前言
开放领域关系抽取(OpenRE)是一个比较常见的任务,其主要是从开放域的语料中抽取关系,目前大多数方法都没有充分的利用好手头已有的宝贵标注语料,今天介绍的这篇paper就提出了一个框架简称MORE,来解决这一问题,一起来看看吧~
论文链接:https://arxiv.org/pdf/2206.00289.pdf
方法
总体框架如下:
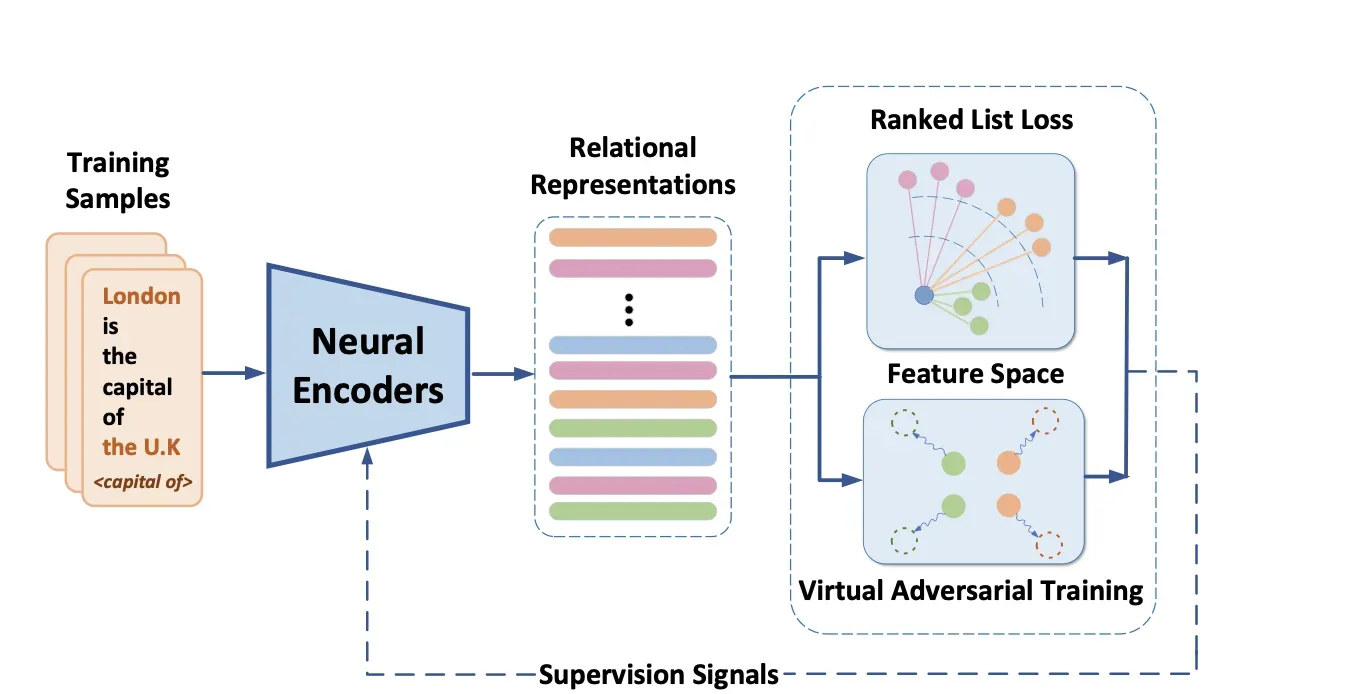
Neural Encoders
该模块是用来表征关系的,即把关系映射为一个embedding,当然了这里有很多方法,作者主要创新点也不是在这里,具体的作者使用了两种网络CNN和BERT,其中BERT就是多加了几个标识符如下:
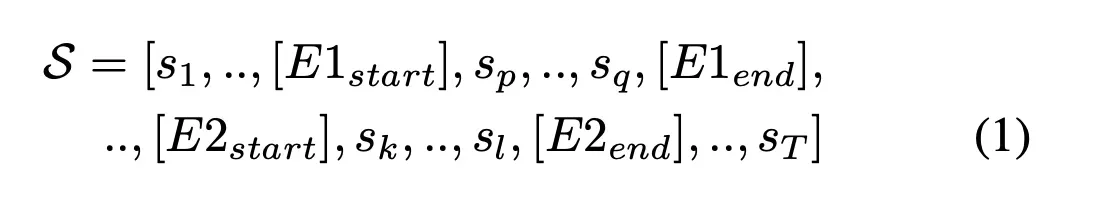
