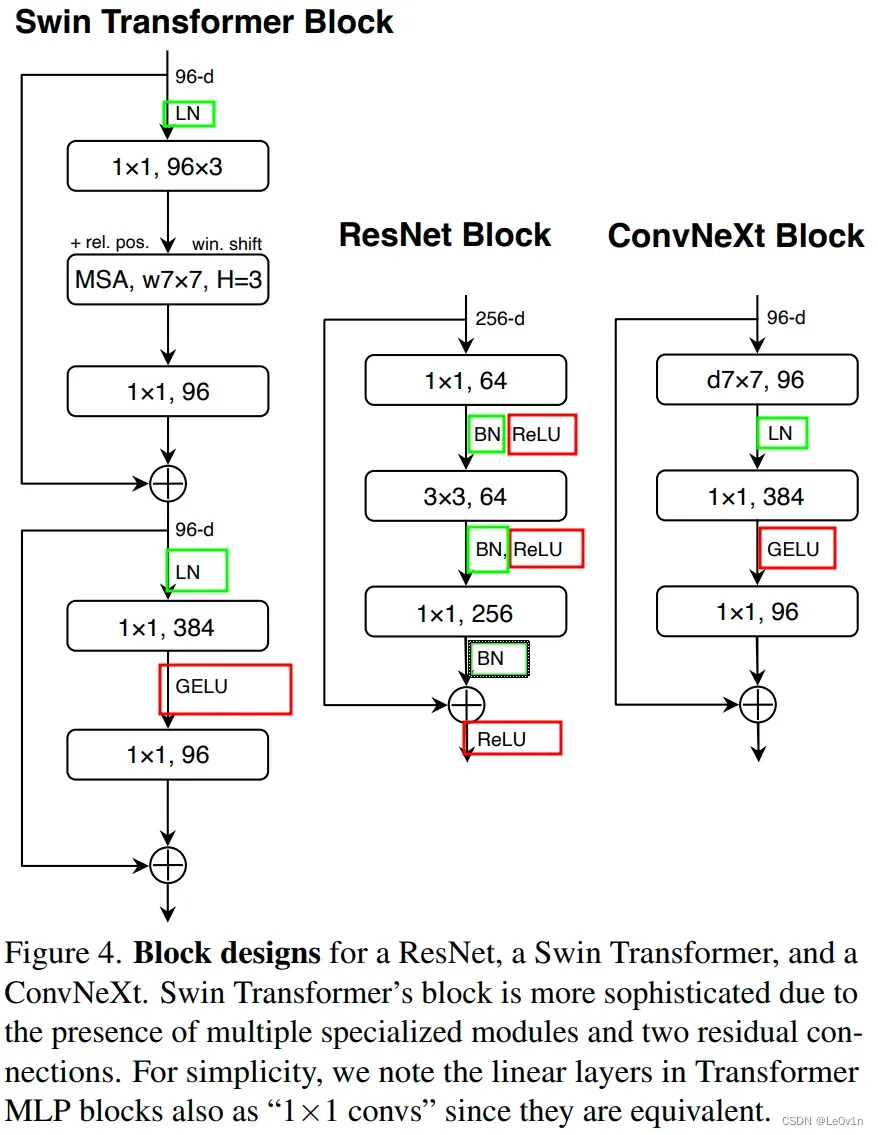
图 4. ResNet、Swin Transformer 和 ConvNeXt 的模块设计。 由于存在多个专用模块和两个残差连接,Swin Transformer 的模块更加复杂。 为简单起见,我们将 Transformer MLP 块中的线性层也称为“1×1 convs”,因为它们是等价的。
6.3 更少的归一化层
Fewer normalization layers,使用更少的Normalization。同样在Transformer中,Normalization使用的也比较少,接着作者也减少了ConvNeXt Block中的Normalization层,只保留了depthwise conv后的Normalization层。此时准确率已经达到了81.4%,已经超过了Swin-T。
6.4 BN -> LN
Substituting BN with LN,将BN替换成LN。Batch Normalization(BN)在卷积神经网络中是非常常用的操作了,它可以加速网络的收敛并减少过拟合(但用的不好也是个大坑)。但在Transformer中基本都用的Layer Normalization(LN),因为最开始Transformer是应用在NLP领域的,BN又不适用于NLP相关任务。
作者将BN全部替换成了LN,发现准确率还有小幅提升达到了81.5%。
6.5 使用单独的下采样层
Separate downsampling layers,单独的下采样层。在ResNet网络中stage2-stage4的下采样都是通过将主分支上3×3的卷积层步距设置成2,捷径分支上1×1的卷积层步距设置成2进行下采样的。但在Swin Transformer中是通过一个单独的Patch Merging实现的。
作者就为ConvNext网络单独使用了一个下采样层,就是通过一个Layer Normalization加上一个卷积核大小为2步距为2的卷积层构成。更改后准确率就提升到了82.0%。
7. ConvNeXt的版本
对于ConvNeXt网络,作者提出了T/S/B/L四个版本,计算复杂度刚好和Swin Transformer中的T/S/B/L相似。
We construct different ConvNeXt variants, ConvNeXt-T/S/B/L, to be of similar complexities to Swin-T/S/B/L.
