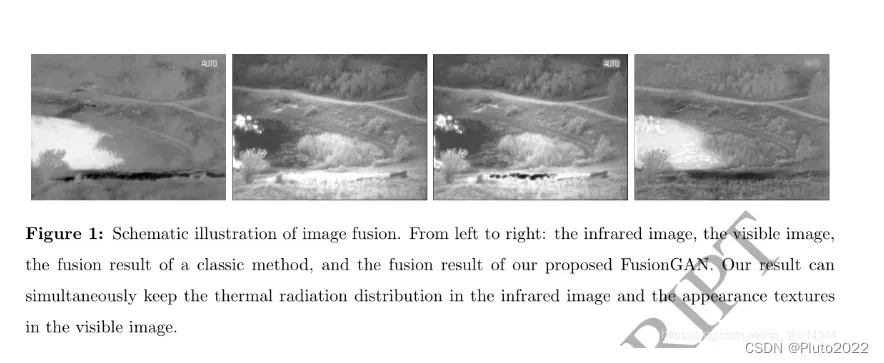
这是首个使用GAN来融合红外与可见光图像的模型,通过生成器和判别器之间的对抗学习避免人工设计activity level和融合规则 。
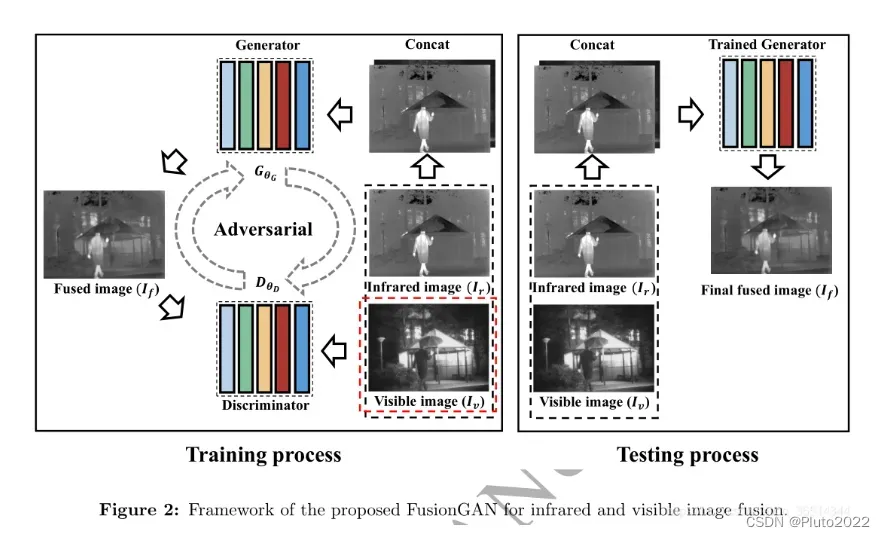
其中生成器同时将红外图像与可见光图像作为输入,输出融合图像;由于可见光图像的纹理细节不能全部都用梯度表示,所以需要用判别器单独调整融合图像中的可见光信息,判别器将融合图像与可见光图像作为输入,得到一个分类结果,用于区分融合图像与可见光图像。
在生成器和判别器的对抗学习过程中,融合图像中保留的可见光信息将逐渐增多。训练完成后,只保留生成器进行图像融合即可。生成器和判别器的网络模型如下图
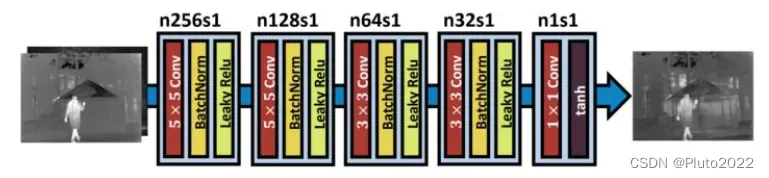
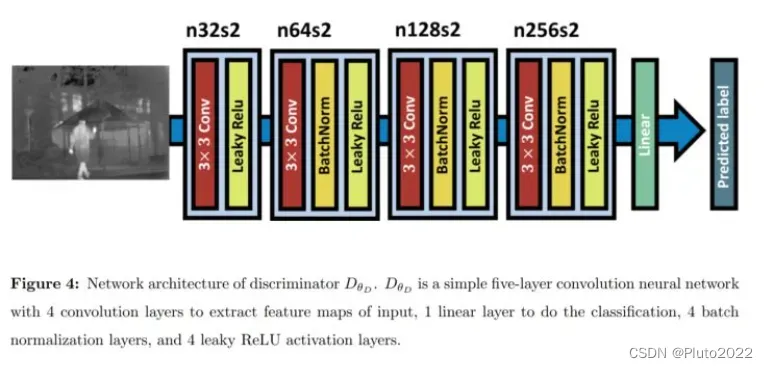
生成器的损失函数主要包括adversarial loss和content loss,如下式。
![]()
第一项的adversarial loss的设计如下式。
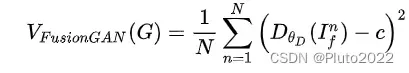
第二项content loss希望融合图像兼具红外图像的像素值幅度信息和可见光图像的纹理细节信息,所以两项分别计算了像素差异和梯度差异,如下式。其中F代表Frobenius范数, 表示梯度算子。
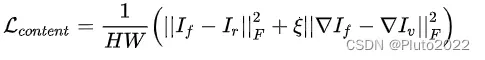
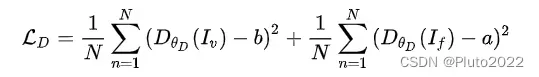
提出方法:
训练迭代:
# -*- coding: utf-8 -*-
from model import CGAN
from utils import input_setup
import numpy as np
import tensorflow as tf
tf.disable_v2_behavior()
import pprint
import os
flags = tf.app.flags
flags.DEFINE_integer("epoch", 10, "Number of epoch [10]")
flags.DEFINE_integer("batch_size", 32, "The size of batch images [128]")
flags.DEFINE_integer("image_size", 132, "The size of image to use [33]")
flags.DEFINE_integer("label_size", 120, "The size of label to produce [21]")
flags.DEFINE_float("learning_rate", 1e-4, "The learning rate of gradient descent algorithm [1e-4]")
flags.DEFINE_integer("c_dim", 1, "Dimension of image color. [1]")
flags.DEFINE_integer("scale", 3, "The size of scale factor for preprocessing input image [3]")
flags.DEFINE_integer("stride", 14, "The size of stride to apply input image [14]")
flags.DEFINE_string("checkpoint_dir", "checkpoint", "Name of checkpoint directory [checkpoint]")
flags.DEFINE_string("sample_dir", "sample", "Name of sample directory [sample]")
flags.DEFINE_string("summary_dir", "log", "Name of log directory [log]")
flags.DEFINE_boolean("is_train", True, "True for training, False for testing [True]")
FLAGS = flags.FLAGS
pp = pprint.PrettyPrinter()
def main(_):
pp.pprint(flags.FLAGS.__flags)
if not os.path.exists(FLAGS.checkpoint_dir):
os.makedirs(FLAGS.checkpoint_dir)
if not os.path.exists(FLAGS.sample_dir):
os.makedirs(FLAGS.sample_dir)
with tf.Session() as sess:
srcnn = CGAN(sess,
image_size=FLAGS.image_size,
label_size=FLAGS.label_size,
batch_size=FLAGS.batch_size,
c_dim=FLAGS.c_dim,
checkpoint_dir=FLAGS.checkpoint_dir,
sample_dir=FLAGS.sample_dir)
srcnn.train(FLAGS)
if __name__ == '__main__':
tf.app.run()
model.py
# -*- coding: utf-8 -*-
from utils import (
read_data,
input_setup,
imsave,
merge,
gradient,
lrelu,
weights_spectral_norm,
l2_norm
)
import time
import os
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
class CGAN(object):
def __init__(self,
sess,
image_size=132,
label_size=120,
batch_size=32,
c_dim=1,
checkpoint_dir=None,
sample_dir=None):
self.sess = sess
self.is_grayscale = (c_dim == 1)
self.image_size = image_size
self.label_size = label_size
self.batch_size = batch_size
self.c_dim = c_dim
self.checkpoint_dir = checkpoint_dir
self.sample_dir = sample_dir