然后concatenate [E1start], [E2start]处的embedding来表征关系
Ranked List Loss
这里是作者的创新点,不像以往的triplet loss、N-pair等度量学习的loss,作者这里用了Ranked List Loss,因为前者都是point-based 或者成对pair-based,而后者想做set-based级别的,具体的计算方式如下:
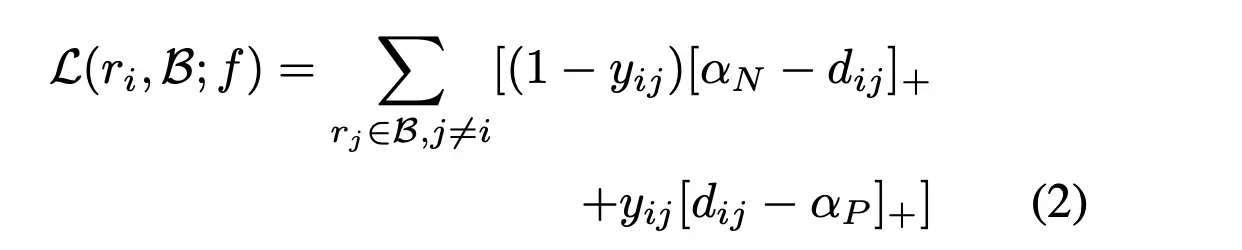
这里的r就是一个句子的关系表征,B可以理解为一个batch,当选取了一个句子即ri,那当前这个这个batch的样本与其的欧式距离为dij,这里把所有的样本分为两类,一类是positive一类是negative,其实就是和ri是相同标签就是positive,不同的就是negative,当是positive时,yij=1,否则是0。