我们构建了不同的 ConvNeXt 变体,ConvNeXt-T/S/B/L,与 Swin-T/S/B/L 具有相似的复杂性。
这四个版本的配置如下:
| ConvNeXt名称 | C | B |
|---|---|---|
| ConvNeXt-T | (96, 192, 384, 768) | (3, 3, 9, 3) |
| ConvNeXt-S | (96, 192, 384, 768) | (3, 3, 27, 3) |
| ConvNeXt-B | (128, 256, 512, 1024) | (3, 3, 27, 3) |
| ConvNeXt-L | (192, 384, 768, 1536) | (3, 3, 27, 3) |
| ConvNeXt-XL | (256, 512, 1024, 2048) | B = (3, 3, 27, 3) |
其中:
C代表4个stage中输入的通道数B代表每个stage重复堆叠block的次数
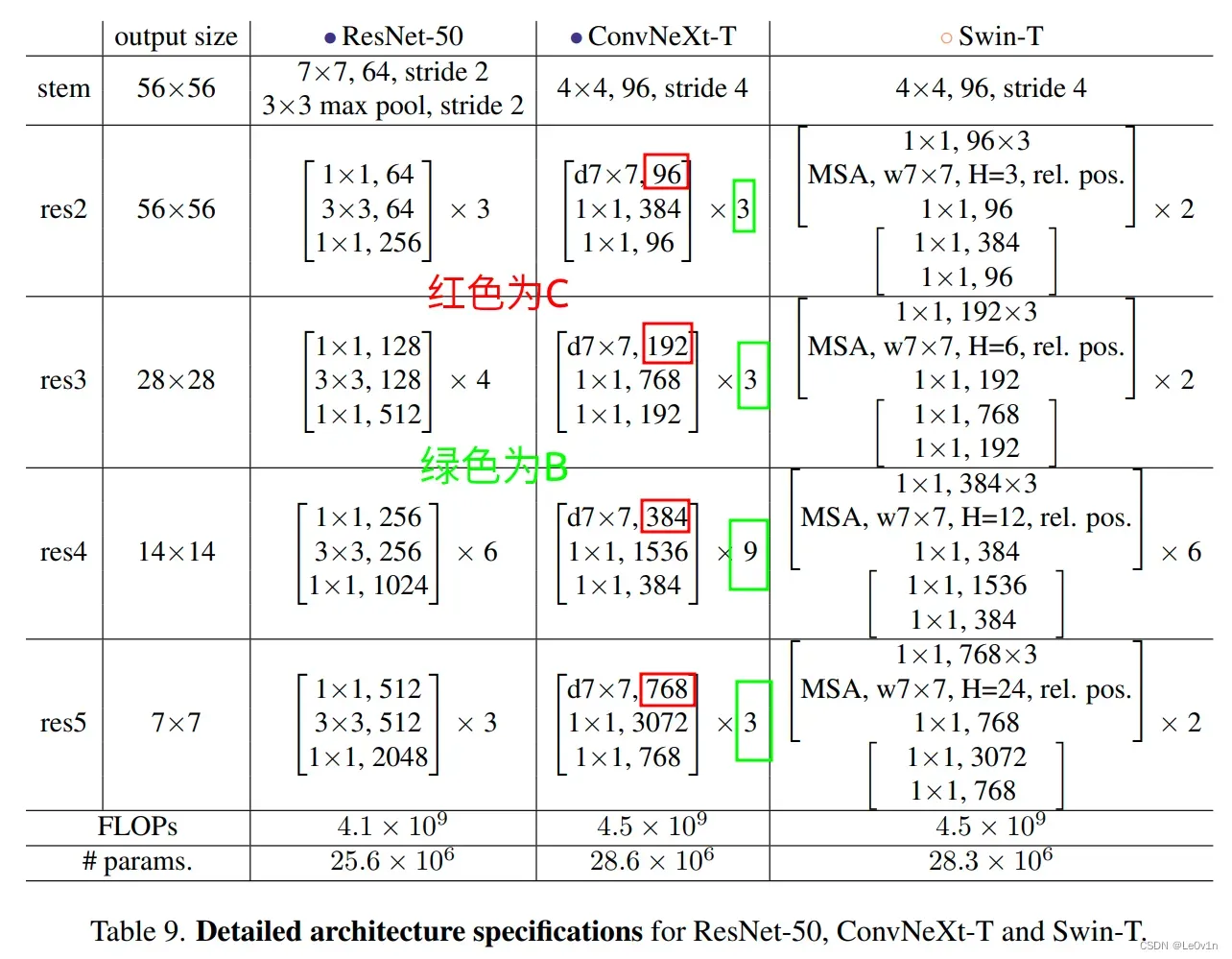
8. ConvNeXt-T 结构图
下图是霹雳吧啦WZ根据源码手绘的ConvNeXt-T网络结构图。
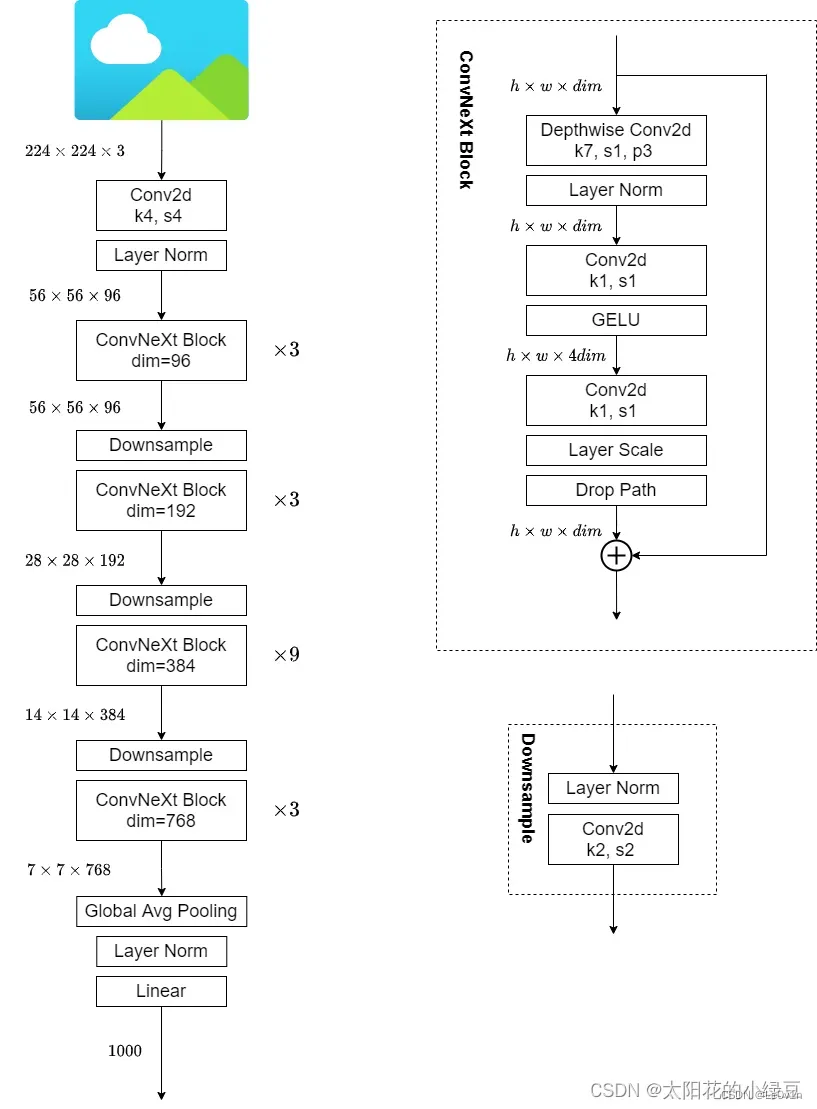
仔细观察ConvNeXt Block会发现其中还有一个Layer Scale操作(论文中并没有提到),其实它就是将输入的特征层乘上一个可训练的参数,该参数就是一个向量,元素个数与特征层channel相同,即对每个channel的数据进行缩放。Layer Scale操作出自于Going deeper with image transformers. ICCV, 2021这篇文章,有兴趣的可以自行了解。Layer Scale源码部分如下:
def __init__(self, dim, drop_rate=0., layer_scale_init_value=1e-6):
...
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim,)),
requires_grad=True) if layer_scale_init_value > 0 else None
...
def forward(self, x: torch.Tensor) -> torch.Tensor:
shortcut = x
x = self.dwconv(x)
...
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x # 调整每个channel的数据,实现缩放scale操作
...
return x
参考
- https://blog.csdn.net/qq_37541097/article/details/122556545
- https://www.bilibili.com/video/BV1SS4y157fu?spm_id_from=333.999.0.0
文章出处登录后可见!