self.build_model()
def build_model(self):
with tf.name_scope('IR_input'):
#红外图像patch
self.images_ir = tf.placeholder(tf.float32, [None, self.image_size, self.image_size, self.c_dim], name='images_ir')
self.labels_ir = tf.placeholder(tf.float32, [None, self.label_size, self.label_size, self.c_dim], name='labels_ir')
with tf.name_scope('VI_input'):
#可见光图像patch
self.images_vi = tf.placeholder(tf.float32, [None, self.image_size, self.image_size, self.c_dim], name='images_vi')
self.labels_vi = tf.placeholder(tf.float32, [None, self.label_size, self.label_size, self.c_dim], name='labels_vi')
#self.labels_vi_gradient=gradient(self.labels_vi)
#将红外和可见光图像在通道方向连起来,第一通道是红外图像,第二通道是可见光图像
with tf.name_scope('input'):
#self.resize_ir=tf.image.resize_images(self.images_ir, (self.image_size, self.image_size), method=2)
self.input_image=tf.concat([self.images_ir,self.images_vi],axis=-1)
#self.pred=tf.clip_by_value(tf.sign(self.pred_ir-self.pred_vi),0,1)
#融合图像
with tf.name_scope('fusion'):
self.fusion_image=self.fusion_model(self.input_image)
with tf.name_scope('d_loss'):
#判决器对可见光图像和融合图像的预测
#pos=self.discriminator(self.labels_vi,reuse=False)
pos=self.discriminator(self.labels_vi,reuse=False)
neg=self.discriminator(self.fusion_image,reuse=True,update_collection='NO_OPS')
#把真实样本尽量判成1否则有损失(判决器的损失)
#pos_loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=pos, labels=tf.ones_like(pos)))
#pos_loss=tf.reduce_mean(tf.square(pos-tf.ones_like(pos)))
pos_loss=tf.reduce_mean(tf.square(pos-tf.random_uniform(shape=[self.batch_size,1],minval=0.7,maxval=1.2)))
#把生成样本尽量判断成0否则有损失(判决器的损失)
#neg_loss=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=neg, labels=tf.zeros_like(neg)))
#neg_loss=tf.reduce_mean(tf.square(neg-tf.zeros_like(neg)))
neg_loss=tf.reduce_mean(tf.square(neg-tf.random_uniform(shape=[self.batch_size,1],minval=0,maxval=0.3,dtype=tf.float32)))
#self.d_loss=pos_loss+neg_loss
self.d_loss=neg_loss+pos_loss
tf.summary.scalar('loss_d',self.d_loss)
with tf.name_scope('g_loss'):
#self.g_loss_1=tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=neg, labels=tf.ones_like(neg)))
#self.g_loss_1=tf.reduce_mean(tf.square(neg-tf.ones_like(pos)))
self.g_loss_1=tf.reduce_mean(tf.square(neg-tf.random_uniform(shape=[self.batch_size,1],minval=0.7,maxval=1.2,dtype=tf.float32)))
tf.summary.scalar('g_loss_1',self.g_loss_1)
#self.g_loss_2=tf.reduce_mean(tf.square(self.fusion_image - self.labels_ir))
self.g_loss_2=tf.reduce_mean(tf.square(self.fusion_image - self.labels_ir))+5*tf.reduce_mean(tf.square(gradient(self.fusion_image) -gradient (self.labels_vi)))
tf.summary.scalar('g_loss_2',self.g_loss_2)
self.g_loss_total=self.g_loss_1+100*self.g_loss_2
tf.summary.scalar('loss_g',self.g_loss_total)
self.saver = tf.train.Saver(max_to_keep=50)
def train(self, config):
if config.is_train:
input_setup(self.sess, config,"Train_ir")
input_setup(self.sess,config,"Train_vi")
else:
nx_ir, ny_ir = input_setup(self.sess, config,"Test_ir")
nx_vi,ny_vi=input_setup(self.sess, config,"Test_vi")