为了更好的理解上述公式的实际作用,作者给了一张图:
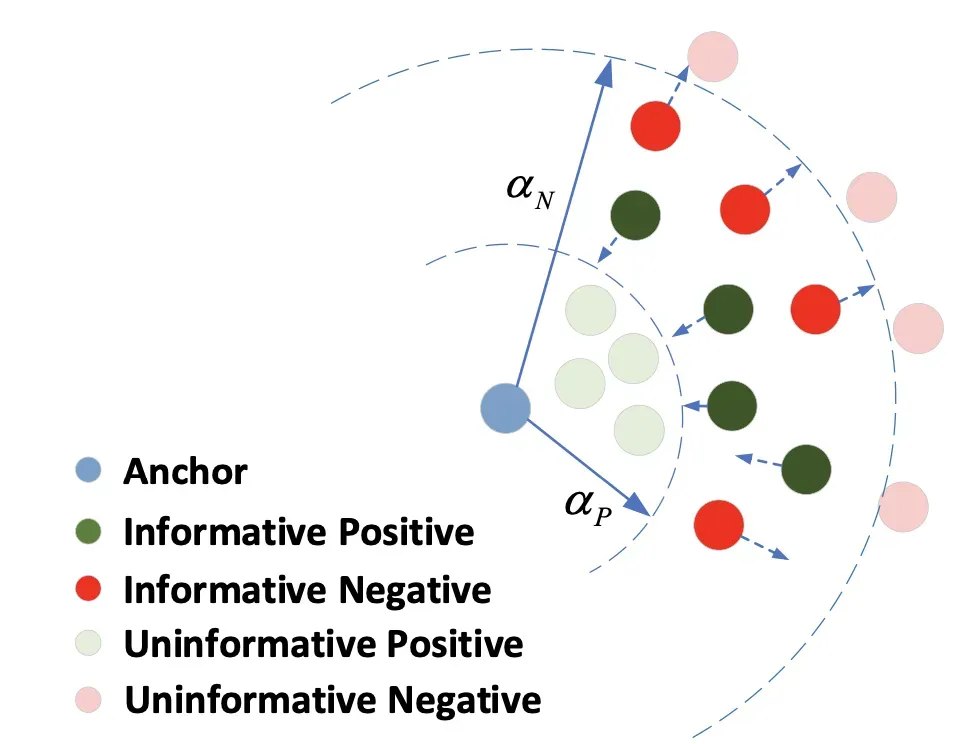
对于那些位于αP外的positive点会被拉近和Anchor(ri)的距离,对于那些位于αN内的negative点会被拉远和Anchor(ri)的距离。
为了更加具体说明,这里将αP和αN公式拆开便是:
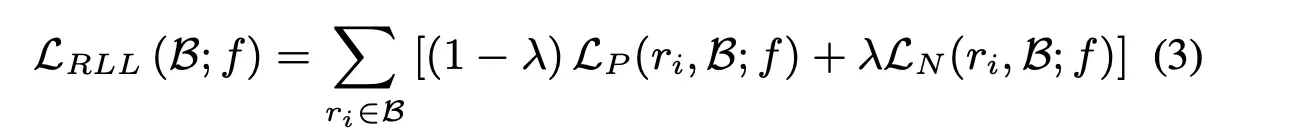
λ是一个平滑系数,实验中作者设置了为0.5。
当给定一个anchor时,在batch内会发现大量的negative样本点,这里作者做了一个归一化,首先是定义了一个权重
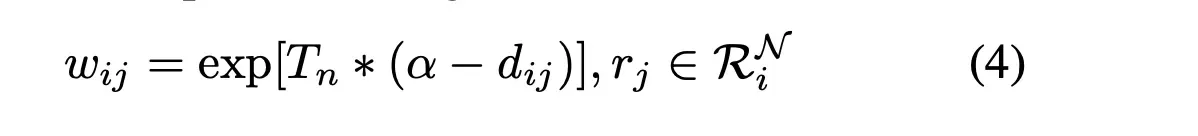