if config.is_train:
data_dir_ir = os.path.join('./{}'.format(config.checkpoint_dir), "Train_ir","train.h5")
data_dir_vi = os.path.join('./{}'.format(config.checkpoint_dir), "Train_vi","train.h5")
else:
data_dir_ir = os.path.join('./{}'.format(config.checkpoint_dir),"Test_ir", "test.h5")
data_dir_vi = os.path.join('./{}'.format(config.checkpoint_dir),"Test_vi", "test.h5")
train_data_ir, train_label_ir = read_data(data_dir_ir)
train_data_vi, train_label_vi = read_data(data_dir_vi)
#找训练时更新的变量组(判决器和生成器是分开训练的,所以要找到对应的变量)
t_vars = tf.trainable_variables()
self.d_vars = [var for var in t_vars if 'discriminator' in var.name]
print(self.d_vars)
self.g_vars = [var for var in t_vars if 'fusion_model' in var.name]
print(self.g_vars)
# clip_ops = []
# for var in self.d_vars:
# clip_bounds = [-.01, .01]
# clip_ops.append(
# tf.assign(
# var,
# tf.clip_by_value(var, clip_bounds[0], clip_bounds[1])
# )
# )
# self.clip_disc_weights = tf.group(*clip_ops)
# Stochastic gradient descent with the standard backpropagation
with tf.name_scope('train_step'):
self.train_fusion_op = tf.train.AdamOptimizer(config.learning_rate).minimize(self.g_loss_total,var_list=self.g_vars)
self.train_discriminator_op=tf.train.AdamOptimizer(config.learning_rate).minimize(self.d_loss,var_list=self.d_vars)
#将所有统计的量合起来
self.summary_op = tf.summary.merge_all()
#生成日志文件
self.train_writer = tf.summary.FileWriter(config.summary_dir + '/train',self.sess.graph,flush_secs=60)
tf.initialize_all_variables().run()
counter = 0
start_time = time.time()
# if self.load(self.checkpoint_dir):
# print(" [*] Load SUCCESS")
# else:
# print(" [!] Load failed...")
if config.is_train:
print("Training...")
for ep in xrange(config.epoch):
# Run by batch images
batch_idxs = len(train_data_ir) // config.batch_size
for idx in xrange(0, batch_idxs):
batch_images_ir = train_data_ir[idx*config.batch_size : (idx+1)*config.batch_size]
batch_labels_ir = train_label_ir[idx*config.batch_size : (idx+1)*config.batch_size]
batch_images_vi = train_data_vi[idx*config.batch_size : (idx+1)*config.batch_size]
batch_labels_vi = train_label_vi[idx*config.batch_size : (idx+1)*config.batch_size]
counter += 1
for i in range(2):
_, err_d= self.sess.run([self.train_discriminator_op, self.d_loss], feed_dict={self.images_ir: batch_images_ir, self.images_vi: batch_images_vi, self.labels_vi: batch_labels_vi,self.labels_ir:batch_labels_ir})
# self.sess.run(self.clip_disc_weights)
_, err_g,summary_str= self.sess.run([self.train_fusion_op, self.g_loss_total,self.summary_op], feed_dict={self.images_ir: batch_images_ir, self.images_vi: batch_images_vi, self.labels_ir: batch_labels_ir,self.labels_vi:batch_labels_vi})
#将统计的量写到日志文件里
self.train_writer.add_summary(summary_str,counter)
if counter % 10 == 0:
print("Epoch: [%2d], step: [%2d], time: [%4.4f], loss_d: [%.8f],loss_g:[%.8f]" \
% ((ep+1), counter, time.time()-start_time, err_d,err_g))
#print(a)
self.save(config.checkpoint_dir, ep)
else:
print("Testing...")
result = self.fusion_image.eval(feed_dict={self.images_ir: train_data_ir, self.labels_ir: train_label_ir,self.images_vi: train_data_vi, self.labels_vi: train_label_vi})
result=result*127.5+127.5
result = merge(result, [nx_ir, ny_ir])
result = result.squeeze()
image_path = os.path.join(os.getcwd(), config.sample_dir)
image_path = os.path.join(image_path, "test_image.png")
imsave(result, image_path)
def fusion_model(self,img):
with tf.variable_scope('fusion_model'):
with tf.variable_scope('layer1'):
weights=tf.get_variable("w1",[5,5,2,256],initializer=tf.truncated_normal_initializer(stddev=1e-3))
weights=weights_spectral_norm(weights)
bias=tf.get_variable("b1",[256],initializer=tf.constant_initializer(0.0))
conv1_ir= tf.contrib.layers.batch_norm(tf.nn.conv2d(img, weights, strides=[1,1,1,1], padding='VALID') + bias, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True)
conv1_ir = lrelu(conv1_ir)
with tf.variable_scope('layer2'):
weights=tf.get_variable("w2",[5,5,256,128],initializer=tf.truncated_normal_initializer(stddev=1e-3))
weights=weights_spectral_norm(weights)
bias=tf.get_variable("b2",[128],initializer=tf.constant_initializer(0.0))
conv2_ir= tf.contrib.layers.batch_norm(tf.nn.conv2d(conv1_ir, weights, strides=[1,1,1,1], padding='VALID') + bias, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True)
conv2_ir = lrelu(conv2_ir)
with tf.variable_scope('layer3'):
weights=tf.get_variable("w3",[3,3,128,64],initializer=tf.truncated_normal_initializer(stddev=1e-3))
weights=weights_spectral_norm(weights)
bias=tf.get_variable("b3",[64],initializer=tf.constant_initializer(0.0))
conv3_ir= tf.contrib.layers.batch_norm(tf.nn.conv2d(conv2_ir, weights, strides=[1,1,1,1], padding='VALID') + bias, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True)
conv3_ir = lrelu(conv3_ir)
with tf.variable_scope('layer4'):
weights=tf.get_variable("w4",[3,3,64,32],initializer=tf.truncated_normal_initializer(stddev=1e-3))
weights=weights_spectral_norm(weights)
bias=tf.get_variable("b4",[32],initializer=tf.constant_initializer(0.0))
conv4_ir= tf.contrib.layers.batch_norm(tf.nn.conv2d(conv3_ir, weights, strides=[1,1,1,1], padding='VALID') + bias, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True)
conv4_ir = lrelu(conv4_ir)
with tf.variable_scope('layer5'):
weights=tf.get_variable("w5",[1,1,32,1],initializer=tf.truncated_normal_initializer(stddev=1e-3))
weights=weights_spectral_norm(weights)
bias=tf.get_variable("b5",[1],initializer=tf.constant_initializer(0.0))
conv5_ir= tf.nn.conv2d(conv4_ir, weights, strides=[1,1,1,1], padding='VALID') + bias
conv5_ir=tf.nn.tanh(conv5_ir)
return conv5_ir
def discriminator(self,img,reuse,update_collection=None):
with tf.variable_scope('discriminator',reuse=reuse):
print(img.shape)
with tf.variable_scope('layer_1'):
weights=tf.get_variable("w_1",[3,3,1,32],initializer=tf.truncated_normal_initializer(stddev=1e-3))
weights=weights_spectral_norm(weights,update_collection=update_collection)
bias=tf.get_variable("b_1",[32],initializer=tf.constant_initializer(0.0))
conv1_vi=tf.nn.conv2d(img, weights, strides=[1,2,2,1], padding='VALID') + bias
conv1_vi = lrelu(conv1_vi)
#print(conv1_vi.shape)
with tf.variable_scope('layer_2'):
weights=tf.get_variable("w_2",[3,3,32,64],initializer=tf.truncated_normal_initializer(stddev=1e-3))
weights=weights_spectral_norm(weights,update_collection=update_collection)
bias=tf.get_variable("b_2",[64],initializer=tf.constant_initializer(0.0))
conv2_vi= tf.contrib.layers.batch_norm(tf.nn.conv2d(conv1_vi, weights, strides=[1,2,2,1], padding='VALID') + bias, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True)
conv2_vi = lrelu(conv2_vi)
#print(conv2_vi.shape)
with tf.variable_scope('layer_3'):
weights=tf.get_variable("w_3",[3,3,64,128],initializer=tf.truncated_normal_initializer(stddev=1e-3))
weights=weights_spectral_norm(weights,update_collection=update_collection)
bias=tf.get_variable("b_3",[128],initializer=tf.constant_initializer(0.0))
conv3_vi= tf.contrib.layers.batch_norm(tf.nn.conv2d(conv2_vi, weights, strides=[1,2,2,1], padding='VALID') + bias, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True)
conv3_vi=lrelu(conv3_vi)
#print(conv3_vi.shape)
with tf.variable_scope('layer_4'):
weights=tf.get_variable("w_4",[3,3,128,256],initializer=tf.truncated_normal_initializer(stddev=1e-3))