其中Tn是一个温度系数,比如当Tn=0时,那所有样本都是被同等对待,当Tn为正无穷时那基本上只关注最难的样本,所以最后套入公式(3)后便可得到
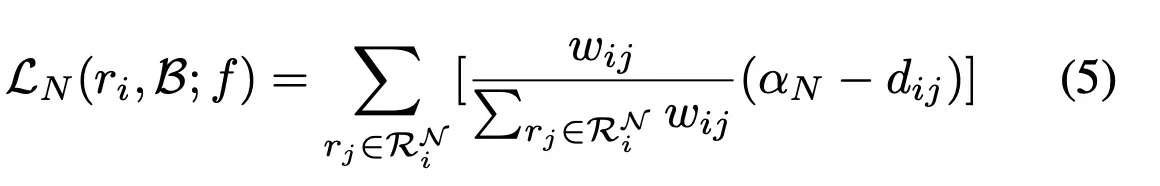
Virtua ladversarial training
为了使得训练的模型更有健壮性,作者使用了对抗学习进行训练,这里就不多讲了,是很常见的对抗方法,说白了就是对embedding进行扰动,感兴趣的小伙伴可以看笔者之前写过的一篇,里面也给出了具体实现的逻辑代码:
 https://zhuanlan.zhihu.com/p/422169401
https://zhuanlan.zhihu.com/p/422169401实验
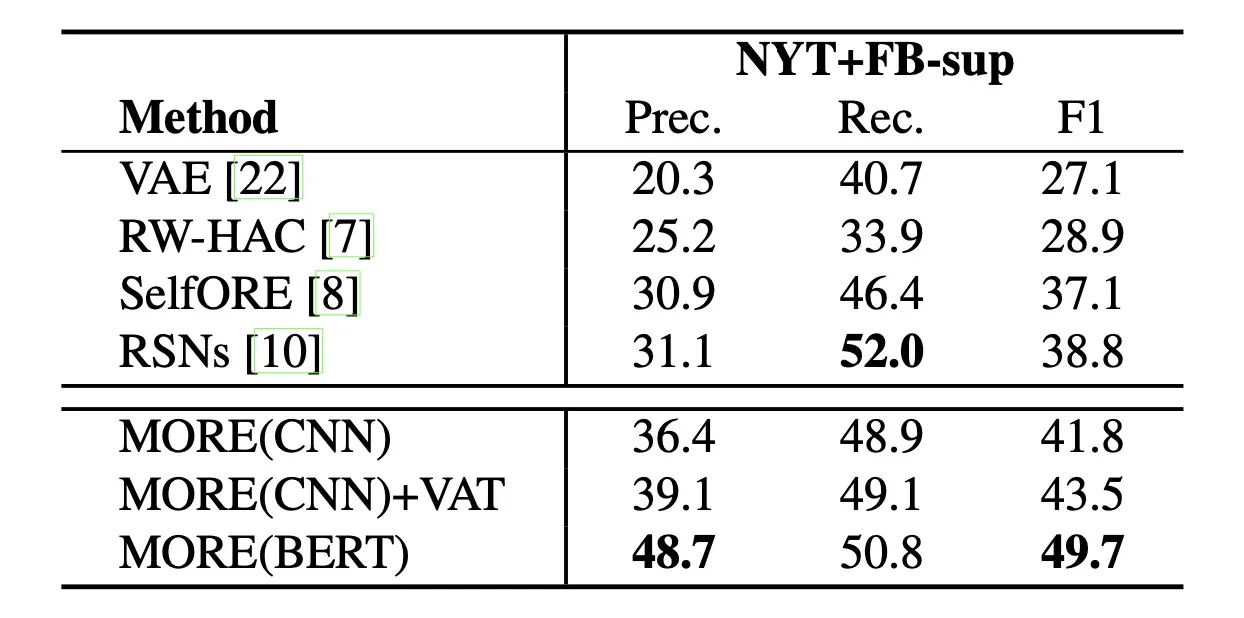