weights=weights_spectral_norm(weights,update_collection=update_collection)
bias=tf.get_variable("b_4",[256],initializer=tf.constant_initializer(0.0))
conv4_vi= tf.contrib.layers.batch_norm(tf.nn.conv2d(conv3_vi, weights, strides=[1,2,2,1], padding='VALID') + bias, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True)
conv4_vi=lrelu(conv4_vi)
conv4_vi = tf.reshape(conv4_vi,[self.batch_size,6*6*256])
with tf.variable_scope('line_5'):
weights=tf.get_variable("w_5",[6*6*256,1],initializer=tf.truncated_normal_initializer(stddev=1e-3))
weights=weights_spectral_norm(weights,update_collection=update_collection)
bias=tf.get_variable("b_5",[1],initializer=tf.constant_initializer(0.0))
line_5=tf.matmul(conv4_vi, weights) + bias
#conv3_vi= tf.contrib.layers.batch_norm(conv3_vi, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True)
return line_5
def save(self, checkpoint_dir, step):
model_name = "CGAN.model"
model_dir = "%s_%s" % ("CGAN", self.label_size)
checkpoint_dir = os.path.join(checkpoint_dir, model_dir)
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
self.saver.save(self.sess,
os.path.join(checkpoint_dir, model_name),
global_step=step)
def load(self, checkpoint_dir):
print(" [*] Reading checkpoints...")
model_dir = "%s_%s" % ("CGAN", self.label_size)
checkpoint_dir = os.path.join(checkpoint_dir, model_dir)
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
ckpt_name = os.path.basename(ckpt.model_checkpoint_path)
print(ckpt_name)
self.saver.restore(self.sess, os.path.join(checkpoint_dir,ckpt_name))
return True
else:
return False
Test_one_image.py
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import scipy.misc
import time
import os
import glob
import imageio
import cv2
#reader = tf.train.NewCheckpointReader("./checkpoint/CGAN_120/CGAN.model-9")
def imread(path, is_grayscale=True):
"""
Read image using its path.
Default value is gray-scale, and image is read by YCbCr format as the paper said.
"""
if is_grayscale:
#flatten=True 以灰度图的形式读取
return scipy.misc.imread(path, flatten=True, mode='YCbCr').astype(np.float)
else:
return scipy.misc.imread(path, mode='YCbCr').astype(np.float)
def imsave(image, path):
return scipy.misc.imsave(path, image)
def prepare_data(dataset):
data_dir = os.path.join(os.sep, (os.path.join(os.getcwd(), dataset)))
data = glob.glob(os.path.join(data_dir, "*.jpg"))
data.extend(glob.glob(os.path.join(data_dir, "*.bmp")))
data.sort(key=lambda x:int(x[len(data_dir)+1:-4]))
return data
def lrelu(x, leak=0.2):
return tf.maximum(x, leak * x)
def fusion_model(img):
with tf.variable_scope('fusion_model'):
with tf.variable_scope('layer1'):
weights=tf.get_variable("w1",initializer=tf.constant(reader.get_tensor('fusion_model/layer1/w1')))
bias=tf.get_variable("b1",initializer=tf.constant(reader.get_tensor('fusion_model/layer1/b1')))
conv1_ir= tf.contrib.layers.batch_norm(tf.nn.conv2d(img, weights, strides=[1,1,1,1], padding='VALID') + bias, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True)
conv1_ir = lrelu(conv1_ir)
with tf.variable_scope('layer2'):
weights=tf.get_variable("w2",initializer=tf.constant(reader.get_tensor('fusion_model/layer2/w2')))
bias=tf.get_variable("b2",initializer=tf.constant(reader.get_tensor('fusion_model/layer2/b2')))
conv2_ir= tf.contrib.layers.batch_norm(tf.nn.conv2d(conv1_ir, weights, strides=[1,1,1,1], padding='VALID') + bias, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True)
conv2_ir = lrelu(conv2_ir)
with tf.variable_scope('layer3'):
weights=tf.get_variable("w3",initializer=tf.constant(reader.get_tensor('fusion_model/layer3/w3')))
bias=tf.get_variable("b3",initializer=tf.constant(reader.get_tensor('fusion_model/layer3/b3')))
conv3_ir= tf.contrib.layers.batch_norm(tf.nn.conv2d(conv2_ir, weights, strides=[1,1,1,1], padding='VALID') + bias, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True)
conv3_ir = lrelu(conv3_ir)
with tf.variable_scope('layer4'):
weights=tf.get_variable("w4",initializer=tf.constant(reader.get_tensor('fusion_model/layer4/w4')))
bias=tf.get_variable("b4",initializer=tf.constant(reader.get_tensor('fusion_model/layer4/b4')))
conv4_ir= tf.contrib.layers.batch_norm(tf.nn.conv2d(conv3_ir, weights, strides=[1,1,1,1], padding='VALID') + bias, decay=0.9, updates_collections=None, epsilon=1e-5, scale=True)
conv4_ir = lrelu(conv4_ir)
with tf.variable_scope('layer5'):
weights=tf.get_variable("w5",initializer=tf.constant(reader.get_tensor('fusion_model/layer5/w5')))
bias=tf.get_variable("b5",initializer=tf.constant(reader.get_tensor('fusion_model/layer5/b5')))
conv5_ir= tf.nn.conv2d(conv4_ir, weights, strides=[1,1,1,1], padding='VALID') + bias
conv5_ir=tf.nn.tanh(conv5_ir)
return conv5_ir
def input_setup(index):
padding=6
sub_ir_sequence = []
sub_vi_sequence = []
input_ir=(imread(data_ir[index])-127.5)/127.5
input_ir=np.lib.pad(input_ir,((padding,padding),(padding,padding)),'edge')
w,h=input_ir.shape
input_ir=input_ir.reshape([w,h,1])
input_vi=(imread(data_vi[index])-127.5)/127.5
input_vi=np.lib.pad(input_vi,((padding,padding),(padding,padding)),'edge')
w,h=input_vi.shape
input_vi=input_vi.reshape([w,h,1])
sub_ir_sequence.append(input_ir)
sub_vi_sequence.append(input_vi)
train_data_ir= np.asarray(sub_ir_sequence)
train_data_vi= np.asarray(sub_vi_sequence)
return train_data_ir,train_data_vi
num_epoch=3
while(num_epoch==3):
reader = tf.train.NewCheckpointReader('./checkpoint/CGAN_120/CGAN.model-'+ str(num_epoch))
with tf.name_scope('IR_input'):
#红外图像patch
images_ir = tf.placeholder(tf.float32, [1,None,None,None], name='images_ir')
with tf.name_scope('VI_input'):
#可见光图像patch
images_vi = tf.placeholder(tf.float32, [1,None,None,None], name='images_vi')
#self.labels_vi_gradient=gradient(self.labels_vi)
#将红外和可见光图像在通道方向连起来,第一通道是红外图像,第二通道是可见光图像
with tf.name_scope('input'):
#resize_ir=tf.image.resize_images(images_ir, (512, 512), method=2)
input_image=tf.concat([images_ir,images_vi],axis=-1)
with tf.name_scope('fusion'):
fusion_image=fusion_model(input_image)
with tf.Session() as sess:
init_op=tf.global_variables_initializer()
sess.run(init_op)
data_ir=prepare_data('Test_ir')
data_vi=prepare_data('Test_vi')
for i in range(len(data_ir)):
start=time.time()
train_data_ir,train_data_vi=input_setup(i)
result =sess.run(fusion_image,feed_dict={images_ir: train_data_ir,images_vi: train_data_vi})
result=result*127.5+127.5
result = result.squeeze()
image_path = os.path.join(os.getcwd(), 'result','epoch'+str(num_epoch))
if not os.path.exists(image_path):
os.makedirs(image_path)
if i<=9:
image_path = os.path.join(image_path,'F9_0'+str(i)+".bmp")
else:
image_path = os.path.join(image_path,'F9_'+str(i)+".bmp")
end=time.time()
# print(out.shape)
imsave(result, image_path)
print("Testing [%d] success,Testing time is [%f]"%(i,end-start))
tf.reset_default_graph()
num_epoch=num_epoch+1
utils.py
# -*- coding: utf-8 -*-
"""
Scipy version > 0.18 is needed, due to 'mode' option from scipy.misc.imread function
"""
import os
import glob
import h5py
import random
import matplotlib.pyplot as plt
from PIL import Image # for loading images as YCbCr format
import scipy.misc
import scipy.ndimage
import numpy as np
import tensorflow as tf
import cv2
FLAGS = tf.app.flags.FLAGS
def read_data(path):
"""
Read h5 format data file
Args:
path: file path of desired file
data: '.h5' file format that contains train data values
label: '.h5' file format that contains train label values
"""
with h5py.File(path, 'r') as hf:
data = np.array(hf.get('data'))
label = np.array(hf.get('label'))
return data, label
def preprocess(path, scale=3):
"""
Preprocess single image file
(1) Read original image as YCbCr format (and grayscale as default)
(2) Normalize
(3) Apply image file with bicubic interpolation
Args:
path: file path of desired file
input_: image applied bicubic interpolation (low-resolution)
label_: image with original resolution (high-resolution)
"""
#读到图片
image = imread(path, is_grayscale=True)
#将图片label裁剪为scale的倍数
label_ = modcrop(image, scale)
# Must be normalized
image = (image-127.5 )/ 127.5
label_ = (image-127.5 )/ 127.5
#下采样之后再插值
input_ = scipy.ndimage.interpolation.zoom(label_, (1./scale), prefilter=False)
input_ = scipy.ndimage.interpolation.zoom(input_, (scale/1.), prefilter=False)
return input_, label_
def prepare_data(sess, dataset):
"""
Args:
dataset: choose train dataset or test dataset
For train dataset, output data would be ['.../t1.bmp', '.../t2.bmp', ..., '.../t99.bmp']
"""
if FLAGS.is_train:
filenames = os.listdir(dataset)
data_dir = os.path.join(os.getcwd(), dataset)
data = glob.glob(os.path.join(data_dir, "*.bmp"))
data.extend(glob.glob(os.path.join(data_dir, "*.tif")))