作者这里在两个数据集上做的实验:FewRel和NYT+FB,实验结果如下:
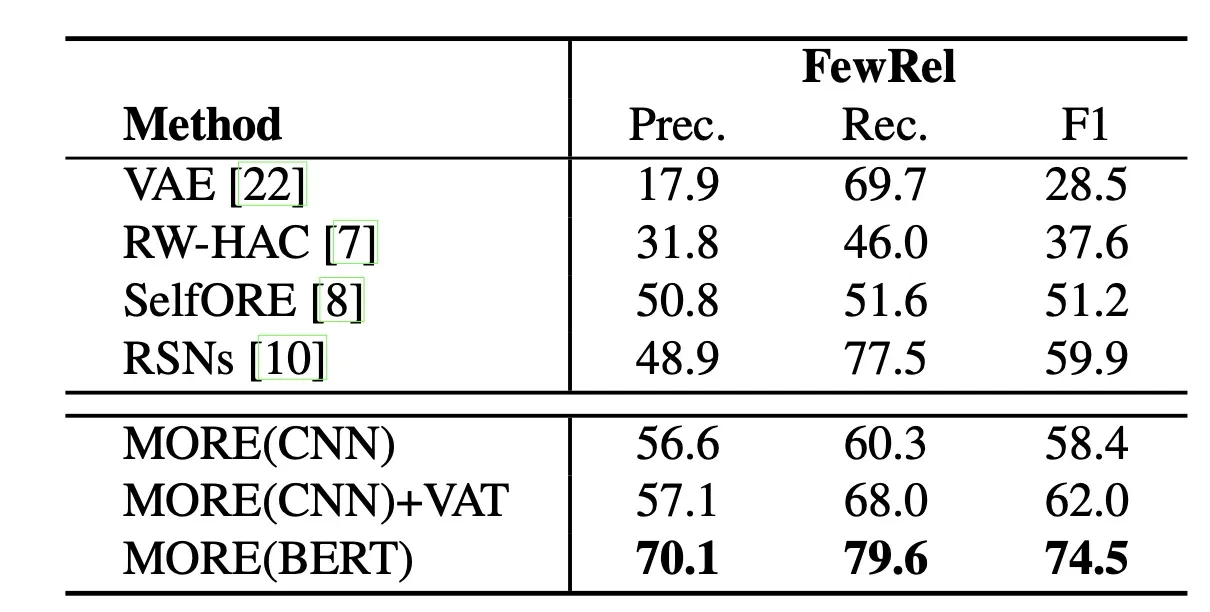
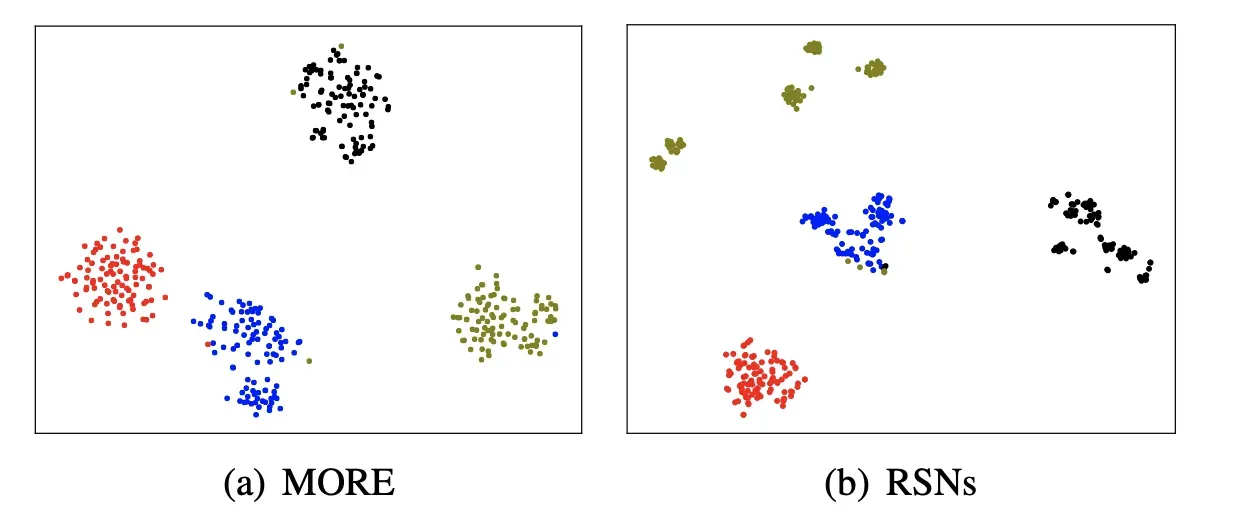
同时还给了在FewRel上的可视化结果:
总结
不知道大家看到作者paper中提到的Ranked List Loss有没有想到交叉熵以及svm中公式,在一定程度上是很像的,总之吧这个Ranked List Loss就是全文的创新点,别的基本上都很常规,大家感兴趣的话可以在自己领域试试吧。
关注
欢迎关注,下期再见啦~
欢迎关注笔者微信公众号:

github:
Mryangkaitong · GitHubhttps://github.com/Mryangkaitong
知乎:
文章出处登录后可见!