#将图片按序号排序
data.sort(key=lambda x:int(x[len(data_dir)+1:-4]))
else:
data_dir = os.path.join(os.sep, (os.path.join(os.getcwd(), dataset)))
data = glob.glob(os.path.join(data_dir, "*.bmp"))
data.extend(glob.glob(os.path.join(data_dir, "*.tif")))
data.sort(key=lambda x:int(x[len(data_dir)+1:-4]))
#print(data)
return data
def make_data(sess, data, label,data_dir):
"""
Make input data as h5 file format
Depending on 'is_train' (flag value), savepath would be changed.
"""
if FLAGS.is_train:
#savepath = os.path.join(os.getcwd(), os.path.join('checkpoint',data_dir,'train.h5'))
savepath = os.path.join('.', os.path.join('checkpoint_20',data_dir,'train.h5'))
if not os.path.exists(os.path.join('.',os.path.join('checkpoint_20',data_dir))):
os.makedirs(os.path.join('.',os.path.join('checkpoint_20',data_dir)))
else:
savepath = os.path.join('.', os.path.join('checkpoint_20',data_dir,'test.h5'))
if not os.path.exists(os.path.join('.',os.path.join('checkpoint_20',data_dir))):
os.makedirs(os.path.join('.',os.path.join('checkpoint_20',data_dir)))
with h5py.File(savepath, 'w') as hf:
hf.create_dataset('data', data=data)
hf.create_dataset('label', data=label)
def imread(path, is_grayscale=True):
"""
Read image using its path.
Default value is gray-scale, and image is read by YCbCr format as the paper said.
"""
if is_grayscale:
#flatten=True 以灰度图的形式读取
return scipy.misc.imread(path, flatten=True, mode='YCbCr').astype(np.float)
else:
return scipy.misc.imread(path, mode='YCbCr').astype(np.float)
def modcrop(image, scale=3):
"""
To scale down and up the original image, first thing to do is to have no remainder while scaling operation.
We need to find modulo of height (and width) and scale factor.
Then, subtract the modulo from height (and width) of original image size.
There would be no remainder even after scaling operation.
"""
if len(image.shape) == 3:
h, w, _ = image.shape
h = h - np.mod(h, scale)
w = w - np.mod(w, scale)
image = image[0:h, 0:w, :]
else:
h, w = image.shape
h = h - np.mod(h, scale)
w = w - np.mod(w, scale)
image = image[0:h, 0:w]
return image
def input_setup(sess,config,data_dir,index=0):
"""
Read image files and make their sub-images and saved them as a h5 file format.
"""
# Load data path
if config.is_train:
#取到所有的原始图片的地址
data = prepare_data(sess, dataset=data_dir)
else:
data = prepare_data(sess, dataset=data_dir)
sub_input_sequence = []
sub_label_sequence = []
padding = abs(config.image_size - config.label_size) / 2 # 6
if config.is_train:
for i in range(len(data)):
#input_, label_ = preprocess(data[i], config.scale)
input_=(imread(data[i])-127.5)/127.5
label_=input_
if len(input_.shape) == 3:
h, w, _ = input_.shape
else:
h, w = input_.shape
#按14步长采样小patch
for x in range(0, h-config.image_size+1, config.stride):
for y in range(0, w-config.image_size+1, config.stride):
sub_input = input_[x:x+config.image_size, y:y+config.image_size] # [33 x 33]
#注意这里的padding,前向传播时由于卷积是没有padding的,所以实际上预测的是测试patch的中间部分
sub_label = label_[x+padding:x+padding+config.label_size, y+padding:y+padding+config.label_size] # [21 x 21]
# Make channel value
if data_dir == "Train":
sub_input=cv2.resize(sub_input, (config.image_size/4,config.image_size/4),interpolation=cv2.INTER_CUBIC)
sub_input = sub_input.reshape([config.image_size/4, config.image_size/4, 1])
sub_label=cv2.resize(sub_label, (config.label_size/4,config.label_size/4),interpolation=cv2.INTER_CUBIC)
sub_label = sub_label.reshape([config.label_size/4, config.label_size/4, 1])
print('error')
else:
sub_input = sub_input.reshape([config.image_size, config.image_size, 1])
sub_label = sub_label.reshape([config.label_size, config.label_size, 1])
sub_input_sequence.append(sub_input)
sub_label_sequence.append(sub_label)
else:
#input_, label_ = preprocess(data[2], config.scale)
#input_=np.lib.pad((imread(data[index])-127.5)/127.5,((padding,padding),(padding,padding)),'edge')
#label_=input_
input_=(imread(data[index])-127.5)/127.5
if len(input_.shape) == 3:
h_real, w_real, _ = input_.shape
else:
h_real, w_real = input_.shape
padding_h=config.image_size-((h_real+padding)%config.label_size)
padding_w=config.image_size-((w_real+padding)%config.label_size)
input_=np.lib.pad(input_,((padding,padding_h),(padding,padding_w)),'edge')
label_=input_
h,w=input_.shape
#print(input_.shape)
# Numbers of sub-images in height and width of image are needed to compute merge operation.
nx = ny = 0
for x in range(0, h-config.image_size+1, config.stride):
nx += 1; ny = 0
for y in range(0, w-config.image_size+1, config.stride):
ny += 1
sub_input = input_[x:x+config.image_size, y:y+config.image_size] # [33 x 33]
sub_label = label_[x+padding:x+padding+config.label_size, y+padding:y+padding+config.label_size] # [21 x 21]
sub_input = sub_input.reshape([config.image_size, config.image_size, 1])
sub_label = sub_label.reshape([config.label_size, config.label_size, 1])
sub_input_sequence.append(sub_input)
sub_label_sequence.append(sub_label)
"""
len(sub_input_sequence) : the number of sub_input (33 x 33 x ch) in one image
(sub_input_sequence[0]).shape : (33, 33, 1)
"""
# Make list to numpy array. With this transform
arrdata = np.asarray(sub_input_sequence) # [?, 33, 33, 1]
arrlabel = np.asarray(sub_label_sequence) # [?, 21, 21, 1]
#print(arrdata.shape)
make_data(sess, arrdata, arrlabel,data_dir)
if not config.is_train:
print(nx,ny)
print(h_real,w_real)
return nx, ny,h_real,w_real
def imsave(image, path):
return scipy.misc.imsave(path, image)
def merge(images, size):
h, w = images.shape[1], images.shape[2]
img = np.zeros((h*size[0], w*size[1], 1))
for idx, image in enumerate(images):
i = idx % size[1]
j = idx // size[1]
img[j*h:j*h+h, i*w:i*w+w, :] = image
return (img*127.5+127.5)
def gradient(input):
#filter_x=tf.reshape(tf.constant([[-1.,0.,1.],[-1.,0.,1.],[-1.,0.,1.]]),[3,3,1,1])
#filter_y=tf.reshape(tf.constant([[-1.,-1.,-1],[0,0,0],[1,1,1]]),[3,3,1,1])
#d_x=tf.nn.conv2d(input,filter_x,strides=[1,1,1,1], padding='SAME')
#d_y=tf.nn.conv2d(input,filter_y,strides=[1,1,1,1], padding='SAME')
#d=tf.sqrt(tf.square(d_x)+tf.square(d_y))
filter=tf.reshape(tf.constant([[0.,1.,0.],[1.,-4.,1.],[0.,1.,0.]]),[3,3,1,1])
d=tf.nn.conv2d(input,filter,strides=[1,1,1,1], padding='SAME')
#print(d)
return d
def weights_spectral_norm(weights, u=None, iteration=1, update_collection=None, reuse=False, name='weights_SN'):
with tf.variable_scope(name) as scope:
if reuse:
scope.reuse_variables()
w_shape = weights.get_shape().as_list()
w_mat = tf.reshape(weights, [-1, w_shape[-1]])
if u is None:
u = tf.get_variable('u', shape=[1, w_shape[-1]], initializer=tf.truncated_normal_initializer(), trainable=False)
def power_iteration(u, ite):
v_ = tf.matmul(u, tf.transpose(w_mat))
v_hat = l2_norm(v_)
u_ = tf.matmul(v_hat, w_mat)
u_hat = l2_norm(u_)
return u_hat, v_hat, ite+1
u_hat, v_hat,_ = power_iteration(u,iteration)
sigma = tf.matmul(tf.matmul(v_hat, w_mat), tf.transpose(u_hat))
w_mat = w_mat/sigma
if update_collection is None:
with tf.control_dependencies([u.assign(u_hat)]):
w_norm = tf.reshape(w_mat, w_shape)
else:
if not(update_collection == 'NO_OPS'):
print(update_collection)
tf.add_to_collection(update_collection, u.assign(u_hat))
w_norm = tf.reshape(w_mat, w_shape)
return w_norm
def lrelu(x, leak=0.2):
return tf.maximum(x, leak * x)
def l2_norm(input_x, epsilon=1e-12):
input_x_norm = input_x/(tf.reduce_sum(input_x**2)**0.5 + epsilon)
return input_x_norm
文章出处登录后可见!
已经登录?立即刷新